鸿蒙生命周期
1.UIAbility组件生命周期
包含四个,分别为Create、Foreground、Background、Destroy四个状态
其中onCreate创建完成后,会进入onWindowStageCreate()回调,可以在onWindowStageCreate()回调中通过loadContent()方法设置应用要加载的页面并根据需要订阅WindowStage的事件(获焦,失焦,可见,不可见)
在UIAbility实例销毁之前会进入onWindowStageDestroy()回调,可以释放UI界面资源。

2.页面和自定义组件生命周期
2.1页面生命周期
页面:即应用的UI页面。可以由一个或者多个自定义组件组成,@Entry装饰的自定义组件为页面的入口组件,即页面的根节点,一个页面有且仅能有一个@Entry。只有被@Entry装饰的组件才可以调用页面的生命周期。
页面生命周期,即被@Entry装饰的组件生命周期,提供以下生命周期接口:
- onPageShow:页面每次显示时触发一次,包括路由过程、应用进入前台等场景。
- onPageHide:页面每次隐藏时触发一次,包括路由过程、应用进入后台等场景。
- onBackPress:当用户点击返回按钮时触发。
2.2自定义组件生命周期
即一般用@Component装饰的自定义组件的生命周期,提供以下生命周期接口:
- aboutToAppear:组件即将出现时回调该接口,具体时机为在创建自定义组件的新实例后,在执行其build()函数之前执行。
- aboutToDisappear:在自定义组件析构销毁之前执行。不允许在aboutToDisappear函数中改变状态变量,特别是@Link变量的修改可能会导致应用程序行为不稳定。
生命周期流程如下图所示,下图展示的是被@Entry装饰的组件(页面)生命周期。

3.Navigation路由容器生命周期
Navigation作为路由容器,其生命周期承载在NavDestination组件上,以组件事件的形式开放。
其生命周期大致可分为三类,自定义组件生命周期、通用组件生命周期和自有生命周期(其中aboutToAppear和aboutToDisappear是自定义组件的生命周期。如果NavDestination外层包含自定义组件时则存在;OnAppear和OnDisappear是组件的通用生命周期,剩下的六个生命周期为NavDestination独有)。
生命周期时序如下图所示:

- aboutToAppear:在创建自定义组件后,执行其build()函数之前执行(NavDestination创建之前),允许在该方法中改变状态变量,更改将在后续执行build()函数中生效。
- onWillAppear:NavDestination创建后,挂载到组件树之前执行,在该方法中更改状态变量会在当前帧显示生效。
- onAppear:通用生命周期事件,NavDestination组件挂载到组件树时执行。
- onWillShow:NavDestination组件布局显示之前执行,此时页面不可见(应用切换到前台不会触发)。
- onShown:NavDestination组件布局显示之后执行,此时页面已完成布局。
- onWillHide:NavDestination组件触发隐藏之前执行(应用切换到后台不会触发)。
- onHidden:NavDestination组件触发隐藏后执行(非栈顶页面push进栈,栈顶页面pop出栈或应用切换到后台)。
- onWillDisappear:NavDestination组件即将销毁之前执行,如果有转场动画,会在动画前触发(栈顶页面pop出栈)。
- onDisappear:通用生命周期事件,NavDestination组件从组件树上卸载销毁时执行。
