SelectDB 是由飞轮科技基于 Apache Doris 内核打造的现代化数据仓库,支持大规模实时数据上的极速查询分析。 通过实时、统一、弹性、开放的核心能力,能够为企业提供高性价比、简单易用、安全稳定、低成本的实时大数据分析支持。SelectDB 具备世界领先的实时分析能力,能够实现秒级的数据实时导入与同步,在宽表、复杂多表关联、高并发点查等不同场景下,提供超越一众国际知名的同类产品的优秀性能,多次登顶 ClickBench 全球数据库分析性能排行榜。
阿里云 DataWorks 是基于大数据引擎,为数据仓库、数据湖、湖仓一体等解决方案提供统一的全链路大数据开发治理平台。 用户可通过 DataWorks 进行海量数据的离线加工分析,并能完成数据的汇聚集成、开发、生产调度与运维、离线与实时分析、数据质量治理与资产管理、安全审计、数据共享与服务、机器学习、应用搭建等工作。让数据从采集到展现、从分析到驱动应用得以解决,实现数据业务化、业务数据化。
近日,阿里云 DataWorks 正式支持 MySQL 整库实时同步至 SelectDB 或 Apache Doris。

详情参考:DataWorks 官方产品公告
当用户面临 MySQL 源库数据量大、查询分析速度慢的问题时,可以通过 DataWorks 将单表或整库同步至 SelectDB 或 Apache Doris,该方案便捷易用、成本低、数据同步延迟可达秒级,源库 MySQL 的数据变化(包括 DML、DDL 记录)都能实时同步。** 目前,DataWorks 对 SelectDB 和 Apache Doris 数据源的支持情况如下表所示,** 用户可通过 DataWorks 配置数据源,连接源库 MySQL 和目标库 SelectDB 或 Apache Doris ,利用 DataWorks 资源组实现 MySQL 单表或整库的全量和增量数据实时同步至 SelectDB 或 Apache Doris。

本文将以 SelectDB Cloud 为例, 为您全面介绍同步流程与步骤,助您快速使用 DataWorks 将 MySQL 整库数据同步至 SelectDB (由于 SelectDB 基于 Apache Doris 内核打造,两者在使用以及同步任务配置上几乎无差异,因此您也可以参考此方法将数据同步至 Apache Doris),轻松实现事务数据的实时同步与分析。
