在本教程中,我们将展示如何使用 Python 和 pyecharts 库,通过对招聘数据的分析,制作一个交互式的招聘数据分析大屏。此大屏将通过不同类型的图表(如柱状图、饼图、词云图等)展示招聘行业、职位要求、薪资分布等信息。

1. 准备工作
1.1 安装必要的 Python 库
在开始之前,确保你已经安装了以下 Python 库:
bash
pip install pandas pyecharts jieba openpyxlpandas:用于数据处理。pyecharts:用于生成可交互的图表。jieba:用于中文分词。openpyxl:用于读取 Excel 文件。
1.2 数据集准备
假设我们已经有一个招聘数据集 tmp.xlsx,它包含以下字段:
Industry:行业Job Experience:工作经验要求Job Education:学历要求Staff Size:公司规模Job Location:工作地点key_word_list:关键词列表Job Intro:职位介绍lowest_salary:最低薪资highest_salary:最高薪资
数据集的每一行代表一个招聘职位信息。
2. 数据加载与处理
2.1 读取数据
我们使用 pandas 读取 Excel 文件,并进行一些初步的数据清理。
python
import pandas as pd
# 读取 Excel 数据
df_reset = pd.read_excel('./tmp.xlsx')
# 查看数据基本信息
print(df_reset.head())2.2 统计行业数量
我们通过 Counter 来统计招聘数据中不同行业的数量,跳过 "None" 值。
python
from collections import Counter
# 统计行业数量,跳过 "None" 值
industry_count = Counter(industry for industry in df_reset['Industry'] if industry != 'None')
# 获取前 10 个最常见的行业
industry_count_top10 = dict(industry_count.most_common(10))2.3 统计工作经验和学历要求
我们同样可以对工作经验和学历要求进行统计,并获取前 10 个最常见的要求。
python
# 统计工作经验要求
education_counts = pd.Series(df_reset['Job Experience']).value_counts()
top10_education_counts = education_counts.head(10)
# 统计学历要求
education_counts = pd.Series(df_reset['Job Education']).value_counts()
top10_education_counts = education_counts.head(10)2.4 处理员工规模
对于员工规模字段,我们需要将包含字符串 "None" 的值替换为 NaN,然后进行统计。
python
# 替换 "None" 为 NaN
df_reset['Staff Size'] = df_reset['Staff Size'].replace('None', pd.NA)
size_counts = df_reset['Staff Size'].value_counts().dropna()2.5 处理职位地点
为了分析职位的地理分布,我们将城市名称处理为带有"市"字的格式,并统计不同城市的数量。
python
# 定义函数,在每个有效字符串值后面添加"市"
def add_city(value):
if isinstance(value, str):
return value + "市"
return value
# 应用函数到 Job Location 列
df_reset["Job Location"] = df_reset["Job Location"].apply(add_city)
# 去除空值行
df_reset1 = df_reset.dropna(subset=["Job Location"])
