
目录
[1.1 安装Kerberos客户端](#1.1 安装Kerberos客户端)
[1.2 环境配置](#1.2 环境配置)
一、安装配置Kerberos客户端环境
1.1 安装Kerberos客户端
在Kerberos官网下载,地址如下:https://web.mit.edu/kerberos/dist/index.html

安装过程就是下一步 ,下一步那种。
1.2 环境配置
配置C:\ProgramData\MIT\Kerberos5\krb5.ini文件,将KDC Server服务器上/etc/krb5.conf文件中的部分内容,拷贝到krb5.ini中,如果直接将krb5.conf文件更名为krb5.ini并替换krb5.ini,会出现文件格式问题导致MIT Kerberos客户端无法正常启动。
[libdefaults]
renew_lifetime = 7d
forwardable = true
default_realm = WINNER.COM
ticket_lifetime = 24h
dns_lookup_realm = false
dns_lookup_kdc = false
default_ccache_name = C:\ProgramData\MIT\Kerberos5\krb5.cache
#default_tgs_enctypes = aes des3-cbc-sha1 rc4 des-cbc-md5
#default_tkt_enctypes = aes des3-cbc-sha1 rc4 des-cbc-md5
[logging]
default = FILE:/var/log/krb5kdc.log
admin_server = FILE:/var/log/kadmind.log
kdc = FILE:/var/log/krb5kdc.log
[realms]
WINNER.COM = {
admin_server = hdp-node1
kdc = hdp-node1
}配置环境变量,krb5.ini以及Kerberos Credential Cache File的路径,
- 变量名:KRB5_CONFIG,变量值:C:\ProgramData\MIT\Kerberos5\krb5.ini。
- 变量名:KRB5CCNAME,变量值:C:\ProgramData\MIT\Kerberos5\krb5.cache。
 kinit认证
kinit认证
 DBeaver配置
DBeaver配置
因为DBeaver通过JDBC的方式访问Hive,底层也是基于Java环境,所以这里需要在DBeaver的配置中增加JVM的参数,主要添加关于Kerberos相关的配置。
进入DBeaver的安装目录,找到dbeaver.ini配置文件,在配置文件末尾增加如下配置:
-Djavax.security.auth.useSubjectCredsOnly=false
-Djava.security.krb5.conf=C:\ProgramData\MIT\Kerberos5\krb5.ini
-Dsun.security.krb5.debug=true需要重启DBeaver才可生效。
二、基于Cloudera驱动创建连接
HDP 集群
 下载驱动
下载驱动
