论文速读|LongReward: Improving Long-context Large Language Models with AI Feedback
论文信息:

简介:
该论文试图解决的问题是如何提高长文本上下文大型语言模型(LLMs)在监督式微调(SFT)中的性能,尤其是在使用由LLMs自身自动合成的数据时,这些数据的质量往往会影响模型的长期上下文处理能力,导致模型存在固有的缺陷,如幻觉和无法充分利用上下文信息。论文的主要动机是,尽管强化学习(RL)通过适当的奖励信号可以进一步提升模型的能力,但在长文本场景中如何获得可靠的奖励信号仍然是一个未被探索的问题。为了解决这一挑战,论文提出了一种新的方法,旨在通过自动化的方式为长文本模型响应提供可靠的奖励,从而使得RL算法能够被用于增强长文本SFT模型。论文所提出的方法名为LongReward,它利用现成的LLM作为评估者,从四个人类价值维度(有用性、逻辑性、忠实性和完整性)为长文本模型响应提供奖励。LongReward通过精心设计的评估流程,为每个维度打分,并取平均值作为最终奖励。通过结合LongReward和离线RL算法DPO,论文展示了如何有效提升长文本SFT模型的性能。
论文方法:
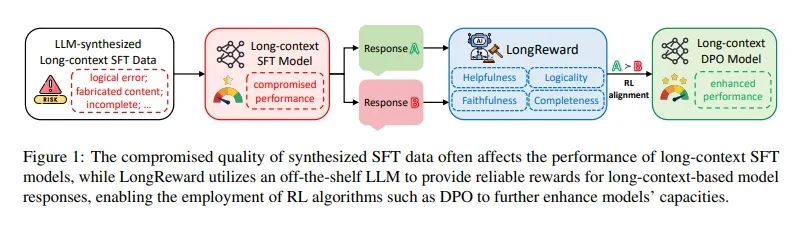
这篇论文提出了一个名为LongReward的方法,旨在解决长上下文大型语言模型(LLMs)在监督微调(SFT)中因合成数据质量不佳而导致的性能问题。LongReward通过一个现成的大型语言模型(LLM),从四个人类价值维度对长上下文模型响应进行评分,这四个维度包括有用性(helpfulness)、逻辑性(logicality)、忠实性(faithfulness)和完整性(completeness)。每个维度的评分范围为0到10,最终奖励为这四个评分的平均值。下面分别是四个维度的含义:
**1)有用性评分:**对于有用性,LLM根据查询和响应内容直接评分,并通过引入Chain-of-Thought(CoT)机制,在提供最终评分前生成分析,以增强评分的可靠性和互操作性。
**2)逻辑性评分:**逻辑性评分旨在检测模型响应中的逻辑错误,同样独立于上下文,通过few-shot学习与CoT机制,使LLM能够首先发现响应中可能存在的逻辑错误,然后对其逻辑性进行评分。
**3)忠实性评分:**忠实性评分衡量模型响应中与上下文一致的事实信息比例。LLM首先将模型响应分解为一系列事实陈述,然后判断每个陈述是否得到上下文的支持。
**4)完整性评分:**完整性评分关注响应是否覆盖了上下文中所有与问题相关的关键点,并提供了足够的信息和细节以满足用户需求。通过将上下文分割成粗粒度的块,并要求LLM从每个块中提取与问题相关的信息,然后再次调用LLM来评估响应的完整性。
LongReward与离线强化学习算法Direct Preference Optimization (DPO) 结合使用,通过构建长上下文偏好数据集来进一步增强长上下文SFT模型的能力。对于每个提示,从SFT模型中采样多个候选响应,然后应用LongReward获得每个响应的奖励,并选择最高和最低奖励的响应作为偏好对。
论文实验:
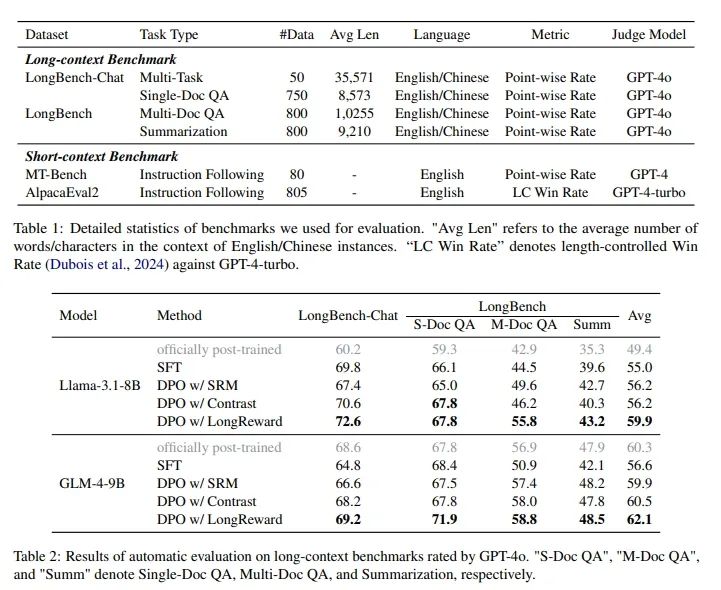
实验使用了两个双语基准测试集,LongBench-Chat和LongBench,这些测试集旨在评估模型在长上下文任务中的表现。LongBench-Chat是一个小规模数据集,包含50个真实查询,而LongBench是一个更全面的基准测试,包含2350个实例,涵盖单文档问答、多文档问答和总结等任务。评估模型表现的指标包括点对点的评分(Point-wise Rate)和长度控制的胜率(Length-Controlled Win Rate),这些指标由GPT-4o自动评估模型响应的质量。使用LongReward方法的DPO模型在所有长上下文任务中均优于SFT模型。具体来说,Llama-3.1-8B和GLM-4-9B在使用LongReward的DPO版本相比于SFT版本分别提升了4.9%和5.5%的平均性能。此外,这些模型的性能甚至超过了官方发布的后期训练模型。LongReward方法在提高模型忠实性方面也显示出效果,通过自动评估模型响应中支持事实的比例,DPO模型使用LongReward的事实得分高于SFT基线,表明LongReward在减少幻觉和提高长上下文LLMs的忠实性方面的有效性。通过人类评估进一步验证了LongReward在提高LLMs长上下文能力方面的有效性。评估者根据LongReward的评分原则对SFT和LongReward+DPO版本的Llama-3.1-8B生成的响应进行评分,结果显示DPO模型在使用LongReward时在所有维度上都优于SFT基线,总体胜率为54%。
论文链接:
https://arxiv.org/abs/2410.21252
原文来自: