聊聊电商系统架构演进
具体以电子商务网站为例, 展示web应用的架构演变过程。
1.0时代
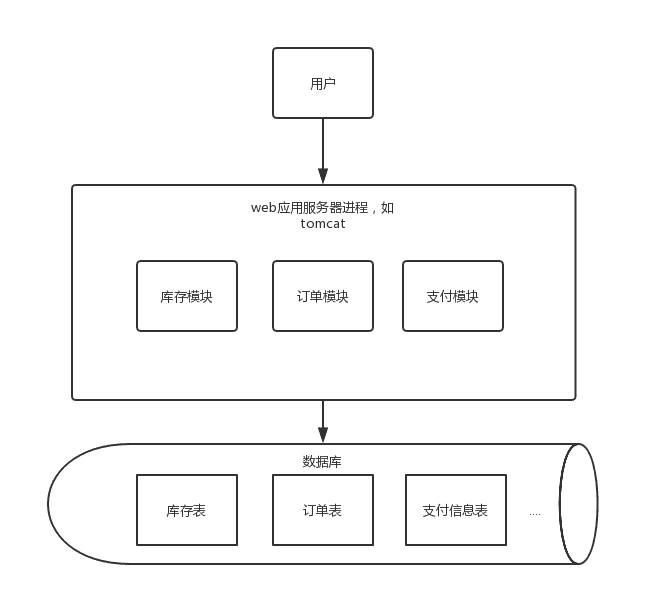
这个时候是一个web项目里包含了所有的模块,一个数据库里包含了所需要的所有表,这时候网站访问量增加时,首先遇到瓶颈的是应用服务器连接数,比如tomcat连接数不能无限增加,线程数上限受进程内存大小、CPU内核数等因素影响,当线程数到达一定数时候,线程上下文的切换对性能的损耗会越来越严重,响应会变慢,通过增加web应用服务器方式的横向扩展对架构影响最小,这时候架构会变成下面这样:
2.0时代
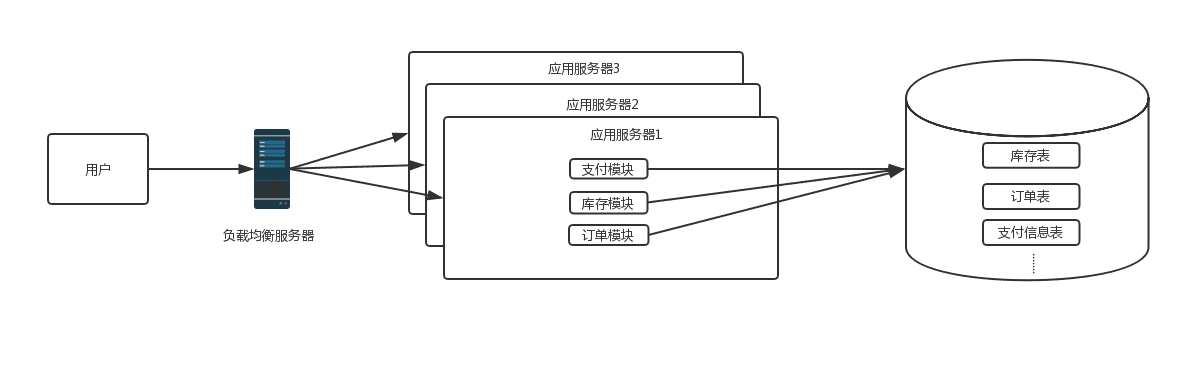
这时候随着网站访问量继续增加,继续增加应用服务器数量后发现数据库成了瓶颈,而数据库的最主要的瓶颈体现在两方面:
- 数据库的最大连接数是有限的,比如当前数据库的连接数设置8000,如果每个应用服务器与数据库的初始连接数设置40,那么200台web服务器是极限, 并且连接数太多后,数据库的读写压力增大,耗时增加
- 当单表数量过大时,对该表的操作耗时会增加,索引优化也是缓兵之计