Download Hive JDBC Driver 2.6.25 | Cloudera
 下载的HiveJDBC42.jar
下载的HiveJDBC42.jar
 Cloudera官网提供的JDBC驱动包比较简单只有一个jar包,Hive JDBC驱动包及其依赖包均打包在里面。具体访问方式如下:
Cloudera官网提供的JDBC驱动包比较简单只有一个jar包,Hive JDBC驱动包及其依赖包均打包在里面。具体访问方式如下:
 添加jar文件
添加jar文件
 找到类
找到类
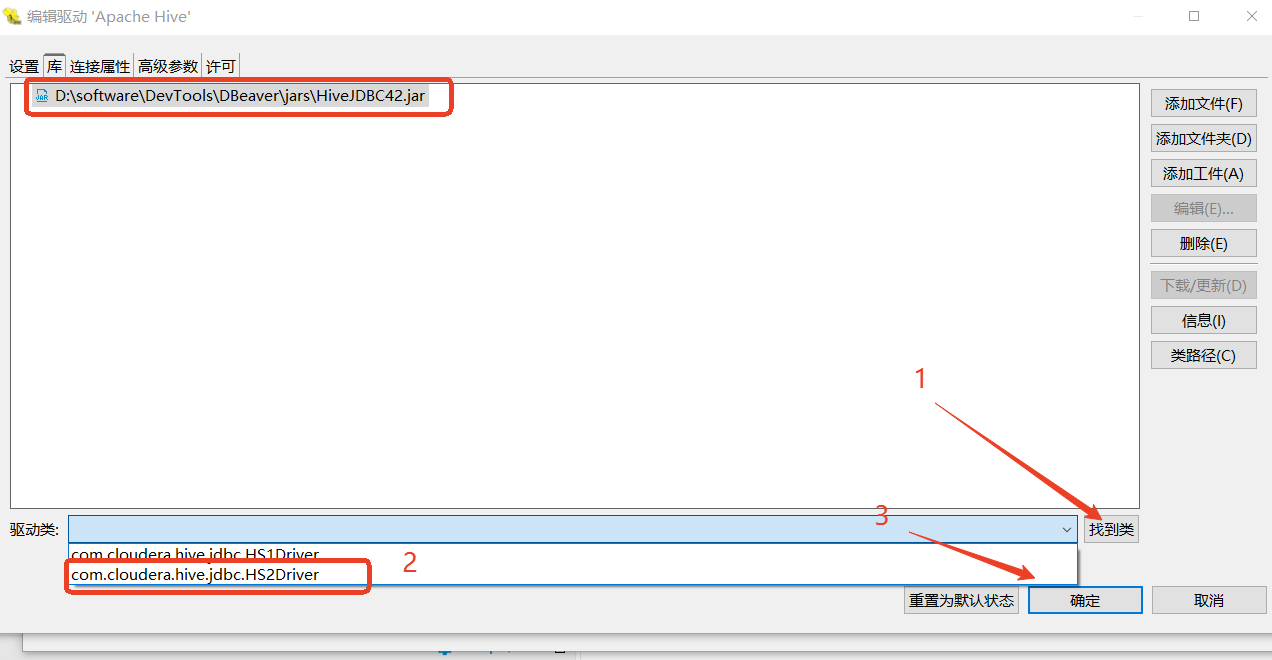
编辑驱动中设置URL和默认端口
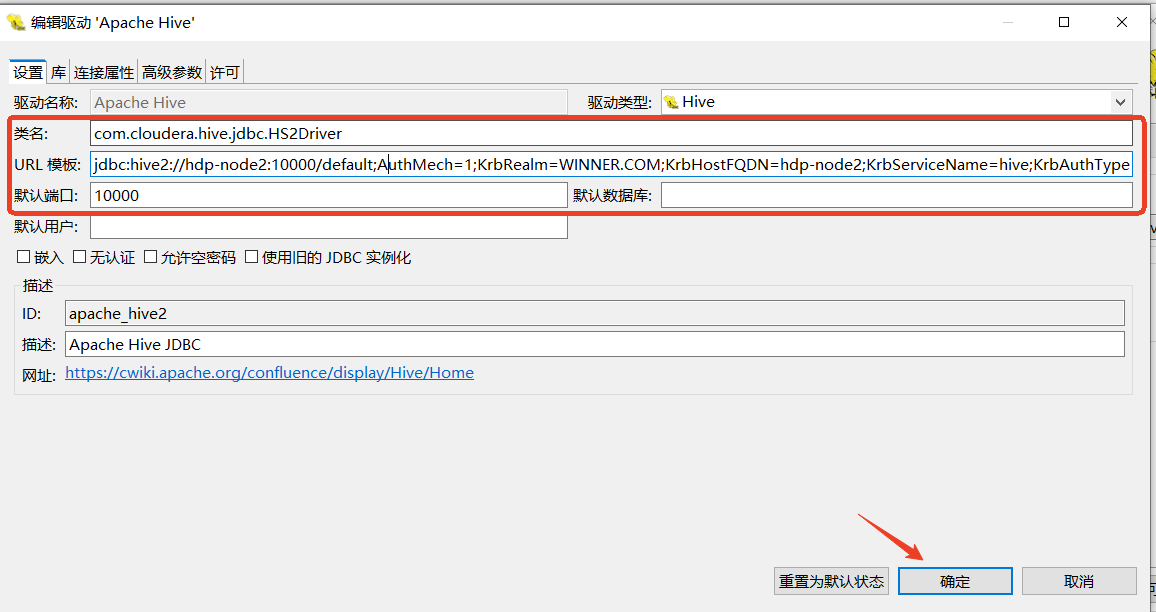
- **类名:**com.cloudera.hive.jdbc.HS2Driver
- **URL:**jdbc:hive2://hdp-node2:10000/default;AuthMech=1;KrbRealm=WINNER.COM;KrbHostFQDN=hdp-node2;KrbServiceName=hive;KrbAuthType=2
-
- AuthMech: 0无认证、1Kerberos认证、2用户名方式、3用户名和密码认证、6使用Hadoop授权认证
- KrbRealm:你的KDC服务定义的域名
- krbHostFQDN:你的HiveServer2服务的FQDN(hostname或你dns解析的域名)
- KrbServiceName:HiveServer2服务的Principal默认为hive