- aboutToDisappear:自定义组件析构销毁之前执行,不允许在该方法中改变状态变量。
其中自定义组件生命周期为aboutToAppear和aboutToDisappear是自定义组件的生命周期。如果NavDestination外层包含自定义组件时则存在;
通用组件生命周期为onAppear和onDisappear;
其余的为自有生命周期。
路由跳转
鸿蒙中跳转主要有两种,一种是router,一种是Navigation
1.router
Router适用于模块间与模块内页面切换,通过每个页面的url实现模块间解耦。模块内页面跳转时,为了实现更好的转场动效场景不建议使用该模块,推荐使用Navigation。
Router模块提供了两种跳转模式,分别是router.pushUrl()和router.replaceUrl()。这两种模式决定了目标页面是否会替换当前页。
同时,Router模块提供了两种实例模式,分别是Standard和Single。这两种模式决定了目标url是否会对应多个实例。
- router.pushUrl():目标页面不会替换当前页,而是压入页面栈。这样可以保留当前页的状态,并且可以通过返回键或者调用router.back()方法返回到当前页。
- router.replaceUrl():目标页面会替换当前页,并销毁当前页。这样可以释放当前页的资源,并且无法返回到当前页。
页面栈的最大容量为32个页面。如果超过这个限制,可以调用router.clear()方法清空历史页面栈,释放内存空间。
同时,Router模块提供了两种实例模式,分别是Standard和Single。这两种模式决定了目标url是否会对应多个实例。
- Standard:多实例模式,也是默认情况下的跳转模式。目标页面会被添加到页面栈顶,无论栈中是否存在相同url的页面。
- Single:单实例模式。如果目标页面的url已经存在于页面栈中,则会将离栈顶最近的同url页面移动到栈顶,该页面成为新建页。如果目标页面的url在页面栈中不存在同url页面,则按照默认的多实例模式进行跳转。
2.Navigation
Navigation是路由容器组件,一般作为首页的根容器,包括单栏(Stack)、分栏(Split)和自适应(Auto)三种显示模式。Navigation组件适用于模块内和跨模块的路由切换,一次开发,多端部署场景。通过组件级路由能力实现更加自然流畅的转场体验,并提供多种标题栏样式来呈现更好的标题和内容联动效果。在不同尺寸的设备上,Navigation组件能够自适应显示大小,自动切换分栏展示效果。
Navigation组件主要包含导航页(NavBar)和子页(NavDestination)。导航页由标题栏(Titlebar,包含菜单栏menu)、内容区(Navigation子组件)和工具栏(Toolbar)组成,其中导航页可以通过hideNavBar属性进行隐藏,导航页不存在页面栈中,导航页和子页,以及子页之间可以通过路由操作进行切换。
在API Version 9上,需要配合NavRouter组件实现页面路由,从API Version 10开始,推荐使用NavPathStack实现页面路由。
Navigation组件通过mode属性设置页面的显示模式。
- 自适应模式
Navigation组件默认为自适应模式,此时mode属性为NavigationMode.Auto。自适应模式下,当页面宽度大于等于一定阈值( API version 9及以前:520vp,API version 10及以后:600vp )时,Navigation组件采用分栏模式,反之采用单栏模式。
- 单页面模式
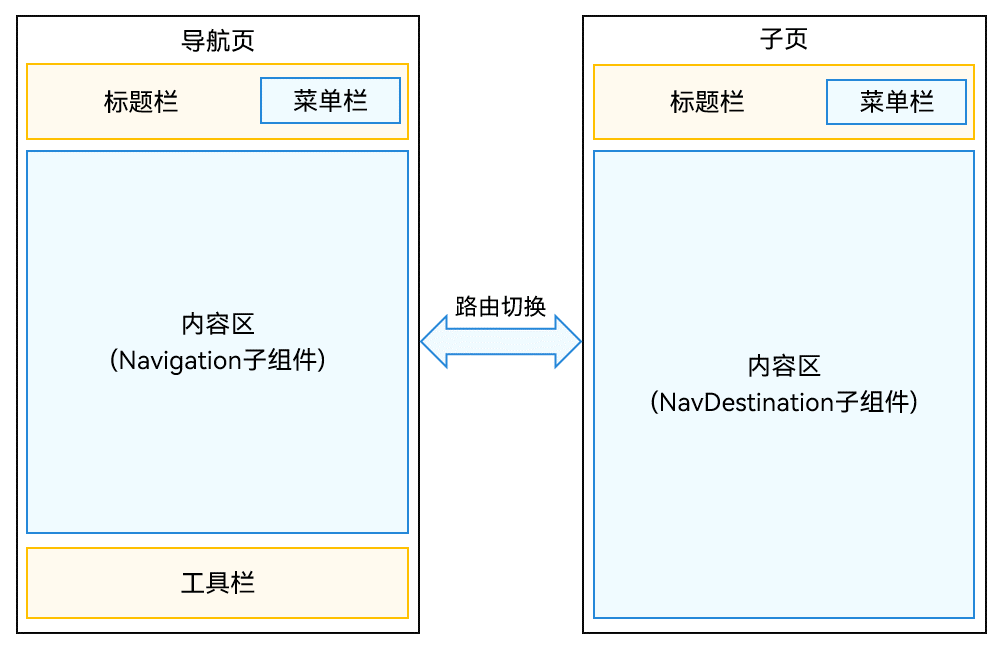
将mode属性设置为NavigationMode.Stack,Navigation组件即可设置为单页面显示模式。