这时,根据业务特点,如果读写比差距不大,并且对数据一致性要求不是很高的情况下,数据库可以采用主从方式进行读写分离的方案,并且引入缓存机制来抗读流量。如果读写比差距很大或者对数据一致性要求高时,就不适合用读写分离方案,需要考虑业务的垂直拆分,这时期的系统架构图如下:
3.0时代
3.1 读写分离

这时候仍然是垂直架构,所有业务集中在一个项目里。项目维护、快速迭代问题会越来越严重,单个模块的开发都需要发布整个项目,项目稳定性也受到很大挑战,这是需要考虑业务的垂直拆分,需要将一些大的模块单独拆出来,这时候的架构图如下:
4.0 业务垂直拆分
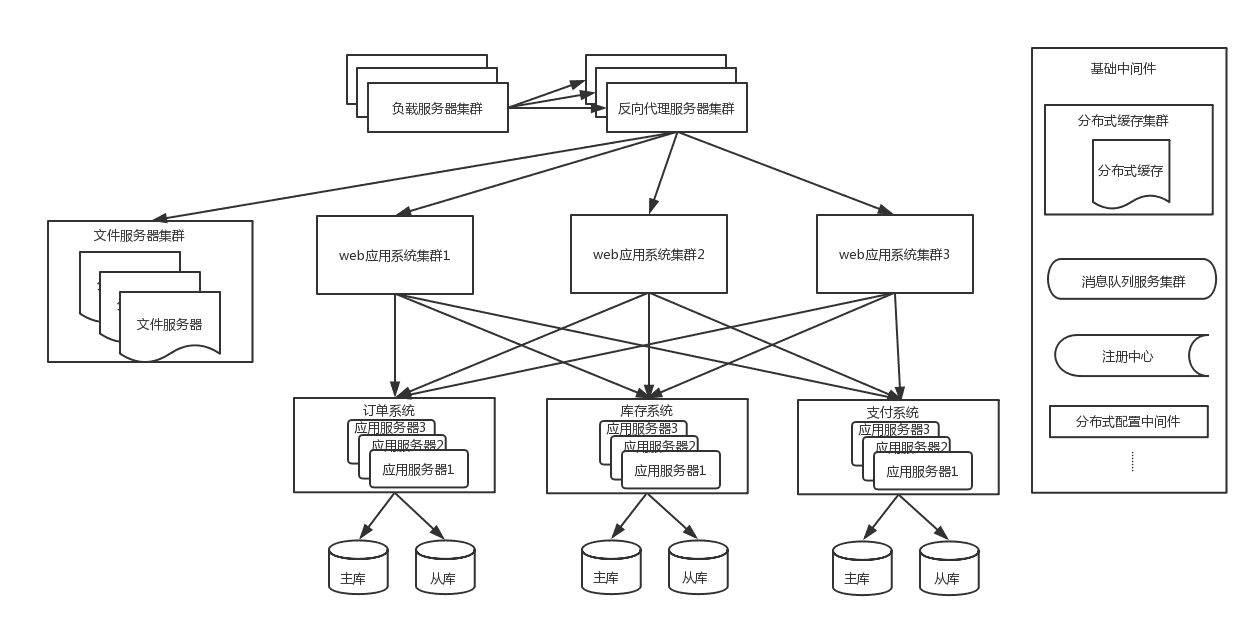
这时候为了进一步提升用户体验,加速用户的网站访问速度,会使用CDN来缓存信息,用户会访问最近的CDN节点来提升访问速度。此时的架构图如下:
4.1 使用CDN来缓存信息

随着业务量增大,一些核心系统数据库单表数量达到几千万甚至亿级,这时候对该表的数据操作效率会大大降低,并且虽然有缓存来抗读的压力,但是对于大量的写操作和一些缓存miss的流量到达一定量时,单库的负荷也会到达极限,这时候需要将表拆分,一般直接采用分库分表,因为只做分表的话,单个库的连接瓶颈仍然无法解决。分库分表后的架构如下:
