Selenium本来是一个自动测试工具,用于模拟用户对网站进行操作。在爬虫领域也有其用处。
一、下载安装Selenium及附属插件
pip install Selenium安装完成后还需要安装一个浏览器驱动,来让python能启动浏览器。
如果是Edge或者其他基于Chromium的浏览器(如下面的百分浏览器),我们先查看Chromium版本号:
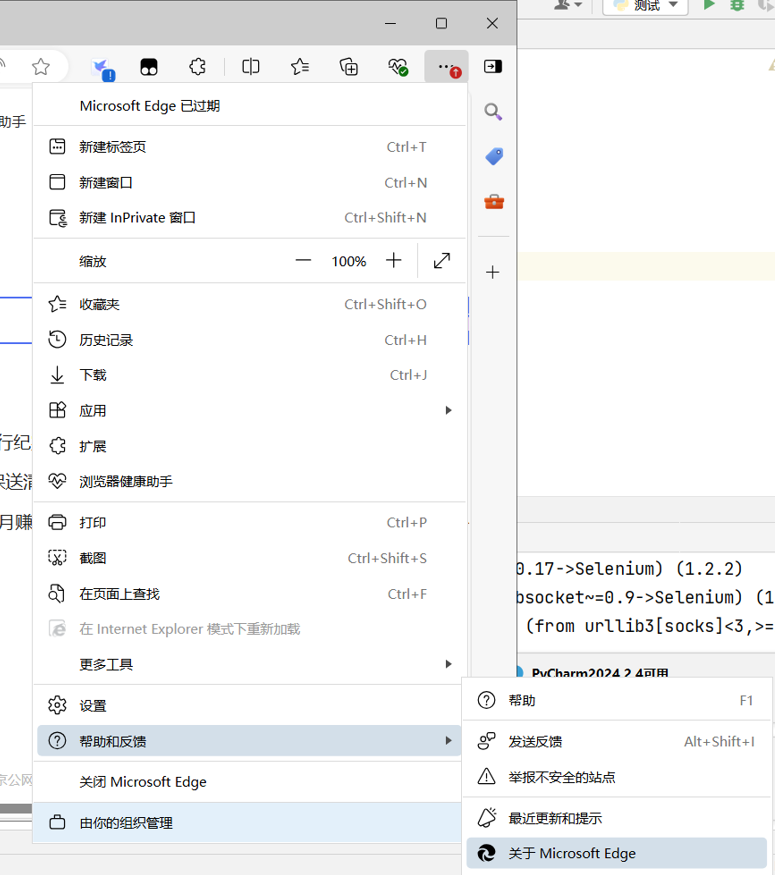
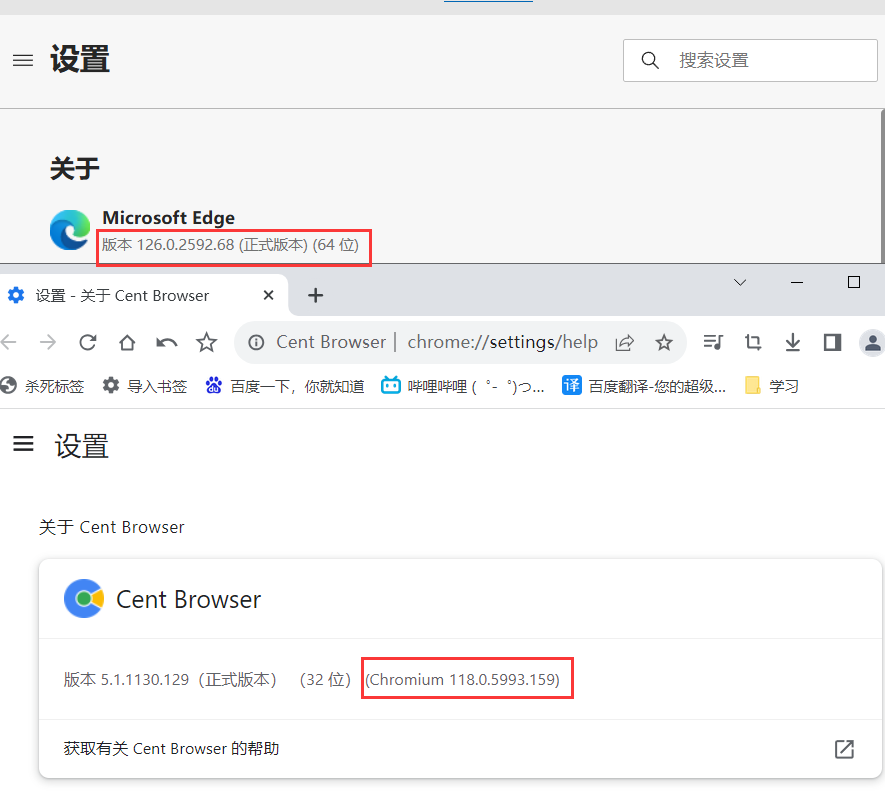
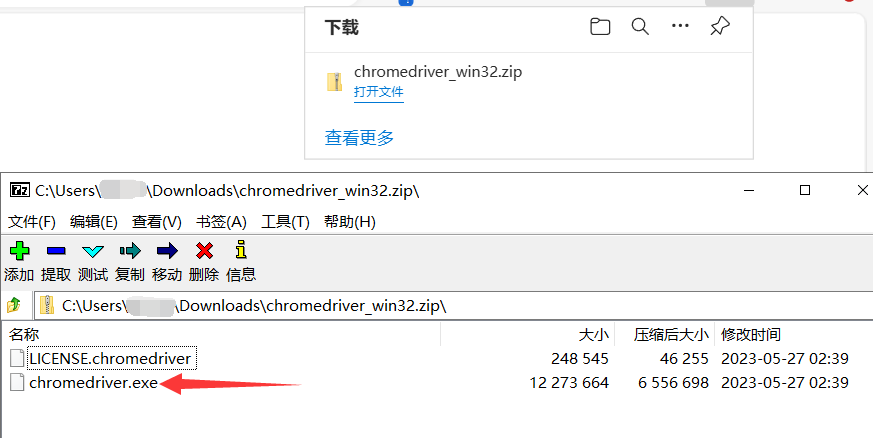
这里以Edge为例,版本为126.0.2592.68,进入下面的网址,咱们就选最后一个,win版本,解压之后的exe文件就是我们需要的东西,你可以把它放在python解释器目录,项目目录或者其他你找得到的地方。
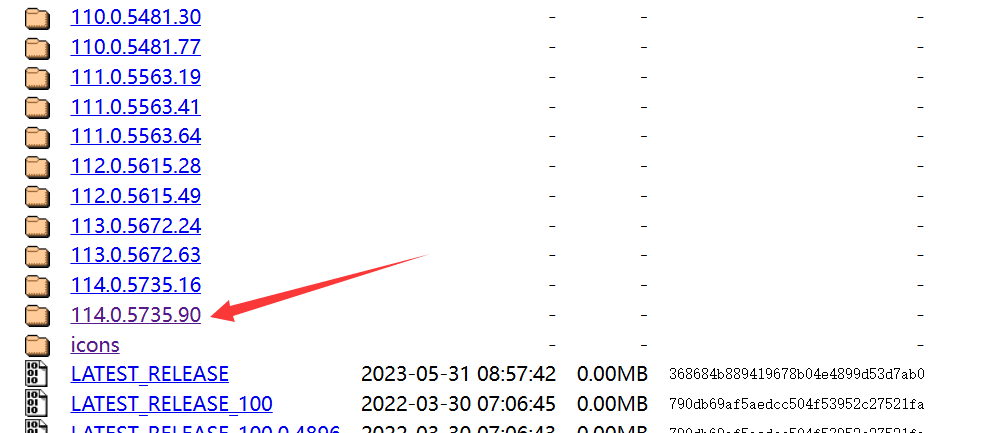
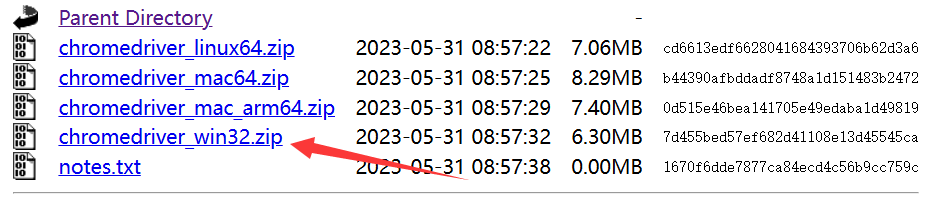
二、selenium的使用
(一)、第一个程序
先来试试第一个程序,它会使用edge打开百度(第一打开时间可能有点长(10s?),并且打开后不久就会自动关闭)然后输出抬头的数据:
python
import time
