本文分享自华为云社区:华为大咖说 | 浅谈智能运维技术-云社区-华为云
本文作者:李文轩 ( 华为智能运维专家 )
全文约2695字,阅读约需8分钟
在大数据、人工智能等新兴技术的加持下,智能运维(AIOps,Artificial Intelligence for IT Operations)成为了高效管控物理设备、定位故障信息,快速迭代需求变更等新时代运维场景下不可或缺的解决方案,加强智能制造和智能服务已经写入"十四五"规划专栏。然而,面向存储领域的智能运维在华为,以及业界仍处于探索并快速发展阶段。
本文主要结合学术界的研究方向,探讨当前智能运维(AIOps)技术面临的挑战及各种方案的优劣 ,并提出自己对存储领域未来智能运维(AIOps)发展的一点看法,同大家一起探讨。
PART 01
智能运维发展方向及现状
传统运维(DevOps)的痛点在于依赖工程师花费大量时间归拢和梳理各个数据源的信息,结合对架构和代码的理解,逐步缩小问题范围,最终找到问题根因。然而,对于运维而言,时间是最贵的奢侈品,如果让计算机解决自动化计算,客观分析的繁琐任务,会极大地提高运维的效率,智能运维(AIOps)显然就带来了一种非常好的解决方案。
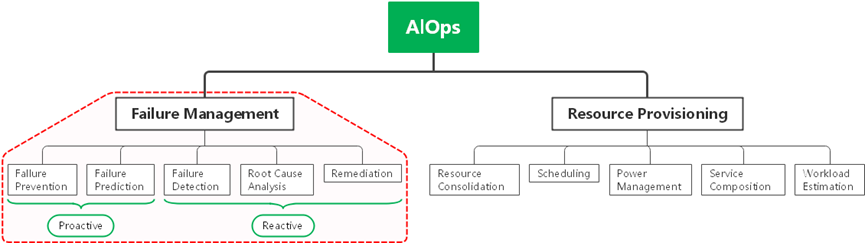
图1 AIOps分类1
智能运维(AIOps)面向问题可以划分为故障管理 (Failure Management)和资源调度(Resource Provisioning)两大类。
故障管理主要是用于处理IT设备中告警乃至错误的场景 ,包含预防、预测、检测、根因分析和恢复;通过预防、恢复和提前预警,提高了整个设备的可用性和可靠性;**资源调度的范围涉及更加广泛,**包含资源整合,调度,电源管理、服务组合和负载预测,资源调度提高了设备的可观测性和总体性能。
总的来说,智能运维(AIOps)是一个非常广泛的概念,即通过结合人工智能技术和运维,增强人工解决问题和通过系统解决问题的能力。2
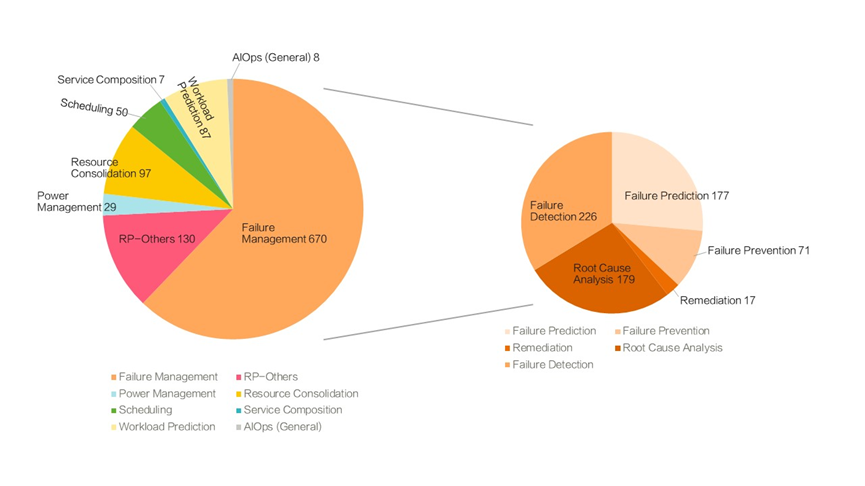
图2 AIOps论文在宏观领域和类别上的分布3
Notaro等学者收集了超过一千篇有关智能运维(AIOps)的论文,并对智能运维(AIOps)的各个分类下的论文数量进行了统计,如图2所示。显然,故障管理是所有智能运维(AIOps)相关论文中数量最多的分类,占据了超过一半(670篇,62.1%)的论文数量。在细分类中,故障检测(failure detection)、故障预测(failure prediction)和根因分析(root cause analysis)成为故障管理方向的主要热点。
PART 02
智能运维(AIOps)的主要方法
如前所述,智能运维(AIOps)是一个广泛的概念,涉及到解决不同的运维问题时会引入新的方法和模型。因此,本文将基于几篇论文,介绍部分典型的方法,并探讨目前智能运维(AIOps)所面临的问题。
1 )基于日志 :日志信息是故障管理中常用的优质数据源,基于日志建模和分析是故障管理比较常见的方法。
2 ) 基于时序数据:通过建模分析IT设备运行过程中产生的时序数据,如带宽、时延等,检验或者预测是否存在数据异常,在故障检测,故障预测以及资源规划中都是常见的手段。
时间序列分析的一个困难就是如何从时间序列中提取关键特征,虽然深度学习的模型有很好的效果,但是可解释性较差。因此,有论文4提出了一种新的方法,通过提取时间感知的shapelets(一种时间序列特征提取方法)构造一个shapelets演化图,运用图嵌入算法DeepWalk(一种基于图的无监督特征学习方法)计算每个时间片段,该时间片段就可以表达各种下游任务,用于故障检测,该方法在多个开源数据集上均取得了较高的准确率。
除此以外,时序数据噪声大,数据量大也是在线分析的难点。有学者建议5结合离线和在线训练,采用基础的DBSCAN(一个比较有代表性的基于密度的聚类算法)算法对KPI(Key Performance Indicator 关键性能指标)进行聚类,把时间序列进行分类,在在线分析时,不同的类使用不同的检测模型来进行异常检测,训练时间相较于基线训练时间减少90%,效果(F-score)仅下降15%。
这类方法的有效性高度依赖于数据的质量,数据中的噪声可能对最终结果产生影响,方法总体的准确率并不高,且分析效率较低。因此业界在实现这类方法时,通常会使用用户自身的历史数据进行构建,或者直接从数据库服务中调用。总的来说,这类方法需要大量且高质量的数据和范式,以及适当的数据模型。