准备环境
准备数据库
本文将以阿里云数据库 RDS MySQL 版实例作为源端数据库。若您尚未创建,请点击如何创建阿里云数据库 RDS MySQL 实例参考完成具体设置。
本文将以 SelectDB Cloud 数据仓库作为目标端数据库,若您尚未创建,请点击如何创建 SelectDB Cloud 数仓参考完成具体设置。
准备 DataWorks 工作空间
您需要准备阿里云 DataWorks 空间以完成后续步骤,若您尚未创建,请点击如何创建阿里云 DataWorks 工作空间参考完成具体设置。
准备资源组
在使用 DataWorks 前,您需要新建 Serverless 资源组,为 MySQL 整库实时同步至 SelectDB Cloud 提供计算资源以及周期调度资源。若您已创建 Serverless 资源组 ,或拥有独享数据集成资源组,即可跳过准备资源组环节。
-
登录 DataWorks 控制台,切换至目标地域后,单击左侧导航栏的资源组,进入资源组列表页面。
-
在资源组列表页面,单击左上角的新建资源组 ,新建 Serverless 通用型 资源组,具体步骤请点击如何新建阿里云 DataWorks Serverless 资源组完成创建。
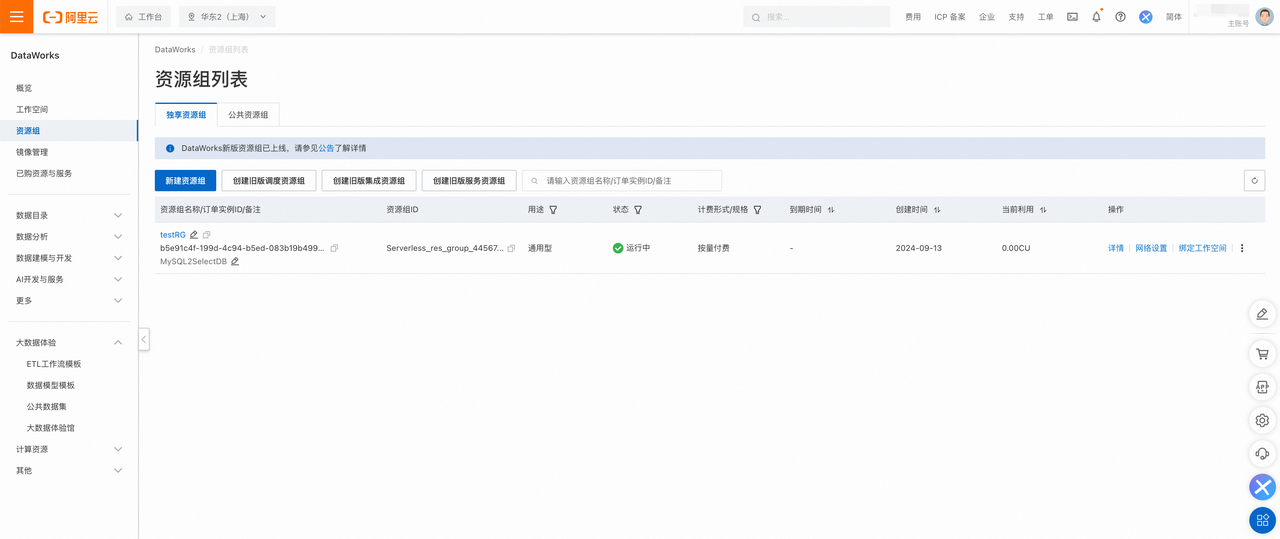
3.资源组创建完成后,您需要返回资源组列表页面,找到创建完毕的资源组,单击操作列内的绑定工作空间 按钮,将新建的资源组与已有的 DataWorks 工作空间进行绑定。
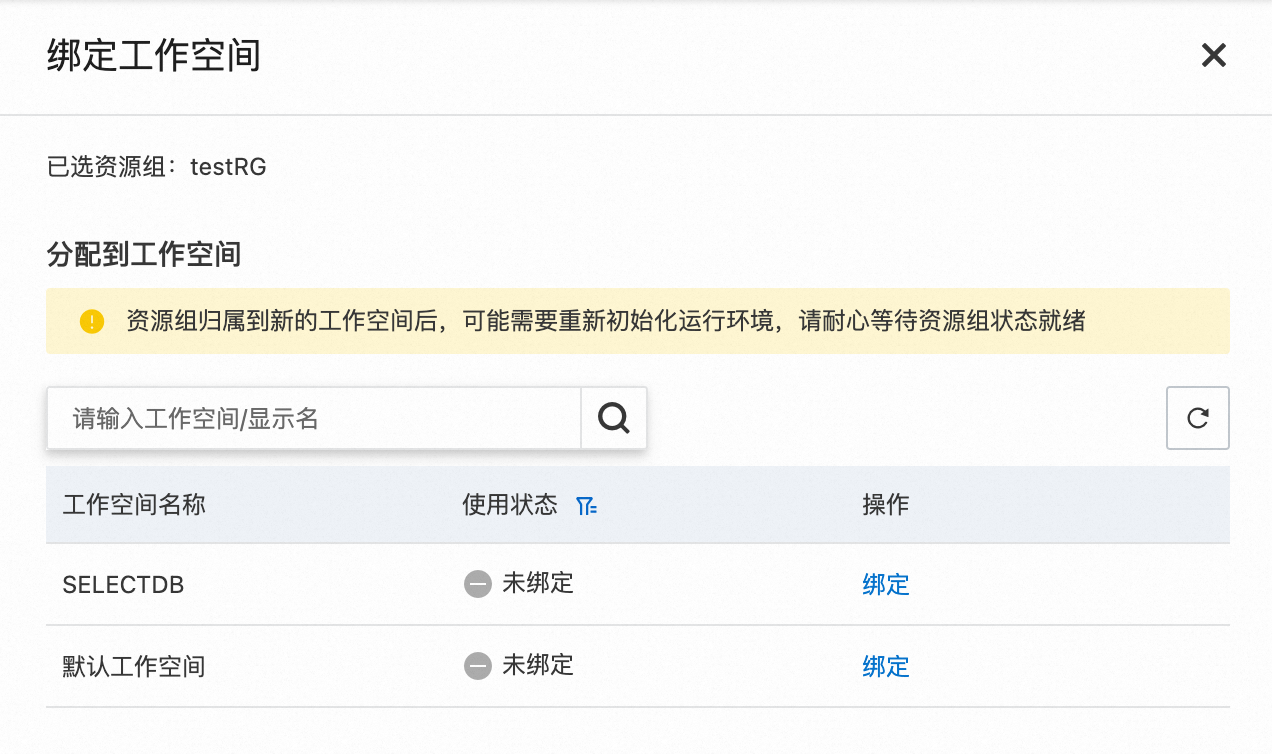
提醒 对于数据源存在白名单访问控制的情况,您需要将 Serverless 资源组绑定的交换机网段或者绑定 VPC 配置的 EIP 添加至其白名单中。
通过内网访问:在 DataWorks 控制台的资源组列表 页面独享资源组 页签下,单击目标 Serverless 资源组操作列的网络设置 ,查看数据集成内容区的交换机网段并将其添加至数据源的白名单列表中。
