文章导读
CoEdge系统的构思基于边缘计算的发展,这一分布式计算范式将服务从云端推向网络边缘,以支持各种物联网应用,如智能交通和自动驾驶。随着通信技术的进步,出现了新的协作边缘系统,多个边缘节点可以通过本地点对点连接实现协作,而无需依赖强大的中心化互联网基础设施。这些系统在拓展性方面具有明显优势,适合广泛的地理部署,但也面临分布式工作负载处理、实时要求、异构环境兼容等挑战。CoEdge提出了一个分层的深度学习任务调度框架,通过任务调度与批处理机制来优化节点资源利用,此外,该系统还设计了GPU并行容器化,以解决任务隔离与GPU共享的难题。实验结果表明,CoEdge在大学校园中的智慧灯杆测试环境中显著降低了任务超时率。
1.研究背景和相关工作
在深度学习任务卸载方面,现有研究已开发了多种方法来缓解边缘设备在处理深度神经网络(DNN)任务时面临的资源限制问题。典型方案包括将计算密集型任务卸载到云端或其他边缘设备。例如,Neurosurgeon系统通过预测每层DNN模型的延迟和功耗,自动在层级粒度上划分任务,以实现高效的任务卸载。EdgeML采用强化学习算法,根据实时通信带宽的动态变化来自动调整任务分区点,从而优化卸载效率。此外,ENGINE系统采用贪心策略,通过决定哪些任务本地执行、哪些任务发送至云端来最小化能耗。然而,这些方法主要面向单一客户端与服务器间的通信,缺乏对多节点分布式深度学习任务的支持,因此无法在多节点之间实现协同优化。针对边缘设备之间的工作负载平衡,有研究提出了多种优化方法。例如,某些研究通过建立整数线性规划模型,优化用户请求在边缘-云架构下的整体响应时间,并将边缘设备的数据全部卸载至云端。然而,这种方法会导致边缘到云端通信延迟较高,无法充分利用边缘设备的计算资源。Dedas系统提出了一种在线的任务调度和任务分派机制,在边缘设备无法满足任务的实时需求时将任务卸载到云端,假设部署有资源丰富的服务器以接近数据源和终端设备。然而,在协作边缘系统中,由于边缘节点无法始终依赖资源丰富的服务器,并且云卸载可能会导致隐私泄露,因此该方法的适用性有限。对于在边缘设备上并发执行深度学习任务的研究,已有一些工作重点关注实时性能优化。DART系统通过基于流水线的数据并行架构,提升了实时DNN推理请求的响应效率。RT-mDL则通过联合模型缩放和调度策略,优化了边缘平台上多种实时/准确性需求下的DNN任务执行效率。