一、项目介绍
1、背景介绍
在互联网、移动互联网的带动下,教育逐渐从线下走向线上,在线教育近几年一直处于行业的风口浪尖,那随着基础设施的不断完善,用户需求也发生不少变化,因此传统教育机构、新兴互联网企业都在探索在线教育的最佳模式。随着在线教育的发展和普及,越来越多的选择在线教育,越来越多的公司也加入的竞争行列中。但是学生个人情况不同,影响学习效果/考试成绩的因素也众多,那么如何充分利用现有数据入对数据进行价值挖掘,找出影响学生学习效果/考试成绩的关键因素,并加以提升或改进,以提高教学效果,改善教学品质,提升学生考试成绩,这一需求已经成为各大在线教育企业亟需解决的问题也是广大学子的共同诉求。
2、划分业务模块
本项目主要分为 4 个业务模块:数据模拟、实时处理、离线处理、推荐模型。其中涵盖了 Spark Core、Structured Streaming、Mlib、数据转储等知识点。后续将按照业务 流程,依次详细讲解
3、项目架构图
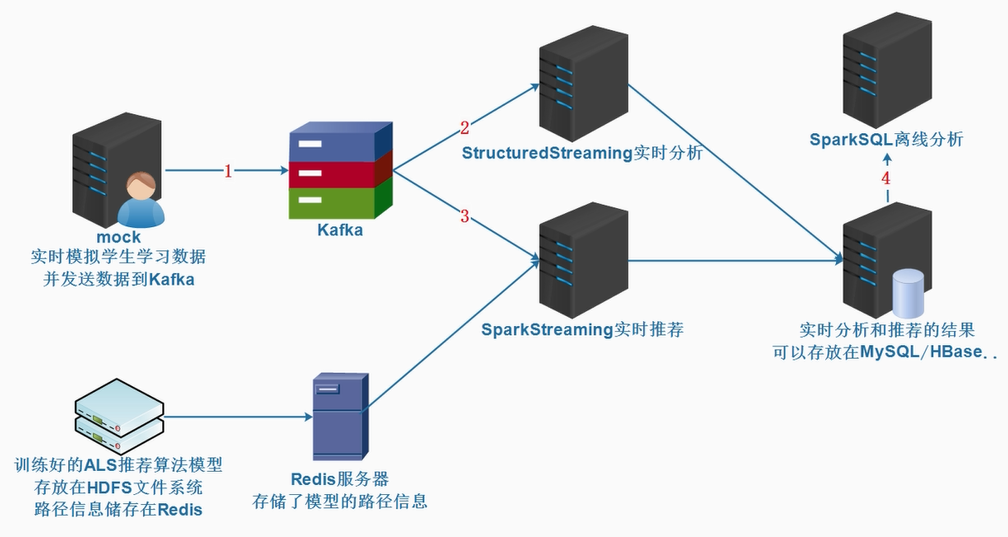
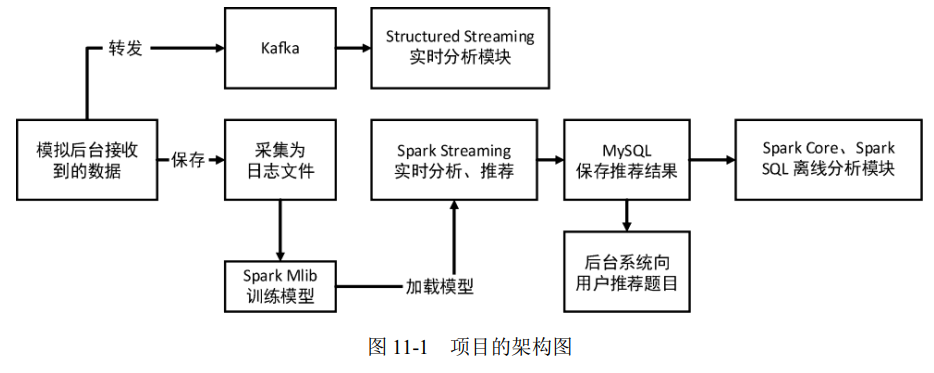
二、项目创建
1、 创建项目
2、创建目录

三、模拟数据的生成
导入包:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.bigdata</groupId>
<artifactId>KafkaProject</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>org.apache.kafka</groupId>
<artifactId>kafka-clients</artifactId>
<version>3.0.0</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>1.18.24</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>2.0.50</version>
</dependency>
</dependencies>
</project>编写实体类:
package com.bigdata.mock;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import java.sql.Timestamp;
@Data
@NoArgsConstructor
@AllArgsConstructor
public class Answer {
String student_id;// 学生id
String textbook_id;//教材id
String grade_id;//年级
String subject_id;// 学科
String chapter_id;//章节
String question_id;// 题目
int score; //得分
String answer_time;// 作答时间
Timestamp ts;// 时间戳
}编写 java 代码:
package com.bigdata.mockedu;
import com.alibaba.fastjson2.JSON;
import com.bigdata.moni.DeviceData;
import org.apache.kafka.clients.producer.KafkaProducer;
import org.apache.kafka.clients.producer.ProducerConfig;
import org.apache.kafka.clients.producer.ProducerRecord;
import java.io.*;
import java.sql.Timestamp;
import java.text.SimpleDateFormat;
import java.util.*;
public class Simulator {
// 教材ID
private static String[] arr2 = {"TextBookID_1", "TextBookID_2"};
// 年级ID
private static String[] arr3 = {"GradeID_1", "GradeID_2", "GradeID_3", "GradeID_4", "GradeID_5", "GradeID_6"};
// 科目ID
private static String[] arr4 = {"SubjectID_1_Math", "SubjectID_2_Chinese", "SubjectID_3_English"};
// 章节ID
private static String[] arr5 = {"ChapterID_chapter_1", "ChapterID_chapter_2", "ChapterID_chapter_3"};
static List<String> stuList = new ArrayList<String>();
static {
for (int i = 1; i <= 50; i++) {
stuList.add("StudentID_" + i);
}
}
static List<String> questionList = new ArrayList<String>();
static {
for (int i = 1; i <= 20; i++) {
questionList.add("QuestionID_" + i);
}
}
// 编写一个方法,调用一次就获取一个问答数据
public static Answer getAnswer(){
Random random = new Random();
int stuIndex = random.nextInt(stuList.size());
String studentId = stuList.get(stuIndex);
int textBookIndex = random.nextInt(arr2.length);
String textBookId = arr2[textBookIndex];
String gradeID = arr3[random.nextInt(arr3.length)];
String subjectID = arr4[random.nextInt(arr4.length)];
String chapterID = arr5[random.nextInt(arr5.length)];
String questionId = questionList.get(random.nextInt(questionList.size()));
int score = random.nextInt(101);
long ts = System.currentTimeMillis();
Timestamp timestamp = new Timestamp(ts);
Date date = new Date();
SimpleDateFormat dateFormat = new SimpleDateFormat("yyyy-MM-dd HH:mm:ss");
String answerTime = dateFormat.format(date);
Answer answer = new Answer(studentId,textBookId,gradeID,subjectID,chapterID,questionId,score,answerTime,timestamp);
return answer;
}
public static void main(String[] args) throws Exception{
/*Properties properties = new Properties();
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"bigdata01:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");*/
//KafkaProducer<String, String> kafkaProducer = new KafkaProducer<String, String>(properties);
File file = new File("data/output1/question_info.json");
System.out.println(file.getAbsolutePath());
FileWriter writer = new FileWriter(file);
for (int i = 0; i < 2000; i++) {
