一、软件包管理器yum
在Linux上想要安装一个软件需要下载程序的源代码并且进行编译得到一个可执行的程序。这样会引发很多的问题,第一是这样做很麻烦;第二是我们不知道软件的开发者在开发这款软件的时候用的是一个什么样的环境,我们用不一样的环境去进行编译就很有可能会发生错误。所以就有人把一些常用的软件提前编译好,做成软件包放在服务器上,通过包管理器我们就可以很方便的获取到编译好的软件包直接进行安装使用,这样介绍的yum就是一块很常用的包管理器。想要安装什么软件我们直接在网络上搜索一下都能直接找到安装对应软件的命令。
二、编辑器vim
vim经常使用的有三种模式,分别是命令模式、插入模式、底行模式。
1、命令模式
可以控制屏幕上的光标在字符、字或者行之间快速移动,可以快速实现拷贝、复制、删除等操作、模式的切换也需要再命令模式下。
2、插入模式
只有在插入模式下才能进行文本的输入,在命令模式下输入i即可进入插入模式;在插入模式下按ESC即可回到命令模式。
3、底行模式
底行模式中可以进行文本编辑的退出、保存操作,也可以进行文本替换、查找字符串、列出行号等操作。在命令模式中输入"shift + :"即可进入底行模式,同样按下ESC也可以从插入模式回到命令模式。
一、vim的基本操作
在命令行中输入vim 文件名即可进入vim的操作页面,如果该文件存在则是打开该文件,模式的切换都要在命令模式下进行,也就说如果我们想从插入模式变为底行模式,我们要先按ESC从插入模式转换成命令模式,在输入"shift + :"进入底行模式。
在底行模式中输入w则是保存当前文件,wq则是保存当前文件并退出vim,q!不保存强制退出vim,目录下没有该文件,则会创建目标文件。
二、vim命令模式命令集
移动光标
在vim上不仅可以使用键盘上的上下左右来移动光标,还可以使用小写的英文字母h、j、kl来控制光标的左、下、上、有。
G:移动到文章的最后
$:移动到光标所在行的最后
^:移动到光标所在行的行首
小写字母w:光标跳转到下一个单词的开头
小写字母e:跳转到下一个单词的尾部
小写字母b:回到上一个字母的开头
#l:将光标移动到当前行的第#个位置
gg:回到文章的开头
dd:删除光标所在行
#dd:从光标所在行开始删除#行
yy:复制光标当前所在行
#yy:复制光标所在及以下#行
p:粘贴复制的内容
u:回到上一个操作,多次按u可以回复多次
三、底行模式命令集
set nu:显示行号
#:#表示一个数字,在底行模式中输入一个数字就会跳转到对应行
/关键字:先输入/在输入要查找的字符,如果当前字符不是想要查找的,想要继续查找可以一直按n,会一直往后查找
?关键字:先输入?在输入要查找的字符,如果当前字符不是想要查找的,想要继续查找可以一直按n,会一直往后查找
/关键字会从文章的开头开始往后找,?会从文章的结尾开始向前找
三、编译器gcc/g++
在编译器将我们的源代码转化成可执行程序时需要经历四个步骤,分别是:预处理、编译、汇编、连接。
预处理:进行宏替换、去注释、条件编译、文件展开等工作
编译:生成汇编代码
汇编:将汇编语言转化成机器语言
连接:将生成的目标文件连接到一起生成可执行程序
gcc的使用格式
gcc 选项 要编译的文件 选项 目标文件
使用-o 目标文件可以指定生成的目标文件的文件名,比如gcc --E hello.c --o hello.i。
预处理
gcc后使用-E选选项作用是让gcc在预处理结束后停止编译过程。
编译
在这个阶段中gcc首先会检查代码的规范性以及是否有语法错误等,同时还会确定代码实际要做的工作,在检查无误以后,gcc会把代码翻译成汇编语言。
在gcc后加上-S选项可以让gcc在编译完成以后不进行汇编,生成汇编代码,比如gcc --S hello.i --o hello.s
汇编
汇编阶段是把编译阶段生成的.s文件转化成目标文件
在gcc后面加上-o选项可以就可以看到gcc把编译生成的.s文件中的汇编代码转化成了.o文件中的二进制目标代码了。gcc --c hello.s --o hello.o
连接
在汇编成功后,gcc会把所有需要的文件连接在一起生成一个可执行程序或者库文件。
