写爬虫的步骤
浏览器打开要抓取的网站
- 推荐Chrome浏览器
- F12调出Chrome的开发者工具(DevTools)
查看源代码,是否包含想要的数据 - 包含,则通过requests库抓取网页,提取数据
- 不包含,则看下一步
检查ajax请求 - 寻找需要的数据
写爬虫的基本操作
1.抓取-->存储html(压缩),未来可能更改需求,所以可以压缩存储,节约时间
- 网页
- ajax
2.提取
3.存储
HTTP请求库
urllib.request # 官方库,但是没有requests好用
requests
r.text:str,chardet,headers->encoding
r.content:bytes cchardet.detect(r.content)
r.json
aiohttp # 异步io
cchardet编码 # 使用c++编写速度比使用python编写的chardet要快,并且对于中文识别更准确
重量级工具,会启动一个完整的浏览器加载数据,如果是一个复杂网页,比如有很多ajax请求,使用他就会很方便
selenium自动化测试工具
webdriver.Chrome()
chrome headless提取数据的库
re正则表达式
在解析HTML代码的时候,如果HTML代码不规范或者不完整,lxml解析器会自动修复或补全代码
lxml使用c语言实现比Beautiful Soup要快
lxml (Beautiful Soup)
xpath()爬虫进阶
- 用Chromel断点调试JavaScript
- 用Charles、Fiddle抓包分析
如何发现ajax加载URL
Chrome浏览器F12调出开发者工具
- Network
- Type:xhr
- Filter:XHR(Doc)
返回结果
- json,xml,html
例子 - https://translate.google.cn/
- https://fanyi.baidu.com/
瀑布流网页的抓取
表现是瀑布流,实现是ajax
- 网页滚动到底部,ajax加载下一页
- JavaScript渲染ajax获取的数据为网页
例子 - https://unsplash.com/
js解密
打开网页加载的js,因为js是脚本语言,不能编译所以源码都能看到,常见的加密
- 压缩、打包、混淆
- 晦涩难懂,pretty格式但变量、函数名难懂
找到js加密/解密算法的代码 - Charles抓包分析
- 例:https:/www.yuanrenxue.com/crawler/get-login-cookies-charles-weibo.html
- Chrome调试avaScript
对付JavaScript的万能钥匙
Python Selenium模块
-
Chrome有界面
-
Chrome Headless
Chrome的运行效率
-
没有requests等库快,但开发速度快
- 不用费劲理解javaScript代码
- 不用使用Python重写javaScript
-
针对单一复杂网站,建议Chrome
- 很难绕开该网站的IP、账号限流
-
对于多个普通网站,使用requests
- 这些网站几乎没有限制。
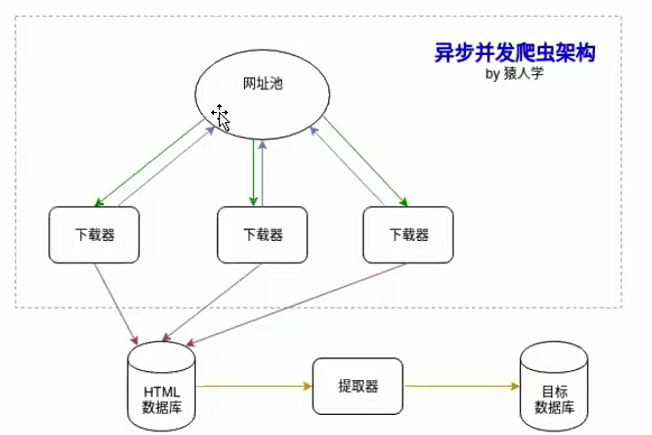
异步并发爬虫
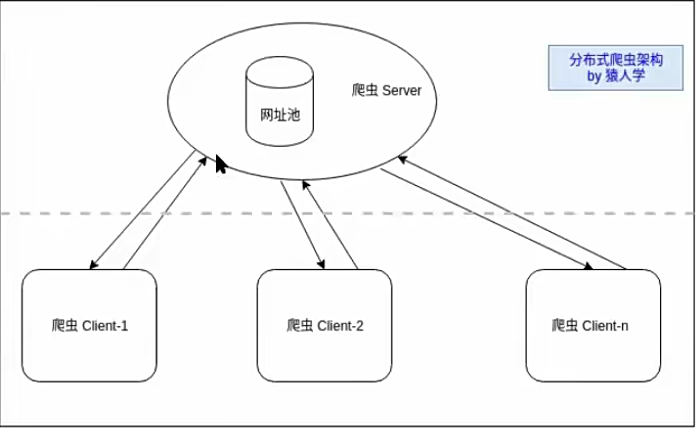
分布式爬虫