前段时间,接到某项目的压测需求。项目所有服务及中间件(redis、kafka)、pg库全部使用的阿里云。
压测工具:jmeter(分布式部署),3组负载机(每组1台主控、10台linux 负载机)
问题现象:
混合场景压测时,发现通过增加线程数、扩容被测服务数量等方式,服务整体吞吐量最大仅到TPS 1.6万左右(预期目标TPS 2万),不会随着线程的增加、服务容器数量增加而增长,且增加线程后,接口耗时开始增加。注:接口耗时正常应为100毫秒内,此时为1秒以上。
下图为几次压测后被测服务的总吞吐量。

问题诊断方向:(因压测的各接口未与数据库交互,数据库未纳入检查范围)
- 查看被测服务日志耗时。确认存在部分耗时超过1秒的日志。基本确认接口耗时慢问题在服务端。
- 检查被测服务的资源使用情况(CPU、内存、磁盘IO、带宽)。压测期间被测服务的各项资源使用正常,排除嫌疑。下图为其中一台服务资源使用情况。

- 检查压测负载机资源使用是否存在瓶颈。压测期间各负载机CPU及内存、磁盘使用均正常,排除嫌疑。
- 检查压测负载机与被测服务间网络带宽。负载机网络带宽100MB,压测期间各负载机带宽仅使用30MB左右,排除嫌疑。
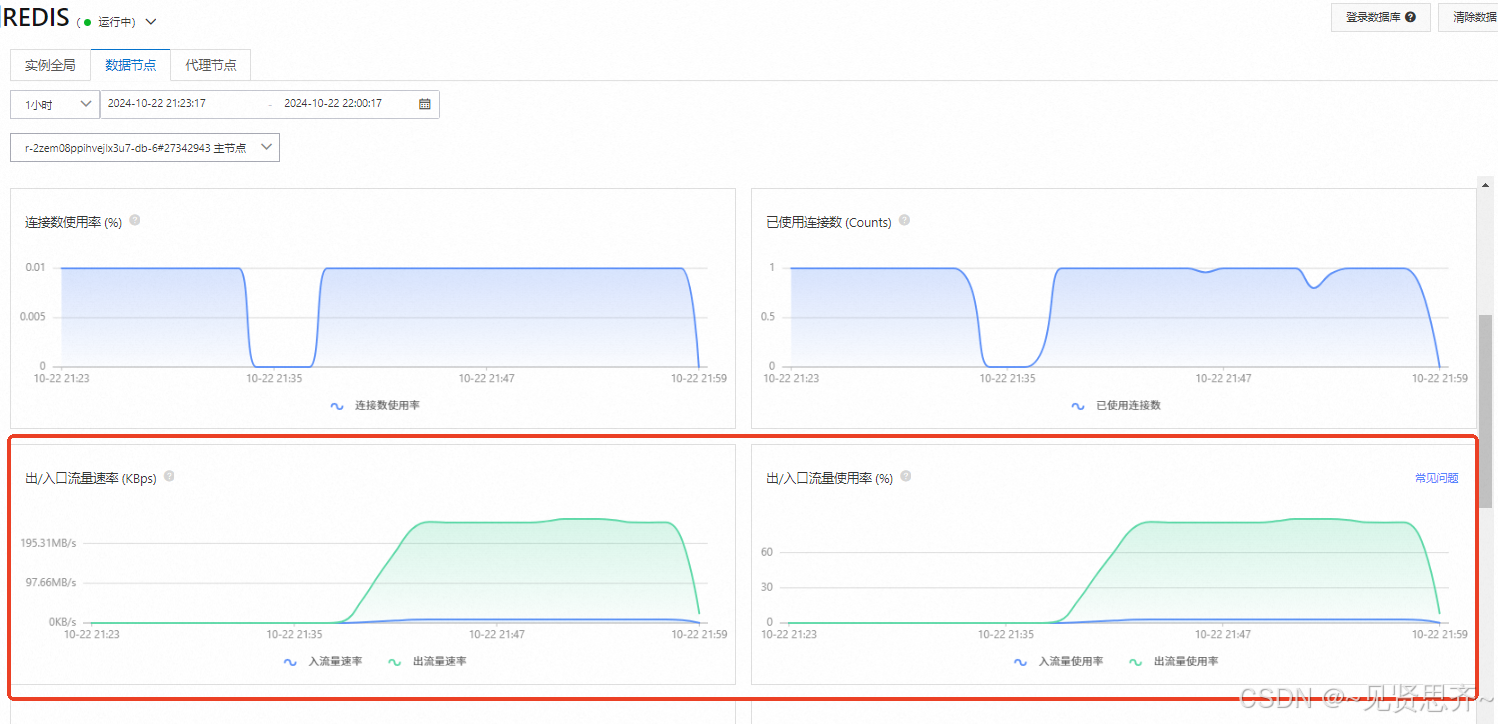
- 检查被测服务使用的中间件(redis、kafka)资源使用情况。下图为redis集群资源使用情况,看起来也没问题。


于是进行下一步的排查:
1、查看接口耗时的各分段耗时。在程序中增加打印断点耗时日志(阶段处理逻辑超过100或200毫秒时会进行打印、仅开启服务集群中的一台断点日志打印即可)
通过断点日志打印,发现耗时超过200ms的为redis查询key的操作。
2、检查redis集群是否存在慢日志。发现redis存在大量的慢日志,redis请求一次耗时500000us(500ms)以上。终于找到元凶了。

接下来针对redis进行仔细的检查(检查下各redis分片使用是否正常、redis中影响性能的配置文件参数)。
经排查,发现redis集群(共8个分片)的其中一个分片带宽比其他7个分片,出网带宽要高90MB。分片带宽使用率100%以上。终于找到原因了。如下图对比:


接着看下redis分片设置的默认带宽值,发现单分片默认带宽值为96MB。如下图。

解决措施:1)redis分片带宽设置为自动弹性带宽。

redis分片带宽调整后,回归压测,确认服务吞吐量上来了(QPS 29000,预期QPS 20000,已满足预期),接口耗时在100ms内,各redis分片带宽使用均匀、各服务资源使用正常。至此优化结束。

 (三组负载机中的其中一组压测结果)
(三组负载机中的其中一组压测结果)