通过公网访问:Serverless 资源组绑定的 VPC 需要有 NAT 网关实例(如无则请新建,具体步骤详见 如何创建 NAT 网关实例),并且绑定弹性公网 IP(EIP),Serverless 资源组才能通过 NAT 网关访问公网。如果已完成配置,您需要在公网 NAT 网关控制台,找到配置好的 SNAT 条目,获取对应交换机绑定的公网 IP 地址(EIP)并将其添加至数据源的白名单列表中。
步骤一:新建数据源
新建 MySQL 数据源
1. 进数据源页面。
- 登录 DataWorks 控制台,切换至目标地域后,单击左侧导航栏的更多-管理中心 ,在下拉框中选择对应工作空间后单击进入管理中心。
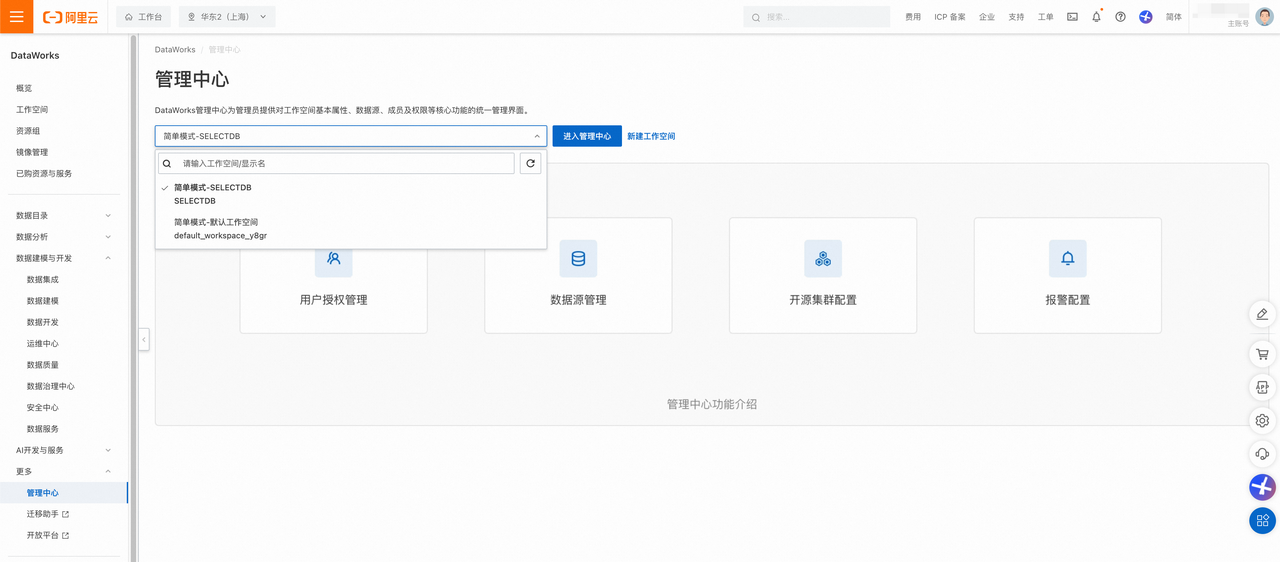
进入工作空间管理中心页面后,单击左侧导航栏的数据源 > 数据源列表,进入数据源页面。
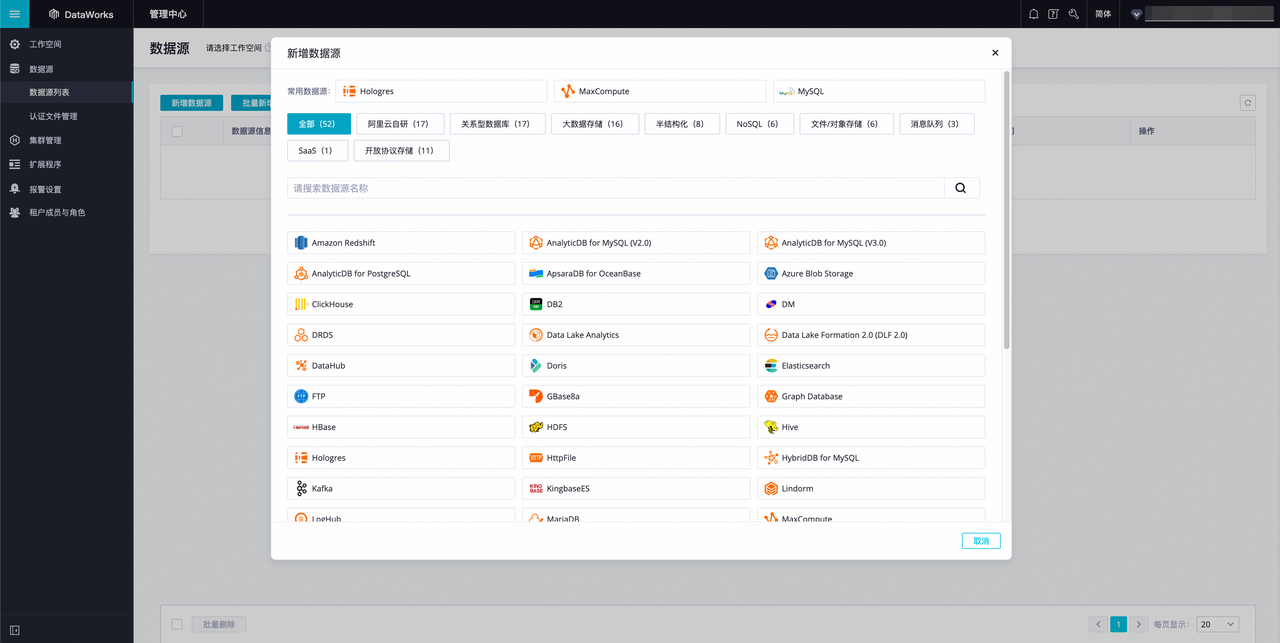
2.单击左上角新增数据源 按钮,在出现的新增数据源 弹窗内寻找并单击 MySQL 数据库,进入创建 MySQL 数据源页面。
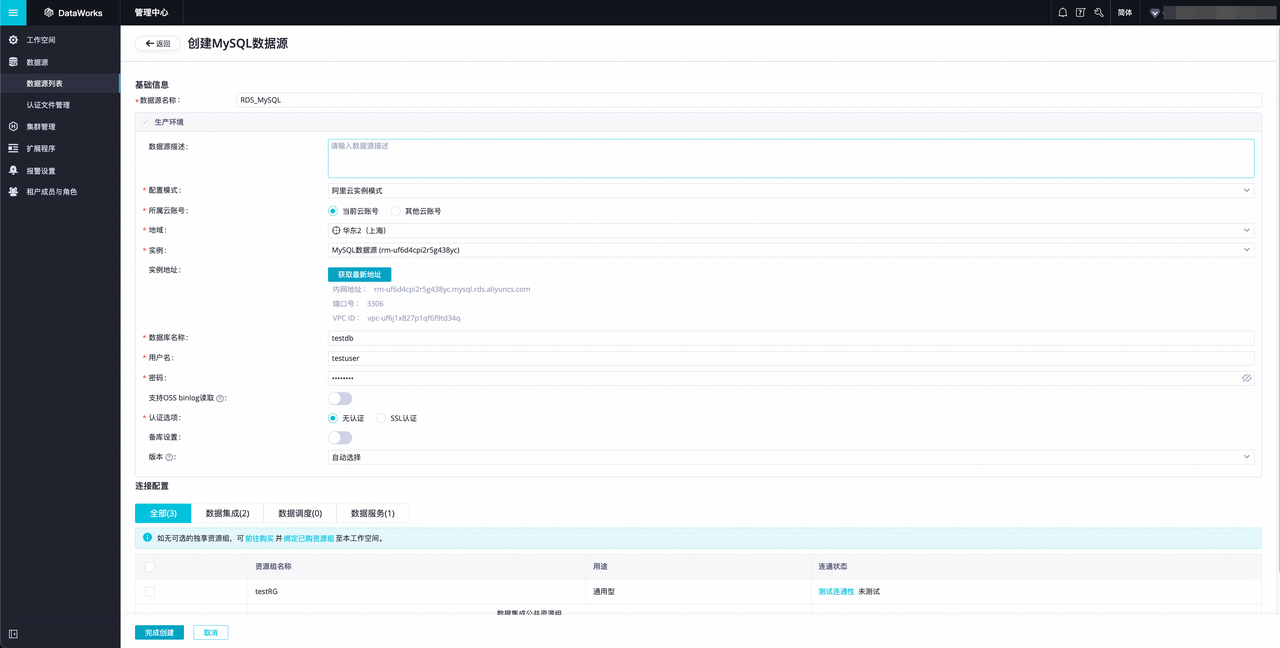
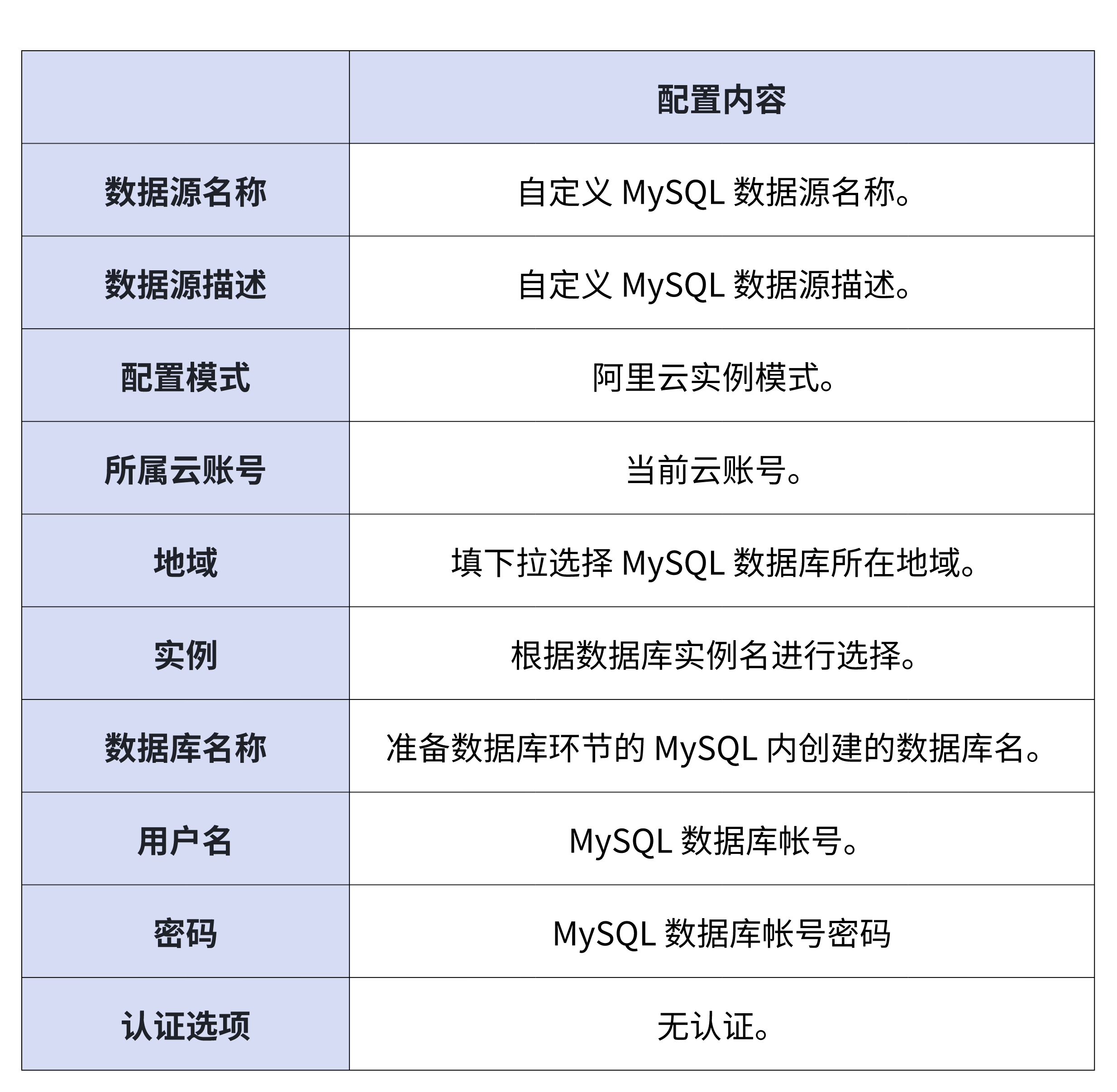
3.在创建 MySQL 数据源页面内,您可依据下表对 MySQL 数据源进行配置,未提及配置项保持默认即可。
说明: MySQL 数据源以阿里云上海地域当前账号下的 RDS MySQL 数据库 为例,若您的 MySQL 为其他类型,可参考 阿里云 DataWorks 支持的 MySQL 数据源。
4.在您填写完 MySQL 数据源的配置项后,请于连接配置 处,找到先前步骤中准备好的资源组,单击连接状态列-测试连通性 ,验证 Serverless 资源组与 MySQL 数据库之间的连通性。如果您在此过程中遇到任何问题,请根据连通性诊断工具报错信息解决处理。
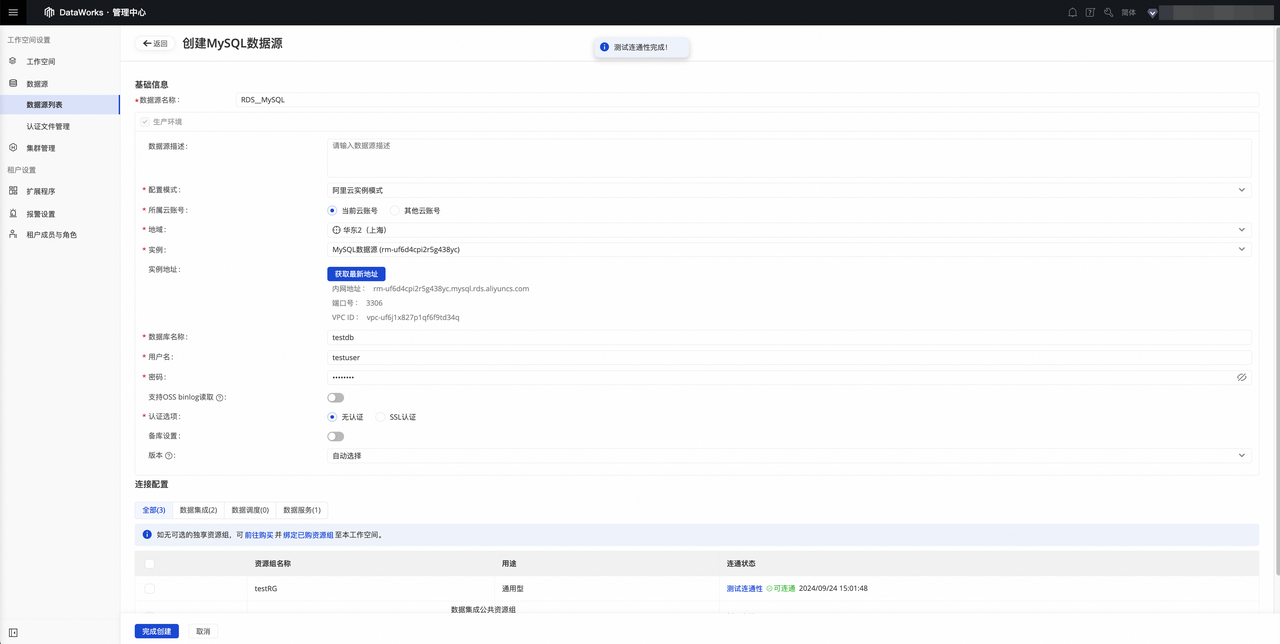
5.连通性测试通过后,单击完成创建,创建 MySQL 数据源。
新建 SelectDB 数据源
