一、前言
上一篇文章我们学习了ES的基本操作和数据类型,接下来就是ES中比较重要的查询操作了,ES的出现就是为了解决搜索问题,正如他的标语 You Know For Search。当然搜索是一个很复杂的功能,我们也是循序渐进的学习,一开始会是一些比较简单的案例。
二、数据准备
1、创建索引
PUT /hotel
{
"mappings": {
"properties": {
"title":{
"type": "text"
},
"city":{
"type": "keyword"
},
"price":{
"type": "double"
},
"create_time":{
"type": "date",
"format": "yyyy-MM-dd HH:mm:ss"
},
"amenities":{
"type": "text"
},
"full_room":{
"type": "boolean"
},
"location":{
"type": "geo_point"
},
"praise":{
"type": "integer"
}
}
}说明:我们创建了一个索引,有以下几个字段
|-------------|-----------|-----------|
| 字段 | 类型 | 含义 |
| title | text | 标题 |
| city | keyword | 所在城市 |
| price | double | 价格 |
| create_time | date | 创建时间 |
| amenities | text | 便利设施 |
| full_room | boolean | 是否满房 |
| location | gen_point | 地理位置(经纬度) |
| praise | integer | 好评数量 |
2、写入数据,这里我们使用批量写入数据,使用bulk
POST /_bulk
{"index":{"_index":"hotel","_id":"001"}}
{"title":"文雅酒店","city":"青岛","price":556.00,"create_time":"2020-04-18 12:00:00","amenities":"浴池,普通停车场/充电停车场","full_room":false,"location":{"lat":36.083078,"lon":120.37566},"praise":10}
{"index":{"_index":"hotel","_id":"002"}}
{"title":"金都嘉怡假日酒店","city":"北京","price":337.00,"create_time":"2021-03015 20:00:00","amenities":"wifi,充电停车场/可升降停车场","full_room":false,"location":{"lat":39.915153,"lon":116.4030},"praise":60}
{"index":{"_index":"hotel","_id":"003"}}
{"itle":"金都欣欣酒店","city":"天津","price":200.00,"create_ime":"2021-05-09 16:00:00","amenities":"提供假日party,免费早餐,可充电停车场","full_room":true,"location":{"lat":39.186555,"lon":117.162007},"praise":30}
{"index":{"_index":"hotel","_id":"004"}}
{"title":"金都酒店","city":"北京","price":500.00,"create_time":"2021-02-18 08:00:00","amenities":"浴池(假日需预定),室内游泳池,普通停车场","full_room":true,"location":{"lat":39.915343,"lon":116.4239},"praise":20}
{"index":{"_index":"hotel","_id":"005"}}
{"title":"文雅精选酒店","city":"北京","price":800.00,"create_time":"2021-01-01 08:00:00","amenities":"浴池(假日需预定),wifi,室内游泳池,普通停车场","full_room":true,"location":{"lat":39.918229,"lon":116.422011},"praise":20}3、我们先查看一下所有的数据
命令:GET /hotel/_search
结果:
#! Elasticsearch built-in security features are not enabled. Without authentication, your cluster could be accessible to anyone. See https://www.elastic.co/guide/en/elasticsearch/reference/7.17/security-minimal-setup.html to enable security.
{
"took" : 852,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "001",
"_score" : 1.0,
"_source" : {
"title" : "文雅酒店",
"city" : "青岛",
"price" : 556.0,
"create_time" : "2020-04-18 12:00:00",
"amenities" : "浴池,普通停车场/充电停车场",
"full_room" : false,
"location" : {
"lat" : 36.083078,
"lon" : 120.37566
},
"praise" : 10
}
},
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "003",
"_score" : 1.0,
"_source" : {
"itle" : "金都欣欣酒店",
"city" : "天津",
"price" : 200.0,
"create_ime" : "2021-05-09 16:00:00",
"amenities" : "提供假日party,免费早餐,可充电停车场",
"full_room" : true,
"location" : {
"lat" : 39.186555,
"lon" : 117.162007
},
"praise" : 30
}
},
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "004",
"_score" : 1.0,
"_source" : {
"title" : "金都酒店",
"city" : "北京",
"price" : 500.0,
"create_time" : "2021-02-18 08:00:00",
"amenities" : "浴池(假日需预定),室内游泳池,普通停车场",
"full_room" : true,
"location" : {
"lat" : 39.915343,
"lon" : 116.4239
},
"praise" : 20
}
},
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "005",
"_score" : 1.0,
"_source" : {
"title" : "文雅精选酒店",
"city" : "北京",
"price" : 800.0,
"create_time" : "2021-01-01 08:00:00",
"amenities" : "浴池(假日需预定),wifi,室内游泳池,普通停车场",
"full_room" : true,
"location" : {
"lat" : 39.918229,
"lon" : 116.422011
},
"praise" : 20
}
}
]
}
}三、开始查询
1、返回指定字段
很多场景我们并不需要返回所有的字段,比如在列表页的时候我们可能只需要返回 标题、价格而不需要把所的字段都查询出来,当然你也可以这么做,只不过这么做会带来一些性能上的损耗,这部分损耗包含从ES查询、从ES返回到客户端,从后端返回给前端等等,所以我们这里做指定字段的查询。使用到的关键字是**_source**
命令:
GET /hotel/_search
{
"_source": ["title","price"]
}
结果:
#! Elasticsearch built-in security features are not enabled. Without authentication, your cluster could be accessible to anyone. See https://www.elastic.co/guide/en/elasticsearch/reference/7.17/security-minimal-setup.html to enable security.