BlastNet提出了跨处理器的动态调度方案,使DNN模型推理在异构CPU-GPU平台上实现高效推理。然而,这些方法的侧重点在于单一边缘设备上的实时并发任务优化,未考虑其他边缘节点协同推理的需求。此外,当前研究未能有效解决在共享边缘平台上部署多个DNN模型时的兼容性问题。多个任务的前/后处理可能需要不同版本的依赖包,如NumPy、SciPy等,因此典型做法是将DL任务分别封装在不同容器中。然而,这种容器化技术在边缘平台上的直接应用存在限制,尤其是多个容器无法同时访问同一边缘设备的GPU资源。最近的一项研究将容器划分为一个共享容器和多个独立容器,以支持多边缘应用的容器化,但该方法并不适用于GPU加速平台上的并发DL任务。
2.成果概述
CoEdge 系统适用于多个分布式实时应用场景,包括智能交通基础设施、自动驾驶、智能港口和工厂等数据密集型任务。例如,在智能道路基础设施中,CoEdge 系统通过多个配备了传感器的智能灯杆进行协作,实现实时的交通监控和基础设施支持的自动驾驶。每个灯杆通常配备热成像相机、毫米波雷达和 LiDAR 等多种传感器,但这些边缘节点的计算和功率受限,使得在不进行重大升级的情况下,仅能提供数十瓦的固定电源供给,这在大规模边缘系统中尤为常见。此类智能灯杆应用要求分布式协作,以在有限的资源条件下满足实时深度学习任务的执行需求。
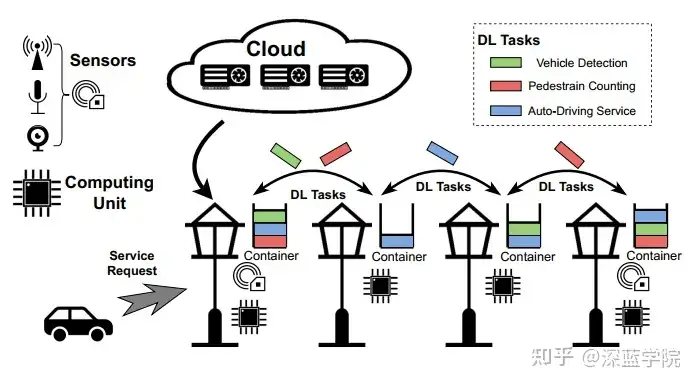 图1:基于路边基础设施的分布式实时任务场景
图1:基于路边基础设施的分布式实时任务场景
具体来说有如下要求:
- 实时与并发 DNN 执行
在智能灯杆的支持下,许多应用需要严格的时间约束,例如车辆跟踪要求在数秒内完成检测和通信。而在自动驾驶中,灯杆节点可能需要实时处理传感器数据并将结果发送至车辆。此外,由于灯杆通常作为共享基础设施,单个节点可能需要同时运行多个深度神经网络模型来执行不同任务。有限的设备资源和严格的实时需求构成了设计协作边缘系统的主要挑战。
- 地理分布的异构工作负载
由于传感器和路况的差异性,不同灯杆的服务和工作负载分布往往不均衡。热成像相机、毫米波雷达和 LiDAR 的传感范围差异较大,从 10 米到 500 米不等,导致传感器的部署方式会因道路和交通情况以及预算而变化。不同的节点在数据和计算负载方面呈现高度动态性,进一步增加了边缘节点协同计算的复杂性。