- 分栏模式
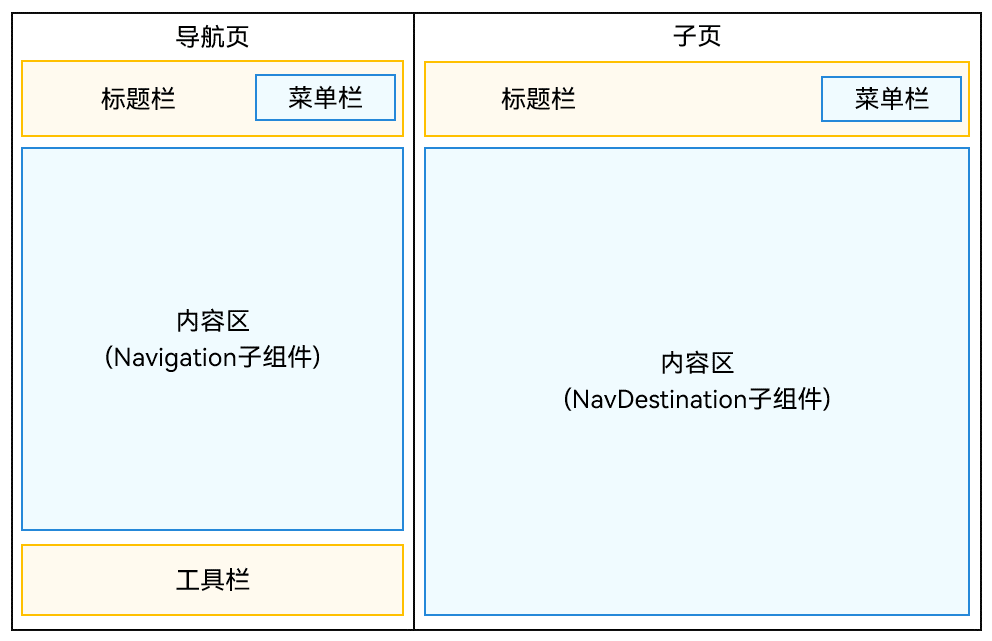
将mode属性设置为NavigationMode.Split,Navigation组件即可设置为分栏显示模式。
3.Navigation与Router对比
当前HarmonyOS支持两套路由机制(Navigation和Router),Navigation作为后续长期演进及推荐的路由选择方案,其与Router比较的优势如下:
- 易用性层面:
- Navigation天然具备标题、内容、回退按钮的功能联动,开发者可以直接使用此能力。Router若要实现此能力,需要自行定义;
- Navigation的页面是由组件构成,易于实现共享元素的转场。
- 功能层面:
- Navigation天然支持一多,Router不支持;
- Navigation没有路由数量限制,Router限制32个;
- Navigation可以获取到路由栈NavPathStack,并对路由栈进行操作;
- Navigation可以嵌套在模态对话框中,也就是说可以模态框中定义路由,Router不支持;
- Navigation的组件全量由开发者自行控制,开发者可以自定义复杂的动效和属性的设置(背景、模糊等),Router的page对象不对外暴露,开发者无法对page进行处理。
- 性能层面
- Navigation传递参数性能更优,Navigation通过引用传递,Router通过深拷贝完成;
- Navigation可以配合动态加载,实现组件动态加载,Router页面使用@Entry进行修饰,当前模块加载时会生成全量页面。
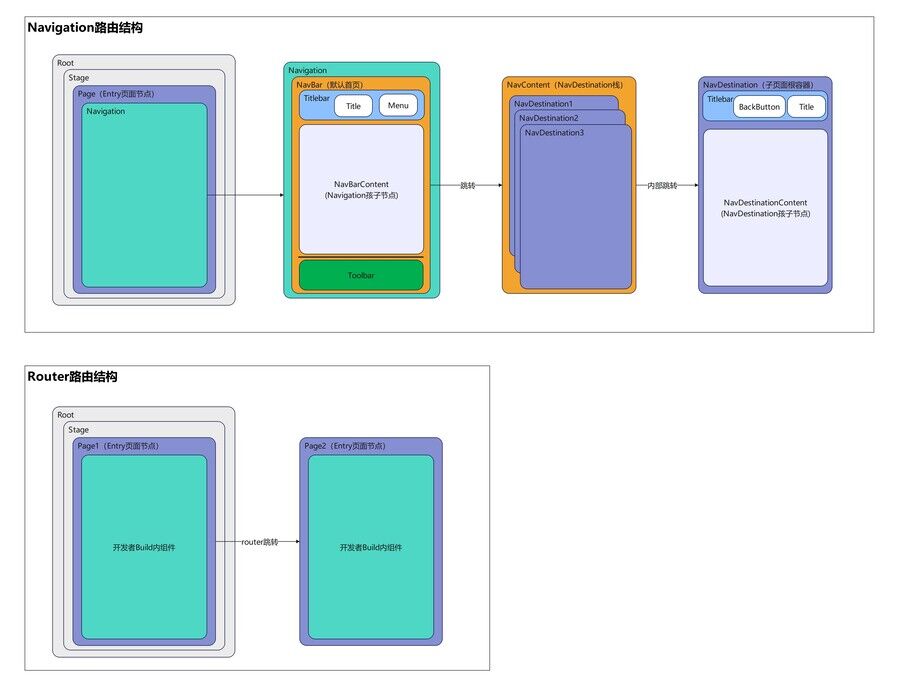
avigation & Router结构对比
- Navigation中的每个页面,承载在一个page里,通过NavDestination容器实现基于组件的页面跳转。
- Router的每一个页面配置在一个单独的page中,通过@Entry进行标识。
使用选择
如果项目只有一个主项目,没有拆分模块,直接用Navigation即可。
如果项目包含模块,比如项目有主项目,A、B模块,主项目的H界面要跳转到A模块的I界面,或者A模块的I界面要跳转到B模块的J界面,这个时候就要用router。但是主项目里的M界面跳转主项目里的N界面,或者A模块的O界面跳转A模块的P界面,这种属于同模块内的不同界面,可以用Navgation。
总结:同模块用Navgation,不同模块用router
常用装饰器
@Entry
表示页面的入口,装饰struct
@Component
装饰struct,表示具有基于组件的能力,保证内部包含一个且只能包含一个build()函数,用于绘制UI界面
@State
来装饰变量的装饰器( 其实就是用于定义变量 ),必须本地初始化数据, 支持通过构造函数赋值,当State值修改,所在build方法会被重新调用
@Prop
继承@State的功能,定义时不需要本地直接初始化,调用子组件时需要对其进行赋值,被修饰的变量建立和父组件单向同步关系,@Prop可变但不会传回父组件,父组件变化@Prop被覆盖
@Link
@Link 装饰的变量和父组件会构建双向同步关系,子组件使用 @Link 定义变量的时候不需要赋值, 而是调用子组件的时候进行赋值,调用子组件赋值的时候使用 "$变量名" 的形式进行赋值,@Link 装饰器不能再 @Entry 装饰的自定义组件中使用。
@Provide 和 @Consume
如果层级过高的话, 在父子组件之间进行数据传递的话, @State/@Link使用起来就比较麻烦,我们可以使用 @Provide 和 @Consume 进行跨组件数据传递。