Answer answer = getAnswer();
String answerJson = JSON.toJSONString(answer);
System.out.println(answerJson);
//Thread.sleep(1000);
writer.write(answerJson+"\n");
writer.flush();
//ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("dhedu",answerJson);
//kafkaProducer.send(producerRecord);
}
writer.close();
}
}运行结果:

其中一条数据样例:
{
"answer_time":"2024-11-11 22:00:20",
"chapter_id":"章节ID_chapter_2",
"grade_id":"年级ID_4",
"question_id":"题目ID_1718",
"score":7,
"student_id":"学生ID_22",
"subject_id":"科目ID_2_语文",
"textbook_id":"教材ID_2",
"ts":1731333620008
}四、实时发送数据到 Kafka
一般情况下,用户的答题数据会通过 HTTP 请求发送至后台服务器。接着,后台需要通过 Kafka 生产者,将该数据转发至 Kafka。
1. 创建 Kafka 主题
在 Kafka 集群正常工作后,创建 test_topic_learning_1 主题,命令如下:
kafka-topics.sh --bootstrap-server shucang:9092 --topic edu --create --replication-factor 1 --partitions 12. 创建 Kafka 生产者
(1)创建 ProducerThreadTest 类,在该类中实现向 Kafka 发送数据
package com.bigdata.mockedu;
import com.alibaba.fastjson.JSON;
import org.apache.kafka.clients.producer.*;
import java.util.Properties;
import java.util.concurrent.*;
class KafkaProducerThread implements Runnable{
Properties properties = new Properties();
KafkaProducer<String, String> kafkaProducer =null;
// 这个里面肯定有给哪个服务器哪个topic发消息
// 设置连接kafka集群的ip和端口
{
properties.put(ProducerConfig.BOOTSTRAP_SERVERS_CONFIG,"shucang:9092");
properties.put(ProducerConfig.KEY_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
properties.put(ProducerConfig.VALUE_SERIALIZER_CLASS_CONFIG,
"org.apache.kafka.common.serialization.StringSerializer");
kafkaProducer = new KafkaProducer<String, String>(properties);
}
@Override
public void run() {
while(true){
Answer answer = Simulator.getAnswer();
String jsonStr = JSON.toJSONString(answer);
ProducerRecord<String, String> producerRecord = new ProducerRecord<String, String>("edu",jsonStr);
kafkaProducer.send(producerRecord, new Callback() {
@Override
public void onCompletion(RecordMetadata metadata, Exception e) {
if (e == null) {
System.out.println("当前分区-偏移量:" + metadata.partition() + "-" + metadata.offset() + "\n数据发送成功:" + jsonStr);
} else {
System.err.println("数据发送失败:" + e.getMessage());
}
}
});
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
}
public class KafkaProducerTest {
/**
* 创建线程的四种方式:
* 1、Thread 继承
* 2、实现Runnable 接口
* 3、Callable 接口
* 4、使用线程池
*/
public static void main(String[] args) throws InterruptedException {
//使用自定义线程池,创建多个线程,发送消息比较快
ExecutorService threadPool = new ThreadPoolExecutor(
5,
10,
2L,
TimeUnit.SECONDS,
new ArrayBlockingQueue<Runnable>(5),
Executors.defaultThreadFactory(),
new ThreadPoolExecutor.DiscardOldestPolicy()
);
//创建5个线程,发送kafka消息
try {
for (int i = 1; i <= 5; i++) {
threadPool.execute(new KafkaProducerThread());
}
} catch (Exception e) {
e.printStackTrace();
} finally {
threadPool.shutdown();
}
}
}(2)运行程序。
使用命令,查看 kafka 数据是否能够正常消费
kafka-console-consumer.sh --bootstrap-server shucang:9092 --topic edu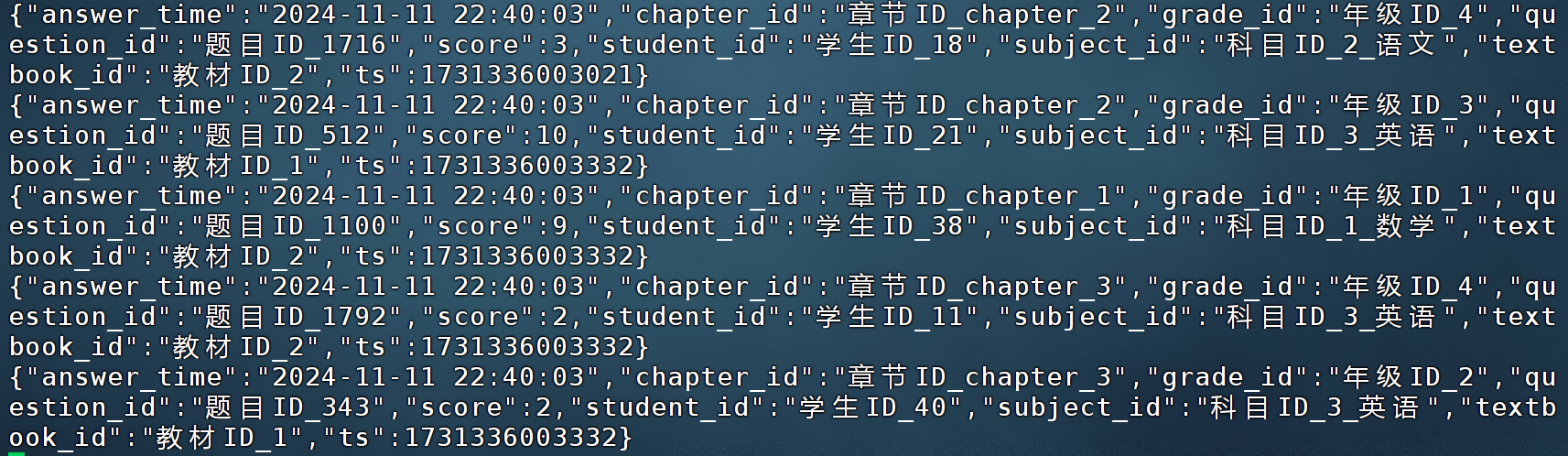

以下是使用 python 操作 kafka 的示例代码:
五、实时分析平台答题数据
本项目中选用 Kafka 作为 Spark 的数据源,随着数据陆续达到 Kafka,Spark 也就可以持续 不断地进行数据分析了。在分析答题数据的场景中,可以包含很多分析目标,而本节主要完成 如下几个目标:
目标一:实时统计热点题(Top10)。
目标二:实时统计答题最活跃的年级。
目标三:实时统计每个科目的热点题(Top10)。
目标四:实时统计每位学生得分最低的题目。
代码如下:
import os
from pyspark.sql import SparkSession
if __name__ == '__main__':
# 配置环境
os.environ['JAVA_HOME'] = 'C:/Program Files/Java/jdk1.8.0_241'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.1'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe' # 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe'
spark = SparkSession.builder.master("local[2]").appName("读取kafka数据并统计指标").config(
"spark.sql.shuffle.partitions", 2).getOrCreate()
readDf = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "shucang:9092") \
.option("subscribe", "edu") \
.load()
#打印表结构
readDf.printSchema()
# 判断dataframe 是否是流数据
print(readDf.isStreaming)
"""
rdd 如何打印:foreach(print)
