我自己的原文哦~https://blog.51cto.com/whaosoft/11859241
#Open3DWorld
突破感知极限!自动驾驶中的开放3D World
开放词汇感知的能力代表了自动驾驶系统的重大进步,促进了实时整合和解释各种文本输入。尽管对2D计算机视觉中的开放词汇任务进行了广泛的研究,但将这种方法应用于3D环境,特别是在大规模室外环境中,仍然相对不发达。本文提出了一种将激光雷达传感器获取的3D点云数据与文本信息相结合的新方法。主要重点是利用文本数据在自动驾驶环境中直接定位和识别目标。我们引入了一种将鸟瞰图(BEV)区域特征与文本特征融合的有效框架,从而使系统能够无缝适应新的文本输入,并增强开放词汇检测任务的鲁棒性。通过在新引入的NuScenes-T数据集上进行广泛实验,对所提出方法的有效性进行了严格评估,并在Lyft Level 5数据集上对其zero-shot性能进行了额外验证。这项研究通过利用多模态数据来增强3D环境中的开放词汇感知,从而突破了自主导航和感知的界限,为自动驾驶技术的进步做出了重大贡献。
本文介绍了一种新方法,该方法将激光雷达传感器的3D点云与文本数据相结合,以增强自动驾驶的感知能力。通过直接使用文本来定位和识别目标,具体来说提出了一种简单而有效的方法,将鸟瞰图(BEV)区域特征与文本特征融合在一起。本文的方法支持无缝适应新的文本输入,促进了3D环境中强大的开放词汇检测任务。方法命为"Open3DWorld"。本文的贡献有三方面:
支持使用激光雷达文本的3D开放词汇检测任务,使自动驾驶系统能够无缝适应新的文本输入,而无需进行大量的再培训。这种能力对于在多样化和动态的环境中运行至关重要。
提出了一种将3D点云与文本数据集成的新方法,增强了自动驾驶系统的感知能力。通过有效地将鸟瞰图(BEV)区域特征与文本特征融合,我们的方法能够直接从文本输入中准确定位和识别目标。
通过对NuScenes数据集((称为NuScenes-T数据集)的扩展词汇表进行综合实验,证明了我们的方法的有效性,并在Lyft 5级数据集上验证了其zero-shot性能。
相关工作回顾
Open vocabulary:开放式词汇感知是自动驾驶系统的一项基本能力,能够识别和解释训练数据中可能不存在的各种文本输入。YoloWorld和GroundingDINO等方法促进了这一领域的最新进展。YoloWorld是YOLO框架的高级扩展,专门用于通过集成来自大规模语言模型的上下文信息来处理开放词汇任务。接地DINO将文本描述的接地与视觉感知模型相结合,实现了文本和图像数据的精确对齐。
为了训练和验证开放词汇感知的模型,已经使用了几个大规模和各种各样的数据集,包括COCO(上下文中的常见目标)、Objects365(O365)、Golden Gate数据集(GoldG)和300万个概念字幕(CC3M)。这些数据集提供了各种各样的目标类别和注释,促进了2D开放词汇任务的全面训练。对于3D开放词汇任务,3D-OWIS提出了一种新的开放世界3D室内实例分割方法,该方法通过自动标注和生成伪标签,并调整未知类别概率来区分和逐步学习未知类别。OV-3DET提出了一种无需任何3D标注即可完成开放词汇表点云目标检测的方法。在室外场景中,POP-3D通过使用预训练的多模态模型来预测3D Occ。
自动驾驶体素网络中的3D目标检测是第一个为基于激光雷达的3D目标探测引入密集卷积的技术,实现了具有竞争力的性能。PointPillars、PillarNet和PillarNext在这些特征图上使用了BEV的2D密集卷积。SECOND是一项开创性的工作,它使用稀疏CNN提取3D稀疏体素特征,然后将其转换为密集的BEV特征图进行预测。CenterPoint引入了一种基于center的检测头。FSDv1将原始点云划分为前景和背景,然后对前景点进行聚类以表示单个目标。它使用PointNet风格的网络从每个聚类中提取特征,以进行初始粗略预测,并由组校正头进行细化。FSDv2用虚拟体素化模块取代了实例聚类,旨在消除人工设计的实例级表示的归纳偏差。SWFormer提出了一种完全基于transformer的3D目标检测架构。最近,VoxelNeXt通过纯粹基于体素的设计简化了完全稀疏的架构,根据最接近其中心的特征定位目标。
多模态融合对于文本和图像特征对齐,CLIP是无监督跨模态训练的开创性工作。因此,MaskCLIP改进了用于像素级密集预测任务的CLIP,特别是语义分割。用于开放词汇检测的多模态特征融合方法包括YoloWorld,该方法提出了一种视觉语言PAN来融合词汇嵌入和多尺度图像特征。GroundingDINO引入了一个特征增强器和一个语言引导的查询选择模块,采用了类似于Transformer的架构。对于图像和点云特征对齐,BEVFusion首先将图像和点云和数据转换为鸟瞰图(BEV)空间,然后将它们融合。对于室内场景中的文本、图像和点云对齐,OV-3DET提出了Debian跨模式三元组对比度损失。POP-3D通过使用预训练的MaskCLIP模型并采用图像特征作为媒介来建立三种模态之间的联系,从而解决了室外场景的问题。
问题定义
方法论NuScenes-T Dataset
TOD3Cap基于原始标注详细描述了NuScenes数据集中的每个目标。我们使用它来提取描述中的名词主题,经过过滤后,我们得到NuScenes中目标的名词描述,例如"汽车"、"盒子"、"垃圾"。所有名词的分布如图2所示。
通过这种方法,我们获得了比原始NuScenes数据集中更多的类别注释。自动驾驶场景中的一些常见挑战性案例,如"石头"和"盒子",也包括在我们的新类别中。
Framework Overview
本文提出的方法的总体框架如图3所示,主要由三个部分组成。第一个是特征提取主干,它包括文本和点云特征提取器。第二个组件是鸟瞰图(BEV)特征和文本特征融合模块,它提取文本感知的BEV特征并获得更新的文本特征。最后,最后一个组件是多模态头,它由对比头和定位头组成。总之,我们的方法输出与文本输入相关的目标3D信息,包括目标的空间位置、大小、标题和其他细节。
Feature Extraction
本文的方法可以无缝地适应不同的文本和点云特征提取器。在我们的配置中,我们采用CLIP文本编码器作为文本骨干。对于点云提取器,我们提出了一个基于SECOND的新模块来获取鸟瞰图(BEV)特征,称为"OpenSECOND"。
并使用从外部信息中提取的所有单词。我们使用文本编码器来获取文本输入的嵌入,文本输入的嵌入式表示为,用于提示需要本地化和识别的内容。
对于点云,我们使用点云编码器来获取BEV特征,作为与文本输入的特征空间交互的特征空间。首先将3D空间划分为体素,将原始点云转换为二进制体素网格。随后,将3D稀疏卷积神经网络应用于体素网格进行特征表示。与前面提到的图像特征类似,Z轴 pooling生成了点云BEV特征图B。
BEV-Region Text Fusion Module
在融合多模态特征时,融合模块非常重要。在我们的Open3DWorld中,将其命名为BEV区域文本融合模块,因为它建立了每个BEV网格和每个文本之间的关系,并更新两者以对齐它们的特征空间。我们进行了广泛的实验来探索最适合我们任务的融合模块,并最终设计了图4所示的融合模块。
首先将鸟瞰图(BEV)特征展平,以获得展平的特征和文本特征。为了初步融合多模态特征,我们使用Max Sigmoid Attention Module通过使用文本特征来更新BEV区域特征,其格式为:
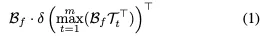
接下来,我们将更全面地融合BEV和文本特征。首先分别对BEV特征和文本特征进行self-att。考虑到大的BEV网格带来的计算负担,使用可变形的自关注来减少计算负担。接下来首先使用交叉注意力将文本特征聚合到鸟瞰图(BEV)特征中,然后使用交叉注意将BEV特征聚合到文本特征中。最后,我们使用FFN来调整特征维度。与Transformer中的编码器块一样,此融合过程执行N次。我们通过实验实现了N等于3,以实现效果和计算负担之间的平衡。
Contrastive Head and Localization Head
对于Contrastive head,使用几个conv来获得最终的BEV网格特征。接下来,我们使用以下公式计算每个BEV网格和文本之间的相似度,表示第i个BEV网格与第j个文本之间的相似性:
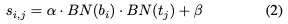
对于定位头,我们与传统的3D检测任务保持一致,并对所有信息进行回归,包括目标的空间位置、大小、航向和其他信息。我们的优势在于,基于与文本特征集成的边界元法特征来预测信息,因此更容易预测某个类别的属性。
Training and Evaluation
在获得BEV网格和文本之间的相似性图后,我们分两步获得GT热图。首先,我们将3D GT框投影到BEV特征图上,从而产生旋转框。例如,我们将一个3D盒子投影到BEV featmap中:
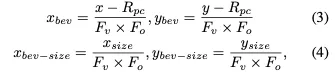
其次使用类似于YoloWorld的样本分配方法来获得H。最后使用交叉熵损失来监督训练,其格式为:
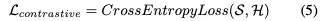

在评估过程中,在生成BEV网格和文本输入之间的相似性图(表示为S)后,我们应用预定义的分数阈值。如果BEV网格和相应文本之间的相似性得分超过此阈值,则网格被视为文本描述的目标的中心。然后通过提取相应网格的3D信息来识别和定位目标。最后,我们应用非最大抑制(NMS)来过滤和细化检测。
实验实验和分析
通过外部描述信息扩展词汇表,我们在NuScenes-T数据集上训练Open3DWorld,使其能够完成与之前的3D检测模型类似的检测任务。由于我们的词汇表包括检测任务的封闭集合中的类别,因此我们可以计算出类似于标准3D检测任务中的定量指标。
我们的检测精度可与专业的3D检测模型相媲美,无需采用额外的训练技术来提高性能。这是有意的,因为我们的主要目标是开发一个能够无缝集成新文本信息的通用开放词汇模型。Nussenes-T数据集的测试结果如表1所示。
Zero-Shot Performance:为了评估零样本性能,在Lyft Level 5数据集上运行了Open3DWorld。结果2表明,融合模型利用BEV特征和文本特征,可以在理论上对齐以实现分类。众所周知,在点云目标检测领域,当我们使用在一个数据集上训练的模型在另一个数据集中进行测试时,模型会崩溃。我们的方法不需要训练,可以在Lyft Level 5数据集上获得初步结果,这表明在文本特征和BEV特征对齐后,泛化能力远优于传统的检测模型。
讨论
从实验中获得的结论强调了所提出的融合模型的优缺点。3D点云和文本数据的集成显著提高了检测精度;然而,目前开放词汇类别的收集在数量和质量上仍然有限。与基于图像的开放词汇检测领域现有的数万个类别相比,我们的数据集需要进一步扩展。此外不同类别的比例不平衡,这对模型的性能产生了负面影响,特别是在长尾类别上。
为了应对这些挑战,未来的工作将侧重于自动收集开放词汇表数据注释或采用无监督的方法来训练模型,使其能够在现实世界场景中管理更广泛的类别。此外,未来的研究将探索其他数据模式的集成,并开发更先进的融合技术,以进一步增强自动驾驶环境中的目标检测能力。
结论
本文介绍了一种在自动驾驶中进行3D开放词汇检测的新方法,该方法利用了激光雷达和文本数据的融合。我们的方法使智能驾驶汽车能够适应新的文本输入,而不需要进行广泛的再训练,从而增强了它们在多样化和动态环境中运行的能力。通过将3D点云与文本数据集成,我们的方法直接从文本查询中改进了目标定位和识别。我们的框架的有效性已经通过在NuScenes-T数据集上的广泛实验得到了证明,并在Lyft Level 5数据集上得到了验证,展示了它在现实世界场景中的鲁棒性和多功能性。通过推进多模态数据的集成,这项工作有助于开发更安全、更可靠、更高效的自动驾驶系统,为未来更具适应性和智能的感知模型铺平了道路。
#HeightLane
车道线还有的卷?超越BEV-LaneDet等一众SOTA!
单目图像的准确3D车道线检测面临重大挑战,主要由于深度信息的歧义性和地面建模的不完善。以往的研究通常采用具有有限自由度的平面地面假设进行地面建模,这在复杂道路环境中,尤其是存在不同坡度的情况下,显得力不从心。本研究提出了一种名为HeightLane的创新方法,它基于多斜率假设创建锚点,从单目图像中预测出高度图,从而提供对地面的详细和精确表示。HeightLane结合了预测出的高度图和基于可变形注意力机制的空间特征转换框架,高效地将2D图像特征转换为3D鸟瞰视图(BEV)特征,增强了空间理解力和车道结构识别能力。此外,高度图还被用于BEV特征的位置编码,进一步提升了空间精度。这种显式视图转换方法有效地弥合了前视感知与空间精确的BEV表示之间的差异,显著提高了检测性能。为了解决原始OpenLane数据集中缺少必要的地面真实高度图的问题,作者利用Waymo数据集的LiDAR数据,为每个场景的可行驶区域生成了高度图。使用这些真实高度图训练了从单目图像中提取高度图的模块。在OpenLane验证集上的广泛实验表明,HeightLane在F-score等指标上达到了最先进的性能,展示了其在现实世界应用中的潜力。
相关工作总结3D车道检测
3D车道检测对于现实驾驶场景中的准确定位至关重要。虽然2D车道检测已经得到了广泛的研究,但关于3D车道建模的却相对较少。传统的方法通常使用逆透视变换(IPM)将2D特征转换到3D空间,基于道路平坦的假设。然而,这种假设在遇到斜坡或下坡等不平坦地形时会失效,导致特征表示扭曲和可靠性降低。
SALAD通过结合前视图图像分割与深度估计来解决3D车道检测问题,但它依赖于密集的深度注释和精确的深度预测。此外,远处车道因显得较小,每个像素覆盖的深度范围更广。M2-3DLaneNet通过融合LiDAR数据增强单目3D检测,将图像特征提升至3D空间,并在鸟瞰视图(BEV)空间中融合多模态数据,但这增加了数据收集的复杂性和成本。DV-3DLane同样使用LiDAR和相机输入进行3D车道检测,但它从两种来源生成车道查询,而非提升图像特征。
与此同时,BEVLaneDet采用视图关系模块学习图像特征与BEV特征之间的映射,要求两者之间的关系固定。该论文引入了一种虚拟坐标,始终使用特定的外参矩阵和内参矩阵来调整图像。此外,它不是使用BEV特征的锚点,而是提出一种在BEV上直接预测车道的关键点表示法。LATR和Anchor3DLane通过将地面假设为具有2个自由度(2-DoF)的平面,在3D车道检测方面取得了最新进展。
LATR使用地面建模作为变换器中的位置编码,预测地面的俯仰角和高度;而Anchor3DLane则利用俯仰角和偏航角进行2D特征提取。与此不同,作者的方法HeightLane在BEV空间中仅使用LiDAR创建地面真实高度图。与M23DlaneNet不同,后者在推理过程中需要同时使用LiDAR和相机数据,而HeightLane仅依赖相机数据简化了推理过程。作者的方法不是用2-DoF对地面进行建模,而是预测预定义BEV网格中每个点的高度,创建了一个密集的高度图。通过采样专注于地面的空间特征,作者生成了BEV特征,允许使用关键点表示法进行准确的3D车道预测,有效地桥接了2D图像数据和3D车道几何学。这种方法优化了空间特征的处理,在保持高精度的同时提高了效率。
鸟瞰视图高度建模
BEVHeight引入了一种新颖的方法,将深度估计中使用的深度分箱技术应用到高度概念上。这种方法通过对图像中的物体高度箱进行分类,首次提出了一种回归方法,用于确定3D目标检测中物体与地面之间的高度。然而,该方法的实验仅限于路边相机数据集,限制了研究的应用范围。BEVHeight旨在通过利用物体的高度信息,提供更精确的3D位置信息。
另一方面,HeightFormer利用Nuscenes自动驾驶数据集,尝试回归物体与地面之间的高度。HeightFormer将预测的高度信息整合到变换器的解码器中,与基于深度的方法相比,实现了性能的提升。这一改进展示了利用高度信息进行更准确3D目标检测的潜力。
作者提出的方法HeightLane,利用了车道始终附着在地面上的特性。通过仅预测相对于地面的高度,HeightLane显式地将图像特征转换到对应于地面的预定义BEV网格中。这种方法简化了任务,旨在提高3D目标检测中空间转换的准确性。
HeightLane方法详解
作者提出的HeightLane整体架构展示于图2。输入一个RGB前视图图像 ,其中 和 分别代表图像的高度和宽度。利用ResNet-50作为CNN骨干网络提取前视图特征 。定义一个与自我车辆相对应,代表地面的预设BEV网格 ,其中 和
图 2. HeightLane方法的总体架构图。HeightLane接收一个2D图像作为输入,并通过卷积神经网络(CNN)主干提取多尺度的前视图特征。利用预定义的多斜率高度图锚点、车辆坐标到相机坐标的外参矩阵 以及相机的内参矩阵 ,将2D前视图特征采样到鸟瞰视图(BEV)网格上,以形成BEV高度特征。随后,该BEV高度特征通过一个CNN层进一步处理,以预测高度图。预测出的高度图用于空间特征的转换,其中初始的BEV特征查询和高度图共同确定了查询在前视图特征中应参考的像素点。在这个过程中,前视图特征充当键和值,而BEV特征则作为查询。通过可变形注意力机制,这一流程最终生成了增强的BEV特征查询。
基于PersFormer研究的洞察,作者提出了一种高度图引导的空间特征转换框架。该框架基于观察到的2D前视图特征可以作为键和值,而BEV特征可以作为查询在可变形交叉注意力中使用。与PersFormer研究假设地面为平面并使用IPM将前视图特征转换为BEV特征查询不同,本方法使用在预定义BEV网格内预测的高度图,允许作者匹配每个BEV特征查询与相应的前视图特征,不依赖于地面平坦的假设。这使得可变形注意力的执行更加高效。这些转换后的BEV特征
高度提取模块高度预测
高度图 的分辨率为每像素0.5米,表示从车辆位置向前 米和向两侧各 米范围内的高度信息,其中高度值为零。与直接从前视图特征预测路面的其他研究不同,作者首先定义了一个密集的BEV网格 ,然后预测这个网格内所有对应点的高度图 。这需要创建BEV特征,这些特征来源于2D前视图特征,以准确捕获高度信息。例如,生成一个斜率为零的高度图锚 ,用作获取BEV网格 的3D坐标。然后,使用内参矩阵和外参矩阵将这个高度图锚投影到图像上,采样对应于BEV点的前视图特征。投影高度图锚
其中, 和 分别表示相机内参矩阵和从自我车辆坐标到相机的变换矩阵,
与投影的 一起,从高度图特征 中采样前视图特征
其中 表示多个斜率。如果实际道路在图像中存在斜率,使用单一斜率锚无法确保图像特征与BEV网格之间的对齐。为此,作者使用多斜率高度锚进行采样,然后将这些特征连接起来形成最终的BEV高度特征 。利用 ,可以预测高度图 :
其中 并且
高度监督
由于OpenLane数据集缺乏地面点云或标签信息,现有研究主要集中在仅包含车道的区域进行数据创建和监督。LATR只在有车道的区域应用损失以估计地面的俯仰角和高度。类似地,LaneCPP通过在车道存在区域插值结果来模拟地面。为了提供密集的高度图真实标注,作者使用Waymo数据集中的LiDAR点云,这是OpenLane的基础数据集。通过累积Waymo数据中每个场景的可行驶区域的LiDAR点云,获得了每个场景的密集地面点云。然后,将这个密集地面点云采样到预定义的BEV网格 上,并用作高度图
图 3. 在OpenLane验证集中展示的"上坡和下坡"场景下,LiDAR数据累积的结果。左侧的颜色条表示与道路高度相对应的颜色值。
高度引导的空间变换框架
作者提出的空间变换框架利用第3.1节预测的高度图,如图4所示。BEV初始查询经过自注意力模块处理,在自注意力过程中,BEV查询之间进行交互,并为每个BEV查询添加位置编码以提供位置信息。位置编码是可学习的参数。与在2D FV特征上执行注意力的研究不同,作者的方法使用BEV网格坐标和每个BEV查询的高度嵌入进行位置编码。
