介绍
流水线通过在较长的组合逻辑路径中插入寄存器降低了组合逻辑延迟,增加了时钟频率并提高了性能。
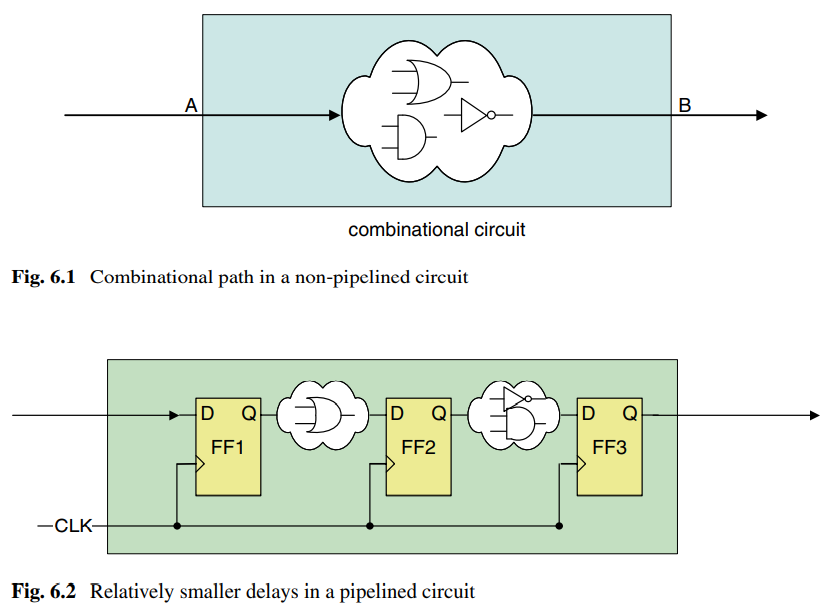
图中分别为插入流水线前后的逻辑。长路径插入寄存器后最大时钟频率明显增加,但是也带来了额外的开销,并且增加了系统延迟。
影响最大时钟频率的因素

图中电路若TCQA、TSB、THB均为0,Fmax就是组合逻辑最大路径延迟的倒数。
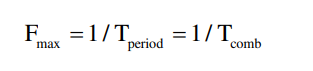
时钟偏移(Skew)
如图6.3,时钟到达B的时间可能相对于寄存器到达A的时间有一些延迟。这种传播延迟的细小差别,可能对整个系统时序产生无法接受的影响,这种现象也叫做"时钟偏移"(Skew)。
这里感觉说反了。。时钟延迟小于数据路径延迟,才是负时钟偏移。这时,时钟先于数据到达第二个寄存器,会导致提前触发寄存器,这样对保持时间更加友好,但是会导致建立时间更严苛。
时钟抖动(Jitter)
到达电路某一点连续时钟边沿之间间隔的变化称为时钟抖动tjit。Skew是可预测的,Jitter是不可预测的,只能给一个范围。