df 如何打印:show()
df是一个流数据:readDf.writeStream.format("console").outputMode("append").option("truncate", "false").start().awaitTermination()
"""
# readDf.writeStream \
# .format("console") \
# .outputMode("append") \
# .option("truncate", "false") \
# .start().awaitTermination()
jsonDf = readDf.selectExpr("CAST(value AS STRING) as value")
jsonDf.createOrReplaceTempView("temp_json")
# jsonDf.writeStream \
# .format("console") \
# .outputMode("append") \
# .option("truncate", "false") \
# .start().awaitTermination()
# 为了指标统计,需要将这个json变为一个表
answerDf = spark.sql("""
select get_json_object(value,'$.answer_time') answer_time,
get_json_object(value,'$.chapter_id') chapter_id,
get_json_object(value,'$.grade_id') grade_id,
get_json_object(value,'$.question_id') question_id,
cast(get_json_object(value,'$.score') as int) score,
get_json_object(value,'$.student_id') student_id,
get_json_object(value,'$.subject_id') subject_id,
get_json_object(value,'$.textbook_id') textbook_id,
get_json_object(value,'$.ts') ts from temp_json
""")
print(answerDf.isStreaming)
answerDf.createOrReplaceTempView("temp_answer")
# 编写第一个指标 统计top10热点题
result01 = spark.sql("""select question_id,count(1) questionCount
from temp_answer group by question_id
order by questionCount desc limit 10
""")
#result01.writeStream.trigger(processingTime='5 seconds').format("console").outputMode("complete").start().awaitTermination()
# 统计top10答题活跃年级
result02 = spark.sql("""select grade_id,count(1) questionCount
from temp_answer group by grade_id
order by questionCount desc limit 10
""")
#result02.writeStream.trigger(processingTime='5 seconds').format("console").outputMode("complete").start().awaitTermination()
# 统计top10热点题并带上所属科目
result03 = spark.sql("""select question_id,subject_id,count(1) questionCount
from temp_answer group by question_id,subject_id
order by questionCount desc limit 10
""")
#result03.writeStream.trigger(processingTime='5 seconds').format("console").outputMode("complete").start().awaitTermination()
# 统计每个学生的得分最低的题目
# 以下方案不可取,报错 Join between two streaming DataFrames/Datasets is not supported in Complete output mode, only in Append output mode;
# result04=spark.sql("""
# with t as (
# select student_id,min(score) minScore from temp_answer group by student_id
# )
# select t.*,t1.question_id from temp_answer t1 ,t where t.student_id =t1.student_id and t1.score = t.minScore
# """)
# Non-time-based windows are not supported on streaming DataFrames/Datasets;
# dataframe 流不支持开窗函数
# result04=spark.sql("""
# select t1.student_id,t1.question_id,min(t1.score) over(partition by t1.student_id) minScore from temp_answer t1
# """)
# 以下这种方式是可以的,但是结果不对,因为第一个数据不一定是分数最低的题目
# 第一个参数是这一批数据,第二个参数是批次号
def getMinScore(df,batch_id):
# 此处的df 是一个 静态的数据 DataFrame
# df.createOrReplaceTempView("temp_answer2")
# spark.sql("""
# select * from temp_answer2
# """).show()
df.show()
print(df.isStreaming)
import pyspark.sql.functions as F
#minDf = df.groupBy("student_id").min("score")
minDf = df.groupBy("student_id").agg(F.min("score").alias("min_score"))
minDf.createOrReplaceTempView("student_min_score")
minDf.show()
resultDf = df.join(minDf,"student_id")
resultDf.show()
#resultDf.createOrReplaceTempView("result_answer")
resultDf.where("score=min_score").select("student_id","question_id","min_score").show()
answerDf.writeStream.foreachBatch(getMinScore).outputMode("append").start().awaitTermination()
#result04.writeStream.trigger(processingTime='5 seconds').format("console").outputMode("append").start().awaitTermination()
# 以下这个语法是可以的,结果不对,因为第一个数据不一定是分数最低的题目
# result04=spark.sql("""
# select t1.student_id,min(score),collect_list(question_id)[0] from
# temp_answer t1
# group by t1.student_id
# """)
#result04.writeStream.trigger(processingTime='5 seconds').format("console").outputMode("complete").start().awaitTermination()
spark.stop()六、实时推荐给学生易错题
使用训练好的ALS推荐算法模型给学生推荐题目(先直接用模型,后续再做补充讲解)如:
一个学生正在做题.上报了一条实时信息到实时推荐系统:
学生Id 110,题目id 119,score 5分
那么这时候可以根据这条信息直接使用训练好的推荐模型,给该学生推荐其他的易错题如:
学生Id 110,题目id 119,score 5分:推荐列表: 题目id 120,题目id 130,题目id 140...
至于为什么推荐题目id 120,题目id 130,题目id 140是由训练好的推荐模型决定的,先直接使用该模型后续再做补充讲。
安装 redis:
pip install redispython 操作 redis 操作示例代码
import redis
# 连接到本地Redis,默认端口是6379
# 如果Redis服务器设置了密码,或者你连接的是远程Redis服务器,则需要使用对应的参数
r = redis.Redis(host='localhost', port=6379, db=0)
# 设置键值
r.set('my_key', 'Hello, Redis!')
# 获取键值
value = r.get('my_key')
print(value.decode('utf-8')) # 输出: Hello, Redis!
# 删除键
r.delete('my_key')
# 使用哈希表
hash_name = 'my_hash'
r.hset(hash_name, 'field1', 'value1')
r.hset(hash_name, 'field2', 'value2')
print(r.hget(hash_name, 'field1')) # 输出: b'value1'
# 列表操作
list_name = 'my_list'
r.rpush(list_name, 'value1')
r.rpush(list_name, 'value2')
print(r.lrange(list_name, 0, -1)) # 输出: [b'value1', b'value2']
# 集合操作
set_name = 'my_set'
r.sadd(set_name, 'value1')
r.sadd(set_name, 'value2')
print(r.smembers(set_name)) # 输出: {b'value1', b'value2'}
# 有序集合操作
zset_name = 'my_zset'
r.zadd(zset_name, {'value1': 1})
r.zadd(zset_name, {'value2': 2})
print(r.zrange(zset_name, 0, -1)) # 输出: [b'value1', b'value2']
# 发布/订阅
pubsub = r.pubsub()
r.publish('my_channel', 'Hello, Redis!')
# 订阅my_channel
pubsub.subscribe('my_channel')
for message in pubsub.listen():
print(message)
import os
import time
from os import truncate
import redis
from pyspark.ml.evaluation import RegressionEvaluator
from pyspark.ml.recommendation import ALS
from pyspark.sql import SparkSession
if __name__ == '__main__':
os.environ['JAVA_HOME'] = 'C:/Program Files/Java/jdk1.8.0_241'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.1'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe' # 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe'
os.environ['HADOOP_USER_NAME'] = 'root'
os.environ['file.encoding'] = 'UTF-8'
# 准备环境
spark = SparkSession.builder.appName("电影推荐案例")\
.master("local[*]").config("spark.sql.shuffle.partitions","4").getOrCreate()
#读取数据,然后切割数据
df1 = spark.read.json("D:\BD240701\donghu_workspace\KafkaProject\data\output\question_info.json")
df1.printSchema()
print(df1.take(10))
df1.createOrReplaceTempView("temp_json")
df2 = spark.sql("""
select
cast(split(student_id,'_')[1] as int) student_id,
cast(split(question_id,'_')[1] as int) question_id,
if(score >80,1,if(score>60,2,if(score>40,3,4))) score_fix
from temp_json
""")
# 将我们的数据分为两部分,80% 用于训练,20% 用于测试
train_data, test_data = df2.randomSplit([0.8, 0.2],11)
"""
rank 可以理解为:可以理解为Cm*n = Am*k X Bk*n 里面的k的值
maxIter:最大迭代次数
alpha : 步长
"""
als = ALS(userCol="student_id",
itemCol="question_id",
ratingCol="score_fix",
rank=20,
maxIter=15,
alpha=0.1)
# 使用训练集训练模型
model = als.fit(train_data).setColdStartStrategy("drop")
# 将训练好的模型进行数据推荐
df3 = model.recommendForAllUsers(20)
df3.show(truncate=False)
# 误差判断
# 7.对测试集进行预测//transform返回值中包含原本的rating和预测的rating
predictions = model.transform(test_data)
# 8.使用RMSE(均方根误差)评估模型误差
# 求误差:均方根误差 = (sum((rating-prediction)^2)/n)^(1/2)
evaluator = RegressionEvaluator() \
.setMetricName("rmse") \
.setLabelCol("score_fix") \
.setPredictionCol("prediction")
rmse = evaluator.evaluate(predictions)
r = redis.Redis(host='localhost', port=6379, db=0)
print(rmse)
if rmse <= 1.5:
print("模型效果好")
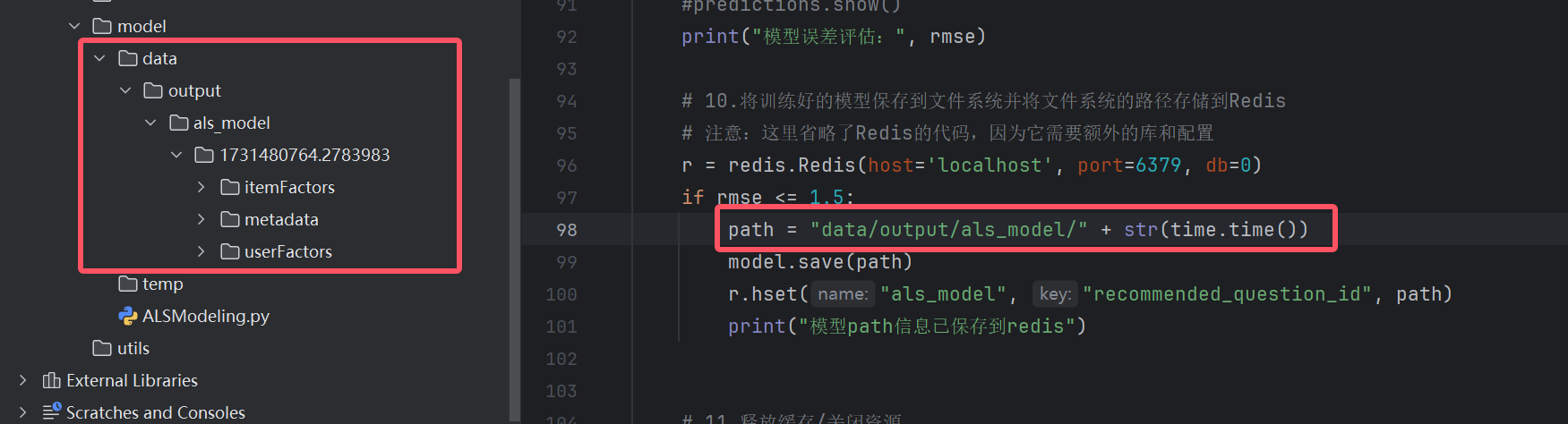
path = r"D:/BD240701/donghushui_workspace/pythonProject/SmartEduProject/data/output/als_model/" + str(time.time())
model.save(path)
# hash 类型
r.hset("als_model", "recommended_question_id", path)
print("模型path信息已保存到redis")
else:
print("模型效果不好")
# 11.释放缓存/关闭资源
df2.unpersist()
train_data.unpersist()
test_data.unpersist()
spark.stop()推荐结果如下:
|student_id|recommendations |