- 多样化的开发和运行环境
作为共享基础设施,智能灯杆需要支持由不同服务提供商在不同软件/硬件环境中开发的多种应用。例如,某些节点可能同时支持安全监控、车辆监控、跟踪和自动驾驶等不同任务。传统的虚拟化技术如容器已被广泛应用于边缘系统中,但现有的容器技术无法同时支持边缘 GPU 上的并发 DNN 执行。这种限制使得在同一 GPU 上并行运行多任务变得困难,因此 CoEdge 提出了专门的容器化技术来解决这一问题。
3.系统设计
3.1 CoEdge概述
CoEdge 是一种协作边缘系统,旨在支持分布式实时深度学习(DL)任务在多个边缘节点之间的高效执行。系统架构由全局任务调度器、本地批量实时深度神经网络(DNN)执行机制和 GPU 感知的并发 DL 容器化组成。此设计提供了一个分层的任务调度框架,以便在多个边缘设备之间协同处理复杂的 DL 任务。
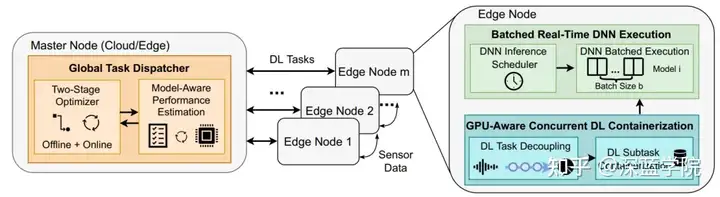 图2:CoEdge系统结构
图2:CoEdge系统结构
在每个边缘节点上,CoEdge 提供了一个批处理机制,将使用相同模型的任务合并在一起进行批量推理,以提高 GPU 的利用效率。这种批处理模式能够在不影响实时性能的前提下优化资源使用率。系统在离线阶段会对不同批量大小下的推理时间进行预估,从而在在线阶段根据实时需求动态调整批次大小。
CoEdge 设计了一种独特的容器化技术,以支持多个任务在隔离环境下共享同一个 GPU。系统将每个任务拆分为 CPU 上的预处理和后处理,以及 GPU 上的 DNN 推理部分。预处理和后处理被分别封装在独立的容器中,而所有 DNN 推理任务则共享一个 GPU 容器。这种设计解决了容器间软件依赖不兼容的问题,并最大限度地利用了异构计算资源。
3.2 分层深度学习任务调度
CoEdge的分层DL任务调度框架旨在优化跨边缘节点的实时分布式DL任务执行。为了解决由于传感器分布不均、地理位置分散及单一边缘节点计算资源不足带来的负载不平衡问题,CoEdge设计了一个由主节点任务分配器和边缘节点本地调度器组成的系统架构。
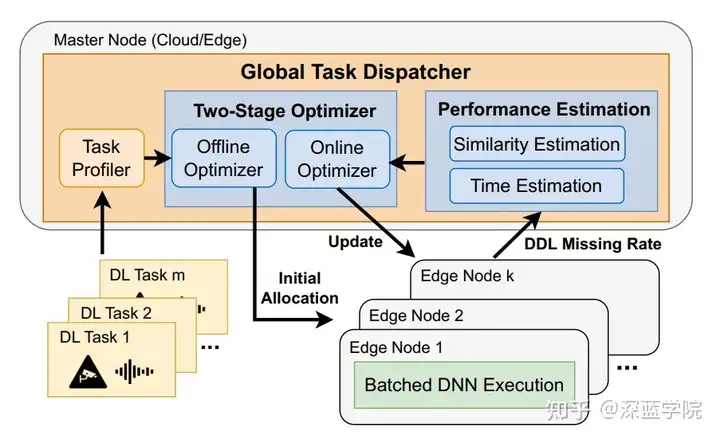 图3:分层DL任务调度流程
图3:分层DL任务调度流程
