作者|郭源
前言
在后LLM时代,随着大语言模型和多模态大模型技术的日益成熟,AI技术的实际应用及其社会价值愈发受到重视。AI智能体(AI Agent)技术通过集成行为规划、记忆存储、工具调用等机制,为大模型装上"手脚",使其能够利用强大的多模态感知交互与推理决策能力,与真实世界进行有效交互,成为连接人类与数字世界的桥梁,并迎来前所未有的发展机遇。(了解更多关于智能体的见解:《在后LLM时代,关于新一代智能体的思考》) 。
近期,在诸多类型的智能体中,能够自动化执行GUI(Graphical User Interface,图形用户界面)交互任务的多模态智能体受到了广泛的关注。多模态GUI智能体能在手机、平板、电脑等终端设备上,通过模拟人类的点击、滑动、输入等操作,与图形用户界面进行交互,完成信息获取和功能执行。例如下图中,移动端GUI智能体框架AppAgent1能够通过接受自然语言指令,理解用户意图,并制定执行计划,在手机APP中完成指定任务,展现了其强大的应用能力。
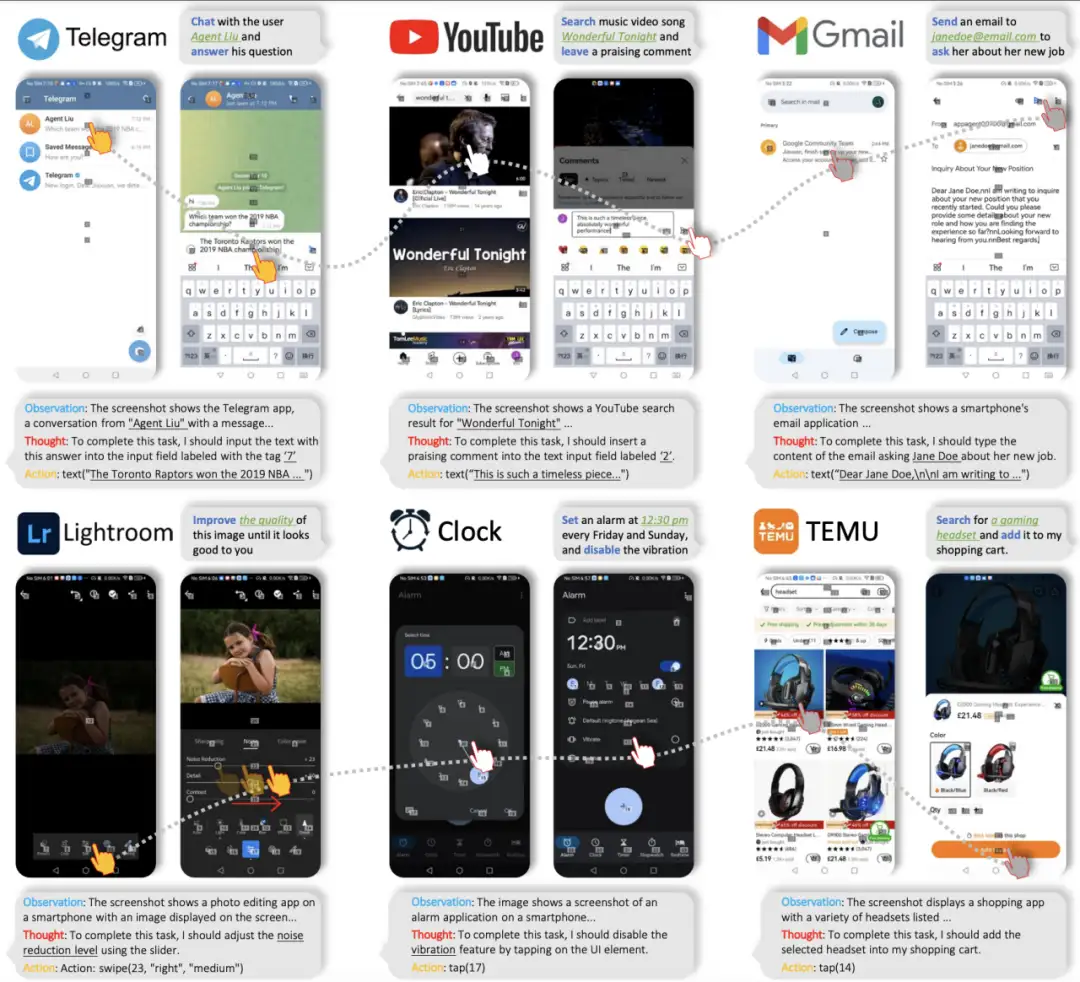
总体来说,多模态GUI智能体具备以下显著优势:
- 高实用价值:手机作为人类最常用的工具,将AI技术与手机深度融合,将带来极大的实用价值;
- 构建"AI操作系统":有助于打破海量应用间的壁垒,实现手机功能间的统一管理;
- 提升用户体验:通过自动化完成重复繁琐的GUI操作,不仅能为日常生活带来便利,还能帮助行动不便的用户轻松使用手机功能,展现出更强的泛化性和拟人性。
近期,国内外众多企业纷纷瞄准GUI智能体领域,推出了一系列相关工作和产品,如Anthropic推出的基于Claude 3.5"Computer Use"功能、微软的解析屏幕截图、标注可交互元素的工具OmniParser、荣耀搭载智能体的个人化全场景AI操作系统MagicOS 9.0等 。
本文将聚焦于GUI智能体中的移动端智能体,从能力维度、核心挑战、技术细节、研究概况、发展瓶颈及未来趋势等多个方面,进行深入解析与探讨。
移动端GUI智能体的技术范式
总的来说,对于大模型驱动的移动端GUI智能体,其核心在于将任务指令、历史轨迹、当前状态、补充提示等信息输入大模型,经大模型推理后形成形式化的动作决策,并通过驱动工具在设备上执行。其技术范式可以从输入模态和基座模型两个维度进行分类。
目前,移动端GUI智能体大多在安卓(Android)平台上实现,这得益于安卓平台在调试工具、模拟器搭建和开源数据等方面的透明度和成熟度。
在输入模态方面,技术可以分为纯文本模态输入和多模态信息输入。纯文本模态主要依赖于Android平台的调试工具(如ADB)和模拟器,通过获取无障碍树(Accessibility Tree,ally tree) 或利用OCR(光学字符识别技术)和IconNet(GUI元素识别网络)等视觉工具解析截屏,获取界面元素和视图信息,然后将这些信息与任务目标、动作历史等一起输入语言模型进行决策。