图 4. 使用可变形注意力的高度引导空间变换框架结构图。该框架展示了BEV查询如何在自注意力阶段接收高度位置编码,并在交叉注意力阶段通过高度图映射到图像像素。可变形注意力学习了从参考点到周围区域的偏移,以生成多个参考点。
自注意力模块输出的查询 在第
其中 是层索引,
经过自注意力处理的BEV查询 与2D前视图特征执行可变形交叉注意力。可变形注意力为每个查询定义了参考点 并学习从这个参考点到周围区域的偏移。这些可学习的偏移决定了最终的参考点,并且在前视图特征 中与这些最终参考点对应的特征作为交叉注意力中的值与BEV查询相互作用。由于作者有对应于BEV网格的高度图 ,作者可以精确地确定每个BEV网格像素将被投影到前视图特征中的参考点 ,如下所示:
经过交叉注意力处理的查询 在第
HeightLane中的空间变换由多个层组成,每层都包含自注意力和交叉注意力模块。实验中,作者将层数设置为 。通过所有 层的BEV查询成为车道检测头部的输入特征。为了捕获不同分辨率的前视图特征,作者采用了多尺度前视图表示。为每种分辨率生成一个BEV查询,最终的BEV特征
训练
通过空间变换框架生成的 会经过几层卷积网络,预测BEV网格的置信度、偏移和嵌入,遵循BEVLaneDet的关键点表示法。预测的密集高度图 被用作3D车道的表示,连同置信度、偏移和嵌入。置信度
其中,BCE表示二元交叉熵损失,IoU代表交并比损失。
车道在x方向上的预测偏移损失定义为:
在22中,每个网格单元的嵌入被预测以区分置信度分支中每个像素的车道身份。作者采用了相同的嵌入损失,如公式(10)所示,其中 表示拉力损失,用于最小化类内方差,而
预测的高度图 与真实高度图
为了确保2D特征有效地捕获车道特征,作者增加了一个2D车道检测头,并结合了一个辅助损失用于2D车道检测,如公式(12)所示:
最终,总损失由公式(13)定义,其中
这个损失函数综合了置信度损失、偏移损失、嵌入损失、高度图损失和2D车道检测损失,以优化整个网络的性能。
实验结果和分析数据集
作者的方法在OpenLane数据集上进行了评估,该数据集覆盖了多样的道路条件、天气状况和照明环境。OpenLane建立在Waymo数据集基础之上,使用了150,000张图像用于训练,40,000张图像用于测试。该数据集包含798个训练场景和202个验证场景,每个场景大约包含200张图像。尽管OpenLane数据集本身不包含生成高度图所需的信息,但由于其基于Waymo数据集构建,作者能够从中提取每个OpenLane场景所需的LiDAR数据。在提取LiDAR数据的过程中,作者注意到数据在每个场景的中部密集,而在末端帧则变得稀疏。例如,图3展示了一个场景,其中车辆启动、上坡、右转,并继续行驶在另一段坡道上。在起始点(绿色区域),LiDAR数据较为稀疏,因此作者采用了双线性插值来填补高度图中的空隙,以确保高度图的一致性。作者的评估包括了多种场景,如上坡/下坡、曲线、极端天气、夜间、交叉口以及合并/分流等条件。评估指标包括F分数、近端和远端的X误差以及Z误差。
实现细节
作者采用了ResNet-50作为2D特征提取的骨干网络,并将图像尺寸设定为576×1024像素。为了获得多尺度的图像特征,作者增加了额外的CNN层,以产生尺寸为输入图像1/16和1/32的特征图,每个特征图具有1024个通道。高度图和BEV特征的BEV网格尺寸被设置为200×48像素,分辨率为每像素0.5米。在高度提取模块中,作者为多斜率高度图锚点设置了-5°、0°和5°的斜率Θ。在5°的斜率下,高度图能够表示高达约8.75米的高度。在高度引导的空间特征转换中,作者使用了具有2个注意力头和4个采样点的可变形注意力机制。位置编码是通过嵌入BEV网格的X和Y位置以及相应的预测高度来生成的。
在OpenLane上的评估定性结果
图5展示了OpenLane验证集上的定性评估结果。作者的方法HeightLane、现有的最佳性能模型LATR以及地面真实值的预测结果被可视化展示。其中,地面真实值用红色表示,HeightLane用绿色表示,LATR用蓝色表示。图5的第一行展示了输入图像,第二行展示了在3D空间中HeightLane、LATR和地面真实值的可视化对比。第三和第四行分别从Y-Z平面视角展示了HeightLane与地面真实值、LATR与地面真实值的3D车道对比。
图 5. 在OpenLane验证集上,与现有最佳性能模型LATR相比,作者的方法HeightLane的定性评估结果。第一行:输入图像。第二行:3D车道检测结果 - 真实值(红色)、HeightLane(绿色)、LATR(蓝色)。第三行和第四行:从Y-Z平面视角展示的真实值与HeightLane、LATR的对比。放大可查看更多细节。
特别是,HeightLane即使在车道中断后再次出现的场景中,如交叉口或减速带上方,也能准确检测到车道。这一点在图5的第1、2、4、5和6列中尤为明显。例如,在第1列中,尽管存在车辆遮挡和部分车道标记不完整,HeightLane仍然能够提供精确的车道预测,证明了其在处理具有遮挡和信息不完整的复杂场景中的鲁棒性。此外,借助高度图的使用,HeightLane有效地模拟了道路坡度的变化,如图3所示,道路从平坦过渡到有坡度的情况。在展示曲线道路和部分可见车道的第2和5列中,HeightLane展示了其在曲线上维持连续车道检测的优越预测精度和性能。
图6可视化了高度提取模块预测的高度图,从左到右依次为输入图像、预测高度图和地面真实值高度图。场景从上到下依次为上坡、平地和下坡路段,更多可视化结果可在补充材料中找到。
图 6. 高度提取模块的可视化结果。从左至右依次为:输入图像、预测的高度图和真实值高度图。图像展示了上坡、平地和下坡的场景。
定量结果
表1展示了HeightLane在OpenLane验证集上的定量评估结果。作者的模型在总体F分数上达到了62.5%,超越了所有现有的最先进模型。特别是在极端天气、夜间和交叉口等具有挑战性的场景中,HeightLane实现了显著的性能提升,并在这些条件下取得了最佳成绩。此外,HeightLane在曲线和合并/分流场景中也展现了强劲的性能,获得了这些类别中的第二佳表现。尽管在持续上坡或下坡的场景中,HeightLane的表现不是最佳,因为在这些情况下,2-DoF平面假设已经足够。然而,HeightLane在斜率变化的场景中表现出色,如图5第3列所示,证明了其在处理变化坡度条件下的适应性和预测能力。
表 1. 在OpenLane验证集的不同场景下,使用F分数对不同方法进行的定量结果比较。每个场景中最佳和次佳结果分别用粗体和下划线标出。
表2展示了Openlane验证集上的F分数、X误差和Z误差的定量比较结果。HeightLane在F分数方面取得了最佳成绩,超越了其他所有模型,达到了62.5%。虽然在Z误差方面并未达到最佳或第二佳的表现,但仍然展示了具有竞争力的结果。在X误差方面,HeightLane实现了第二佳的性能,证明了其在横向方向上准确估计车道位置的能力。
表 2. 在OpenLane验证集上,与其他模型的定量结果比较。评估指标包括F分数(越高越好)、近端和远端的X误差与Z误差(越低越好)。最佳和次佳结果分别用粗体和下划线标出。
消融实验
表3展示了不同高度提取方法对应的F分数。视图关系模块,最初在18中提出,并在22中作为一个MLP模块用于转换BEV特征。单斜率高度图锚点方法将零高度平面投影到图像上,并使用从该平面采样的图像特征作为BEV特征。然而,这种方法假设地面是平坦的,并且仅在该高度处采样2D图像特征,导致特征表示不完整。相比之下,作者提出的多斜率高度图锚点方法在图像上投影了具有不同斜率的多个平面,从每个平面采样图像特征,并将它们融合以形成BEV特征。这种多锚点方法实现了最高的F分数。
表 3. 根据不同的高度提取方法得到的F分数比较。表格中标粗的配置表示作者最终采用的方案。
表4展示了不同高度图锚点设计对应的F分数。第一行对应于表3中的单斜率高度图锚点。当使用0°加上±3°时,性能比仅使用0°提高了4.5%。同样,使用0°加上±5°时,性能提升了6.3%。尽管0°、±3°和±5°的配置实现了最佳性能,但与仅使用0°和±5°相比,性能提升的边际效应较小。然而,增加高度图锚点的数量会增加最终BEV高度特征中的通道数,从而增加计算成本。为了在性能和计算效率之间取得平衡,作者最终选择了0°和±5°高度图锚点的配置作为论文中的最终方法。
表 4. 根据不同高度图锚点设计得到的F分数比较。表格中标粗的配置表示作者最终采用的方案。
表5将作者的方法与各种多模态3D车道检测器进行了比较。其中,Ours (GT)表示在推理步骤中使用真实高度图代替高度提取模块获得的结果。这种替代旨在观察在假设高度提取模块预测的高度图非常准确的情况下,空间特征变换框架的性能。通过使用从LiDAR数据获得的真实高度图,作者可以与使用LiDAR输入的检测器进行公平的比较。结果表明,当高度图预测准确时,作者的HeightLane方法能够实现与使用LiDAR和相机输入的模型相当或甚至更好的性能。这证明了作者方法的潜力,能够有效地利用精确的高度信息,突出了作者在2D图像数据和3D车道几何转换中的鲁棒性和能力。
表 5. 与多模态模型在OpenLane验证集上的比较结果。"Ours (GT)"表示在推理阶段使用真实高度图代替预测的高度图。其中,M代表仅使用相机数据,ML代表同时使用相机和LiDAR数据。
结论
作者的研究工作通过提出一种创新的高度图方法,成功克服了单目图像中3D车道检测面临的主要挑战,包括深度信息的不确定性和地面建模的不完善性。作者的主要贡献包括:
定义了一个用于直接从图像中预测高度信息的鸟瞰视图(BEV)网格和多斜率高度锚点。
提出了一个由高度图引导的空间特征转换框架。
在OpenLane数据集的复杂场景中,实证展示了作者的HeightLane模型的卓越性能。
本研究所提出的方法通过高度图增强了对空间结构的理解和车道的识别能力,显著提升了自动驾驶车辆系统的技术水平。通过精确的3D变换,这些技术进步为自动驾驶领域的发展提供了强有力的支持。作者通过广泛的实验验证了模型的有效性,这标志着在将3D车道检测技术应用于现实世界场景方面迈出了重要的一步。
#CrossFormer
加州大学最新!适用于操作、导航、运动的统一策略
原标题:Scaling Cross-Embodied Learning: One Policy for Manipulation, Navigation, Locomotion and Aviation
论文链接:https://arxiv.org/pdf/2408.11812
项目链接:https://crossformer-model.github.io/
代码链接:https://github.com/rail-berkeley/crossformer
作者单位:加州大学伯克利分校 卡内基梅隆大学
论文思路:
现代机器学习系统依赖于大规模数据集来实现广泛的泛化,而这在机器人学习中往往是一个挑战,因为每种机器人平台和任务可能只有一个小数据集。通过在多种不同类型的机器人上训练单一策略(single policy),机器人学习方法可以利用更广泛和多样化的数据集,从而实现更好的泛化和鲁棒性。然而,在多机器人数据(multi-robot data)上训练单一策略具有挑战性,因为机器人可能具有截然不同的传感器、执行器和控制频率。本文提出了CrossFormer,一种可扩展且灵活的基于Transformer的策略,能够处理来自任何实体(embodiment)的数据。本文在迄今为止最大和最具多样性的数据集上训练了CrossFormer,该数据集包含了来自20种不同机器人实体的90万条轨迹。本文展示了相同的网络权重可以控制截然不同的机器人,包括单臂和双臂操作系统、轮式机器人、四旋翼飞行器和四足机器人。与以往的工作不同,本文的模型不需要手动对齐观测空间或动作空间。大量现实世界中的实验表明,本文的方法不仅能匹配为每个实体量身定制的专用策略的性能,还显著超越了现有的跨实体学习(cross-embodiment learning)的最先进方法。
论文设计:
近年来,机器学习的许多成功都得益于在日益多样化和多任务数据上训练通用模型。例如,视觉和语言任务,曾经由特定任务的方法处理,如今通过通用的视觉-语言模型能够更有效地完成,这些模型可以在任务之间迁移知识 1, 2, 3, 4。类似地,在机器人领域,最近的数据聚合工作 5 使得可以在跨多个实体、任务和环境的机器人数据上训练通用策略(general-purpose policies)。这些通用策略通过迁移视觉表示和技能,能够超越那些仅使用目标机器人和任务数据训练的狭窄策略(narrow policies) 6, 5。除了正迁移(positive transfer)带来的好处之外,训练通用的跨实体策略还减少了为每个机器人设计和调整策略架构所需的工程工作量。
然而,训练通用的机器人策略具有独特的挑战性,因为机器人系统在相机视角、本体感知输入(proprioceptive inputs)、关节配置、动作输出和控制频率等方面可能存在极大的差异。最初在大规模跨实体策略训练上的努力通常局限于单一的机械臂或地面导航机器人,这些机器人可以通过单一的相机视角和基座或末端执行器的相对航点动作进行控制 5, 6, 7, 8。要进一步增加这些策略所能控制的实体的多样性,就需要一种支持任意数量的相机视角或本体感知观测,以及预测任意维度动作的模型架构。遵循以往的工作,本文采用了顺序建模的方法来进行跨实体模仿学习 9, 10。本文提出了一种基于Transformer的策略,通过将输入和输出转换为序列来支持可变的观测和动作。本文将这一方法扩展到目前为止能够用单一策略控制的最为多样化的实体集,包括单臂和双臂机器人、地面导航机器人、四旋翼飞行器和四足机器人。
通过本文的Transformer策略,本文可以通过简单地将观测数据 tokenizing 并排列成序列,来训练具有任意数量相机视角或本体感知传感器的机器人数据。同时,本文可以预测任意维度的动作,关键是无需手动对齐不同实体的动作空间 8。对于每种动作类型,本文将一组动作读取tokens(action readout tokens)插入到输入 token 序列中。然后,本文将相应的输出嵌入传递到特定于动作空间的头部,以生成正确维度的向量。本文的策略可以接受以语言指令或目标图像形式呈现的任务,使用户能够选择最适合特定实体的任务模式。
本文的主要贡献是一种跨实体的机器人策略,该策略在迄今为止最大、最具多样性的机器人数据集上训练完成,包含90万条轨迹和20种不同的实体。本文的策略能够控制具有不同观测和动作类型的机器人,从具有本体感知传感器和12个关节的四足机器人,到配备3个相机和14个关节的双臂机器人。在大量的现实世界实验中,本文发现本文的策略能够匹敌仅在目标机器人数据上训练的相同架构的性能,以及在每种设置中表现最佳的现有方法,这表明本文的架构能够吸收异构的机器人数据而不会产生负迁移,同时在性能上可以媲美为每个机器人量身定制的最先进的专用方法。此外,本文还发现,本文的方法在跨实体学习中优于现有的最先进方法,同时减轻了手动对齐观测空间和动作空间的需求。
在多种实体的机器人学习中,主要挑战在于处理观察空间和动作空间的巨大差异,以及控制频率和机器人系统其他方面的差异。机器人系统可能具有不同数量的相机视角或本体感知传感器,并且可能通过多种不同的动作表示进行控制,包括关节角度、笛卡尔坐标位置和电机扭矩。为了将数据标准化为统一的格式,以往一些关于跨实体策略训练的工作忽略了某些观察类型(例如操作中的腕部视角或第三人称视角)5, 7,或在机器人之间对齐了动作空间8。而本文则遵循其他相关研究9, 10, 6,将跨实体模仿学习视为一个序列到序列的问题,并选择了基于Transformer的策略架构,以处理长度可变的序列输入和输出。
由于Transformer策略的序列化特性,本文可以将每种实体的所有可用观察类型编码为一个扁平的序列。同样地,这种方法允许本文解码可变长度的动作,使本文能够为每种实体使用最佳的动作类型。利用这种灵活的输出方式,本文还可以预测不同大小的动作块。动作块化(Action Chunking)48, 47, 49能够提高动作的时间一致性,并减少累积误差,这对于高频率的精细操作尤为重要。结合Transformer骨干网络和动作块化技术,本文的策略能够控制从使用20Hz关节位置控制的双臂ALOHA系统,到使用5Hz二维航点控制的地面和空中导航机器人等多种机器人。
从总体上看,本文的Transformer策略遵循了以往在多模态数据上训练Transformers的研究9, 10, 6。具体来说,观察数据和任务规范首先通过特定模态的分词器进行分词处理,然后组装成一个token序列,并输入到一个因果性的、仅解码器的Transformer骨干网络中,这个网络在所有实体之间共享。接下来,输出的嵌入向量会被输入到为每类实体设计的独立动作头中,以生成对应维度的动作。有关本文架构的概览,请参见图2。接下来,本文将更详细地描述本文的训练数据以及架构的各个组成部分。
图1:本文介绍了CrossFormer,这是一种基于Transformer的策略,经过在90万条多样化、多实体机器人数据轨迹上的训练,能够控制截然不同的机器人,包括单臂和双臂操作系统、轮式机器人、四旋翼飞行器和四足机器人,同时在性能上匹敌针对每个实体的专用策略,并在跨实体学习中优于以往的工作。
图2:策略架构。本文的架构通过Transformer主干网络实现跨实体策略学习。本文的策略通过将图像和本体感知信息 tokenizing 来接收可变的观测输入,通过动作读取tokens(action readout tokens)预测可变的动作输出,并基于语言指令或目标图像进行条件判断。
实验结果:
图3:训练数据组合。本文将训练数据中的20种实体分为不同类别,并可视化它们在数据组合中的贡献。饼图显示了每个训练批次中基于采样权重的平均组成情况。
图4:评估设置。本文的任务包括单臂操作设置、灵巧和双臂任务设置、导航以及航空任务。详细分类请参见第4节。
图5:实际评估。本文将CrossFormer与仅在目标机器人数据上训练的相同架构进行比较,同时也与在目标机器人数据上表现最佳的现有方法进行对比。
图6:与Yang等人8的比较。本文将CrossFormer与Yang等人8的方法进行比较,该方法对导航和操作任务的动作进行对齐,并且一次只使用单一相机视角。CrossFormer在整体表现上优于Yang等人8三倍,无论是在使用第三人称相机视角进行的桌面操作任务上,还是在常见的导航任务中,均表现出色。
总结:
本文引入了CrossFormer,这是一种可扩展且灵活的Transformer策略,基于迄今为止最大且最为多样化的数据集进行训练,包括20种不同机器人实体的90万条轨迹。本文展示了一种系统化的方法来学习单一策略,该策略能够控制截然不同的实体,包括单臂和双臂操作系统、轮式机器人、四旋翼飞行器和四足机器人。本文的结果表明,CrossFormer的表现与专门针对单一实体的策略相媲美,同时在跨实体学习中显著优于当前的最先进方法。
然而,本文的工作也存在一些局限性。本文的结果尚未显示出在不同实体之间的显著正迁移效应。本文预计,随着本文在更大、更具多样性的机器人数据集上进行训练,本文将看到更大的正迁移效应。另一项局限性是,本文的数据组合使用了人工挑选的采样权重,以避免在包含大量重复情节的数据集上过度训练,或在与本文的评估设置最相关的数据上训练不足。原则上,随着模型规模的扩大,策略应具备同等良好地拟合所有数据的能力,而无需进行数据加权。
最后,由于本文需要大型模型来适应大规模的多机器人数据集,模型的推理速度可能成为一个限制因素。在本研究中,本文成功地将本文的策略应用于高频率、细粒度的双臂操作任务中,但随着模型规模的扩大,本文可能无法控制这些高频率的实体。未来的硬件改进将有助于缓解这一问题,但在如何利用大型模型来控制高频率机器人方面仍需进一步研究。
未来的工作还可以包括探索技术以实现更大的跨实体正迁移,同时保持本文架构的灵活性、改进数据管理技术,并引入更多样化的数据源,如次优的机器人数据或无动作的人类视频。本文希望这项工作能够为开发更通用且灵活的机器人策略打开大门,使其能够有效地从在不同机器人实体上收集的经验中学习并迁移知识。
#Drive-OccWorld
且看世界模型如何拿下端到端!