- KrbAuthType:0表示获取你的Subject来实现Kerberos认证、1表示基于JAAS方式获取Kerberos认证、2表示基于当前客户端的Tick Cache方式认证
- **默认端口:**10000
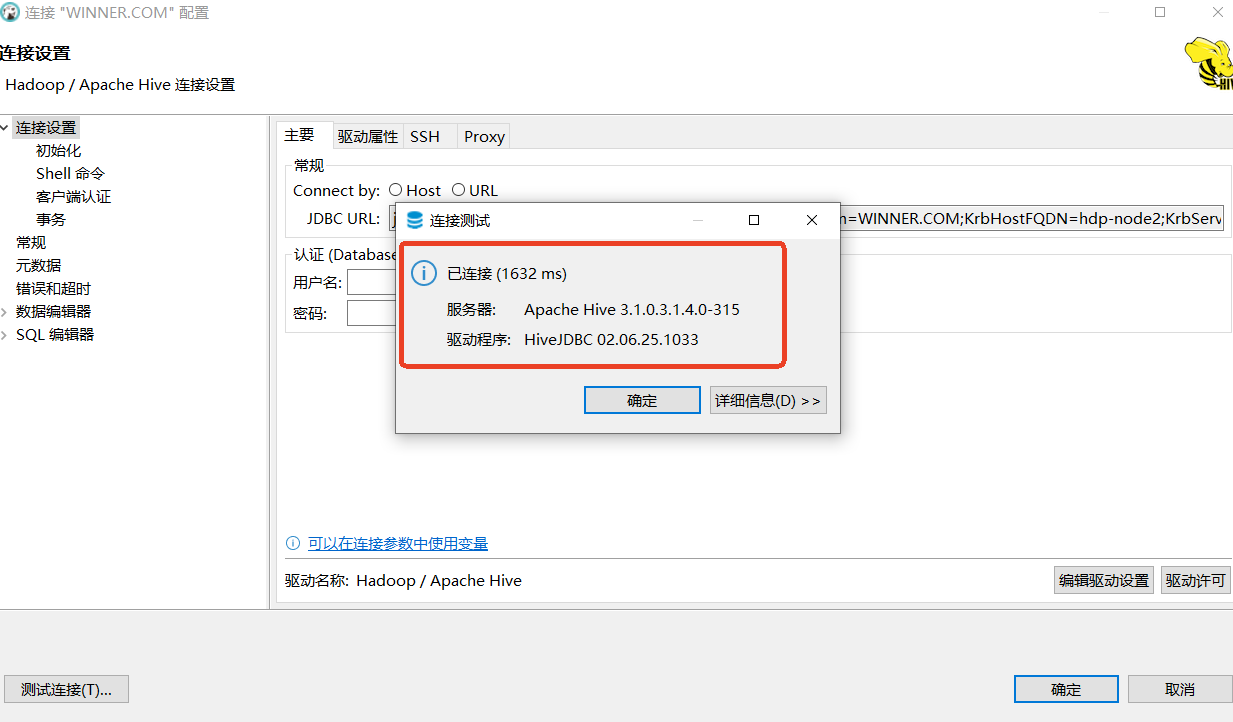
测试连接
 显示已连接,在表示连接成功。
显示已连接,在表示连接成功。
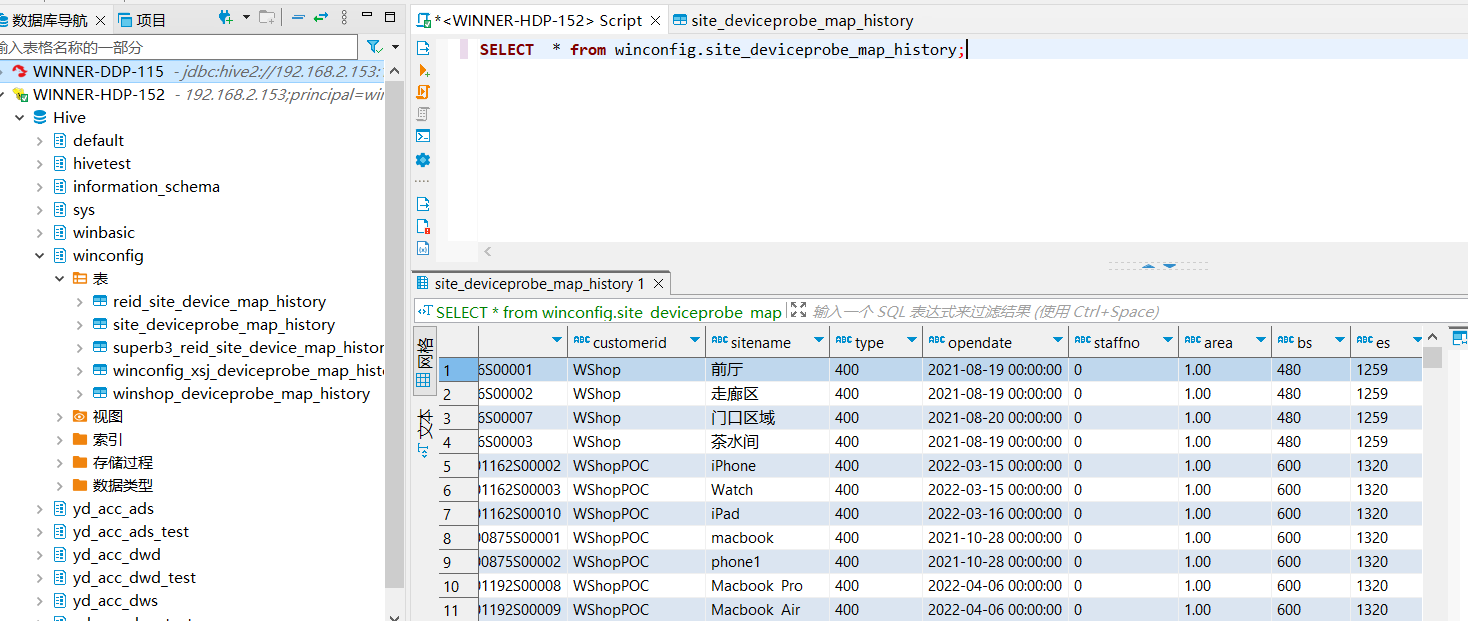
使用SQL编辑器查询
三、基于Hive原生驱动创建连接
基于开源的DDP集群测试,也就是原生的Apache Hive。
 krb5.ini配置文件
krb5.ini配置文件
[libdefaults]
dns_lookup_realm = false
ticket_lifetime = 24h
renew_lifetime = 7d
forwardable = true
rdns = false
default_realm = HADOOP.COM
#default_ccache_name = KEYRING:persistent:%{uid}
[realms]
HADOOP.COM = {
kdc = ddp01
admin_server = ddp01
}
[domain_realm]
# .example.com = HADOOP.COM
# example.com = HADOOP.COM获取hive的keytab文件后认证

DBeaver配置
因为DBeaver通过JDBC的方式访问Hive,底层也是基于Java环境,所以这里需要在DBeaver的配置中增加JVM的参数,主要添加关于Kerberos相关的配置。
