本文结合了个人的笔记以及工作中实践经验以及参考HBase官网,我尽可能把自己的知识点呈现出来,如果有误,还请指正。
1. HBase背景
HBase作为面向列的数据库运行在HDFS之上,HDFS缺乏随机读写操作,HBase正是为此而出现。HBase参考 Google 的 Bigtable 实现,以键值对的形式存储。项目的目标就是快速在主机内数十亿行数据中定位所需的数据并访问它。
分析这句话包含的隐藏信息:



2. hbase特点
-
建立在HDFS之上的分布式面向列的数据库
-
KV结构数据库,原生不支持标准SQL,属于NOSQL数据库
-
支持快速随机读写海量数据
-
具备HDFS的高容错能力
-
不属于关系型数据库,适合存储非机构化数据,基于列存储


3. hbase和hive的区别
-
hive适合统计分析,hive底层执行的是MapReduce,延迟较高
-
列式存储适合关联查询场景,而行式存储适合点查询场景
-
hbase适合大数据量查询,不适合统计分析,hbase底层采用KV结构存储,可以快速返回数据(能知道你的数据存在哪个region上)
-
hbase采用列式存储,可以动态扩展列(想加多少列就能加多少)
具体对上面解释的笔记


4. hbase数据单元
4.1 基础知识
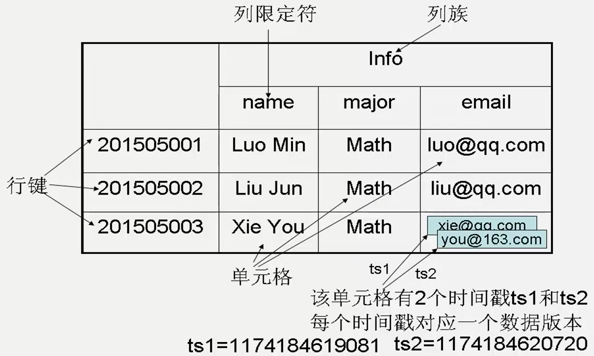
hbase是一个稀疏的、多维度、有序的映射表,表中的每个单元是通过行键、列族、列限定符和时间戳组成的索引来标识的,每个单元存储的值是一个未经解释的二进制数组byte\[\],没有数据类型,当用户在表中存储数据时,每一行都有一个唯一的行键和任意多的列,表的每一行由一个或者多个列族组成,一个列族可以包含任意多个列。
- 行键rowkey(主键)
每条数据的主键,rowkey是有序的,采用字典顺序排序,方便快速查找,rowkey的设计至关重要,建表时不指定。
- 列族column family(将相同类别的字段,放到同一个列族中)
多个列的组合,建表时指定。
- 列限定符column(字段)
归属于一个列族,代表着一列,建表时不指定,可动态扩展列,表达方式为column family:column,例:cf:name,标识在cf列族下的name列。
- 时间戳version
默认为系统时间戳timestamp,代表着一份数据不同时间节点的版本。
- 值value
由rowkey、column family、column、version索引检索得到的唯一值,key<rowkey、column family、column、version> ,value<唯一的值>,KV结构就由此而来。
4.2 hbase架构细节解释
索引
表中的每个单元是通过行键、列族、列限定符和时间戳组成的索引来标识的

【这张图片引用参考:https://zhuanlan.zhihu.com/p/151871736】
单元存储
每个单元存储的值是一个未经解释的二进制数组byte\[\],没有数据类型

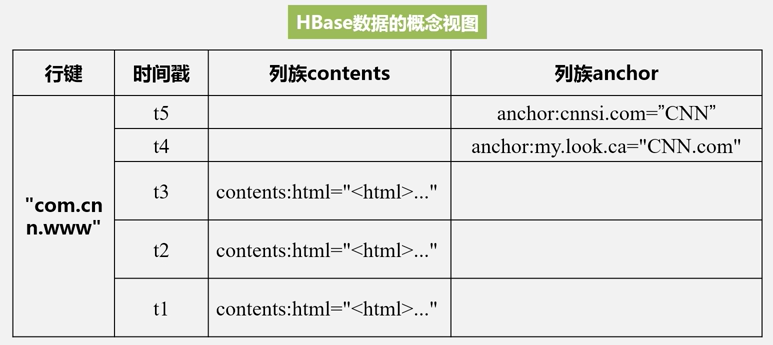
hive行式存储与hbase列式存储
如下示例进行两种数据存储方式的对比: 当用户在表中存储数据时,每一行都有一个唯一的行键和任意多的列,表的每一行由一个或者多个列族组成,一个列族可以包含任意多个列。

列族
列族column family(将相同类别的字段,放到同一个列族中)

4.3两种数据存储方式的对比:
hive行式存储
| rowkey | name | age | address |
|---|---|---|---|
| 1001 | user1 | 20 | beijing |
| 1002 | user2 | 21 | shanghai |
- hbase列式存储
| rowkey | cf | column | version(时间戳) | value |
|---|---|---|---|---|
| 1001 | cf | cf:name | t1 | user1 |
| 1001 | cf | cf:age | t2 | 20 |
| 1001 | cf | cf:address | t3 | beijing |
| 1002 | cf | cf:name | t4 | user2 |
| 1002 | cf | cf:age | t5 | 21 |
| 1002 | cf | cf:address | t6 | shanghai |
hbase 版本
hbase没有修改语法,当要修改一条数据只需要直接写入即可。
version默认是由系统时间戳表示,当用户重复写入一条数据时,hbase会记录两条数据,因为rowkey、column family、column相同,此时则使用version字段进行区分,并且会保留上一个版本的数据,同一条数据不同版本使用version倒序排序!如下:
原数据
| rowkey | cf | column | version | value |
|---|---|---|---|---|
| 1001 | cf | cf:name | t1 | user1 |
| 1001 | cf | cf:age | t2 | 20 |
| 1001 | cf | cf:address | t3 | beijing |
| 1002 | cf | cf:name | t4 | user2 |
| 1002 | cf | cf:age | t5 | 21 |
| 1002 | cf | cf:address | t6 | shanghai |
此时用户要修改如下数据name的value值
| rowkey | cf | column | value |
|---|---|---|---|
| 1001 | cf | cf:name | newusername |
执行添加数据命令put 'namespace:tablename','1001','cf:name','newusername'后hbase表数据
| rowkey | cf | column | version | value |
|---|---|---|---|---|
| 1001 | cf | cf:name | t7 | newusername |
| 1001 | cf | cf:name | t1 | user1 |
| 1001 | cf | cf:age | t2 | 20 |
| 1001 | cf | cf:address | t3 | beijing |
| 1001 | cf | cf:name | t4 | user2 |
| 1001 | cf | cf:age | t5 | 21 |
| 1001 | cf | cf:address | t6 | shanghai |
当一条数据存在多个版本的时候,查询如果不指定版本,则默认查询最新一条数据,hbase的version也不是可以无限存的,默认版本数为3,可以设置最多存储多少个版本,当超过设定的版本数之后则删除最早版本的数据。
laoli_matrix70演示:插入数据

参考资料:
Apache HBase® Reference Guide HBASE官网