使用发布订阅模式, 父类使用 @Provide, 其他需要观察的子类使用 @Consume, 就可以实现双向绑定
当层级很深时, 不需要一层一层传递数据, 直接使用发布订阅进行监听就能实现相同的效果
@Provide 和 @Consume 可以通过相同的变量名或者相同的变量别名绑定, 但是变量类型必须相同
@Provide 必须设置初始值, @Consume 不可以设置默认初始值
@Provide 修饰的变量和 @Consume 修饰的变量可以是一对多的关系
@Watch
观察者装饰器,当监控的变量发生变化,函数触发
@Builder
@Builder 是 ArkUI 提供的一种更加轻量的复用机制
因为在 @Component 内能且只能创建一个 build() 函数
我们可以在组件内利用 @Builder 装饰器自定义一个构建函数
@Builder 创建的构建函数遵循 build() 函数的语法规则, 并且可以在 build() 函数内调用
@Styles
样式的复用
持久化存储
应用数据持久化,是指应用将内存中的数据通过文件或数据库的形式保存到设备上。内存中的数据形态通常是任意的数据结构或数据对象,存储介质上的数据形态可能是文本、数据库、二进制文件等。
HarmonyOS标准系统支持典型的存储数据形态,包括用户首选项、键值型数据库、关系型数据库。
-
用户首选项(Preferences):通常用于保存应用的配置信息。数据通过文本的形式保存在设备中,应用使用过程中会将文本中的数据全量加载到内存中,所以访问速度快、效率高,但不适合需要存储大量数据的场景。
-
键值型数据库(KV-Store):一种非关系型数据库,其数据以"键值"对的形式进行组织、索引和存储,其中"键"作为唯一标识符。适合很少数据关系和业务关系的业务数据存储,同时因其在分布式场景中降低了解决数据库版本兼容问题的复杂度,和数据同步过程中冲突解决的复杂度而被广泛使用。相比于关系型数据库,更容易做到跨设备跨版本兼容。
-
关系型数据库(RelationalStore):一种关系型数据库,以行和列的形式存储数据,广泛用于应用中的关系型数据的处理,包括一系列的增、删、改、查等接口,开发者也可以运行自己定义的SQL语句来满足复杂业务场景的需要。
具体的实现有:
1.用户首选项
用户首选项为应用提供Key-Value键值型的数据存储能力,支持应用持久化轻量级数据,并对其进行增删除改查等。该存储对象中的数据会被缓存在内存中,因此它可以获得更快的存取速度,下面详细介绍下用户首选项的开发过程。
用户首选项的特点是:
1、以Key-Value形式存储数据
Key是不重复的关键字,Value是数据值。
2、非关系型数据库
区别于关系型数据库,它不保证遵循ACID(Atomicity, Consistency, Isolation and Durability)特性,数据之间无关系。
进程中每个文件对应一个Preferences实例,应用获取到实例后,可以从中读取数据,或者将数据存入实例中。通过调用flush方法可以将实例中的数据回写到文件里。
与关系数据库的区别
|-------|--------------------------|---------------------------|
| 分类 | 关系型数据库 | 用户首选项 |
| 数据库类型 | 关系型 | 非关系型 |
| 使用场景 | 提供复杂场景下的本地数据库管理机制 | 对Key-Value结构的数据进行存取和持久化操作 |
| 存储方式 | SQLite数据库 | 文件 |
| 约束与限制 | 1.连接池最大4个 2.同一时间只支持一个写操作 | 1.建议数据不超一万条 2.Key为string型 |
作用:
当用户希望有一个全局唯一存储数据的地方,可以采用用户首选项来进行存储。