世界模型基于各种自车行为预测潜在的未来状态。它们嵌入了关于驾驶环境的广泛知识,促进了安全和可扩展的自动驾驶。大多数现有方法主要关注数据生成或世界模型的预训练范式。与上述先前的工作不同,我们提出了Drive-OccWorld,它将以视觉为中心的4D预测世界模型应用于自动驾驶的端到端规划。具体来说,我们首先在内存模块中引入语义和运动条件规范化,该模块从历史BEV嵌入中积累语义和动态信息。然后将这些BEV特征传输到世界解码器,以进行未来时刻的OCC和flow预测,同时考虑几何和时空建模。此外我们在世界模型中注入灵活的动作条件,如速度、转向角、轨迹和命令,以实现可控发电,并促进更广泛的下游应用。此外,我们探索将4D世界模型的生成能力与端到端规划相结合,从而能够使用基于职业的成本函数对未来状态进行连续预测并选择最佳轨迹。对nuScenes数据集的广泛实验表明,Drive-OccWorld可以生成合理可控的4D占用,为推动世界生成和端到端规划开辟了新途径。
总结来说,本文的主要贡献如下:
提出了Drive OccWorld,这是一个以视觉为中心的世界模型,旨在预测4D Occ和flow,我们探索了世界模型的未来预测能力与端到端规划的整合。
设计了一个简单而高效的语义和运动条件归一化模块,用于语义增强和运动补偿,提高了预测和规划性能。
提供了一个统一的调节接口,将灵活的动作条件集成到后代中,增强了Drive OccWorld的可控性,并促进了更广泛的下游应用。
相关工作回顾World Models for Autonomous Driving
基于未来状态的生成模式,现有的自动驾驶世界模型主要可分为基于2D图像的模型和基于3D体积的模型。2D Image-based Models:旨在使用参考图像和其他条件(例如动作、HDMaps、3D框和文本提示)预测未来的驾驶视频。GAIA-1使用自回归Transformer作为世界模型,根据过去的图像、文本和动作标记预测未来的图像标记。其他方法,如DriveDreamer、ADriver-I、DrivengDiffusion,GenAD、Vista、Delphi和Drive-WM,使用潜在扩散模型(LDMs)生成图像到输出视频。这些方法侧重于设计模块,将动作、BEV布局和其他先验元素纳入去噪过程,从而产生更连贯、更合理的未来视频代。
3D Volume-based Models:以点云或占领的形式预测未来的状态。Copilot4D使用VQVAE对LiDAR观测进行标记,并通过离散扩散预测未来的点云。ViDAR实现了视觉点云预测任务,以预训练视觉编码器。UnO根据激光雷达数据预测了一个具有自我监督功能的持续占领区。OccWorld和OccSora使用场景标记器压缩职业输入,并使用生成变换器预测未来的职业。UniWorld和DriveWorld提出通过4D职业重建进行4D预训练。
在这项工作中通过输入动作条件来实现动作可控生成,并将这种生成能力与端到端的安全驾驶规划者相结合,从而研究了世界模型的潜在应用。
Drive-OccWorld方法详解准备工作
端到端的自动驾驶模型旨在直接基于传感器输入和自我行为来控制车辆(即规划轨迹)。从形式上讲,给定历史传感器观测值和h个时间戳上的自我轨迹,端到端模型A预测了未来f个时间戳的理想自车轨迹:
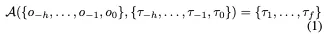
驾驶世界模型W可以被视为一种生成模型,它将先前的观察和自车行为作为输入,生成环境的合理未来状态:
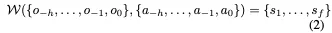
鉴于世界模型预测未来状态的能力,我们建议将其与规划器集成,以充分利用世界模型在端到端规划中的能力。具体来说引入了一个名为Drive-OccWorld的自回归框架,该框架由一个用于预测未来职业和流动状态的生成世界模型W和一个基于职业的规划器P组成,该规划器P使用成本函数来基于评估未来预测来选择最佳轨迹。从形式上讲,我们将Drive OccWorld公式化如下,它自动回归预测下一个时间戳的未来状态和轨迹:
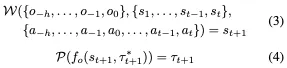
值得注意的是,对于动作可控的生成,可以以速度等形式将a注入W中作为条件,并丢弃P以防止潜在的自车状态泄漏。在端到端规划中,预测轨迹用作处的动作条件,用于预测下一个状态,从而不断推出预测和规划。
在接下来的部分中,我们将详细介绍世界模型的结构,为W配备动作可控生成,并将其与P集成以进行端到端规划。
4D Forecasting with World Model
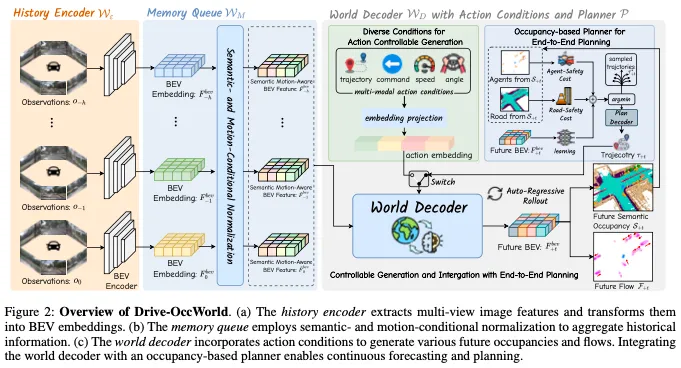
如图2所示,Drive-OccWorld包括三个组件:(1)历史编码器WE,它将历史相机图像作为输入,提取多视图几何特征,并将其转换为BEV嵌入。根据之前的工作,我们使用视觉BEV编码器作为我们的历史编码器。(2)具有语义和运动条件归一化的记忆队列WM,它在潜在空间中采用简单而高效的归一化操作来聚合语义信息并补偿动态运动,从而积累更具代表性的BEV特征。(3)世界解码器WD,其通过具有历史特征的时间建模来提取世界知识,以预测未来的语义职业和流动。灵活的动作条件可以注入WD,以实现可控生成。集成了基于occ的规划器P,用于连续预测和规划。
Semantic- and Motion-Conditional Normalization旨在通过结合语义和动态信息来增强历史BEV嵌入。
如图3所示,我们实现了一个轻量级的预测头来生成体素语义概率:
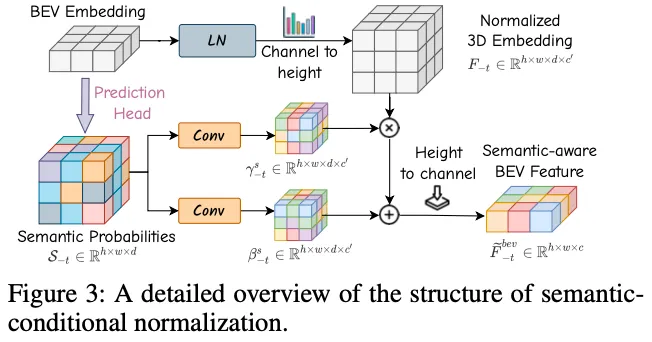
在运动条件归一化中,我们补偿自车和其他代理在不同时间戳上的运动。具体来说,自车姿态变换矩阵(考虑了自我载体从时间戳-t到+t的移动)被展平并编码到MLP处理的嵌入中,以生成仿射变换参数。
Future Forecasting with World Decoder:WD是一种自回归变换器,它根据存储在WM中的历史BEV特征和预期动作条件预测未来帧+t的BEV嵌入。
具体来说,WD将可学习的BEV查询作为输入,并执行可变形的自注意、与历史嵌入的时间交叉注意、与动作条件的条件交叉注意力以及前馈网络来生成未来的BEV嵌入。条件层在BEV查询和动作嵌入之间执行交叉注意力,这将在下一节中说明,将动作可控信息注入预测过程。在获得下一个BEV嵌入后,预测头利用通道到高度操作来预测语义占用和3D backward centripetal flow。
Action-Controllable Generation
由于现实世界的固有复杂性,自我载体的运动状态对于世界模型理解主体如何与其环境交互至关重要。因此,为了全面涵盖环境,我们建议利用各种行动条件,使Drive OccWorld具有可控生成的能力。
Diverse Action Conditions:包括多种格式:(1)速度在给定的时间步长定义为(vx,vy),表示自车辆沿x和y轴分解的速度,单位为m/s。(2)转向角从转向反馈传感器收集。根据VAD,我们将其转换为中的曲线。(3)轨迹表示自车位置到下一个时间戳的移动,公式为(),单位为米。它被广泛用作端到端方法的输出,包括我们的规划器P。(4)命令由前进、左转和右转组成,代表了控制车辆的最高级别意图。
Unified Conditioning Interface旨在将异质动作条件整合到连贯的嵌入中。我们首先将所需的动作编码到傅里叶嵌入中(,通过额外的学习投影将其连接和融合,以与WD中条件交叉注意力层的维度对齐。该方法有效地将灵活的条件集成到可控的生成中。
End-to-End Planning with World Model
现有的世界模型主要关注数据生成或自动驾驶的相关范式。尽管最近的一项开创性工作Drive WM提出将生成的驾驶视频与基于图像的奖励函数相结合来规划轨迹,但环境的几何3D特征并没有完全用于运动规划。如图2所示,鉴于我们的世界模型提供的未来occ预测能力,我们引入了一个基于occ的规划器,对代理和可驾驶区域的占用网格进行采样,以确定安全约束。此外,未来的BEV嵌入用于学习考虑细粒度3D结构的成本量,为安全规划提供更全面的环境信息。
基于占用的成本函数旨在确保自驾车的安全驾驶。它由多个成本因素组成:(1)代理安全成本限制了自车与其他代理(如行人和车辆)的碰撞。它惩罚与其他道路使用者占用的网格重叠的轨迹候选者。此外,在横向或纵向距离方面与其他主体太近的轨迹也受到限制,以避免潜在的碰撞。(2)道路安全成本确保车辆在道路上行驶。它从占用预测中提取道路布局,惩罚超出可驾驶区域的轨迹。(3)学习量成本受ST-P3的启发。它使用基于F bev+t的可学习头部来生成成本量,从而对复杂的世界进行更全面的评估。
BEV Refinement:引入BEV嵌入来进一步细化潜在空间中的轨迹。我们将编码为嵌入,并将其与命令嵌入连接起来,形成自我查询。最终的轨迹是通过MLP基于精炼的自我查询进行预测的。
规划损失Lplan由三个部分组成:引入的max-margin损失,用于约束轨迹候选的安全性;用于模仿学习的l2损失;以及确保规划轨迹避开障碍物占用的网格的碰撞损失。
实验结果Main Results of 4D Occupancy Forecasting
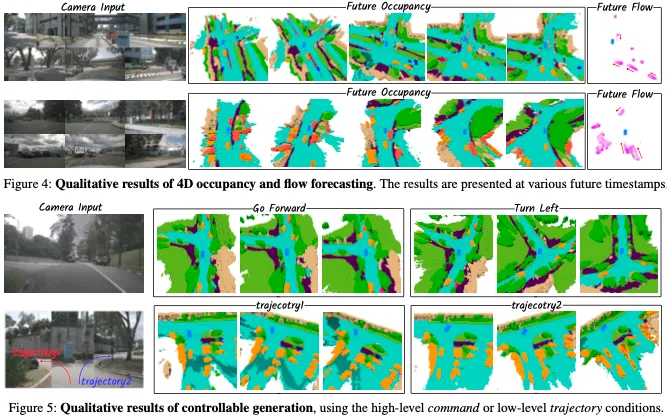
Inflated Occupancy and Flow Forecasting。表1展示了nuScenes数据集上Inflated的占用率和流量预测的比较。尽管Drive OccWorld在当前时刻的结果mIoUc上表现稍差,但它在mIoUf上的表现比Cam4DOcc高出2.0%,表明其预测未来状态的能力更强。

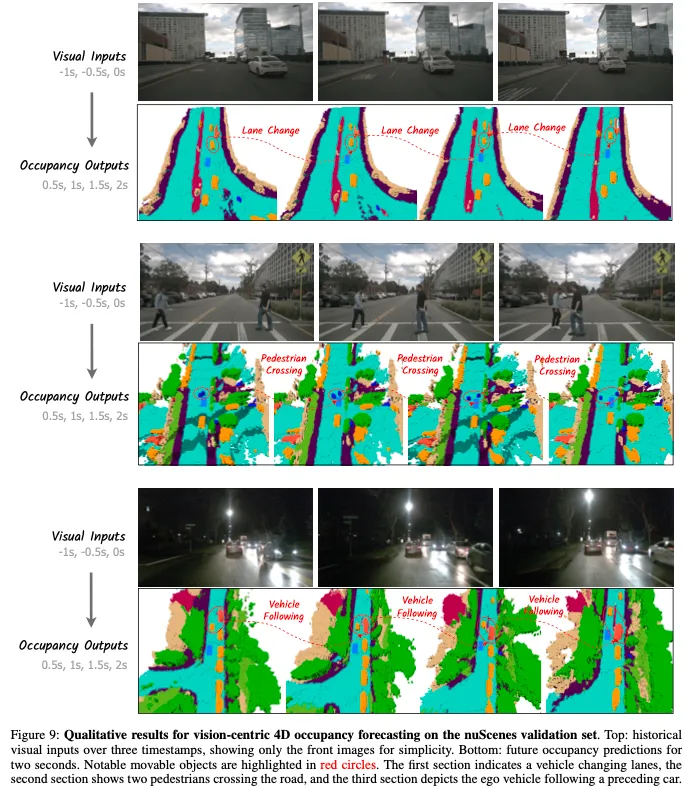
Fine-grained Occupancy Forecasting:表2展示了nuScenes占用率的细粒度占用预测比较。结果表明,与所有其他方法相比,Drive OccWorld实现了最佳性能。值得注意的是,对于当前和未来时间戳的一般可移动对象,Drive OccWorldP在mIoU上分别比Cam4DOcc高出1.6%和1.1%,这表明它能够准确定位可移动对象以进行安全规划。图4提供了跨框架的职业预测和流量预测的定性结果。
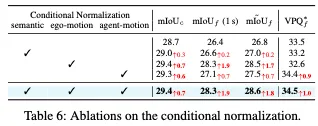
可控性。在表3中,我们考察了各种作用条件下的可控性。与基线变量相比,注入任何动作条件都会产生收益。值得注意的是,低水平条件,即轨迹和速度,为未来的预测提供了更大的改进。相比之下,最高级别的命令条件改善了当前时间戳的mIoUc结果,但对未来的预测提供了有限的增强。可以这么理解,结合更多的低级条件,如轨迹,可以为自车提供更具体的行动,以了解其与世界的相互作用,从而有效地增强未来的预测。
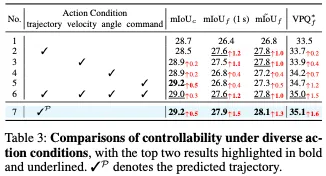
有趣的是,如表4所示,与使用预测轨迹相比,使用地面真实轨迹作为行动条件可以获得更好的规划结果。相反,在入住率和流量预测质量方面观察到相反的趋势。表3中第2行和第7行的比较表明,使用预测轨迹而不是地面真实轨迹可以略微提高预测质量。表1和表2中的结果进一步支持了这一观察结果,其中Drive OccWorldP的表现优于Drive OccWorldA。我们认为,在使用预测轨迹时,对BEV特征施加的轨迹约束可能会导致占用率和流量质量的性能提高。这一发现表明,应用轨迹预测也可以提高感知性能,这与UniAD的结果一致。

此外,在图5中,我们展示了Drive OccWorld基于特定自我运动模拟各种未来职业的能力,展示了Drive OccWorld作为神经仿真为自动驾驶生成合理职业的潜力。
End-to-end Planning with Drive-OccWorld
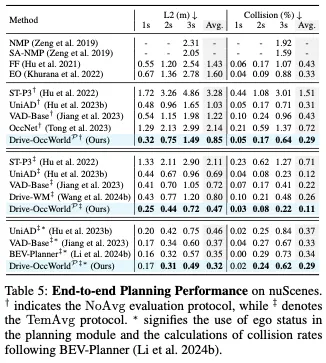
表5展示了与现有端到端方法相比,L2错误和冲突率方面的规划性能。我们提供ST-P3和UniAD不同评估方案设置下的结果。具体来说,NoAvg表示相应时间戳的结果,而TemAvg则通过0.5秒到相应时间戳之间的平均性能来计算指标。
如表5所示,与现有方法相比,Drive OccWorldP实现了更优的规划性能。例如,Drive OccWorldP†在以下方面分别获得了33%、22%和9.7%的相对改善L2@1s、L2@2s和L2@3s与UniAD相比†。我们将这一改进归因于世界模型积累世界知识和展望未来状态的能力。它有效地增强了未来时间戳的规划结果,并提高了端到端规划的安全性和鲁棒性。
最近的研究考察了将自车状态纳入规划模块的影响。根据这项研究,我们还对我们的自我状态模型和之前的工作进行了公平的比较。我们的研究结果表明,Drive OccWorld在遥远的未来时间戳仍然达到了最高的性能,证明了持续预测和规划的有效性。
消融实验结果如下:

其他可视化结果:

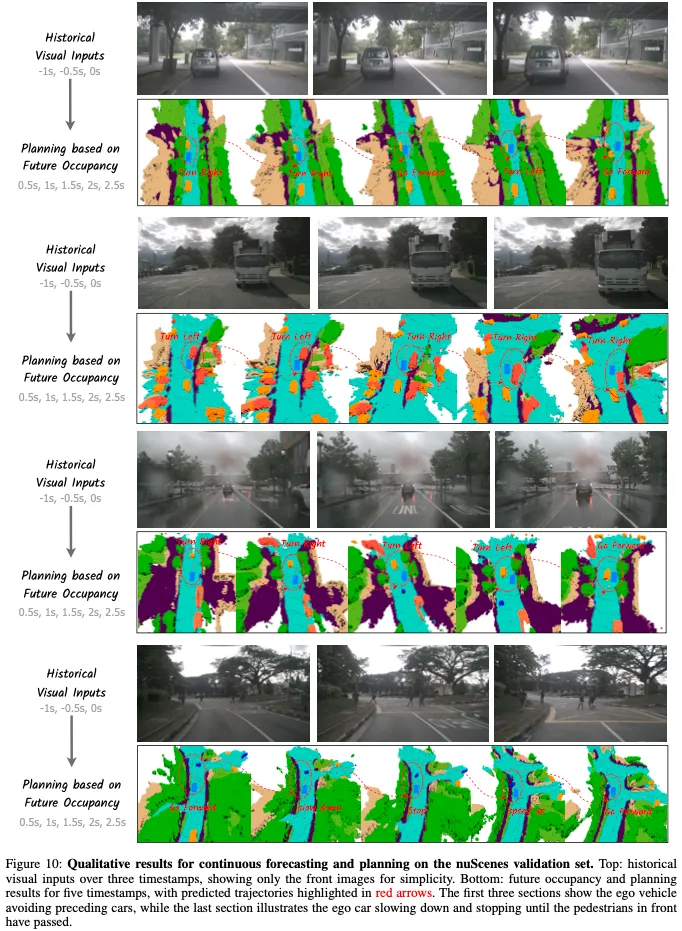
结论
本文提出了Drive OccWorld,这是一个用于自动驾驶的4D Occ预测和规划世界模型。灵活的动作条件可以注入到动作可控发电的世界模型中,促进更广泛的下游应用。基于职业的规划器与运动规划的世界模型相结合,考虑了安全性和环境的3D结构。实验表明,我们的方法在职业和流量预测方面表现出了显著的性能。通过利用世界模型积累世界知识和展望未来状态的能力来提高规划结果,从而增强端到端规划的安全性和稳健性。
#自动驾驶数据闭环2024最前沿论文
近几年,自动驾驶技术的发展日新月异。从ECCV 2020的NeRF问世再到SIGGRAPH 2023的3DGS,三维重建走上了快速发展的道路!再到自动驾驶端到端技术的问世,与之相关的仿真闭环开始频繁出现在大众视野中,新兴的三维重建技术由此在自动驾驶领域也逐渐焕发新机。2023年8月特斯拉发布FSD V12;2024年4月商汤绝影发布面向量产的端到端自动驾驶解决方法UniAD;2024年7月理想夏季发布会宣称端到端正式上车,快系统4D One Model、慢系统VLM,并首次提出**『重建+生成』的世界模型测试方案**。
可以说,端到端+仿真闭环是当下自动驾驶发展的主流路线。但是仿真闭环提了很多年,到底什么是仿真闭环?仿真闭环的核心又是什么?三维重建又在闭环中起到什么样的作用?业内也一直在讨论,百花齐放。无论如何,闭环的目的是明确的,降低实车测试的成本和风险、有效提高模型的开发效率进而优化系统性能、测试各种corner case并优化整个端到端算法。
今天就和大家盘一盘自动驾驶中新兴的三维重建技术相关算法。
MARS: An Instance-aware, Modular and Realistic Simulator for Autonomous Driving(CICAI 2023)
论文链接:https://arxiv.org/abs/2307.15058v1
代码链接:https://github.com/OPEN-AIR-SUN/mars
清华AIR提出的首个开源自动驾驶NeRF仿真工具!如今自动驾驶汽车在普通情况下可以平稳行驶,人们普遍认为,逼真的传感器仿真将在通过仿真解决剩余的corner case方面发挥关键作用。为此,我们提出了一种基于神经辐射场(NeRFs)的自动驾驶仿真器。与现有的工作相比,我们有三个显著的特点:
- Instance-aware:前景目标和背景,单独建模,因此可以保证可控性
- Modular:模块化设计,便于集成各种SOTA的算法进来
- Realistic:由于模块化的设计,不同模块可以灵活选择比较好的算法实现,因此效果SOTA。
UniSim: A Neural Closed-Loop Sensor Simulator(CVPR 2023)
Waabi和多伦多大学在CVPR 2023上的工作:严格测试自动驾驶系统对于实现安全的自动驾驶汽车(SDV)至关重要。它要求人们生成超出世界上安全收集范围的安全关键场景,因为许多场景很少发生在公共道路上。为了准确评估性能,我们需要在闭环中测试这些场景中的SDV,其中SDV和其他参与者在每个时间步相互作用。以前记录的驾驶日志为构建这些新场景提供了丰富的资源,但对于闭环评估,我们需要根据新的场景配置和SDV的决定修改传感器数据,因为可能会添加或删除参与者,现有参与者和SDV之间的轨迹将与原始轨迹不同。本文介绍了UniSim,这是一种神经传感器模拟器,它将配备传感器的车辆捕获的单个记录日志转换为现实的闭环多传感器模拟。UniSim构建神经特征网格来重建场景中的静态背景和动态参与者,并将它们组合在一起,以在新视角仿真LiDAR和相机数据,添加或删除参与者以及新的位置。为了更好地处理外推视图,我们为动态目标引入了可学习的先验,并利用卷积网络来完成看不见的区域。我们的实验表明,UniSim可以在下游任务中模拟具有较小域间隙的真实传感器数据。通过UniSim,我们演示了在安全关键场景下对自主系统的闭环评估,就像在现实世界中一样。UniSim的主要贡献如下:
- 高度逼真(high realism): 可以准确地模拟真实世界(图片和LiDAR), 减小鸿沟(domain gap )
- 闭环测试(closed-loop simulation): 可以生成罕见的危险场景测试无人车, 并允许无人车和环境自由交互
- 可扩展 (scalable): 可以很容易的扩展到更多的场景, 只需要采集一次数据, 就能重建并仿真测
- 知乎解读:https://zhuanlan.zhihu.com/p/636695025
- 一作直播:https://www.bilibili.com/video/BV1nj41197TZ
EmerNeRF: Emergent Spatial-Temporal Scene Decomposition via Self-Supervision
加利福尼亚大学的工作:本文提出了EmerNeRF,这是一种简单而强大的学习动态驾驶场景时空表示的方法。EmerNeRF以神经场为基础,通过自举同时捕获场景几何、外观、运动和语义。EmerNeRF依赖于两个核心组件:首先,它将场景划分为静态和动态场。这种分解纯粹源于自监督,使我们的模型能够从一般的、野外的数据源中学习。其次,EmerNeRF将动态场中的感应流场参数化,并使用该流场进一步聚合多帧特征,从而提高了动态目标的渲染精度。耦合这三个场(静态、动态和流)使EmerNeRF能够自给自足地表示高度动态的场景,而无需依赖GT标注或预先训练的模型进行动态目标分割或光流估计。我们的方法在传感器仿真中实现了最先进的性能,在重建静态(+2.93 PSNR)和动态(+3.70 PSNR)场景时明显优于以前的方法。此外,为了支持EmerNeRF的语义泛化,我们将2D视觉基础模型特征提升到4D时空中,并解决了现代变形金刚中的普遍位置偏差问题,显著提高了3D感知性能(例如,职业预测精度平均相对提高了37.50%)。最后,我们构建了一个多样化且具有挑战性的120序列数据集,用于在极端和高度动态的环境下对神经场进行基准测试。总结来说,本文的主要贡献如下:
- EmerNeRF是一种新颖的4D神经场景表示框架,在具有挑战性的自动驾驶场景中表现出色。EmerNeRF通过自监督执行静态动态分解和场景流估计;
- 一种简化的方法,可以解决ViT中位置嵌入图案的不良影响,该方法可立即应用于其他任务;
- 我们引入NOTR数据集来评估各种条件下的神经场,并促进该领域的未来发展;
- EmerNeRF在场景重建、新视角合成和场景流估计方面实现了最先进的性能。
NeuRAD: Neural Rendering for Autonomous Driving
Zenseact的工作:神经辐射场(NeRF)在自动驾驶(AD)领域越来越受欢迎。最近的方法表明,NeRF具有闭环仿真的潜力,能够测试AD系统,并作为一种先进的训练数据增强技术。然而,现有的方法通常需要较长的训练时间、密集的语义监督或缺乏可推广性。这反过来又阻止了NeRFs大规模应用于AD。本文提出了NeuRAD,这是一种针对动态AD数据量身定制的鲁棒新型视图合成方法。我们的方法具有简单的网络设计,对相机和激光雷达进行了广泛的传感器建模,包括滚动快门、光束发散和光线下降,适用于开箱即用的多个数据集。我们在五个流行的AD数据集上验证了它的性能,全面实现了最先进的性能。
DrivingGaussian: Composite Gaussian Splatting for Surrounding Dynamic Autonomous Driving Scenes
北大&谷歌的工作:本文提出了DrivingGaussian模型,这是一个用于环视动态自动驾驶场景的高效和有效的框架。对于具有运动目标的复杂场景,DrivingGaussian首先使用增量静态3D高斯对整个场景的静态背景进行顺序和渐进的建模。然后利用复合动态高斯图来处理多个运动目标,分别重建每个目标并恢复它们在场景中的准确位置和遮挡关系。我们进一步使用激光雷达先验进行 Gaussian Splatting,以重建具有更多细节的场景并保持全景一致性。DrivingGaussian在动态驱动场景重建方面优于现有方法,能够实现高保真度和多相机一致性的逼真环绕视图合成。总结来说,本文的主要贡献如下:
- 据我们所知,DrivingGaussian是基于复合Gaussian Splatting的大规模动态驾驶场景的第一个表示和建模框架;
- 引入了两个新模块,包括增量静态3D高斯图和复合动态高斯图。前者逐步重建静态背景,而后者用高斯图对多个动态目标进行建模。在激光雷达先验的辅助下,所提出的方法有助于在大规模驾驶场景中恢复完整的几何形状;
- 综合实验表明,Driving Gaussian在挑战自动驾驶基准测试方面优于以前的方法,并能够为各种下游任务进行角情况仿真;
Street Gaussians: Modeling Dynamic Urban Scenes with Gaussian Splatting(ECCV 2024)
浙大&理想在ECCV 2024上的工作:本文旨在解决自动驾驶场景中动态城市街道的建模问题。最近的方法通过将跟踪的车辆姿态结合到车辆动画中来扩展NeRF,实现了动态城市街道场景的照片级逼真视图合成。然而,它们的训练速度和渲染速度都很慢。为此本文引入了Street Gaussians,这是一种新的显式场景表示,可以解决这些限制。具体来说,动态城市场景被表示为一组配备语义逻辑和3D高斯的点云,每个点云都与前景车辆或背景相关联。为了仿真前景目标车辆的动力学,每个目标点云都使用可优化的跟踪姿态进行优化,并使用4D球谐模型进行动态外观优化。显式表示允许轻松组合目标车辆和背景,这反过来又允许在半小时的训练内以135 FPS(1066×1600分辨率)进行场景编辑操作和渲染。该方法在多个具有挑战性的基准上进行了评估,包括KITTI和Waymo Open数据集。实验表明在所有数据集上,所提出的方法始终优于最先进的方法。
GaussianPro: 3D Gaussian Splatting with Progressive Propagation
中科大&港大的工作:3DGS的出现最近在神经渲染领域带来了一场革命,促进了实时速度的高质量渲染。然而,3DGS在很大程度上依赖于运动结构(SfM)技术产生的初始化点云。当处理不可避免地包含无纹理曲面的大规模场景时,SfM技术总是无法在这些曲面上产生足够的点,也无法为3DGS提供良好的初始化。因此,3DGS存在优化困难和渲染质量低的问题。在这篇论文中,受经典多视图立体(MVS)技术的启发,我们提出了GaussianPro,这是一种应用渐进传播策略来指导3D Gaussian致密化的新方法。与3DGS中使用的简单分割和克隆策略相比,我们的方法利用场景现有重建几何的先验和补丁匹配技术来生成具有精确位置和方向的新高斯分布。在大规模和小规模场景上的实验验证了我们方法的有效性,我们的方法在Waymo数据集上显著超过了3DGS,在PSNR方面提高了1.15dB。
LidaRF: Delving into Lidar for Neural Radiance Field on Street Scenes
加州大学欧文分校的工作:真实仿真在自动驾驶等应用中起着至关重要的作用,神经辐射场(NeRF)的进步可以通过自动创建数字3D资产来实现更好的可扩展性。然而,由于共线相机的大运动和高速下的稀疏样本,街道场景的重建质量会受到影响。另一方面,实际使用通常要求从偏离输入的相机视图进行渲染,以准确模拟车道变换等行为。在这篇论文中,我们提出了几个见解,可以更好地利用激光雷达数据来提高街道场景的NeRF质量。首先,我们的框架从激光雷达中学习几何场景表示,将其与隐式基于网格的表示融合用于辐射解码,然后提供显式点云提供的更强几何信息。其次提出了一种鲁棒的遮挡感知深度监督方案,该方案允许通过累积来利用密集的激光雷达点。第三本文从激光雷达点生成增强训练视图,以进一步改进。我们的见解转化为在真实驾驶场景下大大改进的新视图合成。
Gaussian: Self-Supervised Street Gaussians for Autonomous Driving
UC Berkeley&北大&清华的工作:街道场景的真实感3D重建是开发自动驾驶仿真的关键技术。尽管神经辐射场(NeRF)在驾驶场景中的效率很高,但3DGS因其更快的速度和更明确的表示而成为一个有前景的方向。然而,大多数现有的街道3DGS方法需要跟踪的3D车辆边界框来分解静态和动态元素以进行有效的重建,这限制了它们在自由场景中的应用。为了在没有标注的情况下实现高效的3D场景重建,我们提出了一种自监督街道高斯(S3Gaussian)方法,用于从4D一致性中分解动态和静态元素。我们用3D高斯分布来表示每个场景,以保持其明确性,并进一步用时空场网络来压缩4D动力学模型。我们在具有挑战性的Waymo Open数据集上进行了广泛的实验,以评估我们方法的有效性。我们的S3Gaussian展示了分解静态和动态场景的能力,并在不使用3D标注的情况下实现了最佳性能。
Dynamic 3D Gaussian Fields for Urban Areas
ETH和Meta的工作:本文提出了一种高效的神经3D场景表示方法,用于大规模动态城市地区的新视图合成(NVS)。由于其有限的视觉质量和非交互式渲染速度,现有工作品不太适合混合现实或闭环仿真等应用。最近,基于光栅化的方法以令人印象深刻的速度实现了高质量的NVS。然而,这些方法仅限于小规模、均匀的数据,即它们无法处理由于天气、季节和光照引起的严重外观和几何变化,也无法扩展到具有数千张图像的更大、动态的区域。我们提出了4DGF,这是一种神经场景表示,可扩展到大规模动态城市区域,处理异构输入数据,并大大提高了渲染速度。我们使用3D高斯作为高效的几何支架,同时依赖神经场作为紧凑灵活的外观模型。我们通过全局尺度的场景图集成场景动力学,同时通过变形在局部层面建模关节运动。这种分解方法实现了适用于现实世界应用的灵活场景合成。在实验中,我们绕过了最先进的技术,PSNR超过3dB,渲染速度超过200倍。
StreetSurf: Extending Multi-view Implicit Surface Reconstruction to Street Views
上海AI Lab和商汤的工作:本文提出了一种新的多视图隐式表面重建技术,称为StreetSurf,该技术很容易应用于广泛使用的自动驾驶数据集中的街景图像,如Waymo感知序列,而不一定需要LiDAR数据。随着神经渲染研究的迅速发展,将其整合到街景中开始引起人们的兴趣。现有的街景方法要么主要关注新视图合成,很少探索场景几何,要么在研究重建时严重依赖密集的LiDAR数据。他们都没有研究多视图隐式表面重建,特别是在没有激光雷达数据的情况下。我们的方法扩展了现有的以目标为中心的神经表面重建技术,以解决由非以目标为核心、长而窄的相机轨迹捕获的无约束街景所带来的独特挑战。我们将无约束空间划分为近距离、远景和天空三个部分,具有对齐的长方体边界,并采用长方体/超长方体哈希网格以及路面初始化方案,以实现更精细和更复杂的表示。为了进一步解决无纹理区域和视角不足引起的几何误差,我们采用了使用通用单目模型估计的几何先验。再加上我们实施了高效细粒度的多级光线行进策略,我们使用单个RTX3090 GPU对每个街道视图序列进行训练,仅需一到两个小时的时间,即可在几何和外观方面实现最先进的重建质量。此外,我们证明了重建的隐式曲面在各种下游任务中具有丰富的潜力,包括光线追踪和激光雷达模拟。
AutoSplat: Constrained Gaussian Splatting for Autonomous Driving Scene Reconstruction
多伦多大学和华为诺亚的工作:逼真的场景重建和视图合成对于通过仿真安全关键场景来推进自动驾驶系统至关重要。3DGS在实时渲染和静态场景重建方面表现出色,但由于复杂的背景、动态对象和稀疏视图,在建模驾驶场景方面遇到了困难。我们提出了AutoPlat,这是一个采用Gaussian Splatting实现自动驾驶场景高度逼真重建的框架。通过对表示道路和天空区域的高斯分布图施加几何约束,我们的方法能够对包括车道变换在内的具有挑战性的场景进行多视图一致的模拟。利用3D模板,我们引入了反射高斯一致性约束来监督前景对象的可见面和不可见面。此外,为了模拟前景对象的动态外观,我们估计了每个前景高斯的残差球面谐波。在Pandaset和KITTI上进行的大量实验表明,AutoPlat在各种驾驶场景中的场景重建和新颖视图合成方面优于最先进的方法。
DHGS: Decoupled Hybrid Gaussian Splatting for Driving Scene
长安汽车的工作:现有的GS方法在实现驾驶场景中令人满意的新视图合成方面往往不足,主要是由于缺乏巧妙的设计和所涉及元素的几何约束。本文介绍了一种新的神经渲染方法,称为解耦混合GS(DHGS),旨在提高静态驾驶场景新型视图合成的渲染质量。这项工作的新颖之处在于,针对道路和非道路层的解耦和混合像素级混合器,没有针对整个场景的传统统一差分渲染逻辑,同时通过提出的深度有序混合渲染策略仍然保持一致和连续的叠加。此外,对由符号距离场(SDF)组成的隐式道路表示进行训练,以监控具有微妙几何属性的路面。伴随着辅助传输损耗和一致性损耗的使用,最终保留了具有不可察觉边界和高保真度的新图像。在Waymo数据集上进行的大量实验证明,DHGS的性能优于最先进的方法。
#TPVFormer
2.Abstract
bev效率快,但是缺乏高度信息。occ信息丰富,但是太大了,消耗高。
动机:因此提出了一种三视角视图(TPV)表示,它伴随着BEV和两个额外的垂直平面。通过将 3D 空间中的投影特征相加来对 3D 空间中的每个点进行建模。为了将图像特征提升到 3D TPV 空间,作者进一步提出了一种基于变压器的 TPV 编码器 (TPVFormer),以有效地获取 TPV 特征。
3.Method3.1Point Querying formulation
第三个是作者提出的三视图方法(俯视图、侧视图和前视图)
给定现实世界中的 (x, y, z) 处的查询点,TPV 表示试图在顶部、侧面和正面视图上聚合其投影,以便对点进行全面描述。首先将点投影到 TPV 平面上以获得坐标 (h, w)、(d, h)、(w, d),在这些位置对 TPV 平面进行采样以检索相应的特征 th,w, td,h, tw,d,并聚合三个特征。
其中采样函数S和聚合函数A分别用双线性插值和求和实现,每个投影函数P在两个相关坐标上执行简单的缩放,因为TPV平面与现实世界的轴对齐。
TPV的计算复杂度:O(HW + DH + W D) 正常OCC的计算复杂度:O(H×W×D)
3.2TPVFormer
采用图像骨干网为多相机图像提取多尺度特征。然后执行交叉注意,自适应地将 2D 特征提升到 TPV 空间,并使用跨视图混合注意力来实现 TPV 平面之间的交互。为了预测三维空间中一个点的语义占用率,我们在三个TPV平面上对投影特征之和应用一个轻量级的预测头
3.2.1 TPV Queries(Query initial)
文中作者说初始化Query为可学习参数的时候参考了原文公式3的size,
每个 TPV 查询映射到相应视图中大小为 s × s m2 的 2D 网格单元区域,并进一步映射到从垂直方向视图延伸的 3D 柱区域。
然后在HCAB中进行AUG、在HAB中进行上下文线索细化。
Attention 这里的话前面三块是Cross-Atn,负责和图片两者的交互,后面的两块是Hybird-Atn,负责三个视角间的交互。
3.2.2 Image Cross-Attention
首先要拿采样点
这个图论文没找到,就从作者讲这篇论文的视频那扒拉下来哈哈
(1)首先将点通过C2W映射回世界坐标系当中
(2)然后就像sur或者bevformer一样进行点的采样,看图的话是跟sur一样去采四个点
(3)采集完后将点通过W2C映射回图像上并筛选出外面的点,只保留相机镜头的店。
(4)然后每个采样点进行采样,并进行deformable-atn操作
3.2.3Cross-View Hybrid-Attention
这里以俯视图为例子,将其参考点分组到三个不相交的子集中,子集分别包含属于顶部、侧面和前平面的参考点
就例如 找了zyz中俯视图的(3,4)这个点,前视和侧视的(3,z)这一条和和(4,z)都作为采样点。
然后拿这些采样点进行deformable-atn操作。
3.3Applications of TPV
现在获取的三组query都是正交的形式,需要将feature给映射到voxel中
将点投影到 TPV 平面上以检索相应的特征 th,w, td,h, tw,d,并将它们相加以获得逐点特征,沿着相应的正交方向主动广播每个 TPV 平面,以产生三个相同大小的 H × W × D × C 的特征张量,并通过求和聚合它们以获得全尺寸体素特征。
将其映射到occ-voxel中,然后用分割头给他输出语义预测。
4.Experiments
3D 语义占用预测和 nuScenes LiDAR 分割的可视化结果。我们的方法可以生成比 LiDAR 分割地面实况更全面的预测结果。
测试时的任意分辨率。我们可以通过测试时插值来调整预测分辨率。随着分辨率的增加,捕获了有关 3D 对象的更多详细信息。
SemanticKITTI 测试集上的语义场景完成结果。为了公平比较,我们使用MonoScene中报告的前四种方法的RGB推断版本的性能。我们在 IoU 和 mIoU 中都显着优于其他方法,包括基于 3D 卷积的 MonoScene。
尺寸越大,精度越高
两个块的数量消融,感觉差的不大
#自动驾驶目前主流的那些技术方向
一、端到端自动驾驶1.前沿工作
- 【Senna: 一种将LVLM(Senna-VLM)与端到端模型(Senna-E2E)相结合的自动驾驶系统】对两个数据集的广泛实验表明,Senna在规划性能上达到了最先进的水平;
- 【Ramble:具有强化学习的高交互交通场景中的端到端驾驶】Ramble在CARLA Leaderboard 2.0上实现了路线完成率和驾驶评分的最新性能;