|50 |[{574, 2.8823812}, {438, 2.8540382}, {1491, 2.823134}, {1148, 2.7908237}, {1237, 2.773547}, {1860, 2.74146}, {1041, 2.7231498}, {712, 2.6073318}, {1306, 2.551479}, {471, 2.551479}, {332, 2.551479}, {1686, 2.538269}, {679, 2.481941}, {1120, 2.4400349}, {2138, 2.426793}, {1464, 2.4180536}, {1602, 2.3885312}, {836, 2.3885312}, {2032, 2.3824286}, {398, 2.350355}] |
记得启动本地的 redis,运行,redis 中保存了训练的结果集路径

文件中存储了训练的结果集:
接着使用代码进行题目推荐:
import os
import redis
from pyspark.ml.recommendation import ALSModel
from pyspark.sql import SparkSession
if __name__ == '__main__':
# 配置环境
os.environ['JAVA_HOME'] = 'C:/Program Files/Java/jdk1.8.0_241'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.1'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe' # 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe'
spark = SparkSession.builder.master("local[2]").appName("实时题目推荐").config(
"spark.sql.shuffle.partitions", 2).getOrCreate()
readDf = spark.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "shucang:9092") \
.option("subscribe", "edu") \
.load()
#打印表结构
readDf.printSchema()
# 判断dataframe 是否是流数据
print(readDf.isStreaming)
"""
rdd 如何打印:foreach(print)
df 如何打印:show()
df是一个流数据:readDf.writeStream.format("console").outputMode("append").option("truncate", "false").start().awaitTermination()
"""
# readDf.writeStream \
# .format("console") \
# .outputMode("append") \
# .option("truncate", "false") \
# .start().awaitTermination()
jsonDf = readDf.selectExpr("CAST(value AS STRING) as value")
jsonDf.createOrReplaceTempView("temp_json")
# 为了指标统计,需要将这个json变为一个表
answerDf = spark.sql("""
select get_json_object(value,'$.answer_time') answer_time,
get_json_object(value,'$.chapter_id') chapter_id,
get_json_object(value,'$.grade_id') grade_id,
get_json_object(value,'$.question_id') question_id,
cast(get_json_object(value,'$.score') as int) score,
split(get_json_object(value,'$.student_id'),'_')[1] student_id,
get_json_object(value,'$.subject_id') subject_id,
get_json_object(value,'$.textbook_id') textbook_id,
get_json_object(value,'$.ts') ts from temp_json
""")
print(answerDf.isStreaming)
answerDf.createOrReplaceTempView("temp_answer")
# 获取训练好的模型
r = redis.Redis(host='localhost', port=6379, db=0)
path = r.hget("als_model", "recommended_question_id")
print(path) # 获取的值是bytes类型,需要解码为字符串
print(path.decode('utf-8'))
model = ALSModel.load(path.decode('utf-8'))
# 将这一批的学生ID提取出来,形成一个新的df
# studentIdDF = spark.sql("""
# select student_id from temp_answer
# """)
# print(studentIdDF.isStreaming)
# studentIdDF.writeStream \
# .format("console") \
# .outputMode("append") \
# .option("truncate", "false") \
# .start().awaitTermination()
#recommendDF = model.recommendForUserSubset(studentIdDF, 10)
#print(recommendDF.isStreaming)
#recommendDF.printSchema()
#recommendDF.createOrReplaceTempView("temp_recommend")
#recommendDF.rdd
# spark.sql("""
# select * from temp_recommend
# """).writeStream.format("console").outputMode("complete").option("truncate", "false").start().awaitTermination()
# LeftSemi join with a streaming DataFrame/Dataset on the right and a static DataFrame/Dataset on the left is not supported;
#recommendDF.writeStream.format("console").outputMode("complete").option("truncate", "false").start().awaitTermination()
def recommendQuestions(df,batch_id):
df.show()
print(batch_id)
print(df.isStreaming)
# 此处的df不能创建表,编写sql,会报表不存在的异常,解决方案是使用dsl写法
studentIdDF= df.select("student_id").distinct()
studentIdDF.show()
recommendDF = model.recommendForUserSubset(studentIdDF, 10)
print(recommendDF.isStreaming)
recommendDF.printSchema()
recommendDF.createOrReplaceTempView("temp_recommend")
recommendDF = spark.sql("""
select student_id,concat_ws(',',collect_list(concat('QuestionID_',stu.question_id))) recommends from temp_recommend lateral view explode(recommendations) t as stu
group by student_id
""")
resultDf = df.join(recommendDF,"student_id")
