前面两篇文章分别对 DB-GPT 的总体情况进行了介绍,同时涵盖了镜像一键部署与源码部署这两种部署方式。
DB-GPT系列(二):DB-GPT部署(镜像一键部署、源码部署)
当DB-GPT 搭建完成后,怎么修改使用自己需要的大模型?本文将聚焦于DB-GPT底层大模型的修改,包括修改使用开源模型与在线模型。
一、使用在线大模型
1、修改.env文件
该文件在DB-GPT/主目录下
在.env文件中修改LLM_MODEL在线大模型名称、PROXY_API_URL在线大模型的API调用地址、API_KEY在线大模型的API_KEY
OpenAI设置
LLM_MODEL=chatgpt_proxyllm
PROXY_API_KEY={your-openai-sk}
PROXY_SERVER_URL=https://api.openai.com/v1/chat/completions
# 如果使用gpt-4
# PROXYLLM_BACKEND=gpt-4通义千问设置
LLM_MODEL=tongyi_proxyllm
TONGYI_PROXY_API_KEY={your-tongyi-sk}
PROXY_SERVER_URL={your_service_url}智谱清言设置
LLM_MODEL=zhipu_proxyllm
PROXY_SERVER_URL={your_service_url}
ZHIPU_MODEL_VERSION={version}
ZHIPU_PROXY_API_KEY={your-zhipu-sk}文心设置
LLM_MODEL=wenxin_proxyllm
PROXY_SERVER_URL={your_service_url}
WEN_XIN_MODEL_VERSION={version}
WEN_XIN_API_KEY={your-wenxin-sk}
WEN_XIN_API_SECRET={your-wenxin-sct}Gemini设置
LLM_MODEL=gemini_proxyllm
GEMINI_PROXY_API_KEY={your_api_key}2、在线大模型的API配置信息获取(以智谱清言为例)
(1)在线大模型的API调用地址查找
在智谱清言的的AI开放平台中,可以找到接口文档,并在接口文档中找到GLM-4的请求URL地址。
网址:智谱AI开放平台
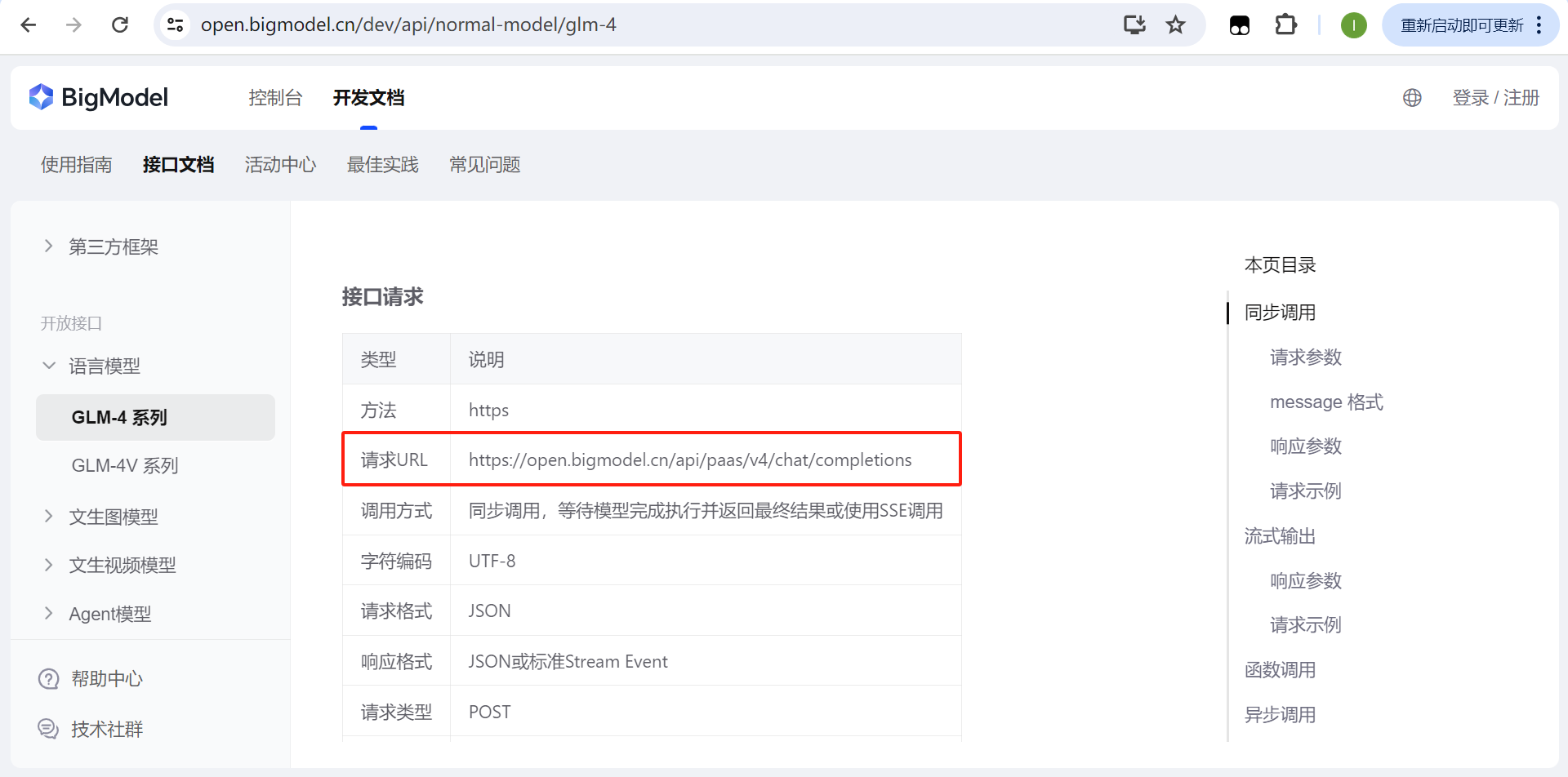