{
"took" : 1,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "001",
"_score" : 1.0,
"_source" : {
"price" : 556.0,
"title" : "文雅酒店"
}
},
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "003",
"_score" : 1.0,
"_source" : {
"price" : 200.0
}
},
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "004",
"_score" : 1.0,
"_source" : {
"price" : 500.0,
"title" : "金都酒店"
}
},
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "005",
"_score" : 1.0,
"_source" : {
"price" : 800.0,
"title" : "文雅精选酒店"
}
}
]
}
}
可以看到ES值返回了价格和标题,其余字段并没有返回。这个搜索就等价于Mysql中的
Select title,price from hotel2、计数查询
有些场景我们只想知道有多少符合条件的数据,而不需要知道确定的数据是什么,此时就可以用ES提供的计数查询来做。例如我们想知道城市为北京的数据有多少条。
GET /hotel/_count
{
"query": {
"term": {
"city": {
"value": "北京"
}
}
}
}
结果:
{
"count" : 2,
//下面这个是分片信息可以暂时忽略
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
}
}
可以看到结果只返回了满足条件的数据的数量,而并没有返回具体是那两条数据。这里用了query 和 term
这些后面也会讲到。这个搜索等价于Mysql中的
SELECT count(*) FROM hotel WHERE city = '北京'3、分页查询
分页查询,这个也很好理解,我们不可能一次性把所有数据都给客户,一方面是性能会很差,另一方面客户或许根本不关心这么多数据,所以此时我们需要将查询结果分页,让用户有选择的查看数据,话不多说直接上代码
GET /hotel/_search
{
"from": 0,
"size": 1,
"query": {
"term": {
"city": {
"value": "北京"
}
}
}
}
结果:
#! Elasticsearch built-in security features are not enabled. Without authentication, your cluster could be accessible to anyone. See https://www.elastic.co/guide/en/elasticsearch/reference/7.17/security-minimal-setup.html to enable security.
{
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 0.87546873,
"hits" : [
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "004",
"_score" : 0.87546873,
"_source" : {
"title" : "金都酒店",
"city" : "北京",
"price" : 500.0,
"create_time" : "2021-02-18 08:00:00",
"amenities" : "浴池(假日需预定),室内游泳池,普通停车场",
"full_room" : true,
"location" : {
"lat" : 39.915343,
"lon" : 116.4239
},
"praise" : 20
}
}
]
}
}
默认ES是只返回10条数据,我们可以通过from和size来设置分页参数,当ES默认最大返回值是
1000。当然这个数字是可以改的,在创建索引或者修改索引时设置settings index中有一个
max_result_window属性
PUT /hotel/_settings
{
"index":{
"max_result_window":2000
}
}
这个搜索相当于Mysql中的
SELECT * FROM hotel WHERE city = '北京' limit 0,1留个坑:ES会有深分页的问题,这个问题会放到后续的文章中讲述!!
4、性能分析
虽然ES是一个很强的搜索引擎,但是如果DSL写的过于抽象(过于烂)或者说索引设计的不合理也会导致ES搜索变慢,那么该如何解决呢?那肯定是要先知道那慢了,此时我们就可以用ES给我们提供的性能分析命令。我们还是以上面的DSL作为例子
DSL:
GET /hotel/_search
{
"profile": true,
"query": {
"match": {
"title": "金都"
}
}
}
结果:
{
"took" : 3,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 2.0834165,
"hits" : [
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "004",
"_score" : 2.0834165,
"_source" : {
"title" : "金都酒店",
"city" : "北京",
"price" : 500.0,
"create_time" : "2021-02-18 08:00:00",
"amenities" : "浴池(假日需预定),室内游泳池,普通停车场",
"full_room" : true,
"location" : {
"lat" : 39.915343,
"lon" : 116.4239
},
"praise" : 20
}
}
]
},
"profile" : {
"shards" : [
{
"id" : "[dglsus9vTpGyHUlIqpKvlw][hotel][0]",
"searches" : [
{
"query" : [
{
"type" : "BooleanQuery",
"description" : "title:金 title:都",
"time_in_nanos" : 2043800,
"breakdown" : {
"set_min_competitive_score_count" : 0,
"match_count" : 1,
"shallow_advance_count" : 0,
"set_min_competitive_score" : 0,
"next_doc" : 6700,
"match" : 4000,
"next_doc_count" : 1,
"score_count" : 1,
"compute_max_score_count" : 0,
"compute_max_score" : 0,
"advance" : 77200,
"advance_count" : 1,
"score" : 13300,
"build_scorer_count" : 2,
"create_weight" : 139400,
"shallow_advance" : 0,
"create_weight_count" : 1,
"build_scorer" : 1803200
},
"children" : [
{
"type" : "TermQuery",
"description" : "title:金",
"time_in_nanos" : 187000,
"breakdown" : {
"set_min_competitive_score_count" : 0,
"match_count" : 0,
"shallow_advance_count" : 3,
"set_min_competitive_score" : 0,
"next_doc" : 0,
"match" : 0,
"next_doc_count" : 0,
"score_count" : 1,
"compute_max_score_count" : 3,
"compute_max_score" : 36400,
"advance" : 1100,
"advance_count" : 2,
"score" : 7400,
"build_scorer_count" : 3,
"create_weight" : 37800,
"shallow_advance" : 12500,
"create_weight_count" : 1,
"build_scorer" : 91800
}
},
{
"type" : "TermQuery",
"description" : "title:都",
"time_in_nanos" : 43700,
"breakdown" : {
"set_min_competitive_score_count" : 0,
"match_count" : 0,
"shallow_advance_count" : 3,
"set_min_competitive_score" : 0,
"next_doc" : 0,
"match" : 0,
"next_doc_count" : 0,
"score_count" : 1,
"compute_max_score_count" : 3,
"compute_max_score" : 5400,
"advance" : 1800,
"advance_count" : 2,
"score" : 1000,
"build_scorer_count" : 3,
"create_weight" : 8400,
"shallow_advance" : 2400,
"create_weight_count" : 1,
"build_scorer" : 24700
}
}
]
}
],
"rewrite_time" : 7200,
"collector" : [
{
"name" : "SimpleTopScoreDocCollector",
"reason" : "search_top_hits",
"time_in_nanos" : 23900
}
]
}
],
"aggregations" : [ ],
"fetch" : {
"type" : "fetch",
"description" : "",
"time_in_nanos" : 102400,
"breakdown" : {
"load_stored_fields" : 19700,
"load_stored_fields_count" : 1,
"next_reader" : 9000,
"next_reader_count" : 1
},
