Apache Atlas 是一套可伸缩且可扩展的数据治理服务,提供了开放的元数据管理和治理能力。它能够自动发现和创建数据资产及其血缘关系。
但是,在使用 Apache Atlas 时,有时会遇到 Hive 库 Alter 语句不更新元数据的问题。当在 Hive 库中执行 ALTER TABLE 语句,如添加新列时,虽然 Hive 库的元数据库如 MySQL 中记录了表结构的变更,但 Apache Atlas 未能实时捕获到这些变更,导致血缘关系图中的元数据未能同步更新,所以对企业的数据治理、分析形成了不利影响。
Aloudata BIG 算子级主动元数据平台,它基于全球独创的算子级血缘解析技术,自动构建准确、精细、全面、实时的数据血缘图谱,能够帮助企业开展全链路自动化的精准溯源、口径盘点、打标扩散及影响面分析等,实现数据质量保障和长效的数据架构治理等。
在某头部险企,最初选择使用了 Apache Atlas 作为元数据底座,进行数据血缘关系解析。但随着该企业数据总量越来越多、数据来源越来越复杂,比如到 2023 年,总任务数近十万,数据表达 50 万+,字段数达千万级,数据链路复杂度剧增,数据资产管理和数据质量保障挑战巨大。
基于 Apache Atlas 所构建的表级血缘准确度不高、粒度太粗,无法准确看清每个指标的来龙去脉,无法做数据标准的保障落地,不得不组织大量人工"扒代码"梳理每个指标的计算口径和加工链路。据评估,按照人工每天梳理 4 个指标的加工口径,预估需要 6000 个人日,以 20 人专职投入计算,需要 1 年左右才能完成梳理,人员成本投入数百万,且这种梳理结果保鲜难度极高。
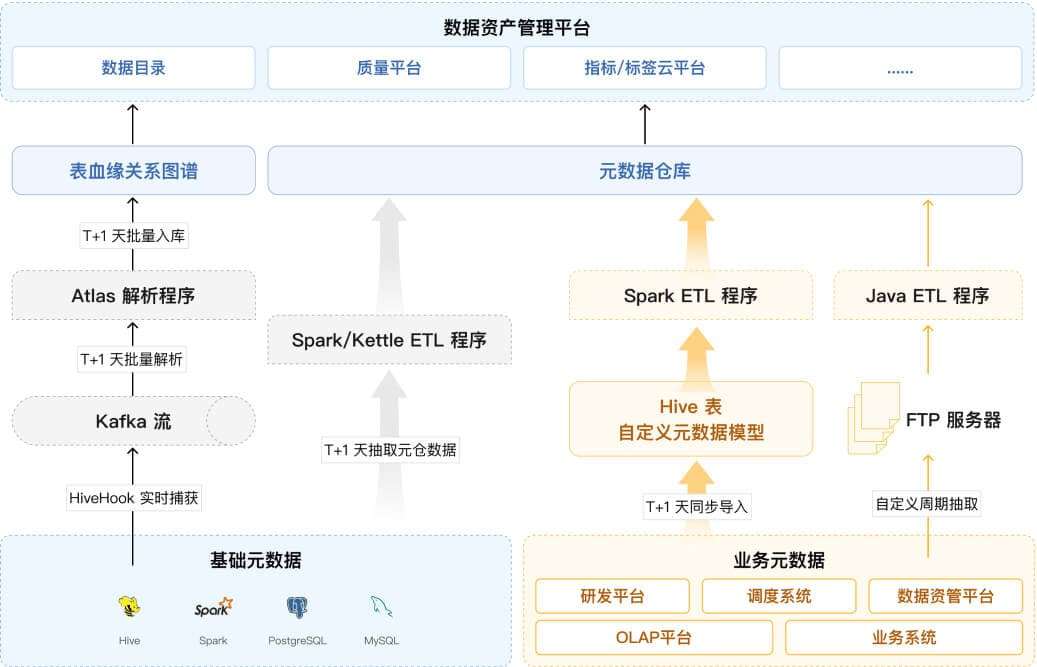
基于 Apache Atlas 构建的数据资产管理平台架构
为了应对全新挑战,该企业选择了 Aloudata BIG 算子级血缘主动元数据平台作为最新的元数据底座,实现了众多方面的关键能力升级:
统一采集全域、全生命周期元数据,简化元数据集成架构
Aloudata BIG 内置大量元数据采集器,可全自动采集多平台(研发平台、调度系统、指标平台、OLAP 平台等)、多技术组件(Hive、Spark 等)的元数据,元数据团队无需再维护复杂的元数据采集 ETL 链路,大幅简化现有元数据采集架构。同时基于 Aloudata BIG 的元模型扩展能力统一管理全域元数据,实现了源端和应用端元数据的全联通,让全链路皆可观测。
全库算子级血缘解析及字段口径抽取
基于 Aloudata BIG 的算子级 SQL 解析技术所构建的算子级血缘图谱,Hive 数仓库内数据血缘解析结果的精准度高达 99%。Aloudata BIG 自动抽取的字段口径在准确率和易读性上实现了与专家人工梳理完全一致的效果。
自动资产分类,实时打标扩散
基于 Aloudata BIG 的开放知识推理框架和元数据图谱模型,实现了数据资产画像标签的灵活挖掘和全链路资产实时打标扩散,帮助数据团队自动、实时、360°刻画每一份数据资产,从而为实施分类分级的数据安全防控策略提供数据基础。
主动、智能的元数据服务,与现有资管平台无缝集成
基于 Aloudata BIG 提供的各类元数据服务 API 及血缘可视化分析组件,可与客户的数据资产管理平台及数据工具无缝集成,无需改变现有用户使用习惯,实现了数据治理能力的透明化升级。
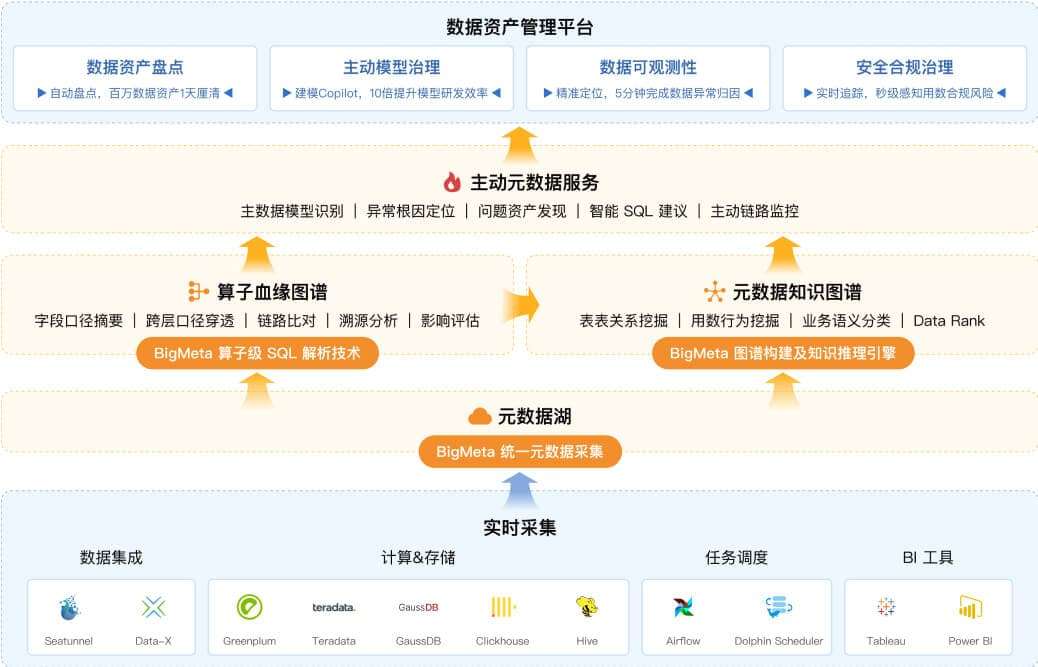
基于 Aloudata BIG 构建的数据资产管理平台架构
在 Aloudata BIG 的支持下,该企业理解一份数据的时间从数小时减少到数分钟,工作效率提升至少 10 倍,从投入大几百万人工成本来为重点指标做一次静态链路盘点,到依靠系统 24h 即可自动盘清全域数据口径,让数据治理的总体投入至少降低十余倍,并实现持续保鲜。此外,还告别了人工审批、流程管控式的被动数据治理模式,实现主动数据治理。进入 Aloudata 官网,了解更多。