首先仍然是先登录大模型体验平台
https://xihe.mindspore.cn/my/clouddev
启动!!
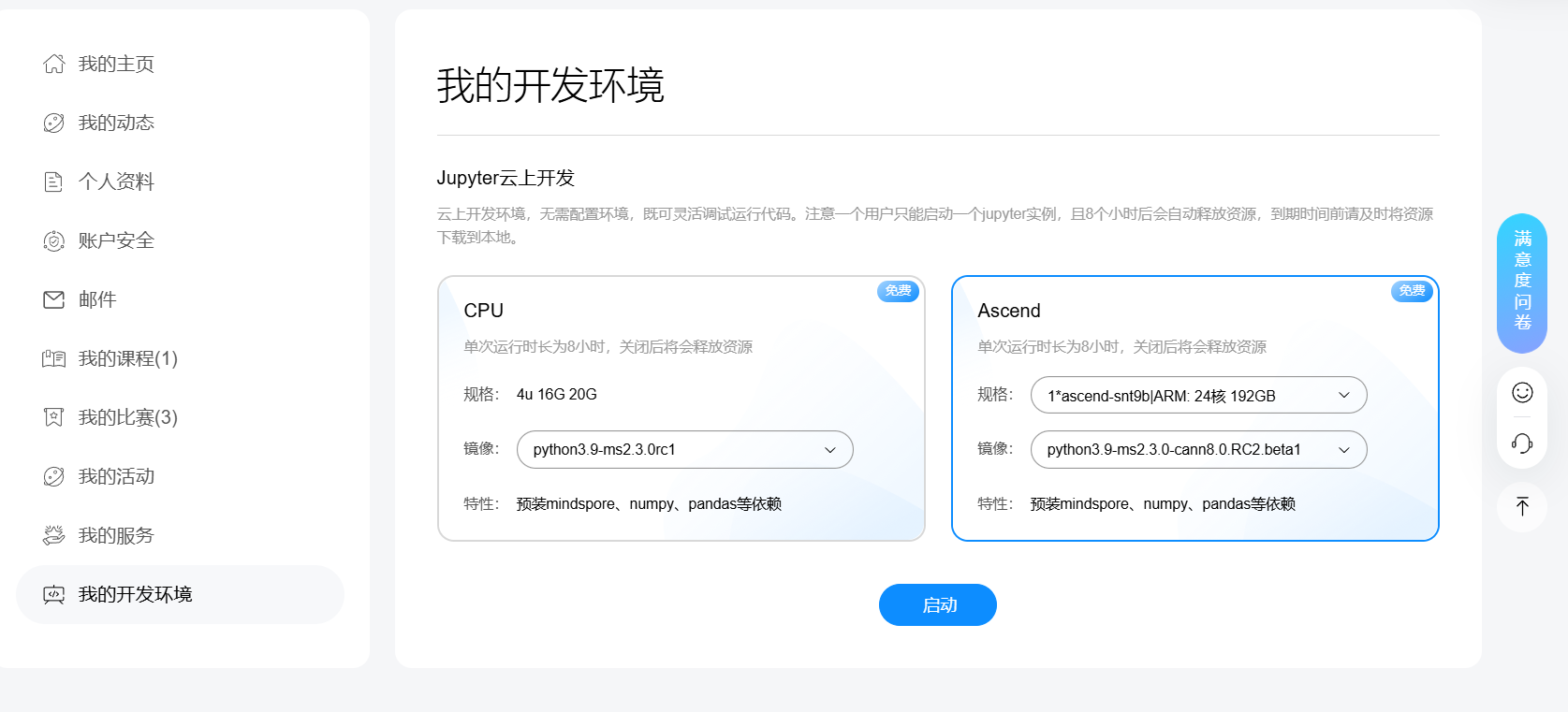
进入环境之后,即可开始运行notebook,
Transformer 模型与实现
Transformer 是一种由 Vaswani 等人在 2017 年提出的神经网络结构(论文"Attention Is All You Need"),专门用于自然语言处理中的机器翻译、语言建模和文本生成任务。与传统的 NLP 特征提取类模型不同,Transformer 主要通过以下特性来实现:
- 基于自注意力机制 和多头注意力机制的模型结构;
- 由于没有 RNN 模型的时序特性,Transformer 通过位置编码来为数据添加位置信息。
这种处理方式带来了显著优势:
- 便于并行化,训练效率更高;
- 在处理长序列任务时表现优越,能够快速捕捉长距离的依赖关系。
注意力机制
注意力机制模仿了人类在阅读时聚焦于重点部分的方式。在自然语言处理中,不同任务可能对句子中某些词的关注度有所不同。注意力机制通过注意力分数来表示词在句子中的重要性,分数越高,表明该词对于任务的完成越重要。
Query、Key 和 Value
计算注意力分数时主要参考三个因素:
query:任务内容;key:索引或标签,用于定位答案;value:答案。
例如,对于"情感分类"任务,"情感分类"即为query,而每个词的出现位置或关联内容为key,这些内容最终帮助模型得到相应的答案(即value)。
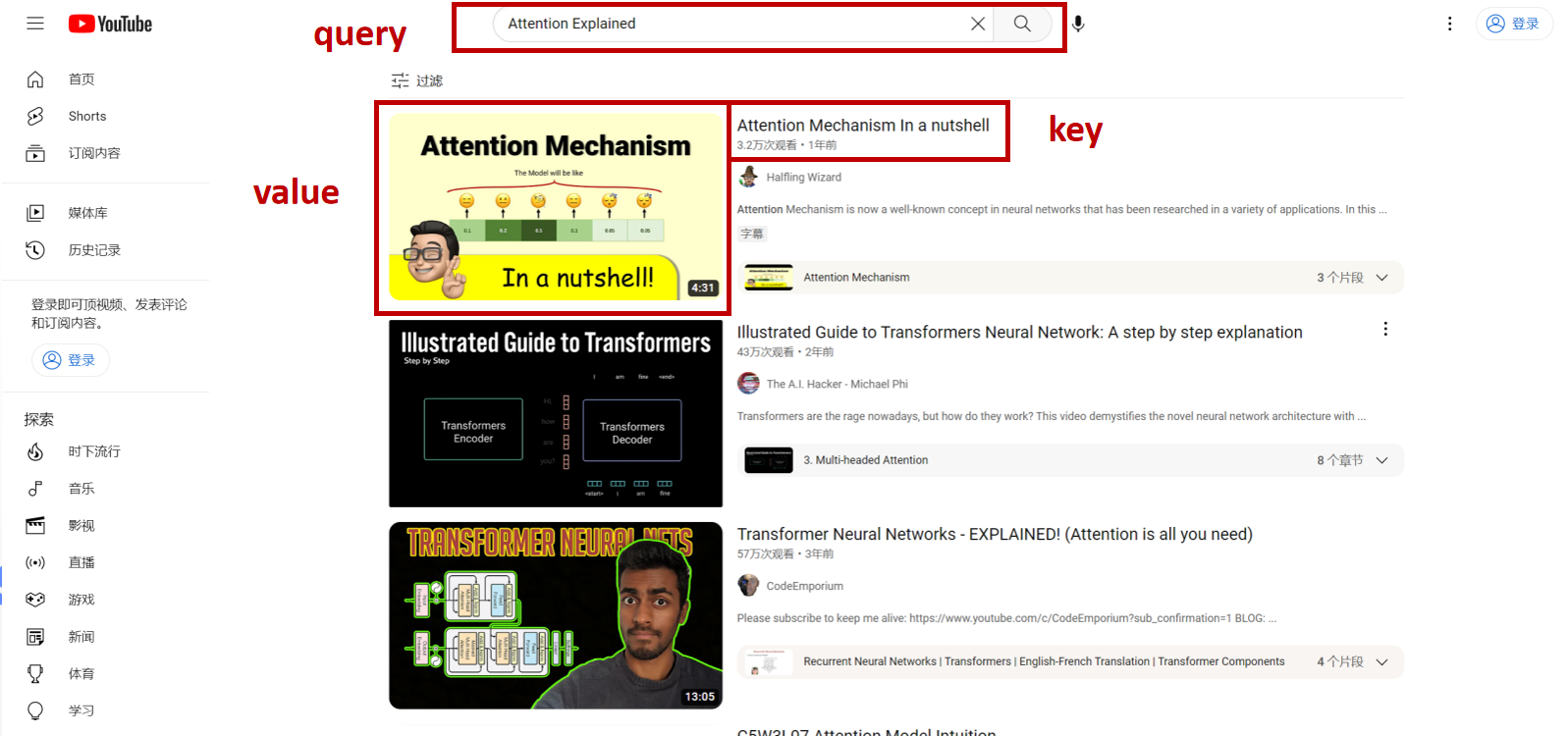
在文本翻译中,翻译后的句子应与原始句子意思相似,因此query通常与目标序列相关,key与源序列相关。
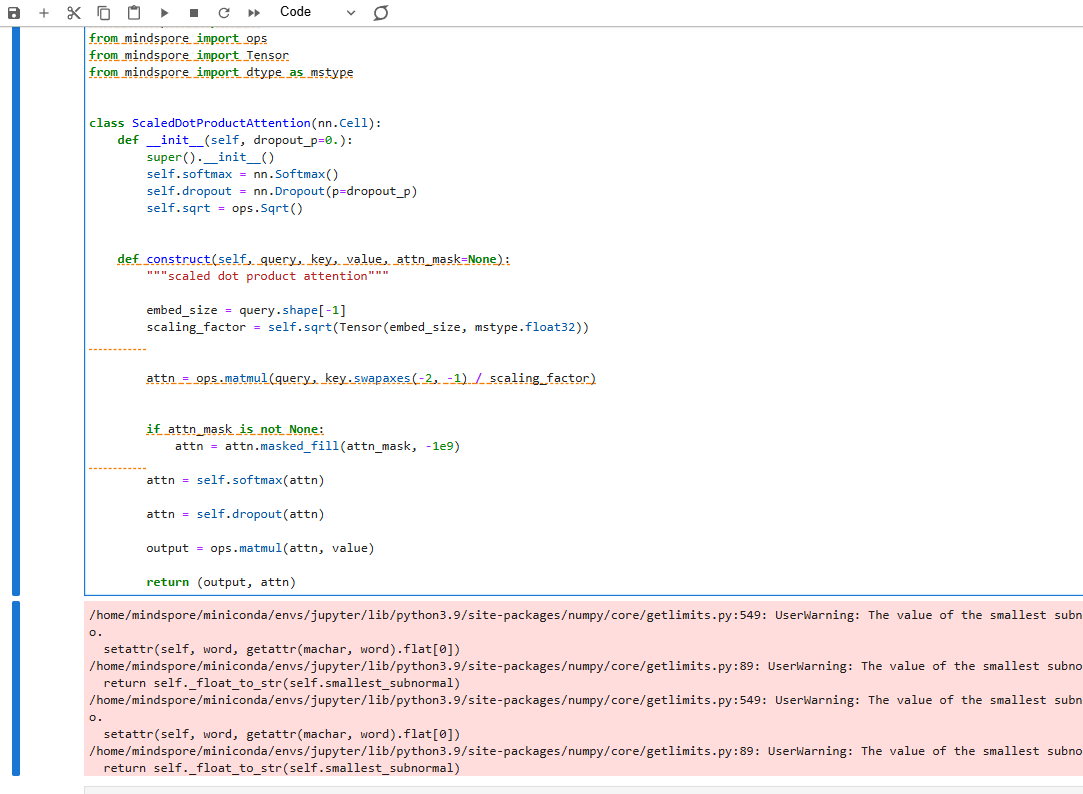
Scaled Dot-Product Attention