from selenium.webdriver import Edge # Edge 可以换成 Chrome/Firefox(火狐)/Ie/BlackBerry······
url = 'http://www.baidu.com'
web = Edge()
web.get(url)
print(web.title)
time.sleep(50)(二)、以站酷为例
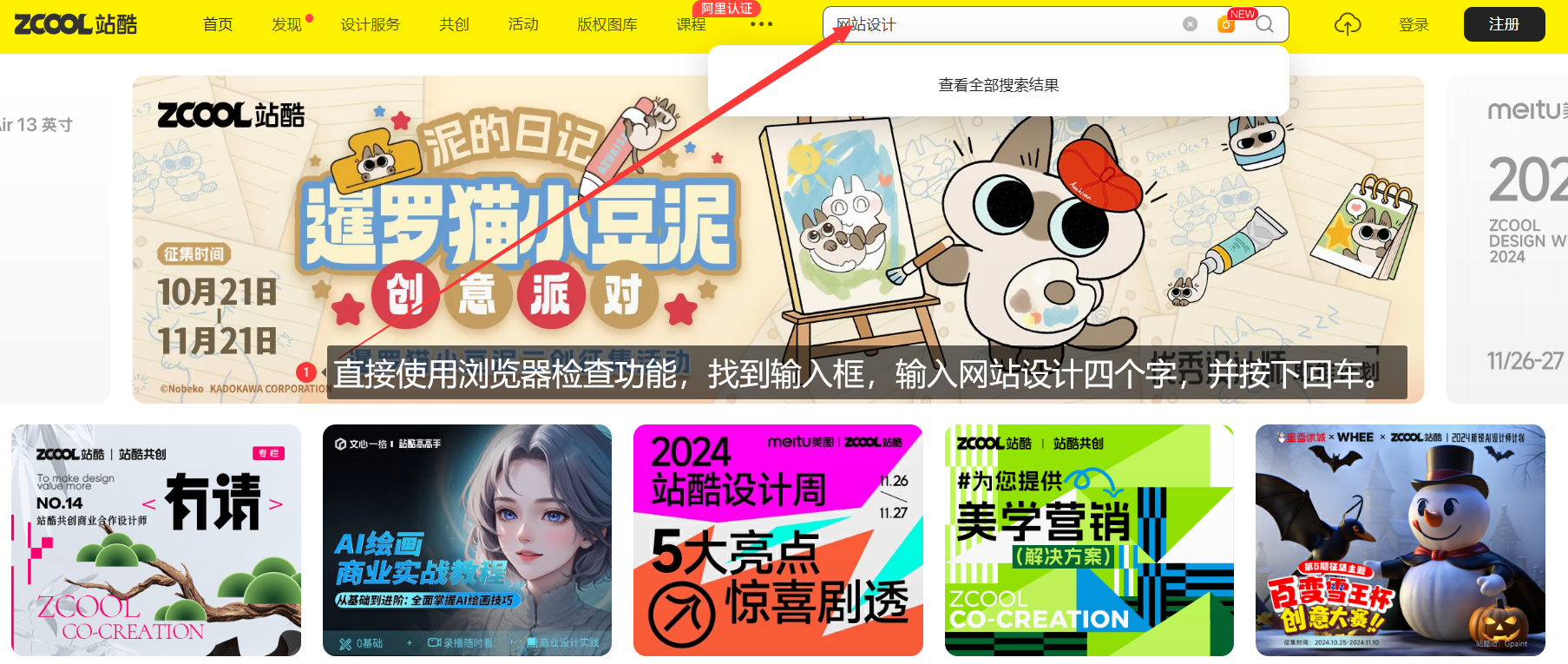
接下来,我们尝试模拟一下从站酷ZCOOL-设计师互动平台-打开站酷,发现更好的设计!中搜索"网站设计",并打开第一个和第二个文章的全过程
在selenium中,我们所有操作,看到的都是已经经过js处理过的页面,也就是说,他是所见即所得。以站酷为例,站酷首页的文章都是二次请求得到的,源代码中没有,用以下代码就能清楚看到。会输出True False,如果不是的话,尝试更改文章名或者延长time.sleep时间,以保证网站完全加载。
python
import time
import requests
from selenium.webdriver import Edge # Edge 可以换成 Chrome/Firefox(火狐)/Ie/BlackBerry······
headers = {