区别于传统的分布式任务调度通常只在节点之间均衡负载,CoEdge的分层DL任务调度不仅考虑节点间负载的平衡,还重点关注每个节点的实际执行效率。其架构包含两部分:主节点上的全局任务分配器和分配在多个边缘节点上的批量DNN执行器。全局任务分配器负责将DL任务分配给边缘节点,并根据各节点的实时性能估计动态优化分配策略。任务分配器不仅要保证任务在节点间的合理分布,还要充分利用节点的批量执行功能以提升GPU资源利用率。同时,各个边缘节点采用批量实时DNN执行机制,边缘节点不仅监控分配任务的实时性能,还与主节点通信以便优化运行时的分配策略。主节点任务分配器通过以下两个步骤来管理不同边缘设备上的分布式DL任务:
- 双阶段优化器:全局任务分配器的核心是双阶段优化器。首先,离线阶段基于任务执行时间的历史数据来生成初始分配方案。在线阶段则在任务实际执行时根据运行时数据进行动态调整,以满足实时需求。这样,分配器可以在负载动态变化的情况下实现最优任务分配 。
- 基于相似性的批量执行策略:分配器会根据任务的模型相似性(使用余弦相似度)来分配DL任务,以便在每个边缘节点上更高效地进行批处理。例如,多个使用同一DNN模型的任务会被集中分配到一个节点,避免模型的重复加载和推理初始化开销。这种分配方法能够有效提高GPU的空间利用率。
在分布式DL任务执行中,通信延迟可能会影响整体性能。CoEdge系统通过测量带宽并计算通信延迟来应对这种挑战,并根据网络带宽的变化动态调整任务分配,以减少因延迟而错过任务截止时间的情况 。
3.3 批量DNN执行策略
在CoEdge系统中,批量DNN执行机制通过增加GPU空间利用率来提升各个边缘节点上的实时DNN推理任务性能。此设计基于观察到同一模型的批处理推理能够显著减少每次推理的平均时间。因此,CoEdge系统将使用相同DNN模型的任务整合在一起进行批量推理,以减少重复的模型加载和初始化时间。例如,如果多个任务使用YOLO模型,则将这些任务的数据合并,并一同送入模型进行推理。这种方法减少了资源消耗,提升了每个模型推理的整体效率。然而,批量大小越大,虽然可以提升GPU的使用率,但会导致每次推理所需时间增加,可能导致任务错过截止时间。
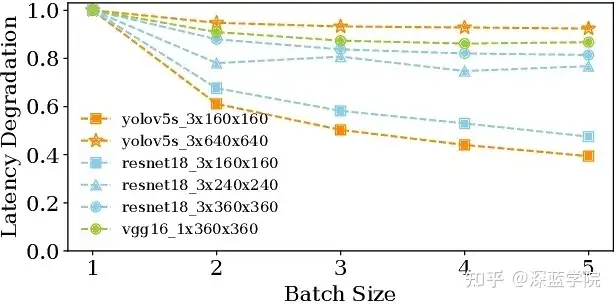 图4:通过批处理提高效率
图4:通过批处理提高效率