为了计算query和key的相似度,通常采用点积 方式。点积用于衡量两个向量间的相似度,反映一个向量在另一个向量方向上的投影。为了避免query和key的大小对相似度计算的影响,需对点积结果进行缩放,具体公式如下:
Attention Score ( Q , K ) = Q K T d m o d e l \text{Attention Score}(Q, K) = \frac{QK^T}{\sqrt{d_{model}}} Attention Score(Q,K)=dmodel QKT
最终,我们将相似度分数范围限制在 0 到 1 之间,并作用于value上:
Attention ( Q , K , V ) = softmax ( Q K T d m o d e l ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_{model}}}\right)V Attention(Q,K,V)=softmax(dmodel QKT)V
以下代码实现了 scaled dot-product attention 的计算,返回加权后的value(output)以及注意力权重(attn)。
自注意力机制(Self-Attention)
在自注意力机制中,我们关注的是句子本身,每个词对其上下文的重要性。例如,句子 "The animal didn't cross the street because it was too tired" 中,"it"指代 "The animal",因此自注意力会赋予"The"和"animal"更高的注意力分值。

图片来源:The Illustrated Transformer by Jay Alammer
在自注意力机制中,计算方式与之前相同,但query、key和value均来自句子本身的不同权重映射。公式如下:
Attention ( Q , K , V ) = softmax ( Q K T d m o d e l ) V \text{Attention}(Q, K, V) = \text{softmax}\left(\frac{QK^T}{\sqrt{d_{model}}}\right)V Attention(Q,K,V)=softmax(dmodel QKT)V
