毕设是做爬虫相关的,本来想的是用java写,也写了几个爬虫,其中一个是爬网易云音乐的用户信息,爬了大概100多万,效果不是太满意。之前听说Python这方面比较强,就想用Python试试,之前也没用过Python。所以,边爬边学,边学边爬。废话不多说,进入正题。
1.首先是获取目标页面,这个对用python来说,很简单
#encoding=utf8
import urllib
res \= urllib.urlopen("http://www.baidu.com")
print res.read()运行结果和打开百度页面,查看源代码一样。这里针对python的语法有几点说明。
a).import 就是引入的意思,java也用import,C/C++用的是include,作用一样
b).urllib 这个是python自带的模块,在以后开发的时候,如果遇到自己需要的功能,python自带的模块中没有的时候,可以试着去网上找一找,比如需要操作MySql数据 库,这个时候python是没有自带的,就可以在网上找到MySQLdb,然后安装引入就行了。
c).res是一个变量,不用像java,C语言那样声明。用的时候直接写就行了
d).标点符号。像java,C这些语言,每行代码后面都要用分号或者别的符号,作为结束标志,python不用,用了反了会出错。不过有的时候,会用标点符号,比如冒号, 这个后面再说
e).关于print,在python2.7中,有print()函数,也有print 语句,作用基本差不多。
f).#注释
g).encoding=utf8代表使用utf8编码,这个在代码中有中文的时候特别有用
2.解析获取的网页中的元素,取得自己想要的,以豆瓣为例,我们想获取这个页面中的所有书籍名称(仅供学习交流)
http://www.douban.com/tag/小说/?focus=book
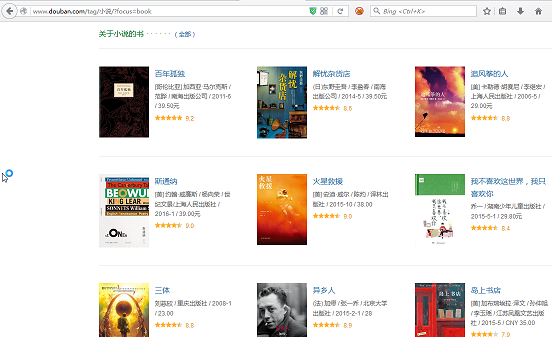
首先获取页面代码:
#encoding=utf8
import urllib
res \= urllib.urlopen("http://www.douban.com/tag/%E5%B0%8F%E8%AF%B4/?focus=book")
print res.read()获取结果,通过分析页面源代码(建议用firefox浏览器,按F12,可看到源代码),可以定位到有效代码如下:
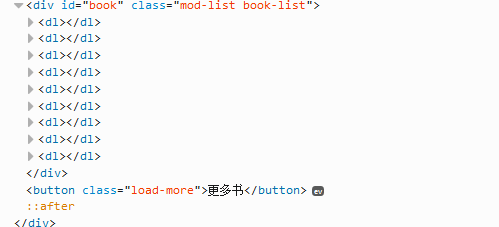
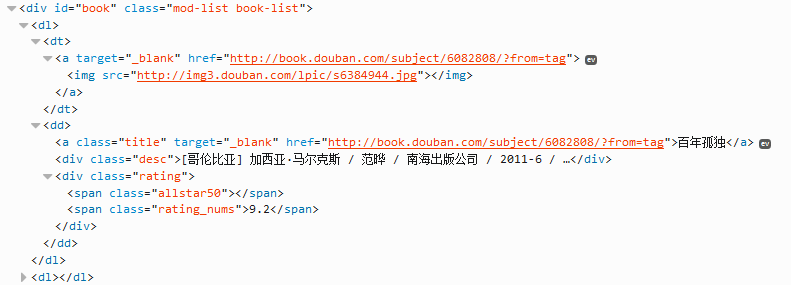
下面我们开始解析(这里用BeautifulSoup,自行下载安装),基本流程:
a).缩小范围,这里我们通过id="book"获取所有的书
b).然后通过class="title",遍历所有的书名。
代码如下:
#encoding=utf8
import urllib
import BeautifulSoup
res \= urllib.urlopen("http://www.douban.com/tag/%E5%B0%8F%E8%AF%B4/?focus=book")
soup \= BeautifulSoup.BeautifulSoup(res)
book\_div \= soup.find(attrs={"id":"book"})
book\_a \= book\_div.findAll(attrs={"class":"title"})
for book in book\_a:
print book.string代码说明:
a).book_div 通过id=book获取div标签
b).book_a 通过class="title"获取所有的book a标签
c).for循环 是遍历book_a所有的a标签
d).book.string 是输出a标签中的内容
结果如下:

3.存储获取的数据,比如写入数据库,我的数据库用的Mysql,这里就以Mysql为例(下载安装MySQLdb模块这里不做叙述),只写怎么执行一条sql语句
代码如下:
connection = MySQLdb.connect(host="\*\*\*",user="\*\*\*",passwd="\*\*\*",db="\*\*\*",port=3306,charset="utf8")
cursor \= connection.cursor()
sql \= "\*\*\*\*\*\*\*"
sql\_res \= cursor.execute(sql)
connection.commit()
cursor.close()
connection.close()说明:
a).这段代码是执行sql语句的流程,针对不同的sql语句,会有不同的处理。比如,执行select的语句,我怎么获取执行的结果,执行update语句,怎么之后成没成功。这 些就要自己动手了
b).创建数据库的时候一定要注意编码,建议使用utf8
4.至此,一个简单的爬虫就完成了。之后是针对反爬虫的一些策略,比如,用代理突破ip访问量限制
如果你是准备学习Python或者正在学习(想通过Python兼职),下面这些你应该能用得上:
包括:Python安装包、Python web开发,Python爬虫,Python数据分析,人工智能、自动化办公等学习教程。带你从零基础系统性的学好Python!