(2)在线大模型的API_KEY获取
在智谱清言的的AI开放平台中进行注册登录
网址:智谱AI开放平台
在个人中心添加新的API key或者复制已有的API key
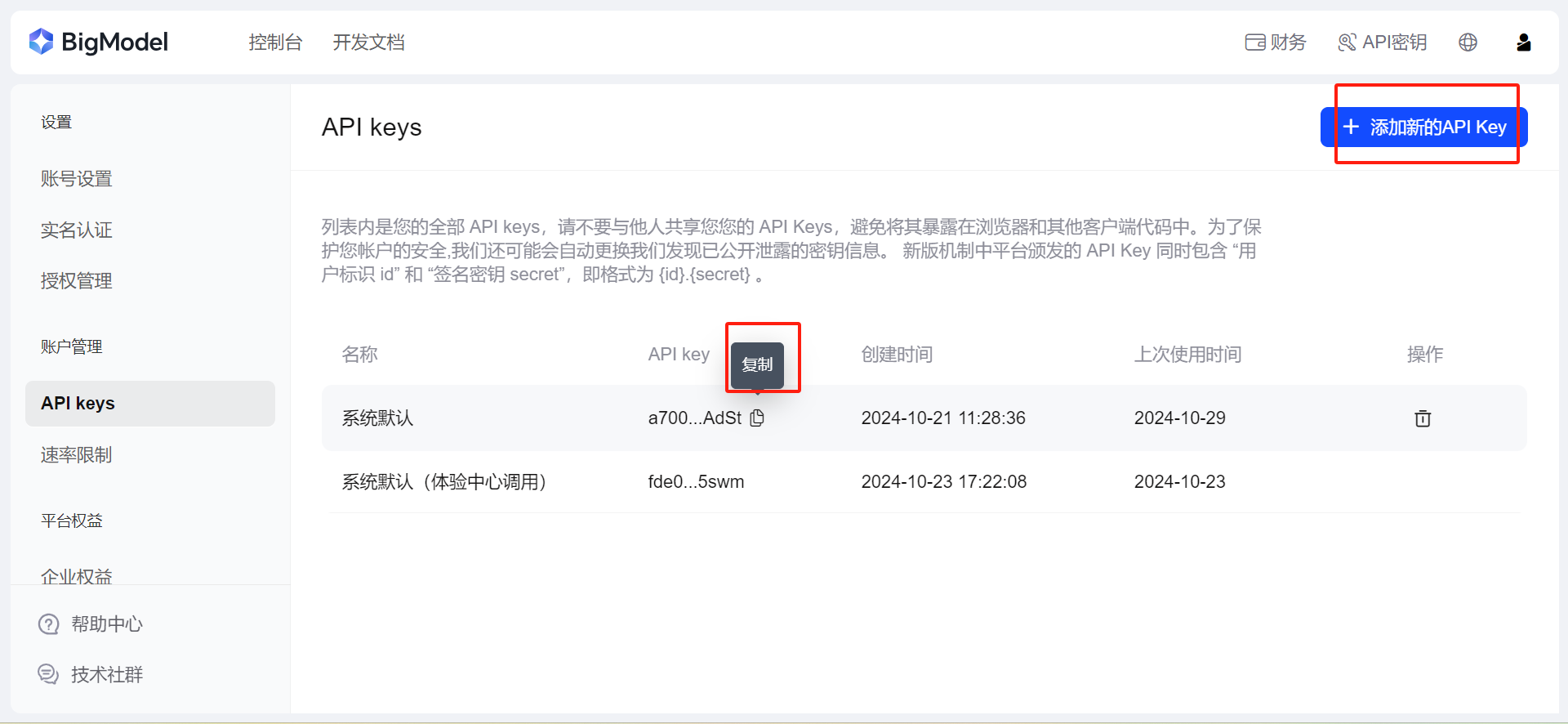
最后的配置如下
LLM_MODEL=zhipu_proxyllm
PROXY_SERVER_URL=https://open.bigmodel.cn/api/paas/v4/chat/completions
ZHIPU_MODEL_VERSION=glm-4
ZHIPU_PROXY_API_KEY=YOUR_API_KEY3、重新启动DB-GPT
最后,重新启动DB-GPT
# 进入DB-GPT主目录
cd /DB-GPT
# 启动DB-GPT
python dbgpt/app/dbgpt_server.py检查DB-GPT是不是有修改后的大模型
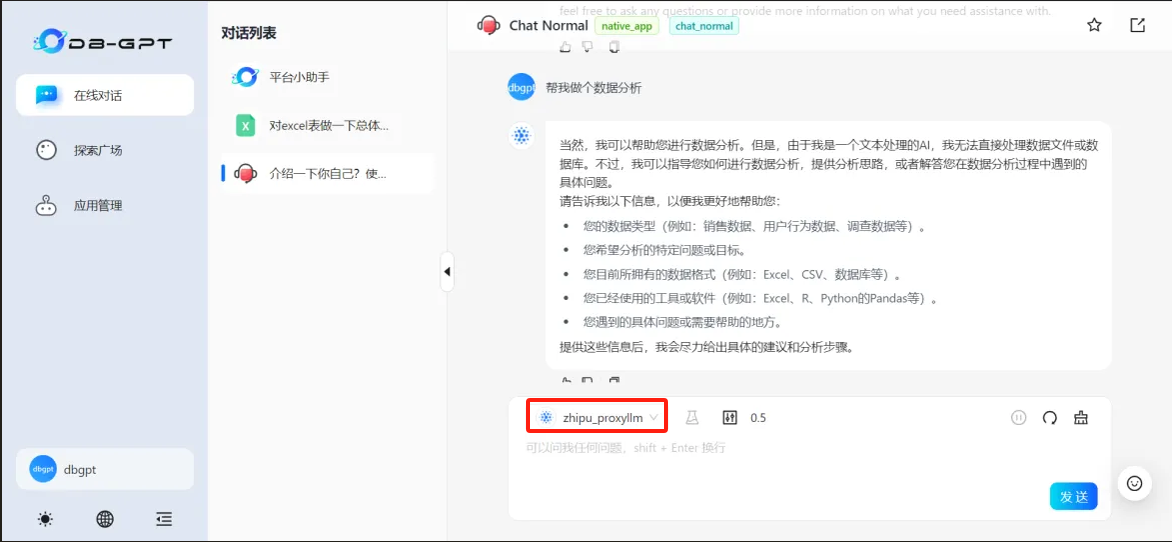
二、使用开源大模型
1、下载开源大模型
步骤:安装git-lfs-->创建模型存放目录-->在目录中开源大模型
首先确保安装了git-lfs,避免下载大文件时候出现超时的情况。
