对 RAG 应用程序进行原型设计很容易,但要使其高性能、健壮且可扩展到大型知识语料库却很困难。
本指南包含各种提示和技巧,以提高 RAG 工作流程的性能。我们首先概述一些通用技术 - 它们按照简单到复杂的顺序进行排列。然后,我们将更深入地研究每种技术、该技术解决的用例,以及如何使用 LlamaIndex 实现它!
RAG 系统的终极目标是:优化系统的检索和生成性能,让 LLMs 能够准确回答来自更复杂的数据集的更多 query,而不会产生幻觉。
构建生产级 RAG 系统的通用技术总结
以下是构建生产级 RAG 的一些主要注意事项:
1️⃣ 用于检索的文本块不一定要与用于LLM生成的文本块相同:
在信息检索阶段,通常将文档分割成较小的文本块,以提高检索的准确性和效率。然而,在让 LLM 生成回答时,可能需要更大的文本块来提供充分的上下文信息。因此,针对检索和生成过程,应采用不同的文本分块策略,以优化各自的效果。
2️⃣ 嵌入应存在于不同的潜在空间中,而不是直接使用原始文本的嵌入:
原始文本可能包含无关的填充词或噪音,直接对其进行 embedding 可能会引入偏差。为了获得更准确的文本表示,可以考虑对文本进行预处理,如去除停用词、提取关键信息,或者对 embedding 模型进行微调,以生成更有意义的 embedding 向量。
3️⃣ 如果检索未能返回正确的上下文,可能需要动态加载或更新数据本身:
当检索结果不理想时,问题可能出在数据源本身过时或不完整。此时,动态地加载新数据或更新现有数据可以改善检索效果,确保LLM使用最新且相关的信息来生成回答。
4️⃣ 设计具有可扩展性的处理流程:
原型阶段的系统延迟可能较高,这在生产环境中是不可接受的。应从易于使用但延迟较高的模块开始,逐步优化各个组件以降低延迟,提升系统的性能和可扩展性,满足生产级应用的需求。
5️⃣ 以层次化的方式存储数据:
为每个文档存储摘要和具体的文本块,可以构建一个层次化的数据结构。这种方法允许在需要快速概览时获取摘要信息,而在需要深入细节时访问具体的文本块,提高了数据检索和处理的效率。
6️⃣ 在生产环境中,健壮的数据管道尤为重要,尤其是当源数据不断变化时:
如果数据仅需加载一次,数据管道的稳定性影响较小。然而,当源数据频繁更新时,必须确保数据管道的可靠性和稳定性,以防止数据不一致或系统故障。
7️⃣ RAG不仅适用于问答,还可用于摘要等其他任务;应根据用例调整文本块大小:
在生成摘要时,可能需要处理所有相关的文本块以涵盖完整的信息;而在问答场景中,只需检索特定的文本块即可。因此,应根据具体的应用场景和需求,调整文本块的大小和分割方式。
8️⃣ 基于嵌入的检索对实体查找效果不佳;混合搜索可结合关键词查找的优势和额外的上下文:
对于查找特定实体(如人名、地名)等精确匹配的需求,纯粹依赖嵌入可能无法获得最佳结果。混合搜索方法将关键词匹配与嵌入检索相结合,既利用了精确匹配的优势,又提供了上下文信息,从而提高了检索效果。
将用于检索的 chunk 与用于 synthesis 的 chunk 分离
更好地检索的关键技术是将用于检索的 chunk 与用于 synthesis 的 chunk 分离。
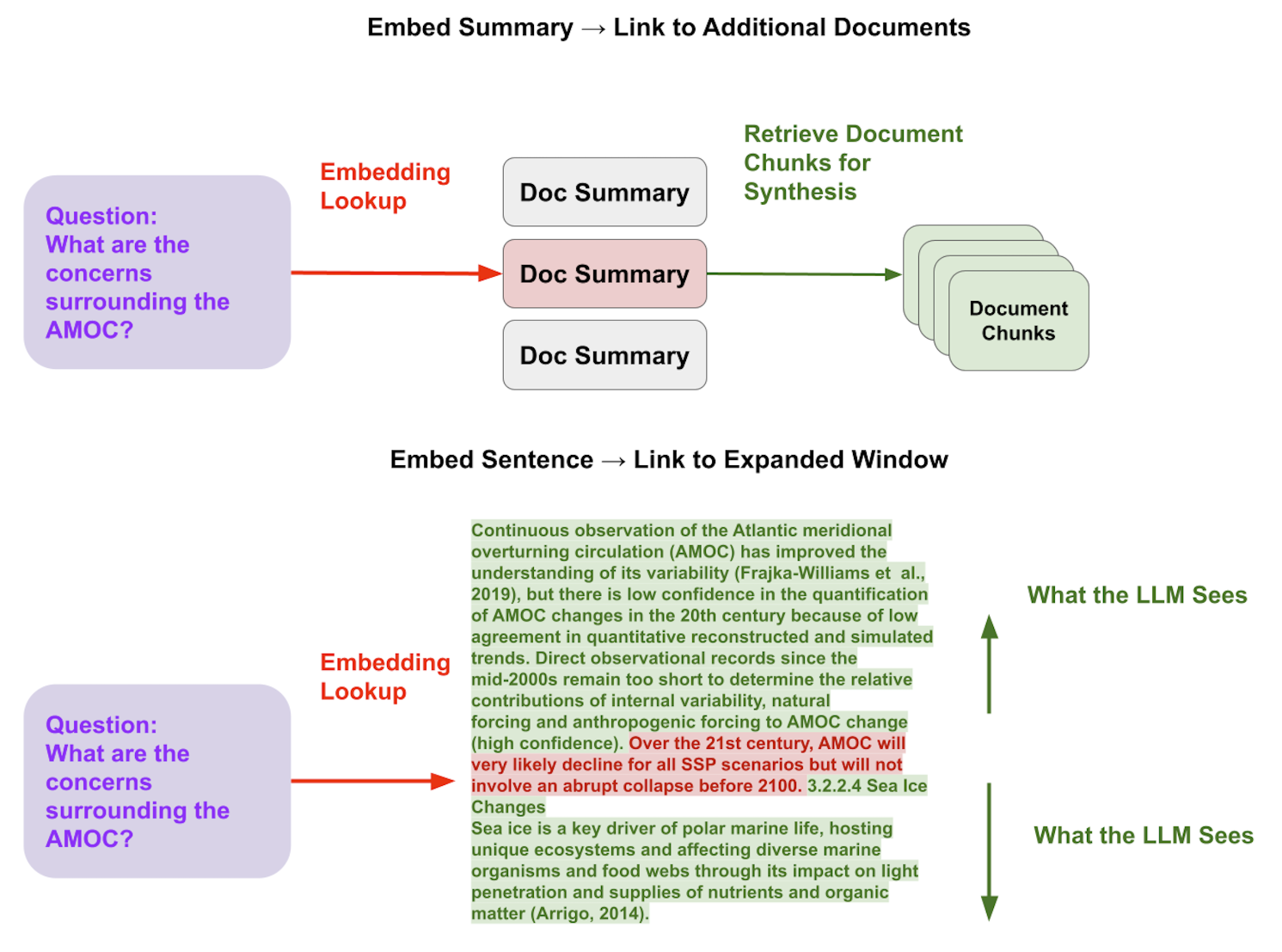