例如,Google的Android in the Wild2和AndroidControl3两篇工作中的智能体实现,均采用了将屏幕信息以html格式的文本形式输入给模型的方法。而AndroidWorld4中的T3A模型,则是通过获取无障碍树生成的元素列表作为屏幕信息的输入,该列表还详细列出了各个元素上可执行的操作。模型经过推理后,会输出一个具体的操作指令,如{"action_type": "scroll","direction": "down"},这种格式化的动作指令经过解析后,可以无缝对接Android调试工具,从而在实体设备上执行相应的操作。

AitW中屏幕解析得到的html
然而,纯文本信息输入模式存在依赖后台工具、解析错误、视觉信息缺失等问题。随着多模态大模型技术的发展,将屏幕截图作为视觉输入已成为操作新范式。例如,AutoGUI5创新性地基于第一性原理,构建了多模态GUI自主智能体。研究者们在1B级别的Encoder-Decoder多模态架构(BLIP2视觉编码器 + FLAN-Alpaca语言模型)上进行GUI训练,能够依据用户目标、历史动作及当前截图进行动作决策,实现了"所见即所得,决策即控制";论文MM-Navigator6中探讨了利用GPT-4V进行GUI操作的可能性,通过输入带元素标注的屏幕截图和任务相关的信息,该模型在常用任务上展现了出色的零样本(Zero-shot)执行能力。
如今,将屏幕截图作为主要输入,并辅以工具及后台解析作为场景感知信息,已成为场景输入模态的主流方案。通过内生能力增强、屏幕解析工具插件等手段,智能体正逐步减少对后台信息、标注信息的依赖,以更便捷地适应更广泛的场景,这已成为一个技术发展的趋势。
在基座模型方面,技术路线包括基于闭源强模型API和基于开源模型领域训练两种。
针对闭源模型技术路线,人们发现GPT-4V,Gemini-1.5-Pro等SoTA多模态大模型已具备在GUI操作中展现零样本执行的潜力,并探究了Prompt的精细设计、输入信息的场景增强及多智能体合作等潜在领域。例如,AitZ(Android in the Zoo)7提出有别于传统Chain-of-Action和Chain-of-Thought Reasoning的Chain-of-Action Thought推理机制,该机制将场景观察,动作规划,操作Grounding等决策流程显式地集成到推理链路中,从而显著提高了决策成功率,Mobile-Agent-v2框架则通过Planning Agent、Decision Agent及Reflection Agent进行协作,辅以memory等机制,进一步提高了任务的完成成功率。
相比之下,开源且参数较小的模型具有部署成本低、推理效率更高以及便于个性化适配等优点,但其通用性和领域能力相对较弱。为了增强基座模型在GUI领域的能力,CogAgent8,MobileVLM9,Qwen2-VL10,OS-ATLAS11等工作通过收集大规模GUI领域数据,对模型进行了场景元素感知、动作Grounding等任务的领域训练。监督微调(Supervised Fine-Tuning,SFT)已被证明能有效提升模型在领域内的表现。例如,Auto-GUI,CoCo-Agent12等工作利用静态操作轨迹进行微调,取得了领域内动作预测表现的大幅提升。而DigiRL13引入offline-to-online强化学习机制,在探索轨迹上训练模型,成功提升了端到端的任务成功率。
移动端GUI智能体的数据构造
我们可以将GUI领域的数据划分为两大类:预训练任务数据和操作序列数据。
预训练任务数据涵盖了交互数据以及标注的单界面数据,这些数据通过GUI grounding、GUI VQA等训练任务,能够有效提升智能体在GUI领域的专业知识和能力。而操作序列数据则是一系列与下游任务一致的序列式数据,包含用户指令和GUI交互轨迹。
在构造这些数据时,我们可以采用多种方法,包括人类手动标注、模型自动化标注以及人类静态标注与模型数据增强相结合的混合标注方式 。目前,主流的GUI交互序列数据集,如Android in the Wild和AndroidControl,都是采用任务分发与人类众包团队标注的方式获得的。其具体做法是让标注者通过web工具在电脑端操作手机,并记录操作轨迹。
为了进一步提升数据集的质量,有些研究采用了数据增强的方法。例如,AitZ使用GPT-4o对人类标注的静态交互数据进行额外信息的标注,如场景简述、动作思考等,模拟合成人类的分析、决策过程。
在模型自动化数据方面,OS-ATLAS通过DFS和随机游走探索从模拟器中收集界面相关信息,以构建训练数据集。此外,DigiRL和DistRL尝试了让智能体在交互式环境中自生成行为轨迹,并用于训练。
下图展示了AndroidControl数据集的论文中(2024年6月)对各个常用静态GUI轨迹数据集的对比和总结。
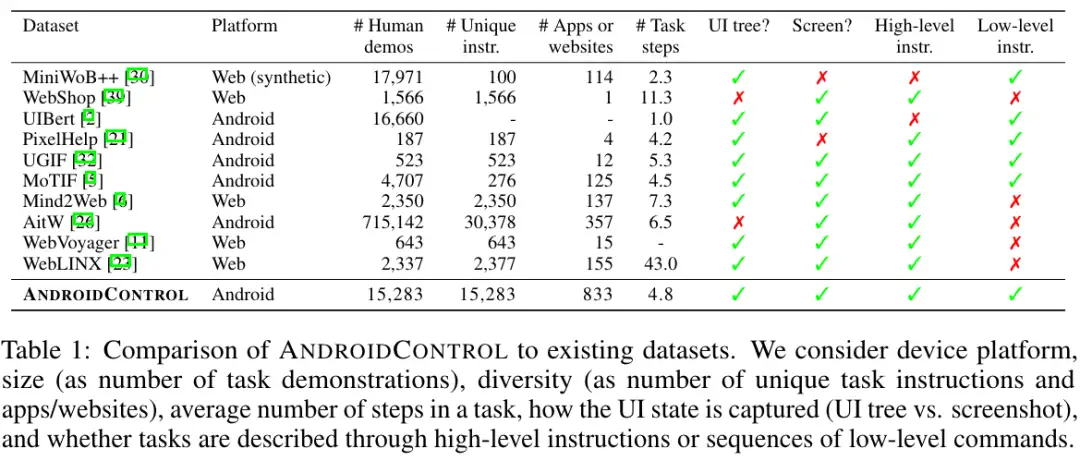
值得一提的是,许多测评和实践结果都表明,现有的基于微调的开源GUI智能体基座在领域外测试任务上常常表现出灾难性的OOD性能下降(后面部分中会详细展开) 。这凸显了构建多样、丰富的GUI训练数据的迫切性。Google在AndroidControl中进行了GUI Data Scaling Law的探索,并指出要想在OOD任务上达到与当前领域内相当的表现,训练数据量需要增加1-2个数量级。因此,搭建一个自动化、可扩展的数据构建框架对开源、通用GUI智能体的开发以及迭代具有重要意义。
移动端GUI智能体的基座增强
在这一部分,我将深度剖析移动端GUI智能体的核心能力构成,并探讨这些领域内的最新研究进展。
从宏观视角来看,智能体的行为逻辑可以总结为其与复杂外界环境的交互过程。这一过程包含从环境中获取当前状态的观察(Observation) ,基于环境状态、自身知识及任务目标进行推理(Thought/Reasoning) ,进而做出动作决策并执行于环境(Act) ,并最终进行观察总结(Reflection) 。这三个阶段分别对应环境感知能力、规划推理能力以及动作落实(Grounding)能力。此外,在实际落地部署时,高效部署能力和场景泛化能力也是衡量GUI智能体性能的关键指标。
环境感知(Perception)能力
环境感知能力主要指GUI智能体对其操作设备(所处环境)的观察和解读能力,包含对环境特征的感知(如屏幕上的文本、控件、布局等视觉层面)和对环境内容的理解(如各元素的功能、屏幕状态等知识层面信息) 。