git-lfs安装命令:
● CentOS安装: yum install git-lfs
● Ubuntu安装: apt-get install git-lfs
● MacOS安装: brew install git-lfs创建模型存放目录,并在目录中开源大模型
# 进入DB-GPT主目录
cd DB-GPT
# 创建models文件夹并进入
mkdir models
cd models
# 下载开源大模型,下面是下载Qwen2.5-14B模型
git clone https://www.modelscope.cn/Qwen/Qwen2.5-14B-Instruct.git
# 其他开源大模型
# 百川
# git clone https://huggingface.co/baichuan-inc/Baichuan2-13B-Chat
# chatglm2
# git clone https://huggingface.co/THUDM/chatglm2-6b具体各类开源大模型对应的硬件需求,后续会专门写一篇文章说明。
2、修改配置文件
步骤:修改.env 文件 -->修改model_config.py 文件
.env 文件则定义了DB-GPT项目运行方式
model_config.py 文件定义了模型名称和模型路径的映射关系
(1)修改.env文件,该文件在DB-GPT/主目录下
LLM_MODEL=Qwen2.5-14B-Instruct(2)修改model_config.py 文件,该文件在DB-GPT/dbgpt/configs/目录下
打开model_config.py文件,找到LLM_MODEL_CONFIG如下图所示。
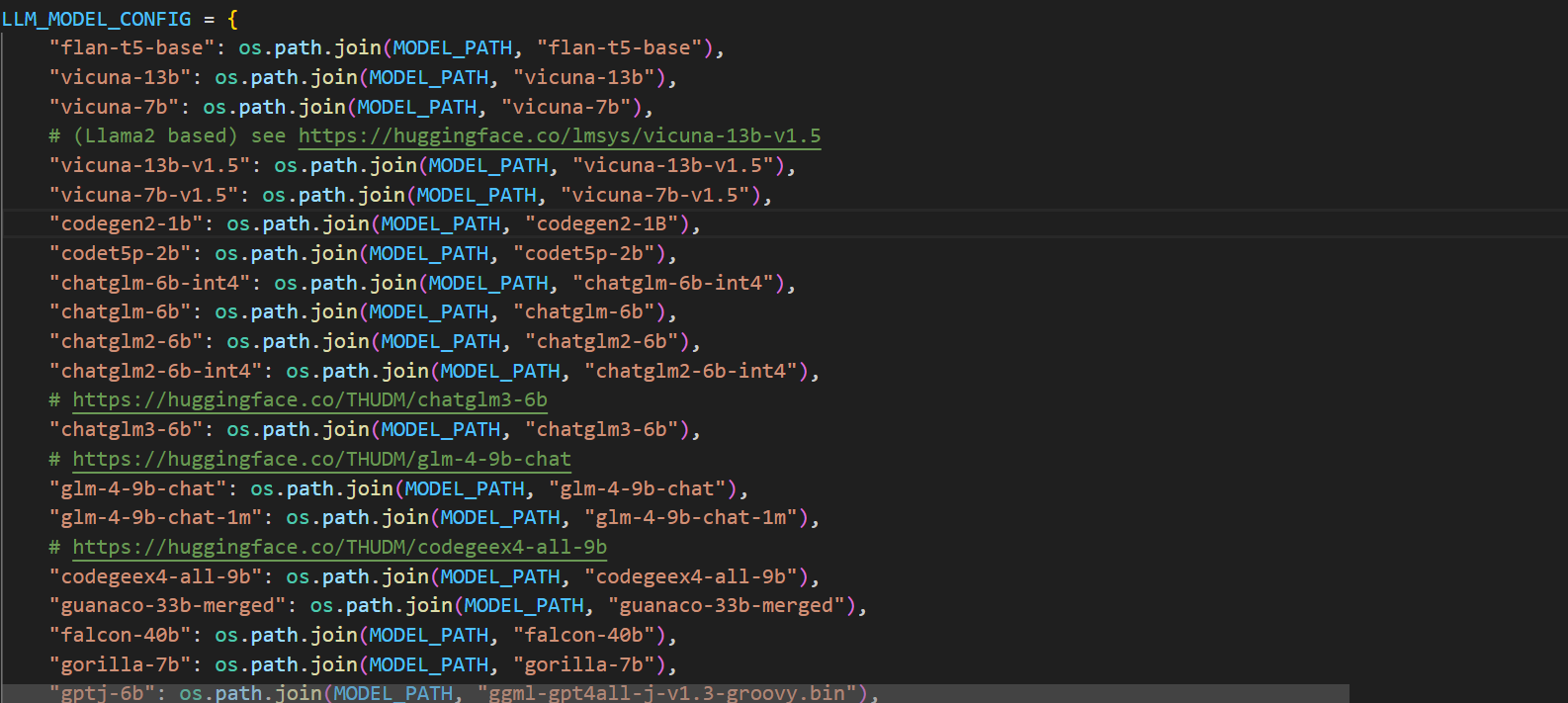
LLM_MODEL_CONFIG是一个字典,其中Key是模型名称,value是模型文件名称
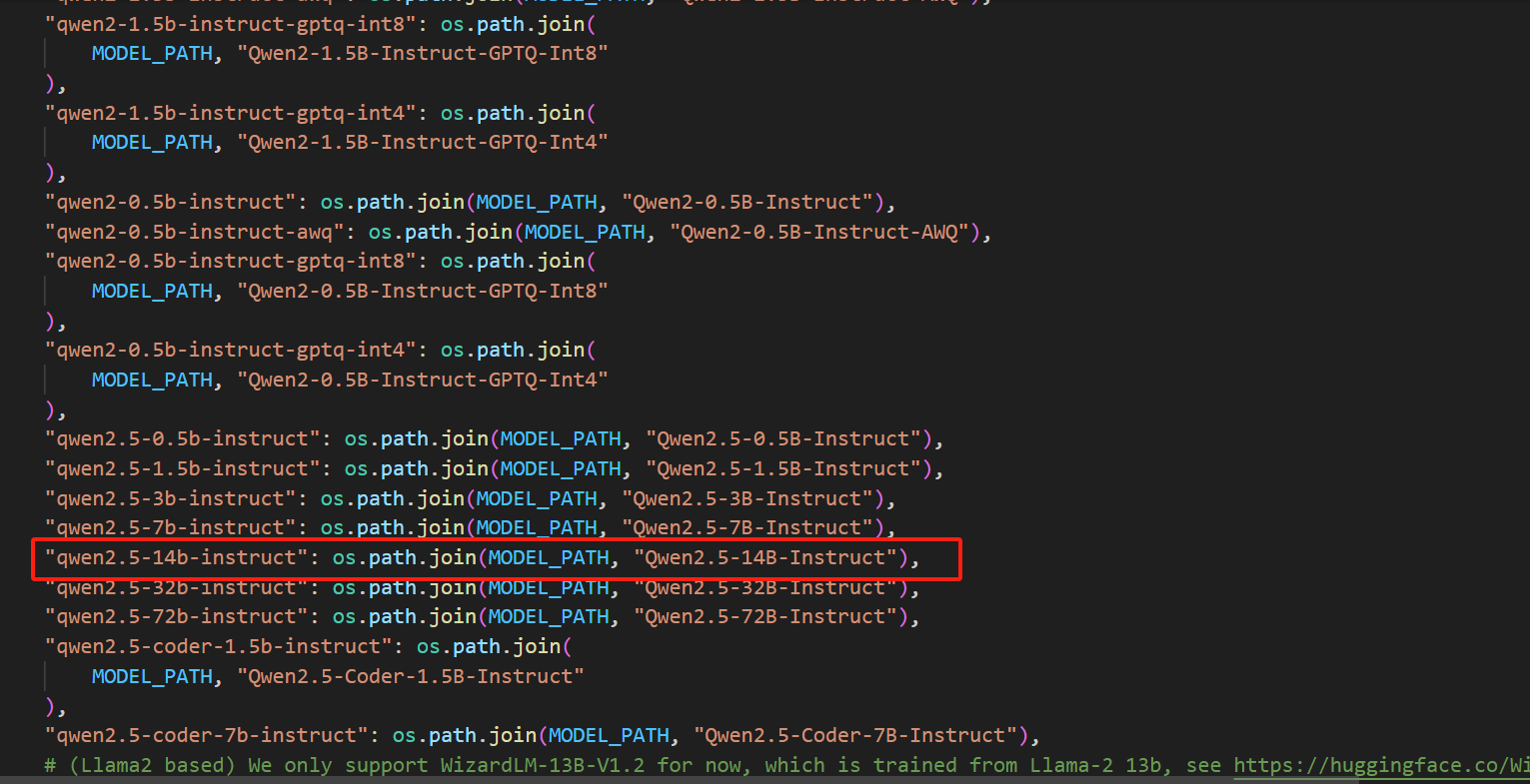
搜索下载大模型,有没有相应配置,例如前面下载的Qwen2.5-14B-Instruct,以及对应的模型文件是不是一致。如无配置,则需要手动添加。
3、重新启动DB-GPT
最后,重新启动DB-GPT
# 进入DB-GPT主目录
cd /DB-GPT
# 启动DB-GPT
python dbgpt/app/dbgpt_server.py检查DB-GPT是不是有修改后的大模型