CoEdge系统中包含一个DNN推理调度器,它控制不同模型推理的执行顺序和批量大小,以满足任务的实时性要求。调度器首先依据各任务的紧迫性选择待执行的模型推理队列中的任务。每个任务在分配到模型队列时,会被计算出最低的截止时间,然后调度器选择距离截止时间最近的任务来优先执行。
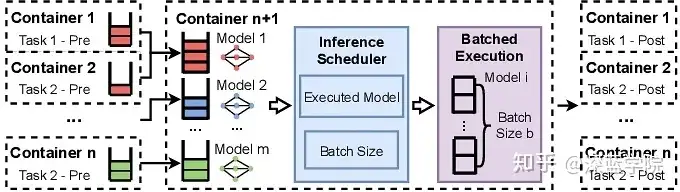 图5:单个节点上批量DNN任务的执行
图5:单个节点上批量DNN任务的执行
此外,CoEdge系统对每种DNN模型在不同批量设置下的推理时间进行了离线分析,并在运行时动态确定适合的批量大小。调度器会在线上选择能够满足所有任务实时性需求的最大批量大小。对于每个模型的推理任务,调度器会比较任务的当前时间和推理执行时间,以确保任务能在截止时间内完成推理。例如,YOLO模型在批量大小为3时,推理时间缩短一倍,这种动态调整帮助CoEdge在不牺牲实时性前提下提升了GPU资源的利用率 。
3.4 GPU容器化
CoEdge设计了一种GPU感知的并发DL容器化机制,以支持在同一GPU上高效、隔离地并行执行多个深度学习(DL)任务。这种方法旨在解决边缘节点上不同DL任务间的兼容性和资源利用问题,因为当前低功耗边缘设备通常仅配备一个GPU且不支持GPU虚拟化。传统上,边缘设备上并行执行多个DL任务会面临两个主要问题:首先是不同DL任务可能使用不同的框架版本(如PyTorch或NumPy),而在同一容器中运行多个DL任务可能导致依赖冲突。例如,某些任务依赖NumPy的1.14版本,而另一些任务则要求低于1.23的NumPy版本,导致难以在同一环境中兼容多个DL任务。其次,如果将所有任务封装在单一容器中,并将容器绑定到GPU上,可能造成资源浪费,并难以实现任务间的独立执行。因此,多任务只能顺序执行,从而限制了资源利用效率。为解决上述问题,CoEdge采用了以下容器化设计:
任务分解与容器化:每个DL任务被分解为三个部分:CPU上的预处理、GPU上的DNN推理和CPU上的后处理。预处理和后处理被分别封装在独立的容器中,而所有DNN推理任务则共享一个GPU绑定的容器。这种设计确保了不同任务间的隔离,同时优化了GPU资源的利用率。
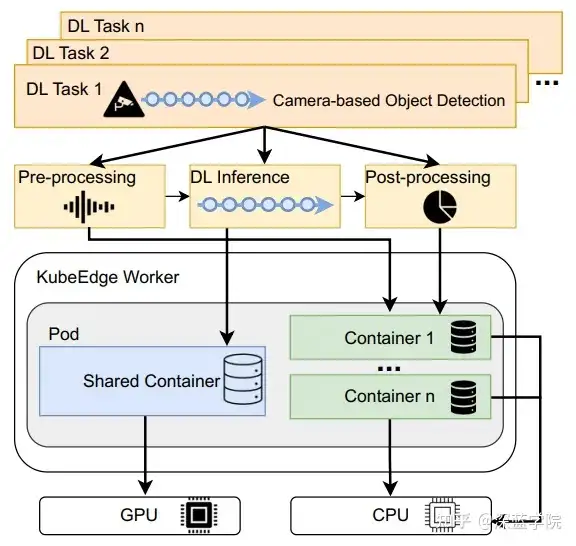 图6:GPU共享与内存隔离
图6:GPU共享与内存隔离