# 真实的情况下,需要把数据放入hbase等数据库中,做练习的时候,把数据放入mysql即可
# 数据库需要事先创建好,t_recommended 无需提前创建
if resultDf.count() > 0:
resultDf.write.format("jdbc") \
.mode('append') \
.option("url", "jdbc:mysql://localhost:3306/edu") \
.option("driver", "com.mysql.cj.jdbc.Driver") \
.option("dbtable", "t_recommended") \
.option("user", "root") \
.option("password", "123456").save()
answerDf.writeStream.foreachBatch(recommendQuestions).trigger(processingTime='5 seconds').start().awaitTermination()
spark.stop()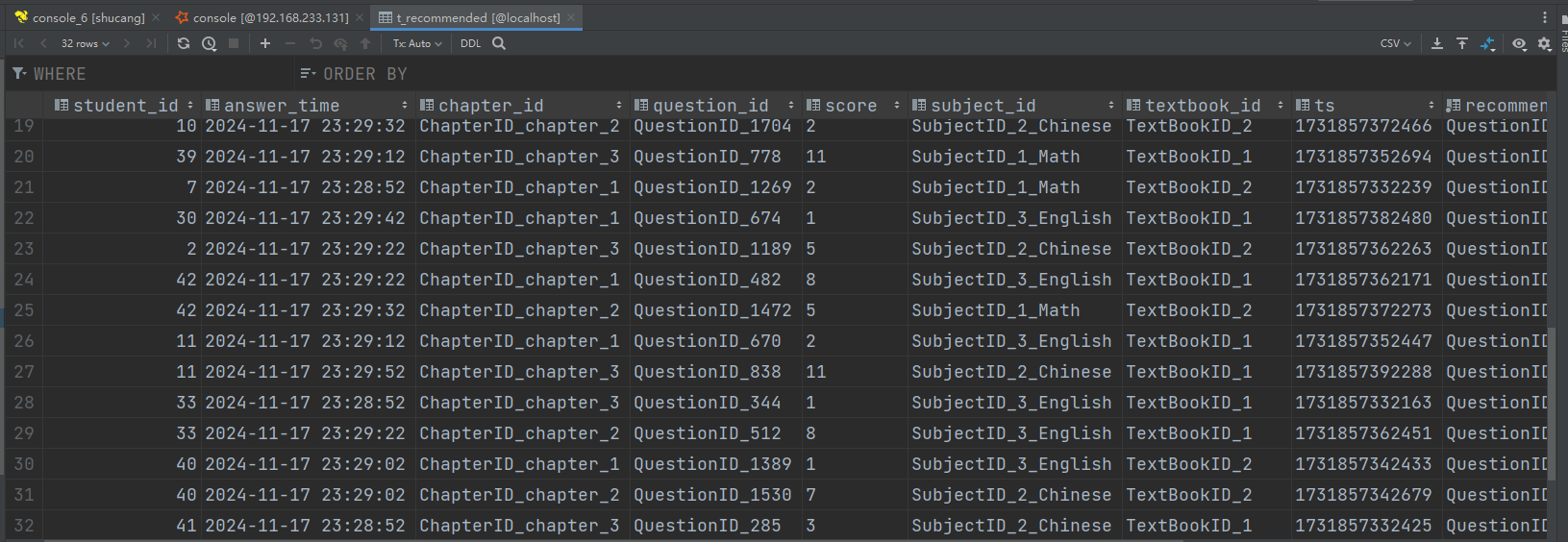
七、离线数据分析
在 mysql 的数据集上,进行指标分析,前提是:你的 mysql 已经陆续有数据了。
需求1:各科目热点题分析
要求:找到Top50热点题对应的科目,然后统计这些科目中,分别包含这几道热点题的条目数
举例:
热点题
题号 热度 学科
1 100 数学
2 99 数学
3 98 语文
最终结果:
学科 热点题数量
数学 2
语文 1
需求2:各科目推荐题分析
要求:找到Top20热点题对应的推荐题目,然后找到推荐题目对应的科目,并统计每个科目分别包含推荐题目的条数
举例:
热点题对应的学科和推荐题号
题号 热度 学科 推荐题号
1 100 数学 2,3,4
2 99 数学 3,4,5
3 98 语文 6,7,8
最终结果
学科 推荐题数量
数学 4道
语文 3道
import os
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField, StringType, DoubleType, LongType
if __name__ == '__main__':
# 配置环境
os.environ['JAVA_HOME'] = 'C:/Program Files/Java/jdk1.8.0_241'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.1'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe' # 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe'
# 得到sparkSession对象
spark = SparkSession.builder.master("local[2]").appName("离线数据分析").config("spark.sql.shuffle.partitions", 2).getOrCreate()
# jdbc的另一种写法
jdbcDf = spark.read.format("jdbc") \
.option("driver", "com.mysql.cj.jdbc.Driver") \
.option("url", "jdbc:mysql://localhost:3306/edu") \
.option("dbtable", "t_recommended") \
.option("user", "root") \
.option("password", "123456").load()
jdbcDf.show()
jdbcDf.createOrReplaceTempView("answer_recommend")
"""
找到Top50热点题对应的科目,然后统计这些科目中,分别包含这几道热点题的条目数
"""
# spark.sql("""
# with t as (
# select question_id,count(1) totalNum from answer_recommend group by question_id order by totalNum desc limit 50
# ),t2 as (
# select t.question_id,t.totalNum,subject_id from t inner join answer_recommend on t.question_id = answer_recommend.question_id
# )
# select * from t2
# """).show()
spark.sql("""
with t as(
select distinct question_id,subject_id,count(1) over(partition by question_id,subject_id) totalNum from answer_recommend
),t2 as(
select * from t order by totalNum desc limit 50
)
select subject_id,count(distinct question_id) question_num from t2 group by subject_id
""").show()
# 找到Top20热点题对应的推荐题目,然后找到推荐题目对应的科目,并统计每个科目分别包含推荐题目的条数
spark.sql("""
with t as(
select distinct question_id,subject_id,count(1) over(partition by question_id,subject_id) totalNum from answer_recommend
),t2 as(
select * from t order by totalNum desc limit 20
),t3 as(
select explode(split(recommends,',')) question_id from t2 join answer_recommend on t2.question_id = answer_recommend.question_id
and t2.subject_id = answer_recommend.subject_id
),t4 as(
select t3.question_id,a.subject_id from t3 left join answer_recommend a on t3.question_id = a.question_id
),t5 as(
select subject_id,count(distinct question_id) question_num from t4 group by subject_id
)
select * from t5
""").show(1000)
# 关闭
spark.stop()八、推荐系统算法入门
1)什么是推荐系统
推荐系统: 数据 + 挖掘/训练 ---> 模型/用户的兴趣爱好等特征---> 给用户做推荐
2)应用场景
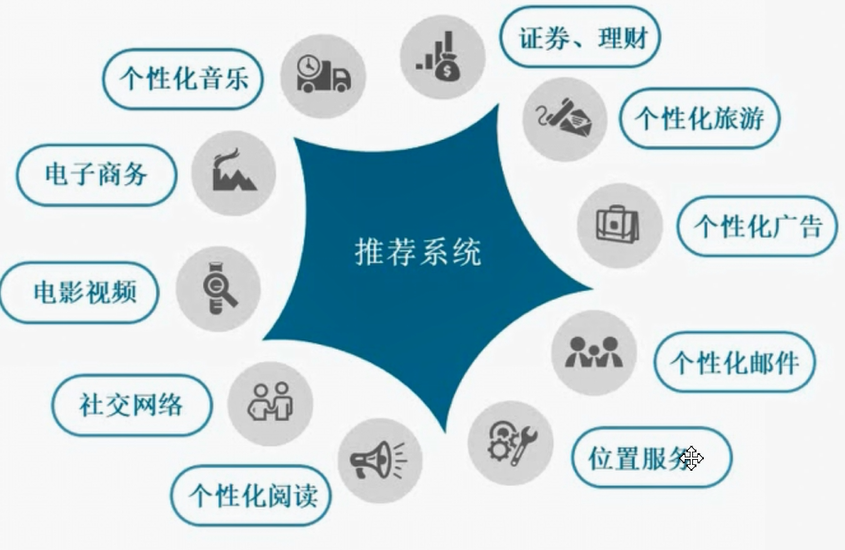
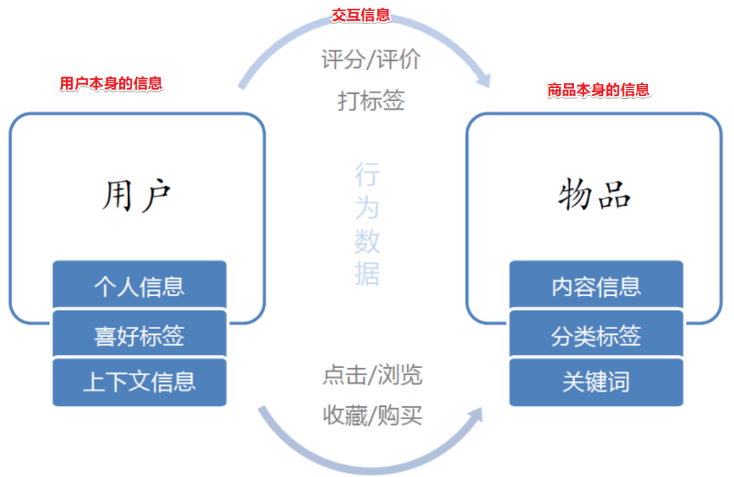
3)推荐系统需要的数据
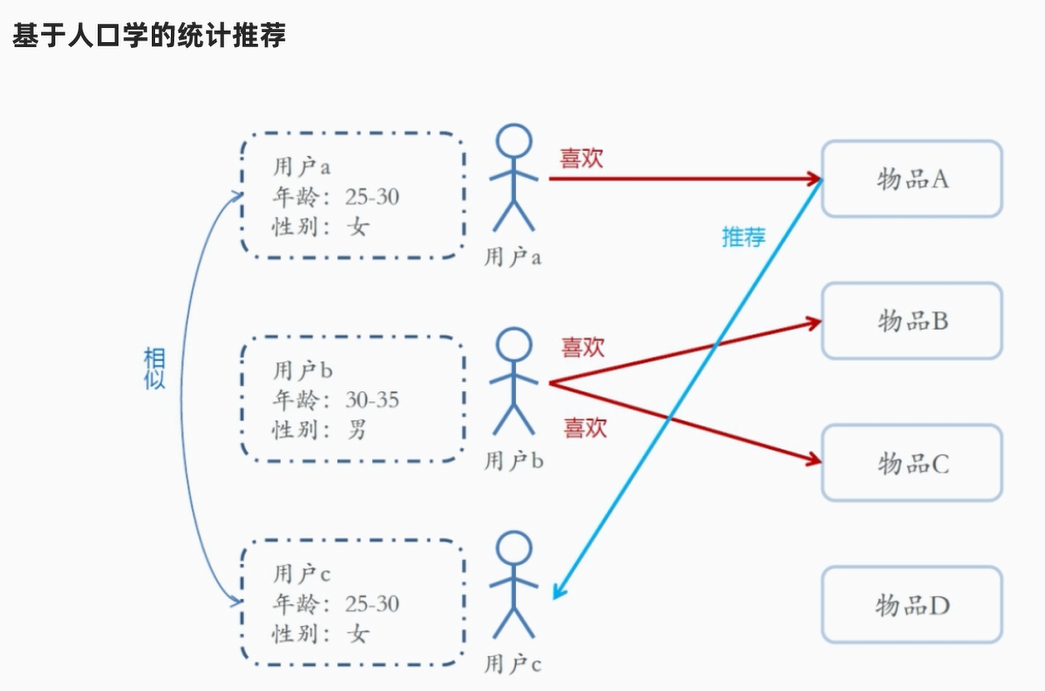
4)推荐算法分类

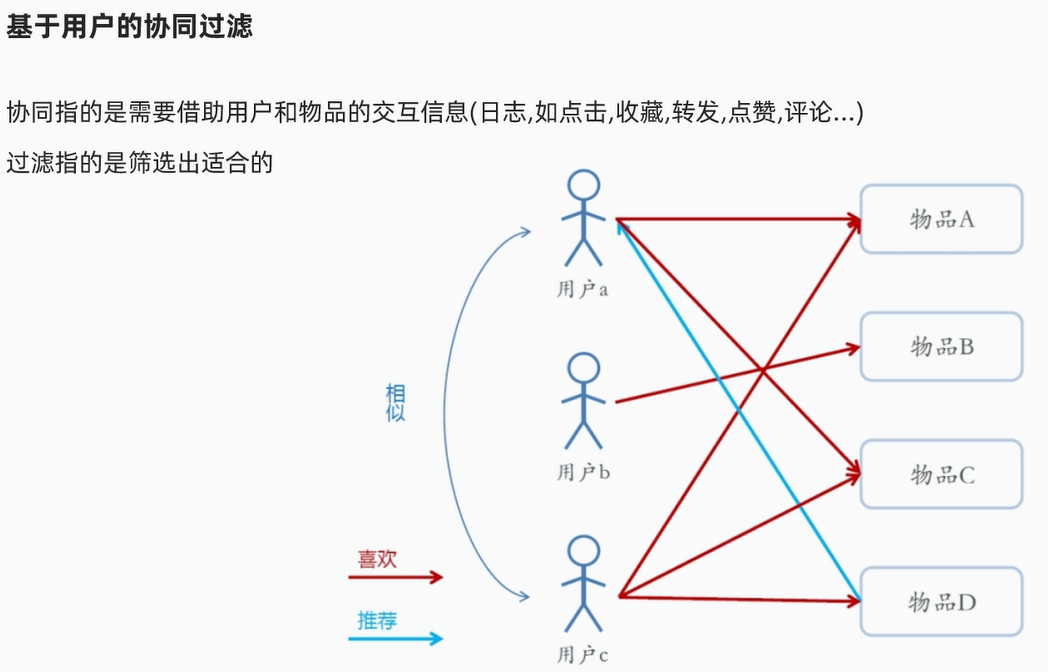
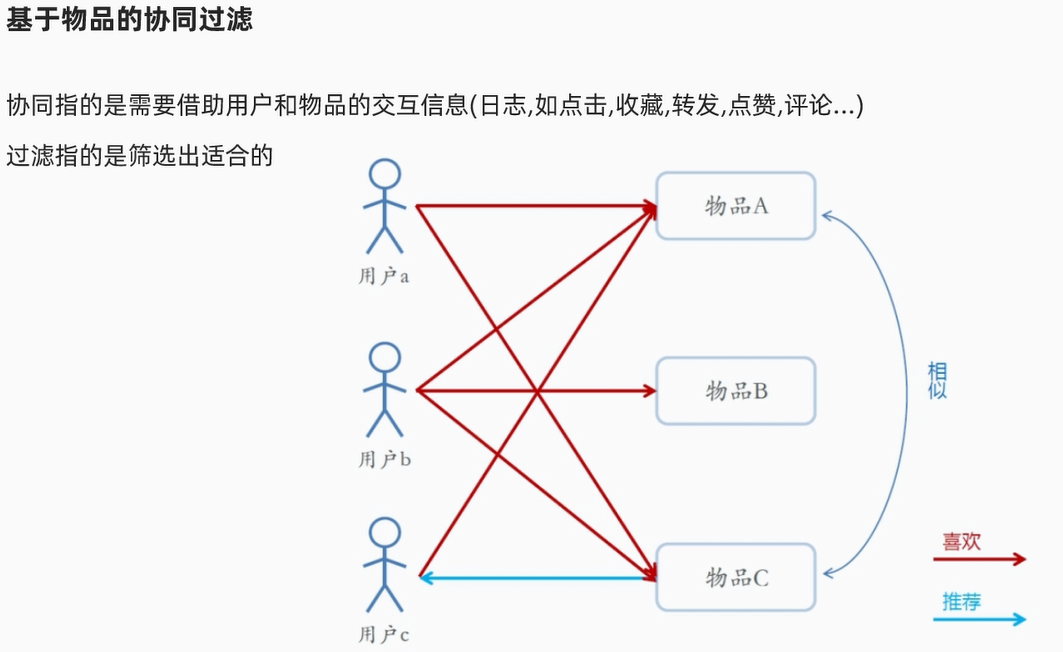
目前来说都是混合推荐的。
5)ALS 推荐算法
数学知识补充:矩阵


总结来说:
Am*k X B k*n = Cm*n ----至于乘法的规则,是数学问题, 知道可以乘即可,不需要我们自己计算
反过来
Cm*n = Am*k X Bk*n ----至于矩阵如何拆分/如何分解,是数学问题,知道可以拆/可以分解即可
ALS 推荐算法案例:电影推荐
需求:
大数据分析师决定使用SparkMLlib的ALS(Alternating Least Squarcs)推荐算法,采用这种方式可以解决稀疏矩阵(SparseMatrix)的问题。即使是大量的用户与产品,都能够在合理的时间内完成运算。在使用历史数据训练后,就可以创建模型。
有了模型之后,就可以使用模型进行推荐。我们设计了如下推荐功能,
可以增加会员观看电影的次数:
针对用户推荐感兴趣的电影: 以针对每一位会员,定期发送短信或E-mail或会员登录时,推荐给他/她可能会感兴趣的电影。
针对电影推荐给感兴趣的用户:当想要促销某些电影时,也可以找出可能会对这些电影感兴趣的会员,并且发送短信或E-mail.