- 【CARLA中的端到端自动驾驶全面综述】讨论了基于CARLA的最先进实现如何通过各种模型输入、输出、架构和训练范式解决端到端自动驾驶中遇到的各种问题;
- 【端到端预测和规划最新SOTA!一种用于端到端自动驾驶的新交互机制:PPAD】。
2.报告和行业大佬直播分享


大模型1.前沿工作
- 【全面回顾当前关于L(V)LM在自动驾驶应用方面的研究】重点关注四个关键领域:模块化整合、端到端整合、数据生成和评估平台。
- 【自动驾驶中的大语言模型(LLM4AD):概念、基准、仿真和实车实验】LLMs在提升自动驾驶技术各个方面的显著潜力,包括感知、场景理解、语言交互和决策;
- 【基于 LLM 驱动的鲁棒 RL 自动驾驶数据合成与策略调整】RAPID能够有效将LLM的知识整合到缩减版的RL策略中,以高效、适应性强且鲁棒的方式运行;
- 【大型语言模型会成为自动驾驶的灵丹妙药吗?】本文对LLM在自动驾驶系统中的潜在应用进行了详尽的分析。
2.报告和行业大佬直播分享

BEV感知1.前沿工作
- 【nuScenes和nuScenes最新SOTA!】Focus on BEV: 基于自标定周期视图变换的单目BEV图像分割;
- 【MambaBEV:一种基于mamba2的BEV目标检测】还采用了端到端的自动驾驶范式来测试该模型的性能。模型在nuScenes数据集上表现出了相当好的结果:基础版本达到了51.7%的NDS;
- 【QuadBEV: 高效的多任务感知框架】它利用四个关键任务------3D目标检测、车道检测、地图分割和占用预测------之间共享的空间和上下文信息。
- 【nuScenes-360和DeepAccident-360最新SOTA!】OneBEV:利用一幅全景图像进行鸟瞰语义建图!在nuScenes-360和DeepAccident-360上分别达到了51.1%和36.1%的mIoU,取得了最先进的性能。
2.报告和行业大佬直播分享

Occupancy感知1.前沿工作
- 【OccLoff框架:旨在"学习优化特征融合"以进行3D占用预测】具体提出了一种稀疏融合编码器和熵掩模,该编码器可以直接融合3D和2D特征,从而提高模型的准确性,同时减少计算开销;
- 【nuScenes最新占用预测SOTA! TEOcc: 一种基于Radar-相机多模态的时间增强占用预测网络】所提出的时间增强分支是一个即插即用的模块,能够轻松集成到现有的占用预测方法中以提升占用预测的性能;
- 【SyntheOcc: 通过扩散模型生成的系统,它通过在驾驶场景中以占据标签为条件来合成真实感和几何控制的图像】
- 【RELIOCC:一种旨在增强基于相机的占用网络可靠性的方法】首次从可靠性角度对现有的语义占用预测模型进行全面评估。显著提高了模型的可靠性,同时保持几何和语义预测的准确性。
2.报告和行业大佬直播分享


世界模型1.前沿工作
- 【探索自动驾驶中视频生成与世界模型之间的相互作用:一项调查】探讨了这两种技术之间的关系,重点分析它们在结构上的相似性,尤其是在基于扩散的模型中,如何促进更准确和一致的驾驶场景模拟;
- 【从有效多模态模型到世界模型:探讨了MLMs的最新发展和挑战,强调它们在实现人工通用智能和作为通向世界模型的路径中的潜力】;
- 【nuPlan闭环规划新SOTA!AdaptiveDriver:一种基于模型预测控制(MPC)的规划器,可以根据BehaviorNet的预测展开不同的世界模型】将测试误差从6.4%减少到4.6%,即使应用于从未见过的城市;
- 【Vista:一个具有高保真度和多功能可控性的可泛化驾驶世界模型!】通过高效的学习策略,结合了一套多功能的控制方法,从高层次的意图(命令、目标点)到低层次的操作(轨迹、角度和速度),在超过70%的比较中优于最先进的通用视频生成器,并且在FID上超过最佳驾驶世界模型55%,在FVD上超过27%。
2.报告和行业大佬直播分享

自动驾驶仿真1.前沿工作
- 【IGDrivSim,一个基于Waymax仿真器的基准】证明人工专家与自动驾驶智能体之间的感知差距会妨碍安全和有效驾驶行为的学习;
- 【WorldSimBench:双重评估框架来评估世界仿真器】包括显式感知评估和隐式操作评估,涵盖了从视觉角度的人工偏好评估和具身任务中的动作级评估,涉及三个代表性的具身场景:开放式具身环境、自动驾驶和机器人操作;
- 【CARLA2Real,这是一个易于使用的公共工具(插件),适用于广泛使用的开源CARLA仿真器】;
- 【2024最新,自动驾驶框架和仿真器综述】本文回顾了开源和商业自动驾驶框架及仿真器,介绍并比较了它们的特点和功能等,还从硬件不足、自动驾驶算法、场景生成、V2X、安全与性能以及联合仿真等角度,提出了AD框架和仿真器在近期未来的有前景的研究方向。
2.报告和行业大佬直播分享



#从视觉表征到多模态大模型
转眼2024,距离上次知乎写作就快过去一年,上一次的计划主题还是"开源大模型"(参见《ChatGPT的朋友们:大语言模型经典论文一次读到吐》),无奈这个方向变化太快,而且也不乏优质总结文章,也就一直没有动笔。正好最近做图文多模态大模型相关的工作,在查阅资料的过程中没遇到比较完整的脉络梳理文章,往往需要综合参考;反观这个方向的综述型论文又过于追求"完美",个人感觉详略把控不尽人意。
因此,借此机会结合自己的学习过程,对多模态和多模态大模型做一个系统的梳理,尝试以一个亲历者的视角谈谈这部分技术的发展思路,希望能给读者一些不一样的收获,如有偏颇,欢迎指正。
为了表述简单,我们不严谨的将"图文多模态"表述为"多模态"(标题有些夸张),如果后面有机会可以讨论更多模态的相关工作。此外,本文假设读者已经对视觉表征和多模态融合有一定入门背景,希望通过一篇文章回顾将过去几年的经典工作。
一、总览
由于是讲"图文多模态",还是要从"图"和"文"的表征方法讲起,然后讲清楚图文表征的融合方法。对于文本模态的表征发展,我们在《闲话NLP:文本表征的半世今生》一文中有过一轮的梳理,因此本文只要讲两件事情:
- 视觉表征:分为两个部分问题,一是如何合理建模视觉输入特征,二是如何通过预训练手段进行充分学习表征,这两点是基于视觉完成具体算法任务的基础;
- 视觉与自然语言的对齐(Visul Language Alignment)或融合:目的是将视觉和自然语言建模到同一表征空间并进行融合,实现自然语言和视觉语义的互通,这点同样离不开预训练这一过程。模态对齐是处理多模态问题的基础,也是现在流行的多模态大模型技术前提。
对于视觉表征,从发展上可以分为卷积神经网络(CNN)和Vision Transformer(VIT)两大脉络,二者分别都有各自的表征、预训练以及多模态对齐的发展过程。而对于VIT线,另有多模态大模型如火如荼的发展,可谓日新月异。
因此,本文的行文思路也就非常简单,如图1所示。第一部分介绍以CNN为基础的视觉表征和预训练手段,以及在此基础上的多模态对齐的方法。由于预训练已经成为AI技术取得效果的标配,多模态对齐部分的内容也是以多模态预训练技术承载;第二部分从VIT技术出发,分别介绍VIT视觉表征的预训练探索工作、多模态对齐的预训练工作以及近两年火热的研究方向多模态大模型。
由于多年间的优秀工作太多,不胜枚举,本文仅挑选笔者从业过程中印象较深,且有标志性特点的工作为代表。优秀的工作不止于本文,不过还是期望通过有限的工作,将近几年的图文多模态相关技术串连起来,方便读者按图索骥进行更深入的学习。下面开始正式的内容。
二、CNN:视觉理解的一代先驱
2.1 卷积视觉表征模型和预训练
对视觉信息的表征,简单来说是将图像信息转化成深度学习输入所需的特征向量或向量序列,如图2。深度学习时代,卷积神经网络(CNN)凭借其局部区域连接、权重共享以及位移不变性等特点,天然的符合了图像信息的建模归纳假设,成为早期最适合视觉表征的模型。具体的,卷积神经网络应用视觉表征的模型很多,我们简单从LeNet-5、AlexNet、VGG和ResNet等模型的演进一窥其在关键要素。
2.1.1 卷积视觉表征:从LeNet到ResNet
LeNet-5早期在数字识别中取得了成功的应用,网络结构是 **CONV-POOL-CONV-POOL-FC-FC** 。卷积层使用 55的卷积核,步长为1;池化层使用 22 的区域,步长为2;后面是全连接层;AlexNet相比LeNet-5做了更多层数的堆叠,网络参数进行了相应的调整,并在ImageNet大赛2012夺得冠军;相应VGG网络使用更小的卷积核,同时相比AlexNet进一步提升了网络层数。
随着研究的深入,神经网络的层数也出现了爆发式地增长,由此也不可避免的带来梯度消失和梯度爆炸的问题,使得模型训练的困难度也随之提升。一种解决方法是将神经网络某些层跳过下一层神经元的连接,隔层相连,弱化每层之间的强联系。这种神经网络被称为Residual Network(ResNet)残差网络,网络结构的原理是将卷积层的堆叠,替换成跨层连接的模块,如图3所示。
有了合理的建模模型,可以使用具体任务的训练数据学习视觉表征,进而完成不同的任务(如分类、分割、目标检测等)。而更加有效的方式通常是先用"海量"的数据让模型学到通用的视觉表征,再进行下游具体任务数据的学习,也就是预训练+微调的范式。
2.1.2 卷积视觉预训练
在CNN视觉表征体系下,早期的视觉预训练有另一个叫法是迁移学习,在BERT的预训练+微调范式流行之前就已经被广泛应用。迁移学习中,传统CNN视觉模型在做具体任务训练之前,先在大量的图像任务数据集上进行预先训练(如ImageNet分类任务数据集等)。然后使用预训练的CNN权重初始化Backbone,并增加一些任务定制网络模块,完成在下游任务上的微调(如Backbone+全连接层做分类任务)。
卷积神经网络视觉表征和预训练的优化升级工作还有很多,介绍相关内容的资料也很多,篇幅原因我们对此不进行详细展开和概述,而是把更多的笔墨放在近几年更热门的研究方向上。
2.2 早期多模态融合与预训练
接着是CNN体系下的多模态融合和预训练,视觉和自然语言的跨模态对齐和融合有两种表现形式:一种是双塔结构,多模态分别表征,通过对比学习机制实现视觉和文本在同一空间中的距离度量;另一种是视觉表征和文本表征通过交互型网络结构融合成多模态表征,进而完成下游任务应用。由于前者可以看作后者的特例,我们用后一种表现形式为例,将二者统一,进而讲述以CNN为基础的早期多模态融合与预训练技术。
如图4,展示了上述的多模态融合框架,包括视觉特征提取模块、文本特征提取模块和模态融合模块。文本模块是常见的Token Embedding方式;视觉表征方面,由于CNN已经验证了有效性,因此大多数的工作在都考虑使用CNN做视觉特征抽取,得到高级语义特征,然后将高级语义表征作为输入,和文本Token Embedding序列一起输入到下游融合模块。不同工作的差异主要集中在视觉特征提取CNN Backbone以及Modality Interaction两个模块。
我们以2019年作为粗略分界点,在此之后BERT的训练范式开始流行,多模态方向上的研究热点则是借鉴BERT的成功,使用Transformer网络(特指Transformer Encoder)作为Modality Interaction模块把视觉和自然语言进行特征融合,并通过大规模预训练来学习得到多模态表征;而在此之前的方案通常是简单的多层全连接网络实现,我们不多赘述。
顺着这个思路,确定了使用Transformer作为模型融合模块这个大方向后,第二个问题是**如何对视觉特征进行有效编码,得到和文本一样的Token Embedding序列作为模型输入?**这一问题的解法在CNN为主的时期有两种主要方式,如图5:
- Region Feature Base:先通过基于CNN的目标检测模型(Fast R-CNN等),识别图像中的关键物体区域集合(ROI,Region Of Interest),并提取区域的表征向量,作为Transformer模型的视觉输入Embedding序列。这么做的动机是,每个ROI区域,都有明确的语义表达(人、建筑、物品等),方便后续和文本特征的对齐。比较有代表性的工作如LXMERT、VL-BERT和UNITER等;
- Grid Feature Base:区域特征方法虽然看上去合理,但是依赖前置的目标检测模型,整体链路较重。因此也有工作探索,不经过区域检测,直接使用CNN网络提取深层的像素特征作为交互模型输入,同样取得了一些成果。比较有代表性的工作如Pixel-Bert等。
下面我们分别介绍这一时期的经典工作,了解其中基本思路和方法。
2.2.1 LXMERT
LXMERT是早期进行多模态特征融合的工作之一,如图6,模型采用经典的两路深层表征输入结构 。在视觉侧关注单图,图像经过目标检测模型得到区域块的特征序列,又经过Transformer做进一步编码区域块之间的关系(Object-Relationship Encoder);文本侧通过BERT结构得到文本的特征序列(Language Encoder),最后两者使用深层Transformer结构做交叉Attention,最后进行多任务的预训练。LXMERT的预训练任务相比BERT较多,包括Masked图像特征的预测、图像Label的预测(猫、狗等)、VQA、图文是否匹配以及纯文本侧的Masked语言模型(MLM)。
预训练模型经过特定任务微调后,LXMERT在两个视觉问答数据集(VQA和GQA)上达到了当时最先进的结果。作者还展示了LXMERT可以很好地泛化到一个具有挑战性的视觉推理任务(NLVR2),并将之前的最佳结果提高了22%(从54%到76%),是一个比较优秀的工作。
2.2.2 VL-BERT
另一个Region Feature Base的经典工作是VL-BERT。如图7,与LXMERT不同的是,VL-BERT属于单路输入模式,视觉特征在经过目标检测模型进行Region特征提取后,直接和文本Embedding一起拼接输入到Transformer网络中进行多模态的交叉Attention。
VL-BERT设计了两个预训练任务:带视觉特征的掩码语言模型学习(Masked Language Modeling with Visual Clues)、带文本特征的视觉Region分类(Masked RoI Classification with Linguistic Clues)。经过预训练和微调流程,模型可以适用于多种视觉和语言任务,并在视觉问答、图像-文本检索、视觉常识推理等任务上都取得了非常不错的性能。VL-BERT印证了,多模态语义特征不需要各自的单独深度编码,直接做交互也可以取得有效结果。
2.2.3 UNITER
如图8,UNITER使用和VL-BERT类似的架构,同样的单路架构,同样是目标检测模型做视觉的语义特征抽取,并进一步使用更多的训练数据、更多的预训练任务,希望得到一个更加通用的图文多模态表征模型。UNITER通过在四个图像和文本数据集(COCO, Visual Genome, Conceptual Captions, and SBU Captions)上进行大规模的预训练,可以支持多种视觉和语言任务的联合多模态表征。同时设计了四种预训练任务:遮蔽语言建模(MLM),遮蔽区域建模(MRM,有三种变体),图像-文本匹配(ITM),和词-区域对齐(WRA)。
相比于之前方案,UNITER提出了通过最优传输(OT,Optimal Transport)的方法来进行WRA,在预训练过程中显式地加强词和图像区域之间的细粒度对齐。相比其他工作仅使用图像-文本匹配(ITM)的全局对齐方式,WRA更加精准。经过大量的消融实验,UNITER还探索了预训练任务的最佳组合方式,并最终在视觉问答,图像-文本检索,指代表达理解,视觉常识推理,视觉蕴含,和NLVR2等任务上都达到了新的最先进的水平。
UNITER称得上是Region Feature Based多模态预训练的集大成者,同时期的大多数工作也多是类似结构上的修补或增强。但也不乏另辟蹊径的工作,其中以Grid Feature Based相关工作最具影响力。
2.2.4 Pixel-BERT
Pixel-BERT是Grid Feature Based多模态融合代表工作之一。如图9,与Region Feature Based方法不同的是,Pixel-BERT不需要使用目标检测模型进行ROI区域的特征抽取,而是直接通过卷积网络提取图片的像素级别特征,直觉和文本特征一起输入到下游的Transformer网络进行特征融合。这种方式减少了目标检测区域框标注的成本,同时缓解了视觉语义label与文本语义的不均衡问题(区域框的物体类别往往上千规模,而文本可以表达的语义远不止于此)。
详细来说,当时主流的Region Feature Based方法提取视觉特是使用如Fast R-CNN的目标检测模型,通常在Visual Genome数据集上训练得到。这种目标检测模型,通常先提取可能存在物体的区域,然后根据区域特征进行物体类别的分类。相应的,这些区域的特征往往局限在固定的类目集合范围内,语义范围较为有限,这是也使用区域语义特征的固有缺陷。

此外,Pixel-BERT使用随机像素采样机制来增强视觉表示的鲁棒性,并使用MLM和ITM作为预训练任务进行预训练。最后通过对下游任务进行广泛的实验,在包括视觉问答(VQA)、图像文本检索和视觉推理等下游任务中取得了SOTA效果。
三、VIT:拥抱Transformer
