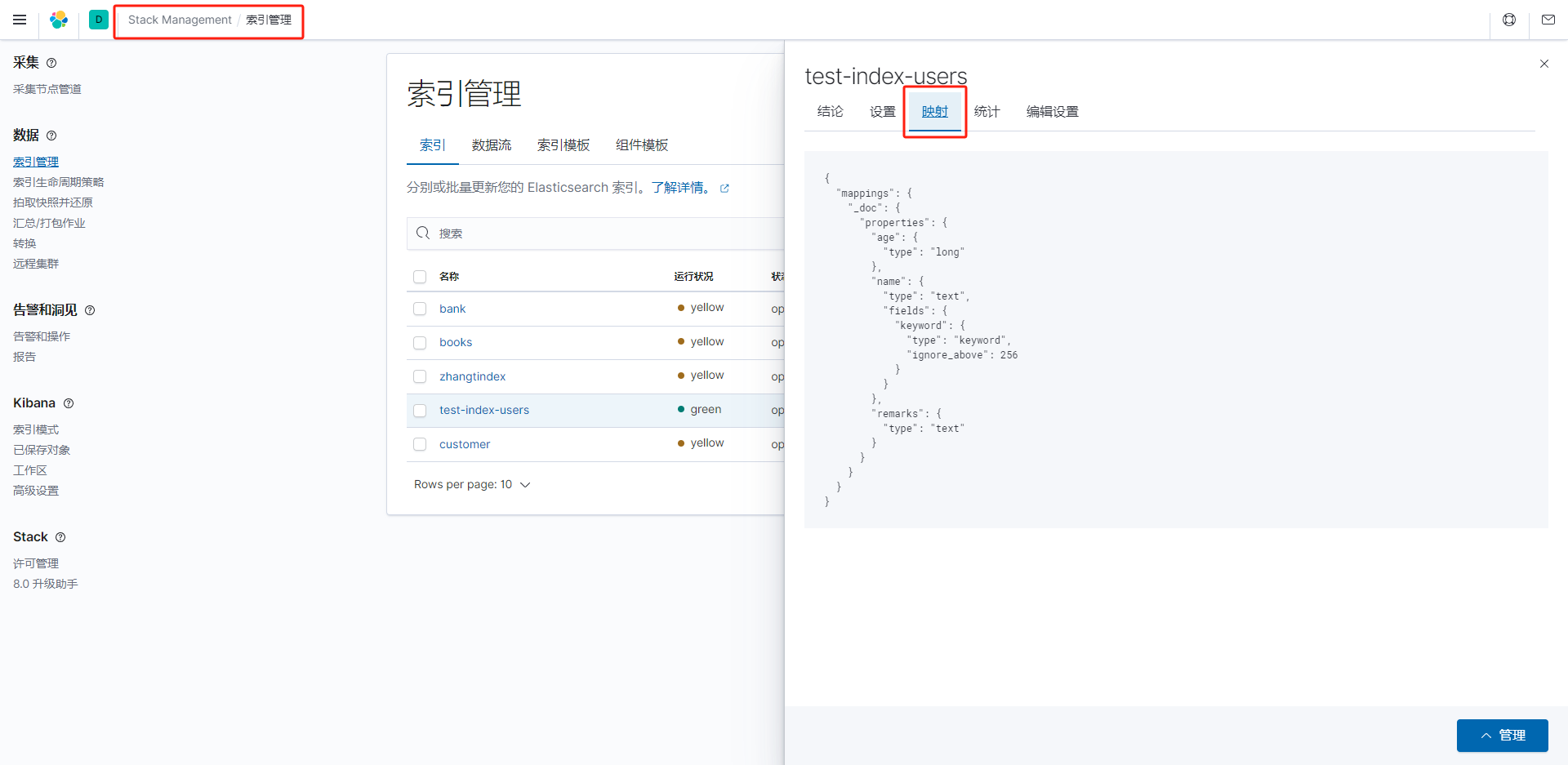
索引管理
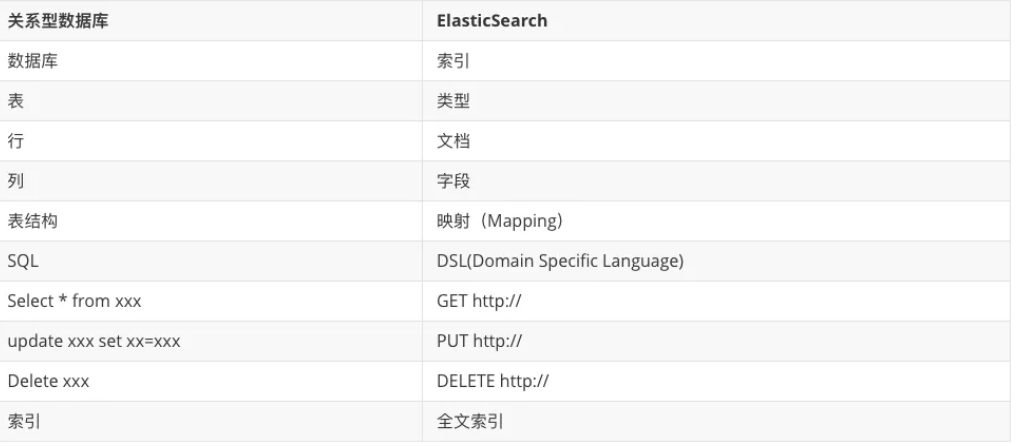
再讲索引(Index)前,我们先对照下 ElasticSearch Vs 关系型数据库:
javascript
PUT /customer/_doc/1
{
"name": "DLBOY"
}系统默认是自动创建索引的
如果我们需要对这个建立索引的过程做更多的控制:
比如想要确保这个索引有数量适中的主分片,并且在我们索引任何数据之前,分析器和映射已经被建立好。
那么我们需要做两件事:第一个禁止自动创建索引 ,第二个是手动创建索引。
禁止自动创建索引
可以通过在 config/elasticsearch.yml 的每个节点下添加下面的配置
javascript
action.auto_create_index: false创建索引
创建一个名称为test-index-users的索引(Index)
javascript
PUT /test-index-users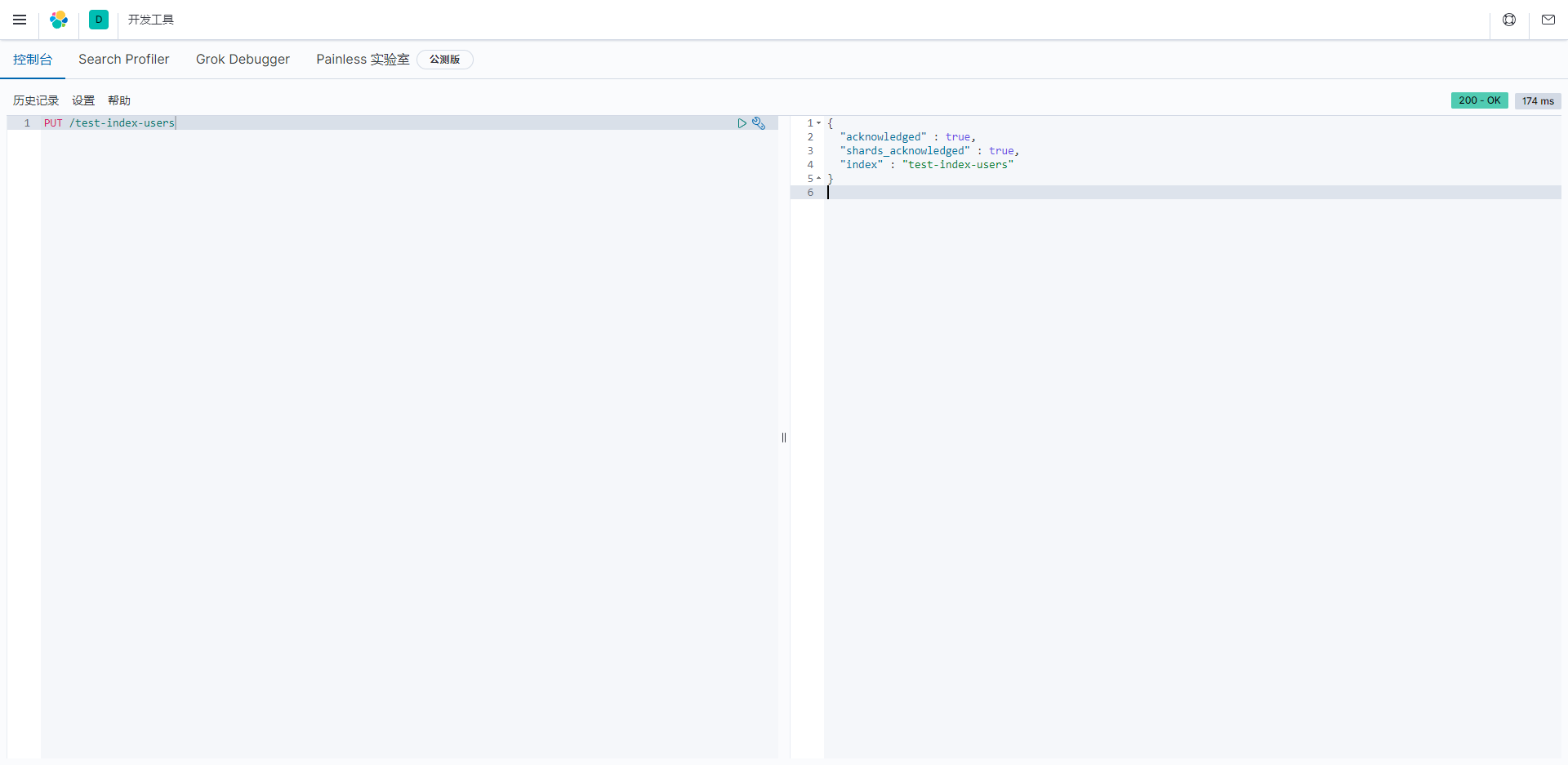
javascript
{
"acknowledged" : true,
"shards_acknowledged" : true,
"index" : "test-index-users"
}这是一个Elasticsearch索引创建的响应示例,包含了以下关键信息:
- "acknowledged": 这是一个布尔值,表示索引的创建是否得到了确认。如果为true,则表示索引成功创建。
