1. 自定义拦截器
interceptor是拦截器,可以拦截到发送到kafka中的数据进行二次处理,它是producer组成部分的第一个组件。
java
public static class MyInterceptor implements ProducerInterceptor<String,String>{
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
return null;
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
}
@Override
public void close() {
}
@Override
public void configure(Map<String, ?> configs) {
}
}实现拦截器需要实现ProducerInterceptor这个接口,其中的泛型要和producer端发送的数据的类型一致。
onSend 方法是最主要的方法用户拦截数据并且处理完毕发送
onAcknowledgement 获取确认应答的方法,这个方法和producer端的差不多,只能知道结果通知close是执行完毕拦截器最后执行的方法
configure方法是用于获取配置文件信息的方法
我们拦截器的实现基于场景是获取到producer端的数据然后给数据加上时间戳。
整体代码如下:
java
package com.hainiu.kafka.producer;
/**
* ClassName : producer_intercepter
* Package : com.hainiu.kafka.producer
* Description
*
* @Author HeXua
* @Create 2024/10/31 22:56
* Version 1.0
*/
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.StringSerializer;
import java.util.Date;
import java.util.Map;
import java.util.Properties;
public class producer_intercepter {
public static class MyInterceptor implements ProducerInterceptor<String,String>{
@Override
public ProducerRecord<String, String> onSend(ProducerRecord<String, String> record) {
String value = record.value();
Long time = new Date().getTime();
String topic = record.topic();
//获取原始数据并且构建新的数据,增加时间戳信息
return new ProducerRecord<String,String>(topic,time+"-->"+value);
}
@Override
public void onAcknowledgement(RecordMetadata metadata, Exception exception) {
//获取确认应答和producer端的代码逻辑相同
String topic = metadata.topic();
int partition = metadata.partition();
long offset = metadata.offset();
if(exception == null ){
System.out.println("success"+" "+topic+" "+partition+" "+offset);
}else{
System.out.println("fail"+" "+topic+" "+partition+" "+offset);
}
}
@Override
public void close() {
//不需要任何操作
//no op
}
@Override
public void configure(Map<String, ?> configs) {
//不需要任何操作
//no op
}
}
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop106:9092");
pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.ACKS_CONFIG, "all");
pro.put(ProducerConfig.RETRIES_CONFIG,3 );
pro.put(ProducerConfig.BATCH_SIZE_CONFIG, 16*1024);
pro.put(ProducerConfig.LINGER_MS_CONFIG, 0);
pro.put(ProducerConfig.INTERCEPTOR_CLASSES_CONFIG,MyInterceptor.class.getName());
//设定拦截器
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(pro);
ProducerRecord<String, String> record = new ProducerRecord<>("topic_a", "this is hainiu");
for(int i=0;i<5;i++){
producer.send(record, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception exception) {
String topic = metadata.topic();
int partition = metadata.partition();
long offset = metadata.offset();
if(exception == null ){
System.out.println("success"+" "+topic+" "+partition+" "+offset);
}else{
System.out.println("fail"+" "+topic+" "+partition+" "+offset);
}
}
});
}
producer.close();
}
}ack返回的元数据信息。
java
success topic_a 0 17
success topic_a 0 17
success topic_a 0 18
success topic_a 0 18
success topic_a 0 19
success topic_a 0 19
success topic_a 0 20
success topic_a 0 20
success topic_a 0 21
success topic_a 0 21查看consumer端消费的数据。

在客户端消费者中可以打印出来信息带有时间戳。
拦截器一般很少人为定义,比如一般producer在生产环境中都是有flume替代,一般flume会设定自己的时间戳拦截器,指定数据采集时间,相比producer更加方便实用。
2. 自定义序列化器
kafka中的数据存储是二进制的byte数组形式 ,所以我们在存储数据的时候要使用序列化器进行数据的转换,序列化器的结构要和存储数据的kv的类型一致。
比如我们要实现系统的String类型序列化器。
2.1 实现String类型的序列化器
java
package com.hainiu.kafka.producer;
/**
* ClassName : producer_String_Serializer
* Package : com.hainiu.kafka.producer
* Description
*
* @Author HeXua
* @Create 2024/10/31 23:12
* Version 1.0
*/
import org.apache.kafka.clients.producer.*;
import org.apache.kafka.common.serialization.Serializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.nio.charset.StandardCharsets;
import java.util.Map;
import java.util.Properties;
public class producer_String_Serializer {
public static void main(String[] args) {
Properties pro = new Properties();
//bootstrap-server key value batch-size linger.ms ack retries interceptor
pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop106:9092");
// 自定义生产记录的key和value的序列化器
pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, MyStringSerializer.class.getName());
pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, MyStringSerializer.class.getName());
pro.put(ProducerConfig.BATCH_SIZE_CONFIG,16*1024);
pro.put(ProducerConfig.LINGER_MS_CONFIG,0);
pro.put(ProducerConfig.ACKS_CONFIG,"all");
pro.put(ProducerConfig.RETRIES_CONFIG,3);
KafkaProducer<String, String> producer = new KafkaProducer<String, String>(pro);
for (int i = 0; i < 100; i++) {
ProducerRecord<String, String> record = new ProducerRecord<>("topic_a", "hainiu","message_" + i);
producer.send(record);
}
producer.close();
}
public static class MyStringSerializer implements Serializer<String>{
@Override
public byte[] serialize(String topic, String data) {
return data.getBytes(StandardCharsets.UTF_8);
}
}
}消费者消费数据:
java
message_0
message_1
message_2
message_3
message_4
message_5
message_6
message_7
message_8
message_9
message_10
message_11
message_12
..........2.2 序列化对象整体
java
package com.hainiu.kafka.producer;
/**
* ClassName : producer_Student_Serializer
* Package : com.hainiu.kafka.producer
* Description
*
* @Author HeXua
* @Create 2024/10/31 23:20
* Version 1.0
*/
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.Serializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.io.ByteArrayOutputStream;
import java.io.IOException;
import java.io.ObjectOutputStream;
import java.io.Serializable;
import java.nio.charset.StandardCharsets;
import java.util.Properties;
/**
* producerRecord==> key:string,value:student
*/
public class producer_Student_Serializer {
public static class Student implements Serializable{
private int id;
private String name;
private int age;
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Student() {
}
public Student(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
}
public static class MyStudentSerializer implements Serializer<Student>{
// ByteArrayOutputStream
// ObjectOutputStream
@Override
public byte[] serialize(String topic, Student data) {
ByteArrayOutputStream byteOS = null;
ObjectOutputStream objectOS = null;
try {
byteOS =new ByteArrayOutputStream();
objectOS = new ObjectOutputStream(byteOS);
objectOS.writeObject(data);
} catch (IOException e) {
throw new RuntimeException(e);
}finally {
try {
byteOS.close();
objectOS.close();
} catch (IOException e) {
throw new RuntimeException(e);
}
}
return byteOS.toByteArray();
}
}
public static void main(String[] args) {
Properties pro = new Properties();
//bootstrap-server key value batch-size linger.ms ack retries interceptor
pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop106:9092");
pro.put(ProducerConfig.BATCH_SIZE_CONFIG,16*1024);
pro.put(ProducerConfig.LINGER_MS_CONFIG,0);
pro.put(ProducerConfig.ACKS_CONFIG,"all");
pro.put(ProducerConfig.RETRIES_CONFIG,3);
pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,MyStudentSerializer.class.getName());
KafkaProducer<String, Student> producer = new KafkaProducer<>(pro);
Student s1 = new Student(1, "zhangsan", 20);
Student s2 = new Student(2, "lisi", 30);
ProducerRecord<String, Student> r1 = new ProducerRecord<>("topic_a", "hainiu", s1);
ProducerRecord<String, Student> r2 = new ProducerRecord<>("topic_a", "hainiu", s2);
producer.send(r1);
producer.send(r2);
producer.close();
}消费的数据:
java
[hexuan@hadoop107 kafka]$ kafka-console-consumer.sh --bootstrap-server hadoop106:9092 --topic topic_a
¬첲=com.hainiu.kafka.producer.producer_Student_Serializer$Student8Ӯ¥ClOIageIidLnametLjava/lang/String;xpzhangsan
¬첲=com.hainiu.kafka.producer.producer_Student_Serializer$Student8Ӯ¥ClOIageIidLnametLjava/lang/String;xptlisi
XshellXshell2.3 序列化对象字段信息
比如我们想要发送一个Student对象,其中包含id name age等字段,这个数据需要对应的序列化器
序列化器的实现需要指定类型并且实现。
需要实现serializer接口,并且实现serialize的方法用于将数据对象转换为二进制的数组
整体代码如下:
java
package com.hainiu.kafka.producer;
/**
* ClassName : producer_Student_Serializer2
* Package : com.hainiu.kafka.producer
* Description
*
* @Author HeXua
* @Create 2024/10/31 23:30
* Version 1.0
*/
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import org.apache.kafka.common.serialization.Serializer;
import org.apache.kafka.common.serialization.StringSerializer;
import java.nio.charset.Charset;
import java.util.Properties;
public class producer_Student_Serializer2 {
public static void main(String[] args) {
Properties pro = new Properties();
pro.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"hadoop106:9092");
pro.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG, StringSerializer.class.getName());
//key因为没有放入任何值,所以序列化器使用原生的就可以
pro.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG, StudentSeria.class.getName());
//value的序列化器需要指定相应的student序列化器
pro.put(ProducerConfig.BATCH_SIZE_CONFIG, 16*1024);
pro.put(ProducerConfig.LINGER_MS_CONFIG, 0);
KafkaProducer<String, Student> producer = new KafkaProducer<String, Student>(pro);
//producer生产的数据类型也必须是string,student类型的kv
Student student = new Student(1, "zhangsan", 30);
ProducerRecord<String, Student> record = new ProducerRecord<>("topic_a", student);
producer.send(record);
producer.close();
}
public static class Student{
private int id;
private String name;
private int age;
public int getId() {
return id;
}
public Student() {
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
public Student(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
}
public static class StudentSeria implements Serializer<Student> {
@Override
public byte[] serialize(String topic, Student data) {
String line =data.getId()+" "+data.getName()+" "+data.getAge();
//获取student对象中的所有数据信息
return line.getBytes(Charset.forName("utf-8"));
//转换为byte数组返回
}
}
}消费者消费数据:
java
[hexuan@hadoop107 kafka]$ kafka-console-consumer.sh --bootstrap-server hadoop106:9092 --topic topic_a
1 zhangsan 303. 分区器
首先在kafka存储数据的时候topic中的数据是分为多个分区进行存储的,topic设定分区的好处是可以进行分布式存储和分布式管理,那么好的分区器可以让数据尽量均匀的分布到不同的机器节点,数据更加均匀,那么kafka中的分区器是如果实现的呢?