应用首选项的持久化文件保存在应用沙箱内部,可以通过context获取其路径。
首选项适用于存储小型配置项数据,例如应用的用户个性化设置(字体大小、是否开启夜间模式等)。
限制约束:
-
首选项无法保证进程并发安全,会有文件损坏和数据丢失的风险,不支持在多进程场景下使用。
-
Key键为string类型,要求非空且长度不超过1024个字节。
-
如果Value值为string类型,请使用UTF-8编码格式,可以为空,不为空时长度不超过16 * 1024 * 1024个字节。
-
内存会随着存储数据量的增大而增大,所以存储的数据量应该是轻量级的,建议存储的数据不超过一万条,否则会在内存方面产生较大的开销。
2.键值型数据库
键值型数据库存储键值对形式的数据,当需要存储的数据没有复杂的关系模型,比如存储商品名称及对应价格、员工工号及今日是否已出勤等,由于数据复杂度低,更容易兼容不同数据库版本和设备类型,因此推荐使用键值型数据库持久化此类数据。
约束限制
-
设备协同数据库,针对每条记录,Key的长度≤896 Byte,Value的长度<4 MB。
-
单版本数据库,针对每条记录,Key的长度≤1 KB,Value的长度<4 MB。
-
每个应用程序最多支持同时打开16个键值型分布式数据库。
-
键值型数据库事件回调方法中不允许进行阻塞操作,例如修改UI组件。
若要使用键值型数据库,首先要获取一个KVManager实例,用于管理数据库对象。
3.关系型数据库
关系型数据库基于SQLite组件,适用于存储包含复杂关系数据的场景,比如一个班级的学生信息,需要包括姓名、学号、各科成绩等,又或者公司的雇员信息,需要包括姓名、工号、职位等,由于数据之间有较强的对应关系,复杂程度比键值型数据更高,此时需要使用关系型数据库来持久化保存数据。
约束限制
-
系统默认日志方式是WAL(Write Ahead Log)模式,系统默认落盘方式是FULL模式。
-
数据库中有4个读连接和1个写连接,线程获取到空闲读连接时,即可进行读取操作。当没有空闲读连接且有空闲写连接时,会将写连接当做读连接来使用。
-
为保证数据的准确性,数据库同一时间只能支持一个写操作。
-
当应用被卸载完成后,设备上的相关数据库文件及临时文件会被自动清除。
-
ArkTS侧支持的基本数据类型:number、string、二进制类型数据、boolean。
-
为保证插入并读取数据成功,建议一条数据不要超过2M。超出该大小,插入成功,读取失败。
使用关系型数据库实现数据持久化,需要获取一个RdbStore,其中包括建库、建表、升降级等操作。
4.状态存储
如果开发者要实现应用级的,或者多个页面的状态数据共享,就需要用到应用级别的状态管理的概念。ArkTS根据不同特性,提供了多种应用状态管理的能力:
-
LocalStorage:页面级UI状态存储,通常用于UIAbility内、页面间的状态共享。
-
AppStorage:特殊的单例LocalStorage对象,由UI框架在应用程序启动时创建,为应用程序UI状态属性提供中央存储。
-
PersistentStorage:持久化存储UI状态,通常和AppStorage配合使用,选择AppStorage存储的数据写入磁盘,以确保这些属性在应用程序重新启动时的值与应用程序关闭时的值相同。
-
Environment:应用程序运行的设备的环境参数,环境参数会同步到AppStorage中,可以和AppStorage搭配使用。
4.1 LocalStorage
LocalStorage是页面级的UI状态存储,通过@Entry装饰器接收的参数可以在页面内共享同一个LocalStorage实例。LocalStorage支持UIAbility实例内多个页面间状态共享。
LocalStorage是ArkTS为构建页面级别状态变量提供存储的内存内的"数据库"。