- 进入 DataWorks 工作空间管理中心到数据源页面后,单击左上角新增数据源 按钮,在出现的新增数据源 弹窗内寻找并单击 SelectDB 数据库,进入创建 SelectDB 数据源页面。
2.在创建 SelectDB 数据源页面内,您可依据下表对 SelectDB 数据源进行配置,未提及配置项保持默认即可。
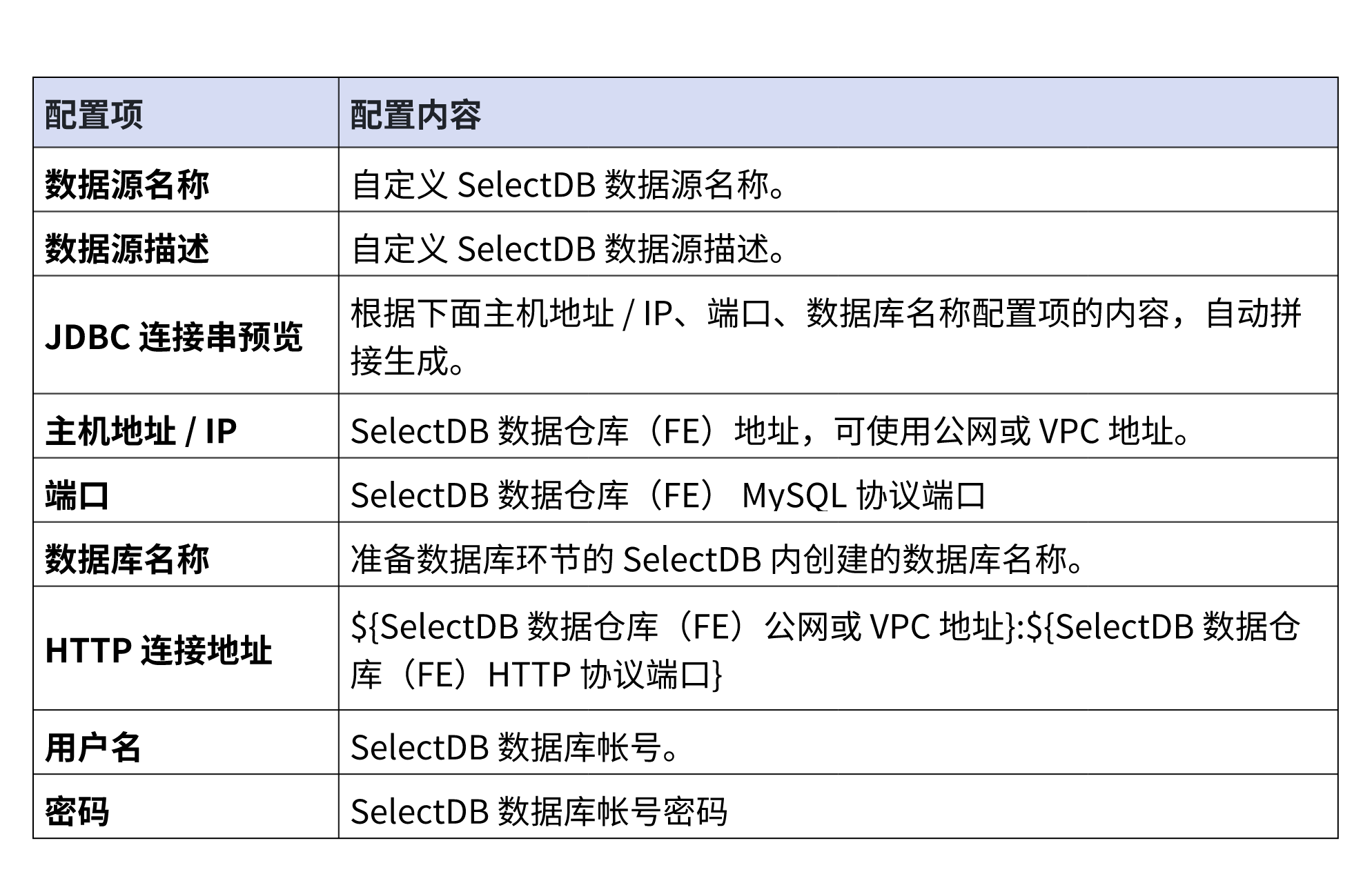
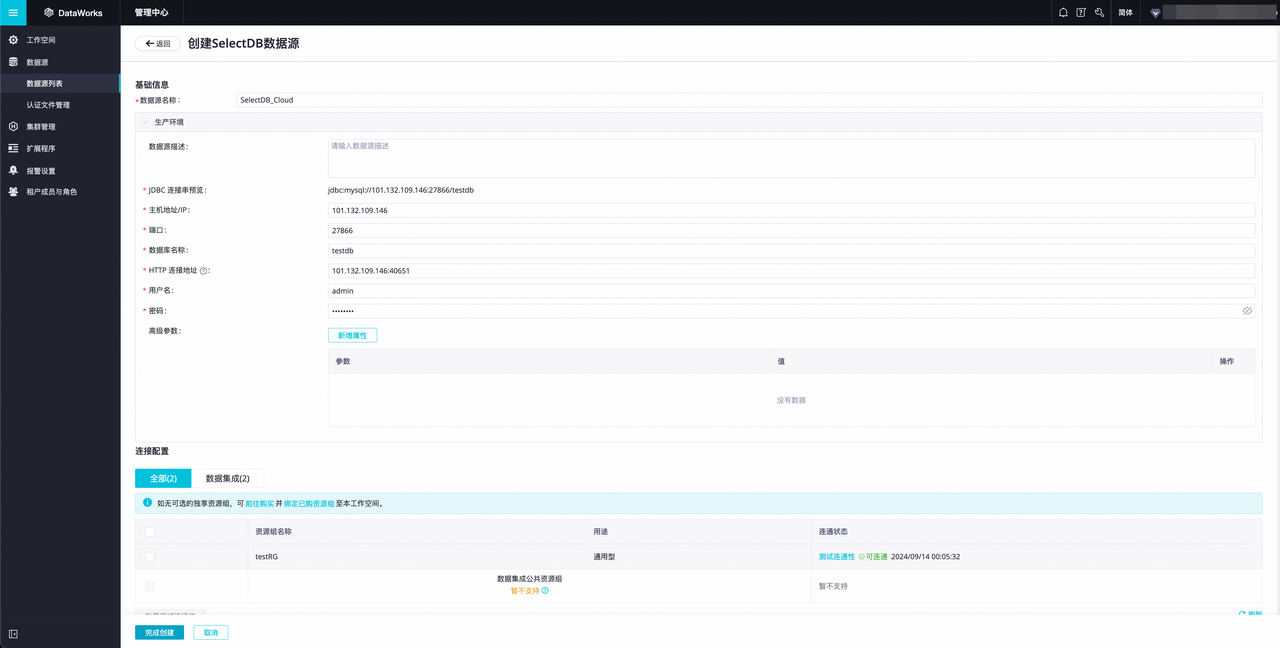
说明: SelectDB 数据源以阿里云上海地域的 SelectDB Cloud 数仓为例,若您的 SelectDB 为其他类型,可参考 阿里云 DataWorks 支持的 SelectDB 数据源。
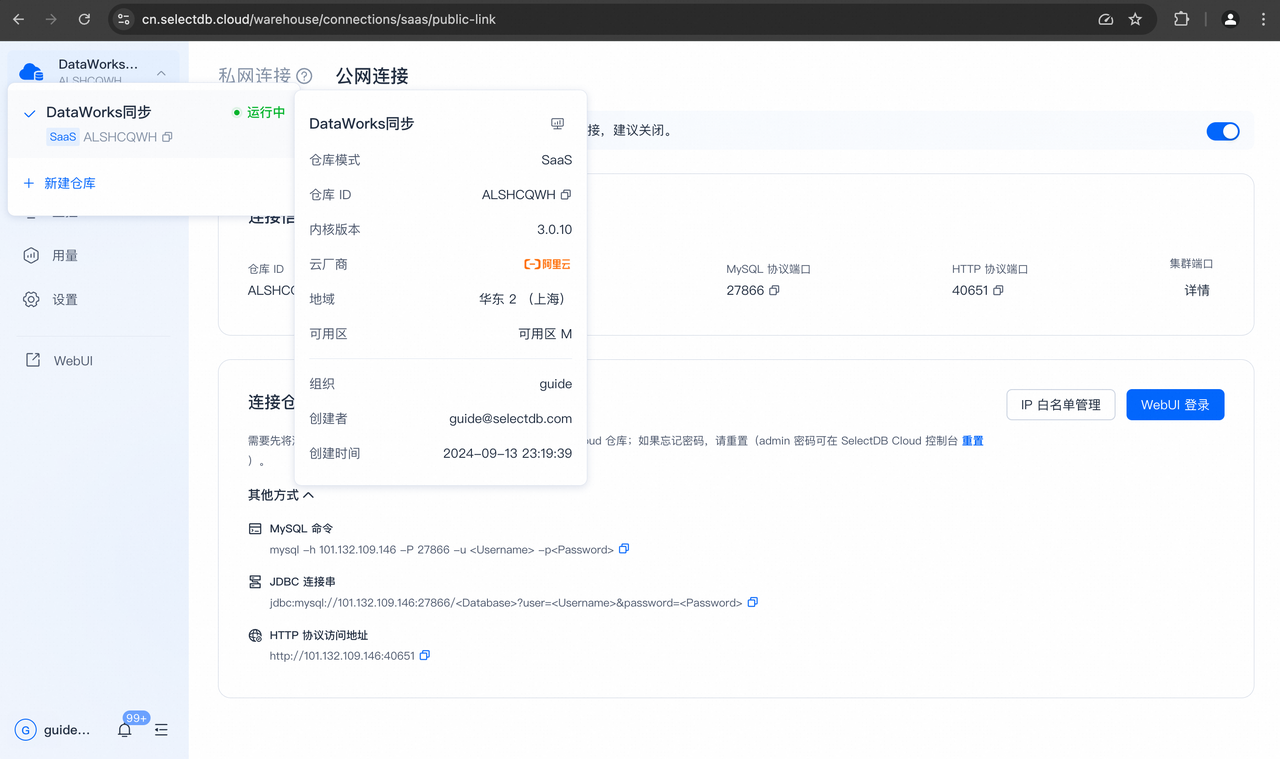
提醒:
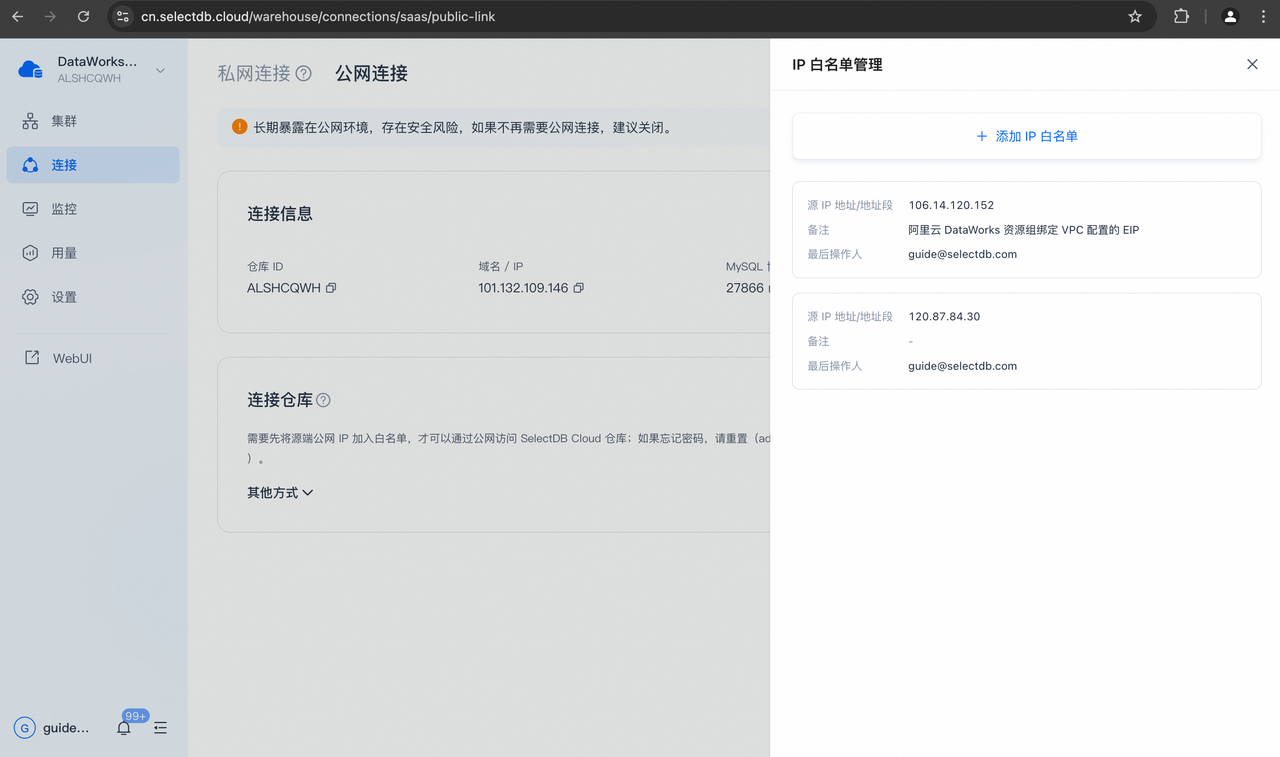
本文以公网连接 SelectDB Cloud 数仓为例,您需要将 Serverless 资源组绑定 VPC 配置的 EIP 添加至其白名单中。
在生产环境中,建议通过私网连接 SelectDB Cloud 数仓(具体步骤详见 如何私网连接 SelectDB Cloud 数仓)。您需要将 Serverless 资源组绑定的交换机网段 IP,添加到已绑定 VPC 内的安全组的访问控制列表中,以允许 Serverless 资源组访问终端节点,从而通过 PrivateLink 私网连接 SelectDB Cloud 数仓。
3.在您填写完 SelectDB 数据源配置项后,您可在连接配置 处,找到先前步骤中准备好的资源组,单击连接状态列 > 测试连通性 ,验证 Serverless 资源组与 SelectDB 数据库之间的连通性。如果您在此过程中遇到任何问题,请根据连通性诊断工具报错信息解决处理。
4.连通性测试通过后,单击完成创建,创建 SelectDB 数据源。
步骤二:创建同步任务
进入数据集成页面
登录 DataWorks 控制台,切换至目标地域,单击左侧导航栏的数据建模与开发 > 数据集成 ,在下拉框中选择对应工作空间后,单击进入数据集成页面。
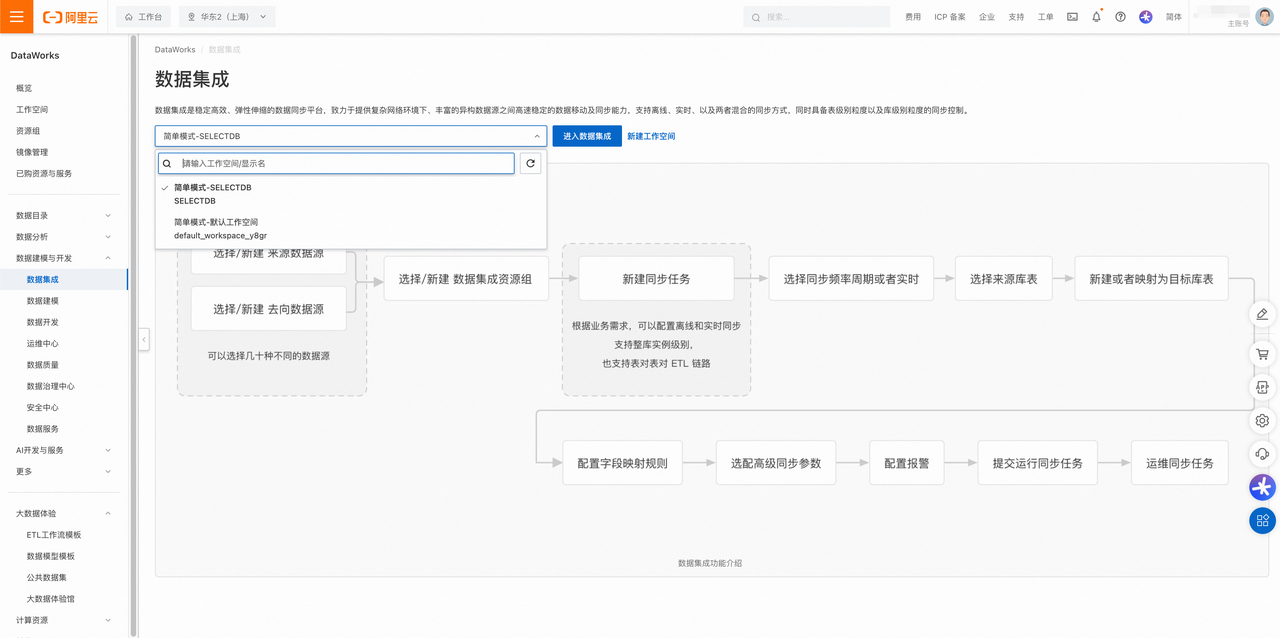
