介绍
今天我想和大家分享一个我在研究技术资料时发现的很好玩的东西------Tesseract。这不仅仅是一个普通的库,而是一个用C语言编写的OCR神器,能够识别一大堆不同国家的语言。我一直在寻找能够处理各种文档的工具,而Tesseract就像是给了我一把万能钥匙。
有时候我们手头会有一堆扫描的文件或者图片,里面有很多有用的信息,但是它们就是静静地躺在那里,不能复制粘贴,也不能搜索。这让我特别头疼。直到我发现了Tesseract,这个问题才迎刃而解。它不仅能够识别英文,还能搞定中文、日文、韩文等等,简直是多语言文档的救星。
我在这里不是要给大家上技术课,而是想分享一个我觉得特别有意思的案例。这个案例展示了如何用Tesseract和其他几个开源工具,在服务器上把PDF文件和图片里的文字给"抠"出来。这个过程我觉得既神奇又实用,我觉得你们可能会感兴趣。
接下来,我会一步步地带你们了解这个过程。我们将会用到Ghostscript、Tesseract和PDFtk这三个工具,搭建起一个完整的OCR流水线。
我相信,这个案例也可以给你带来一些关于开发上新的思路和实用的小技巧。
那么,我们就不多废话了,一起来探索OCR的奥秘吧!
前提条件
如标题所示,是在服务器端对 PDF 进行 OCR 处理,所以我们我们需要一台 Linux 服务器,我的环境是 Ubuntu,建议与我的环境一致,避免运行的过程中出错。
如果你没有服务器,那可以跟着我的步骤 ,创建一台属于自己的Linux服务器,
我将会以 雨云 为例,带大家创建一台自己的云服务器,尝试本篇文章的内容。
注册链接 : https://www.rainyun.com/NTEzMTM1_?s=blog
创建云服务器
