数学知识补充:矩阵


总结来说:
Am*k X Bk*n = Cm*n ----至于乘法的规则,是数学问题, 知道可以乘即可,不需要我们自己计算
反过来
Cm*n = Am*k X Bk*n ----至于矩阵如何拆分/如何分解,是数学问题,知道可以拆/可以分解即可
ALS 推荐算法案例:电影推荐
需求:
大数据分析师决定使用SparkMLlib的ALS(Alternating Least Squarcs)推荐算法,采用这种方式可以解决稀疏矩阵(SparseMatrix)的问题。即使是大量的用户与产品,都能够在合理的时间内完成运算。在使用历史数据训练后,就可以创建模型。
有了模型之后,就可以使用模型进行推荐。我们设计了如下推荐功能,可以增加会员观看电影的次数:
针对用户推荐感兴趣的电影: 以针对每一位会员,定期发送短信或E-mail或会员登录时,推荐给他/她可能会感兴趣的电影。
针对电影推荐给感兴趣的用户:当想要促销某些电影时,也可以找出可能会对这些电影感兴趣的会员,并且发送短信或E-mail.
数据引入:
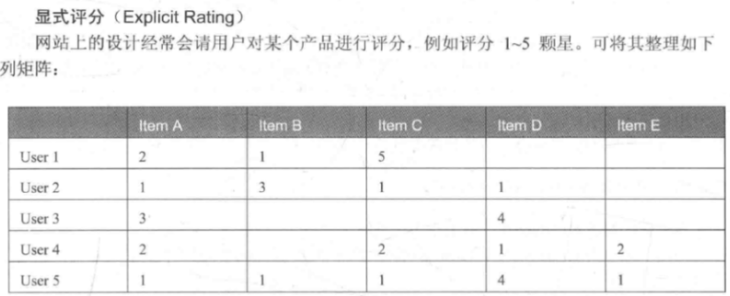
第一种:显示评分数据
现在我们手里有用户对电影,那么接下来就可以使用SparkMLlib中提供的一个基于隐语义模型的协同过滤推荐算法-ALS
第二种:隐式评分(Implicit rating)
有时在网站的设计上,并不会请用户对某个产品进行评分,但是会记录用户是否点选了某个产品。如果点选了某个产品,代表该用户可能对该产品感兴趣,但是我们不知道评分为几颗星,这种方式称为隐式评分;1代表用户对该项产品有兴趣。

具体做法

将该评分矩阵进行拆解如下:

然后进行计算填充:
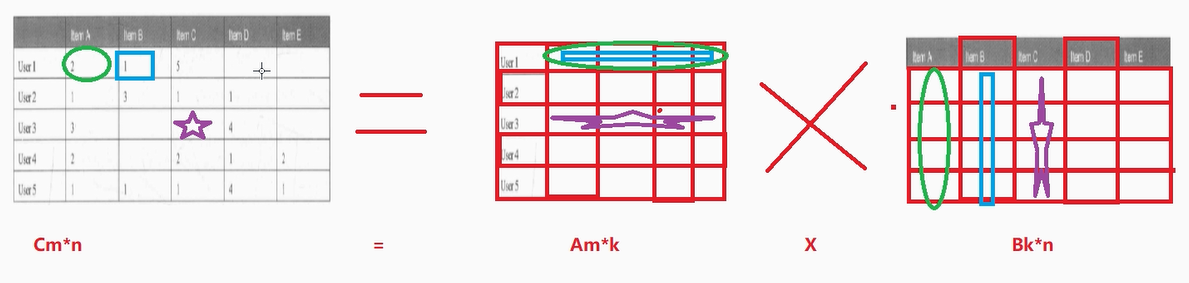
上面已经可以将空白处进行补全了,但是问题是:凭什么补全的数字就能够代表用户对电影的预测评分?
SparkMlLib中的ALS算法:基于隐语义模型的协同过滤算法,认为:
拆分出来的
A矩阵是用户的隐藏的特征矩阵,
B矩阵是物品的隐藏的特征矩阵,
用户之所以会给物品打出相应的评分,是因为用户和物品具有这些隐藏的特征。
代码编写:
import org.apache.spark.SparkContext
import org.apache.spark.ml.recommendation.{ALS, ALSModel}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object ALSMovieDemoTest {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val spark: SparkSession = SparkSession.builder().appName("BatchAnalysis").master("local[*]")
.config("spark.sql.shuffle.partitions", "4")//本次测试时将分区数设置小一点,实际开发中可以根据集群规模调整大小,默认200
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
import spark.implicits._
import org.apache.spark.sql.functions._
//TODO 1.加载数据并处理
val fileDS: Dataset[String] = spark.read.textFile("data/input/u.data")
val ratingDF: DataFrame = fileDS.map(line => {
val arr: Array[String] = line.split("\t")
(arr(0).toInt, arr(1).toInt, arr(2).toDouble)
}).toDF("userId", "movieId", "score")
val Array(trainSet,testSet) = ratingDF.randomSplit(Array(0.8,0.2))//按照8:2划分训练集和测试集
//TODO 2.构建ALS推荐算法模型并训练
val als: ALS = new ALS()
.setUserCol("userId") //设置用户id是哪一列
.setItemCol("movieId") //设置产品id是哪一列
.setRatingCol("score") //设置评分列
.setRank(10) //可以理解为Cm*n = Am*k X Bk*n 里面的k的值
.setMaxIter(10) //最大迭代次数
.setAlpha(1.0)//迭代步长
//使用训练集训练模型
val model: ALSModel = als.fit(trainSet)
//使用测试集测试模型
//val testResult: DataFrame = model.recommendForUserSubset(testSet,5)
//计算模型误差--模型评估
//......
//TODO 3.给用户做推荐
val result1: DataFrame = model.recommendForAllUsers(5)//给所有用户推荐5部电影
val result2: DataFrame = model.recommendForAllItems(5)//给所有电影推荐5个用户
val result3: DataFrame = model.recommendForUserSubset(sc.makeRDD(Array(196)).toDF("userId"),5)//给指定用户推荐5部电影
val result4: DataFrame = model.recommendForItemSubset(sc.makeRDD(Array(242)).toDF("movieId"),5)//给指定电影推荐5个用户
result1.show(false)
result2.show(false)
result3.show(false)
result4.show(false)
}
}如果 使用 python 语言编写需求:
import os
from pyspark.sql import SparkSession
from pyspark.ml.recommendation import ALS
from pyspark.sql.functions import col
# TODO 0. 准备环境
# 配置环境
if __name__ == '__main__':
os.environ['JAVA_HOME'] = 'C:/Program Files/Java/jdk1.8.0_241'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.1'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe' # 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe'
os.environ['HADOOP_USER_NAME'] = 'root'
os.environ['file.encoding'] = 'UTF-8'
# 准备环境
spark = SparkSession.builder.appName("StreamingAnalysis")\
.master("local[*]").config("spark.sql.shuffle.partitions","4").getOrCreate()
sc = spark.sparkContext
sc.setLogLevel("WARN")
# TODO 1. 加载数据并处理
fileDS = spark.read.text("data/input/u.data")
fileDS.printSchema()
print(fileDS.take(5))
ratingDF = fileDS.rdd.map(lambda row: row.value.split("\t")) \
.map(lambda x: (int(x[0]), int(x[1]), float(x[2]))) \
.toDF(["userId", "movieId", "score"])
train_set, test_set = ratingDF.randomSplit([0.8, 0.2]) # 按照8:2划分训练集和测试集
# TODO 2. 构建ALS推荐算法模型并训练
als = ALS(userCol="userId",
itemCol="movieId",
ratingCol="score",
rank=10,
maxIter=10,
alpha=1.0)
# 使用训练集训练模型
model = als.fit(train_set)
# 使用测试集测试模型
# test_result = model.recommendForUserSubset(test_set, 5)
# 计算模型误差--模型评估
# ...
# TODO 3. 给用户做推荐
result1 = model.recommendForAllUsers(5) # 给所有用户推荐5部电影
result2 = model.recommendForAllItems(5) # 给所有电影推荐5个用户
result3 = model.recommendForUserSubset(spark.createDataFrame([(196,)], ["userId"]), 5) # 给指定用户推荐5部电影
result4 = model.recommendForItemSubset(spark.createDataFrame([(242,)], ["movieId"]), 5) # 给指定电影推荐5个用户
result1.show(truncate=False)
result2.show(truncate=False)
result3.show(truncate=False)
result4.show(truncate=False)
# 关闭Spark会话
spark.stop()最终结果如下所示:
root
|-- value: string (nullable = true)
[Row(value='196\t242\t3\t881250949'), Row(value='186\t302\t3\t891717742'), Row(value='22\t377\t1\t878887116'), Row(value='244\t51\t2\t880606923'), Row(value='166\t346\t1\t886397596')]
+------+---------------------------------------------------------------------------------------------+
|userId|recommendations |
+------+---------------------------------------------------------------------------------------------+
|12 |[{1643, 5.44792}, {1463, 5.249074}, {1450, 5.1887774}, {64, 5.0688186}, {318, 5.0383205}] |
|13 |[{1643, 4.8755937}, {814, 4.873669}, {963, 4.7418056}, {867, 4.725667}, {1463, 4.6931405}] |
|14 |[{1463, 5.1732297}, {1643, 5.1153564}, {1589, 5.0040984}, {1367, 4.984417}, {1524, 4.955745}]|
|18 |[{1643, 5.213776}, {1463, 5.1320825}, {1398, 4.819699}, {483, 4.6260805}, {1449, 4.6111727}] |
|25 |[{1643, 5.449965}, {1589, 5.017608}, {1463, 4.9372115}, {169, 4.6056967}, {963, 4.5825796}] |
|37 |[{1643, 5.3220835}, {1589, 4.695943}, {1268, 4.610497}, {42, 4.4597883}, {169, 4.4325438}] |
|38 |[{143, 5.9212527}, {1472, 5.595081}, {1075, 5.4555163}, {817, 5.4316535}, {1463, 5.2957745}] |
|46 |[{1643, 5.9912925}, {1589, 5.490053}, {320, 5.175288}, {958, 5.080977}, {1131, 5.067922}] |
|50 |[{838, 4.6296134}, {324, 4.6239386}, {962, 4.567323}, {987, 4.5356846}, {1386, 4.5315967}] |
|52 |[{1643, 5.800831}, {1589, 5.676579}, {1463, 5.6091275}, {1449, 5.2481527}, {1398, 5.164145}] |
|56 |[{1643, 5.2523932}, {1463, 4.8217216}, {174, 4.561838}, {50, 4.5330524}, {313, 4.5247965}] |
|65 |[{1643, 5.009448}, {1463, 4.977561}, {1450, 4.7058015}, {496, 4.6496506}, {318, 4.6017523}] |
|67 |[{1589, 6.091304}, {1643, 5.8771777}, {1268, 5.4765506}, {169, 5.2630634}, {645, 5.1223965}] |
|70 |[{1643, 4.903953}, {1463, 4.805949}, {318, 4.3851447}, {50, 4.3817987}, {64, 4.3547297}] |
|73 |[{1643, 4.8607855}, {1449, 4.804972}, {1589, 4.7613616}, {1463, 4.690458}, {853, 4.6646543}] |
|83 |[{1643, 4.6920056}, {1463, 4.6447496}, {22, 4.567131}, {1278, 4.505245}, {1450, 4.4618435}] |
|93 |[{1643, 5.4505115}, {1463, 5.016514}, {1160, 4.83699}, {1131, 4.673481}, {904, 4.6326823}] |
|95 |[{1643, 4.828537}, {1463, 4.8062463}, {318, 4.390673}, {64, 4.388152}, {1064, 4.354666}] |
|97 |[{1589, 5.1252556}, {963, 5.0905123}, {1643, 5.014373}, {793, 4.8556504}, {169, 4.851328}] |
|101 |[{1643, 4.410446}, {1463, 4.167996}, {313, 4.1381097}, {64, 3.9999022}, {174, 3.9533536}] |
+------+---------------------------------------------------------------------------------------------+
only showing top 20 rows
+-------+------------------------------------------------------------------------------------------+
|movieId|recommendations |
+-------+------------------------------------------------------------------------------------------+
|12 |[{118, 5.425505}, {808, 5.324106}, {628, 5.2948637}, {173, 5.2587204}, {923, 5.2580886}] |
|13 |[{928, 4.5580163}, {808, 4.484994}, {239, 4.4301133}, {9, 4.3891873}, {157, 4.256134}] |
|14 |[{928, 4.7927723}, {686, 4.784753}, {240, 4.771472}, {252, 4.7258406}, {310, 4.719638}] |
|18 |[{366, 3.5298047}, {270, 3.5042968}, {118, 3.501615}, {115, 3.4122925}, {923, 3.407579}] |
|25 |[{732, 4.878368}, {928, 4.8120456}, {688, 4.765749}, {270, 4.7419496}, {811, 4.572586}] |
|37 |[{219, 3.8507814}, {696, 3.5646195}, {366, 3.4811506}, {75, 3.374816}, {677, 3.3565707}] |
|38 |[{507, 4.79451}, {127, 4.5993023}, {137, 4.4605145}, {849, 4.3109775}, {688, 4.298151}] |
|46 |[{270, 4.6816626}, {928, 4.5854187}, {219, 4.4919205}, {34, 4.4880714}, {338, 4.484614}] |
|50 |[{357, 5.366201}, {640, 5.2883763}, {287, 5.244199}, {118, 5.222288}, {507, 5.2122903}] |
|52 |[{440, 4.7918897}, {565, 4.592798}, {252, 4.5657616}, {697, 4.5496006}, {4, 4.52615}] |
|56 |[{628, 5.473441}, {808, 5.3515406}, {252, 5.2790856}, {4, 5.197684}, {118, 5.146353}] |
|65 |[{770, 4.4615817}, {242, 4.3993964}, {711, 4.3992624}, {928, 4.3836145}, {523, 4.365783}] |
|67 |[{887, 4.6947756}, {511, 4.151247}, {324, 4.1026692}, {849, 4.0851464}, {688, 4.0792685}] |
|70 |[{928, 4.661159}, {688, 4.5623326}, {939, 4.527151}, {507, 4.5014353}, {810, 4.4822607}] |
|73 |[{507, 4.8688984}, {688, 4.810653}, {849, 4.727747}, {810, 4.6686435}, {127, 4.6246667}] |
|83 |[{939, 5.135272}, {357, 5.12999}, {523, 5.071391}, {688, 5.034591}, {477, 4.9770975}] |
|93 |[{115, 4.5568433}, {581, 4.5472555}, {809, 4.5035434}, {819, 4.477037}, {118, 4.467347}] |
|95 |[{507, 5.097106}, {688, 4.974432}, {810, 4.950163}, {849, 4.9388885}, {152, 4.897256}] |
|97 |[{688, 5.1705074}, {628, 5.0447206}, {928, 4.9556565}, {810, 4.8580494}, {849, 4.8418307}]|
|101 |[{495, 4.624121}, {67, 4.5662155}, {550, 4.5428996}, {472, 4.47312}, {347, 4.4586687}] |
+-------+------------------------------------------------------------------------------------------+
only showing top 20 rows
+------+------------------------------------------------------------------------------------------+
|userId|recommendations |
+------+------------------------------------------------------------------------------------------+
|196 |[{1463, 5.5212154}, {1643, 5.4587097}, {318, 4.763221}, {50, 4.7338095}, {1449, 4.710921}]|
+------+------------------------------------------------------------------------------------------+
+-------+-----------------------------------------------------------------------------------------+
|movieId|recommendations |
+-------+-----------------------------------------------------------------------------------------+
|242 |[{928, 5.2815547}, {240, 4.958071}, {147, 4.9559183}, {909, 4.7904325}, {252, 4.7793174}]|
+-------+-----------------------------------------------------------------------------------------+
Process finished with exit code 0