gcc hello.o --o hello
动态链接和静态链接
在我们实际开发的过程中,不可能将所有的代码放在一个源文件中,所以会出现有多个源文件的情况。而且多个源文件之前也不可能是独立的,会存在多种依赖关系,比如说一个源文件中可能会调用另外一个用文件中定义的函数,但是每个源文件都是独立编译的,也就是说每个.c文件都会形成一个独立的.o文件,为了满足前面说的依赖关秀,就需要将这些源文件产生的目标文件进行链接,从而写成一个可执行程序。这个链接的过程就是静态链接。静态链接有以下的缺点:
一、浪费空间,每个可执行程序中都需要的目标文件都要有一个副本,所以如果多个程序对一个同一个目标文件有依赖,那么在内存中存在多个这个目标文件的副本;
二、更新比较困难:当库函数的代码发生了修改,这个时候就需要重新进行编译链接形成可执行程序。
但是静态链接的优先是在可执行程序中已经具备了执行程序需要的所有东西,所以在执行的时候速度更快。
而动态链接则解决了静态链接中出现的问题。动态链接的基本思路就是把程序按照模块拆分成各个相对独立的部分,只有在程序运行的时候才将这些独立的部分链接在一起形成一个完成的程序,而不是像静态链接那样把所有程序模块都链接成一个单独的可执行文件。
这里还要提一点,gcc在编译的时候是不会产生调试信息的,使用-g选项就可以生成调试信息,就可以用gdb进行调试。
四、自动化构建-make/Makefile
在Linux中每次编译都需要自己输入gcc语句,如果需要用到的文件很多,那每次在编写命令的时候都会很繁琐而且很容易出错,如果漏了某个文件都会导致错误的出现。所以有了makefile这种自动化变异的工具出现。make是一个命令工具,Makefile则是一个文件,写好了一个Makefile的内容,只需要一个make命令就可以直接完成编译。
下面就是一个Makefile的基本编写格式。其中test是我们要生成的可执行出程序,:以后的是生成这个可执行程序需要依赖的文件,下面一行用TAB开头跟的是生成test可执行文件所需要的语句。同时工程里是需要清理的,所以就有clean这样的命令,像clean这种和第一个目标文件没有直接关联或者间接关联的句子我们想要执行的时候需i要输入"make clean"。一般这样的写法是不会有问题的,但是如果当前目录下有一个文件叫做clean时,清理的语句就不会执行了。
cpp
test:test.c
gcc -o test test.c
clean:
rm -f test所以一般我们会把clean这样的总是要被执行的语句设置成伪目标,就能避免上述情况的发生。
cpp
test:test.c
gcc -o test test.c
.PHONY:clean
clean:
rm -f test当我们只输入make命令时,make会在当前目录下找名字为"Makefile"或者"makefile"的文件,如果找到了,它会找文件中的第一个目标文件作文最终的目标文件。如果这个文件不存在,或者是这个文件依赖的文件的文件修改时间比这个文件新了,那么它就会执行后面定义的命令来生成一个新的这个文件。如果这个文件所依赖的文件不存在,那么make会在当前文件中找目标为被依赖文件的一个文件,如果找到了,再根据那个文件的规则生成一个被依赖的文件。就这样make会一层层的向里去找文件的依赖关系,直到最终编译出第一个目标文件。在找寻的过程中,如果出现错误,⽐如最后被依赖的⽂件找不到,那么make就会直接退出,并报错,⽽对于所定义的命令的错误,或是编译不成功,make根本不理。make只管⽂件的依赖性,即,如果在我找了依赖关系之后,冒号后⾯的⽂件还是不在,那么不⼯作了。
如果依赖文件很多还有可以使用下面这种写法,其中"@"表示目标文件名,"^"表示依赖文件列表,也就说有多个依赖文件,我们也只需要写一个"$^"就可以了。
cpp
test:test.c
gcc -o $@ $^
.PHONY:clean
clean:
rm -f test五、gdb/cgdb