# 用户代理,某些网站验证用户代理,微微改一下,如果提示要验证码之类的,使用它
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome"
"/118.0.0.0 Safari/537.36",
}
url = 'https://www.zcool.com.cn/'
web = Edge()
web.get(url)
# print(web.page_source)
time.sleep(8)
print('字体合集' in web.page_source) # 字体合集是一个文章名
with requests.get(url=url, headers=headers) as resp:
resp.encoding = "utf-8" # 当页面乱码改这里
# print(resp.text)
print('字体合集' in resp.text)# 字体合集是一个文章名需要模拟的行为流程
 模拟代码
模拟代码
通过以下代码即可获取所需内容:通常来说,人怎么想,就怎么用selenium访问页面。
python
import time
from selenium.webdriver import Edge # Edge 可以换成 Chrome/Firefox(火狐)/Ie/BlackBerry······
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
url = 'https://www.zcool.com.cn/'
web = Edge()
web.get(url)
time.sleep(3) # 等几秒使得网站完全加载
# 已经进入网站,找到搜索框,输入数据并回车搜索。
# By有By.ID、By.NAME、By.XPATH、By.CSS_SELECTOR等
search_box = web.find_element(By.XPATH, '//*[@id="headerSearchInput"]') # 直接通过检查元素中的xpath获得位置
search_box.send_keys("网站设计")
# 方法一、点击搜索,
# search = web.find_element(By.CLASS_NAME, '_search-icon_1wwm7_457')
# search.click()
# 方法二,按下回车,也可以直接放一块:search_box.send_keys("网站设计",Keys.ENTER)
search_box.send_keys(Keys.ENTER)
time.sleep(3)
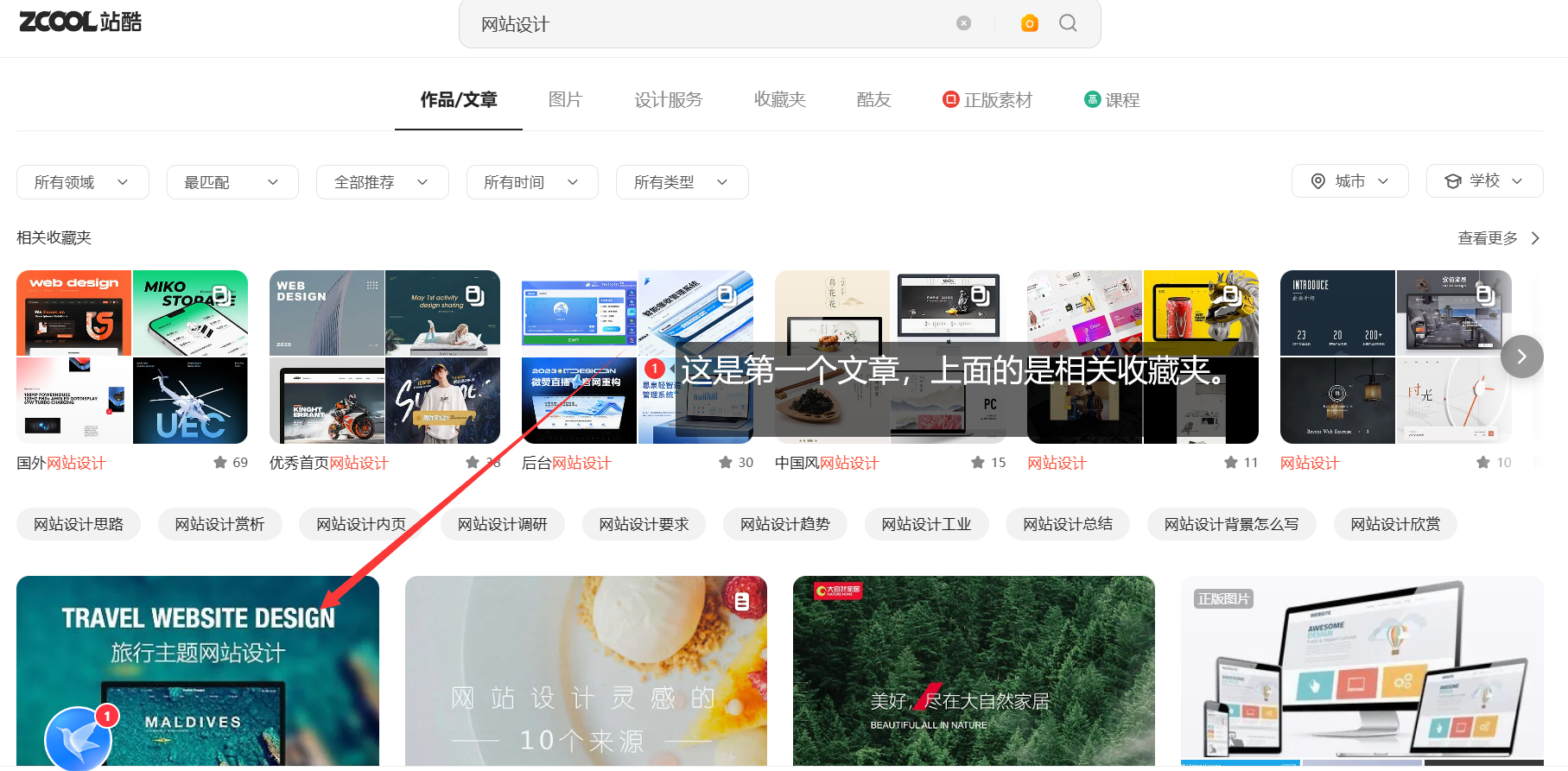
# 打开两个文章
img = web.find_element(By.XPATH, '//*[@id="__next"]/main/div/div/div[2]/section[2]/section/section/div[1]/div[1]')
img.click()
img = web.find_element(By.XPATH, '//*[@id="__next"]/main/div/div/div[2]/section[2]/section/section/div[2]/div[1]')
img.click()
time.sleep(2)
# 遇到不能按F12打开控制台和没有右键菜单的情况,应该是拦截了快捷键,点击地址栏然后按F12即可
# 切换窗口获得所需内容
web.switch_to.window(web.window_handles[1])
text = web.find_element(By.XPATH, '//*[@id="__next"]/main/div/section/div[1]')
print(text.text)
web.switch_to.window(web.window_handles[2])
text = web.find_element(By.XPATH, '//*[@id="__next"]/main/div/section/div[1]')
print(text.text)总结:
selenium优点自然是使用比较简单,怎么访问网站就怎么写代码即可,但是访问速度比较慢,需要等待页面JS加载。