配置来源与去向数据源
- 单击数据集成页面左侧导航栏中同步任务,选择来源为 MySQL 数据源 ,选择去向为 SelectDB 数据源。
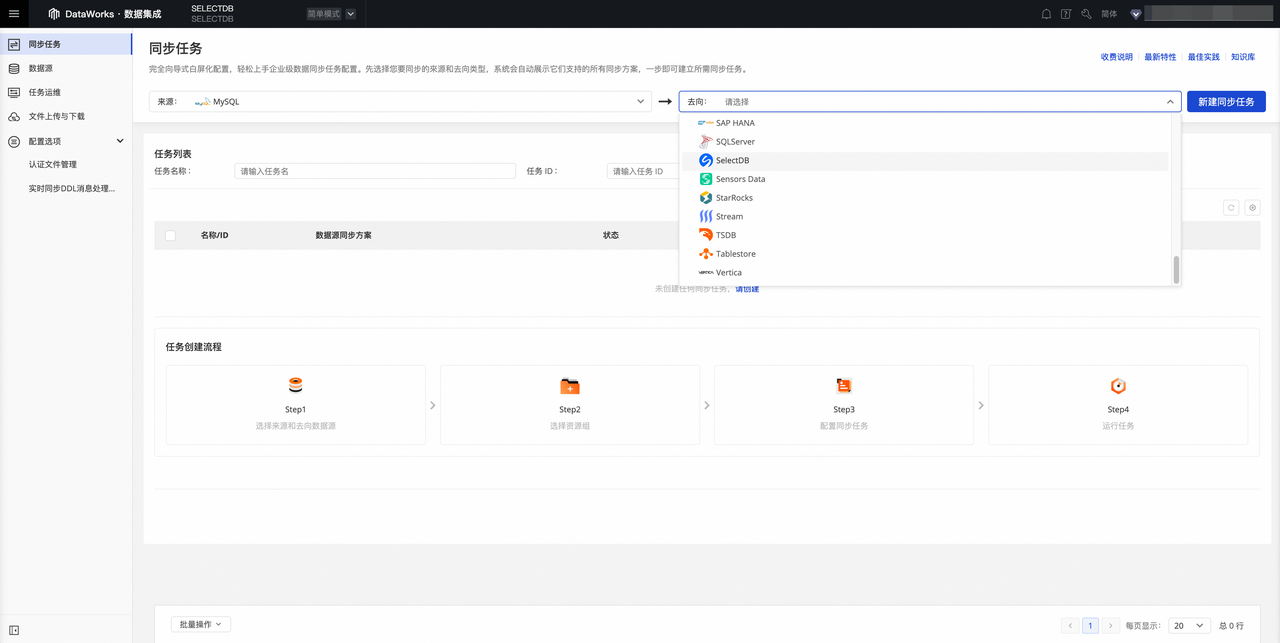
2.完成数据源选择后,单击开始创建,进入数据集成任务配置页面。
配置同步方式
- 在新建同步任务页面,您需要在基本配置与网络资源配置中分别配置以下内容:
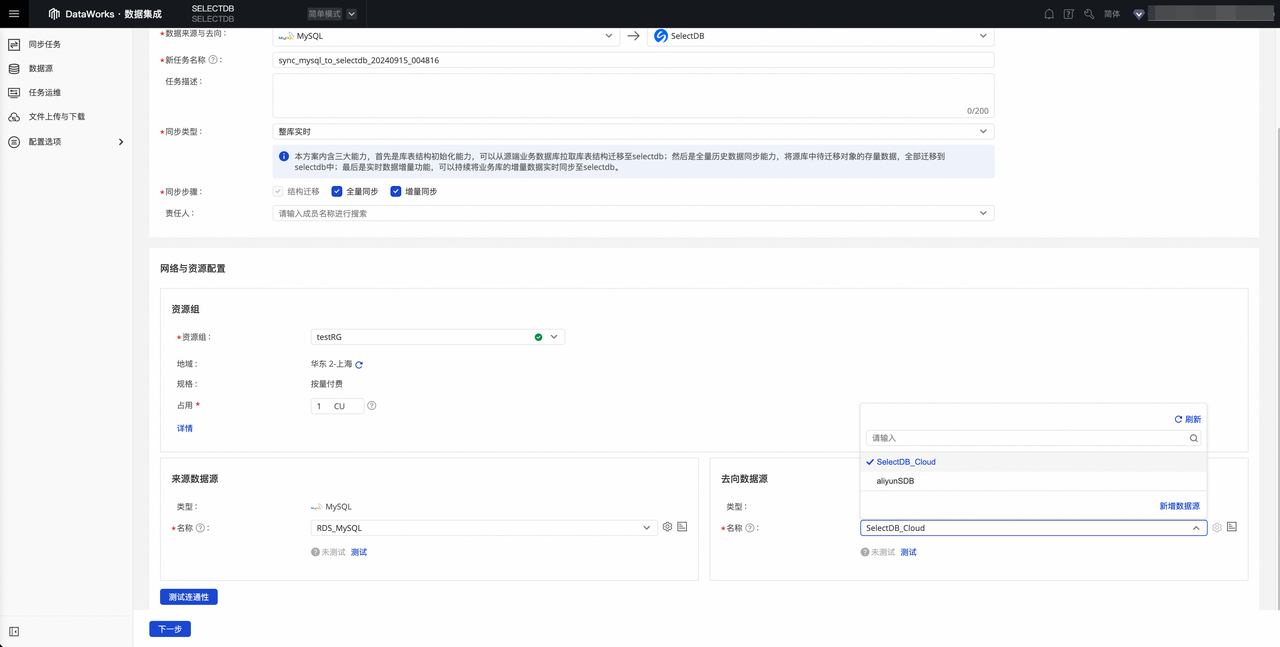
2.完成基本配置、网络与资源配置后,单击下一步进入下一阶段。
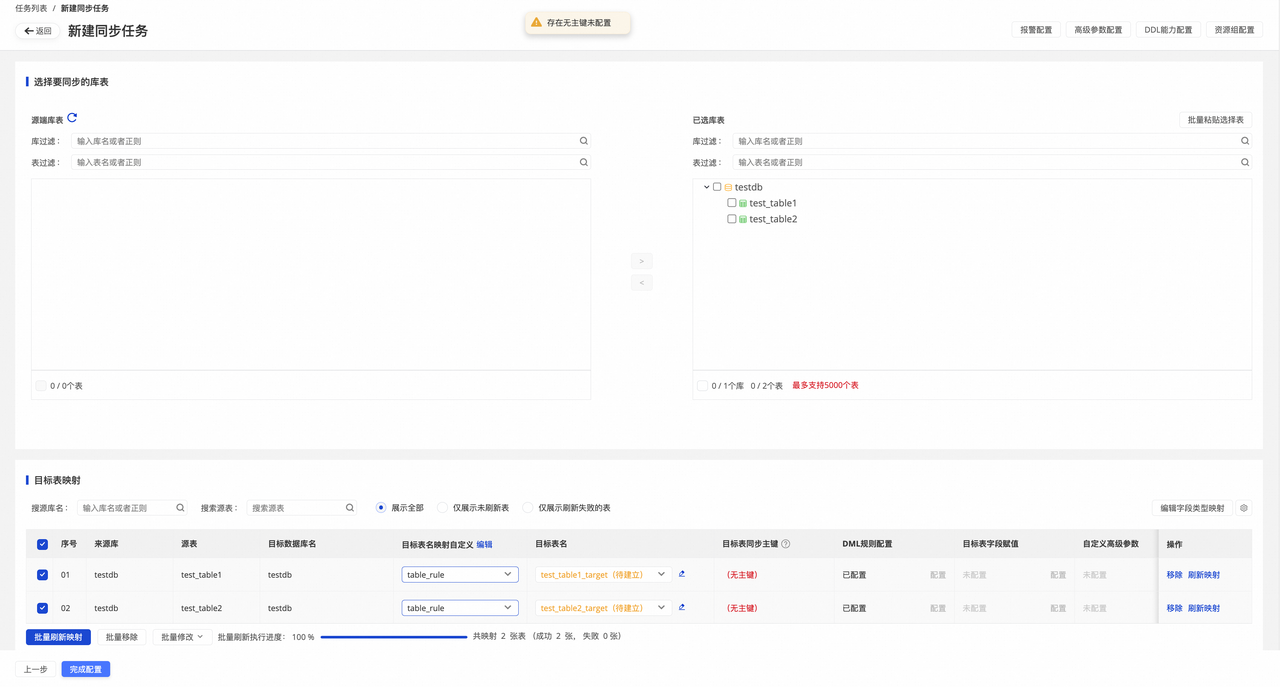
选择要同步的库表
在源端库表 内容区域勾选您想要同步的数据库和数据表,单击屏幕中央向右按钮(下图已标注),将数据库和表加载到已选库表内容区。
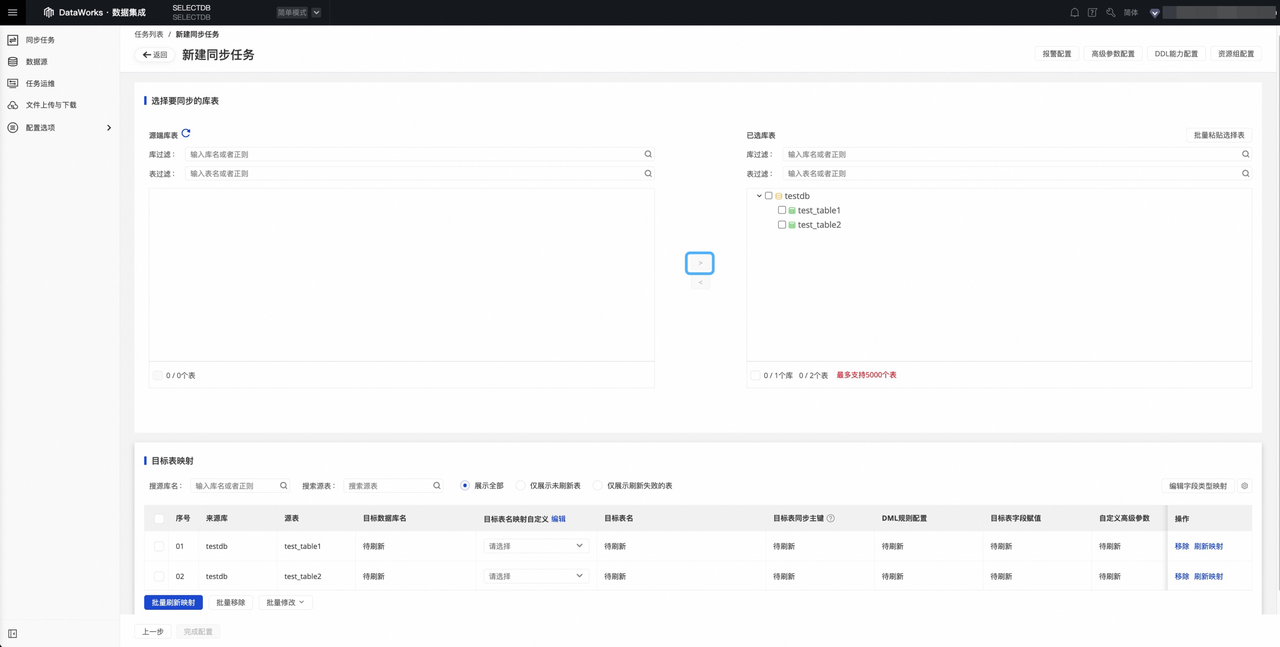
目标表映射
- 编辑数据读取与写入关系。
完成同步库表选择后,将自动在此页面展示当前待同步的表,目标表的相关属性默认为待映射状态,需要您定义并确认源表与目标表映射关系,即数据的读取与写入关系,确认并单击刷新映射以继续后续步骤。您可选择直接刷新映射,或自定义目标表规则后,再进行刷新。
说明:
您可以选中待同步表后,单击批量刷新映射 ,未配置映射规则时,默认表名规则为
${来源库名}_${源表名},若目标端不存在同名表时,将自动新建。您可以自定义目标表名规则,在目标表名映射自定义 列,单击编辑按钮。可以使用内置变量和手动输入的字符串拼接成为最终目标表名。例如,新建一个表名规则,将源表名增加后缀作为目标表名。
同步至 SelectDB 需要指定目标表的主键,默认会使用和源表一致的主键,需确保源表包含主键。目标表的主键是用于同步写入时做数据去重所使用,请根据自己的业务需求在建表时合理设置。
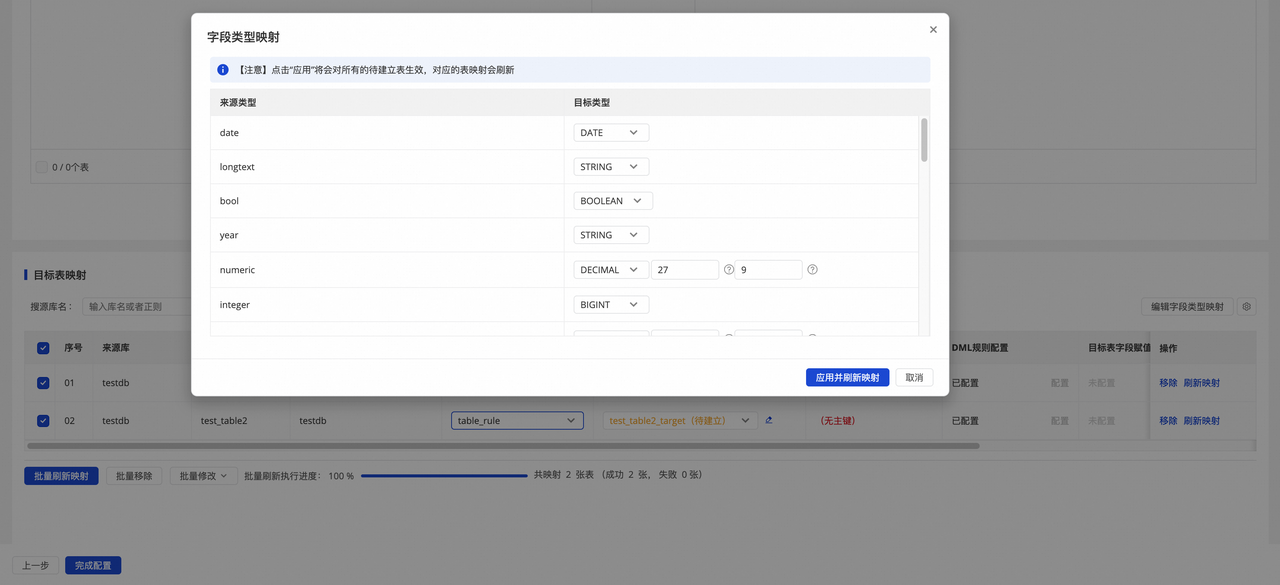
2.编辑字段类型映射。
同步任务存在默认源端字段类型与目标端字段类型映射,您可单击右上角编辑字段类型映射 ,自定义源端表与目标端表字段类型映射关系,配置完后单击应用并刷新映射。
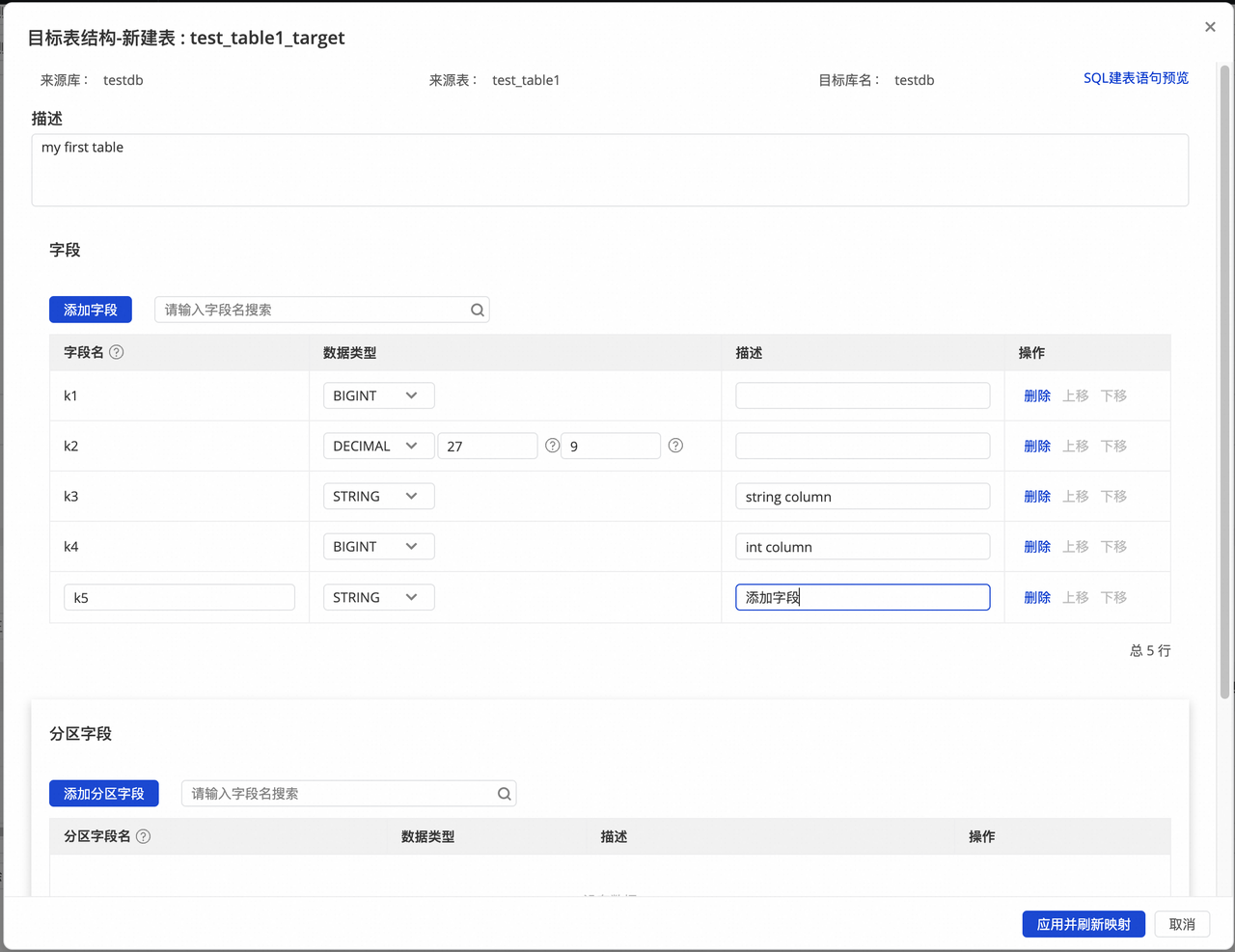