程序的发布方式有两种,一种是debug模式,另外一种是release模式。在Linux环境中使用gcc/g++编译出来的程序默认是release模式的。release模式下是没有调试信息的,所以我们想要调试程序,就必须在生成可执行程序的时候加上-g选项。
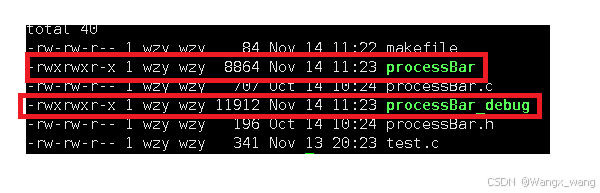
processBar是正常编译出来的,processBar_debug是带-g选项编译出来的,明显可以看出processBar_debug的文件大小是更大的,也就是因为它携带了调试信息的原因。
cgdb的图形化界面比gdb使用起来要方便一些,所以下面我们都用cgdb来演示。
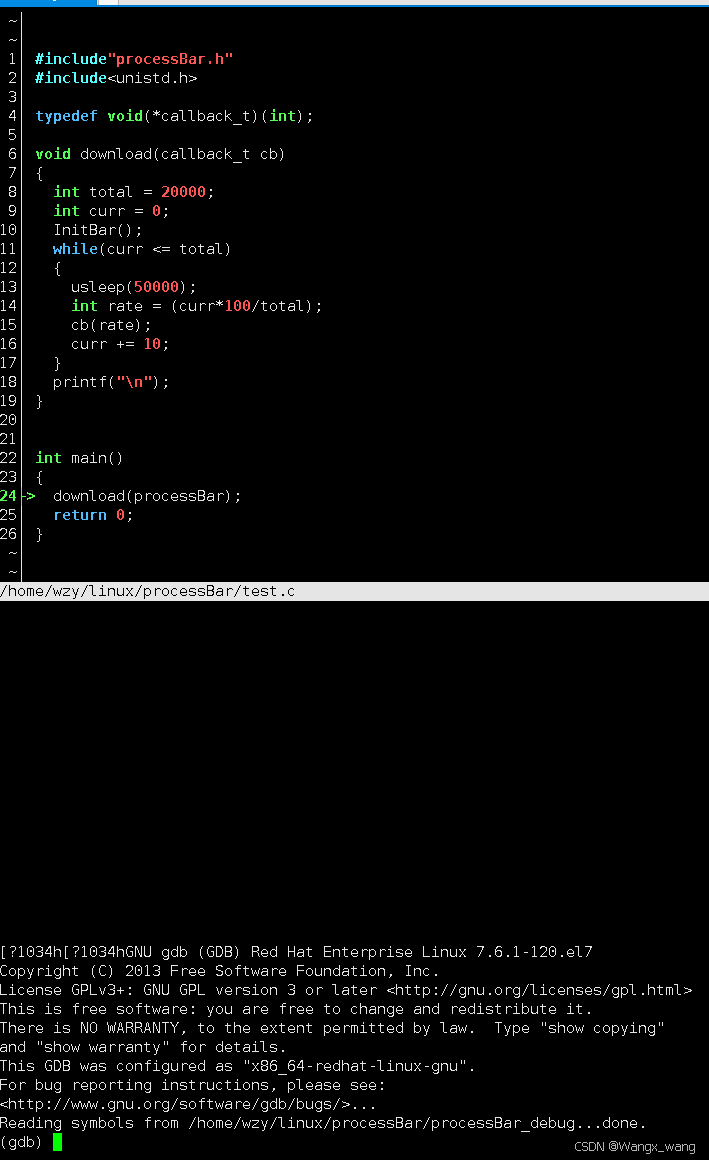
cgdb的界面分为上下两个部分,上面部分是我们的源代码的界面,下面则是gdb的界面,绿色箭头指的位置则是当前程序运行到的位置。
常见命令
|------------------------|------------------------|--------------------------|
| 命令 | 作用 | 样例 |
| list/l | 显⽰源代码,从上次位置开始,每次列出 10⾏ | list/l 10 |
| list/l 函数名 | 列出指定函数的源代码 | list/l main |
| list/l ⽂件名:⾏号 | 列出指定⽂件的源代码 | list/l mycmd.c:1 |
| r/run | 从程序开始连续执⾏ | run |
| n/next | 单步执⾏,不进⼊函数内部 | next |
| s/step | 单步执⾏,进⼊函数内部 | step |
| break/b ⽂件名:⾏号 | 在指定⾏号设置断点 | break 10 break test.c:10 |
| break/b 函数名 | 在函数开头设置断点 | break main |
| info break/b | 查看当前所有断点的信息 | info break |
| finish | 执⾏到当前函数返回,然后停⽌ | finish |
| print/p 表达式 | 打印表达式的值 | print start+end |
| p 变量 | 打印指定变量的值 | p x |
| set var 变量=值 | 修改变量的值 | set var i=10 |
| continue/c | 从当前位置开始连续执⾏程序 | continue |
| delete/d breakpoints | 删除所有断点 | delete breakpoints |
| delete/d breakpoints n | 删除序号为n的断点 | delete breakpoints 1 |
| disable breakpoints | 禁⽤所有断点 | disable breakpoints |
| enable breakpoints | 启⽤所有断点 | enable breakpoints |
| info/i breakpoints | 查看当前设置的断点列表 | info breakpoints |
| display 变量名 | 跟踪显⽰指定变量的值(每次停⽌时打印) | display x |
| undisplay 编号 | 取消对指定编号的变量的跟踪显⽰ | undisplay 1 |
| until X ⾏号 | 执⾏到指定⾏号 | until 20 |
| backtrace/bt | 查看当前执⾏栈的各级函数调⽤及参数 | backtrace |
| info/i locals | 查看当前栈帧的局部变量值 | info locals |
| quit | 退出GDB调试器 | quit |
如果我们想在程序执行的过程中监视一个表达式(如变量)。我们可以使用watch。
watch + 表达式,gdb会在表达式的值发生变化时,暂停当前程序的执行并通知使用者。
假如我们想要在某个地方添加条件断点可以使用b # if 条件,这里的#表示增加断点位置的行号,而条件就是这一行的某个等式,如果想要给已存在的断点追加条件的格式是:condition # 条件,这里的#是已有的断点编号。