传统的多模态预训练方法往往侧重于图像整体标签的识别,而忽视了细粒度元素和布局的理解,同时,缺乏GUI相关的领域数据,导致在面对复杂GUI界面时,模型容易出现场景感知残缺和知识匮乏等问题。例如,在下图的安卓屏幕截图中,基于GPT-4V的智能体在执行创建特定日程的任务时,并没有感知到"All-day"选项没有被勾选这个重要信息,导致无法满足用户需求。
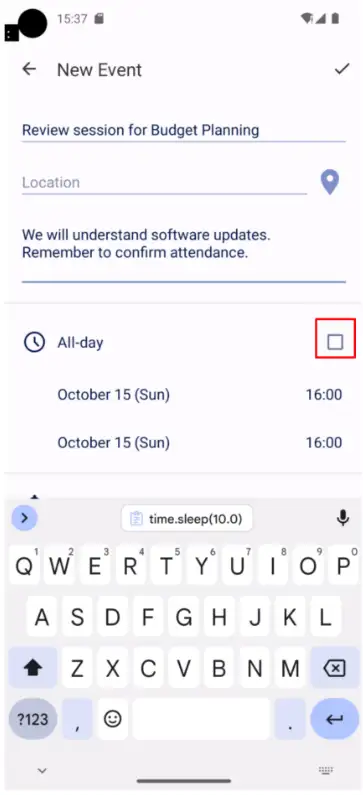
环境感知能力缺陷例子
为了增强环境感知能力,可以从数据增强和模型增强两个层面入手。在数据层面,通过引入后台无障碍树中包含的界面信息和外部工具的屏幕的解析信息来补充输入,以弥补模型感知能力的不足。例如,AndroidWorld中M3A,AitZ等工作。微软近期开源的OmniParser微调了一个目标识别的YOLO模型和一个对元素做Image Caption的BLIP模型,能够轻量化地实现解析屏幕,识别并标注出当前界面中的UI元素信息作为辅助信息输入,可以作为灵活的插件来赋能智能体感知增强。
在模型层面,需要通过创新模型架构和训练数增强模型在预训练阶段对复杂GUI界面和元素的处理、分析能力。例如,开源GUI专家模型CogAgent中,通过设计轻量级的"高分辨率交叉注意力模块",在降低显存和计算开销的同时,可以成功理解高分辨率图片。小米MobileVLM收集大量GUI界面数据,设计了元素列表生成、动作空间生成、GUI任务执行等预训练任务,增强基座模型的GUI领域知识和环境感知能力。
长远来看,环境感知和理解能力应当随着训练数据和策略的进步,集成为多模态基座模型的内生能力。
规划推理(Reasoning)能力
规划推理能力是指智能体结合世界知识和场景理解,制定实现用户需求的下一步动作规划的过程。可以形式化为输入用户目标 、场景观察和交互历史,输出自然语言形式的动作计划 。
在推理内容结构方面,GUI智能体推理范式包含直接构建动作链的Chain-of-Action(CoA)范式和逐步推理后做出决策的Chain-of-Thought(CoT)范式。此外,Android in the Zoo提出Chain-of-Action Thought(CoAT)范式,将决策拆分为屏幕总结、动作思考和动作预测步骤,提升了决策准确率。
以上几种范式既可以作为强基座模型做Prompting时的模式选择,也是构造GUI下游任务微调数据时的格式参考。OpenAI o1-preview的发布揭示了Inference Scaling在推理领域中的巨大潜力。这一技术不仅在数学、代码等LLM推理任务中展现了其搜索和优化的强大功能,还与智能体在复杂环境中的任务规划、执行工作流存在着天然的契合。具体而言,我们可以将智能体所处的每个状态建模为一个节点,而智能体在环境中的搜索、执行、回溯等过程,则可以建模为部分可观测马尔可夫决策过程(Partially Observable Markov Decision Process, POMD) 。
例如,Agent Q14在WebAgent的设定下进行了智能体自主学习框架的实践。它在每个决策节点采样多个动作方案进行尝试,并结合蒙特卡洛树搜索(MCTS)算法和自我评价机制,构建偏好数据进行迭代优化。这一方法显著超过了行为克隆和强化微调等传统基线方法的表现。WebPilot15利用Planner、Control、Explorer、Appraiser等机制,借鉴MCTS的思想在环境中进行尝试探索、调整回溯等,在尝试中得出正确的行为轨迹。基于Inference Scaling的复杂场景推理优化,有望成为提升智能体规划推理能力和泛化性能的关键技术。
此外,多智能体协作(如UFO16框架中以Host Agent+Actor Agent的dual Agent模式来进行复杂任务的规划)和智能体行为流程优化(如M3A框架中引入React+Reflextion思路)也是进一步提升GUI规划推理能力的有效尝试。
动作落实(Grounding)能力
动作落实能力是将自然语言形成的动作计划转换为形式化的操作指令的能力。由于智能体与真实环境进行交互的本质要求,这一能力成为了GUI智能体另一大性能考验。
SeeAct中的研究表明,GPT-4V在web agent(网页智能体)任务上拥有较强的通用性计划制定能力,即能够制定被验证为正确的自然语言形式行为规划 ,然而,其将计划落实到具体场景的能力却存在明显局限。这一问题同样存在于具有富媒体多控件的移动端GUI任务中。因此,针对grounding能力的强化训练也成为了GUI基座模型强化的一个重要任务。
在模型训练方面,研究者们通过构造大量数据来增强GUI智能体基座模型的grounding能力。例如,SeeClick17从Common Crawl中收集了约300k个网站,从html中收集元素;同时,还整理面向Mobile端的Widget-Captioning和Rico数据集,构造了大规模的GUI grounding数据集,用于训练Qwen-VL模型得到SeeClick。
UGround18则通过网页合成大量高质量的训练数据,利用先进的MLLM生成多样化的指代表达,并训练一个强大的通用视觉定位模型,以精确地将这些表达映射到GUI上的坐标 。
此外,OS-ATLAS构建了自动化数据收集框架,构建了涵盖web、desktop、mobile端的13M GUI grounding数据,对多模态基座进行了大规模的GUI预训练,从而成功验证了GUI grounding任务上的scaling law,并大幅提升了模型作为预训练基座的GUI能力。
在决策范式方面,如SeeAct这样将动作规划和grounding解耦的决策范式也被越来越多地采纳。例如,清华等机构近期发布的AutoGLM便采用了这种模式。此外,UGround等工作还尝试了闭源模型+开源模型协同工作的模式,用理解、推理能力强大的闭源模型(如GPT-4o)作为规划模型,用grounding上做过强化训练的开源模型(如SeeClick,UGround)来执行Action Grounding操作,各取所长,提高表现。

AutoGLM决策模式
高效部署(Efficiency)能力
由于移动端GUI智能体的部署和应用场景的实际需求,轻量化、高效部署推理也是其重要的能力要求。使用闭源模型api进行复杂的提示词工程(prompt engineering)虽然能提升性能,但往往伴随高昂的时间和token成本。因此,使用小模型执行任务更符合应用需求。
Auto-GUI利用1B级别的Encoder-Decoder多模态架构,实现了近乎实时的预测速度,每轮动作预测耗时不足1秒,且GPU显存占用低于10GB。
华为、UCL联合推出的LiMAC框架,结合了 Transformer 网络和一个小型的微调版 VLM,实现了高效任务的处理。LiMAC首先利用一个约500M参数量的紧凑型模型处理任务描述和智能手机状态,有效应对大部分动作需求。对于需要自然语言理解的动作(如撰写短信或查询搜索引擎),则会调用一个 VLM 来生成必需的文本。这种混合策略不仅可以降低了计算需求,还提高了响应速度,任务执行时间明显缩短(速度提升30倍,平均每个任务只需3秒),同时提高了准确性。
尽管如此,模型的轻量化和复杂任务规划推理能力以及对不同应用场景的泛化性能之间仍然需要寻求一个平衡点,为未来的研究留下了广阔的空间。
场景泛化(Generalization)能力
理想的移动端GUI智能体不应局限于少数常用App中预定义高频任务,而具备在广泛场景(如系统更新、新下载的App以及训练数据中未包含的小程序)中的强大泛化能力。良好的泛化能力,一方面要求提高并充分激活基座模型的基础能力,另一方面则需要确保训练数据多样性,防止过拟合。
在模型的环境适配方面,OmniParser的屏幕信息解析功能和AppAgent的环境探索机制在一定程度上帮助了模型在未知领域的泛化。
在训练数据方面,已有的工作证实了:
- 仅在特定GUI数据集上微调的开源模型,在领域外任务上的表现往往不尽如人意。
- 要使模型在领域外的表现与领域内相当,通常需要比领域内多一到两个数量级的训练数据。
- 利用在线轨迹进行偏好学习,展现出帮助模型更好适应环境的潜力。
移动端GUI智能体的性能评估
当前,GUI智能体的基准测试主要聚焦在两个方向:
- 单步动作决策平均准确率
- 端到端任务完成成功率
在GUI智能体发展早期,受限于测试环境,研究者往往依赖于人类标注的静态GUI操作序列数据集。利用GUI智能体来预测当给定了用户指令、动作历史、当前截屏、标注信息等的下一步动作,并将其与人类标注的执行合成标准(作为ground truth)进行比较,从而评估动作类型预测准确率以及动作预测准确率。
Google发布的Android in the Wild(AitW)数据集便是此类评测方法的典型代表。AitW数据集是由人类标注团队众包标注的一个大规模GUI操作轨迹数据集,它包含了30K个不同的任务指令、715K段任务执行轨迹,以及每张截图对应的IconNet、OCR识别结果。单步动作预测测试表明,SoTA多模态大模型在动作预测上展现出一定能力,而经过微调的开源模型在领域内测评中表现突出。
下图是CoCo-Agent中所做的各个模型在AitW上的测试结果。基于全面感知,轨迹微调的llava在测试中表现显著优于GPT-4,达到SoTA水平。
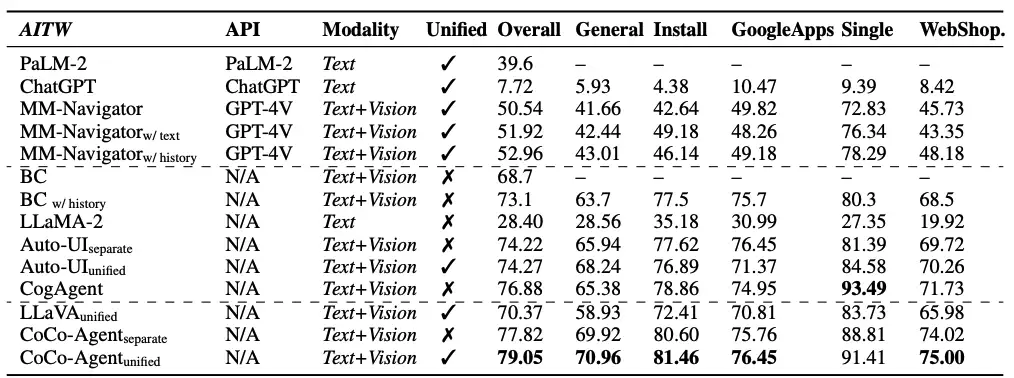
但是,基于单步动作决策的测评模式与真实部署场景中端到端的任务执行模式仍存在差距。另外,人类标注的静态数据集因噪声、GUI操作任务多样性等原因,可能导致性能测评上的偏差。因此,近期多个国内外团队基于安卓模拟器搭建了端到端的GUI Agent任务执行测试环境,通过模拟器系统信号或VLM评估模型,来测定端到端任务完成成功率。
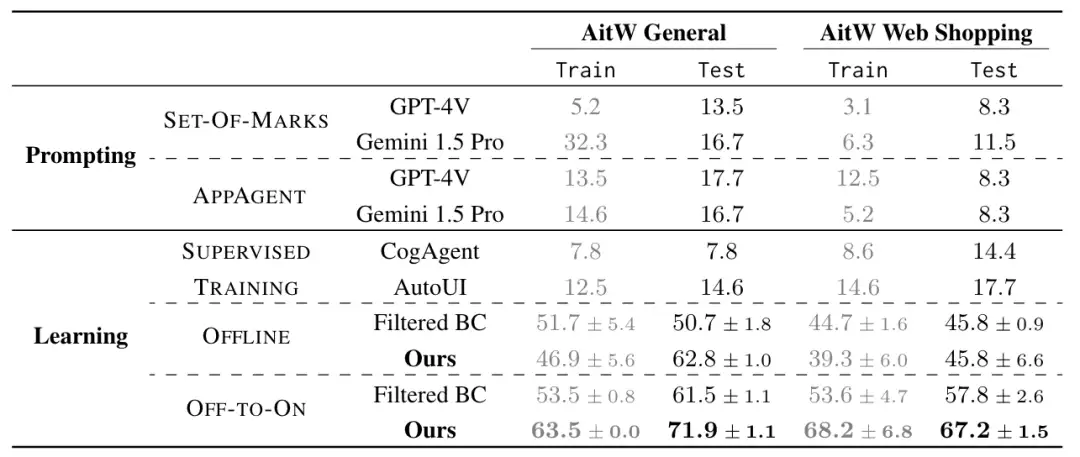