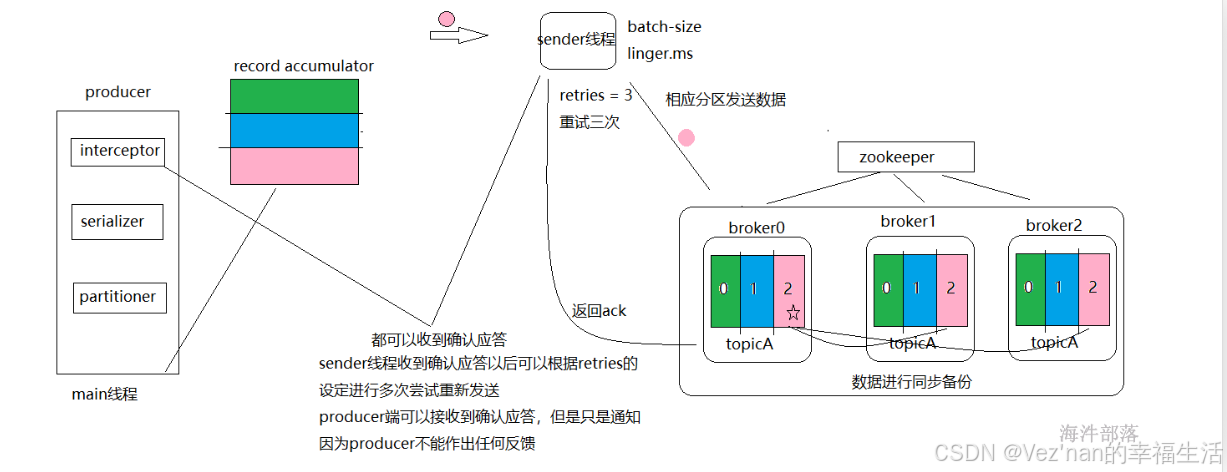
根据图我们可以看出数据首先通过分区器进行分类 ,在本地的累加器中进行存储缓存 ,然后在复制到kafka集群中,所以分区器产生作用的位置在本地的缓存之前。
kafka的分区规则是如何实现的呢?
java
ProducerRecord<String, Student> record = new ProducerRecord<>("topic_a", student);
producer.send(record);kafka的生产者数据发送是通过上面的方法实现的
首先要构造一个ProducerRecord对象,然后通过producer.send来进行发送数据。
其中ProducerRecord对象的构造器种类分为以下几种。
构造器指定分区,包含key, value。
构造器没有指定分区,但有key,有value。
构造器只有value。
java
/**
* Creates a record to be sent to a specified topic and partition
*
* @param topic The topic the record will be appended to
* @param partition The partition to which the record should be sent
* @param key The key that will be included in the record
* @param value The record contents
*/
public ProducerRecord(String topic, Integer partition, K key, V value) {
this(topic, partition, null, key, value, null);
}
/**
* Create a record to be sent to Kafka
*
* @param topic The topic the record will be appended to
* @param key The key that will be included in the record
* @param value The record contents
*/
public ProducerRecord(String topic, K key, V value) {
this(topic, null, null, key, value, null);
}
/**
* Create a record with no key
*
* @param topic The topic this record should be sent to
* @param value The record contents
*/
public ProducerRecord(String topic, V value) {
this(topic, null, null, null, value, null);
}我们想要发送一个数据到kafka的时候可以构造以上的ProducerRecord但是构造的方式却不同,大家可以发现携带的参数也有所不同,当携带不同参数的时候数据会以什么样的策略发送出去呢,这个时候需要引入一个默认分区器,就是在用户没有指定任何规则的时候系统自带的分区器规则。
在ProducerConfig源码中看到:
java
public static final String PARTITIONER_CLASS_CONFIG = "partitioner.class";
private static final String PARTITIONER_CLASS_DOC = "A class to use to determine which partition to be send to when produce the records. Available options are:" +
"<ul>" +
"<li>If not set, the default partitioning logic is used. " +
"This strategy will try sticking to a partition until " + BATCH_SIZE_CONFIG + " bytes is produced to the partition. It works with the strategy:" +
"<ul>" +
"<li>If no partition is specified but a key is present, choose a partition based on a hash of the key</li>" +
"<li>If no partition or key is present, choose the sticky partition that changes when " + BATCH_SIZE_CONFIG + " bytes are produced to the partition.</li>" +
"</ul>" +
"</li>" +
"<li><code>org.apache.kafka.clients.producer.RoundRobinPartitioner</code>: This partitioning strategy is that " +
"each record in a series of consecutive records will be sent to a different partition(no matter if the 'key' is provided or not), " +
"until we run out of partitions and start over again. Note: There's a known issue that will cause uneven distribution when new batch is created. " +
"Please check KAFKA-9965 for more detail." +
"</li>" +
"</ul>" +
"<p>Implementing the <code>org.apache.kafka.clients.producer.Partitioner</code> interface allows you to plug in a custom partitioner.";在producerConfig对象中我们可以看到源码指示,如果没有任何人为分区器规则指定,那么默认使用的DefaultPartitioner的规则.
java
package org.apache.kafka.clients.producer.internals;
import org.apache.kafka.clients.producer.Partitioner;
import org.apache.kafka.common.Cluster;
import java.util.Map;
/**
* NOTE this partitioner is deprecated and shouldn't be used. To use default partitioning logic
* remove partitioner.class configuration setting. See KIP-794 for more info.