-
应用程序可以创建多个LocalStorage实例,LocalStorage实例可以在页面内共享,也可以通过GetShared接口,实现跨页面、UIAbility实例内共享。
-
组件树的根节点,即被@Entry装饰的@Component,可以被分配一个LocalStorage实例,此组件的所有子组件实例将自动获得对该LocalStorage实例的访问权限。
-
被@Component装饰的组件最多可以访问一个LocalStorage实例和AppStorage,未被@Entry装饰的组件不可被独立分配LocalStorage实例,只能接受父组件通过@Entry传递来的LocalStorage实例。一个LocalStorage实例在组件树上可以被分配给多个组件。
-
LocalStorage中的所有属性都是可变的。
应用程序决定LocalStorage对象的生命周期。当应用释放最后一个指向LocalStorage的引用时,比如销毁最后一个自定义组件,LocalStorage将被JS Engine垃圾回收。
LocalStorage根据与@Component装饰的组件的同步类型不同,提供了两个装饰器:
-
@LocalStorageProp:@LocalStorageProp装饰的变量与LocalStorage中给定属性建立单向同步关系。
-
@LocalStorageLink:@LocalStorageLink装饰的变量与LocalStorage中给定属性建立双向同步关系。
限制条件
- LocalStorage创建后,命名属性的类型不可更改。后续调用Set时必须使用相同类型的值。
- LocalStorage是页面级存储,getShared接口仅能获取当前Stage通过windowStage.loadContent传入的LocalStorage实例,否则返回undefined。例子可见将LocalStorage实例从UIAbility共享到一个或多个视图。
4.2 AppStorage
AppStorage是应用全局的UI状态存储,是和应用的进程绑定的,由UI框架在应用程序启动时创建,为应用程序UI状态属性提供中央存储。
和AppStorage不同的是,LocalStorage是页面级的,通常应用于页面内的数据共享。而AppStorage是应用级的全局状态共享,还相当于整个应用的"中枢",持久化数据PersistentStorage和环境变量Environment都是通过AppStorage中转,才可以和UI交互。
AppStorage是在应用启动的时候会被创建的单例。它的目的是为了提供应用状态数据的中心存储,这些状态数据在应用级别都是可访问的。AppStorage将在应用运行过程保留其属性。属性通过唯一的键字符串值访问。
AppStorage可以和UI组件同步,且可以在应用业务逻辑中被访问。
AppStorage支持应用的主线程内多个UIAbility实例间的状态共享。
AppStorage中的属性可以被双向同步,数据可以是存在于本地或远程设备上,并具有不同的功能,比如数据持久化(详见PersistentStorage)。这些数据是通过业务逻辑中实现,与UI解耦,如果希望这些数据在UI中使用,需要用到@StorageProp和@StorageLink。
4.3 PersistentStorage
LocalStorage和AppStorage都是运行时的内存,但是在应用退出再次启动后,依然能保存选定的结果,是应用开发中十分常见的现象,这就需要用到PersistentStorage。
PersistentStorage是应用程序中的可选单例对象。此对象的作用是持久化存储选定的AppStorage属性,以确保这些属性在应用程序重新启动时的值与应用程序关闭时的值相同。
概述