检索到的质量最好的 chunk 可能与最适合用于 synthesis 的 chunk 不同。例如,原始文本块可能包含 LLM 给定查询的更详细答案所需的详细信息。但是,它可能包含冗余的词或信息,这可能会使 embedding 表示产生偏差,或者它可能缺少全局上下文,并且在相关查询出现时根本无法检索。
解决方案:
1. 嵌入文档摘要,该摘要链接到与文档关联的数据块。
这有助于在检索 chunk 之前整合更多相关的文档,而不是直接检索 chunks(可能在不相关的文档中)。
相关资源:Table Recursive Retrieval、Document Summary Index
2. 嵌入一个句子,然后扩展到句子周围的内容。
这允许更细粒度地检索相关上下文(embedding 巨大的 chunk 会导致 LLM"迷失在长文本中"),但也确保了 LLM 能看到足够长的上下文。
相关资源:Metadata Replacement Postprocessor
大型文档集的结构化检索
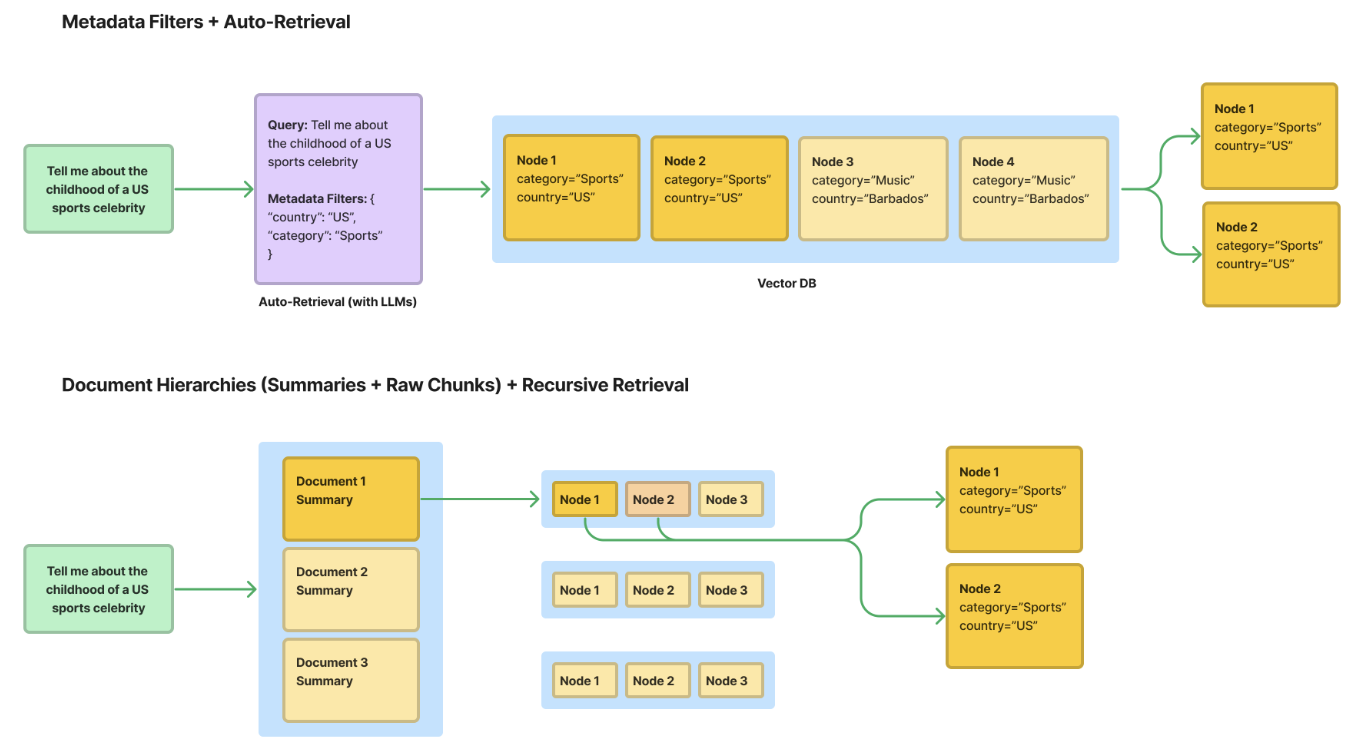
标准 RAG 流程(top-k 检索 + 基础的文本拆分)的一个大问题是,随着文档数量的增加,它表现不佳 - 如果您有 100 个不同的 PDF。在这种情况下中,给定一个 query,你可能希望使用结构化信息来帮助进行更精确的检索;例如,如果您提出一个仅与两个 PDF 相关的问题,请使用结构化信息来确保返回的内容来自这两个 PDF。
解决方案:
有几种方法可以为生产质量的 RAG 系统执行更结构化的标记和检索,每种方法都有自己的优点/缺点。
**1. 元数据过滤器 + 自动检索:**用元数据标记每个文档,然后存储在向量数据库中。在推理期间,使用 LLM 筛选符合条件的元数据,然后再查询向量数据库。
✅ 优点 : 主流向量数据库支持。可以通过多个维度过滤文档。