Pixel-BERT之类的网络,减少了对与目标检测模型的依赖,仅使用深层卷积神经网络提取像素级别的特征作为下游多模态融合模块,极大简化了图文多模态表征模型的网络结构。那么,我们能不能进一步简化视觉表征模块,直接把图像特征简单加工后就直接输入到Transformer网络和文本特征一起做模态的融合?要做到这一点,我们需要先回答另一个问题,Transformer网络能不能替换CNN作为视觉表征的Backnone?虽然现在来看,答案是肯定的,但在开始阶段,这个过程并不是那么顺利。
我们知道,CNN应用于视觉表征有着很强的归纳偏置或者说先验,在 CNN 中,局部性、二维邻域结构和平移不变性是在整个模型的每一层中都有体现,和视觉图像的特点极其类似:
- 局部感知性:卷积层通过卷积操作和参数共享,能够高效地提取输入图像的局部特征。这种局部感知性使得CNN能够捕捉图像中的局部结构,例如边缘、纹理等,从而更好地表征图像。
- 层级结构:CNN的层级结构包括卷积层、激活函数、池化层和全连接层。这种层级结构使得CNN能够逐层提取和组合特征,从低级到高级,形成更复杂的视觉表征。
- 参数共享:卷积层中的参数共享使得CNN的训练更加高效。相同的卷积核在不同位置对图像进行卷积操作,共享参数减少了模型的复杂度,同时也增强了模型的泛化能力。
- 空间不变性:卷积操作具有平移不变性,即无论图像中的物体在图像中的位置如何变化,卷积核都能检测到相应的特征,这对于图像分类、目标检测和图像分割等计算机视觉任务非常重要。
而在 Transformer 中的Self-Attention层则是全局的,对于视觉输入的局部关系建模、图像的2D位置关系的建模,以及图像元素的平移不变性的把握上,都需要从头学习。然而,即便是困难重重,因为有BERT的巨大成功,仍然有许多的研究者前赴后继投入到这个方向,并最终取得成功,其中Vision Transformer (ViT) 是最为经典的案例之一。
3.1 VIT范式视觉表征和预训练
3.1.1 VIT:Transformer视觉表征
如图10,VIT将输入图片平铺成2D的Patch序列(16x16),并通过线性投影层将Patch转化成固定长度的特征向量序列,对应自然语言处理中的词向量输入。同时,每个Patch可以有自己的位置序号,同样通过一个Embedding层对应到位置向量。最终Patch向量序列和视觉位置向量相加作为Transfomer Encoder的模型输入,这点与BERT模型类似。
同样,VIT通过一个可训练的CLS token得到整个图片的表征,并接入全链接层服务于下游的分类任务。当经过大量的数据上预训练,迁移到多个中等或小规模的图像识别基准(ImageNet, CIFAR-100, VTAB 等)时,ViT取得了比CNN系的模型更好的结果,同时在训练时需要的计算资源大大减少。按说,ViT的思路并不复杂,甚至一般人也不难想到,但是为什么真正有效的工作确没有很快出现?不卖关子,VIT成功的秘诀在于大量的数据做预训练,如果没有这个过程,在开源任务上直接训练,VIT网络仍会逊色于具有更强归纳偏置的CNN网络。
因此,在此之后的一大研究方向就是如何更加有效的对VIT结构的网络进行预训练。下面我们通过MAE和BEIT两个优秀的工作,来讨论这个方向上的两类主流方案。
3.1.2 MAE:激进的Mask自监督预训练
与自然语言理解类似,VIT模型能取得成功得益于预训练+微调的训练范式。前文提到,传统CNN视觉模型的预训练,仅仅是在大量的图像任务数据集上进行预先训练(如ImageNet分类任务等),然后使用训练后的权重进行初始化Backbone,在下游任务上继续微调完成相应任务。
早期的VIT的预训练和CNN预训练一样,都是通过大规模的有监督分类任务数据集进行训练,和BERT的自监督预训练仍有区别。而自监督预训练有着数据获取成本低、不需要标注、任务难度大模型学习充分等诸多好处,因此很多研究工作探索自监督视觉预训练,比较有代表性的实践工作如Masked AutoEncoder(MAE)。
如图11,所示,MAE以VIT为基础模型,先对完整图片进行Patch掩码,接着使用一个Transformer Encoder对未Mask的Patch进行编码,然后通过相对小的Transformer Decoder模型还原被Masked Patch,从而实现模型的自监督预训练。
MAE取得成功的另一个核心原因是通过75%的高掩码率来对图像添加噪音,这样图像便很难通过周围的像素来对被掩码的像素进行重建,从而使编码器去学习图像中的语义信息。预训练之后,解码器被丢弃,编码器可以应用于未掩码的图像来进行识别任务。
相对于自然语言的自监督训练,MAE使用了更大的掩码比例。后人进一步分析,这么做动机是考虑自然语言和视觉特征的信息密度不同,简单来说:文本数据是经过人类高度抽象之后的一种信号,信息是密集的,可以仅仅预测文本中的少量被掩码掉的单词就能很好的捕捉文本的语义特征。而图像数据是一个信息密度非常小的矩阵,包含着大量的冗余信息,像素和它周围的像素存在较大的相似性,恢复被掩码的像素并不需要太多的语义信息。
3.1.3 BEIT:视觉"分词"表征预训练
另一类Transformer视觉模型预训练的代表范式是BEIT(BERT Pre-Training of Image Transformers)模型。为了与BERT的预训练框架对齐,BEIT通过辅助网络模块先对视觉Patch进行Tokenizer,得到整张图各部分的视觉Token ID。然后将视觉Patch视为自然语言中的单词进行掩码预测,完成预训练流程。
具体的如图12,在预训练之前,BEIT先通过一个离散自回归编码器( discrete Variational AutoEncoder,dVAE)学习了一个"图像分词"器,最终可以将图像编码成离散的视觉Token集合。而在预训练阶段,输入的图片存在两个视角,一是图像Patch,另一个是视觉Token。BEIT随机对Patch进行掩码,并将掩码部分替换为特殊的Mask Embedding(M,图中的灰色部分),随后将掩码后的Patch序列输入到VIT结构的模型中。预训练的目标则是基于被掩码的图像输入向量序列,预测源图像对应的视觉Token ID。
BEIT需要单独的dVAE网络辅助,相对MAE更为复杂。在效果上,MAE验证了使用normalized pixels进行目标像素重建,也可以实现类似效果,因此视觉tokenization过程并非必须。但即便如此,BEIT为视觉预训练提供了一个不错的范式,同样是一次十分有价值的探索。
3.2 VIT为基础的多模态对齐与预训练
以VIT为基础的视觉预训练可以通过Transformers对视觉进行有效表征,这种方法也逐渐成为目前视觉信息编码的主流手段。以此为延伸,基于此的多模态预训练工作也层出不穷,也为如今的多模态大模型的顺理成章打下了坚实基础。
如图13,梳理了以VIT为延伸的多模态对齐和预训练工作,各工作之间都或多或少的有所关联,可谓是一脉相承。下面我们分别介绍这个技术方向的经典工作,读完本小结下面的内容再来看图中的模型关系,可能会更有感觉。
3.2.2 CLIP
CLIP模型是OpenAI 2021发布的多模态对齐方法。与OpenAI的许多工作类似,CLIP强调强大的通用性和Zero-Shot能力,也因此至今仍有很强的生命力,相关技术被广泛应用。
CLIP的核心思路是通过对比学习的方法进行视觉和自然语言表征的对齐。如图xx(1),CLIP首先分别对文本和图像进行特征抽取,文本的Encoder为预训练BERT,视觉侧的Encoder可以使用传统的CNN模型,也可是VIT系列模型。得到图文表征向量后,在对特征进行标准化(Normalize)后计算Batch内图文Pair对之间的余弦距离,通过Triple Loss或InfoNCELoss等目标函数拉近正样本对之间的距离,同时使负样本对的距离拉远。
经过大量的图文Pair对进行预训练后,我们可以得到在同一表征空间下的文本Encoder和图像Encoder。下游应用通常也是两种方式,一是在下游任务上对模型进行微调,适应定制的图文匹配任务,或者仅使用文本或图像Encoder做单模态任务;另一种使用方式是直接使用预训练的图文表征Zero-Shot方式完成下游任务。
CLIP进行Zero-Shot的一种使用方式如图14(2)和(3),对于一个图像分类任务,可以首先将所有的候选类别分别填充"A photo of a {object}"的模板,其中object为候选类别,对于一张待预测类别的图像,通过图像Encoder的到视觉表征后,与所有类别的模板文本Encoder表征进行相似度计算,最后选择相似度最高的类别即可作为预测结果。
CLIP凭借其简洁的架构和出众的效果,被后来很多工作引用,并使用CLIP预训练的Backbone作为视觉表征模块的初始化参数。
3.2.3 VILT
CLIP方法简单有效,双塔的网络结构对于下游应用也十分友好。但是如同表示型语义匹配类似,双塔结构同样也有交互不足的问题,内积或余弦距离的模态融合方式匹配能力上限较低,对于一些需要细粒度跨模态匹配的任务(VQA等)有时力不从心。因此,交互式的多模态对齐和融合仍然极具价值,典型的如VILT模型。
VILT是VIT在图文多模态方向上的工作延续。我们了解了基于Transformer的自然语言模型和视觉模型的预训练范式后,进阶到多模态融合十分容易理解。如图15所示,与BERT文本对的输入方式类似,VILT将文本和视觉Patch的Embedding直接拼接作为Transformer编码器的输入,两种模态有各自可学习的位置编码和模态类型编码。
通过深层的Transformer编码,文本与视觉的模态得到了充分的融合。ViLT使用常用的ITM(Image Text Matching)和MLM(Masked Language Modeling)作为预训练目标。
- ITM(Image Text Matching):图文是否匹配的二分类目标,正样本为常用数据集中提供的语义一致的图文Pair对,负样本对以0.5的概率随机地用替换正图文对中的图片为其他图片;此外借鉴前人工作,匹配目标还增加了图文子区域的匹配目标Word Patch Alignment (WPA),该目标并不常用,我们也不作过多展开。
- MLM(Masked Language Modeling):以0.15的概率对文本的Token进行掩码,并通过图文的整体上下文信息对预测被掩码的Token。
如图16,可以对比以CNN为基础的多模态预训练和以VIT为基础的预训练,在模型架构上的区别。
而在ViLT之后,多模态预训练的一个较为明显的趋势,是进一步提升模态对齐与融合的效果以及模型结构的通用性,使用统一模型视角进行跨模态对齐和融合。在这个过程中,ALBEF(Align before Fuse)、BLIP(Bootstrapping Language-Image Pre-training)与BEIT-3系列等工作极具参考价值,下面我们简单对比其设计思路。
3.2.5 ALBEF与BLIP
ALBEF通过多任务联合训练将类似CLIP的对比学习和类ViLT的交互融合范式统一到一个训练框架中。如图17所示,模型结构包括一个图像Encoder(12层)、一个文本Encoder(6层)和一个多模态融合的Encoder(6层),各Encoder均沿用Transformer网络。ALBEF的训练任务包括图文对比ITC(Image-Text Contrastive Learning)、ITM(Image-Text Matching)、MLM(Masked Language Modeling)。
- ITC:在图文模态深层融合之前,在对图文的表征序列Pooling后,通过对比学习Loss对图文单模态表征进行对齐。这部分和CLIP模型的训练设置类似,不同的是文本的Encoder相对视觉Encoder层数更浅。
- ITM:图文Encoder输出的表征序列深层交互后,判断输入图文对是否匹配,与VILT一样是二分类任务。不同的是负样本对的构造,使用对比学习模块进行了Batch内的难负样本挖掘。主要思路是,对比学习模块中一个Batch中,模型认为最为相似的负样本对可以作为难负样本。
- MLM:与VILT类似,随机对输入文本token进行掩码,通过图文上下文的输入信息预测被掩码的Token。
最后,由于ALBEF的预训练数据多数为互联网中挖掘的图文对,天然存在较大的噪声数据。为了缓解这个问题,ALBEF在训练过程中通过一个动量自蒸馏的模块(一个移动平均版本的ALBEF模型),生成训练数据集的伪标签,用来辅助模型的训练。
ALBEF通过多任务训练机制将模态对比匹配和深度模态融合结合在一起,下游任务可以根据具体需求使用不同的模块进行微调。与之遥相呼应的的是BLIP模型,在ALBEF基础上,将MLM替换为LM( Language Modeling)Loss,的使得训练得到的模型同时可以支持图像描述文本的生成能力,如图18所示。使得多模态融合预训练有了多模态大模型即视感。
经过大规模多模态数据的预训练,ALBEF和BLIP在下游任务微调中均取得了十分亮眼的效果,在工业界也被广泛应用。
3.2.8 VL-BEIT、VLMO与BEIT-3
ALBEF和BLIP之类的工作虽然能够同时兼顾对比和深度融合两种训练模式,但视觉和自然语言仍然需要单独的Encoder分别编码,这显然还不是我们所期望的真正的多模态统一模型框架。我们可以从Microsoft Research的VL-BEIT、VLMO与BEIT-3这一系列工作一窥这个方向的探索过程。
VL-BEIT可以看作是前文提到的BEIT在多模态对齐预训练工作的延续,同时借鉴了ViLT的网络结构。如图19,与ViLT的区别在于,VL-BEIT期望将单模态和多模态统一到一个模型中,在预训练任务设计上,同时考虑了纯文本、纯视觉以及图文多模态任务。纯文本任务为MLM(a);纯视觉特征的MIM,其中MIM的目标是BEIT工作中的Visual Token ID(b);图文多模态任务包括考虑文本特征的视觉Token预测,以及考虑视觉特征的文本Token预测(c)。
VLMO是VL-BEIT的同期工作,如图20。VLMO相较于VL-BEIT的不同之处在于:1、舍弃了视觉侧的Visual Token ID预测,简化了整体的网络结构;2、增加了类似CLIP的图文对比学习任务,以及交互型的图文匹配任务。虽然VLMO相对于VL-BEIT在效果上并不出彩,但为后续BEIT-3的工作奠定了基础。网络结构上,VLMO是VL-BEIT都使用MoME Transformer结构,对不同的模态使用不同的Expert头,以区分不同模态的表征。
与VLMO网络结构类似,BEIT-3将图像、文本和图文多模态输入统一到一个单独的Multiway Transformer网络。不同于经典的Transformer,BEIT-3使用一个多类型输入共享的多头自注意力模块(Multi-Head Self-Attention),不同类型的模态输入各有一个全连接专家模块单独学习。如图21,视觉模态使用V-FFN、文本模态对应L-FFN,图文多模态输入对应VL-FFN,模型会根据不同类型的模态输入选择不同的模块生效。
在预训练任务上,如图22,BEIT-3相比之下也更加全面,不仅包括常用的图文对比学习、MLM和图像文本描述生成任务,还引进了文本和图像的单模态任务。这样的训练方式,使得BEIT-3真正统一了多模态的不同输入类型,同时更加全面和灵活的支持不同模态的下游任务。为了能够实现这样的能力,BEIT-3使用了更多的预训练数据,模型容量相对于之前的工作也有了显著的提高(达到1.9B),相应地最终也取得了在当时更好的效果。
BEIT-3将多模态对齐和预训练的研究推到了一个新的高度,验证了更多的数据+更大的模型取得更好的效果,在这个研究方向仍不失准 。虽然开始饱受争议,但随着ChatGPT的问世,这个发展思路的正确性被进一步加深,也催生了后面多模态大模型的一众研究工作。
四、多模态与大模型
写到这里,经过大规模篇幅的铺垫,终于到了大家都关心的多模态大模型章节。打开前两天的笔记,原来的计划是这部分内容参考综述论文的梳理,选择一些有代表性的工作进行问题的串连。当我重新下载这篇综述论文,想截一张示意图时,却是目瞪狗呆。对比一下,图23是年前的截图,图24是年后的。
这个速度,属实有点跟不上了。调整情绪后,我告诉自己很多工作万变不离其宗,可以延续原来的思路继续写,不增加加新的内容。这样,应该也挺合理的吧。下面我们通过各时期的优秀工作,来系统看一下类似GPT-4的多模态大模型的主流思路。
4.1 Flamingo
如今GPT-4代表着多模态大模型的顶尖水平,但在此之前,甚至在ChatGPT之前就已有相关探索工作,其中谷歌的Flamingo最具当前主流技术雏形。事实上,Flamingo更像是图文多模态领域的GPT-3,不同的是它支持图文上下文的输入,通过In-Context Few-Shot方式完成任务。Flamingo同样支持视频帧序列作为输入,通过Prompt指令完成Video理解任务。
做到这种功能,在模型侧和GPT-3类似,不同的是Flamingo在文本Transfomer网络中增加视觉输入特征,模型结构如图26,包括三个部分。
- 视觉侧特征抽取使用预训练的ResNet和采样模块(Perceiver Resampler,将变长的视觉特征输入转成少量的视觉特征)模型;
- 文本侧模型使用LLM(基座使用Chinchilla,同样是谷歌发布的对标GPT-3的大语言模型,并提供了1.4B、7B、和70B等版本,分别对应Flamingo-3B、Flamingo-9B和Flamingo-80B);
- GATED XATTN-DENSE层,用于连接LLM 层与视觉特征,允许 LM 在处理文本时考虑视觉信息。通过交叉注意力,LM 可以关注与视觉特征相关的部分。预训练LLM和视觉ResNet参数训练过程中是冻结状态。