3.编辑目标表结构。
当目标 SelectDB 表为待建立 状态时,您可以在原有表结构基础上为目标表新增字段。您可单击目标表名列的编辑图标以添加字段。
配置其他项
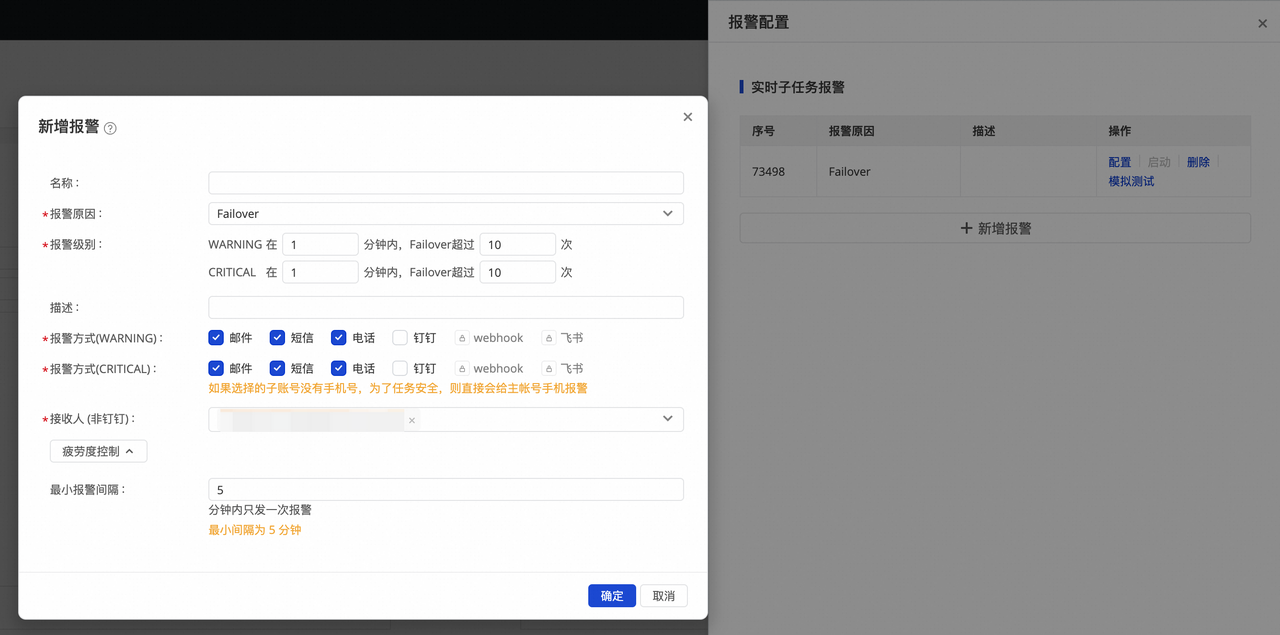
- 报警配置。
为避免任务出错导致业务数据同步延迟,您可以对实时同步子任务设置不同的报警策略。
-
单击页面右上方的报警配置,进入实时同步子任务报警设置页面。
-
单击新增报警,配置报警规则。
-
管理报警规则。您可以根据报警级别将报警发送给不同的人员。
2.高级参数配置。
数据集成提供读端最大连接数 、写端缓冲区大小 、运行时任务并发度等配置的默认值。如果您需要对任务做精细化配置,达到自定义同步需求,您可对参数值进行修改,例如通过最大连接数上限限制,避免当前同步方案对数据库造成过大压力从而影响生产。
-
单击界面右上方的高级参数配置,进入高级参数配置页面。
-
在高级参数配置 页面基于业务需要与资源组、数据库实际情况配置读端 。 源端最大连接数:通过该参数,您可以控制当前同步方案所能使用的源端数据库连接数,即同一时间内,当前同步解决方案任务读取数据库的并发数上限。
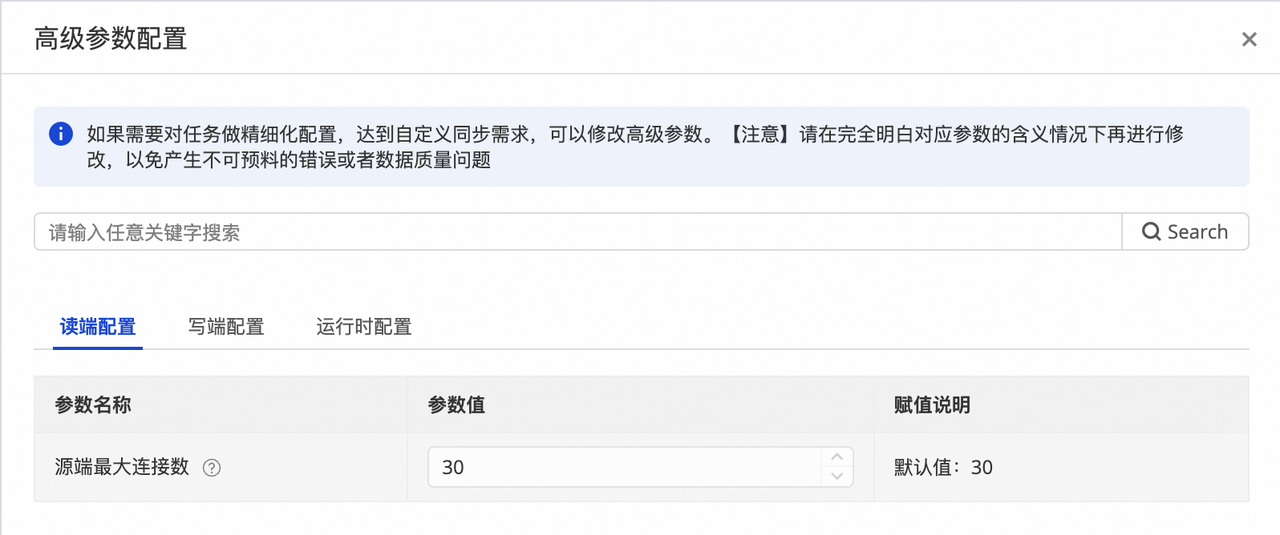
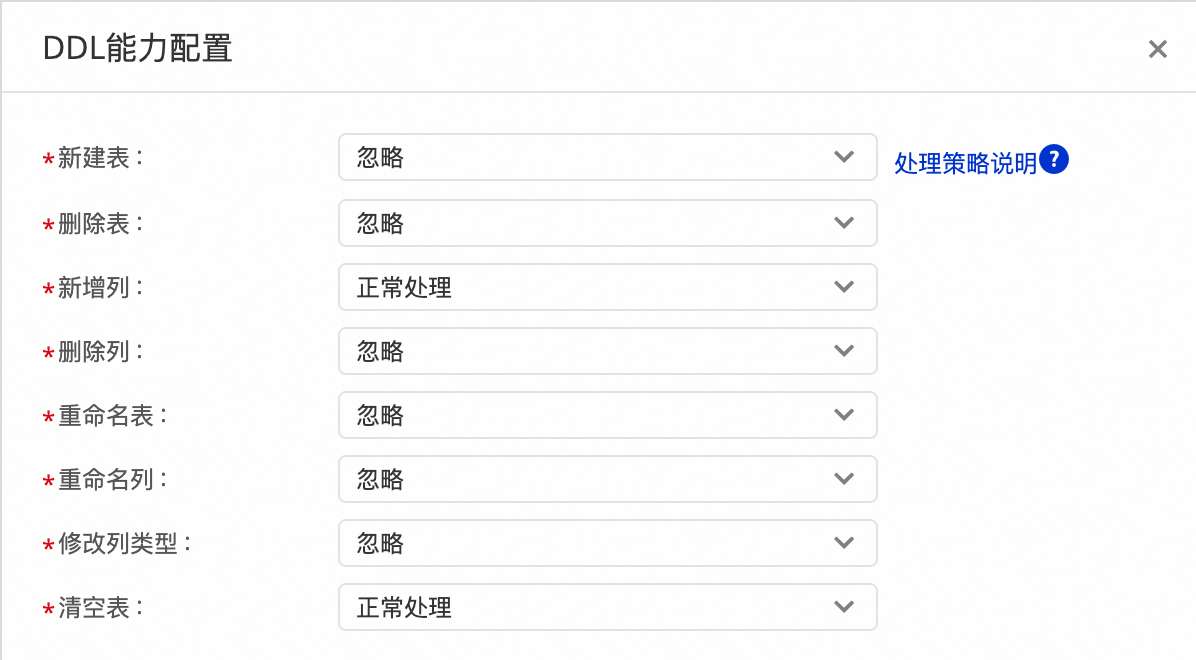
3.DDL 能力配置。
来源数据源会包含许多 DDL 操作,您可根据业务需求,在界面右上方单击 DDL 能力配置,进入 DDL 能力配置页面,对不同的 DDL 消息设置同步至目标端的处理策略。
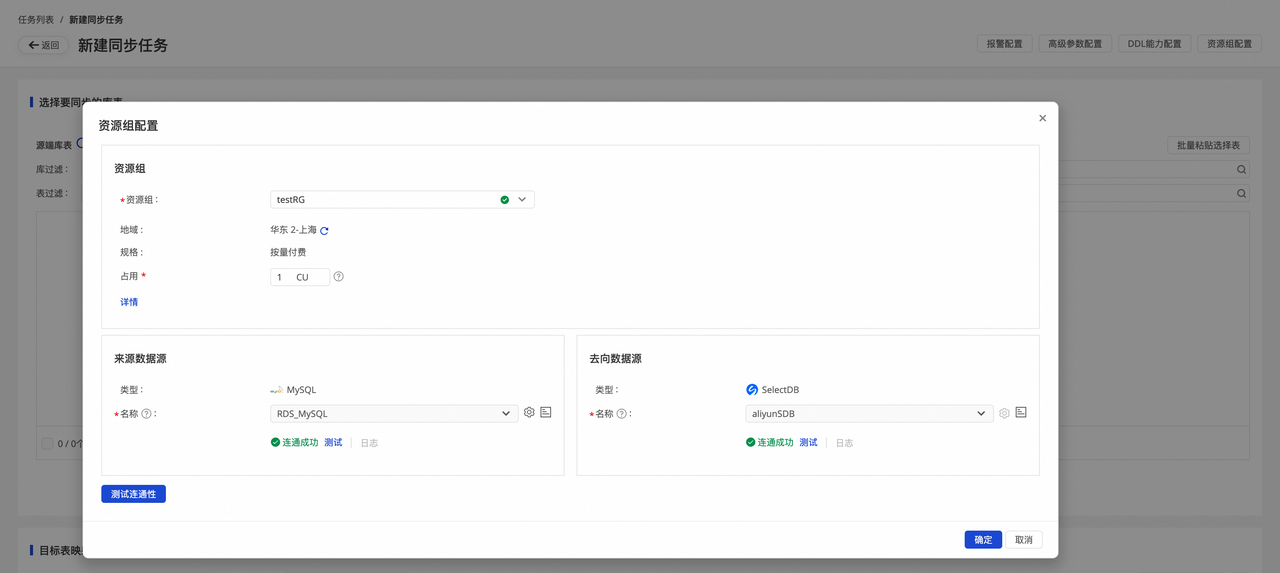
4.资源组配置。
您可单击界面右上方的资源组配置,查看并切换当前的任务所使用的资源组。
完成以上配置后,单击完成配置,完成数据集成的同步任务配置。
步骤三:运维同步任务
启动同步任务
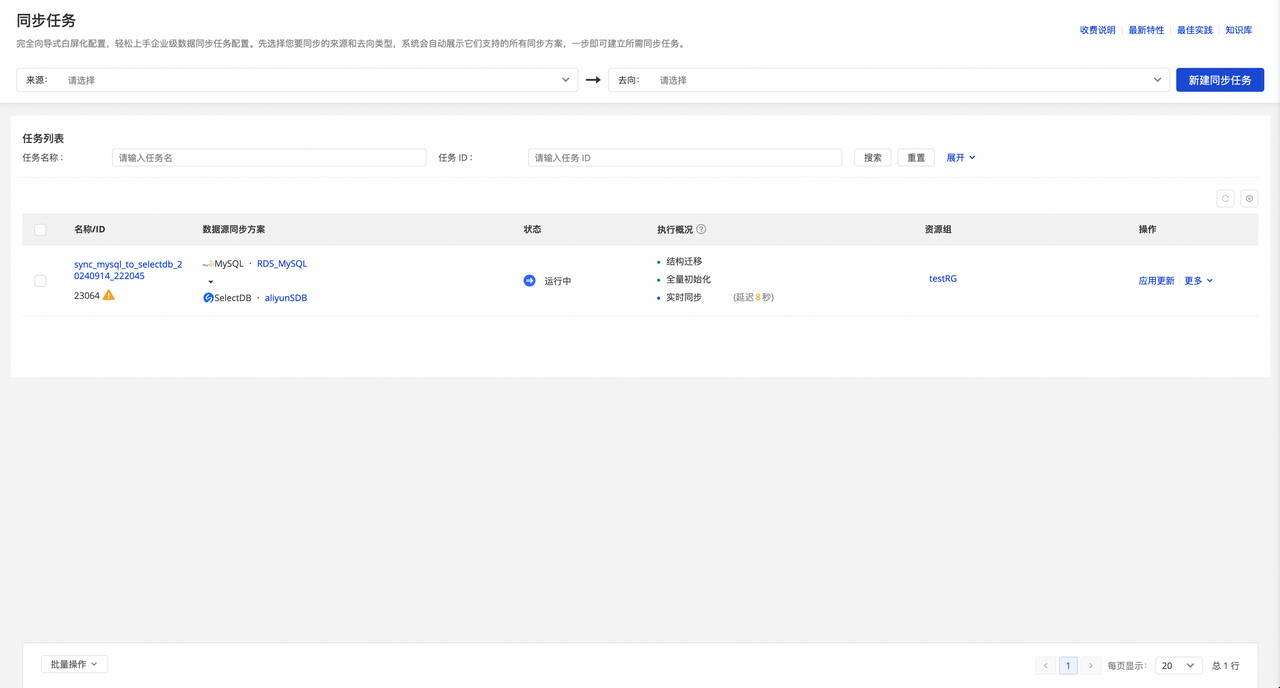
完成配置后,跳转至任务列表 ,您可单击对应任务的启动按钮,启动同步任务。
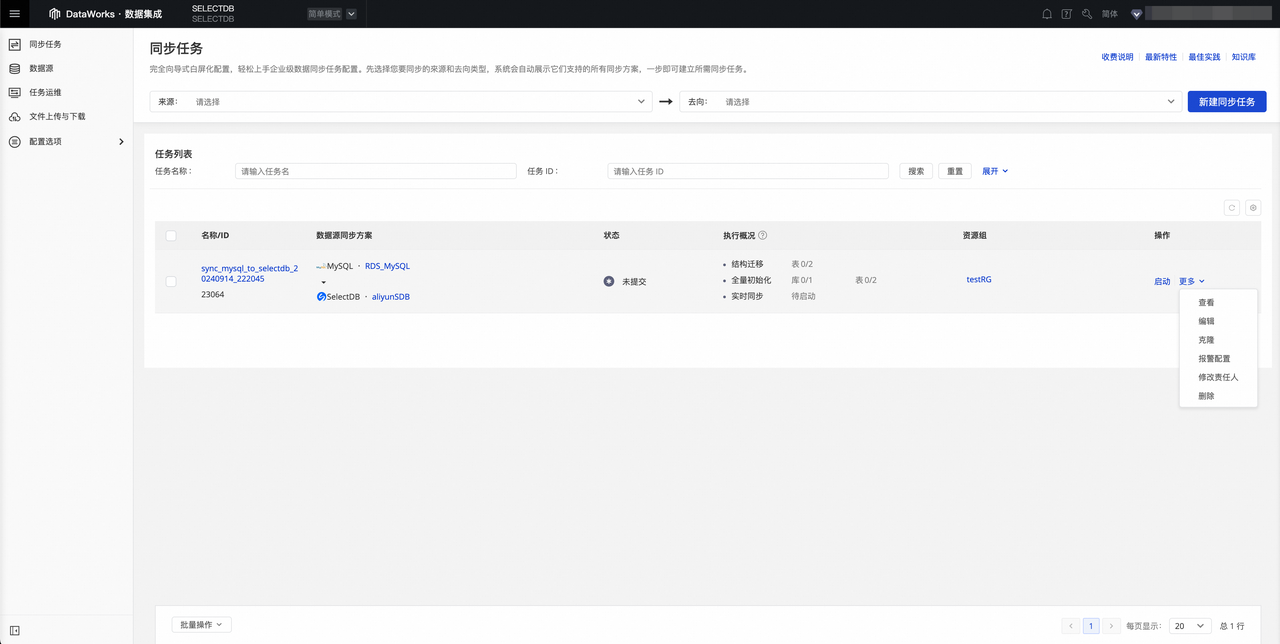
