目录
[7.1 生成器和判别器的损失函数图像](#7.1 生成器和判别器的损失函数图像)
[7.2 训练过程中生成器生成的图像](#7.2 训练过程中生成器生成的图像)
由于之前写gans的代码时,我的生成器和判别器不是使用的全连接网络就是卷积,但是无论这两种方法怎么组合,最后生成器生成的图像效果都很不好。因此最后我选择了生成器使用转置卷积 ,而判别器使用卷积,最后得到的生成图像确实效果比之前好很多了。
一、第三方库导入
python
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
from torchvision import transforms
import os
from PIL import Image
from torch.utils.data import Dataset, DataLoader二、数据集准备
python
# 手写数字数据集
class MINISTDataset(Dataset):
def __init__(self, files, root_dir, transform=None):
self.files = files
self.root_dir = root_dir
self.transform = transform
self.labels = []
for f in files:
parts = f.split("_")
p = parts[2].split(".")[0]
self.labels.append(int(p))
def __len__(self):
return len(self.files)
def __getitem__(self, idx):
img_path = os.path.join(self.root_dir, self.files[idx])
img = Image.open(img_path).convert("L")
if self.transform:
img = self.transform(img)
label = self.labels[idx]
return img, label三、使用转置卷积的生成器
python
class Generator(nn.Module):
def __init__(self, latent_dim=100):
super().__init__()
self.main = nn.Sequential(
# 输入: latent_dim维噪声 -> 输出: 7x7x256
nn.ConvTranspose2d(latent_dim, 256, kernel_size=7, stride=1, padding=0, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(True),
# 上采样: 7x7 -> 14x14
nn.ConvTranspose2d(256, 128, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(True),
# 上采样: 14x14 -> 28x28
nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
# 输出层: 28x28x1
nn.ConvTranspose2d(64, 1, kernel_size=3, stride=1, padding=1, bias=False),
nn.Tanh()
)
def forward(self, x):
# 将噪声重塑为 (batch_size, latent_dim, 1, 1)
x = x.view(x.size(0), -1, 1, 1)
return self.main(x)四、使用卷积的判别器
python
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.main = nn.Sequential(
# 输入: 1x28x28
nn.Conv2d(1, 32, kernel_size=4, stride=2, padding=1), # 输出: 32x14x14
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout2d(0.3),
nn.Conv2d(32, 64, kernel_size=4, stride=2, padding=1), # 输出: 64x7x7
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout2d(0.3),
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1), # 输出: 128x7x7
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout2d(0.3),
nn.Flatten(),
nn.Linear(128 * 7 * 7, 1),
nn.Sigmoid()
)
def forward(self, x):
return self.main(x)五、生成器生成图像
python
# 展示生成器生成的图像
def gen_img_plot(test_input, save_path):
gen_imgs = gen(test_input).detach().cpu()
gen_imgs = gen_imgs.view(-1, 28, 28)
plt.figure(figsize=(4, 4))
for i in range(16):
plt.subplot(4, 4, i + 1)
plt.imshow(gen_imgs[i], cmap="gray")
plt.axis("off")
plt.savefig(save_path, dpi=300)
plt.close()六、主程序
python