4.2分库分表架构
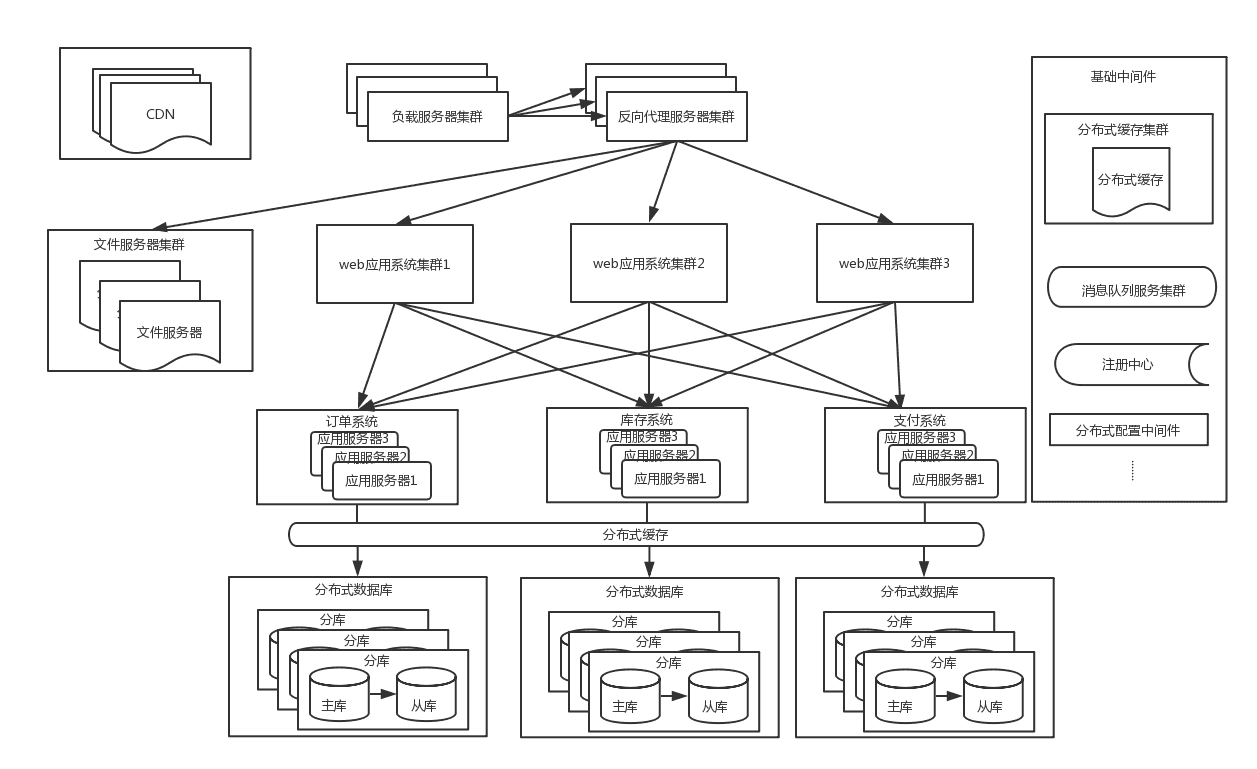
随着流量的进一步增大,这时候系统仍然会有瓶颈出现,以订单系统为例: 单个机房的机器是有限的,不能一直新增下去,并且基于容灾的考虑,一般采用同城双机房的方式,机房之间用专线链接,同城跨机房质检的延时在几毫秒,此时的架构图如下:
4.3 同城双机房
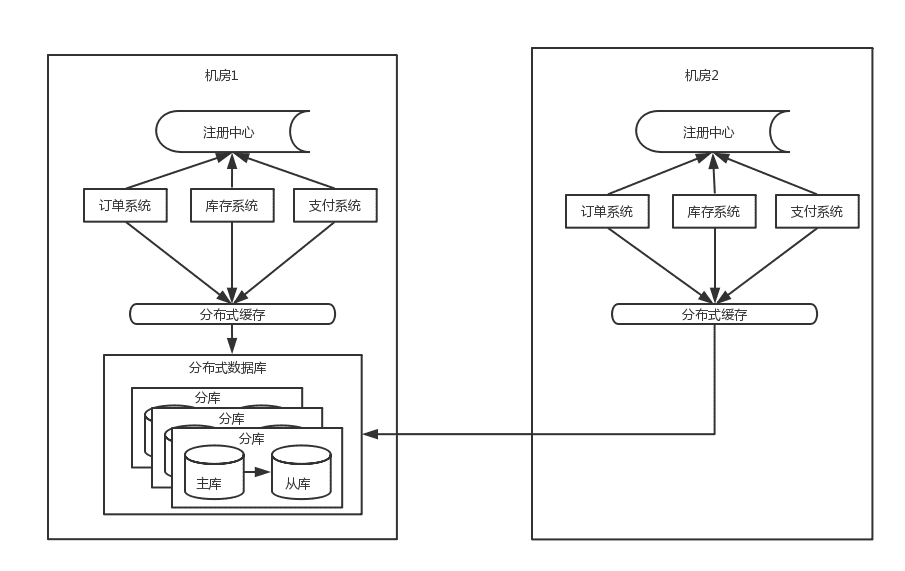
由于数据库主库只能是在一个机房,所以仍然会有一半的数据库访问是跨机房的,虽然延时只有几毫秒,但是一个调用链里的数据库访问太多后,这个延时也会积少成多。其次这个架构还是没能解决数据库连接数瓶颈问题
- 随着应用服务器的增加,虽然是分库分表,但每增加一台应用服务器,都会与每个分库建立连接,比如数据库连接池默认连接数是40,而如果mysql数据库的最大连接数是8000的话,那么200台应用服务器就是极限。