🚫 缺点 : 可能很难定义正确的标签。标签可能不包含足够的相关信息,无法进行更精确的检索。此外,使用标签进行搜索主要基于关键词匹配,无法理解词语的深层含义或上下文关系,因此无法进行语义层面的查找。
2. 存储文档的层级结构(摘要 -> 原始文本块)+ 递归检索: 首先嵌入文档摘要,并为每个文档建立一个摘要与分块的映射。在检索时,先在文档级别找到相关内容,然后再深入到更细的文本块层次。
✅ 优点 :支持文档级别的语义查找,通过摘要嵌入,系统可以进行语义匹配,而不仅仅依赖于关键词,从而获得更有深度和关联的搜索结果。
🚫 缺点 : 无法通过结构化标签进行关键词查找 (关键词匹配有时能更精准地找到特定信息,而语义查找较为泛化,可能无法替代关键词的精确性);自动生成摘要的成本较高(要为大量文档生成和维护准确的摘要非常耗时、昂贵,尤其在处理大型数据集时更为明显)
根据任务动态检索数据块
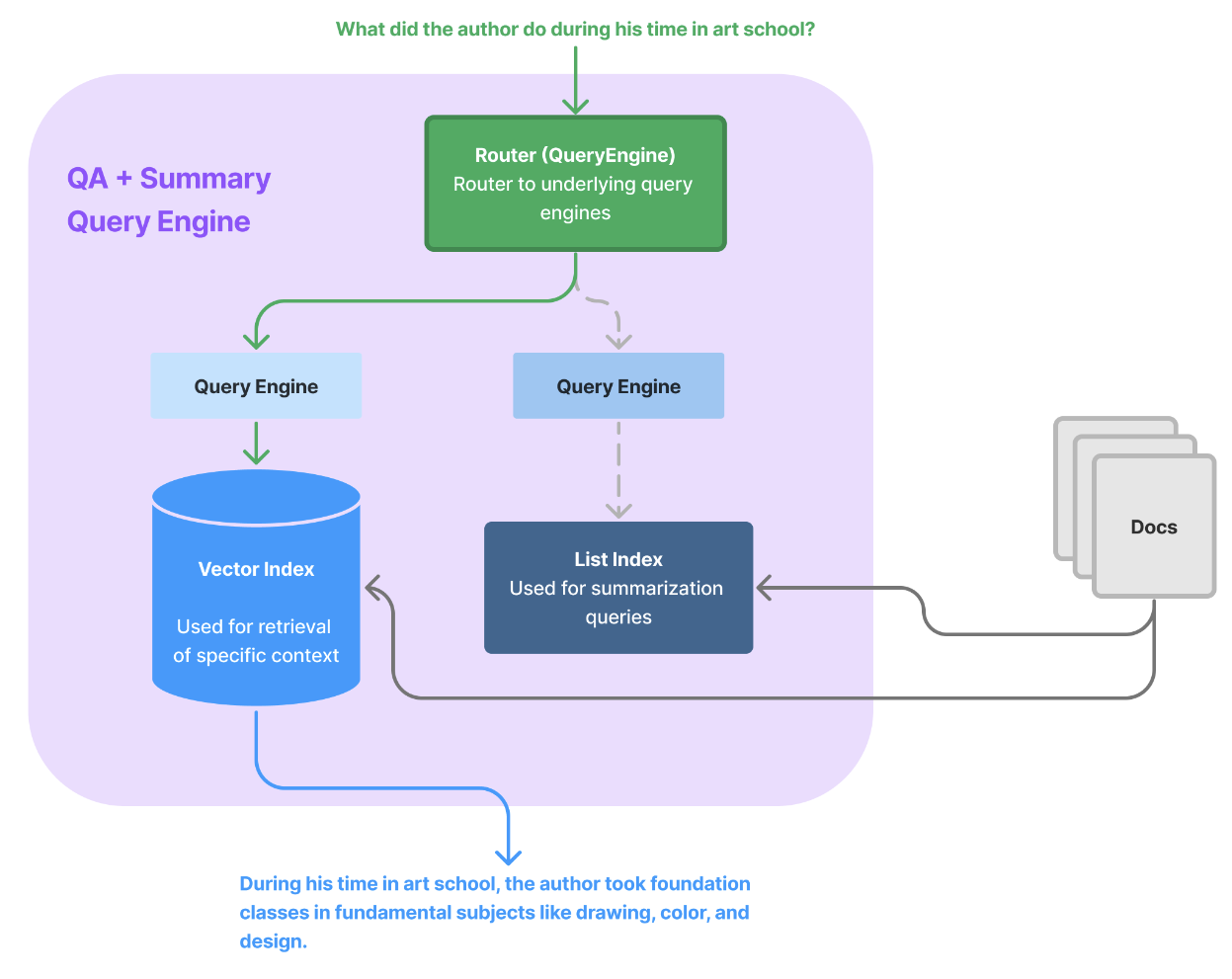
RAG(检索增强生成)不仅适用于回答特定事实问题(通常通过 top-k 相似度检索优化),还广泛涵盖了多种查询需求。用户可能提出各种类型的问题,例如关于具体事实的问答(如"这家公司2023年的多元与包容计划是什么?"或"叙述者在Google的经历是什么?");还可能需要对整个文档进行总结(如"能给我一个这篇文档的高层次概述吗?"),甚至进行比较(如"你能对比X和Y吗?")。这些不同的查询需求表明,RAG应用不仅仅局限于事实问答,而是扩展到了更多的检索和生成任务。构建 RAG 系统时,为适应多样化的需求,可能需要灵活配置不同的检索和生成方法,以确保在各种场景下都能提供最佳的回答。
解决方案:
LlamaIndex 提供了一些抽象的 core 来帮助完成基于特定任务的检索,包括 router 模块以及 data agent 模块。这还包括一些高级查询引擎模块。这还包括链接结构化和非结构化数据的其他模块。你可以使用这些模块进行联合问答和总结,甚至可以将结构化查询与非结构化查询相结合。
Core Module Resources
Detailed Guide Resources
- Sub-Question Query Engine
- Joint QA-Summary
- Recursive Retriever Agents
- Router Query Engine
- OpenAI Agent Cookbook
- OpenAIAgent Query Planning
优化上下文嵌入
这与上面"Decoupling chunks used for retrieval vs. synthesis" 中描述的动机有关。我们希望确保 embedding 的内容经过优化,以便更好地检索到正确数据语料。基于通用场景预训练的模型可能无法捕获实际应用案例中数据的显著特征。
解决方案:
除了上面列出的一些技术之外,我们还可以尝试微调 embedding 模型。我们可以使用无标签的非结构化文本语料进行微调。
在此处查看相关指南:Embedding Fine-tuning Guide
参考内容:
Building Performant RAG Applications for Production - LlamaIndex