进入DBeaver的安装目录,找到dbeaver.ini配置文件,在配置文件末尾增加如下配置,第一行是新增的配置需要添加不然测试连接会报错:
--add-exports=java.security.jgss/sun.security.krb5=ALL-UNNAMED # 新增的
-Djavax.security.auth.useSubjectCredsOnly=false
-Djava.security.krb5.conf=C:\ProgramData\MIT\Kerberos5\krb5.ini
-Dsun.security.krb5.debug=truejdbc依赖下载,并加载驱动类
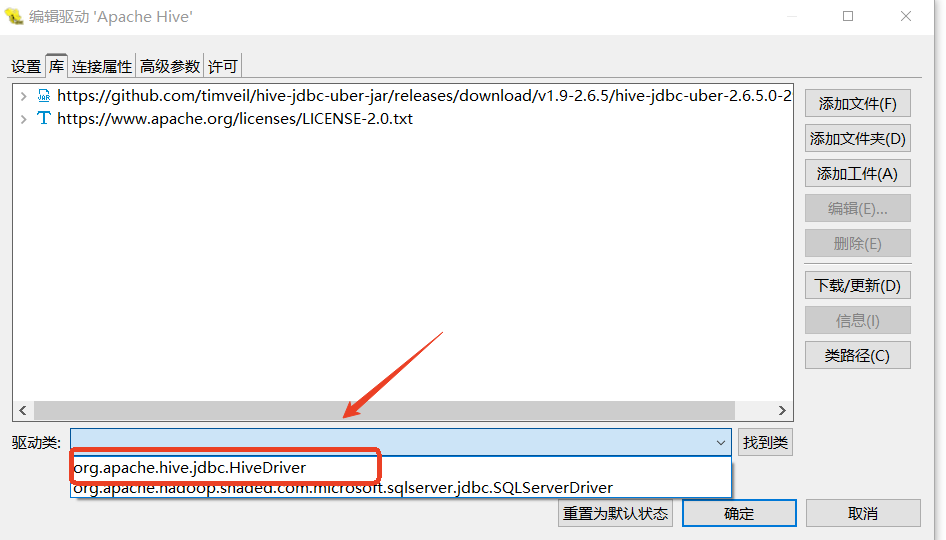
- URL模板:jdbc:hive2://{host}:{port}/{database}/;principal=hive/{host}@HADOOP.COM
- 默认端口:10000
 填上hiveservice2主机名和访问端口
填上hiveservice2主机名和访问端口
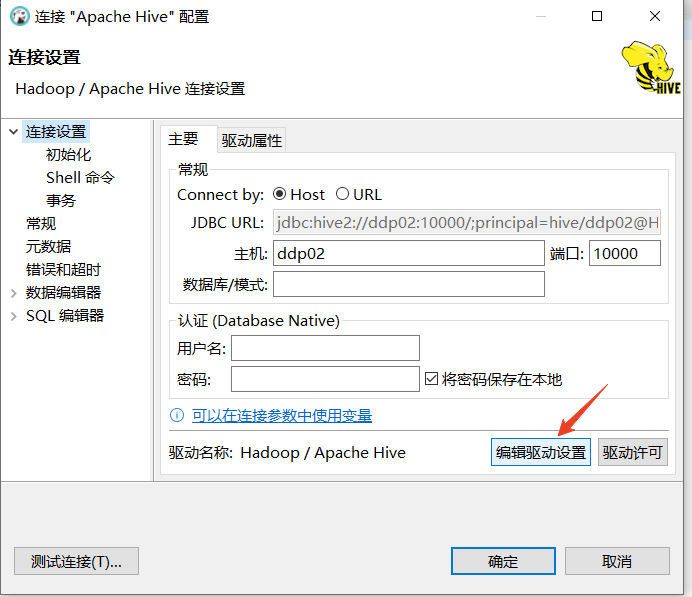
测试连接成功
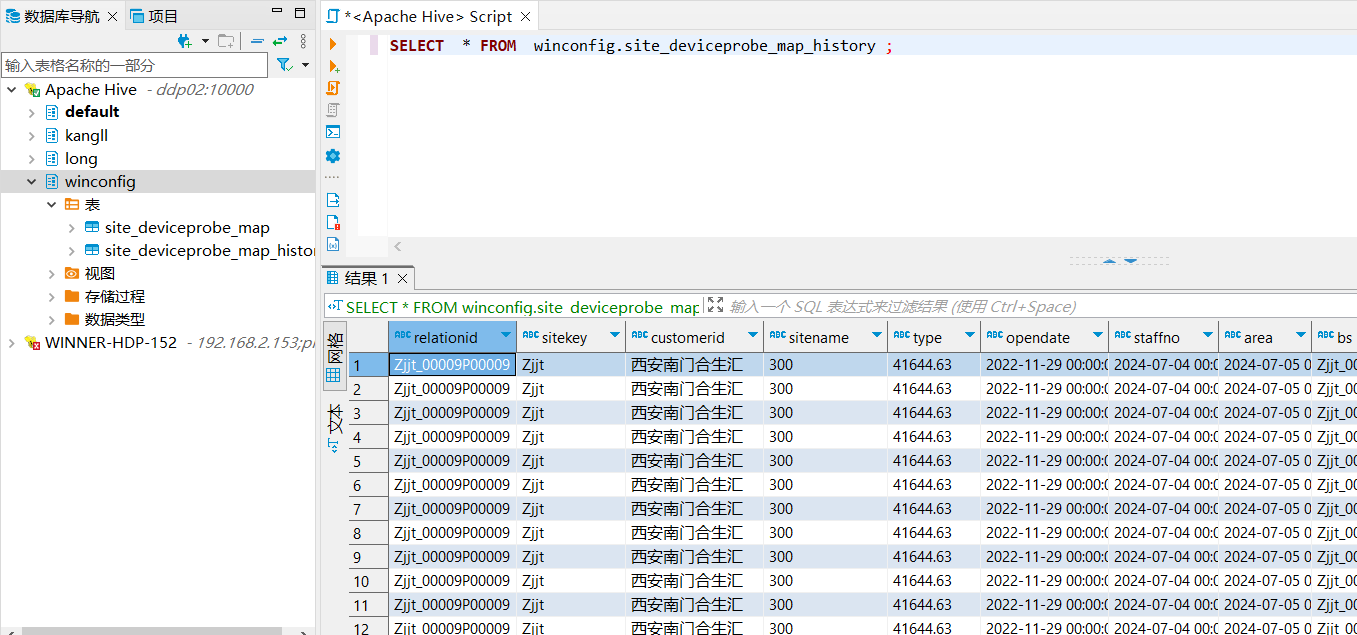
 数据查询
数据查询
参考文档:0468-如何使用DBeaver访问Kerberos环境下的Hive-腾讯云开发者社区-腾讯云
kerberos方式连接hive hive配置kerberos_mob6454cc6c8549的技术博客_51CTO博客