如图,Jitter会影响始终占空比。
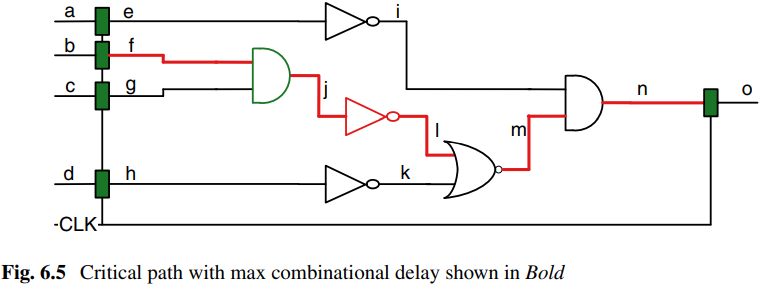
图中红线是关键组合电路路径。
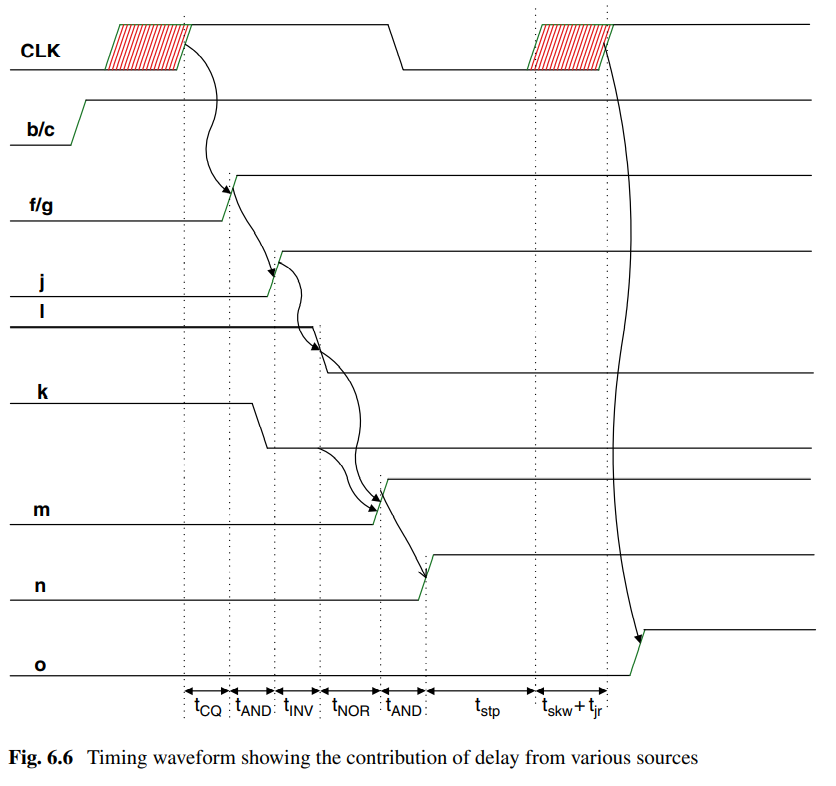
根据时序图可以计算最大周期:
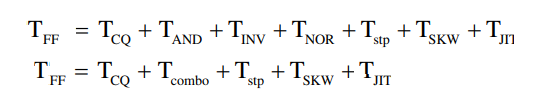
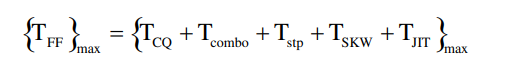
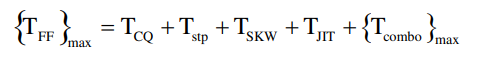
组合延迟部分可以通过添加多个触发器减少,增加了电路操作的最大频率,显著提升电路的吞吐率。
流水线
流水线通过存储器件将时钟周期内关键路径分隔开,减少了关键路径延迟并使电路能以更高频率工作。流水线增加了各时钟计算能力,但是由于使用了存储器单元也增加了负载。
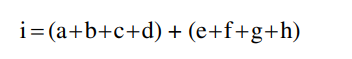
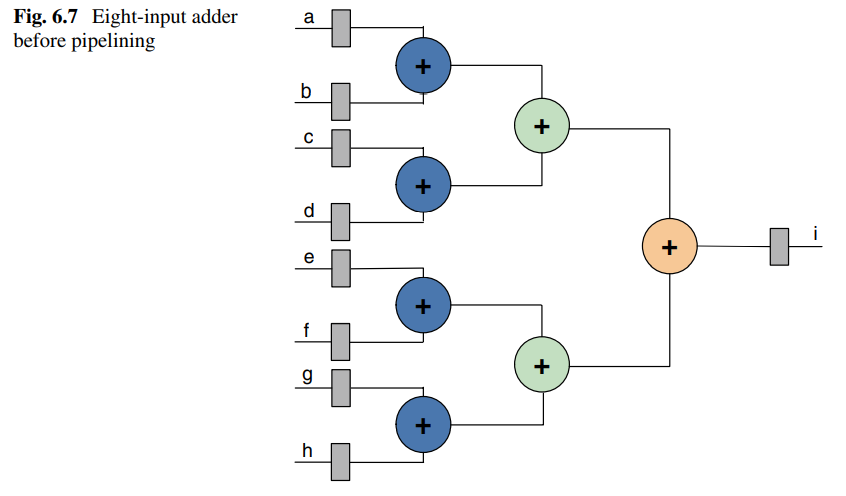
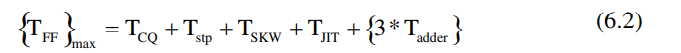
可以计算总延迟:

在插入两级流水线后:
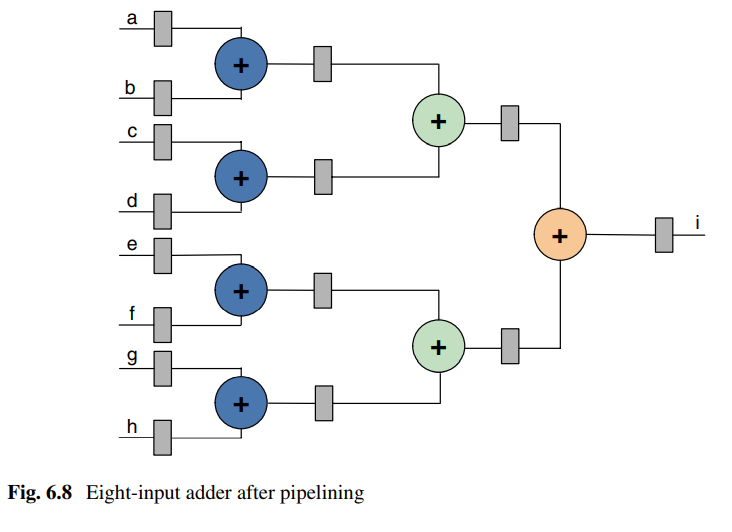
插入流水线之后的延迟:
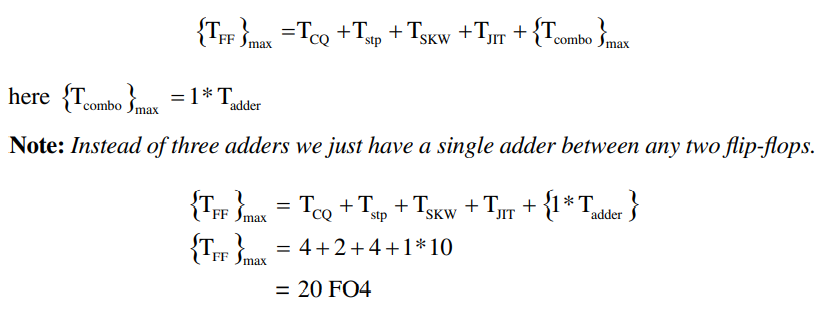
加流水线后实现8输入加法,吞吐率增加到每个时钟周期计算一次8输入之和,总延迟为3个时钟周期。(增大了延迟,提高了吞吐率)
一般来说使用并行电路比复用电路达到同样的效果在面积和功耗方面的开支更大,因为使用了更多的触发器和额外逻辑,导致了更多连线。
解释流水线----------一个真实的例子

这个例子比较简单,就是把各个工序分开,进行流水线生产。
来自流水线的性能提升

如图两个寄存器之间有一个大规模组合逻辑矩阵。
流水线延迟是指数据进入流水线的输入端到经过处理后输出所消耗的时间。

把同样的电路插入n级流水线:
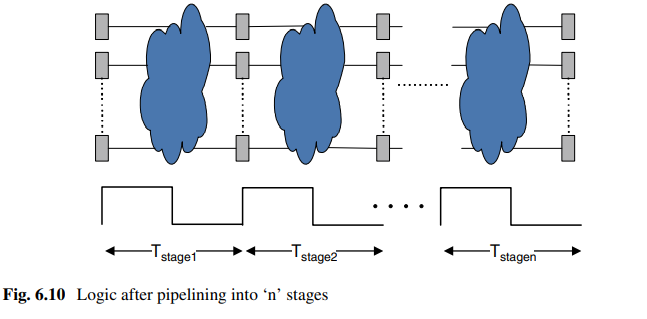
单级的周期:
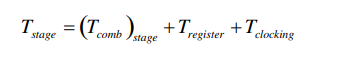
延迟最大的流水线决定了最小周期:

总延迟就是时钟周期的n倍
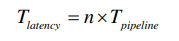
理想情况下各级流水线延迟应当相等,使流水线中最大组合逻辑延迟相同。

所以最小可能的时钟周期为:

最终延迟:
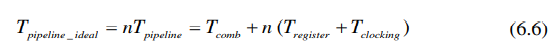
电路速度增加公式可以用插入流水线之后的最大频率除以插入流水线之前的频率得到:
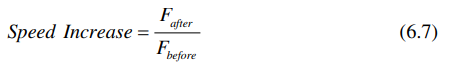
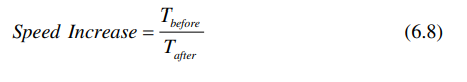
由6.3和6.5可以得到:
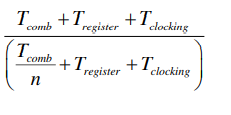
设寄存器和时钟开支占总时钟周期百分比为k
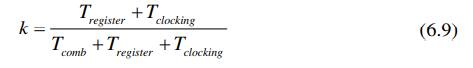
代入6.8:
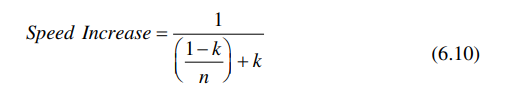
流水线的性能增加可以定义为:
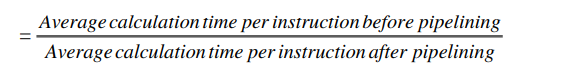
所以:
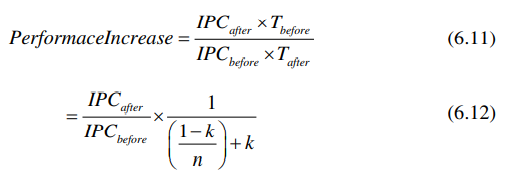
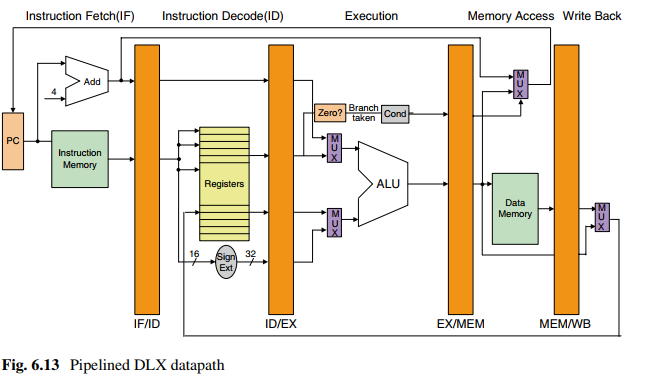
DLX指令集的实现
这节开始将指令集相关内容,没学过相关知识,看不太懂,就快速浏览一下好了。
DLX指令集包括五个部分:
1、指令获取(IF)
IR <= MEMPC
NPC <= PC +4
从存储器中获取指令(PC为指针)并放入指令寄存器(IR),IR保存下个时钟周期所需指令,PC值递增4,指向下个指令地址。
2、指令解码/寄存器获取(ID)
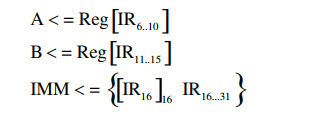
指令格式是固定的,所以读寄存器和解码可以同时进行。这称为固定域译码。
3、执行/有效地址周期(EX)
根据指令类型执行下面4个功能之一:
a)访问存储器

b)寄存器------寄存器ALU指令

c)寄存器------立即数ALU指令

d)分支指令

4、访问存储器/分支完成周期(MEM)
a)访问寄存器

b)分支


5、写回周期(WB)
a)寄存器------寄存器ALU指令

b)寄存器------立即数周期
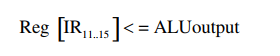
c)取指令
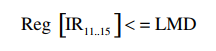
以上操作将结果写回入寄存器堆中,结果可能来自存储器(LMD)或者来自于ALU。
无流水线DLX数据通路上的5个步骤:
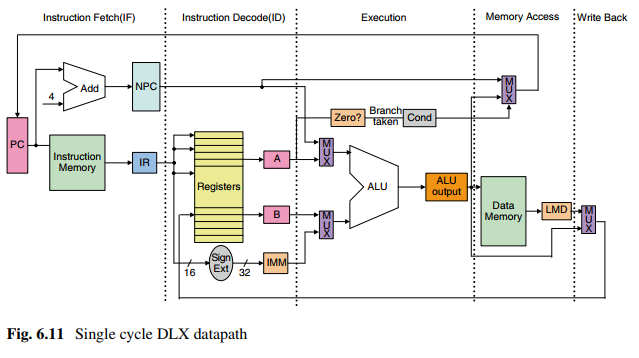
无流水线无法并行执行指令,只有当第一条指令执行完才开始执行第二条指令。
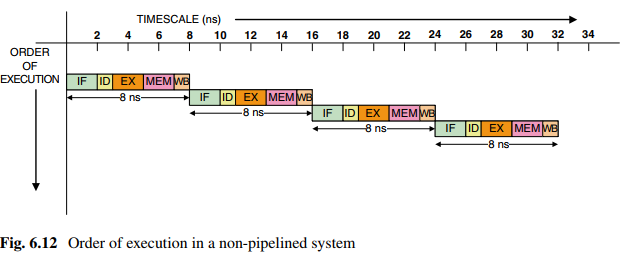
流水线对吞吐率的影响
在每个阶段加一级流水线:
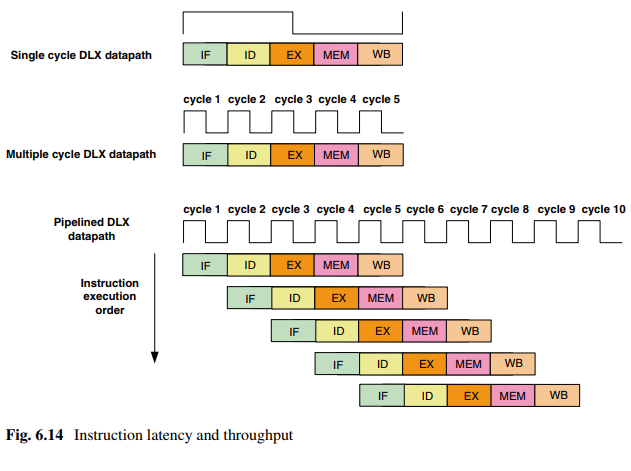
如图,不加流水线消耗时间5(5条指令)*5(每条指令消耗周期数)*2(周期)=50ns,加了之后9*2=18ns,性能提升了50/18=2.8倍。
但是使用流水线时会引入额外的开销,如Skew和寄存器延迟,这种开销限制了流水线所能达到的加速值。
流水线原理

流水线冒险
冒险会干扰流水线并阻止下一条指令在目标时钟周期内的执行。冒险会降低流水线在理想情况下所能带来的速度提升。
冒险分类:
1、结构冒险:资源冲突导致硬件无法支持所有可能的指令组合同时执行。
2、数据冒险:指令执行需要之前指令计算结果,而这个结果还在流水线中没计算出来。
3、控制冒险:分支的流水线的其他指令改变程序计数器的值。
通用方法:停止流水线直至风险消除,在流水线中插入多个"气泡"。
结构冒险
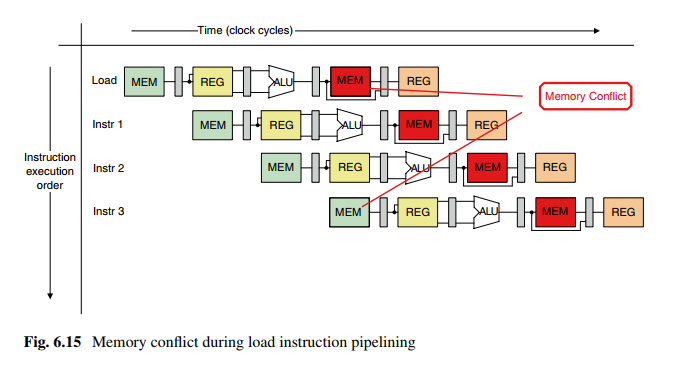
如图,MEM在一个周期内被两个指令使用,产生冲突。
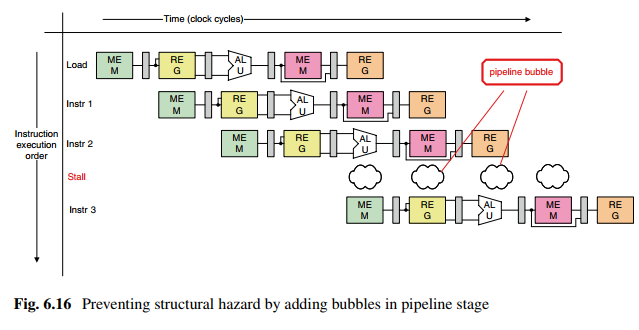
解决方法:如图,停一个周期,待对MEM的冲突解除后再恢复流水线。
另一种方法:IF和MEM阶段使用不同的存储器来避免同时访问同一块存储器。缺点:消耗更多资源。
数据冒险
对于下面指令:

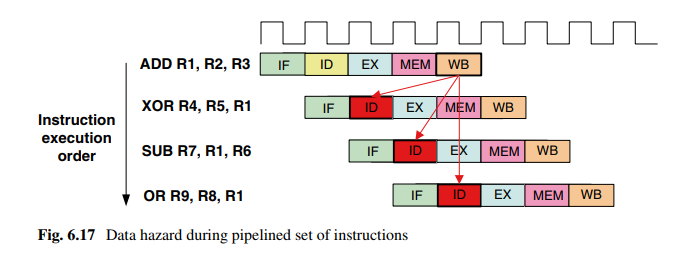
如图,ADD之后的指令无法得到正确的执行结果,因为后续指令的ID阶段都需要ADD指令的结果。
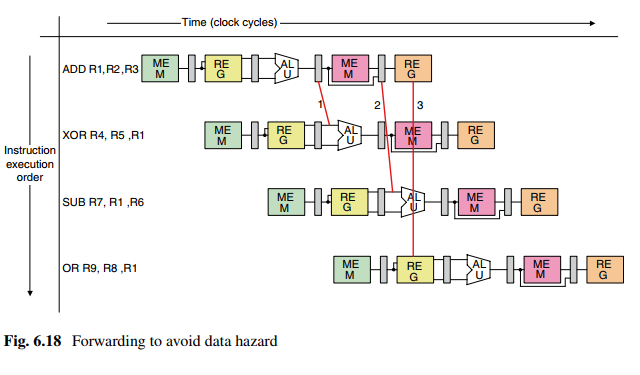
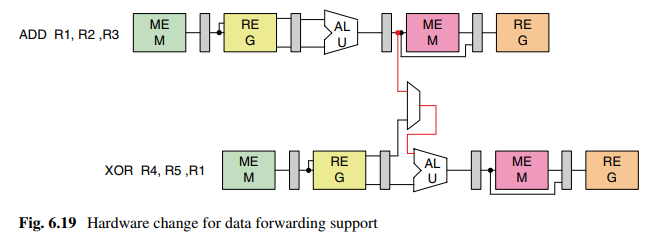
解决方法:数据/寄存器转移。大概意思就是把第一个指令的ALU寄存后直接输出到下一级ALU的输入。对于两个、三个周期后的指令,则需要把MEM输出、REG输出直接连接到后续流水线。
对于下面指令:

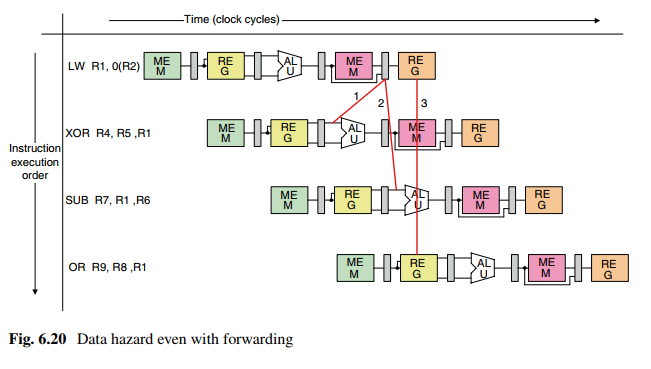
如图6.20,路径1永远无法实现,因为XOR指令需要在ALU输入端使用R1寄存器的值,该值在LW指令执行后才能更新。
简单的方法:使用纵向旗袍,将ALU周期延一个时钟。

除了使用硬件技术,也可以使用基于编译器调度的软件方式来解决数据冒险的问题。这时,编译器跟踪每个寄存器中的数据,并重新安排指令次序阻止数据冒险的产生。
控制冒险
如下指令:

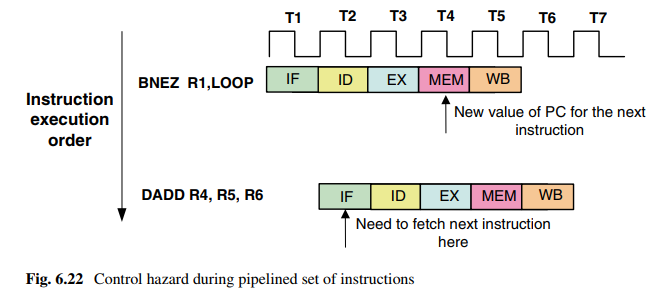
T2在执行第二条指令时就需要PC值,但是该值要在第二条指令的MEM操作后才可能。
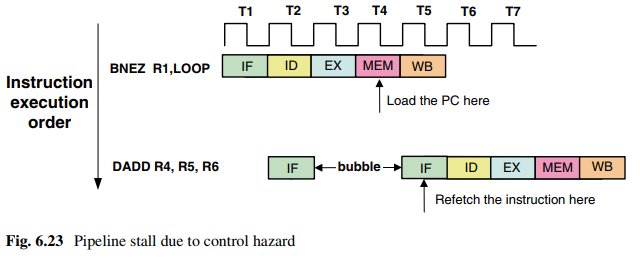
解决方法:分支语句中用新的PC值重新获取下一条指令。这种情况下,需要将流水线停止几个周期,直到重新获取下一条指令。如图:
其他风险
指令获取或在数据读写时会访问存储器,指令获取时,数据应该由PC寄存器保持稳定。该值应该一直保持到把获取的指令写入IF/ID流水线寄存器的IR域为止。因此,对IF/ID寄存器的IR操作必须在PC写操作之前。
数据读写时,有效地址在EX阶段由ALU计算得到。在将存储器中的数据存入LMD寄存器或存储器写信号被激活使数据写入存储器之前,该地址不能变化。
ADC流水线------一个例子
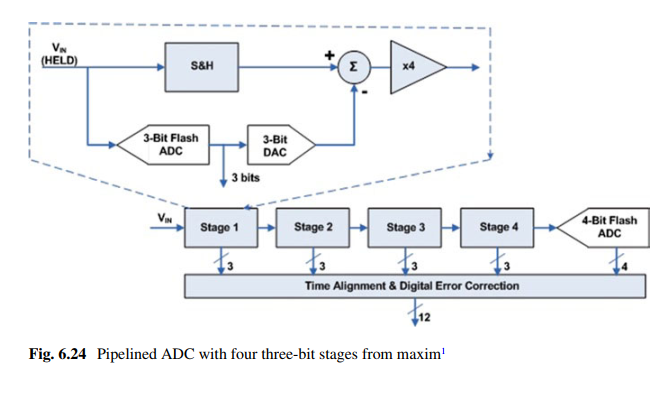
该ADC有四级流水线,每级流水线提供三位数字量,所以一共是12位ADC。每级流水线采样并得到差值传递到下一级,提高了ADC的处理能力。