"debug" : {
"stored_fields" : [
"_id",
"_routing",
"_source"
]
},
"children" : [
{
"type" : "FetchSourcePhase",
"description" : "",
"time_in_nanos" : 4600,
"breakdown" : {
"process_count" : 1,
"process" : 3900,
"next_reader" : 700,
"next_reader_count" : 1
},
"debug" : {
"fast_path" : 1
}
}
]
}
}
]
}
}这里的结果分析还是很冗长的,读起来也是有一点的难度的。索性我们可以借助kibana来帮我们分析

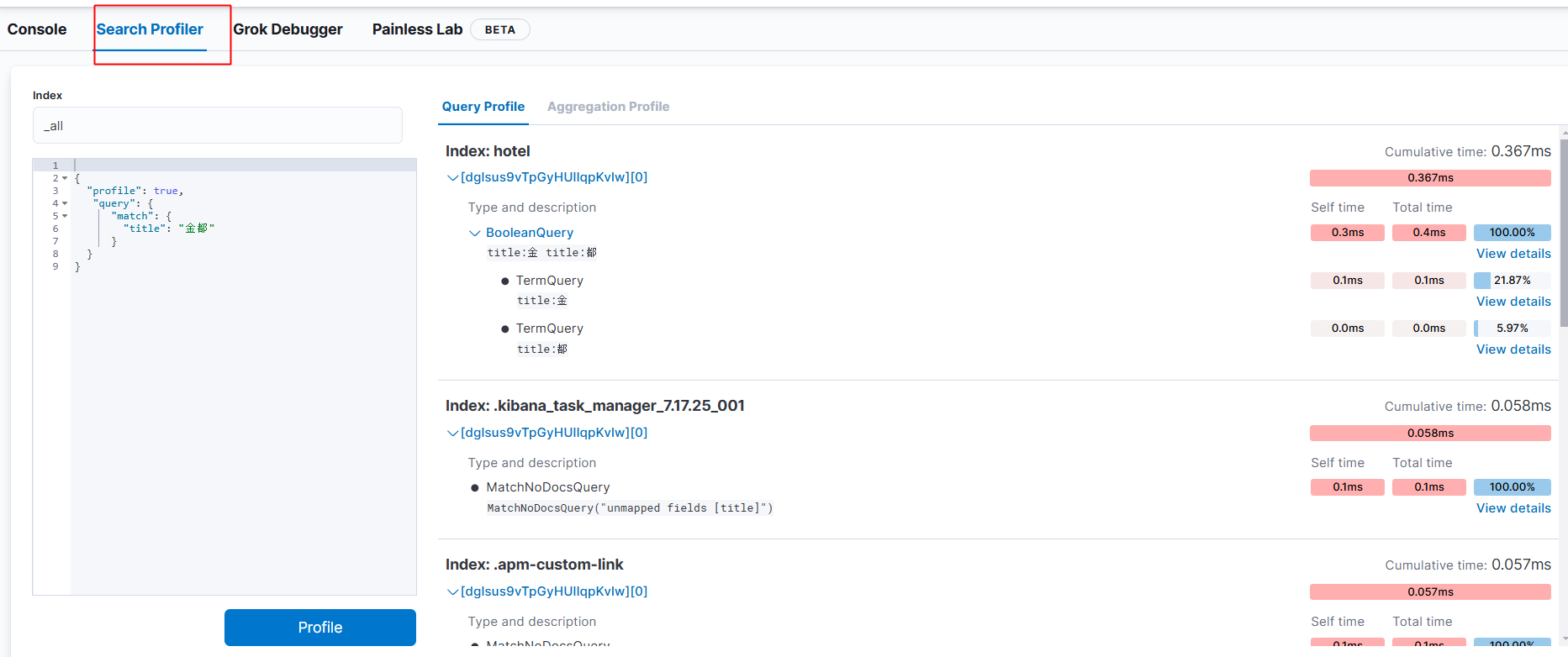
实话实说,笔者学到这里的时候还是很会看这个,后续再补充!
5、评分分析
ES是会对搜索条件进行评分的,如果用户没有指定按照那个字段进行排序,ES会使用自己的打分算法对文档进行排序,当然也可以人为干预,百度就是这么做的。有时候我们需要知道某个文档的具体打分详情,此时可以使用ES提供的explain来查询,例如
GET /hotel/_explain/002
{
"query":{
"match":{
"title":"金都"
}
}
}
结果:
#! Elasticsearch built-in security features are not enabled. Without authentication, your cluster could be accessible to anyone. See https://www.elastic.co/guide/en/elasticsearch/reference/7.17/security-minimal-setup.html to enable security.
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "002",
"matched" : true,
"explanation" : {
"value" : 1.1689311,
"description" : "sum of:",
"details" : [
{
"value" : 0.58446556,
"description" : "weight(title:金 in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.58446556,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.6931472,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 2,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.38327527,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 8.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 5.5,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
},
{
"value" : 0.58446556,
"description" : "weight(title:都 in 0) [PerFieldSimilarity], result of:",
"details" : [
{
"value" : 0.58446556,
"description" : "score(freq=1.0), computed as boost * idf * tf from:",
"details" : [
{
"value" : 2.2,
"description" : "boost",
"details" : [ ]
},
{
"value" : 0.6931472,
"description" : "idf, computed as log(1 + (N - n + 0.5) / (n + 0.5)) from:",
"details" : [
{
"value" : 2,
"description" : "n, number of documents containing term",
"details" : [ ]
},
{
"value" : 4,
"description" : "N, total number of documents with field",
"details" : [ ]
}
]
},
{
"value" : 0.38327527,
"description" : "tf, computed as freq / (freq + k1 * (1 - b + b * dl / avgdl)) from:",
"details" : [
{
"value" : 1.0,
"description" : "freq, occurrences of term within document",
"details" : [ ]
},
{
"value" : 1.2,
"description" : "k1, term saturation parameter",
"details" : [ ]
},
{
"value" : 0.75,
"description" : "b, length normalization parameter",
"details" : [ ]
},
{
"value" : 8.0,
"description" : "dl, length of field",
"details" : [ ]
},
{
"value" : 5.5,
"description" : "avgdl, average length of field",
"details" : [ ]
}
]
}
]
}
]
}
]
}
}
这个过于复杂,现在了解即可四、结束语
今天学习了ES中的查询,当然受限于篇幅,只是一部分。后续还会有更多的复杂搜索,希望对你有所帮助。