ONNX格式转换:为避免软件依赖冲突,CoEdge将所有DNN模型转换为Open Neural Network Exchange(ONNX)格式。ONNX是一个通用模型格式,使得不同DL任务可以在相同的GPU容器中运行,进一步简化了环境依赖管理。
共享内存机制:不同容器间的数据传输通过共享内存实现,减少了通信延迟。具体而言,CoEdge通过传递共享内存地址来避免数据的多次复制,从而显著提高了跨容器通信的效率。
 图7:GPU批处理
图7:GPU批处理
4.系统实现和分析
4.1 系统实现
CoEdge 的实现基于 KubeEdge、ROS2 和 TensorRT,旨在支持分布式、实时的深度学习任务。CoEdge 系统的核心构建在 KubeEdge 上,这是一种轻量化的边缘计算平台,用于管理边缘节点上的容器化应用。CoEdge 利用 ROS2 来管理多种异构数据源,特别适用于处理边缘节点上的多种传感器数据。每个边缘节点运行一个 ROS2 容器来读取传感器数据。为了加速边缘设备上的深度神经网络(DNN)推理,CoEdge 将所有模型转换为 TensorRT 格式。这一格式由 NVIDIA 提供,专门用于边缘平台的 DNN 加速。此外,模型被进一步转换为 ONNX 格式,以便在不同容器中兼容运行,确保模型的高效利用。
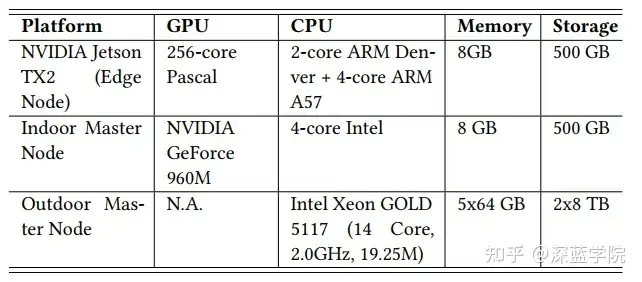 表1:系统资源
表1:系统资源
4.2 实验平台构建
CoEdge在大学校园中部署在由12个智能路灯节点组成的户外测试平台上。
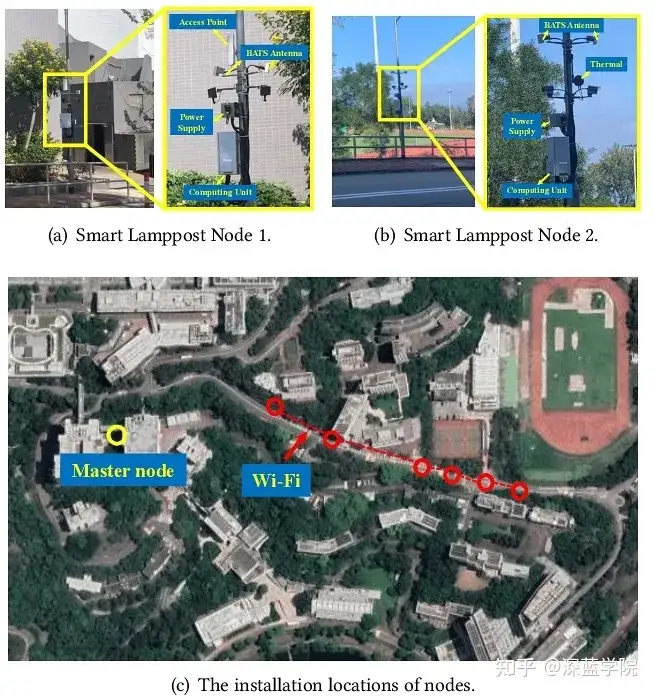 图8:实验平台
图8:实验平台
每个路灯节点都配备了NVIDIA Jetson TX2计算板,以MIC-720-AI防水外壳封装,并附加了450 GB的SSD存储。节点间的通信通过多跳无线网络实现,平均带宽为80 Mbps。主节点与各路灯节点的连接则通过4G蜂窝网络进行。在实验室环境中,为了模拟控制网络带宽的情况,使用3个NVIDIA Jetson TX2计算板作为边缘节点,并将所有节点连接至PoE交换机以设置网络带宽。主节点由配备Intel 4核CPU和NVIDIA GeForce 960M GPU的笔记本电脑组成。CoEdge测试了四个DL任务,包括不同传感器与三种DNN模型的组合。使用YOLOv5s、ResNet 18和VGG19进行图像分类和对象检测任务,并将所有模型转换为ONNX格式并通过TensorRT加速。