if __name__ == "__main__":
# 对数据做归一化处理
transforms = transforms.Compose([
transforms.Resize((28, 28)),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 路径
base_dir = 'C:\\Users\\Administrator\\PycharmProjects\\CNN'
train_dir = os.path.join(base_dir, "minist_train")
# 获取文件夹里图像的名称
train_files = [f for f in os.listdir(train_dir) if f.endswith('.jpg')]
# 创建数据集和数据加载器
train_dataset = MINISTDataset(train_files, train_dir, transform=transforms)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
# 参数
epochs = 50
lr = 0.0002
# 初始化模型的优化器和损失函数
gen = Generator()
dis = Discriminator()
d_optim = torch.optim.Adam(dis.parameters(), lr=lr, betas=(0.5, 0.999)) # 判别器的优化器
g_optim = torch.optim.Adam(gen.parameters(), lr=lr, betas=(0.5, 0.999)) # 生成器的优化器
loss_fn = torch.nn.BCELoss() # 二分类交叉熵损失函数
# 记录loss
D_loss = []
G_loss = []
# 训练
for epoch in range(epochs):
d_epoch_loss = 0
g_epoch_loss = 0
count = len(train_loader) # 返回批次数
for step, (img, _) in enumerate(train_loader):
# 每个批次的大小
size = img.size(0)
random_noise = torch.randn(size, 100)
# 判别器训练
d_optim.zero_grad()
real_output = dis(img)
d_real_loss = loss_fn(real_output, torch.ones_like(real_output))
# d_real_loss.backward()
gen_img = gen(random_noise)
gen_img = gen_img.view(size, 1, 28, 28)
fake_output = dis(gen_img.detach())
d_fake_loss = loss_fn(fake_output, torch.zeros_like(fake_output))
# d_fake_loss.backward()
d_loss = (d_real_loss + d_fake_loss) / 2
d_loss.backward()
d_optim.step()
# 生成器的训练
g_optim.zero_grad()
fake_output = dis(gen_img)
g_loss = loss_fn(fake_output, torch.ones_like(fake_output))
g_loss.backward()
g_optim.step()
# 计算在一个epoch里面所有的g_loss和d_loss
with torch.no_grad():
d_epoch_loss += d_loss
g_epoch_loss += g_loss
# 计算平均损失值
with torch.no_grad():
d_epoch_loss = d_epoch_loss / count
g_epoch_loss = g_epoch_loss / count
D_loss.append(d_epoch_loss.item())
G_loss.append(g_epoch_loss.item())
print("Epoch:", epoch, " D loss:", d_epoch_loss.item(), " G Loss:", g_epoch_loss.item())
# 每隔2个epoch绘制生成器生成的图像
if (epoch + 1) % 2 == 0:
test_input = torch.randn(16, 100)
name = f"gen_img_{epoch}.jpg"
save_path = os.path.join('C:\\Users\\Administrator\\PycharmProjects\\CNN\\gen_img_11', name)
gen_img_plot(test_input, save_path)
# 绘制损失曲线图
plt.figure(figsize=(12, 6))
plt.plot(D_loss, label="判别器", color="tomato")
plt.plot(G_loss, label="生成器", color="orange")
plt.xlabel("epoch")
plt.ylabel("loss")
plt.title("生成器和判别器的损失曲线图")
plt.legend()
plt.grid()
plt.savefig("C:\\Users\\Administrator\\PycharmProjects\\CNN\\gen_dis_loss_11.jpg", dpi=300, bbox_inches="tight")
plt.close()七、运行结果
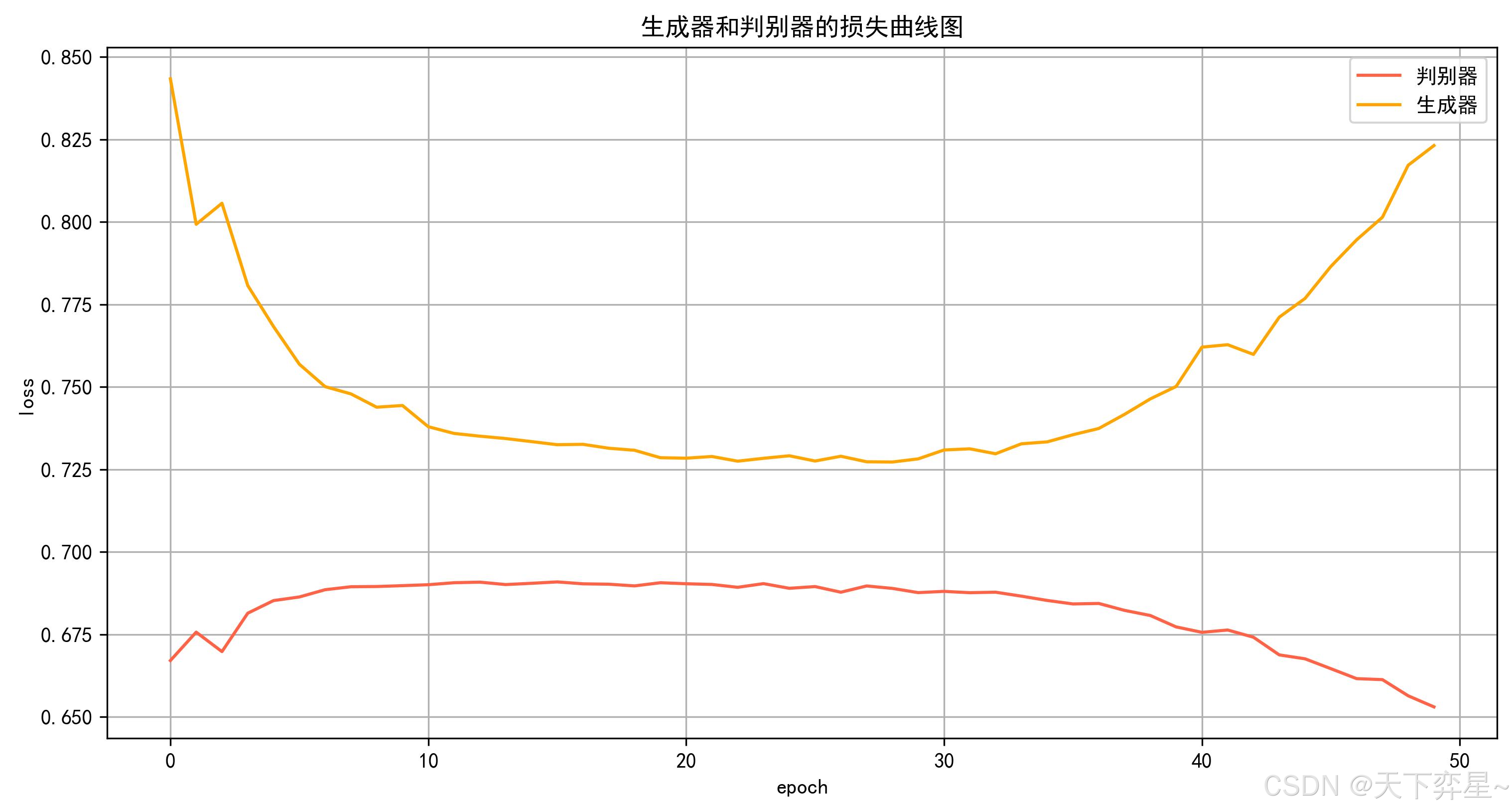
7.1 生成器和判别器的损失函数图像
7.2 训练过程中生成器生成的图像
这里只展示一部分

gen_img_1.jpg

gen_img_25.jpg

gen_img_49.jpg
八、完整的pytorch代码
python
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 设置中文字体
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
from torchvision import transforms
import os
from PIL import Image
from torch.utils.data import Dataset, DataLoader
# 手写数字数据集
class MINISTDataset(Dataset):
def __init__(self, files, root_dir, transform=None):
self.files = files
self.root_dir = root_dir
self.transform = transform
self.labels = []
for f in files:
parts = f.split("_")
p = parts[2].split(".")[0]
self.labels.append(int(p))
def __len__(self):
return len(self.files)
def __getitem__(self, idx):
img_path = os.path.join(self.root_dir, self.files[idx])
img = Image.open(img_path).convert("L")
if self.transform:
img = self.transform(img)
label = self.labels[idx]
return img, label
# 改进的生成器(使用转置卷积)
class Generator(nn.Module):
def __init__(self, latent_dim=100):
super().__init__()
self.main = nn.Sequential(
# 输入: latent_dim维噪声 -> 输出: 7x7x256
nn.ConvTranspose2d(latent_dim, 256, kernel_size=7, stride=1, padding=0, bias=False),
nn.BatchNorm2d(256),
nn.ReLU(True),
# 上采样: 7x7 -> 14x14
nn.ConvTranspose2d(256, 128, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(128),
nn.ReLU(True),
# 上采样: 14x14 -> 28x28
nn.ConvTranspose2d(128, 64, kernel_size=4, stride=2, padding=1, bias=False),
nn.BatchNorm2d(64),
nn.ReLU(True),
# 输出层: 28x28x1
nn.ConvTranspose2d(64, 1, kernel_size=3, stride=1, padding=1, bias=False),
nn.Tanh()
)
def forward(self, x):
# 将噪声重塑为 (batch_size, latent_dim, 1, 1)
x = x.view(x.size(0), -1, 1, 1)
return self.main(x)
# 改进的判别器(使用深度卷积网络)
class Discriminator(nn.Module):
def __init__(self):
super().__init__()
self.main = nn.Sequential(
# 输入: 1x28x28
nn.Conv2d(1, 32, kernel_size=4, stride=2, padding=1), # 输出: 32x14x14
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout2d(0.3),
nn.Conv2d(32, 64, kernel_size=4, stride=2, padding=1), # 输出: 64x7x7
nn.BatchNorm2d(64),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout2d(0.3),
nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1), # 输出: 128x7x7
nn.BatchNorm2d(128),
nn.LeakyReLU(0.2, inplace=True),
nn.Dropout2d(0.3),
nn.Flatten(),
nn.Linear(128 * 7 * 7, 1),
nn.Sigmoid()
)
def forward(self, x):
return self.main(x)
# 展示生成器生成的图像
def gen_img_plot(test_input, save_path):
gen_imgs = gen(test_input).detach().cpu()
gen_imgs = gen_imgs.view(-1, 28, 28)
plt.figure(figsize=(4, 4))
for i in range(16):
plt.subplot(4, 4, i + 1)
plt.imshow(gen_imgs[i], cmap="gray")
plt.axis("off")
plt.savefig(save_path, dpi=300)