DigiRL选取了AitW的任务指令和系统版本,但是让模型在安卓模拟器的交互式环境中尝试执行任务。在这样的测试模式下,在单步动作预测测试中表现优异的Auto-UI、CogAgent模型显示出很低的任务完成率。而在离线静态轨迹和在线主动探索轨迹上进行强化学习后,Auto-UI的测试集任务完成成功率由14.6%提升到71.9%,这体现了强化学习方法在提升端到端任务完成能力上的潜力。同时,类似Mobile-Agent-Bench,AndroidWorld等测试基准也展现了主流GUI Agent框架在端到端任务执行上实际表现并不理想。
9月,SPA-Bench19团队构建了一个涵盖中英文、系统及第三方应用、单一应用及跨应用场景的GUI测试基准,集成了7个基于GPT-4o的闭源智能体和4个经过微调的开源智能体,进行了全面的性能评估,包括任务成功率、任务执行时间、token消耗数。测试结果显示:
- 在领域内表现良好的开源微调模型在领域外任务执行上展现出极其严重的OOD性能下降,表现远不如基于闭源模型的智能体;
- 由于基座模型和训练数据的原因,GUI Agent在中文任务上的表现弱于英文任务;
- 基座模型在跨app复杂任务上的表现显著弱于单app简单任务;
- 调用闭源模型api、设计多流程决策、多智能体合作等精细prompt策略能提高表现,但同时也增加了执行时间和token的开销。
总的来说,移动端GUI智能体的评估经历了从单步动作预测到端到端任务成功率测评,从分布内任务到通用任务泛化能力,从简单任务到跨App,甚至跨平台(移动端+PC端)的演变。测试结果表明,无论是开源模型还是闭源模型,在高效、泛化地执行GUI操作任务方面还有较大差距。尤其是开源模型,因训练数据多样性缺乏而导致的OOD性能下降问题尤其显著。此外,不同智能体实现中输入模态、形式和输出动作空间的差异也为测评基准的搭建带来挑战。因此,我们期待未来能有更加统一、规范的动作空间和任务测试形式,以推动GUI智能体的进一步发展。
移动端GUI智能体的安全风险
随着GUI性能的持续增强,其潜在的安全风险也愈发受到关注。研究工作EnvDistrac讨论了环境中的干扰带来的风险,即智能体是否会被环境中的信息所诱导,忘记原始指令。研究者构建了弹框、搜索、推荐和聊天四种常见的攻击场景,插入与任务无关的攻击指令,发现在有风险的环境中,智能体容易受到干扰,不仅会放弃原始用户目标还可能做出不忠实的行为。
杨笛一团队针对OS智能体设计了一种新的弹窗攻击的方法,利用Attention Hook(注意力钩子)、Instruction(指令)、Info Banner(信息横幅)等多种弹窗攻击机制使Claude的计算机操作表现大幅下降。这些工作揭示了在大规模部署使用GUI智能体之前,我们需要更强大的安全措施。
移动端GUI智能体的未来展望
从前文的技术分析中,我们可以总结出移动端GUI智能体面临的几大挑战:
- 闭源模型导致的高执行成本和开销:采用闭源模型api及多流程、多智能体决策机制,会显著增加任务决策时间和token消耗,难以应用于实际场景;
- 开源模型的OOD性能瓶颈:虽然经过GUI训练增强后的开源模型在领域内表现优异,甚至优于GPT-4o等SoTA闭源模型,但在领域外数据上却展现出严重的OOD性能下降,泛化性能较差。传统的基于行为克隆(Behavior Cloning,BC)的微调方法不足以构建具有强大泛化性能的GUI操作智能体;
- 对后台及标注信息的过度依赖:现有的决策范式和框架多依赖于系统后台信息和外部工具标注信息,这限制了智能体在通用领域外任务以及微信小程序、IOS系统等难以获得后台信息的场景下的表现;
- 数据构造的低效与不可扩展性:目前主流的GUI数据集,尤其是操作序列数据集,大都依赖人类众包标注得到,数据生产效率低、成本高、可扩展性差;
- 复杂任务的规划、执行能力弱:在执行跨App、长序列,复合任务等复杂GUI任务时成功率显著偏低;
- 对复杂GUI场景的理解能力欠缺;
- 很容易被环境注入攻击劫持,存在安全风险。
从这些挑战出发,我们可以展望这一技术领域的未来发展方向:
- 端云协同机制:发挥云端模型高性能和端侧模型高效、保护隐私的优势,设计端云协同工作的机制,平衡效率和性能;
- 轻量化模型GUI操作能力:通过知识蒸馏、高效微调、混合结构等方法让轻量化小模型拥有GUI操作能力;
- 自主数据合成与探索:统建智能体通过自主探索、分享、记忆等机制掌握工具、适应新环境的能力,自动合成轨迹数据;
- 文生图技术辅助数据构建:通过文生图技术模拟app界面并构建数据,减轻对实际交互式环境中收集数据的依赖;
- 规划、推理、错误分析机制的优化:引入长程规划、过程监督、自我反思及基于搜索的复杂推理等机制,进一步提高智能体在复杂任务中的表现;
- 智能体行为安全对齐:构建用户-智能体-环境的三方安全对齐机制,完善人机交互、隐私保护等现实问题。
参考资料:
- https://arxiv.org/abs/2312.13771
- https://arxiv.org/abs/2307.10088
- https://arxiv.org/abs/2406.03679
- https://arxiv.org/abs/2405.14573
- https://arxiv.org/abs/2309.11436
- https://arxiv.org/abs/2311.07562
- https://arxiv.org/abs/2403.02713
- https://arxiv.org/abs/2312.08914
- https://arxiv.org/abs/2409.14818
- https://arxiv.org/abs/2409.12191
- https://arxiv.org/abs/2410.23218
- https://arxiv.org/abs/2402.11941
- https://arxiv.org/abs/2406.11896
- https://arxiv.org/abs/2408.07199
- https://arxiv.org/abs/2408.15978
- https://arxiv.org/abs/2402.07939
- https://arxiv.org/abs/2401.10935
- https://arxiv.org/abs/2410.05243
- https://arxiv.org/abs/2410.1516