- "shards_acknowledged": 这也是一个布尔值,表示索引中的分片是否得到了确认。如果为true,则表示所有分片成功创建。
- "index": 这是新创建索引的名称,名称为"test-index-users"。
这个响应表明,索引"test-index-users"已成功创建,并且所有分片也得到了确认。索引创建成功后,你可以向该索引中添加文档,执行搜索操作以及执行其他与索引相关的操作。索引是Elasticsearch中组织和存储数据的重要结构。
我们创建一个user 索引test-index-users,其中包含三个属性:name,age, remarks; 存储在一个分片一个副本上。
手动创建带有mapping关系的索引
创建索引test-index-users,其中包含三个属性:name,age, remarks; 存储在一个分片一个副本上。
json
## 先删除掉创建过的索引
DELETE /test-index-users
PUT /test-index-users
{
"settings":{
"number_of_shards":1,
"number_of_replicas":1
},
"mappings":{
"properties":{
"name":{
"type":"text",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":256
}
}
},
"age":{
"type":"long"
},
"remarks":{
"type":"text"
}
}
}
}
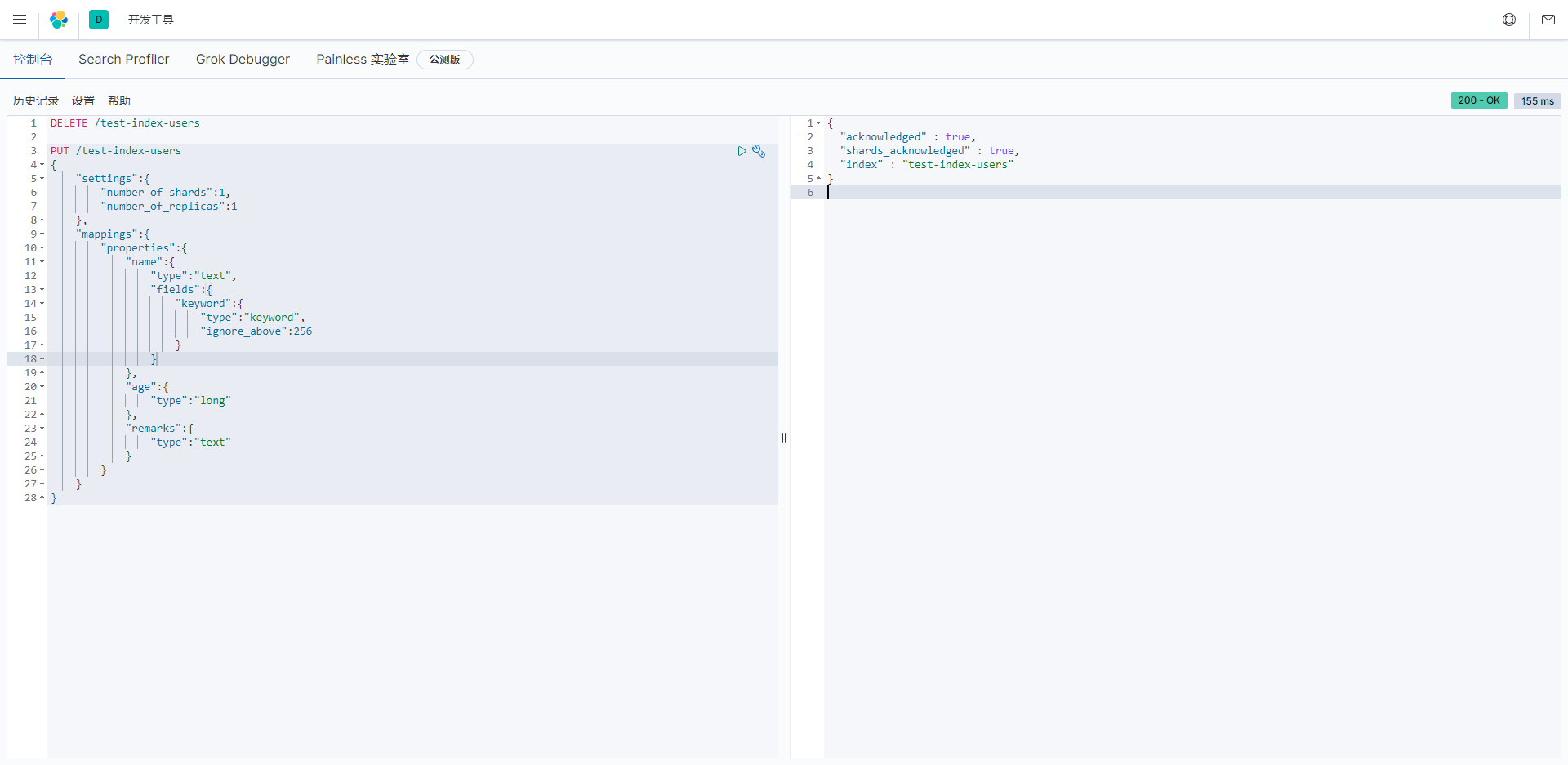
Elasticsearch索引的设置(settings)和映射(mappings)的示例。让我来解释其中的各个部分:
"settings": 这是索引的设置部分,包含了索引的全局设置。
"number_of_shards": 这是指定索引的主分片数量。在这个示例中,设置为1,表示索引有一个主分片。主分片用于存储索引的主要数据。
"number_of_replicas": 这是指定索引的副本数量。在这个示例中,设置为1,表示为索引创建一个副本。副本用于提高数据的冗余性和可用性。
"mappings": 这是索引的映射部分,定义了索引中文档的结构。
"properties": 这是文档字段的定义部分。
"name": 这是一个名为"name"的字段,具有以下属性:
"type": 这是字段的数据类型,这里是"text"。text数据类型通常用于全文搜索,支持分词等功能。
"fields": 这是一个嵌套的字段定义,包含了一个名为"keyword"的子字段。
"type": 这是子字段的数据类型,这里是"keyword"。keyword数据类型通常用于精确匹配和排序,不进行分词。
"ignore_above": 这是一个可选的参数,用于指定在索引前多少个字符之前,不进行分词处理。在这里,设置为256,表示只有前256个字符会被索引,超过这个长度的文本将被截断。
"age": 这是一个名为"age"的字段,具有数据类型"type":"long",表示一个长整数类型的字段。