查看同步任务运行状态
创建完成同步任务后,您可在同步任务页面,找到已创建的同步任务,单击任务名称 或执行概览,查看任务运行详情。任务运行详情分为以下五个部分:
-
基本信息:同步任务的数据源信息、绑定的资源组、同步方案等信息。
-
执行状态 :分为结构迁移 、全量初始化 以及实时数据同步 三个状态,以下为执行状态的详细信息:
-
结构迁移:包含目标表的创建方式(已有表或自动建表),如果是自动建表,将会为您展示建表的 DDL。
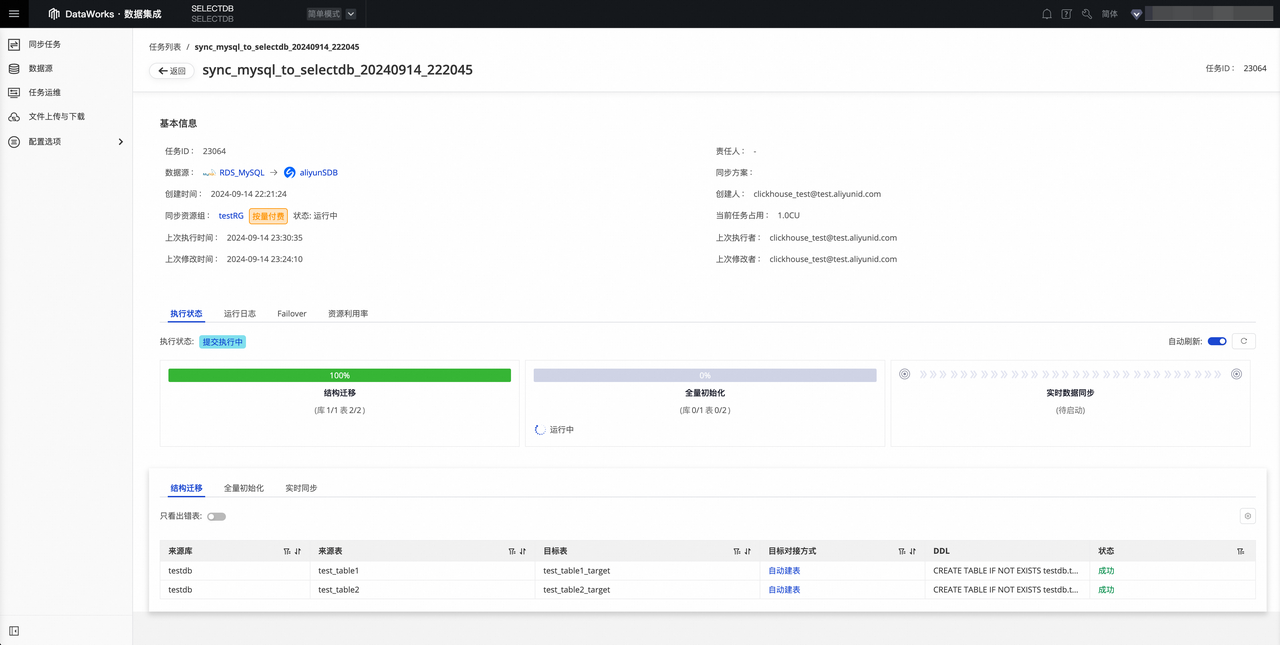
-
全量初始化 :包含对来源表与目标表数据的全量进度 、已写入数据条数 、全量启动时间 、全量完成时间展示。
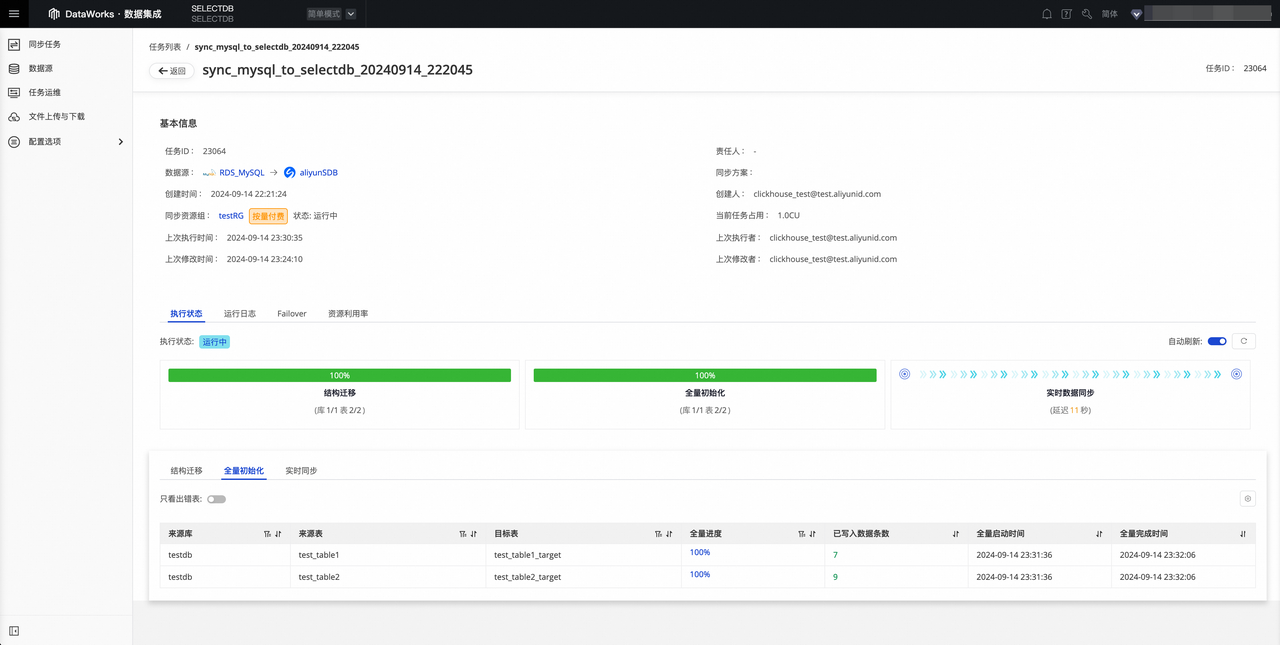
-
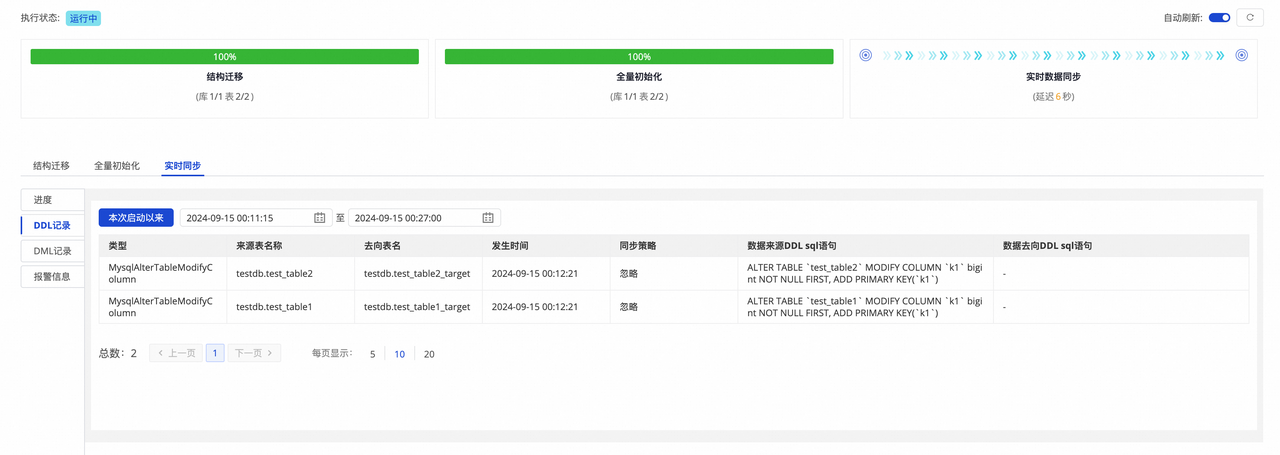
实时同步 :包含实时同步的统计信息,包含实时集成进度 、DDL 记录 、DML 记录 和报警信息的展示。
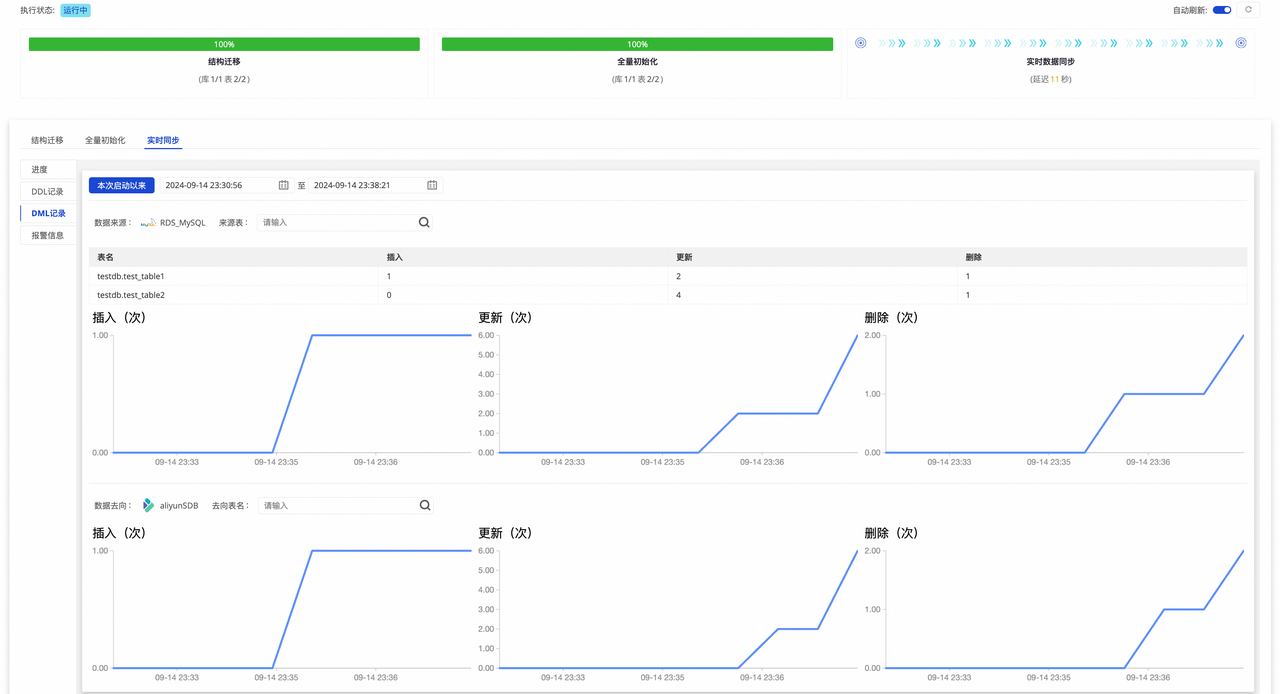
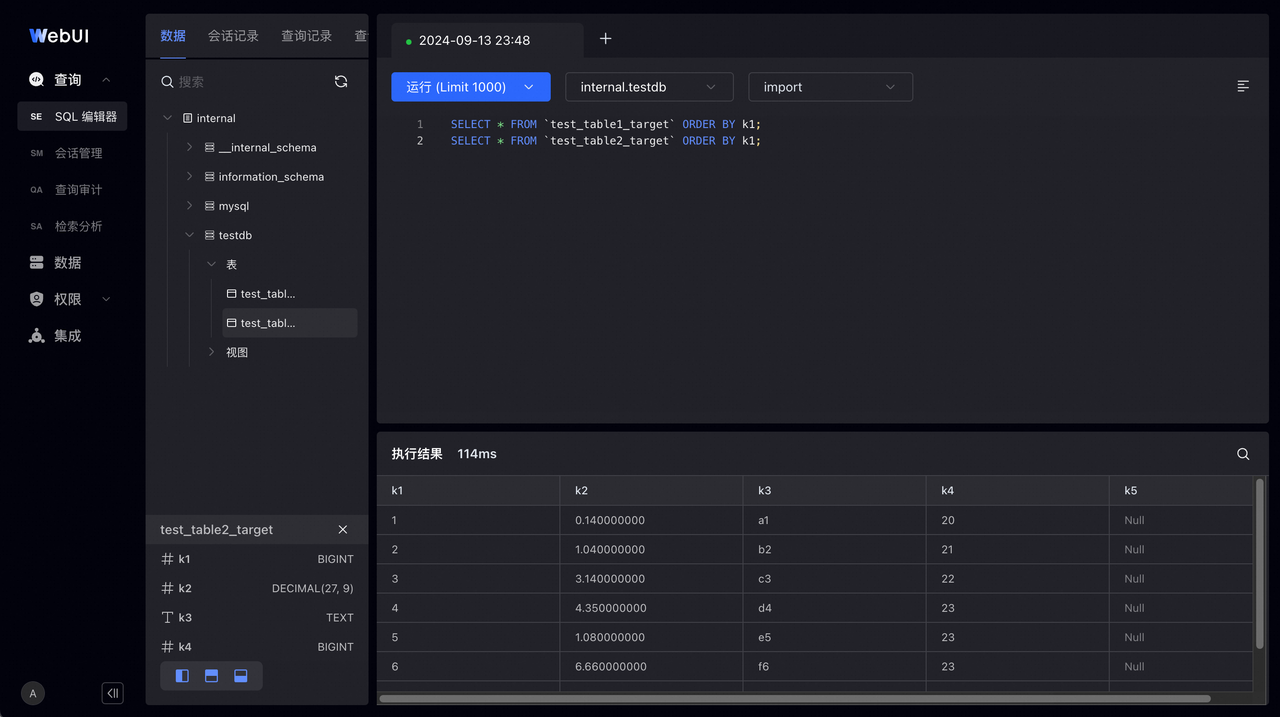
源库表结构和数据:
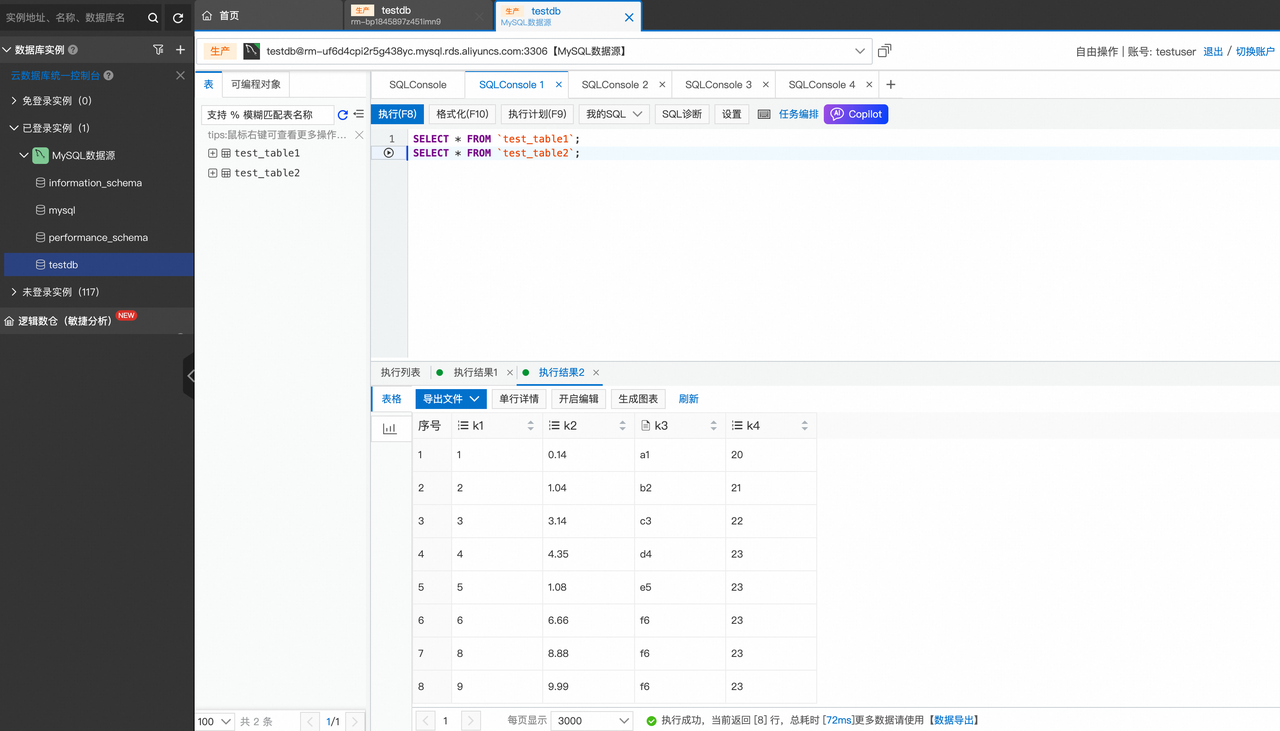
目标库表结构和数据:
3.运行日志 :数据同步采取了主从架构(master-worker 架构),其中包含 Master 和 Worker,一个同步解决方案任务对应一个 master 和一个或多个 worker,您可在对应日志中查看相关步骤详细信息。
-
Master:任务初始化、数据分片、worker 的协调。
-
Worker:具体数据分片的读写、转换。
4.Failover :包含了数据同任务中出现的 Failover 事件的详细时间与报错信息,您可查看同步任务在最近一次启动以来的异常恢复记录。
5.资源利用率:对数据集成任务占用的资源状况进行监控及查看,可根据实际使用率对资源占用做调整。
任务重跑
-
直接重跑。
在不修改任务配置的情况下,您可直接单击同步任务操作列更多 > 重跑,重新运行从结构迁移到启动实时同步的流程。