4.3 评估指标
评估使用以下两项主要指标:
- 截止时间未达成率(Deadline Missing Rate):用于衡量实时任务的完成情况,即在指定时间段内未达成截止时间的任务比例。该指标帮助量化CoEdge在分布式DL任务中的实时性能。
- 端到端延迟(End-to-End Latency):指任务从启动到完成的总延迟,包括边缘节点间通信时间、预处理/后处理时间、DNN推理时间等。
4.4 测试结果
CoEdge在校园内的智能路灯平台上进行测试,任务包括实时交通监控、行人识别和车辆识别。实验结果表明,在任务优先级排序中(交通监控、行人识别、车辆识别),CoEdge在车辆通过检测区域前完成了实时检测,减少了存储和计算负担。
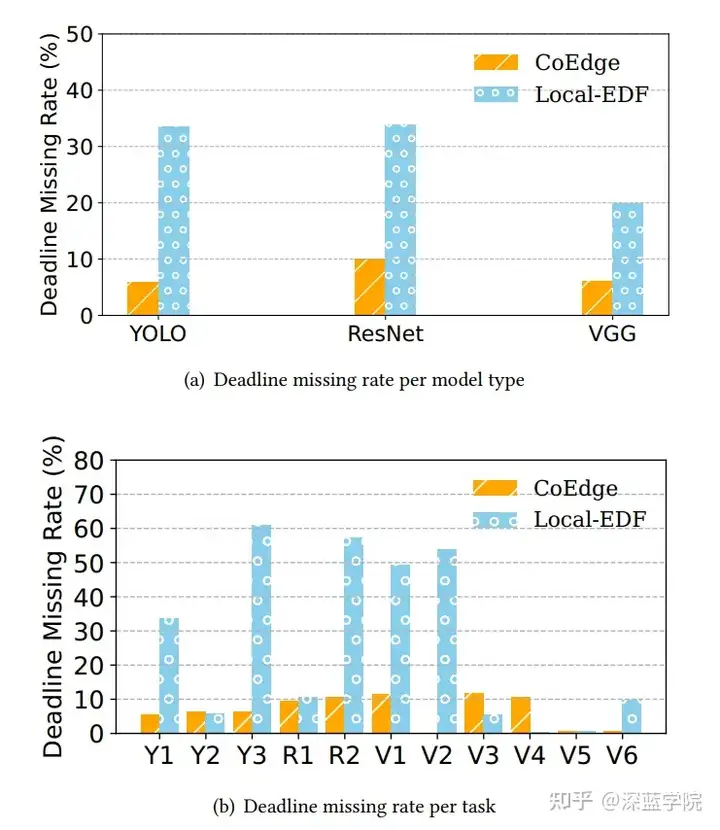 图9:截止时间未达成率
图9:截止时间未达成率
 图10:端到端延迟
图10:端到端延迟
4.5 网络带宽对系统的影响
在室内测试中,通过在100 Mbps和1,000 Mbps的不同带宽下测试CoEdge的性能,结果表明,在较低带宽条件下,CoEdge的任务丢失率低于无任务卸载和简单全局分配两种基线方法。该结果表明,CoEdge即使在带宽限制下,仍能够优化任务分配策略,从而在网络波动环境中提高任务完成。
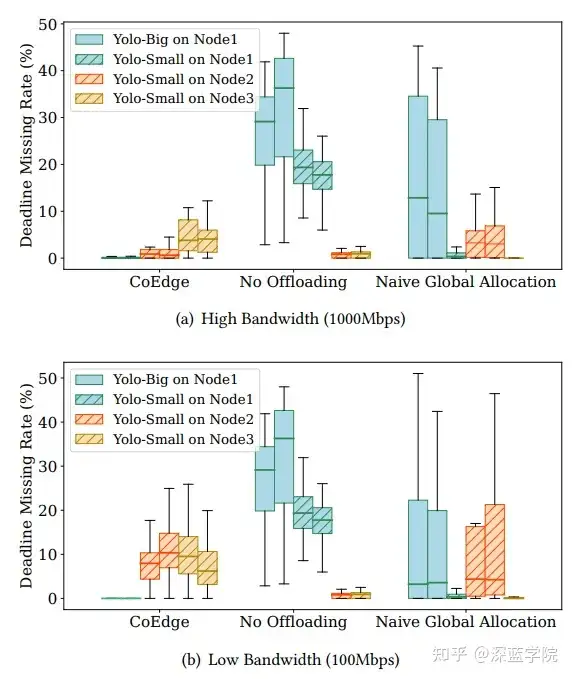 图11:不同网络带宽下CoEdge的实时性能
图11:不同网络带宽下CoEdge的实时性能
4.6 批量DNN执行的性能
在低负载和高负载条件下,分别使用ResNet和YOLO模型测试批量DNN执行性能。结果表明,与固定优先级和最早截止时间优先(EDF)两种基线方法相比,CoEdge在低负载条件下实现了0%的截止时间未达成率,而高负载条件下的任务完成率也优于基线方法。CoEdge通过有效的批量执行和优先级调整,显著降低了任务的截止时间未达成率。
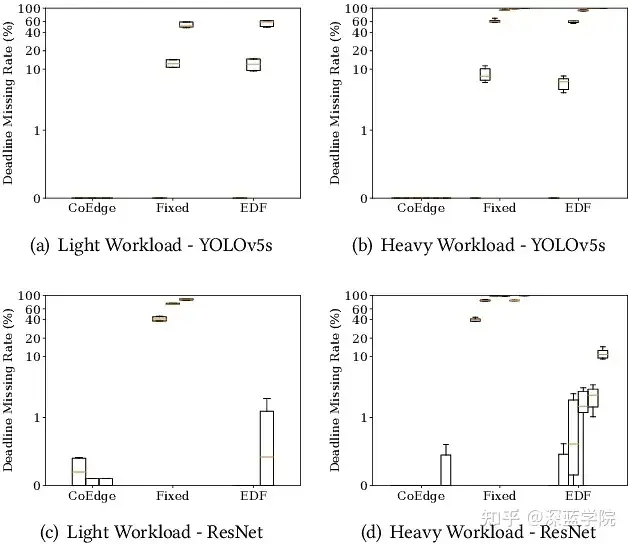 图12:不同DNN工作负载下批量DNN执行的实时性能
图12:不同DNN工作负载下批量DNN执行的实时性能
4.7 容器化开销