3 **) 基于代码:基于代码的分析是一种常用的根因分析及故障预防的手段。**其核心思路是通过建模分析识别代码中的潜在问题,提高问题定位效率。这种方法不仅适用于智能运维(AIOps),而且在开发测试过程中也会有很大的收益。其中,有文章提及6通过解析程序二进制文件,构建静态依赖图(SDG, Static Dependency Graph),分析因果相关事件之间的关系,并过滤影响性较小的因素,在性能问题快速定位上具有较好的效果。
这类方法的局限性在于构建因果关系和分析需要耗费大量的时间,且很难存在一种方法可以适应所有场景的解决方案,适用于所有问题。
PART 03
总结和未来
智能运维(AIOps)是一个相对年轻,远非成熟的技术,它面临的挑战主要有以下几个方面:
首先,为了更快、更准确地发现潜在的SLA(Service-Level Agreement,服务水平协议)违规问题,它需要不断整合其他研究领域的成果,并引入新的建模技术。
其次**,数据质量问题也是智能运维** (AIOps)**发展的关键挑战,**现网IT设备运行过程中大量的监控数据中并不是都是有效的,一旦脏数据对结果产生影响,就会导致性能下降甚至服务复位,从而增加额外的成本(比如存储领域误判故障盘,慢盘等)。
最后,找到合适的智能运维 (AIOps)应用场景,需要对业务有深入理解,且构造合适的建模方法比较困难。智能运维(AIOps)的用例分析和识别是整个IT运营环境中的挑战和机遇,如果没有准确识别潜在的问题,那么采用智能运维(AIOps)可能不会有收益。
智能运维(AIOps)在存储领域上已经得到了一定的应用,并较好地提高了存储设备的可靠性和可观测性,例如波动检测和器件故障的预测。
未来,存储领域的智能运维具备着广阔发展前景,例如文中利用LLM(大语言模型)进行根因分析或许准确率并不高,但是利用类似的方法可以制作一个运维对话机器人,提高运维的效率,在移动端远程运维智能场景会有很多的应用空间。
此外,在可观测性上, 智能运维(AIOps)大有发展空间,构造完整的告警视图,智能地根据告警的不同场景提供该告警所需的更全面的指标、告警、变更、日志相关数据,供运维工程师在一个视图下完成对告警的综合分析、响应和处置操作。更进一步地,打造一体化的"统一运维平台",自主配置自动化告警处理方式,通过特定的场景将指标,日志,变更,告警等数据组合在一起来帮助减少告警噪音、增强告警处理效率、提供运维人员更多的告警上下文。
尽管不存在任何一个解决方案可以永久性地解决所有问题,但智能运维(AIOps)会给整个运维产业带来新的进化。
参考文献
1 Rijal L, Colomo-Palacios R, Sánchez-Gordón M. Aiops: A multivocal literature reviewJ. Artificial Intelligence for Cloud and Edge Computing, 2022: 31-50.
2 what is aiops (2023) redhat. Available at: https://www.redhat.com/zh/topics/ai/what-is-aiops (Accessed: 2023).
3 Notaro P, Cardoso J, Gerndt M. A systematic mapping study in AIOpsC//International Conference on Service-Oriented Computing. Cham: Springer International Publishing, 2020: 110-123.
4 Cheng Z, Yang Y, Wang W, et al. Time2graph: Revisiting time series modeling with dynamic shapeletsC//Proceedings of the AAAI conference on artificial intelligence. 2020, 34(04): 3617-3624.
5 Li Z, Zhao Y, Liu R, et al. Robust and rapid clustering of kpis for large-scale anomaly detectionC//2018 IEEE/ACM 26th International Symposium on Quality of Service (IWQoS). IEEE, 2018: 1-10.
6 Ren X J, Wang S, Jin Z, et al. Relational Debugging---Pinpointing Root Causes of Performance ProblemsC//17th USENIX Symposium on Operating Systems Design and Implementation (OSDI 23). 2023: 65-80.