"remarks": 这是一个名为"remarks"的字段,具有数据类型"type":"text",通常用于全文搜索。
这个示例的索引定义了一些基本设置,包括主分片和副本数量,以及文档结构,包括"name"字段,包括了一个子字段"keyword","age"字段和"remarks"字段。这种映射和设置允许索引文档,支持各种查询和分析操作。
插入数据
javascript
POST /test-index-users/_doc
{
"name": "goboy test name",
"age": "101",
"remarks": "hello world"
}POST在不标记ID的时候,系统会默认帮着我们创建一个ID
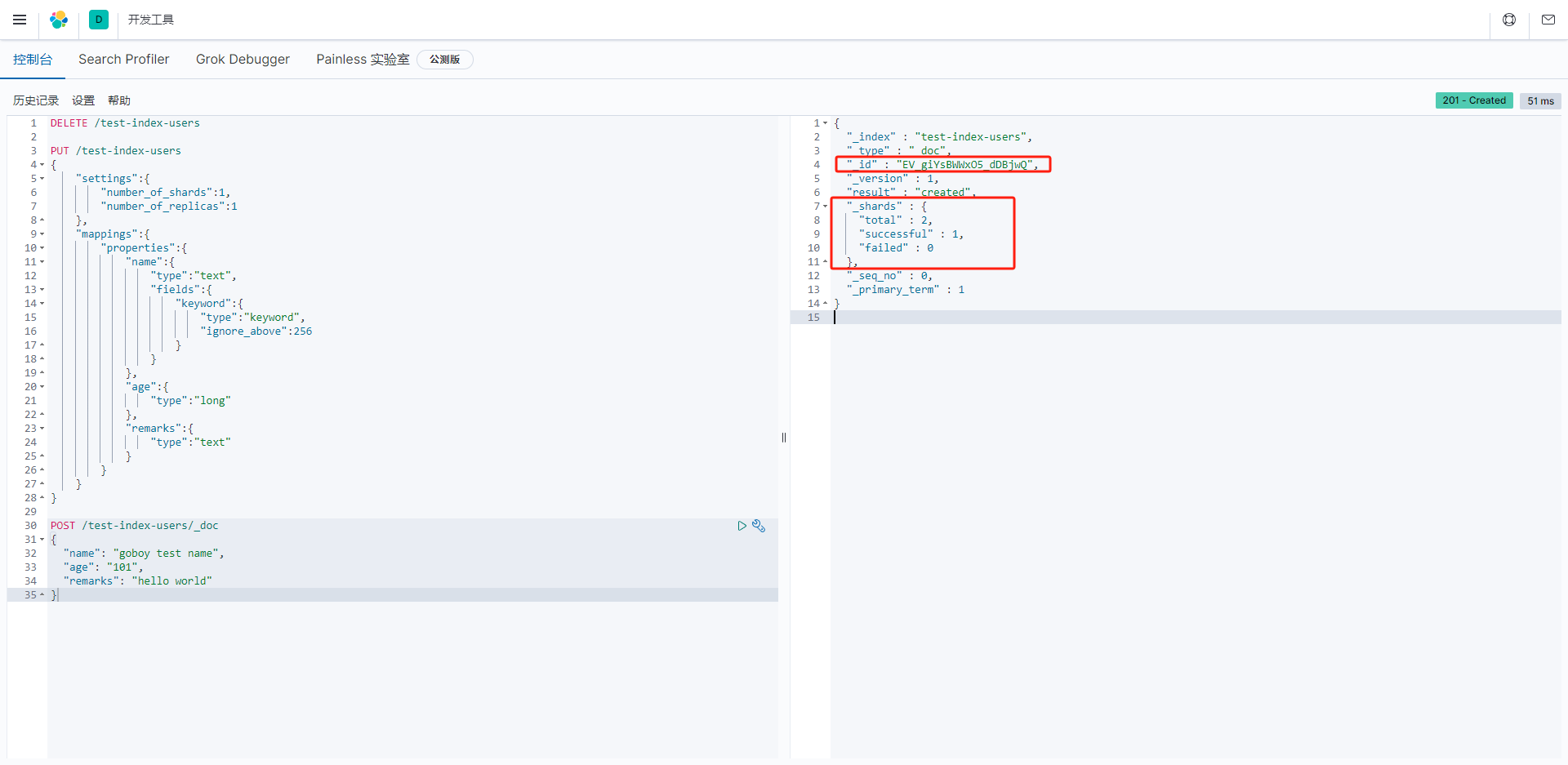
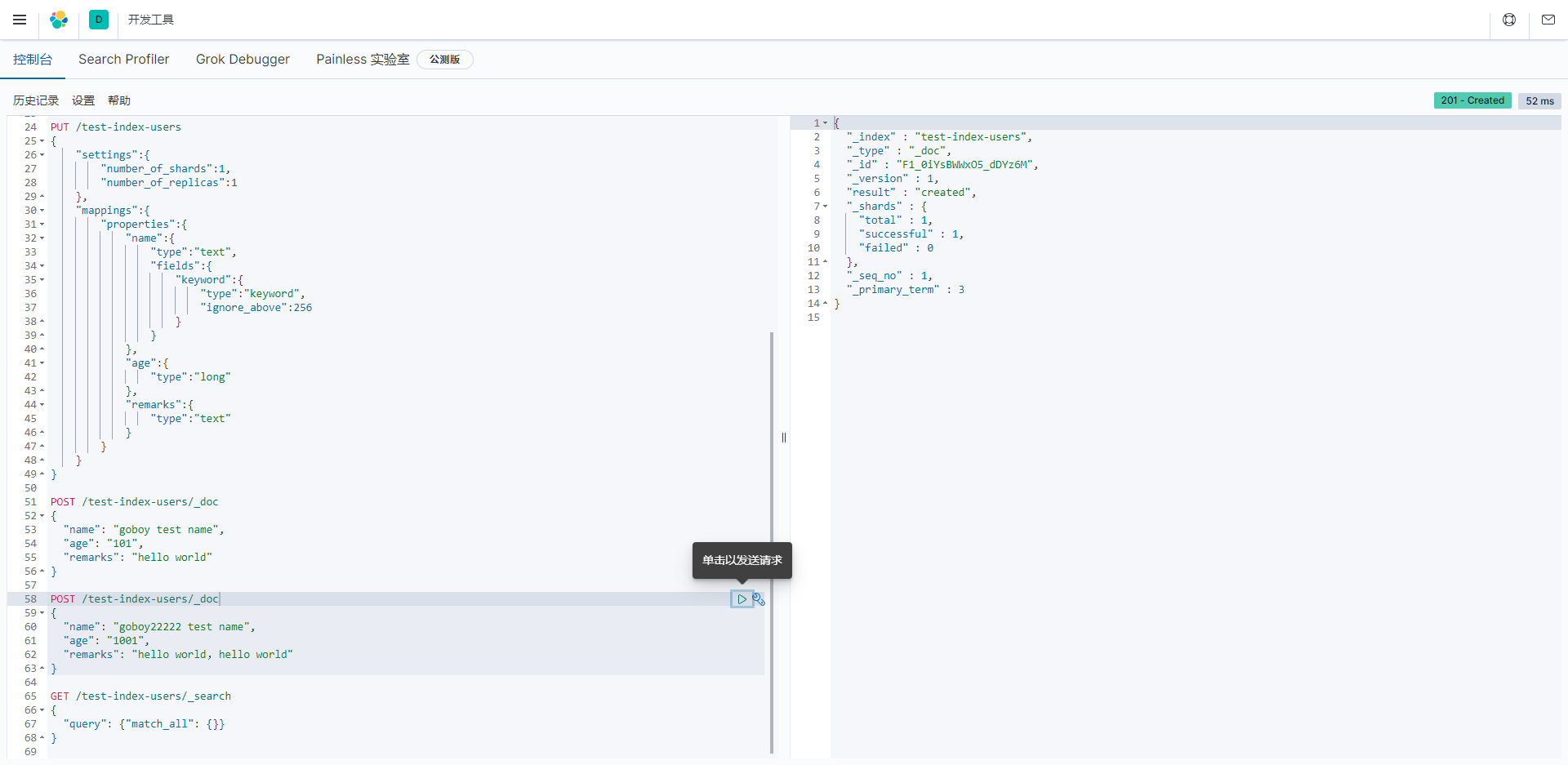
Elasticsearch文档的索引响应示例,包含了以下关键信息:
"_index": 这是文档所属的索引的名称,这里是"test-index-users"。
"_type": 这是文档的类型,在Elasticsearch 7.x版本之后,通常为"_doc",表示默认文档类型。
"_id": 这是文档的唯一标识符,用于在索引中唯一标识文档。这里是"EV_giYsBWWxO5_dDBjwQ"。
"_version": 这是文档的版本号,表示文档的版本。在这里,文档的版本号是1。
"result": 这是文档索引操作的结果,这里是"created",表示文档已经成功创建。
"_shards": 这是关于文档索引操作的分片信息。
"total": 这是总分片数量,这里是2。
"successful": 这是成功索引的分片数量,这里是1。这表示在2个分片中的1个成功索引。
"failed": 这是失败的分片数量,这里是0。表示没有分片索引操作失败。
"_seq_no": 这是文档的序列号,用于跟踪文档的变化。
"_primary_term": 这是文档所在的主分片的主要期(primary term)。
这个响应表明文档成功地被索引到了"test-index-users"索引中,索引操作是成功的,只有一个分片成功地完成了索引操作。索引操作通常用于将文档添加到Elasticsearch索引中,以便后续搜索和检索。
查看数据
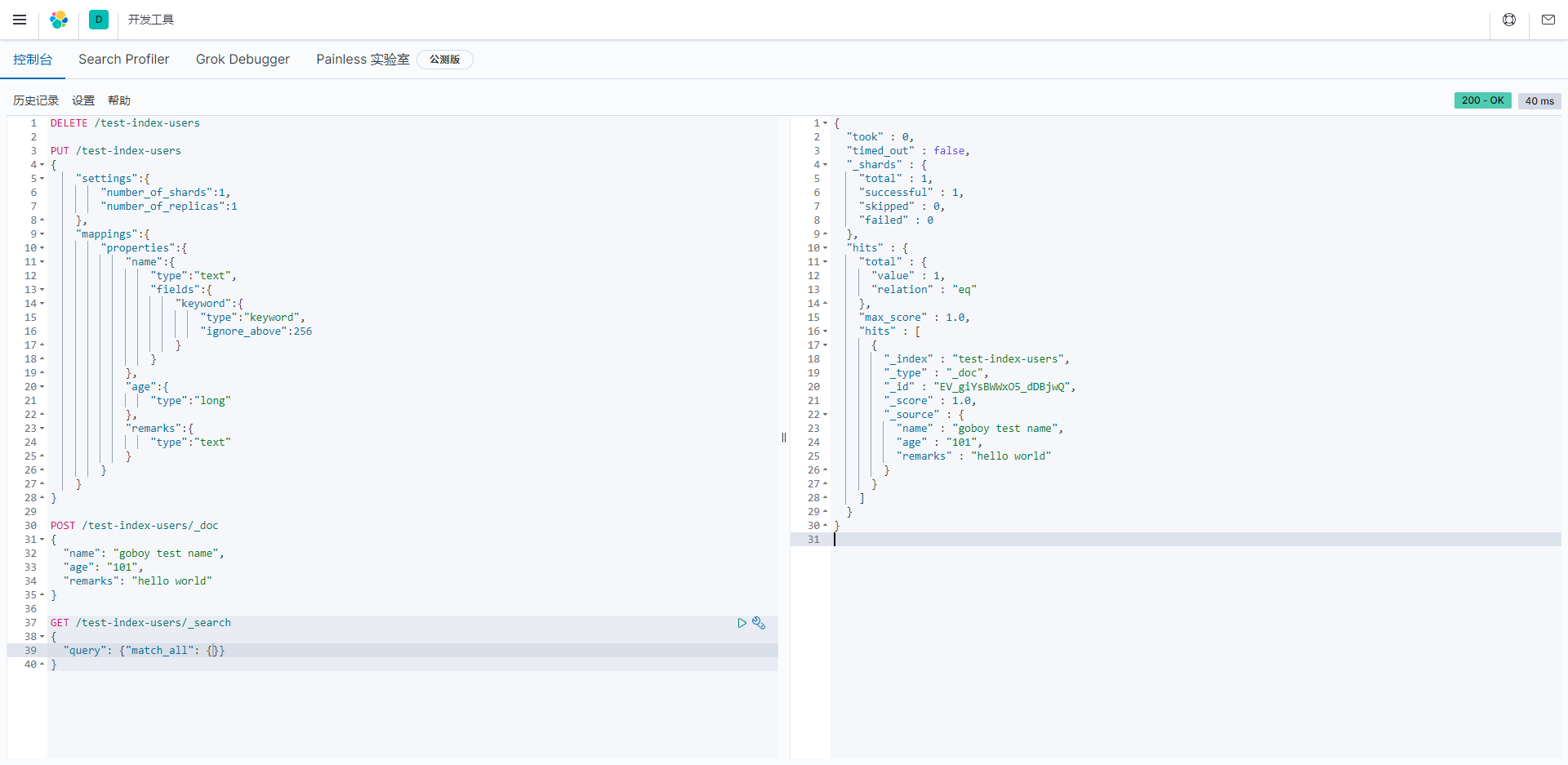
- 测试(age)字段与设定的数据类型不匹配的情况
javascript
POST /test-index-users/_doc
{
"name": "test user",
"age": "error_age",
"remarks": "hello eeee"
}- 提示错误
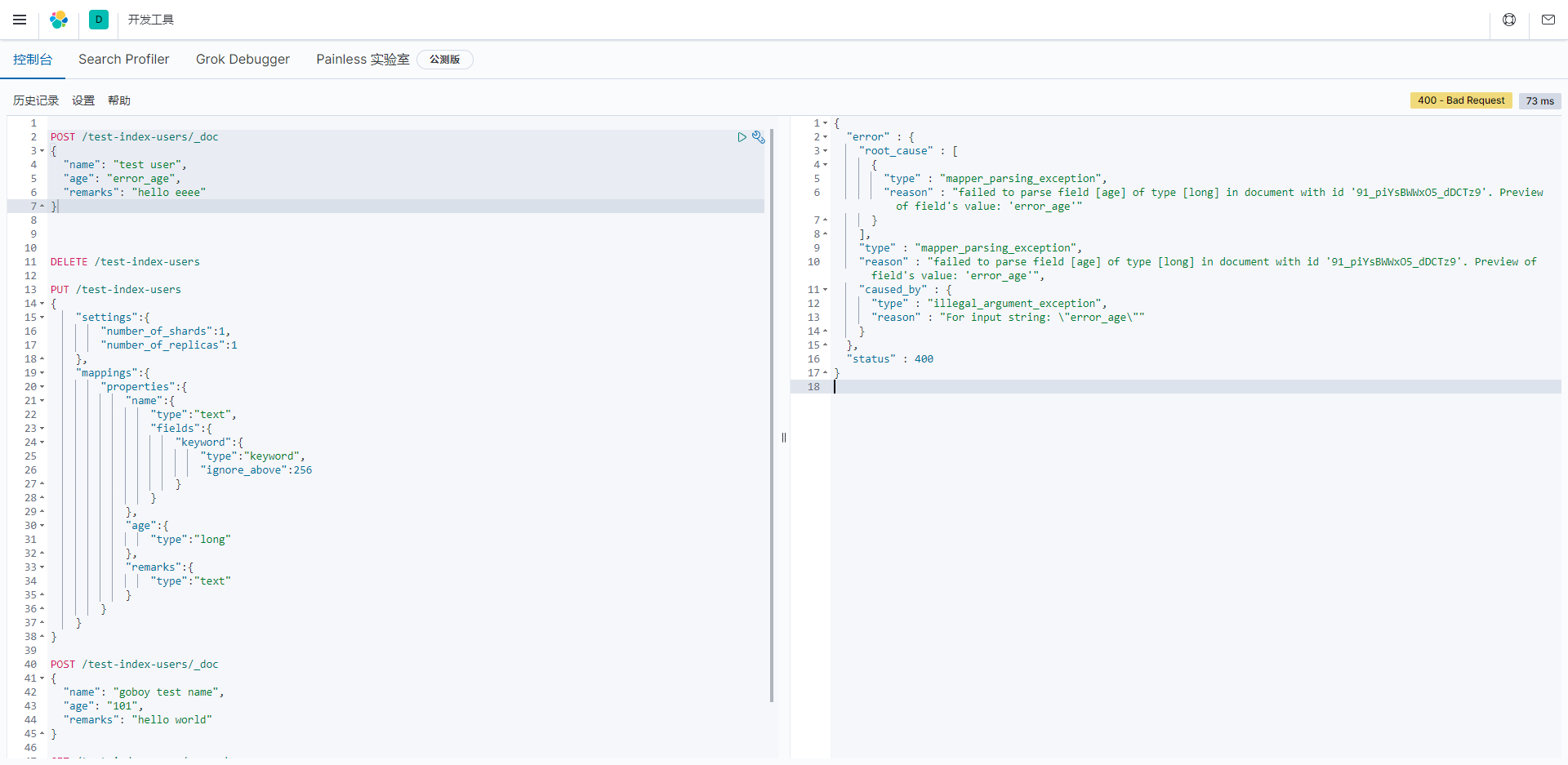
修改索引
查看索引状态
javascript
curl 'localhost:9200/_cat/indices?v' | grep users这个命令是使用curl工具查询Elasticsearch中的索引,并使用grep筛选出包含"users"的索引。在Elasticsearch中,_cat/indices端点用于获取有关索引的信息,而| grep users则用于筛选包含"users"的行。
以下是示例命令的解释:
- curl 'localhost:9200/_cat/indices?v': 这是一个curl命令,用于向Elasticsearch实例发出HTTP请求,从_cat/indices端点获取索引信息。-v参数用于显示详细信息。
- |: 这是Linux/Unix中的管道操作符,用于将前一个命令的输出作为后一个命令的输入。
- grep users: 这是grep命令,用于筛选包含"users"的行。
当你执行这个命令时,它会列出Elasticsearch中的索引信息,并筛选出包含"users"的索引。这对于检查包含特定关键词的索引非常有用,特别是在具有大量索引的Elasticsearch集群中。请确保你的Elasticsearch实例正常运行,并且能够通过localhost:9200地址访问。
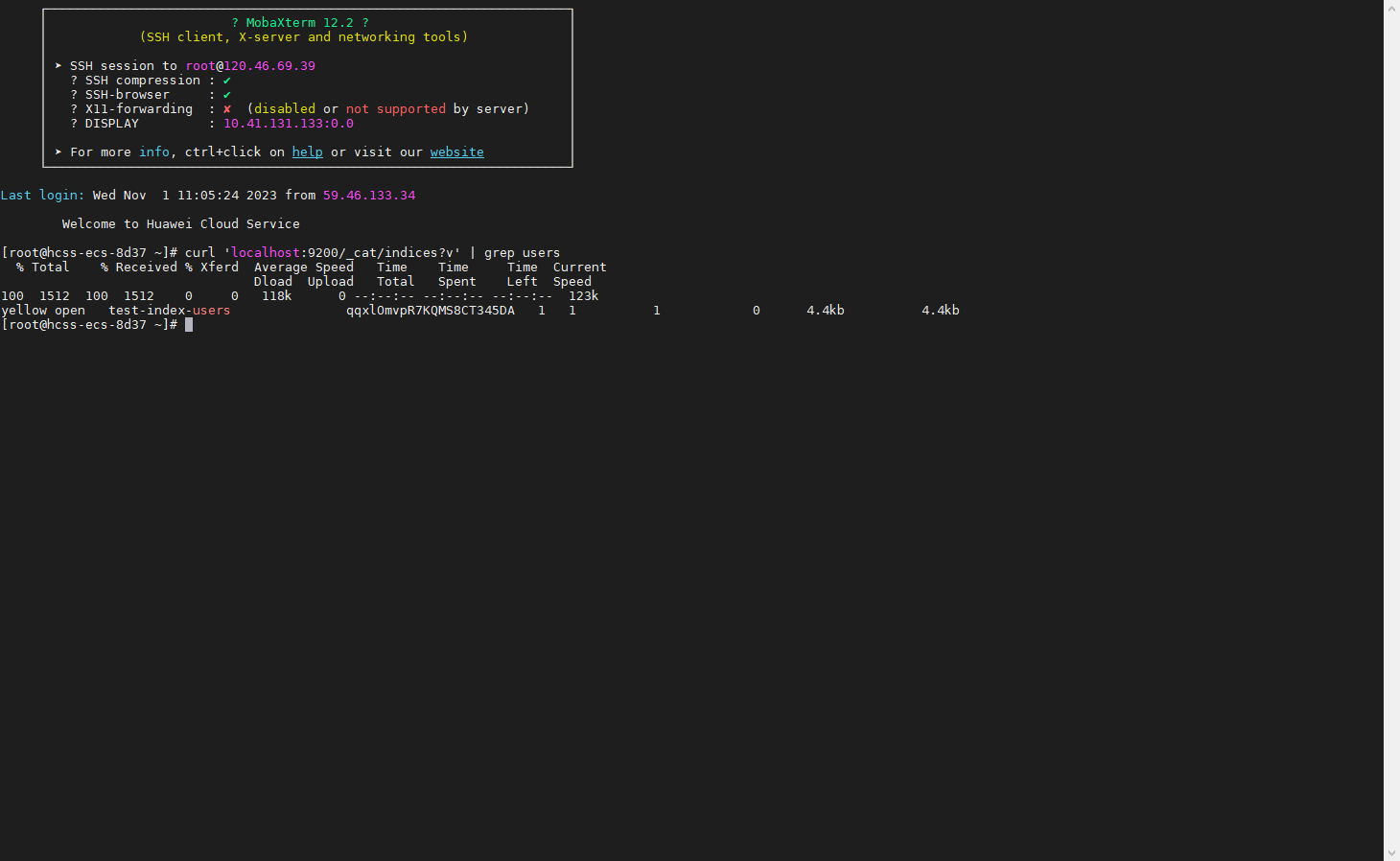
注意刚创建的索引的状态是yellow的,因为我测试的环境是单点环境,无法创建副本,但是在上述number_of_replicas配置中设置了副本数是1; 所以在这个时候我们需要修改索引的配置。
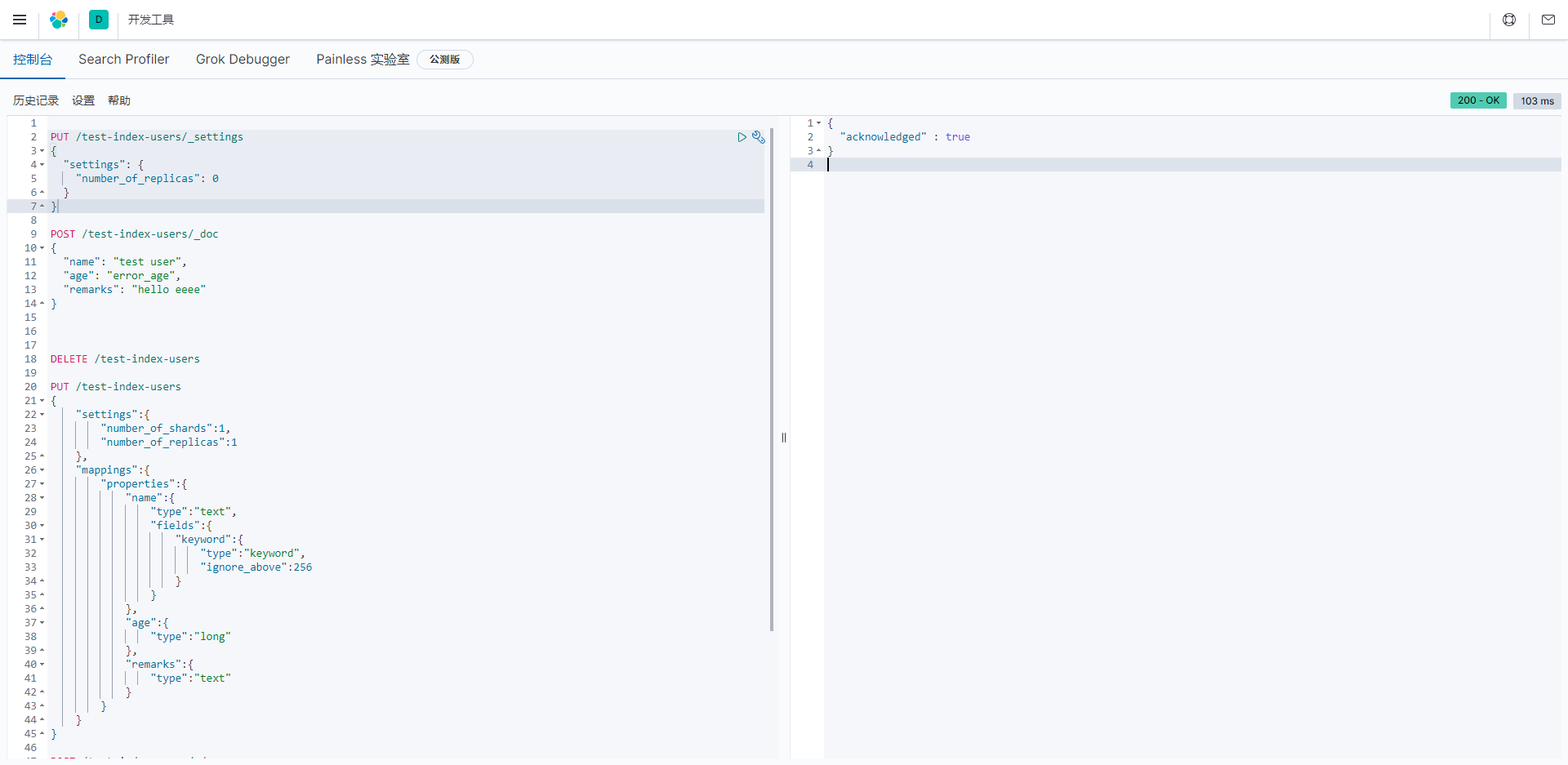
修改副本数量为0
javascript
PUT /test-index-users/_settings
{
"settings": {
"number_of_replicas": 0
}
}
再次查看状态
javascript
curl 'localhost:9200/_cat/indices?v'| grep users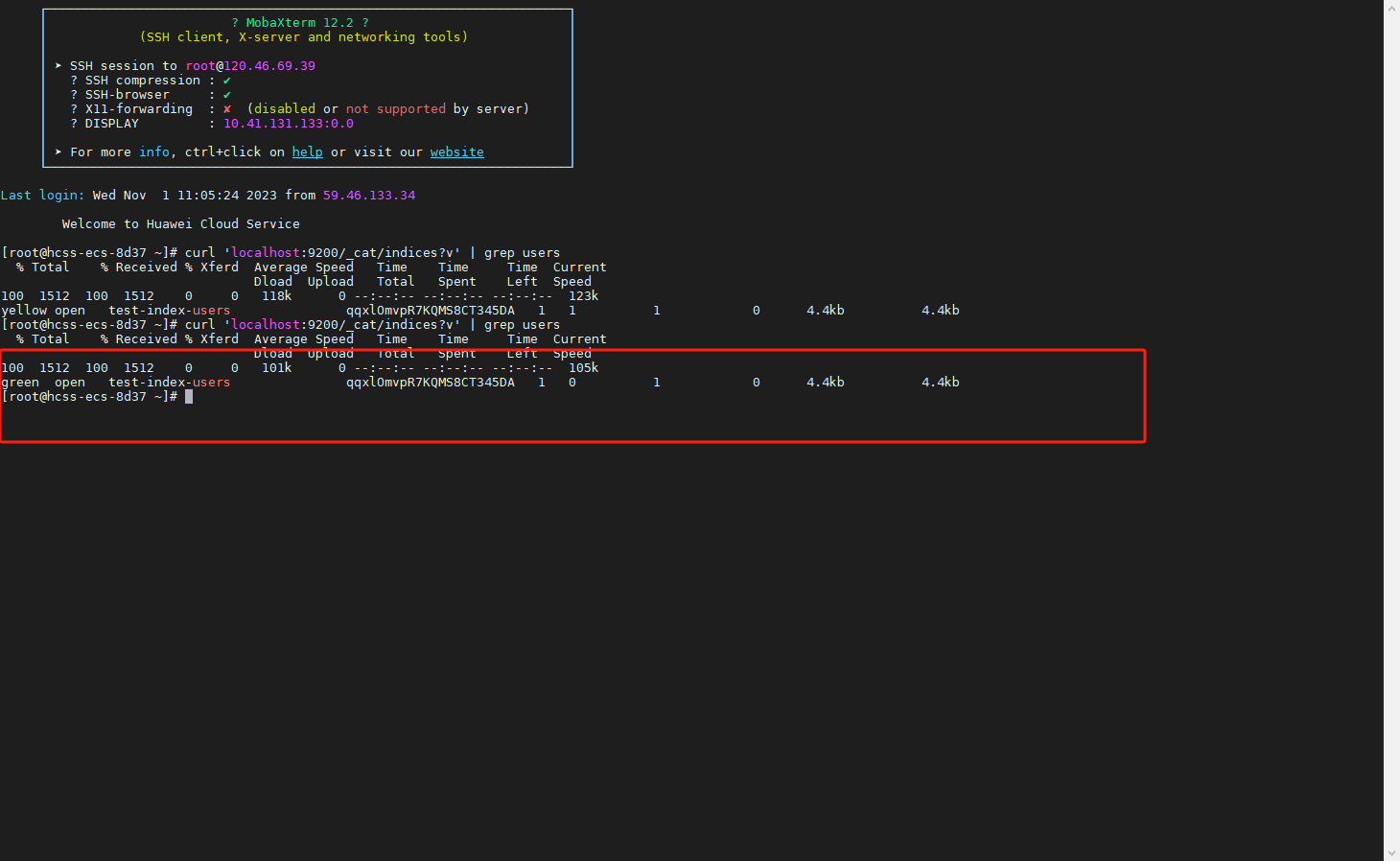
打开/关闭索引
关闭索引
javascript
POST /test-index-users/_close索引关闭操作将导致该索引不可用,文档无法查询,但数据仍然存在。
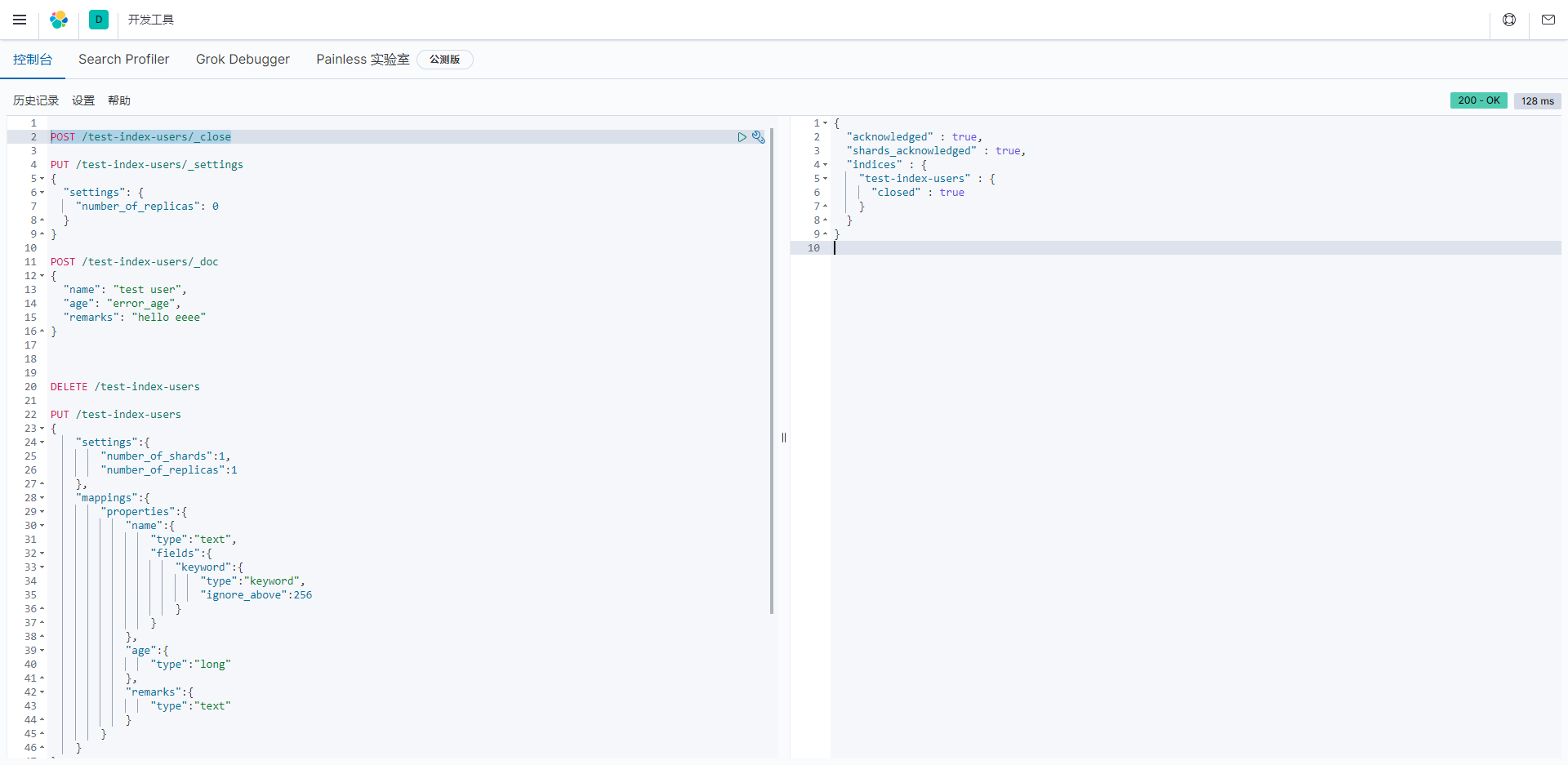
关闭以后再查询数据时
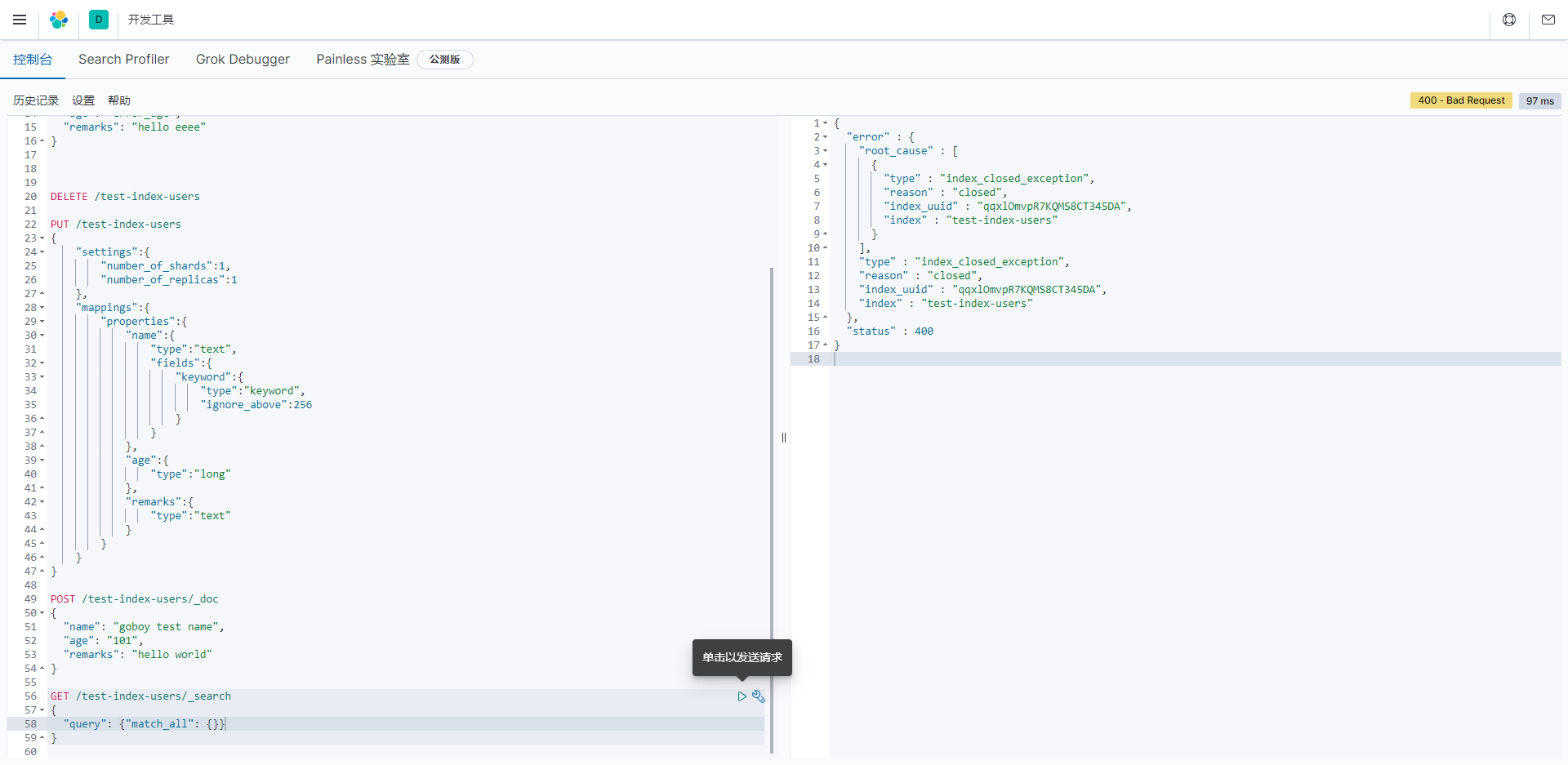
打开索引
javascript
POST /test-index-users/_open
打开后重新插入数据
javascript
POST /test-index-users/_doc
{
"name": "goboy22222 test name",
"age": "1001",
"remarks": "hello world,hello world"
}
查看索引
mapping
javascript
GET /test-index-users/_mapping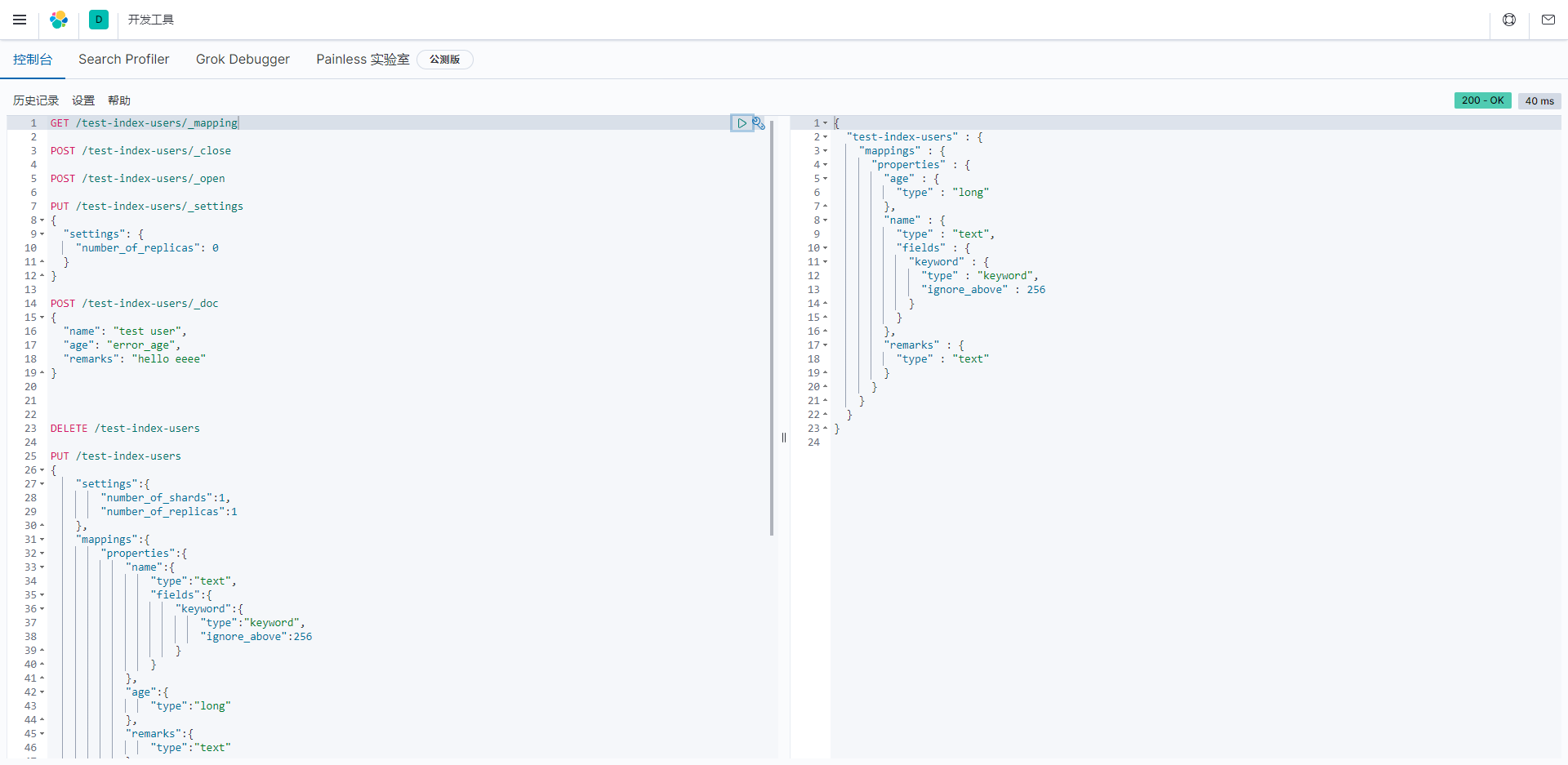
settings
javascript
GET /test-index-users/_settings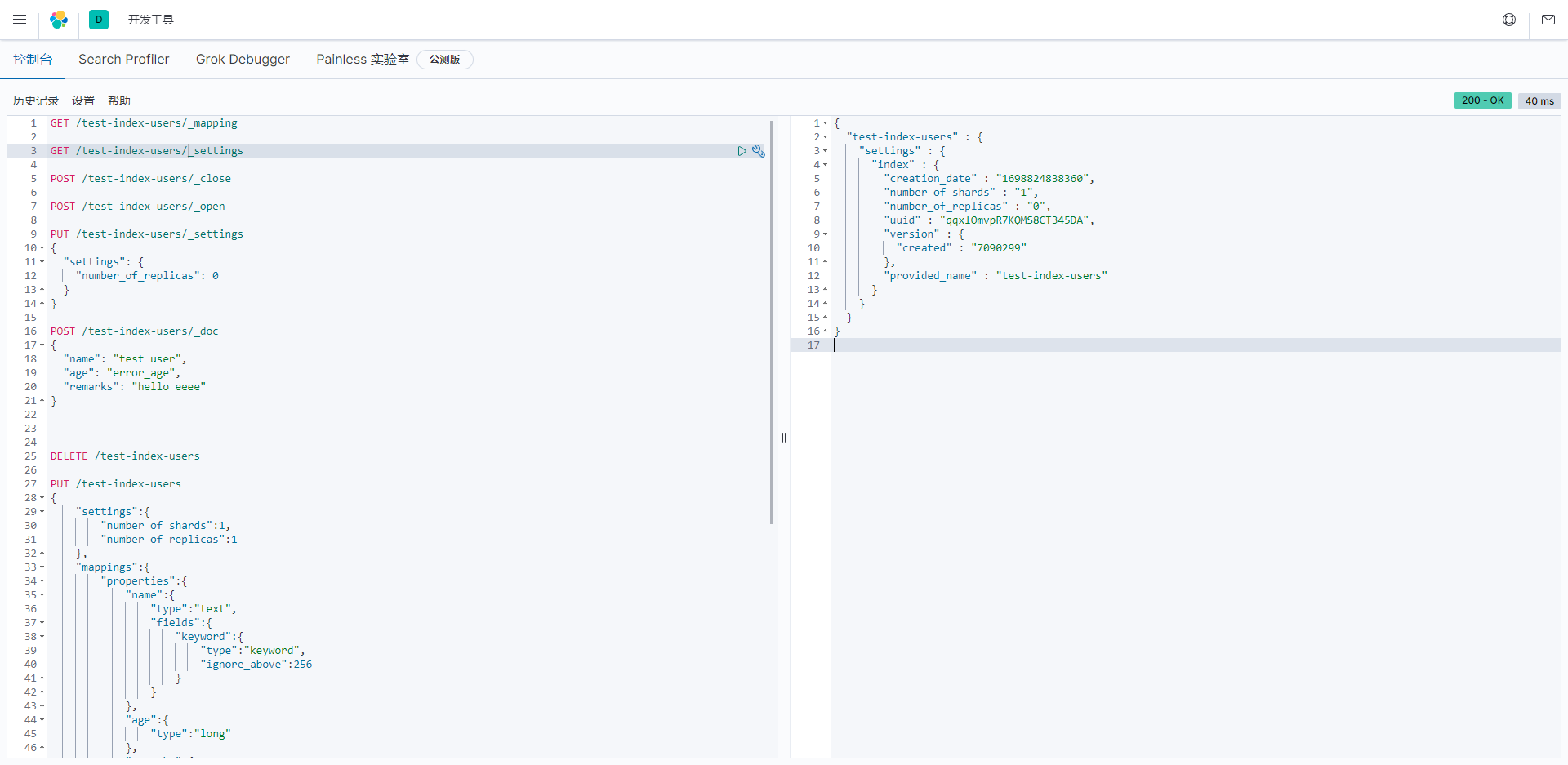
关于Elasticsearch索引"test-index-users"的配置信息示例,其中包含了索引的设置(settings)的详细信息。让我为你解释这个信息的各个部分:
"test-index-users": 这是索引的名称,指定了要配置的索引,名称为"test-index-users"。
"settings": 这是索引的设置部分,包含了关于索引的配置信息。
"index": 这是具体索引设置的部分,包括以下属性:
"creation_date": 这是索引的创建日期,表示为一个时间戳(以毫秒为单位)。在这里,创建日期是"1698824838360"。
"number_of_shards": 这是主分片的数量,指定为"1",表示该索引有一个主分片。
"number_of_replicas": 这是副本的数量,指定为"0",表示该索引没有副本。
"uuid": 这是索引的唯一标识符(UUID),用于唯一标识索引。UUID是"qqxlOmvpR7KQMS8CT345DA"。
"version": 这是有关索引版本的信息,包括索引的创建版本等。
"provided_name": 这是索引的提供名称,与索引的名称相同,为"test-index-users"。
这个信息提供了关于"test-index-users"索引的详细配置信息,包括创建日期、分片数量、副本数量、UUID等。这些配置属性对于管理和维护索引非常重要,可以影响索引的性能和行为。
删除索引
将创建的test-index-users删除。
javascript
DELETE /test-index-usersKibana管理索引
在Kibana可以查看和管理索引