相应的,在数据层面Flamingo也是使用了多样形式的训练语聊,包括:
- 图文穿插形式:MultiModal MassiveWeb (M3W),43 Million;
- 图文Pair对形式:LTIP(Long Text & Image Pairs),312 Million;
- 带文本描述的短视频:VTP (Video & Text Pairs) ,27 Million 。
最后Flamingo在各种多模态任务上的效果也非常优秀,甚至在有些数据集上通过few-shot方式可以超过经典模型的SOTA。
Flamingo凭借其出色的效果,吸引了许多研究者对于多模态大模型的注意,但当时这种规模的模型训练不是谁都能玩的起,因此并没有引起特别火热的跟风潮。直到ChatGPT的出现,让人逐渐接受了大模型这条道路的正确性,以前觉得自己玩不起的机构,砸锅卖铁拉投资也愿意投入,自此相关的开源研究开始如火如荼。
在众多开源工作中,BLIP-2以及与之一脉相承的InstructBLIP算是早期的探路者之一,我们可以从这两个工作开始讲起。
4.2 BLIP-2和InstructBLIP
BLIP-2的论文标题是Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models,核心思路是通过利用预训练好的视觉模型和语言模型来提升多模态效果和降低训练成本。
BLIP-2的网络结构如图28所示,从架构上来说,和Flamingo十分类似。包括视觉编码层、视觉与文本的Adapter(Q-Former)以及大语言模型层。
- 视觉编码层:使用ViT模型,权重初始化通过CLIP预训练完成,并剔除最后一次提升输出特征的丰富性;训练过程中冻结权重,不更新;
- 文本侧的大语言模型层:早期的BLIP-2使用OPT/FlanT5来实验Decoder based和Encoder-Decoder based LLM的效果;这部分同样在训练过程中冻结权重,不更新;
- 图文Adapter层:Q-Former结构,类似BLIP网络(同样先进行了图文多模态预训练模块),通过Queries向量,提取视觉侧的关键信息输入到LLM;这部分是多模态大模型训练过程中的主要参数。
和Flamingo相比,BLIP-2简化了视觉特征和大模型的交互,直接仅仅将视觉特征和文本特征一起作为大模型的输入,没有深层的交互模块(如GATED XATTN-DENSE层);另一方面在视觉和LLM的Adapter层做了更多的设计,即Q-Former结构,如图29。从Q-Former结构图,我们可以看到BLIP的影子,最大的不同在于一个Learned Queries模块,用于对ViT输出的视觉特征进行采样(Pooling),得到固定长度的视觉特征序列。
上面提到,为了避免灾难遗忘,BLIP-2冻结了ViT和LLM的参数,只训练Q-Former模块。为了训练更加稳定,Q-Former模块的训练包括两个阶段。
- Stage1: 将Q-Former与冻结的ViT拼接,借鉴BLIP,使用 ITC(图文对比学习)、ITG(图生成文本)和ITM(图文匹配)任务进行学习,对参数进行初始化,学习图文相关性特征。
- Stage2:如图30,将Stage1得到的模型再拼接LLM,即Q-Former的输出可通过线性投影输入到LLM(冻结参数),进行视觉到自然语言的生成学习,目标是训练Q-Former使其输出的视觉特征和LLM的输入分布对齐。
BLIP-2通过视觉和LLM的特征对齐,使得LLM具备了多模态理解能力,但其训练数据主要沿用BLIP(图文Pair对形式),和当下的多模态模型的主流技术方案仍存在一定GAP,是早期代表性探索之一。不过,随着指令微调成为大模型必备流程,后续BLIP-2也自然升级为InstructBLIP。
如图31,InstructBLIP的网络结构与BLIP-2几乎一致,同样也是2阶段训练,不同的是采样了指令微调范式,将文本模态的Instruction也作为输入同时给到Q-former和LLM进行学习。
对应的,InstructBLIP的另一个不同是训练数据也使用指令形式,将各种类型任务的开源学术数据,使用模板构造成指令多模态数据。数据模板如图31。
通过指令数据和指令微调,是的InstructBLIP可以像GPT-4一样通过指令提示词的方式完成任务,虽然效果上仍有差距。即使不是InstructBLIP的训练范式并不是开创性的,但是我们依然可以用InstructBLIP作为参考,来看对比后面要介绍的其他工作。
4.3 Qwen-VL
阿里巴巴的Qwen-VL是另一个比较经典的模型,十分值得作为案例介绍多模态大模型的训练要点。Qwen-VL使用Qwen-7B LLM作为语言模型基座,Openclip预训练的ViT-bigG作为视觉特征Encoder,随机初始化的单层Cross-Attention模块作为视觉和自然语言的的Adapter,总参数大小约9.6B。
如图33,Qwen-VL的训练过程分为三个阶段:
- Stage1 为预训练,目标是使用大量的图文Pair对数据对齐视觉模块和LLM的特征,这个阶段冻结LLM模块的参数;
- Stage2 为多任务预训练,使用更高质量的图文多任务数据(主要来源自开源VL任务,部分自建数据集),更高的图片像素输入,全参数训练;
- Stage3 为指令微调阶段,这个阶段冻结视觉Encoder模块,使用的数据主要来自大模型Self-Instruction方式自动生成,目标是提升模型的指令遵循和多轮对话能力。
Qwen-VL的另一个启发是在Stage2和Stage3的训练过程中,不止使用VL数据,还使用了纯文本的训练数据,避免遗忘LLM的能力,这个策略的效果在其他的工作中也有所印证。此外,相比InstructBLIP,Qwen-VL模型视觉和LLM的Adapter模块简化很多,仅仅是一个浅层的Attention Pooling模块,通过更加细节的训练流程和更加丰富的训练数据,仍取得了比InstructBLIP更优的效果。
4.4 LLaVA1.5
同样,微软的LLaVA也是一个持续更新的系列工作,这里主要总结LLaVA和LLaVA1.5的核心思路。图34为LLaVA1.5的数据和模型概况。可以看到,和Qwen-VL相比,LLaVA1.5在预训练和指令微调数据上使用了更少的数据(将Qwen-VL的Stage2和Stage3都视作指令微调);在模型结构上,除了视觉Encoder和LLM均使用了不同的基座模型,视觉和自然语言的Adapter使用更简单的MLP层。
LLaVA1.5模型的效果在一些评测数据集上相比Qwen-VL有更好的效果,说明通过一些优化工作,使用更少的数据,更简单的Adapter结构,也能使LLM具备不错的多模态理解能力。在数据层面,如图35,对比LLaVA1.5和LLaVA工作,通过增加高质量细粒度的VL数据、丰富指令、纯文本指令微调数据、提升图片输入像素、提升LLM参数规模等手段,可以有效提升模型效果。
4.5 VILA
另一个与LLaVA比较类似,但有所补充的工作是英伟达的VILA(不是显卡)。VILA模型的网络结构和LLaVA十分类似,我们不做过多赘述。不同的是VILA通过实验,总结了多模态预训练的一些经验,其中有些经验在相关工作中也有所体现,主要为以下三点:
- LLM参与训练更好:在预训练阶段冻结LLM参数,能做到不错的zero-shot的能力,但会损失in-context学习的能力,而LLM参数参与训练的话可以有效缓解;
- 预训练数据使用图文交替数据更好:图文Pair对并不是最优的选择,图文交错的数据效果更好;
- SFT时纯文本数据图文数据混合更好:在图文指令微调训练数据中混入纯文本的指令数据,不仅可以缓解纯文本能力的遗忘,还能提升VL任务的能力。
具体的,如图37,VILA的训练分为3个阶段,视觉编码模块ViT参数均是冻结状态。Step 0 使用图文Pair数据对初始化Projector(图文Adapter)参数,LLM模块参数冻结;Step 1使用图文交替数据全参数预训练;Step 2使用指令微调数据进行全参数微调,其中微调数据混合了图文指令和纯文本指令;
VILA是较新的工作,因此有更丰富的模型效果对比,如图38,相对各时期的SoTA,VILA在公开评测指标上有不错的效果。
4.6 Gemini 1.0和Gemini 1.5
目光来到闭源世界,与VILA同阶段,谷歌公司发布了Gemini系列,又在近期发布了性能更强的Gemini 1.5,可惜被另一个热爱闭源的OpenAI的Sora抢了风头,属实悲催。由于Gemini系列并没有开源,我们只能通过技术报告中的简单介绍来了解其方法。
Gemini 1.0是一个多模态模型,这里模态除了图图像和文还包括音频、视频,符合谷歌多模态大模型一贯的ALL IN ONE的风格,这也是依赖积累丰富的数据资源和算力资源。Gemini 1.0提供Ultra、Pro和Nano版本,分别适应不同能力、参数大小和推理速度要求,最小的Nano甚至可以端上运行。
方法上,Gemini 1.0的网络结构同样是Transformer Decoders,支持32K上下文长度,使用了Multi-Query Attention等优化机制。如图39,模型输入可以是文本、音频、视觉输入,输入视觉可以是图片、图表、截图、PDFs或视频等,输出可以是图片和文本(没错,可以生成图片)。视觉的Encoder模块借鉴了谷歌自己的Flamingo、CoCa和PaLI,结合这些模型,可以输入多模态的同时,也可以通过离散的视觉Tokens生成图片或视频等视觉模态。
对于音频模态,Gemini可以直接输入Universal Speech Model (USM)的16kHz特征,具体可以参考USM工作。对于视频理解,Gemini通过将视频编码为长上下文窗口中的一系列帧来实现。视频帧或图像可以与文本或音频自然交织在一起,作为模型输入的一部分。Gemini同时支持不同像素输入的视觉以满足不同粒度的理解任务。
在具体训练数据方面,技术报告同样并没有提过多细节,只是简单说了数据包括什么模态、经过了什么清洗步骤等,我们也不再深究。至于最近的Gemini 1.5,同样是技术报告的形式发布,没有特别多技术细节,主要介绍了模型是如何的强。区别要点包括:模型在Gemini 1.0基础上引入了sparse mixture-of-expert (MoE),同时强化了上下文长度(32K->10M)同时几乎没有损失上下文感知能力。在训练过程中,Gemini 1.5强化了指令微调过程,使用了用户偏好数据。
总体来说,虽然Gemini没有提供技术细节,但也体现了谷歌对于多模态大模型技术方向的判断,比如我们可以get到**网络结构的MoE、一个模型更多模态、超长上下文、文本生成+多模态生成结合等。**
4.7 LWM
最后,我们再介绍一篇和Gemini类似的开源工作《World Model on Million-Length Video And Language With RingAttention》,模型名LWM(Large World Model)。至于为什么叫World Model,意思可以通过视觉和视频的理解物理世界,,LWM是UC Berkeley最近发布的一篇工作,个人认为在开源方向上是一个优秀的工作,但好像也是由于Sora和Gemini 1.5的热度,没有引起太多关注。
LWM希望完成的任务和Gemini十分相似,核心是超长上下文理解的多模态大模型。凭借支持1M的token输入,LWM可以对超过一小时的视频进行理解,在Gemini 1.5之前几乎是多模态大模型中最长的上下文输入(之一)。LWM的主要工作要点包括:
- 支持超长上下文,可处理超长的文本、图片序列或视频等;
- 一些技术难点方案:Masked Sequence Packing方法混合的输入长度;通过loss weighting 平衡视觉和文本模态;模型自动生成长序列问答数据集用于模型训练;
- 实现了高性能的RingAttention,Masked Sequence Packing等优化项,完成了百万级别长度的多模态序列的训练;
- 开源7B参数规模的大模型,包括长上下文的文本模态模型(LWM-Text,LWM-Text-Chat),和多模态模型(LWM,LWM-Chat)。
具体方案上,LWM使用Transformer架构,在LLama2 7B基础上扩充上下文理解的长度上限,模型结构如图40:
与之前大多数方法不同的是,视觉的编码器使用VQGAN,可以将256 × 256输入图片编码成16 × 16 离散Token。这使得LWM不仅可以生成文本,也可以基于文本生成Image Token还原成视频。对于多图或视频帧,可以分别做视觉特征抽取,和文本模态一起输入到LLM中。
在模型训练流程上,主要分为两个阶段的训练:
- 阶段一,使用Books数据集,先扩充文本LLM上下文长度到1M;
- 阶段二,长上下文的多模态训练,即混合图-文数据、视频-文本数据、以及纯文本的Books数据进行训练。
上面两个过程有两个核心问题需要解决:1、长文档的可扩展训练;2、如何稳定地扩展LLM的上下文。前者关注训练的效率和开销,后者则关注长上下文拓展的有效性。针对问题1,LWM主要实现了高效的RingAttention,同时结合了FlashAttention;针对问题2,一方面,两个训练阶段都是多轮训练方式,逐步提升上下文长度的方式,如图41。另一方面通过简单的调整了RoPE的参数,提升模型长文本的位置编码能力。
总的来说,LWM是一篇不错的文章,最重要的是开源,技术方案基本没有保留,值得拉出来单独讨论。在效果上LWM和Gemini 1.0 Pro以及GPT4有一定的竞争力,更多的细节可以阅读原论文。
五、总结
写到这里,吐一口老血,但还是要总结一下。本文梳理了2019年之后视觉表征和多模态表征的一些变化,主要涉及视觉表征和视觉预训练、多模态表征对齐(或融合)和多模态预训练、多模态大模型技术的相关工作。各工作之间的简化关系如图42,脉络主要是结合笔者自己各阶段的实践经历和认识,会出现一些地方不严谨的地方,欢迎指正。
关于未来畅想,从最近的工作上来看,多模态的呈现出以大模型为主线,逐步开始朝长上下文、混合模态、世界模型、多模态生成等方向发展。开始在自己工作的实践中得到的一个个人观点,是多模态大模型的惊艳能力主要来自于文本大模型中所蕴含的知识,以及超强的上下文理解能力,视觉特征只是从属的信息输入或感知源。但近期Gemini 1.5、LWM、甚至Sora等工作又开始尝试大模型理解物理世界(引出世界模型的概念),大模型好像开始从文本之外的模态强化输入信息的影响力。不管怎么说,持续的更新迭代让人耳目一新,相信也会不断刷新人们对人工智能边界的认知。
最后,感觉知乎长文确实耗时耗力,如果有收获欢迎关注本账号:菜人卷。另外打算后面开一个小红书的坑,写一些日常学习和实践的短篇经验,提高一下更新频率,系统性内容也会周期性的搬到知乎上来,欢迎扫码关注支持。
http://xhslink.com/ljMMsC (二维码自动识别)
六、论文打包下载
PS:引用文章可以细读,论文打包下载链接: https://pan.baidu.com/s/18tkHDkDmGKvzEeGSEc52Jg 提取码: hvkf
#PCP-MAE
不用Encoder也能重建点云?点云MAE自监督新框架引言
点云被广泛用于表示3D信息,可以表达丰富的几何信息。多功能性使得它们在各种应用场景中得到了广泛采用,包括自动驾驶、机器人技术和元宇宙。在点云理解的早期发展阶段,有许多相关工作提出来增强网络对点云的理解能力,其中网络通常需要从头开始进行有监督训练。然而,与2D视觉和NLP中的数据相比,点云数据更难注释,因为人工对点云分类更加困难。这导致了3D领域中出现了所谓的"数据荒漠"现象,限制了这些有监督方法的发展。最近,研究者们提出了许多自监督学习方法来缓解"数据荒漠"带来的负面影响,其中以Point-MAE为代表的Generative自监督学习范式最近发展迅速。Point-MAE是3D自监督学习领域十分重要的一项工作,也是很多后续工作的基础模型,其在点云领域得到了广泛应用。
Point-MAE的缺陷
掩码自编码器(Masked Autoencoders MAE)是一种自监督预训练方法,旨在通过在大量无标注数据中预训练,使模型学习到语义丰富的表征,从而迁移到下游任务中提升模型性能。MAE的架构具有明显的不对称性,包含一个编码器(encoder)和一个轻量级的解码器(decoder)。其典型的处理流程是将输入分割成若干patch,并在编码之前选择性地对其进行掩码。编码器仅接受可见patch作为输入,并附带patch的位置编码(Positional Embeddings PE)。解码器则接收编码过后的可见patch和掩码patch的位置编码进行输入样例的重建,经过预训练后,将encoder用于下游任务微调。
Point-MAE是首个把2D图像领域的MAE拓展到点云领域的工作,其将点云划分为多个patch,并对patch中的点进行归一化处理,归一化是通过减去相应中心的坐标并缩放点云实现的。Point-MAE所代表的是一类目前在点云自监督领域中应用广泛的掩码重建预训练范式。
然而,与2D MAE中图像patch的位置编码(图像patch的索引编号)不同的是,Point-MAE中点云patch的位置编码是由patch中心的坐标得到的,这些中心的坐标包含丰富的几何和语义信息。 因此,本文提出了一个问题:在点云领域,执行掩码重建时,是否应该像2D中那样直接提供掩码patch的位置编码给decoder用于样例重建?