数据引入:
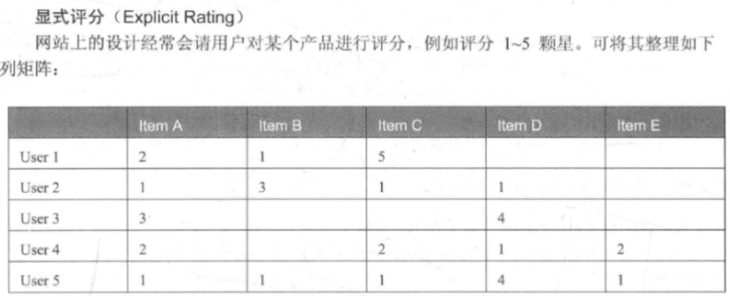
第一种:显示评分数据
现在我们手里有用户对电影,那么接下来就可以使用SparkMLlib中提供的一个基于隐语义模型的协同过滤推荐算法-ALS
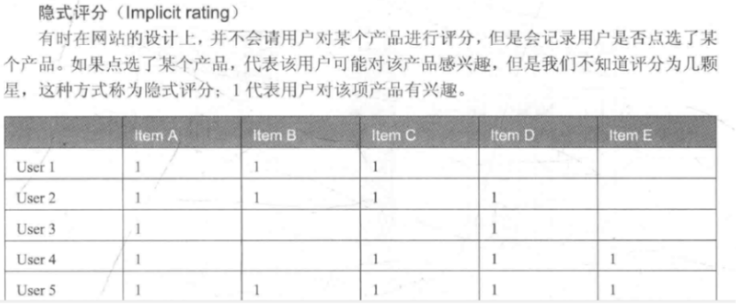
第二种:隐式评分(Implicit rating)
有时在网站的设计上,并不会请用户对某个产品进行评分,但是会记录用户是否点选了某个产品。如果点选了某个产品,代表该用户可能对该产品感兴趣,但是我们不知道评分为几颗星,这种方式称为隐式评分;1代表用户对该项产品有兴趣。
具体做法
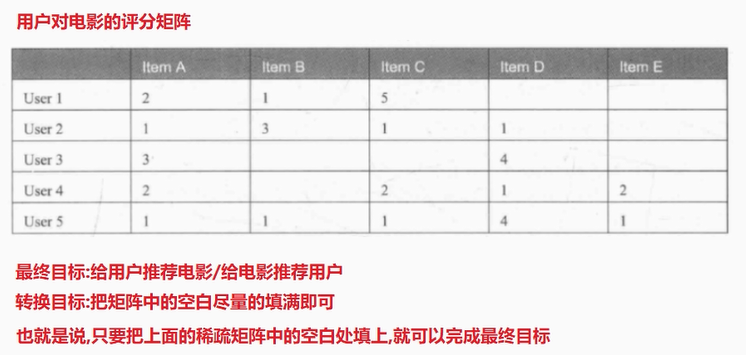
将该评分矩阵进行拆解如下:
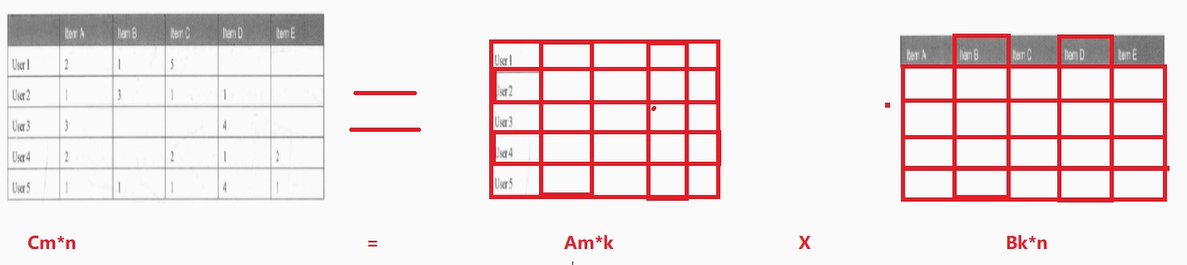
然后进行计算填充:
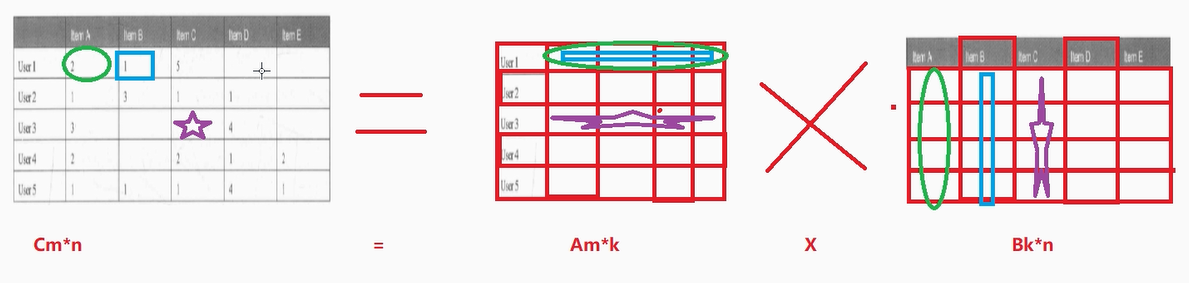
上面已经可以将空白处进行补全了,但是问题是:凭什么补全的数字就能够代表用户对电影的预测评分?
SparkMlLib中的ALS算法:基于隐语义模型的协同过滤算法,认为:
拆分出来的
A矩阵是用户的隐藏的特征矩阵,
B矩阵是物品的隐藏的特征矩阵,
用户之所以会给物品打出相应的评分,是因为用户和物品具有这些隐藏的特征。
代码编写:
import org.apache.spark.SparkContext
import org.apache.spark.ml.recommendation.{ALS, ALSModel}
import org.apache.spark.sql.{DataFrame, Dataset, Row, SparkSession}
object ALSMovieDemoTest {
def main(args: Array[String]): Unit = {
//TODO 0.准备环境
val spark: SparkSession = SparkSession.builder().appName("BatchAnalysis").master("local[*]")
.config("spark.sql.shuffle.partitions", "4")//本次测试时将分区数设置小一点,实际开发中可以根据集群规模调整大小,默认200
.getOrCreate()
val sc: SparkContext = spark.sparkContext
sc.setLogLevel("WARN")
import spark.implicits._
import org.apache.spark.sql.functions._
//TODO 1.加载数据并处理
val fileDS: Dataset[String] = spark.read.textFile("data/input/u.data")
val ratingDF: DataFrame = fileDS.map(line => {
val arr: Array[String] = line.split("\t")
(arr(0).toInt, arr(1).toInt, arr(2).toDouble)
}).toDF("userId", "movieId", "score")
val Array(trainSet,testSet) = ratingDF.randomSplit(Array(0.8,0.2))//按照8:2划分训练集和测试集
//TODO 2.构建ALS推荐算法模型并训练
val als: ALS = new ALS()
.setUserCol("userId") //设置用户id是哪一列
.setItemCol("movieId") //设置产品id是哪一列
.setRatingCol("score") //设置评分列
.setRank(10) //可以理解为Cm*n = Am*k X Bk*n 里面的k的值
.setMaxIter(10) //最大迭代次数
.setAlpha(1.0)//迭代步长
//使用训练集训练模型
val model: ALSModel = als.fit(trainSet)
//使用测试集测试模型
//val testResult: DataFrame = model.recommendForUserSubset(testSet,5)
//计算模型误差--模型评估
//......
//TODO 3.给用户做推荐
val result1: DataFrame = model.recommendForAllUsers(5)//给所有用户推荐5部电影
val result2: DataFrame = model.recommendForAllItems(5)//给所有电影推荐5个用户
val result3: DataFrame = model.recommendForUserSubset(sc.makeRDD(Array(196)).toDF("userId"),5)//给指定用户推荐5部电影
val result4: DataFrame = model.recommendForItemSubset(sc.makeRDD(Array(242)).toDF("movieId"),5)//给指定电影推荐5个用户
result1.show(false)
result2.show(false)
result3.show(false)
result4.show(false)
}
}如果 使用 python 语言编写需求:
import os
from os import truncate
from pyspark.ml.recommendation import ALS
from pyspark.sql import SparkSession
if __name__ == '__main__':
os.environ['JAVA_HOME'] = 'C:/Program Files/Java/jdk1.8.0_241'
# 配置Hadoop的路径,就是前面解压的那个路径
os.environ['HADOOP_HOME'] = 'D:/hadoop-3.3.1'
# 配置base环境Python解析器的路径
os.environ['PYSPARK_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe' # 配置base环境Python解析器的路径
os.environ['PYSPARK_DRIVER_PYTHON'] = 'C:/ProgramData/Miniconda3/python.exe'
os.environ['HADOOP_USER_NAME'] = 'root'
os.environ['file.encoding'] = 'UTF-8'
# 准备环境
spark = SparkSession.builder.appName("电影推荐案例")\
.master("local[*]").config("spark.sql.shuffle.partitions","4").getOrCreate()
#读取数据,然后切割数据
df1 = spark.read.text("../../../data/input/u.data")
df1.printSchema()
print(df1.take(10))
# 根据\t 切割文件中的数据
def split_data(line):
arr =line.split("\t")
return (int(arr[0]),int(arr[1]),int(arr[2]))
df2 = df1.rdd.map(lambda row:split_data(row.value)).toDF(["userId", "movieId", "score"])
print(df2.take(1))
# 将我们的数据分为两部分,80% 用于训练,20% 用于测试
train_data, test_data = df2.randomSplit([0.8, 0.2])
"""
rank 可以理解为:可以理解为Cm*n = Am*k X Bk*n 里面的k的值
maxIter:最大迭代次数
alpha : 步长
"""
als = ALS(userCol="userId",
itemCol="movieId",
ratingCol="score",
rank=10,
maxIter=10,
alpha=1.0)
# 使用训练集训练模型
model = als.fit(train_data)
# 将训练好的模型进行数据推荐
# df3 = model.recommendForAllUsers(5) # 给所有用户推荐5部电影
# df4 = model.recommendForAllItems(5) # 给所有电影推荐5个用户
# df3.show(truncate=False)
# df4.show(truncate=False)
# 给某个用户推荐电影
df5 = model.recommendForUserSubset(spark.createDataFrame([(653,)],["userId"]),5)
df6 = model.recommendForItemSubset(spark.createDataFrame([(411,)],["movieId"]),5)
# 给某个电影推荐用户
df5.show(truncate=False)
df6.show(truncate=False)
# 如何把df5中的数据提取为 字符串
df5.printSchema()
def getMovieIds(row):
tuijianFilms = []
arr = row.recommendations
for ele in arr:
print(ele.movieId)
tuijianFilms.append(ele.movieId)
print("推荐的电影有:",tuijianFilms)
df5.foreach(getMovieIds)最终结果如下所示:
root
|-- value: string (nullable = true)
[Row(value='196\t242\t3\t881250949'), Row(value='186\t302\t3\t891717742'), Row(value='22\t377\t1\t878887116'), Row(value='244\t51\t2\t880606923'), Row(value='166\t346\t1\t886397596')]
+------+---------------------------------------------------------------------------------------------+
|userId|recommendations |
+------+---------------------------------------------------------------------------------------------+
|12 |[{1643, 5.44792}, {1463, 5.249074}, {1450, 5.1887774}, {64, 5.0688186}, {318, 5.0383205}] |
|13 |[{1643, 4.8755937}, {814, 4.873669}, {963, 4.7418056}, {867, 4.725667}, {1463, 4.6931405}] |