以下内容只是参考,具体按照自己的需求选择配置即可。
点击"云产品"→"云服务器"→"立即购买"。
建议选择距离您较近的区域,以降低延迟。
选择配置。
选择Ubuntu 22.04版本,并看自己需求是否勾选预装Docker。
点击"立即购买",并完成后续购买流程。 购买完成后,等待服务器部署完毕,进入管理面板,找到远程连接信息。
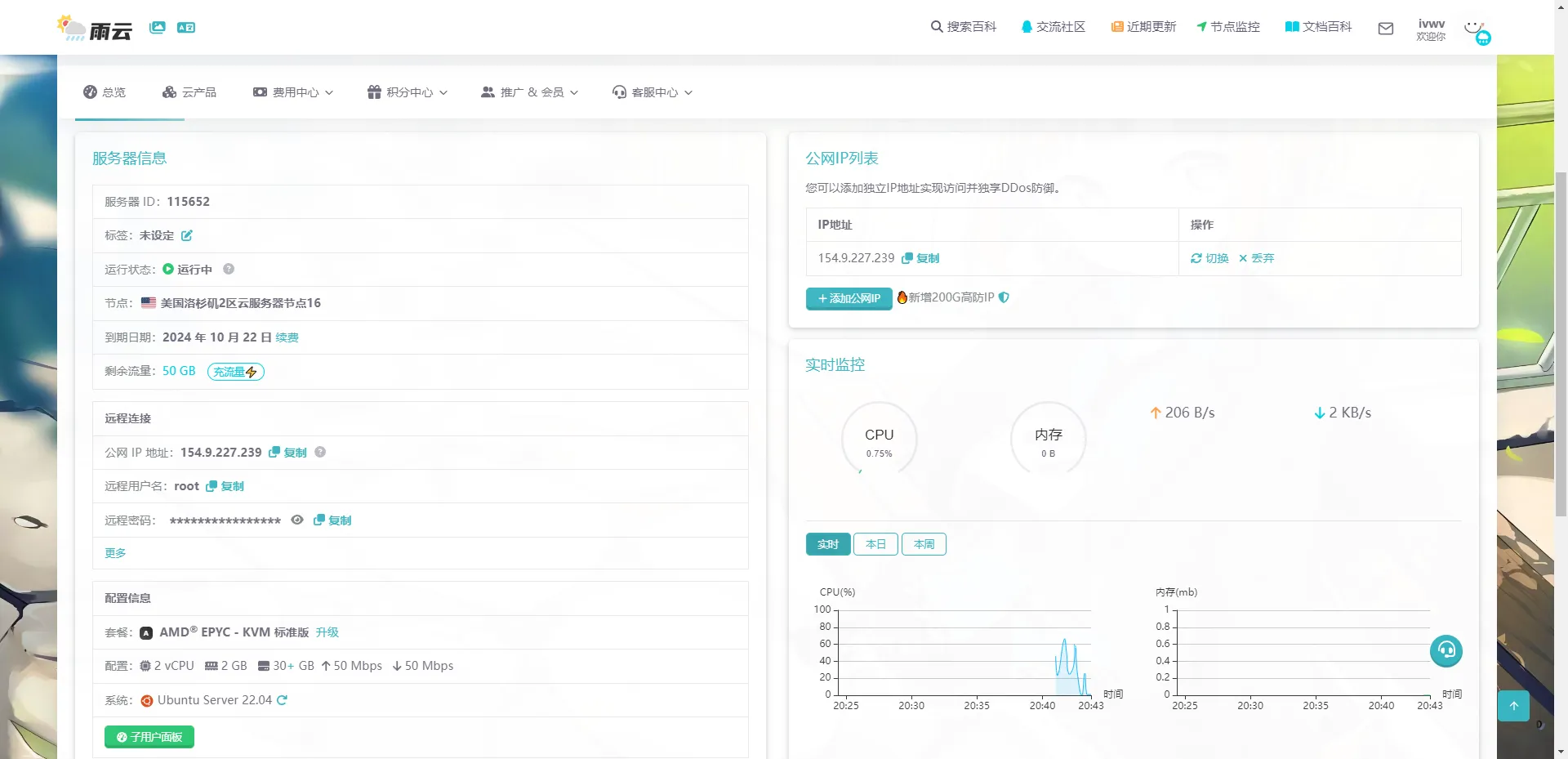
使用PowerShell进行远程连接:输入ssh root@你的服务器IP (例如ssh root@154.9.227.239),首次连接需输入yes,然后回车即可登录。
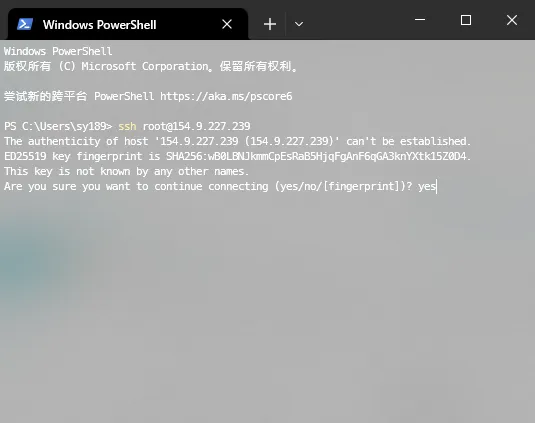
到这里,我们的服务器就创建完毕,并且能够远程SSH访问了。
教程开始
第一步:安装 Ghostscript、Tesseract 和 PDFtk
OCR既能处理PDF文件(PDF文件里有时也包含图片),也能直接处理图片。处理PDF文件会多一些步骤,如果你只处理图片,可以跳过这些步骤。
我们需要三个工具:
Ghostscript: 能把PDF转换成图片,也能把图片转换成PDF的工具。Tesseract: OCR引擎,能把图片里的文字识别出来。PDFtk: 这个工具比较小巧,主要用来把PDF文件拆分成单页,或者把单页重新组合成一个完整的PDF。
在Ubuntu系统上,安装这三个工具非常简单,只需要在终端输入以下命令:
bash
sudo apt update
sudo apt install pdftk ghostscript tesseract-ocr x11-utils安装完成后,可以用which命令检查一下是否安装成功:
bash
which pdftk
# /usr/bin/pdftk
which gs
# /usr/bin/gs
which tesseract
# /usr/bin/tesseract接下来,我们就可以开始提取文字了!
第二步:将 PDF 转换为图片并运行 Tesseract
如果你没有PDF文件,可以下载我这个示例PDF文件先练练手,如果你有自己的PDF文件,可以替换后面内容中的文件名。
bash
curl -L "https://paste.c-net.org/MckennaBuzzing" -o "OCR-sample-paper.pdf"如果你的文件是PDF,首先需要把它转换成图片。我们可以用 Ghostscript 来完成这个任务:
bash
mkdir output # 创建一个文件夹存放生成的图片
gs -o output/%05d.png -sDEVICE=png16m -r300 -dPDFFitPage=true OCR-sample-paper.pdf这段命令有点长,但别怕!我会解释这些参数:
-o output/%05d.png表示把图片保存到output文件夹,%05d会自动给图片编号;-sDEVICE=png16m指定图片格式为PNG;-r300设置图片分辨率;-dPDFFitPage=true确保图片大小合适。
运行后会输出一下信息,Ghostscript 将单独输出 PDF 中的每个页面:
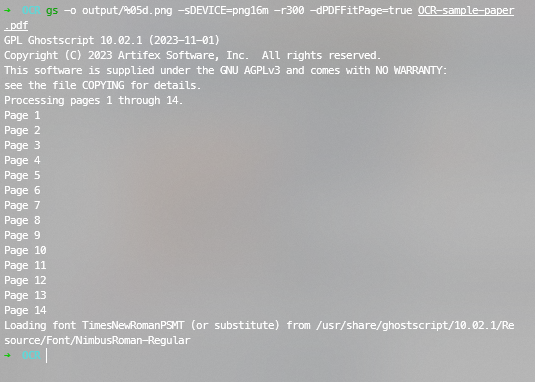
完成后,你可以用ls output命令查看生成的图片。

此时看到 output 目录下有14张图片,如果你的环境中有Nodejs环境,可以使用以下命令,将当前路径设置为静态资源目录,我们来看看,这些 png 图片是什么:
bash
npx http-server
运行好后浏览器打开网址,我这里是: http://you_server_ip:8080 并进入output目录

我点击打开 00003.png ,发现是一张图片,图片并不能够复制文字。
接下来,我们用Tesseract把图片转换成可复制文字的PDF:
bash
for png in $(ls output); do
tesseract -l eng \
-c preserve_interword_spaces=0 \
output/$png \
output/$(echo $png | sed -e "s/\.png//g") \
pdf
