json 是个好东西,它可以使用公共的文本形式承载了丰富的结构化数据的信息。现代很多技术都在喜欢使用 json 作为数据传输格式,比如 Elastic Search,Restful,Kafka 等,Mongodb 这类对性能较在意的技术则使用了二进制化的 json。
结构化的数据常常是批量的,也常常是需要再计算的。
但是,json 相关的类库却没什么方便用来做计算的。jsonpath 解析 json 没问题,却没什么计算能力,简单的过滤聚合还可以,稍复杂到分组汇总就不灵了,基本上是靠自己硬编码完成了。
写进数据库来算?这也太沉重了。何况,json 经常是多层的结构化数据,写进关系数据库要建几个关联的表,入库的成本远高于计算本身了。
esProc SPL 来帮你。
esProc SPL 是纯 Java 开发的开源计算引擎,开源地址
esProc SPL 对 json 库进行了封装,一句话就可以把 json 文本解析成可计算的 SPL 序表(SPL 的内存结构化数据对象):
|---|----------------------------------------------|
| | A |
| 1 | =file("d:\\xml\\emp_orders.json").read() |
| 2 | =json(A1) |
SPL 序表天然多层结构,即字段取值可以是另一个序表,这和 json 天然契合:
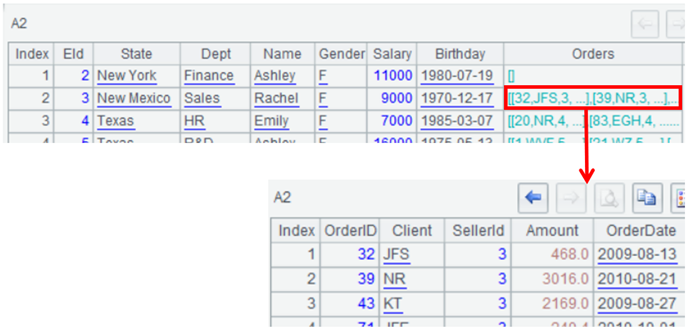
一旦转换成 SPL 序表之后,计算本身就是 esProc 的强项了。过滤、分组、连接都不在话下,大部分计算目标都可以一句话完成:
Filter:T.select(Amount>1000 && Amount<=3000 && like(Client,"*s*"))
Sort:T.sort(Client,-Amount)
Distinct:T.id(Client)
Group:T.groups(year(OrderDate);sum(Amount))
Join:join(T1:O,SellerId; T2:E,EId)
TopN:T.top(-3;Amount)
TopN in group:T.groups(Client;top(3,Amount))这些内容很多,这里就不展开了,感兴趣的小伙伴可以到 乾学院去参考相关资料。
esProc SPL 已经封装了很多常见的 json 数据源的访问接口。
Restful:纯文本式的 json,计算完了还可以反向生成 json 文本
|---|---------------------------------------------------------------------------------------------|
| | A |
| 1 | =httpfile("http://127.0.0.1:6868/restful/emp_orders").read() |
| 2 | =json(A1) |
| 3 | =A2.conj(Orders).select(Amount>1000 && Amount<=2000 && like@c(Client,"*business*")) |
| 4 | =json(A3) |
Elastic Search:可以直接在 SPL 代码中写 json 常数后参与传输和计算
|---|--------------------------------------------------------------------------------------------------------|
| | A |
| 1 | >apikey="Authorization:ApiKey a2x6aEF......KZ29rT2hoQQ==" |
| 2 | '{ "counter" : 1, "tags" : "red" ,"beginTime":"2022-01-03" ,"endTime":"2022-02-15" } |
| 3 | =es_rest("https://localhost:9200/index1/_doc/1", "PUT",A2;"Content-Type: application/x-ndjson",apikey) |
| 4 | =json(A3.Content) |
Mongodb:二进制化的 json 也没问题
|---|--------------------------------------------------------------------------------------------------|
| | A |
| 1 | =mongo_open("mongodb://127.0.0.1:27017/mymongo") |
| 2 | =mongo_shell(A1,"{'find':'orders',filter:{OrderID: {$gte: 50}},batchSize:100}") |
| 3 | =A2.cursor.firstBatch.select(Amount>1000 && Amount<=2000 && like@c(Client,"*business*")) |
| 4 | =mongo_close(A1) |
Kafka:SPL 也封装了向这些数据源写出的接口,形成 IO 闭环
|---|-------------------------------------------------------|
| | A |
| 1 | =kafka_open("/kafka/my.properties", "topic1") |
| 2 | =kafka_poll(A1) |
| 3 | =A2.derive(json(value):v).new(key, v.fruit, v.weight) |
| 4 | =kafka_send(A1, "A100", json(A3)) |
| 5 | =kafka_close(A1) |
对于 Mongodb,Kafka 这类可能返回大数据量的数据源,esProc SPL 还提供游标对象和方法,可以逐步读取,边读边处理。这里就不详细举例了,小伙伴也可以去官网查阅资料。
通常 json 数据不会单独存在,还会和其它数据源交换数据以及混合计算。esProc SPL 当然也不只专门为了对付 json 而发明的,它是专业的计算引擎,能支持的数据源非常丰富:

这些数据源都有被 SPL 读成序表和游标,再实现混合计算以及交换数据就非常容易了。
那么,esProc SPL 写出来的代码如何集成到应用程序中呢?
很简单,esProc 提供了标准的 JDBC 驱动,被 Java 程序引入后,就可以使用 SPL 语句了,和调用数据库 SQL 一样。
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
Statement statement = conn.createStatement();
ResultSet result = statement.executeQuery("=json(file(\"Orders.csv\")).select(Amount>1000 && like(Client,\"*s*\")件,然后就像调用存储过程一样:
Class.forName("com.esproc.jdbc.InternalDriver");
Connection conn =DriverManager.getConnection("jdbc:esproc:local://");
CallableStatement statement = conn.prepareCall("call queryOrders()");
statement.execute();作为纯 Java 开发的软件,esProc SPL 可以完全无缝地集成进 Java 应用中,就和应用程序员自己写的代码一样,一起享受成熟 Java 框架的优势。SPL 本身有完善的流程控制语句,像 for 循环,if 分支都不在话下,还支持子程序调用。只用 SPL 就能实现非常复杂的业务逻辑,直接构成完整的业务单元,不需要上层 Java 代码来配合,主程序只要简单地调用 SPL 脚本就可以了。
将 SPL 脚本存储成文件,置于主应用程序之外,代码修改可以独立进行且立即生效,不像 Java 代码在修改代码后还要重新编译,整个应用都要停机重启。这样可以做到业务逻辑的热切换,特别适合支持变化频繁的业务,而这也是 json 广泛应用的地方。