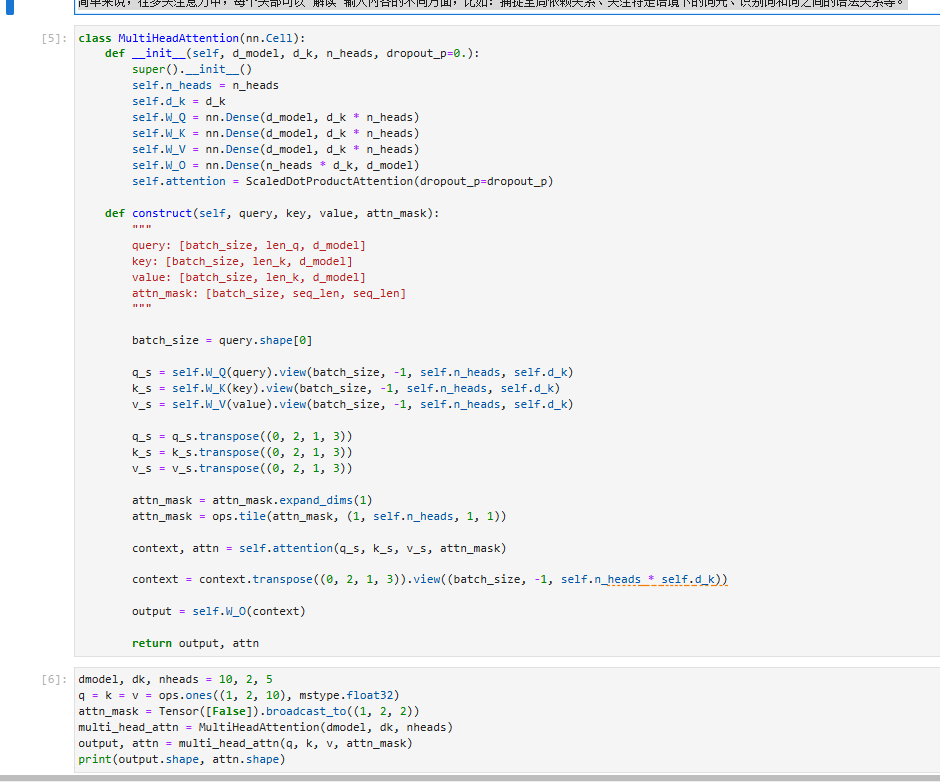
多头注意力机制(Multi-Head Attention)
多头注意力机制通过不同方式关注输入序列的不同部分,从而提升模型的效果。它对输入的嵌入乘以不同的权重参数 W Q W^{Q} WQ、 W K W^{K} WK和 W V W^{V} WV,映射到多个小维度空间(即"头"),每个头部并行计算自注意力分数。公式如下:
head i = Attention ( Q W i Q , K W i K , V W i V ) = softmax ( Q i K i T d k ) V i \text{head}_i = \text{Attention}(QW^Q_i, KW^K_i, VW^V_i) = \text{softmax}\left(\frac{Q_iK_i^T}{\sqrt{d_k}}\right)V_i headi=Attention(QWiQ,KWiK,VWiV)=softmax(dk QiKiT)Vi
得到多组自注意力分数后,将结果拼接得到最终的多头注意力输出:
MultiHead ( Q , K , V ) = Concat ( head 1 , . . . , head h ) W O \text{MultiHead}(Q, K, V) = \text{Concat}(\text{head}_1, ..., \text{head}_h)W^O MultiHead(Q,K,V)=Concat(head1,...,headh)WO
Transformer 的整体结构
Transformer 模型的结构如下图所示。输入序列在进入编码器(encoder)或解码器(decoder)前需进行以下两步预处理:
- Word Embedding:将序列转换为词向量表示,包含内容信息。
- Positional Encoding:在词向量的基础上添加位置信息。

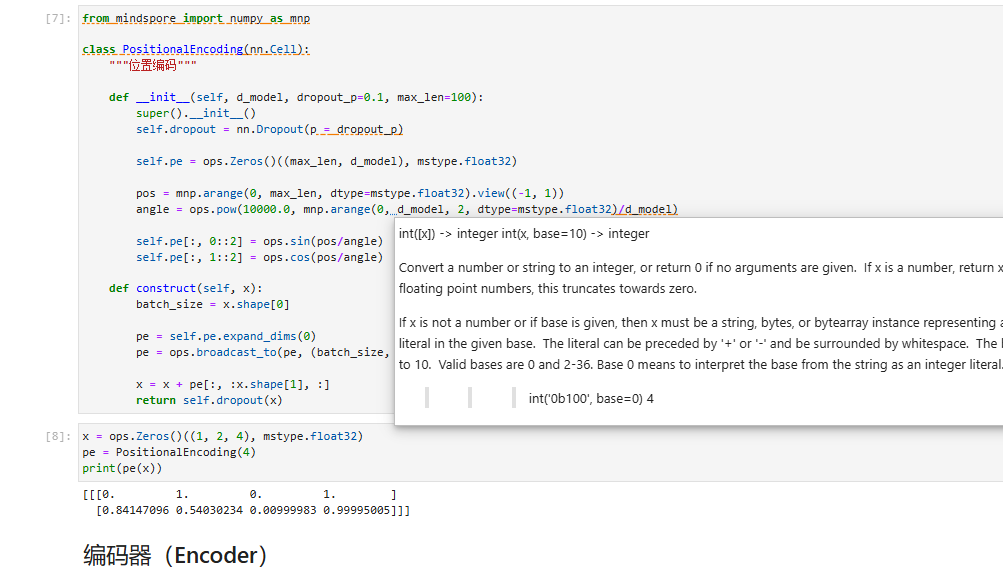
位置编码(Positional Encoding)
由于 Transformer 不包含 RNN 结构,因此无法记录序列信息。为了弥补这一缺陷,我们在输入数据中添加位置编码。位置编码公式如下:
P E ( p o s , 2 i ) = sin ( p o s 1000 0 2 i / d model ) PE_{(pos, 2i)} = \sin\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) PE(pos,2i)=sin(100002i/dmodelpos)
P E ( p o s , 2 i + 1 ) = cos ( p o s 1000 0 2 i / d model ) PE_{(pos, 2i+1)} = \cos\left(\frac{pos}{10000^{2i/d_{\text{model}}}}\right) PE(pos,2i+1)=cos(100002i/dmodelpos)
实现位置编码的代码如下:
编码器(Encoder)
Transformer 的编码器负责处理源序列,将输入信息整合为上下文向量。每个编码器层包含两个子层:多头自注意力(multi-head self-attention)和基于位置的前馈神经网络(position-wise feed-forward network)。子层之间使用残差连接(residual connection)和层规范化(layer normalization)。
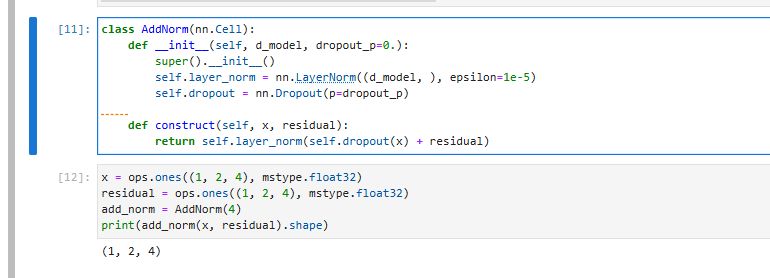
基于位置的前馈神经网络
前馈神经网络由两个线性层组成,用于对输入中的每个位置进行非线性变换:
F F N ( x ) = R e L U ( x W 1 + b 1 ) W 2 + b 2 \mathrm{FFN}(x) = \mathrm{ReLU}(xW_1 + b_1)W_2 + b_2 FFN(x)=ReLU(xW1+b1)W2+b2
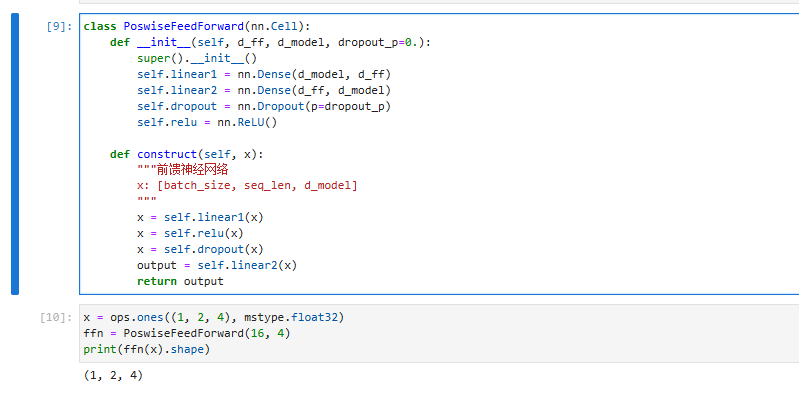
Add & Norm
Add & Norm 采用残差连接和层归一化的组合:
Add&Norm ( x ) = LayerNorm ( x + Sublayer ( x ) ) \text{Add\&Norm}(x) = \text{LayerNorm}(x + \text{Sublayer}(x)) Add&Norm(x)=LayerNorm(x+Sublayer(x))
- Add:残差连接,帮助缓解网络退化;
- Norm:层归一化,帮助加速模型收敛。
解码器(Decoder)
解码器将编码器输出的上下文序列转换为目标序列的预测结果,并与真实目标输出计算损失。每个解码器层包含两层多头注意力机制:
- 第一层:计算目标序列的注意力分数(掩码多头自注意力);
- 第二层:用于计算上下文序列与目标序列的关系。
带掩码的多头注意力
在处理目标序列时,为确保每个时间步仅关注先前的词元,需在第一层注意力中增加时间掩码(subsequent mask):
0 1 1 1 1 0 0 1 1 1 0 0 0 1 1 0 0 0 0 1 0 0 0 0 0 \begin{matrix} 0 & 1 & 1 & 1 & 1\\ 0 & 0 & 1 & 1 & 1\\ 0 & 0 & 0 & 1 & 1\\ 0 & 0 & 0 & 0 & 1\\ 0 & 0 & 0 & 0 & 0\\ \end{matrix} 0000010000110001110011110
该掩码确保模型在 t 时刻仅关注 t-1
之前的词元。
Transformer 模型代码实现
以下为 Transformer 模型的代码实现,涵盖了从词频统计到词典构建、编码、解码的各个细节。
词典构建(Vocab 类)
通过 Vocab 类实现词典的构建。首先通过词频字典构建词典,并设置一些特殊标记(如 <unk>、<pad>、<bos>、<eos>)。每个词在整个语料库中的频率都会影响词典的生成。常用词通常被分配较小的索引,以节省空间并提高计算效率。
python