done这段命令有点复杂,但核心就是用Tesseract识别图片里的文字,并生成PDF文件。-l eng表示使用英语语言模型,如果你需要识别其他语言,需要安装对应的语言包。
Tesseract会逐页处理图片,完成后,你可以在output文件夹里看到生成的PDF文件。
继续列出 output 目录下的内容,会看到多了同名的 PDF 文件。

我们继续浏览器查看这些文件,还是打开00003.pdf:
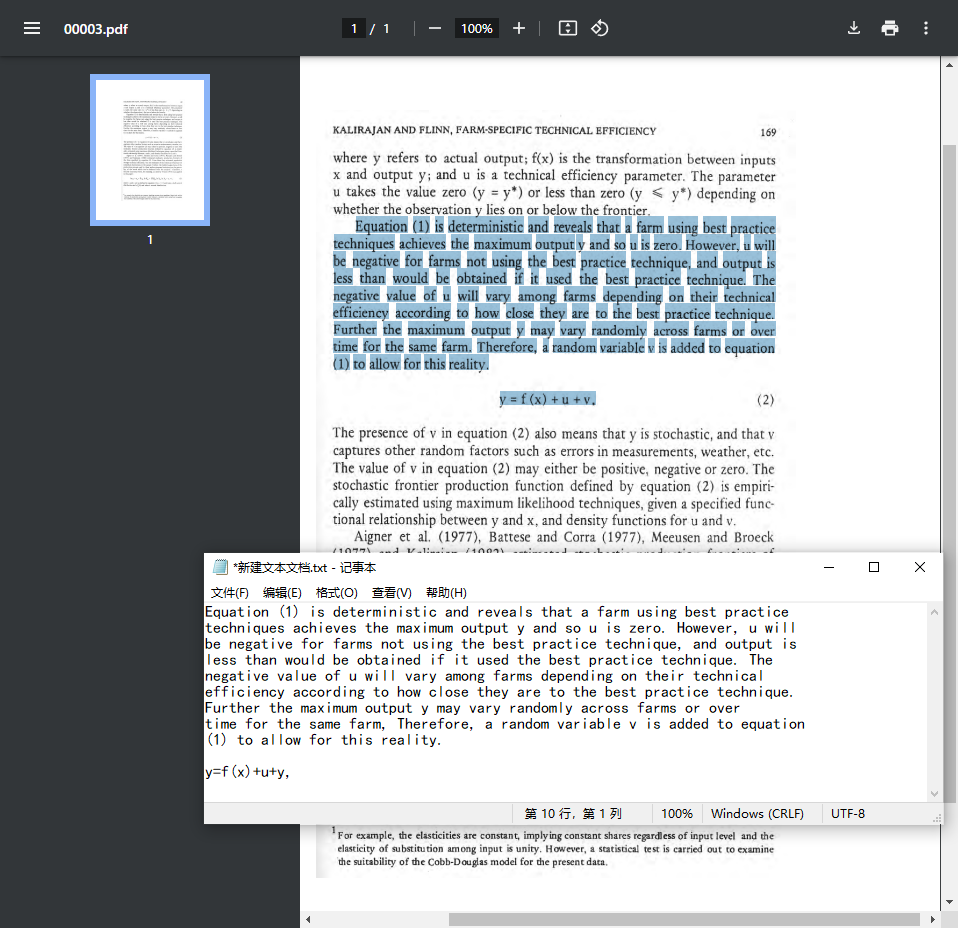
发现这次就可以任意复制了,并且识别正确率还是很高的。
小提示: Ubuntu系统默认只安装了英语语言包,如果你需要识别其他语言,需要安装对应的语言包,例如
sudo apt install tesseract-ocr-all安装所有语言包。安装好后浏览器打开 https://tesseract-ocr.github.io/tessdoc/Data-Files-in-different-versions.html 这个网址,可以找到对应的 LangCode ,如果你需要识别中文,那么
-l参数后面将eng修改为chi_sim即可。
第三步:把单页PDF合并成一个
如果你处理的是PDF文件,现在需要把第二步生成的单页PDF文件合并成一个完整的PDF文件。我们可以用 **PDFtk **来完成这个任务:
bash
pdftk output/*.pdf cat output joined.pdf
这段命令很简单,就是把output文件夹里的所有PDF文件合并成一个名为joined.pdf的文件。
最后,我们用 Ghostscript 调整一下PDF文件的格式,让它看起来更漂亮:
bash
gs -sDEVICE=pdfwrite -sPAPERSIZE=letter -dFIXEDMEDIA -dPDFFitPage -o final.pdf joined.pdf这段命令主要用来调整PDF的尺寸和格式。-sPAPERSIZE=letter表示使用Letter纸张大小,你可以根据需要修改。
现在,你已经成功地完成了OCR!如果实际应用到开发中,你可以使用这一系列工具,自动化完成,并且使用pdftotext final.pdf命令把PDF文件转换成文本文件,可以开发一个知识库的全文检索,将原本内容为图片扫描件的PDF提取文字。
相关链接
雨云 - 新一代云服务提供商: https://www.rainyun.com/NTEzMTM1_?s=blog