|14 |[{1463, 5.1732297}, {1643, 5.1153564}, {1589, 5.0040984}, {1367, 4.984417}, {1524, 4.955745}]|
|18 |[{1643, 5.213776}, {1463, 5.1320825}, {1398, 4.819699}, {483, 4.6260805}, {1449, 4.6111727}] |
|25 |[{1643, 5.449965}, {1589, 5.017608}, {1463, 4.9372115}, {169, 4.6056967}, {963, 4.5825796}] |
|37 |[{1643, 5.3220835}, {1589, 4.695943}, {1268, 4.610497}, {42, 4.4597883}, {169, 4.4325438}] |
|38 |[{143, 5.9212527}, {1472, 5.595081}, {1075, 5.4555163}, {817, 5.4316535}, {1463, 5.2957745}] |
|46 |[{1643, 5.9912925}, {1589, 5.490053}, {320, 5.175288}, {958, 5.080977}, {1131, 5.067922}] |
|50 |[{838, 4.6296134}, {324, 4.6239386}, {962, 4.567323}, {987, 4.5356846}, {1386, 4.5315967}] |
|52 |[{1643, 5.800831}, {1589, 5.676579}, {1463, 5.6091275}, {1449, 5.2481527}, {1398, 5.164145}] |
|56 |[{1643, 5.2523932}, {1463, 4.8217216}, {174, 4.561838}, {50, 4.5330524}, {313, 4.5247965}] |
|65 |[{1643, 5.009448}, {1463, 4.977561}, {1450, 4.7058015}, {496, 4.6496506}, {318, 4.6017523}] |
|67 |[{1589, 6.091304}, {1643, 5.8771777}, {1268, 5.4765506}, {169, 5.2630634}, {645, 5.1223965}] |
|70 |[{1643, 4.903953}, {1463, 4.805949}, {318, 4.3851447}, {50, 4.3817987}, {64, 4.3547297}] |
|73 |[{1643, 4.8607855}, {1449, 4.804972}, {1589, 4.7613616}, {1463, 4.690458}, {853, 4.6646543}] |
|83 |[{1643, 4.6920056}, {1463, 4.6447496}, {22, 4.567131}, {1278, 4.505245}, {1450, 4.4618435}] |
|93 |[{1643, 5.4505115}, {1463, 5.016514}, {1160, 4.83699}, {1131, 4.673481}, {904, 4.6326823}] |
|95 |[{1643, 4.828537}, {1463, 4.8062463}, {318, 4.390673}, {64, 4.388152}, {1064, 4.354666}] |
|97 |[{1589, 5.1252556}, {963, 5.0905123}, {1643, 5.014373}, {793, 4.8556504}, {169, 4.851328}] |
|101 |[{1643, 4.410446}, {1463, 4.167996}, {313, 4.1381097}, {64, 3.9999022}, {174, 3.9533536}] |
+------+---------------------------------------------------------------------------------------------+
only showing top 20 rows
+-------+------------------------------------------------------------------------------------------+
|movieId|recommendations |
+-------+------------------------------------------------------------------------------------------+
|12 |[{118, 5.425505}, {808, 5.324106}, {628, 5.2948637}, {173, 5.2587204}, {923, 5.2580886}] |
|13 |[{928, 4.5580163}, {808, 4.484994}, {239, 4.4301133}, {9, 4.3891873}, {157, 4.256134}] |
|14 |[{928, 4.7927723}, {686, 4.784753}, {240, 4.771472}, {252, 4.7258406}, {310, 4.719638}] |
|18 |[{366, 3.5298047}, {270, 3.5042968}, {118, 3.501615}, {115, 3.4122925}, {923, 3.407579}] |
|25 |[{732, 4.878368}, {928, 4.8120456}, {688, 4.765749}, {270, 4.7419496}, {811, 4.572586}] |
|37 |[{219, 3.8507814}, {696, 3.5646195}, {366, 3.4811506}, {75, 3.374816}, {677, 3.3565707}] |
|38 |[{507, 4.79451}, {127, 4.5993023}, {137, 4.4605145}, {849, 4.3109775}, {688, 4.298151}] |
|46 |[{270, 4.6816626}, {928, 4.5854187}, {219, 4.4919205}, {34, 4.4880714}, {338, 4.484614}] |
|50 |[{357, 5.366201}, {640, 5.2883763}, {287, 5.244199}, {118, 5.222288}, {507, 5.2122903}] |
|52 |[{440, 4.7918897}, {565, 4.592798}, {252, 4.5657616}, {697, 4.5496006}, {4, 4.52615}] |
|56 |[{628, 5.473441}, {808, 5.3515406}, {252, 5.2790856}, {4, 5.197684}, {118, 5.146353}] |
|65 |[{770, 4.4615817}, {242, 4.3993964}, {711, 4.3992624}, {928, 4.3836145}, {523, 4.365783}] |
|67 |[{887, 4.6947756}, {511, 4.151247}, {324, 4.1026692}, {849, 4.0851464}, {688, 4.0792685}] |
|70 |[{928, 4.661159}, {688, 4.5623326}, {939, 4.527151}, {507, 4.5014353}, {810, 4.4822607}] |
|73 |[{507, 4.8688984}, {688, 4.810653}, {849, 4.727747}, {810, 4.6686435}, {127, 4.6246667}] |
|83 |[{939, 5.135272}, {357, 5.12999}, {523, 5.071391}, {688, 5.034591}, {477, 4.9770975}] |
|93 |[{115, 4.5568433}, {581, 4.5472555}, {809, 4.5035434}, {819, 4.477037}, {118, 4.467347}] |
|95 |[{507, 5.097106}, {688, 4.974432}, {810, 4.950163}, {849, 4.9388885}, {152, 4.897256}] |
|97 |[{688, 5.1705074}, {628, 5.0447206}, {928, 4.9556565}, {810, 4.8580494}, {849, 4.8418307}]|
|101 |[{495, 4.624121}, {67, 4.5662155}, {550, 4.5428996}, {472, 4.47312}, {347, 4.4586687}] |
+-------+------------------------------------------------------------------------------------------+
only showing top 20 rows
+------+------------------------------------------------------------------------------------------+
|userId|recommendations |
+------+------------------------------------------------------------------------------------------+
|196 |[{1463, 5.5212154}, {1643, 5.4587097}, {318, 4.763221}, {50, 4.7338095}, {1449, 4.710921}]|
+------+------------------------------------------------------------------------------------------+
+-------+-----------------------------------------------------------------------------------------+
|movieId|recommendations |
+-------+-----------------------------------------------------------------------------------------+
|242 |[{928, 5.2815547}, {240, 4.958071}, {147, 4.9559183}, {909, 4.7904325}, {252, 4.7793174}]|
+-------+-----------------------------------------------------------------------------------------+
Process finished with exit code 0