# 统计职位地点
location_counts = df_reset1['Job Location'].value_counts().reset_index()2.6 关键词提取和频率统计
我们从职位介绍中提取关键词,并统计它们的出现频率。使用 jieba 库进行中文分词,并过滤停用词。
python
import jieba
from collections import Counter
# 提取所有关键词
all_keywords = []
for keywords in df_reset1["key_word_list"].dropna():
all_keywords.extend(keywords.split(','))
# 统计关键词出现频率
keyword_counts = Counter(all_keywords)
# 获取前 10 个关键词
top_ten_keywords = keyword_counts.most_common(10)
keywords, counts = zip(*top_ten_keywords)3. 数据可视化
我们将使用 pyecharts 库来生成各种类型的图表,展示数据的不同方面。
3.1 设置主题与表格
首先,设置一些基础配置,比如页面主题和表格颜色。
python
from pyecharts import options as opts
from pyecharts.components import Table
from pyecharts.globals import ThemeType
from pyecharts.charts import Page
theme_config = ThemeType.PURPLE_PASSION # 更改为您需要的主题类型
# 设置表格颜色
table_color = '#5B5C6E' # 紫色主题的颜色3.2 创建柱状图:行业数量
我们将创建一个柱状图,展示前 10 个行业的招聘数量。
python
from pyecharts.charts import Bar
bar_chart = Bar(init_opts=opts.InitOpts(theme=theme_config, width="450px", height="350px"))
bar_chart.add_xaxis(list(industry_count_top10.keys()))
bar_chart.add_yaxis("行业数量", list(industry_count_top10.values()))
bar_chart.set_global_opts(title_opts=opts.TitleOpts(title="前十大行业数量"))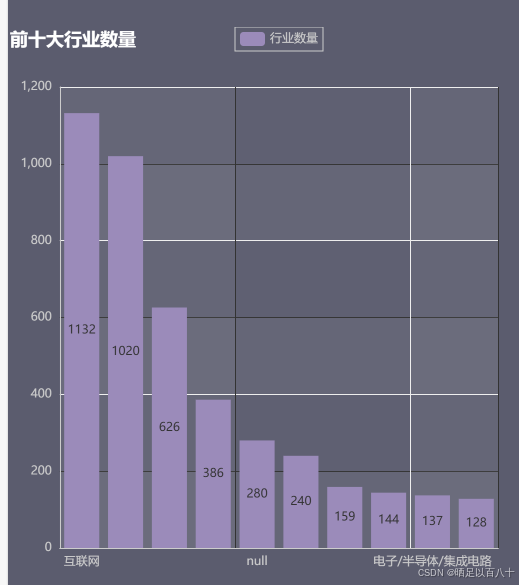
3.3 创建饼图:学历要求分布
使用 Pie 图来展示工作经验和学历要求的分布。
python
from pyecharts.charts import Pie
pie_chart_education = Pie(init_opts=opts.InitOpts(theme=theme_config, width="450px", height="350px"))
sizes = [int(count) for count in top10_education_counts]
pie_chart_education.add("", [list(z) for z in zip(top10_education_counts.index, sizes)], radius=["30%", "75%"], rosetype="radius")
pie_chart_education.set_global_opts(title_opts=opts.TitleOpts(title="学历要求分布"))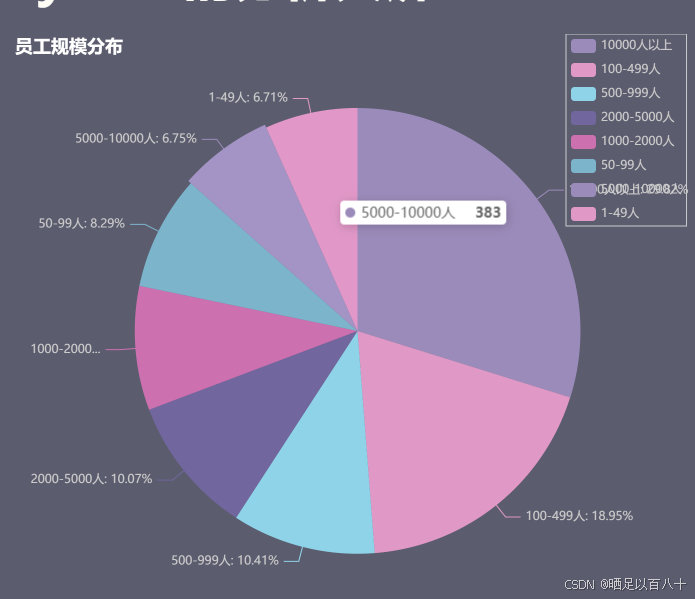
3.4 创建雷达图:职位地点
为了展示职位地点的分布,我们使用 Radar 图。
python