class Vocab:
"""通过词频字典构建词典"""
special_tokens = ['<unk>', '<pad>', '<bos>', '<eos>']
def __init__(self, word_count_dict, min_freq=1):
self.word2idx = {}
for idx, tok in enumerate(self.special_tokens):
self.word2idx[tok] = idx
# 筛选出现频率大于等于 min_freq 的词汇构建词典
filted_dict = {w: c for w, c in word_count_dict.items() if c >= min_freq}
for w, _ in filted_dict.items():
self.word2idx[w] = len(self.word2idx)
# 生成词汇索引的反向映射
self.idx2word = {idx: word for word, idx in self.word2idx.items()}
# 设置特殊标记的索引
self.bos_idx = self.word2idx['<bos>']
self.eos_idx = self.word2idx['<eos>']
self.pad_idx = self.word2idx['<pad>']
self.unk_idx = self.word2idx['<unk>']
def _word2idx(self, word):
"""单词映射至数字索引"""
return self.word2idx.get(word, self.unk_idx)
def _idx2word(self, idx):
"""数字索引映射至单词"""
if idx not in self.idx2word:
raise ValueError('输入索引不在词典中。')
return self.idx2word[idx]
def encode(self, word_or_list):
"""将单个单词或单词列表映射至索引或索引列表"""
if isinstance(word_or_list, list):
return [self._word2idx(i) for i in word_or_list]
return self._word2idx(word_or_list)
def decode(self, idx_or_list):
"""将单个索引或索引列表映射至单词或单词列表"""
if isinstance(idx_or_list, list):
return [self._idx2word(i) for i in idx_or_list]
return self._idx2word(idx_or_list)
def __len__(self):
return len(self.word2idx)词频统计
在构建词典之前,使用 Python 的 collections 模块中的 Counter 和 OrderedDict 统计源语言和目标语言(如德语和英语)中每个单词的出现频率。这样构建出的词频字典可以进一步转换为词典对象:
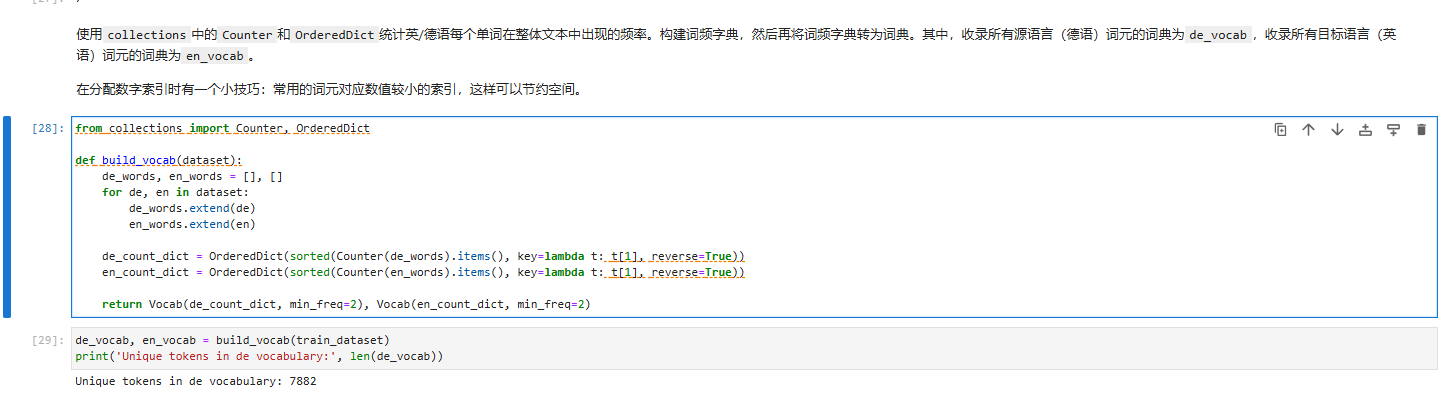
其中,源语言(德语)的词典为 de_vocab,目标语言(英语)的词典为 en_vocab。分配索引时,频繁出现的词被分配较小的数值索引以提升空间和计算效率。
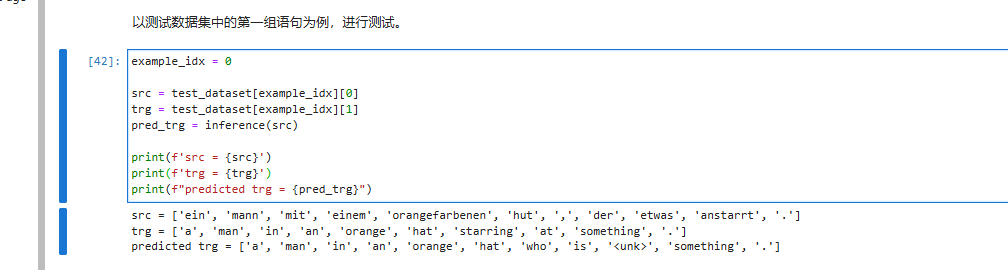
计算 BLEU 分数
在自然语言生成任务中,常用 BLEU 分数来评估生成的文本和参考文本之间的相似度。BLEU 分数是基于词块的重叠计算,是自然语言处理任务中常用的性能指标。以下代码实现了 BLEU 分数的计算逻辑:
总结
本文从 Transformer 模型的基础概念入手,深入探讨了自注意力、多头注意力、位置编码等核心机制,并通过代码演示了如何构建词典和计算 BLEU 分数。通过这种实现,我们可以更深入理解 Transformer 在自然语言处理中如何捕捉语义信息,从而生成更准确和流畅的翻译或其他语言生成任务的输出。