本文通过一个有趣的实验解答了这个问题。本文将Point-MAE的掩码比例设置为100%,并进行掩码重建预训练(移除encoder),以验证仅通过将掩码patch的位置信息提供给decoder,是否能够重建出整个点云。出乎意料的是,尽管没有使用encoder的输出,经过预训练后的decoder依然能够很好地重建点云,结果如下图所示。
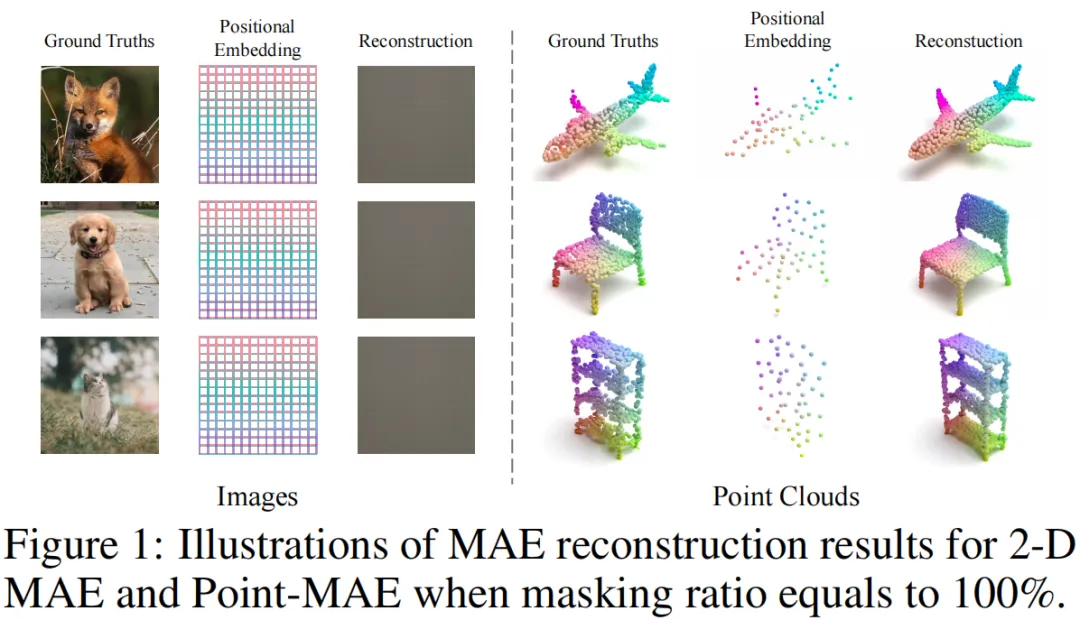
这个现象在2D MAE中是无法复现的,因为当掩码100%的图像,仅提供掩码patch的位置编码(即图像patch的索引编号)时,2D MAE无法识别图像(所有具有相同分辨率的图像共享相同的位置嵌入)。这种差异表明,相比于图像领域,点云领域patch的中心坐标至关重要。这也说明当前Point-MAE所采用的预训练范式在一定程度上是存在掩码重建捷径的,不利于encoder学习到语义丰富的表征,本文认为前文的问题答案是:掩码patch的中心(位置编码)不能直接提供给decoder,而应该以更加合理的方式利用它们。
对此,本文提出了PCP-MAE,即Learning to Predict Centers for Point Masked AutoEncoders。现有的基于MAE的方法(Point-MAE,ACT,ReCon,Point-FEMAE,I2P-MAE等)忽视了patch中心的重要性,直接将掩码中心泄漏给解码器。和它们不同的是,PCP-MAE很好地利用了patch中心,不仅执行点云重建,还引导模型学习预测掩码patch的中心位置编码,使用预测的中心替代真实的掩码中心。
代码仓库:https://github.com/aHapBean/PCP-MAE
PCP-MAE1 的核心思想如下:
在Point-MAE的基础上,本文提出了一个新颖的中心位置编码预测任务,旨在引导encoder不仅学习编码可见patch的表征,还要学习预测掩码patch的位置编码。
具体实现上,本文将可见patch和掩码patch同时输入到encoder中。可见patch(包含位置编码)通过自注意力机制在每个模块中进行编码;而掩码patch(不含位置编码)则通过交叉注意力机制,从可见patch和自身中获取位置编码信息。
此外,本文还引入了一个专门的目标函数,用于最小化预测的掩码位置编码与真实值之间的差异。预测的掩码patch位置编码将替代真实的位置编码,输入到decoder中。这一过程使得encoder不仅能够有效地编码可见patch,还能学习到可见和掩码patch中心之间的相互关系。通过这种方式,encoder能够推断出缺失的位置信息,从而学习到语义更加丰富的表征。
主要贡献如下:
- 本文指出了2D(图像)和3D(点云)在patch划分上的差异:在2D中,位置编码代表的是patch的索引编号,而在点云中,位置编码(PE)则表示patch中心的坐标,其中坐标信息比索引编号提包含了更加丰富的信息。在100%掩码比例下,点云能够通过解码器成功重建,这表明解码器不完全依赖于编码器学习到的表示也能完成掩码重建预训练。而这一现象在2D MAE中并不存在,表明现有基于MAE的点云自监督学习方法的掩码重建预训练是有缺陷的,存在捷径。
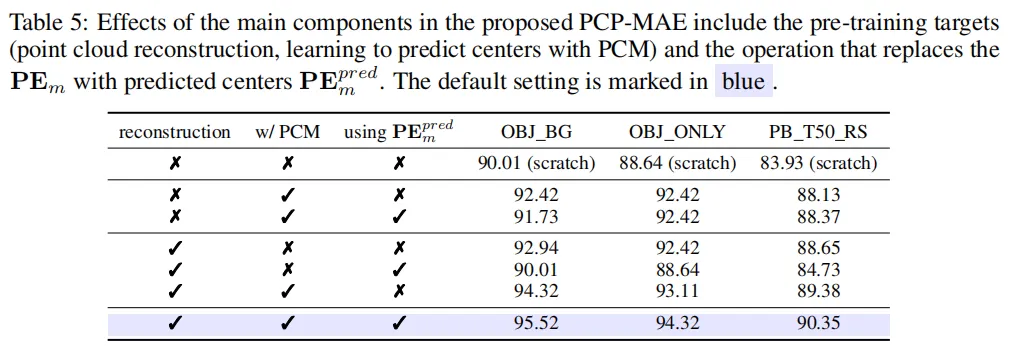
- 本文提出了PCP-MAE,它不仅用于点云重建,还通过引导网络学习预测掩码patch的中心,在避免直接泄漏中心信息的同时,使得encoder学习到的表征更加丰富。为此,提出了预测中心模块(PCM),该模块负责预测中心的位置编码,并与encoder共享参数,从而避免增加额外的参数量。
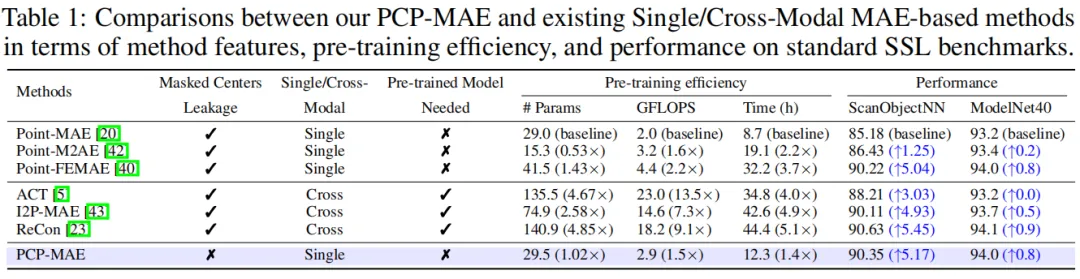
- 与其他基于MAE的方法相比,PCP-MAE仅引入了少量的额外参数和可接受的额外预训练时间,保持了非常高的预训练效率,如下图所示。 PCP-MAE的性能在某些基准上达到了SOTA。特别地,PCP-MAE在ScanObjectNN的三个基准上相比于Point-MAE分别提高了5.50%、6.03%和5.17%。
具体方法
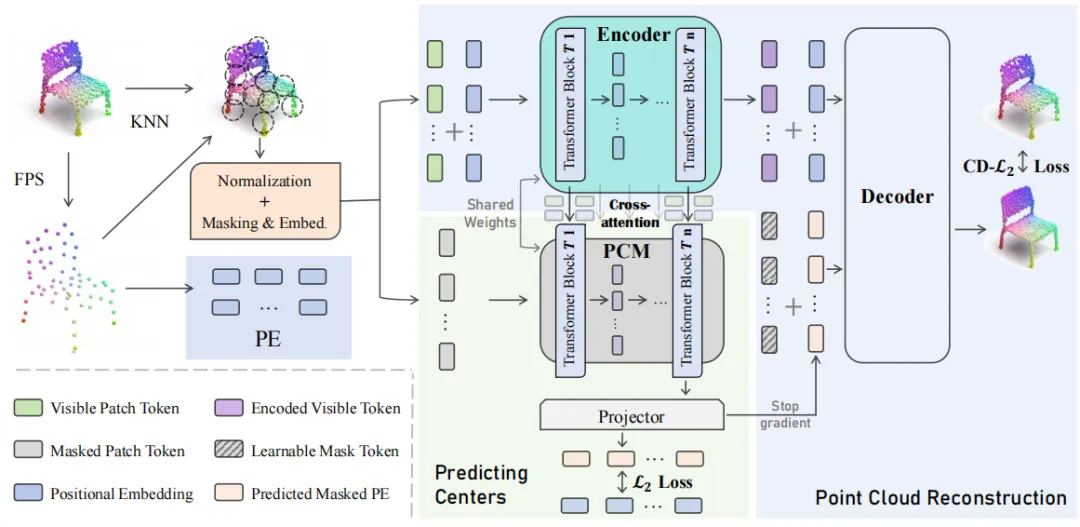
PCP-MAE的框架如下图所示。在进行patch划分后,将中心和归一化的patch划分为可见部分和掩码部分,利用中心坐标得到位置编码,patch编码为tokens。编码器接收可见tokens和PE作为输入,执行自注意力操作。同时,权重共享的PCM(预测中心模块)执行交叉注意力(将掩码tokens作为查询,结合可见和掩码tokens作为键和值),从中获取知识以预测掩码patch的位置编码。CD-L2表示L2 Chamfer距离损失函数。
Patch生成与掩码
Patch生成:基于patch的学习范式已经被证明比直接处理整个点云更有效。本文采用该范式,通过Farthest Point Sampling (FPS) 和 K-Nearest Neighborhood (KNN)算法将输入点云划分为多个point patch。具体地,给定一个包含个点的点云 ,首先应用FPS从个点中采样出个中心点,然后使用KNN选择每个中心点的个最近邻点,组成个point patch :
点云patch中的点通过其对应的中心点进行归一化。
掩码:使用预定义的掩码比例,对点云patch进行全局随机掩码。掩码后的patch表示为,可见的patch表示为,其中和分别表示下取整和上取整函数。对应的中心点分别为和。
嵌入:可见的patch 通过轻量级的PointNet进行嵌入,得到编码后的tokens ,具体如下:
对每个中心点的坐标计算固定的sin-cos位置编码(sin-cos PE):
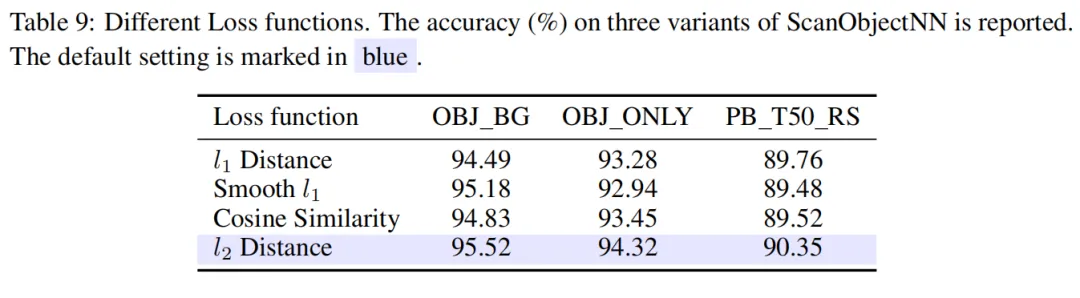
其中。然后将、和连接,得到。接着将该sin-cos位置嵌入输入到可学习的MLP模块(Positional Embedding Module, PEM)中,得到最终的PE。这种方式与Point-MAE中的操作不同,通过sin-cos PE可以为位置提供更加稀疏的信息,从而更适合作为预测任务的目标。过程可以表示为:
编码器与PCM
本文采用一个由标准Transformer模块组成的编码器。给定编码后的可见tokens 、掩码tokens 和可见位置编码 ,编码器通过自注意力编码,同时利用掩码tokens 进行交叉注意力,以从可见和掩码表示中获取掩码中心的信息。需要注意的是,自注意力和交叉注意力共享Transformer块的参数,以避免增加额外的参数。
可见tokens编码:可见部分的潜在表示通过将和输入编码器,并使用自注意力机制获得。过程可表示为:
具体地,第个Transformer块中的自注意力计算为:
其中,,,、、为可学习的参数。注意,。
学习预测中心的模块(PCM):PCM与编码器共享参数,并且仅接受掩码patch 作为输入。除了共享的Transformer块参数外,PCM还引入了一个MLP,用于将潜在的预测投影到掩码中心的嵌入。PCM的目标是通过从可见和掩码表示中获取信息,恢复掩码patch的中心。可以将其理解为,在给定局部模式(没有告知中心位置)和可见的全局模式的情况下,任务是从已知的局部模式中获取局部模式的中心位置。交叉注意力机制如下:
具体地,对于PCM中的第个Transformer块,交叉注意力计算为:
其中,,,、为共享参数。将和连接得到,同样操作也适用于和。注意,是PCM的输入,即。
解码器
解码器同样由Transformer模块组成,用于点云的掩码重建。在现有基于MAE的方法(如Point-MAE、ReCon、Point-FEMAE)中,解码器通常接受、、作为输入,并结合可学习的掩码token。具体形式为:
其中,掩码patch的中心直接提供给解码器。然而,点云中patch的中心非常重要。因此,用代替,即使用网络学习到的结果,但不直接泄漏位置编码的真实值给解码器。过程可以写成:
其中,表示停止梯度操作,。停止梯度用于防止解码器通过反向传播修改PCM的权重,进而找到重建的捷径(详见消融实验部分)。最后,沿用Point-MAE的方法,本文使用一个包含MLP层的映射头来预测输入点云中归一化掩码patch中点的坐标:
目标函数
目标函数由两部分组成,用来衡量所预测掩码patch的中心和重建每个掩码patch中点的坐标和真值之间的差异。可以表示为:
其中,是一个缩放因子。
中心预测:本文使用损失函数计算预测中心的损失:
由于生成点云patch时通过归一化移除了中心信息,因此PCM无法通过、和找到恢复掩码patch中心的捷径。恢复并非易事,因为这要求PCM能够很好地编码掩码patch,并且要求可见表示不仅包含自身的信息,还要能够跨patch地包含掩码patch的中心信息。换句话说,最小化使得可见表示能够包含足够的信息来推断掩码patch中心的分布,这是Point-MAE中是所做不到的。
点云重建:重建损失使用 Chamfer Distance损失函数计算:
实验效果





总结一下
本文首先指出了了图像和点云中位置编码的差异,发现直接泄漏掩码中心会使得Point-MAE和现有基于Point-MAE的方法在预训练阶段变得 trivial,即不使用编码器,解码器也能完成重建。为了解决这个问题,本文提出了PCP-MAE,它引入了一个新的预训练目标,指导编码器预测掩码patch的中心信息,从而使编码器能够学习到更多语义信息。为此,本文提出了一个预测中心模块(PCM),该模块使用交叉注意力机制并与编码器共享参数。通过在自监督学习基准上的大量实验,展示了其提出的方法相比于Point-MAE具有更优的性能,并在多个任务上达到了SOTA。
局限性与未来工作:PCP-MAE的局限性主要体现在两个方面。首先,PCP-MAE是一个单模态自监督方法,而目前3D点云数据集的规模较小,这限制了该方法的广泛应用。其次,PCP-MAE是一种Generative学习范式,而没有结合Contrastive学习范式的优势。未来的研究可以基于PCP-MAE进行多模态扩展、或者是提出一个结合生成式和对比学习的混合PCP-MAE模型。