plt.close()
if __name__ == "__main__":
# 对数据做归一化处理
transforms = transforms.Compose([
transforms.Resize((28, 28)),
transforms.ToTensor(),
transforms.Normalize((0.5,), (0.5,))
])
# 路径
base_dir = 'C:\\Users\\Administrator\\PycharmProjects\\CNN'
train_dir = os.path.join(base_dir, "minist_train")
# 获取文件夹里图像的名称
train_files = [f for f in os.listdir(train_dir) if f.endswith('.jpg')]
# 创建数据集和数据加载器
train_dataset = MINISTDataset(train_files, train_dir, transform=transforms)
train_loader = DataLoader(train_dataset, batch_size=64, shuffle=True)
# 参数
epochs = 50
lr = 0.0002
# 初始化模型的优化器和损失函数
gen = Generator()
dis = Discriminator()
d_optim = torch.optim.Adam(dis.parameters(), lr=lr, betas=(0.5, 0.999)) # 判别器的优化器
g_optim = torch.optim.Adam(gen.parameters(), lr=lr, betas=(0.5, 0.999)) # 生成器的优化器
loss_fn = torch.nn.BCELoss() # 二分类交叉熵损失函数
# 记录loss
D_loss = []
G_loss = []
# 训练
for epoch in range(epochs):
d_epoch_loss = 0
g_epoch_loss = 0
count = len(train_loader) # 返回批次数
for step, (img, _) in enumerate(train_loader):
# 每个批次的大小
size = img.size(0)
random_noise = torch.randn(size, 100)
# 判别器训练
d_optim.zero_grad()
real_output = dis(img)
d_real_loss = loss_fn(real_output, torch.ones_like(real_output))
# d_real_loss.backward()
gen_img = gen(random_noise)
gen_img = gen_img.view(size, 1, 28, 28)
fake_output = dis(gen_img.detach())
d_fake_loss = loss_fn(fake_output, torch.zeros_like(fake_output))
# d_fake_loss.backward()
d_loss = (d_real_loss + d_fake_loss) / 2
d_loss.backward()
d_optim.step()
# 生成器的训练
g_optim.zero_grad()
fake_output = dis(gen_img)
g_loss = loss_fn(fake_output, torch.ones_like(fake_output))
g_loss.backward()
g_optim.step()
# 计算在一个epoch里面所有的g_loss和d_loss
with torch.no_grad():
d_epoch_loss += d_loss
g_epoch_loss += g_loss
# 计算平均损失值
with torch.no_grad():
d_epoch_loss = d_epoch_loss / count
g_epoch_loss = g_epoch_loss / count
D_loss.append(d_epoch_loss.item())
G_loss.append(g_epoch_loss.item())
print("Epoch:", epoch, " D loss:", d_epoch_loss.item(), " G Loss:", g_epoch_loss.item())
# 每隔2个epoch绘制生成器生成的图像
if (epoch + 1) % 2 == 0:
test_input = torch.randn(16, 100)
name = f"gen_img_{epoch}.jpg"
save_path = os.path.join('C:\\Users\\Administrator\\PycharmProjects\\CNN\\gen_img_11', name)
gen_img_plot(test_input, save_path)
# 绘制损失曲线图
plt.figure(figsize=(12, 6))
plt.plot(D_loss, label="判别器", color="tomato")
plt.plot(G_loss, label="生成器", color="orange")
plt.xlabel("epoch")
plt.ylabel("loss")
plt.title("生成器和判别器的损失曲线图")
plt.legend()
plt.grid()
plt.savefig("C:\\Users\\Administrator\\PycharmProjects\\CNN\\gen_dis_loss_11.jpg", dpi=300, bbox_inches="tight")
plt.close()