- 当应用的量级太大后,单个城市的机器、电、带宽等资源无法满足业务的持续增长。这时就需要考虑SET化架构,也就是单元化架构,大体思路就是将一些核心系统拆成多个中心,每个中心成为一个单元,流量会按照一定的规则分配给每个单元,这样每个单元只负责处理自己的流量就可以了。每个单元要尽量自包含、高内聚。这是从整体层面将流量分而治之的思路。这是单元化后的机构简图如下:
5.0 单元化
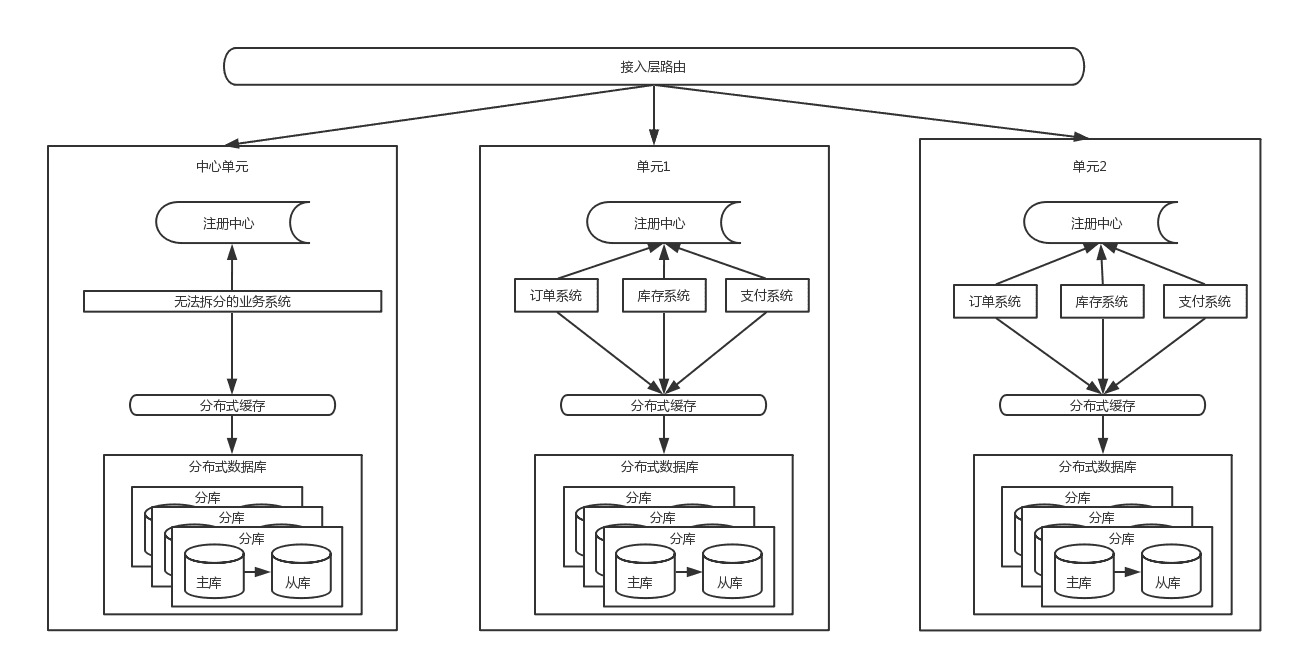
从上面的架构图里能看到,流量从接入层按照路由规则(比如以用户ID来路由)路由到不同单元,每个单元内都是高内聚,包含了核心系统,数据层面的分片逻辑是与接入层路有逻辑一致,也解决了数据库连接的瓶颈问题,但是一些跨单元的调用是无法避免的,同时也有些无法拆分的业务需要放在中心单元,供所有其他单元调用。
参考文章
- 文章主要参考自 李智慧的 《大型网站技术架构》
- https://blog.csdn.net/caoyuanyenang/article/details/86943397
- https://www.cnblogs.com/lfs2640666960/p/9021205.html
- http://www.hollischuang.com/archives/728 本文由博客一文多发平台 OpenWrite 发布!