CoEdge的GPU感知并发DL容器化机制通过隔离不同任务的运行环境,实现了DL任务的并发执行。实验结果表明,尽管容器化带来了额外的通信开销,但与单一容器的实现相比,CoEdge在执行多个DL任务时的额外延迟极小,仅增加了8.45毫秒。这表明CoEdge实现了高效的并发DL任务处理,并在保持任务隔离的同时优化了GPU资源的利用。
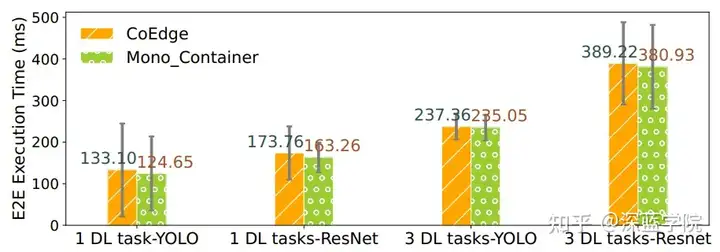 图13:容器化开销成本
图13:容器化开销成本
5.讨论和分析
虽然CoEdge的评估是在智慧城市场景中进行的,系统的协作多边缘架构也可以应用于其他智能场景。CoEdge能够支持智能建筑、工厂、港口等场景中的边缘计算需求。例如,在智能港口场景中,各类边缘节点(如智能设备、起重机、卡车等)配备了摄像头、激光雷达等多种传感器。这些节点可以协同执行任务,例如自动识别路面卡车和运动追踪。在这种场景中,CoEdge的全局任务分配器可以将深度学习(DL)任务分配给每个设备节点,同时通过本地调度器支持每个节点上的高效并发DL任务执行。CoEdge可以与现有的边缘云卸载方案集成,通过将部分DL工作负载(例如部分模型层)卸载至云端,以减轻边缘节点的计算负担。然而,传统卸载方法可能导致边缘节点上资源竞争问题,因为剩余的部分推理工作仍需在边缘进行。在此情况下,可以采用模型共享的批处理方式来减少工作负载。然而,由于任务的卸载策略不同,处理时间可能会有所差异,因此在本地调度时需要考虑卸载策略,以准确估算批处理时间。虽然CoEdge的测试平台仅包含六个节点,但系统的设计能够扩展到更大规模的应用场景。由于每个节点主要处理来自附近传感器的数据,通常只需与相邻节点协同即可,而无需依赖系统的整体规模。即使模型种类和任务数量增加,CoEdge的本地调度器和全局任务分配器仍能在算法复杂度为 O(n)的情况下高效运行(其中 nnn 为任务数量或模型种类数量),从而适应更大规模应用的需求。CoEdge 的成功表明,该系统能够为需要实时、高效的数据密集型应用提供支持,为未来的智能城市及其他应用场景的边缘计算提供了新的可能性。
Ref:
CoEdge: A Cooperative Edge System for Distributed Real-Time Deep Learning Tasks
编译|小乔
审核|fafa
第二届线下自主机器人研讨会(ARTS)即将召开👇
第二届ARTS报名入口即详情须知
第二届ARTS奖学金通知
ARTS 2024 学术辩论通知抢"鲜"发布