PersistentStorage将选定的AppStorage属性保留在设备磁盘上。应用程序通过API,以决定哪些AppStorage属性应借助PersistentStorage持久化。UI和业务逻辑不直接访问PersistentStorage中的属性,所有属性访问都是对AppStorage的访问,AppStorage中的更改会自动同步到PersistentStorage。
PersistentStorage和AppStorage中的属性建立双向同步。应用开发通常通过AppStorage访问PersistentStorage,另外还有一些接口可以用于管理持久化属性,但是业务逻辑始终是通过AppStorage获取和设置属性的。
限制条件
PersistentStorage允许的类型和值有:
- number, string, boolean, enum 等简单类型。
- 可以被JSON.stringify()和JSON.parse()重构的对象,但是对象中的成员方法不支持持久化。
- API12及以上支持Map类型,可以观察到Map整体的赋值,同时可通过调用Map的接口set, clear, delete 更新Map的值。且更新的值被持久化存储。详见装饰Map类型变量。
- API12及以上支持Set类型,可以观察到Set整体的赋值,同时可通过调用Set的接口add, clear, delete 更新Set的值。且更新的值被持久化存储。详见装饰Set类型变量。
- API12及以上支持Date类型,可以观察到Date整体的赋值,同时可通过调用Date的接口setFullYear, setMonth, setDate, setHours, setMinutes, setSeconds, setMilliseconds, setTime, setUTCFullYear, setUTCMonth, setUTCDate, setUTCHours, setUTCMinutes, setUTCSeconds, setUTCMilliseconds 更新Date的属性。且更新的值被持久化存储。详见装饰Date类型变量。
- API12及以上支持undefined 和 null。
- API12及以上支持联合类型。
PersistentStorage不允许的类型和值有:
- 不支持嵌套对象(对象数组,对象的属性是对象等)。因为目前框架无法检测AppStorage中嵌套对象(包括数组)值的变化,所以无法写回到PersistentStorage中。
持久化数据是一个相对缓慢的操作,应用程序应避免以下情况:
-
持久化大型数据集。
-
持久化经常变化的变量。
PersistentStorage的持久化变量最好是小于2kb的数据,不要大量的数据持久化,因为PersistentStorage写入磁盘的操作是同步的,大量的数据本地化读写会同步在UI线程中执行,影响UI渲染性能。如果开发者需要存储大量的数据,建议使用数据库api。
PersistentStorage和UI实例相关联,持久化操作需要在UI实例初始化成功后(即loadContent传入的回调被调用时)才可以被调用,早于该时机调用会导致持久化失败。
冷启动与热启动
uiability首次启动为冷启动,非首次为热启动
冷启动为onCreate()→onWindowStageCreate()→onForeground()
热启动为onNewWant()→onForeground()
布局性能优化
布局时应尽量减少总节点数,减少性能消耗
方向
1,移除冗余的节点
2,使用扁平化布局减少节点数
具体内容:
移除多余的外层线性布局
切换不同的布局类型实现扁平化
合理控制元素的显示隐藏
设置固定宽高减少measure的耗时(未设置和百分比宽高性能消耗较大)
仅在必要环境下使用高性能布局
长列表加载性能优化
