2024-11-01,由伊利诺伊大学厄巴纳-香槟分校的研究团队创建的AIDOVECL数据集,通过AI生成的车辆图像,显著减少了手动标注工作,为自动驾驶、城市规划和环境监测等领域提供了丰富的眼水平车辆图像资源。
数据集地址:AIDOVECL|自动驾驶数据集|车辆图像识别数据集
一、研究背景:
随着计算机视觉技术的发展,自动驾驶、城市规划和环境监测等领域对于车辆识别技术的需求日益增长。这些技术的进步依赖于机器学习模型的准确性和鲁棒性,而这一切都建立在高质量、多样化的训练数据集之上。然而,目前面临的一个主要挑战是缺乏多样化的眼水平车辆图像,这对于自动驾驶和路边监控应用至关重要。
目前遇到困难和挑战:
1、图像标记瓶颈:在计算机视觉技术的发展中,图像标记是一个关键瓶颈,由于手动注释的耗时性,限制了机器学习模型的潜力。
2、缺乏多样化的眼水平车辆图像:在所需的类别中,缺乏多样化的、与眼睛齐平的车辆图像,这对于自动驾驶和路边监控应用至关重要。
3、公共数据集的局限性:公共数据集经常缺乏足够的眼水平车辆表示,且这些数据集往往不包括详细或所需的车辆分类,限制了它们的实际应用。
数据集地址:AIDOVECL|自动驾驶数据集|车辆图像识别数据集
二、 让我们一起来看一下AIDOVEC数据集:
AIDOVECL是一个AI生成的车辆图像数据集,旨在解决眼水平分类和定位问题,通过扩展画布技术(outpainting)来模拟真实世界条件。
包含超过15000张AI生成的车辆图像,这些图像通过检测和裁剪手动选择的种子图像生成,并使用高级外绘技术模拟真实世界条件。
数据集构建:
创建过程包括车辆检测、图像裁剪、外绘和质量评估,确保视觉保真度和上下文相关性。
具体从现有图像中检测车辆,然后裁剪出"种子图像",这些图像可以手动分类。为了增加数据集的多样性,研究者们使用生成性AI进行扩展画布操作,包括重新着色并将裁剪出的车辆图像放置在更大的画布上的随机坐标和尺度上。
数据集特点:
1、AI生成的图像:AIDOVECL数据集包含超过15000张AI生成的车辆图像,这些图像通过检测和裁剪手动选择的种子图像生成,并使用高级外绘技术模拟真实世界条件。
2、高质量的地面真实数据:数据集中的外绘图像包括详细的注释,提供高质量的真实数据,用于训练和评估目的。
3、减少手动标注工作量:通过利用外绘技术,AIDOVECL数据集显著减少了手动标注的工作量,解决了带注释的数据稀缺问题。
4、视觉保真度和上下文相关性:先进的外绘技术和图像质量评估确保了数据集的视觉保真度和上下文相关性。
5、多样化操作场景:AIDOVECL数据集旨在提高机器学习模型在多样化操作场景下的分类和定位性能,特别是在自动驾驶、交通分析和城市规划领域。
6、自我注释范式:AIDOVECL展示了外绘作为自我注释范式的应用,提供了一种增强机器学习多个领域数据集多功能性的解决方案。
数据集可以用于训练和评估车辆分类和定位模型。每个图像都自动注释了详细的边界框坐标,为训练和评估目的提供了宝贵的真实数据。
基准测试:
在基准测试中,使用AIDOVECL数据集进行训练的模型在分类和定位任务中表现出色,与仅使用真实数据集训练的模型相比,性能提升了高达8%,并且在预测代表性不足的类别时提升了高达20%。
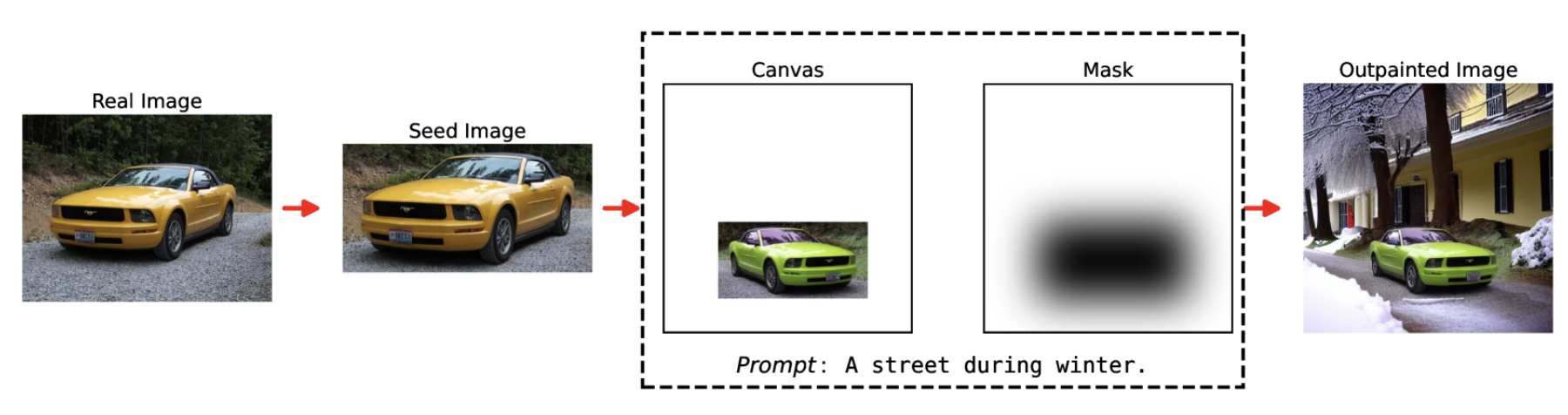
来自真实图像的车辆被随机重新着色、缩放和放置在画布上,然后使用结构化提示和模糊蒙版进行着色。