*
* The default partitioning strategy:
* <ul>
* <li>If a partition is specified in the record, use it
* <li>If no partition is specified but a key is present choose a partition based on a hash of the key
* <li>If no partition or key is present choose the sticky partition that changes when the batch is full.
*
* See KIP-480 for details about sticky partitioning.
*/
@Deprecated
public class DefaultPartitioner implements Partitioner {
private final StickyPartitionCache stickyPartitionCache = new StickyPartitionCache();
public void configure(Map<String, ?> configs) {}
/**
* Compute the partition for the given record.
*
* @param topic The topic name
* @param key The key to partition on (or null if no key)
* @param keyBytes serialized key to partition on (or null if no key)
* @param value The value to partition on or null
* @param valueBytes serialized value to partition on or null
* @param cluster The current cluster metadata
*/
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster) {
return partition(topic, key, keyBytes, value, valueBytes, cluster, cluster.partitionsForTopic(topic).size());
}
/**
* Compute the partition for the given record.
*
* @param topic The topic name
* @param numPartitions The number of partitions of the given {@code topic}
* @param key The key to partition on (or null if no key)
* @param keyBytes serialized key to partition on (or null if no key)
* @param value The value to partition on or null
* @param valueBytes serialized value to partition on or null
* @param cluster The current cluster metadata
*/
public int partition(String topic, Object key, byte[] keyBytes, Object value, byte[] valueBytes, Cluster cluster,
int numPartitions) {
if (keyBytes == null) {
return stickyPartitionCache.partition(topic, cluster);
}
return BuiltInPartitioner.partitionForKey(keyBytes, numPartitions);
}
public void close() {}
/**
* If a batch completed for the current sticky partition, change the sticky partition.
* Alternately, if no sticky partition has been determined, set one.
*/
@SuppressWarnings("deprecation")
public void onNewBatch(String topic, Cluster cluster, int prevPartition) {
stickyPartitionCache.nextPartition(topic, cluster, prevPartition);
}
}而打开DefaultPartitioner以后可以看到他的分区器规则,就是在构建ProducerRecord的时候
java
new ProducerRecord(topic,partition,k,v);
//指定分区直接发送数据到相应分区中
new ProducerRecord(topic,k,v);
//没有指定分区就按照k的hashcode发送到不同分区
new ProducerRecord(topic,v);
//如果k和partition都没有指定就使用粘性分区partition方法中,如果key为空就放入到粘性缓冲中,它的意思就是如果满足batch-size或者linger.ms就会触发应用执行,将数据复制到kafka中,并且再次随机到其他分区,所以简单来说粘性分区就是可一个分区放入数据,一旦满了以后才会改变分区,粘性分区规则使用主要是为了让每次复制数据更加快捷方便都赋值到一个分区中。
而如果key不为空那么就按照hashcode值进行取余处理。(哈希分区器)
总的来说就是分为默认分区分为三种情况:
如果指定了分区,就复制到kafka集群指定的分区。
如果没有指定分区,但又有key存在,那么将会对key求哈希值再取余。
即 key.hashCode()%numPartition,将得到一个数字,消息将会被复制到kafka集群的该数字对应的分区。
- 如果没有指定分区,并且不存在key,只有value。那么我们会采用粘性分区策略。
即产生一个随机值k,并将没有key的记录都放入粘性缓冲,如果满足batch-size或者linger.ms就会触发应用执行,将粘性缓冲的消息复制到kafka集群随机一个分区。然后重复此步骤。