主要分为四种
懒加载(10000条数据以上时建议使用layz)
缓存列表项(额外缓存部分列表项,一般为页面数据显示条数/2)
组件复用(减少组件创建的耗时操作@Reusable,aboutToReuse)
布局优化(相对布局,控制布局在5-8层)
webview的使用与传参
导入
import { webview } from '@kit.ArkWeb';
创建控制器
webController: webview.WebviewController = new webview.WebviewController();
再去build中选择本地的页面or网络中的页面
Web({ src: $rawfile('index.html'), controller: controller })//本地
Web({ src: 'www.example.com', controller: this.controller })//网络
当网页中调用
function submitAgreement(){ confirm(agreeCheckbox.checked) }
时,回调原生的onConfirm方法。
.onConfirm((event) => { return true; })
带的参数可以通过event.message获取
异步编程
ArkTS 支持 Promise 和 async/await 语法,使得异步编程变得更加简洁明了。
async function fetchData(url: string): Promise { let response = await fetch(url); let data = await response.json(); return data; }
fetchData('https://api.example.com/data') .then(data => console.log(data)) .catch(error => console.error(error));
Worker和TaskPool
TaskPool和Worker均支持多线程并发能力。由于TaskPool的工作线程会绑定系统的调度优先级,并且支持负载均衡(自动扩缩容),而Worker需要开发者自行创建,存在创建耗时以及不支持设置调度优先级,故在性能方面使用TaskPool会优于Worker,因此大多数场景推荐使用TaskPool。
TaskPool偏向独立任务维度,该任务在线程中执行,无需关注线程的生命周期,超长任务(大于3分钟且非长时任务)会被系统自动回收;而Worker偏向线程的维度,支持长时间占据线程执行,需要主动管理线程生命周期。
常见的一些开发场景及适用具体说明如下:
-
运行时间超过3分钟(不包含Promise和async/await异步调用的耗时,例如网络下载、文件读写等I/O任务的耗时)的任务。例如后台进行1小时的预测算法训练等CPU密集型任务,需要使用Worker。
-
有关联的一系列同步任务。例如在一些需要创建、使用句柄的场景中,句柄创建每次都是不同的,该句柄需永久保存,保证使用该句柄进行操作,需要使用Worker。
-
需要设置优先级的任务。例如图库直方图绘制场景,后台计算的直方图数据会用于前台界面的显示,影响用户体验,需要高优先级处理,需要使用TaskPool。
-
需要频繁取消的任务。例如图库大图浏览场景,为提升体验,会同时缓存当前图片左右侧各2张图片,往一侧滑动跳到下一张图片时,要取消另一侧的一个缓存任务,需要使用TaskPool。
-
大量或者调度点较分散的任务。例如大型应用的多个模块包含多个耗时任务,不方便使用Worker去做负载管理,推荐采用TaskPool。
总结:
TaskPool性能比较好
短时任务用TaskPool,长时任务(3分钟以上)用Woker