车辆分类和子类别

使用 BRISQUE ≤15 、 CLIP-IQA ≥0.9 和缩小(32x32 像素)的 TV 损失 ≤15 绘制各种车辆类别的着色图像。
三、让我们一起展望AIDOVECL数据集应用
比如,你是一名自动驾驶汽车公司的工程师,你的任务是确保汽车在繁忙的城市街道上安全行驶。
以前啊,你的自动驾驶汽车在繁忙的城市街道上,尤其是十字路口,车水马龙,各种类型的车辆从四面八方涌来。大小不一,速度不一,方向也不一,虽然你的自动驾驶汽车技术不错,但经验不足。这些汽车的"眼睛"------也就是传感器和摄像头------有时候看不太清楚,或者不太能准确判断其他车辆的位置和动向。
现在有了AIDOVECL数据集,这个数据集里有成千上万张车辆的图片,都是从人眼高度拍的,特别真实。这样一来,自动驾驶汽车就能学习到更多关于车辆的信息,比如车辆的大小、形状、类型,还有它们在不同情况下的行为。自动驾驶汽车通过学习,能够识别和理解周围的环境,尤其是其他车辆的位置和动向。
对于突然从右边冲出来的SUV,速度还挺快。但自动驾驶汽车一眼就认出了那是辆SUV,还判断出了它的行驶轨迹和速度。然后,它迅速地减速,保持了安全距离,避免了可能的碰撞。
还有路上会有那种大货车,特别长,以前的系统可能就把它当成两辆车,或者判断不好它的边界。但现在,自动驾驶汽车能准确识别出这是一辆完整的大货车,知道该怎么安全地超车或者并线。
总的来说,有了AIDOVECL数据集,自动驾驶汽车就像是从新手变成了老司机,对路上的情况更加了如指掌,反应也更快、更准确。
知识小课堂:
眼水平车辆图像(Eye-level vehicle images)指的是那些从与人类眼睛大致平行的视角拍摄的车辆图像。这种图像能够提供类似于人在实际环境中观察车辆时的视角,这对于自动驾驶系统、交通监控和城市规划等应用来说非常重要,因为它们需要以人类的视角来理解和解释车辆的位置、类型和行为。
具体来说,眼水平车辆图像能够提供以下几个方面的信息:
1、车辆的位置区域:指车辆在图像中的确切位置,包括车辆所在矩形区域的左上角的横、纵向像素数,以及矩形区域的宽度和高度。
2、车辆的姿态:指车辆相对于监控图像在三维空间的角度,包括水平转动角(Y)、俯仰角(X)和倾斜角(Z)。
3、车辆特征:包括号牌特征、车型特征、驾驶行为特征、个性化特征等,这些特征有助于对车辆进行结构化的描述和识别。
4、车辆特征向量:利用深度学习技术从车辆图像中提取的代表车辆唯一特征的向量,可以通过相似度计算判定不同车辆特征向量的相似性。
来吧,让我们走进:AIDOVECL|自动驾驶数据集|车辆图像识别数据集
免费数据集网站:遇见数据集
遇见数据集是一个平台,致力于让每个数据集都被发现,让每一次遇见都有价值,
1、数据获取的便利性:遇见数据集通过集中整合全球数据资源,提供了一个一站式平台,使得用户能够轻松搜索和访问各种数据集,无需在多个来源之间进行切换,从而提高了数据获取的效率。
2、数据的可发现性:通过详细的数据标签和分类系统,遇见数据集增强了数据集的可发现性,帮助用户快速找到特定领域的数据集,尤其是对于特定研究领域或应用场景的数据,极大地方便了数据的检索和使用。
3、数据更新的及时性:遇见数据集频繁更新数据集内容,确保用户能够获取最新的数据资源,这对于需要最新数据进行分析和研究的用户来说尤为重要,保证了数据的时效性和相关性。