from pyecharts.charts import Radar
radar = Radar(init_opts=opts.InitOpts(theme=theme_config, width="450px", height="350px"))
radar.add_schema(
schema=[opts.RadarIndicatorItem(name=city, max_=1000) for city in location_counts['Job Location']]
)
radar.add("职位地点", [location_counts['Job Location'].tolist()], areastyle_opts=opts.AreaStyleOpts(opacity=0.5))
radar.set_global_opts(title_opts=opts.TitleOpts(title="职位地点雷达图"))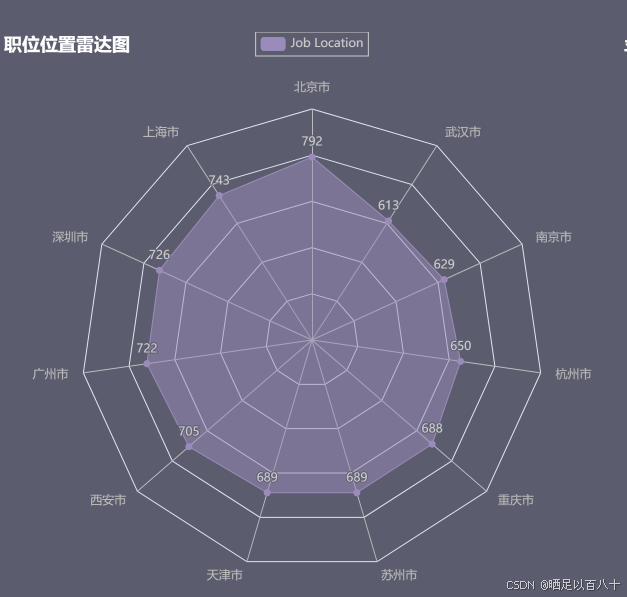
3.5 创建词云图:职位介绍
使用 WordCloud 图展示职位介绍中的高频词。
python
from pyecharts.charts import WordCloud
wordcloud = WordCloud(init_opts=opts.InitOpts(theme=theme_config, width="450px", height="350px"))
wordcloud.add("", top_words, word_size_range=[20, 100])
wordcloud.set_global_opts(title_opts=opts.TitleOpts(title="职位介绍词云图"))
3.6 创建薪资分布直方图
计算每个职位的平均薪资,并绘制薪资分布的直方图。
python
df_reset['average_salary'] = (df_reset['lowest_salary'] + df_reset['highest_salary']) / 2
salary_distribution = df_reset['average_salary'].value_counts().sort_index().reset_index()
salary_histogram = Bar(init_opts=opts.InitOpts(theme=theme_config, width="450px", height="350px"))
salary_histogram.add_xaxis(salary_distribution['index'].astype(str).tolist())
salary_histogram.add_yaxis("Frequency", salary_distribution['average_salary'].tolist())
salary_histogram.set_global_opts(title_opts=opts.TitleOpts(title="薪资分布"))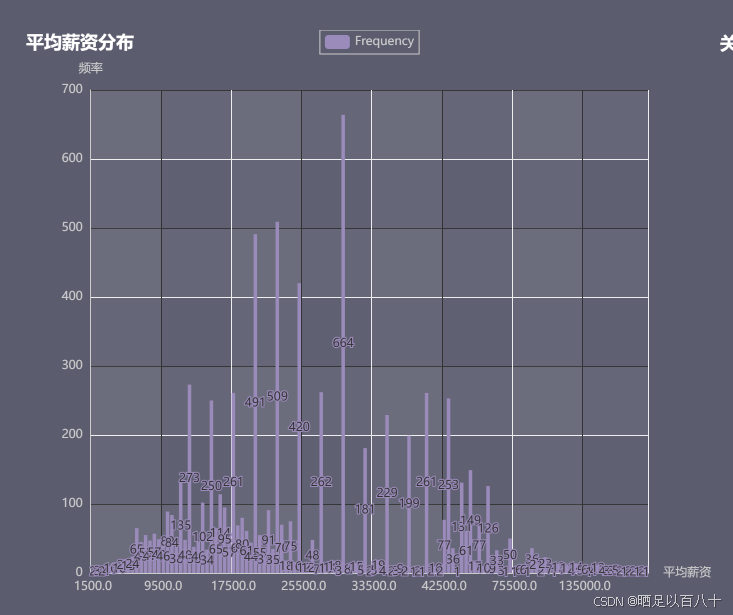
3.7 将所有图表组合成页面
最后,我们将所有生成的图表组合成一个页面,并渲染为 HTML 文件。
python
page = Page(page_title="基于Python分析大屏")
page.add(
bar_chart,
pie_chart_education,
radar,
wordcloud,
salary_histogram
)
page.render('招聘分析大屏.html')4. 结果展示
运行完上述代码后,你将得到一个名为 招聘分析大屏.html 的文件。打开这个 HTML 文件,你将看到一个交互式的招聘数据分析大屏,展示了不同的图表和统计结果,包括行业分布、学历要求、职位地点等信息。

总结
本教程展示了如何利用 Python 和 pyecharts 库,从招聘数据中提取关键信息,并通过多种可视化图表呈现分析结果。你可以根据自己的需求调整数据来源和图表类型,进一步扩展和优化你的数据分析大屏。