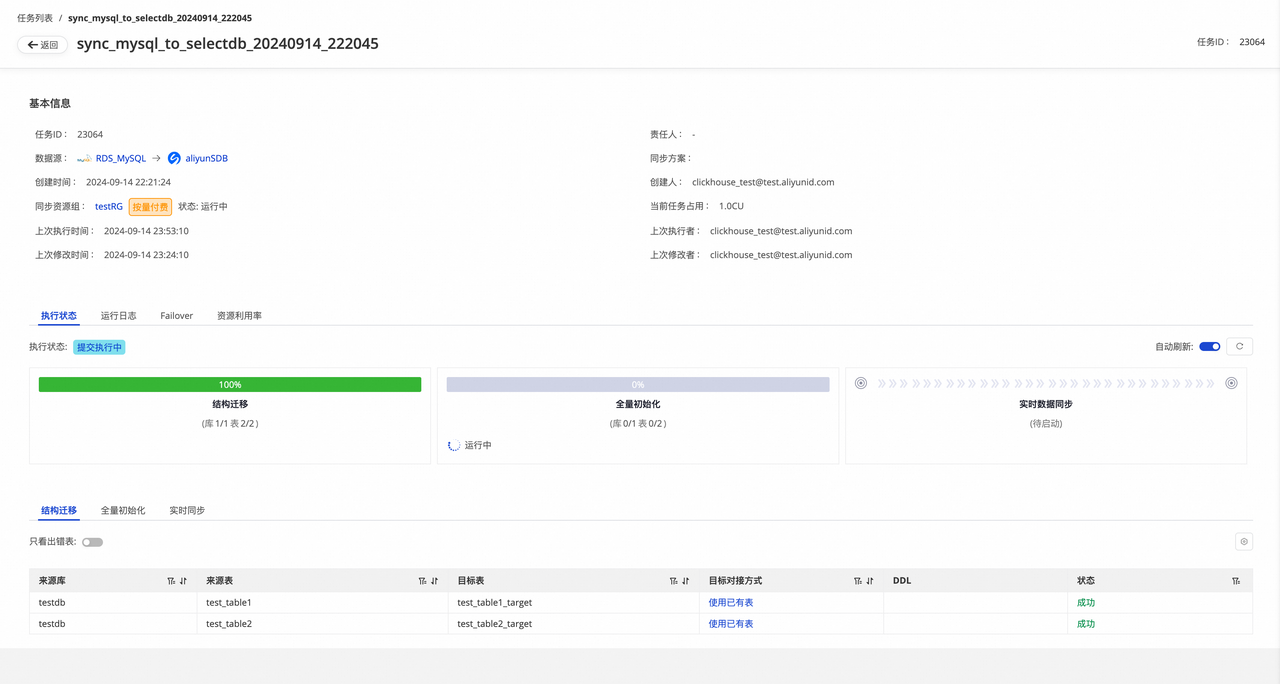
- 结构迁移:使用已有表,不会再创建新表,因此没有建表的 DDL。
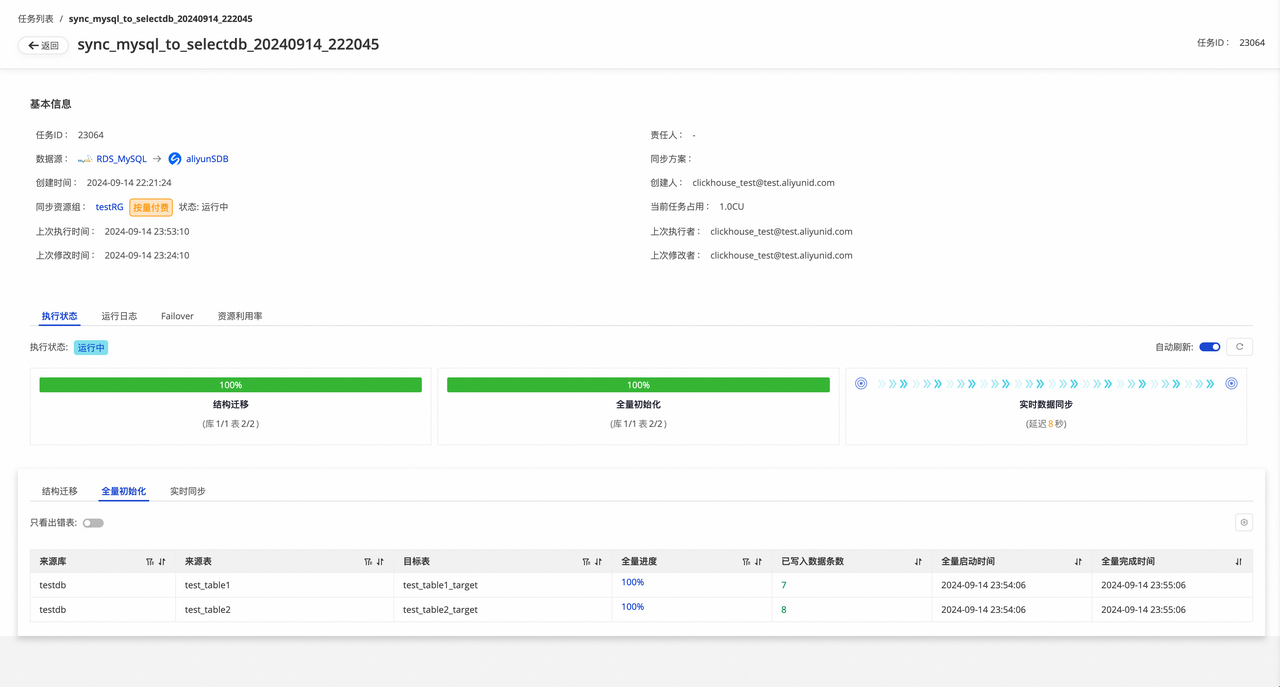
- 全量初始化 :对源库表目前的全量数据进行一次性同步,可以发现已写入数据条数 、全量启动时间 、全量完成时间与第一次同步时不同。
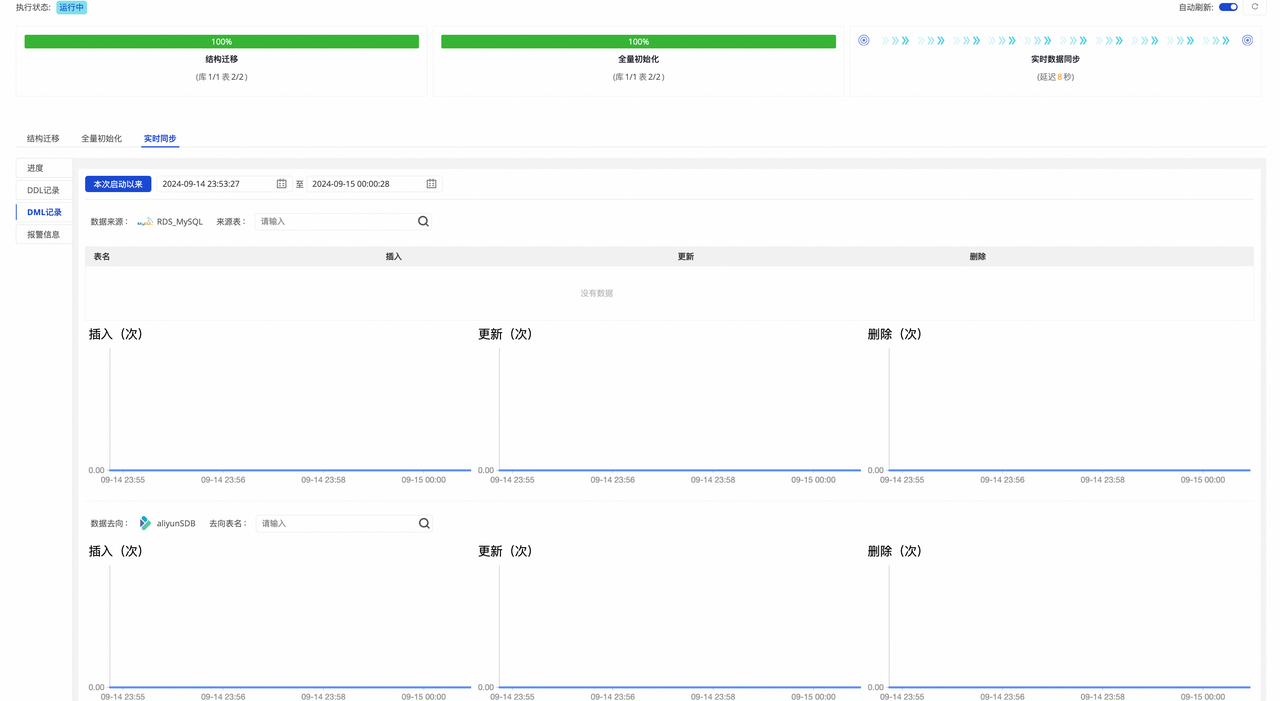
- 实时同步:由于重跑任务后,源库表数据没有增量变化,因此实时同步没有数据。
-
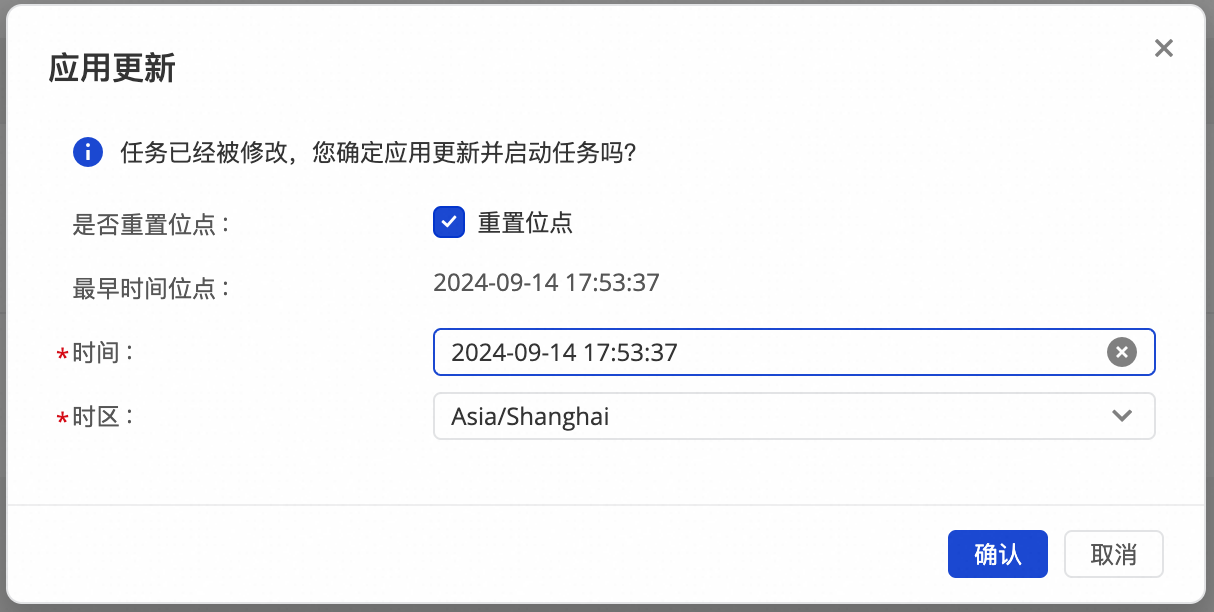
修改后重跑。
编辑任务,进行修改操作后,单击完成 。此时任务的操作会变为应用更新 ,点击应用更新会直接触发修改后的任务重跑,实时同步任务会按照新的配置运行。
可选择重置位点的时间和时区:
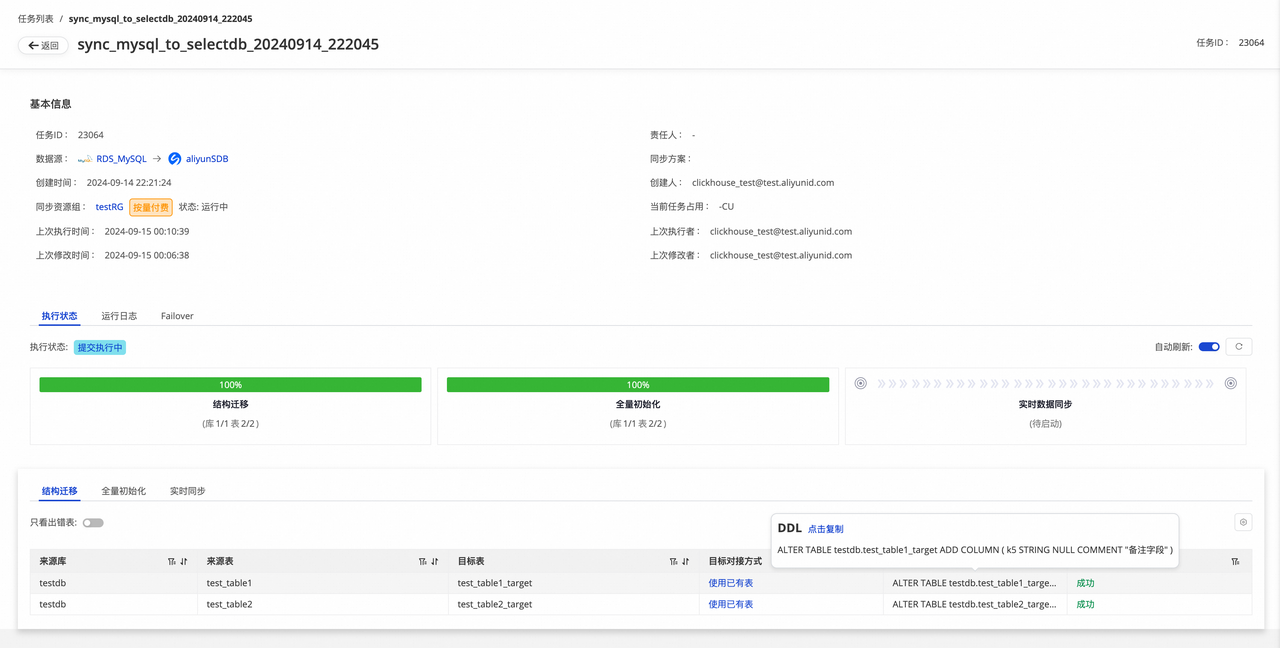
- 结构迁移:修改后重跑任务时,使用的仍为已有表,不会创建新表,但会按修改后的任务添加了字段,所以有 ALTER TABLE 的 DDL。
-
全量初始化:由于选择了重置位点重跑,因此会将源库表的变更日志发送到目标库表重新执行,不需要进行全量数据同步。
-
实时同步:由于选择了重置位点重跑,因此会将源库表的变更日志发送到目标库表重新执行。可以看到所设置位点时间后所有的 DML 都被执行了一遍。
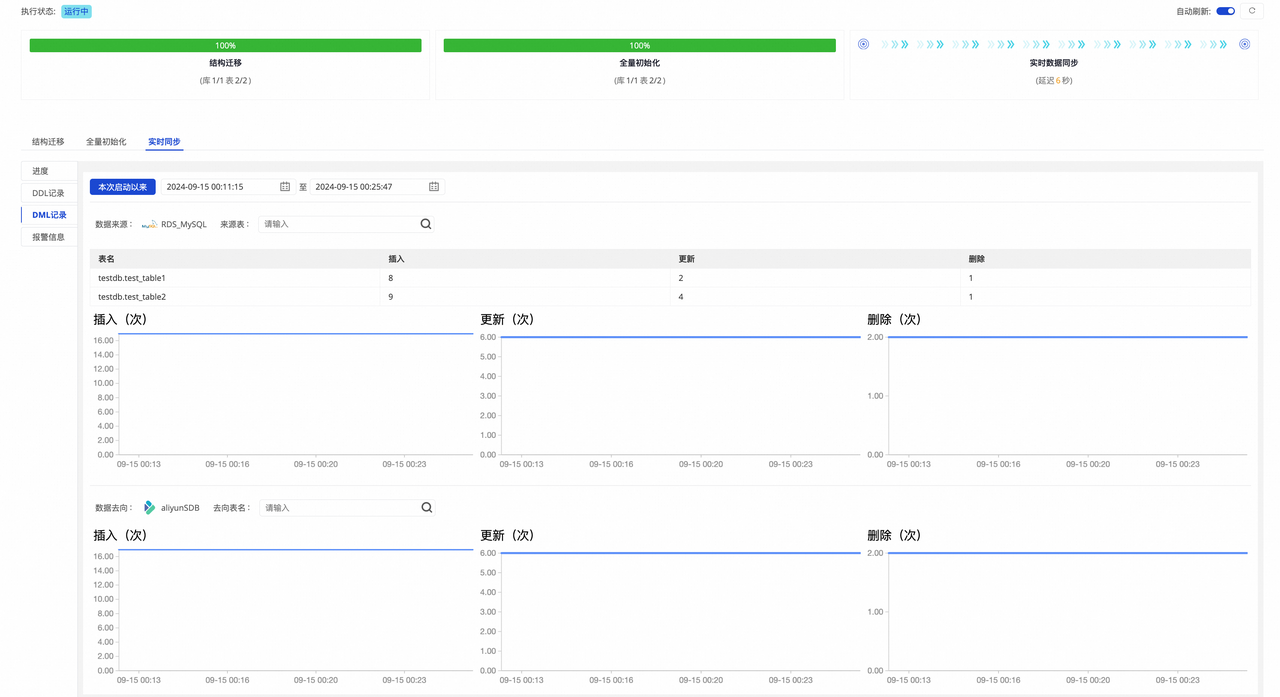
由于任务的 DDL 能力配置 对修改列类型设置了"忽略"同步至目标端的处理策略,因此可以看到修改列类型的 DDL 被忽略了,并未同步至目标端。
总结语
以上即为将 MySQL 整库实时同步至 SelectDB Cloud 的具体操作步骤。通过使用 Dataworks,您能够高效地将 MySQL 数据库同步至 SelectDB Enterprise、SelectDB Cloud、阿里云数据库 SelectDB 版与 Apache Doris 中,确保业务连续性不受影响。 同时,凭借 SelectDB 极速分析性能和灵活弹性优势,您能够加速决策过程,优化业务运营效率,推动业务持续稳健增长。