
「【新智元导读】提示词才是 AI 隐藏的王牌!马里兰 MIT 等顶尖机构研究证明,一半提示词,是让 AI 性能飙升 49% 的关键。」
AI 性能的提升,一半靠模型,一半靠提示词。

最近,来自马里兰大学、MIT、斯坦福等机构联手验证,模型升级带来的性能提升仅占 50%,而另外一半的提升,在于用户提示词的优化。
他们将其称之为「提示词适应」(prompt adaptation)。

为此,他们让 DALL-E 2 和 DALL-E 3 来了一场 PK,1,893 名「选手」在 10 次尝试中,用随机分配三种模型之一复现目标图像。
令人惊讶的是,DALL-E 3 图像相似度显著优于 DALL-E 2。
其中,模型升级本身仅贡献了 51% 的性能,剩余的 49% 全靠受试者优化的提示词。
关键是,那些没有技术背景的人,也能通过提示词,让 DALL-E 3 模型生成更好的图片。

OpenAI 总裁 Greg Brockman 也同样认为,「要充分发挥模型的潜力,确实需要一些特殊的技巧」。
他建议开发者们去做「Prompt 库」管理,不断探索模型的边界。

换言之,你的提示词水平,决定了 AI 能不能从「青铜」变成「王者」。

「别等 GPT-6 了!」
「不如「调教」提示词」
GenAI 的有效性不仅取决于技术本身,更取决于能否设计出高质量的输入指令。
2023 年,ChatGPT 爆红之后,全世界曾掀起一股「提示词工程」的热潮。
尽管全新的「上下文工程」成为今年的热点,但「提示词工程」至今依旧炙手可热。

然而共识之下,提示词设计作为一种动态实践仍缺乏深入研究。
多数提示词库和教程,将有效提示视为「可复用成品」,但却用到新模板中可能会失效。
这就带来了一些现实的问题:提示策略能否跨模型版本迁移?还是必须持续调整以适应模型行为变化?
为此,研究团队提出了「提示词适应」这一可测量的行为机制,用以解释用户输入如何随技术进步而演进。
他们将其概念化为一种「动态互补能力」,并认为这种能力对充分释放大模型的经济价值至关重要。
为评估提示词适应对模型性能的影响,团队采用了 Prolific 平台一项预注册在线实验数据,共邀请了 1,893 名参与者。
每位受试者被随机分配三种不同性能的模型:DALL-E 2、DALL-E 3,或自动提示优化的 DALL-E 3。

除模型分配外,每位参与者还独立分配到 15 张目标图像中的一张。这些图像选自商业营销、平面设计和建筑摄影三大类别。
实验明确告知参与者模型无记忆功能------每个新提示词均独立处理,不继承先前尝试的信息。
每人需要提交至少 10 条提示词,需通过模型尽可能复现目标图像,最优表现者将获得高额奖金。
任务结束后参与者需填写涵盖年龄、性别、教育程度、职业及创意写作 / 编程 / 生成式 AI 自评能力的人口统计调查。
「 」
」
「随机分配,10 次生成」
实验的核心结果指标,是参与者生成的每张图像与指定目标图像之间的相似度。
这项指标通过 CLIP 嵌入向量的余弦相似度进行量化。
由于生成模型的输出具有随机性,同一提示词在不同尝试中可能产生不同的图像。
为控制这种变异性,研究人员为每个提示词生成 10 张图像,并分别计算它们与目标图像的余弦相似度,随后取这 10 个相似度得分的平均值作为该提示词的预期质量分数。
「」
「回放分析:是模型,还是提示词?」
实验的另一个核心目标在于,厘清图像复现性能的提升中,有多少源于更强大的模型,又有多少来自提示词的优化?
根据概念框架的表述,当模型从能力水平θ1 升级至更高水平θ2 时,其输出质量的总改进可表示为:
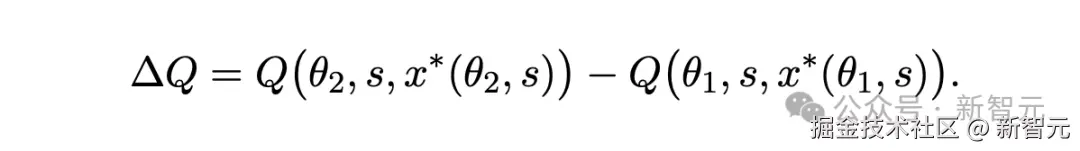
研究人员将这一变化分解为两部分:
- 模型效应:将相同提示词应用于更优模型时,获得的性能提升;
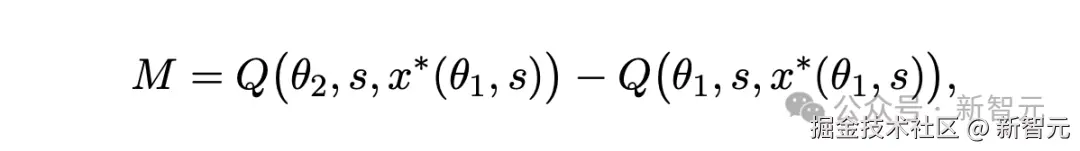
- 提示词效应:通过调整提示词以充分发挥更强大模型优势所带来的额外改进。
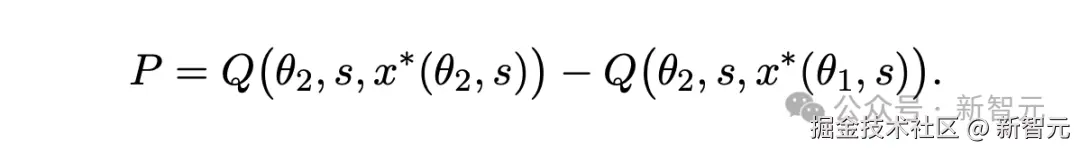
为实证评估这两个组成部分,研究人员对 DALL-E 2 和 DALL-E 3(原词版)实验组参与者的提示词进行了额外分析。
具体方法是将实验过程中参与者提交的原始提示词,重新提交至其原分配模型和另一模型,并分别生成新图像。
「· 分离模型效应」
针对 DALL-E 2 参与者编写的提示词(x*(θ1,s)),团队同时在 DALL-E 2 和 DALL-E 3 模型上进行评估,分别获得 Qθ1s,x\*(θ1,s) 和 Qθ2,s,x\*(θ_1,s) 的实测值。
这一对比可分离出模型效应:即在固定提示词情况下,仅通过升级模型获得的输出质量提升。
「· 比较提示效应」
为了评估提示词效应,作者还比较了以下两组数据:
- 在 DALL-E 3 上回放 DALL-E 2 提示词的质量(即 Qθ2,s,x\*(θ1,s) 估计值)
- DALL-E 3 的参与者专门为模型编写的提示词在相同模型上的质量(即 Qθ2,s,x\*(θ2,s) 估计值)
这一差异恰恰能反映,用户通过调整提示词,模型本身得到的额外改进。
那么,这项实验的具体结果如何?
「DALL-E 3 强大的生图能力」
「提示词解锁了一半」
实验中,研究团队主要探讨了三大问题:
(i) 接入更强大的模型(DALL-E 3)是否能提升用户表现;
(ii) 用户在使用更强模型时如何改写或优化他们的提示词;
(iii) 整体性能提升中有多少应归因于模型改进,多少应归因于提示词的适应性调整。
「」
「模型升级,是核心」
首先,团队验证了使用 DALL-E 3 的参与者,是否比使用 DALL-E 2 的参与者表现更优?
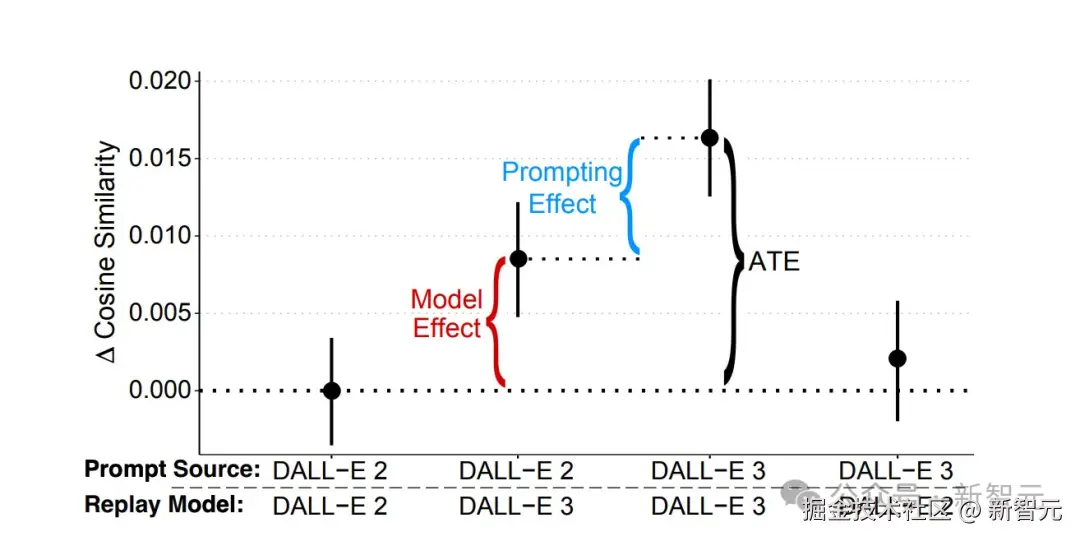
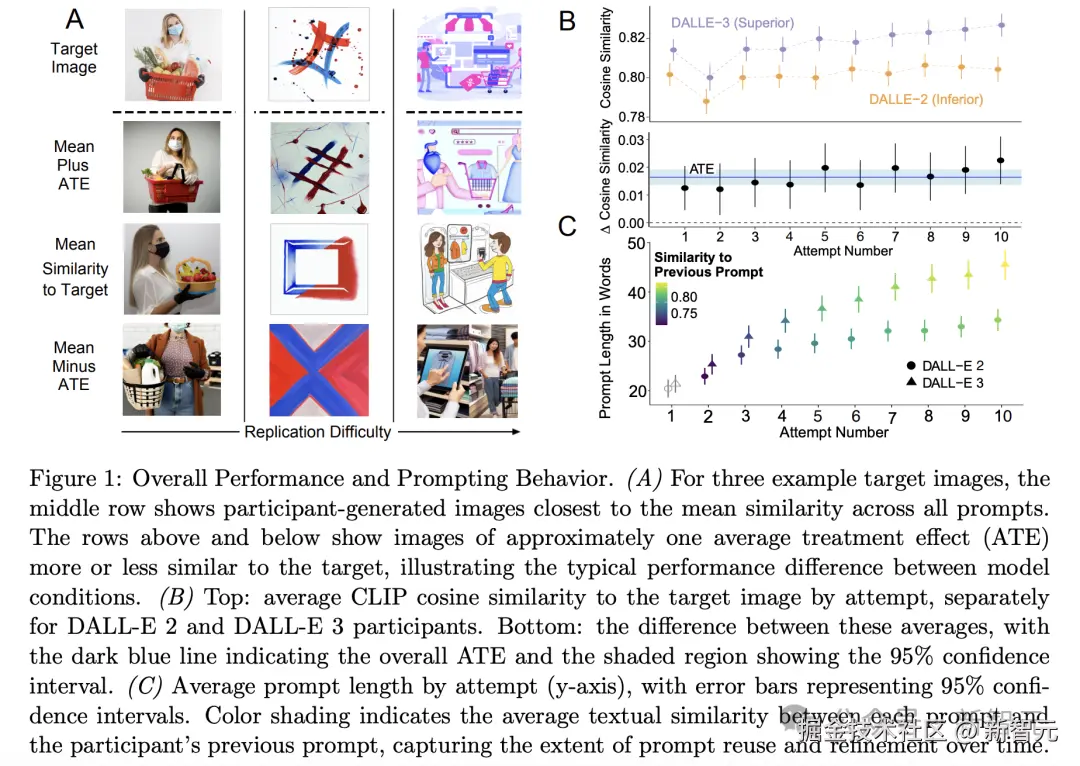
如下图 1 所示,汇总了所有发现。
A 展示了三组代表性目标图像,每组都包含了从两种模型中抽取的三张图像。
中间行是,目标图像余弦相似度最接近全体参与者平均值的生成结果,上行(下行)则呈现比均值相似度高(低)约一个平均处理效应(ATE)的图像。
在 10 次必要提示尝试中,使用 DALL-E 3 的参与者生成图像与目标图像的余弦相似度平均高出 0.0164。
这个提升相当于 0.19 个标准差,如下图 1 B 所示。
而且,这种优势在 10 次尝试中持续存在,因此不可否认,模型升级一定会比前代有着显著的性能提升。
而且,参与者的动态提示行为在两种模型间也存在显著差异:
图 C 表明,DALL-E 3 使用者的提示文本平均比 DALL-E 2 组长 24%,且该差距随尝试次数逐渐扩大。
他们更倾向于复用或优化先前提示,这表明当发现模型能处理复杂指令后,他们会采取更具开发性的策略。
此外词性分析证实,增加的词汇量提供的是实质性描述信息而非冗余内容:
名词和形容词(最具描述性的两类词性)占比在两种模型间基本一致(DALL-E 3 组 48% vs DALL-E 2 组 49%,p = 0.215)。
这说明了,提示文本的延长反映的是------语义信息的丰富化,而非无意义的冗长。
「」
「模型 51%,提示词 49%」
研究人员观察到提示行为的差异表明,用户会主动适应所分配模型的能力。
DALL-E 3 使用者的整体性能提升中,有多少源自模型技术能力的增强,又有多少归因于用户针对该能力重写提示?
为解答这一问题,研究人员采用前文所述的回放(replay)分析法,以实证分离这两种效应。
「模型效应」
将 DALL-E 2 参与者编写的原始提示,分别在 DALL-E 2 和 DALL-E 3 上评估性能。
结果显示,相同提示在 DALL-E 3 上运行时余弦相似度提升 0.0084(p<10^-8),占两组总性能差异的 51%。
「提示效应」
将 DALL-E 2 参与者的原始提示与 DALL-E 3 参与者编写的提示(均在 DALL-E 3 上评估)进行对比。
结果显示,该效应贡献了剩余 48% 的改进,对应余弦相似度提升 0.0079(p=0.024)。
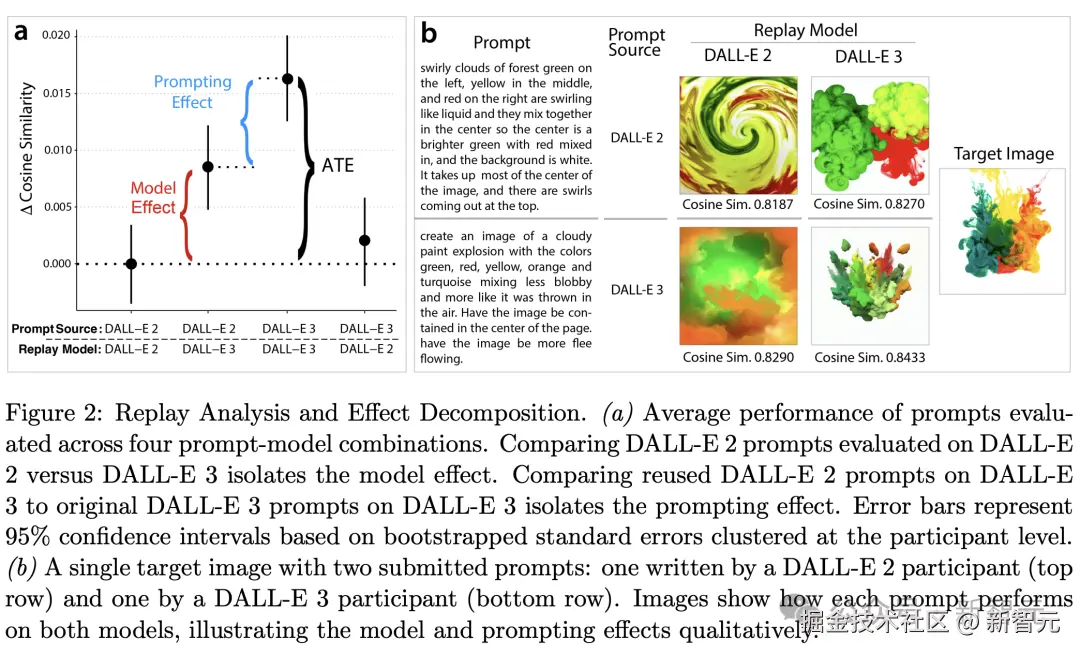
「总处理效应」
总处理效应为 0.0164,关键的是,当 DALL-E 3 用户编写的提示应用于 DALL-E 2 时,性能较原始 DALL-E 2 提示无显著提升(Δ=0.0020;p=0.56)。
这种不对称性,印证了提示优化的效果依赖于模型执行复杂指令的能力边界。
图 2 B 通过单一目标图像直观呈现这些效应:
- 上行展示 DALL-E 2 参与者的原始提示,在 DALL-E 3 上生成更高保真度的图像,证明固定提示下模型升级的效果;
- 下行显示 DALL-E 3 参与者的提示在 DALL-E 2 上输出质量显著下降,凸显当模型能力不足时,提示优化的效果存在天花板。
这些发现研究人员的理论主张,提供了实证支持:
提示优化是一种动态互补策略------用户根据模型能力提升而主动调整行为,且这种调整对实际性能增益的贡献不可忽视。
「」
「技能异质性」
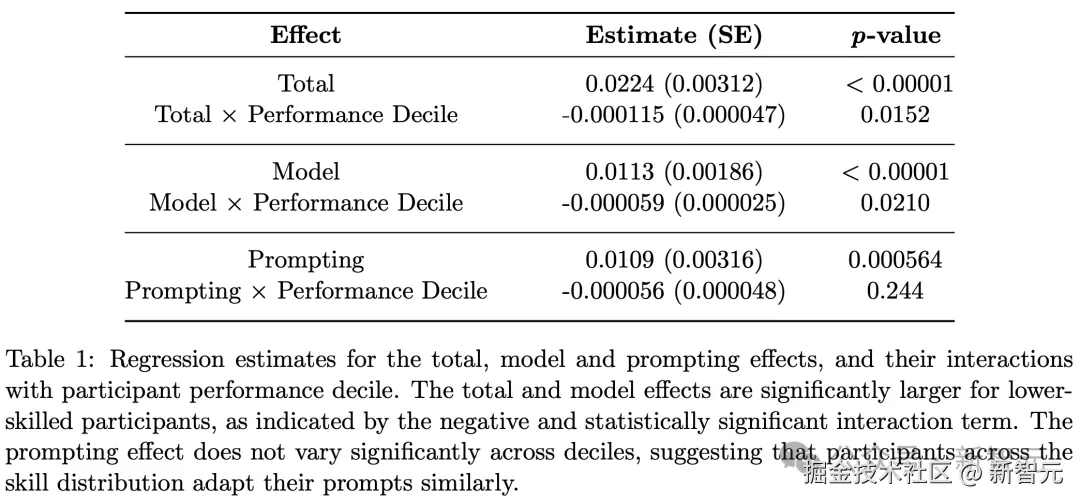
如下表 1 呈现了「回归分析结果」,测试了模型效应、提示词效应以及总效应是否会在不同技能水平的参与者之间系统性地变化。
主要发现如下:
- 总效应与表现十分位数的交互项呈负相关且统计显著(−0.000115,p = 0.0152)。
这表明模型改进缩小了高、低绩效用户之间的整体差距,这与概念框架中的命题 1 一致。
- 模型效应与表现十分位数的交互项,同样呈负相关且统计显著(−0.000059,p=0.0210)。
这说明模型升级主要惠及低技能用户。这与命题 2 的理论预测相符,因为接近性能上限的高技能用户存在收益递减效应。
- 并没有发现提示词适应的效益,在技能分布上存在显著差异(−0.000056,p=0.2444)。
此外,研究团队还评估了自动化提示词的效果。
结果发现,GPT-4 经常添加无关细节或微妙改变参与者的原意,导致模型输出质量下降 58%。
用简单的话来说,AI 写的提示词曲解了意图,不如用户精心编制的提示词。
对此,Outbox.ai 的创始人 Connor Davis 给出了建议,不要去过度自动化提示词,人还应该在其中发挥主动性。

「作者介绍」
Eaman Jahani

Eaman Jahani 是马里兰大学商学院信息系统专业的助理教授。
他曾在 UC 伯克利统计系担任博士后研究员,还获得了 MIT 的社会工程系统与统计学双博士学位。
Benjamin S. Manning

Benjamin S. Manning 目前是 MIT 斯隆管理学院 IT 组的四年级博士生。他曾获得 MIT 硕士学位和华盛顿大学学士学位。
他的研究围绕两个相辅相成的方向:(1) 利用 AI 系统进行社会科学发现;(2) 探索 AI 系统如何代表人类并按照人类指令行事。
Joe Zhang

Joe Zhang 目前是斯坦福大学博士生,此前,曾获得了普林斯顿大学的学士学位。
个人的研究喜欢从人机交互到社会科学等多个学术领域汲取灵感,试图理解新兴的人机协作系统及其对商业和社会的影响。
参考资料: