Pre-Trained Image Processing Transformer
本文介绍一篇发表在CVPR 2021上的文章,该文章提出了一种基于Transformer的图像处理预训练模型,可以在较小的数据集上进行微调后,直接应用到具体的图像处理任务(如去噪,超分,去雨等)。
随着现代硬件计算能力的大幅提升,在大规模数据集上训练的预训练深度学习模型(如BERT、GPT-3)已经显示出比传统方法更好的效果。这一重大进展主要得益于Transformer及其变体架构的强大表示能力。 在本文中,我们研究了低层次计算机视觉任务(如去噪、超分辨率和去雨)并开发了一种新的预训练模型,称为图像处理Transformer(IPT)。
为了最大限度地挖掘Transformer的潜力,我们采用了知名的ImageNet基准数据集来生成大量的损坏图像对。IPT模型在这些图像上进行训练,具有多头和多尾结构。此外,引入了对比学习,以便更好地适应不同的图像处理任务。因此,经过微调后,该预训练模型可以高效地应用于目标任务。仅使用一个预训练模型,IPT就在各种低层次基准上超越了当前的最新方法。
Chen, Hanting, et al. "Pre-trained image processing transformer." Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 2021.
Introduction
图像处理是更全局的图像分析或计算机视觉系统的低级部分的一个组成部分。 图像处理的结果可以极大地影响后续的高级部分对图像数据的识别和理解。 最近,深度学习已广泛应用于解决低级视觉任务,如图像超分辨率、修复、去雨和着色。 由于许多图像处理任务都是相关的,因此很自然地期望在一个数据集上预训练的模型可以对另一个数据集有帮助。但很少有研究将预训练推广到图像处理任务中。
预训练有可能通过解决以下两个挑战为图像处理任务提供有吸引力的解决方案: 首先,特定于任务的数据可能有限。这个问题在涉及付费数据或数据隐私的图像处理任务中更加严重,例如医学图像和卫星图像。各种不一致的因素(例如相机参数、照明和天气)会进一步扰乱用于训练的捕获数据的分布。 其次,在测试图像呈现之前,我们无法知道需要执行哪种类型的图像处理任务。 因此,我们必须准备一系列图像处理模块。它们的目的各不相同,但一些底层操作可以共享。
现在,在自然语言处理和计算机视觉预训练进行预训练已很常见,但现存的方法主要研究预测试分类任务,而图像处理任务中的输入和输出都是图像。 直接应用这些现有的预训练策略可能不可行。 此外,如何在预训练阶段有效解决不同的目标图像处理任务仍然是一个艰巨的挑战。
在本文中,他们使用 Transformer 架构开发了一个用于图像处理的预训练模型, 即图像处理 Transformer (IPT)。由于预训练模型需要兼容不同的图像处理任务,包括超分辨率、去噪和去雨, 整个网络由对应于不同任务的多对头和尾以及单个共享主体组成。 由于需要使用大规模数据集来挖掘 Transformer 的潜力,因此他们准备了大量具有相当多样性的图像来训练 IPT 模型,选择了包含 1,000 个类别的各种高分辨率的 ImageNet 基准。 对于 ImageNet 中的每张图像,会使用几个精心设计的操作生成多个损坏的对应图像以服务于不同的任务。 例如,超分辨率任务的训练样本是通过对原始图像进行下采样生成的。整个用于训练 IPT 的整个数据集包含大约 1000 多万张图像。
Image Processing Transformer
IPT 结构
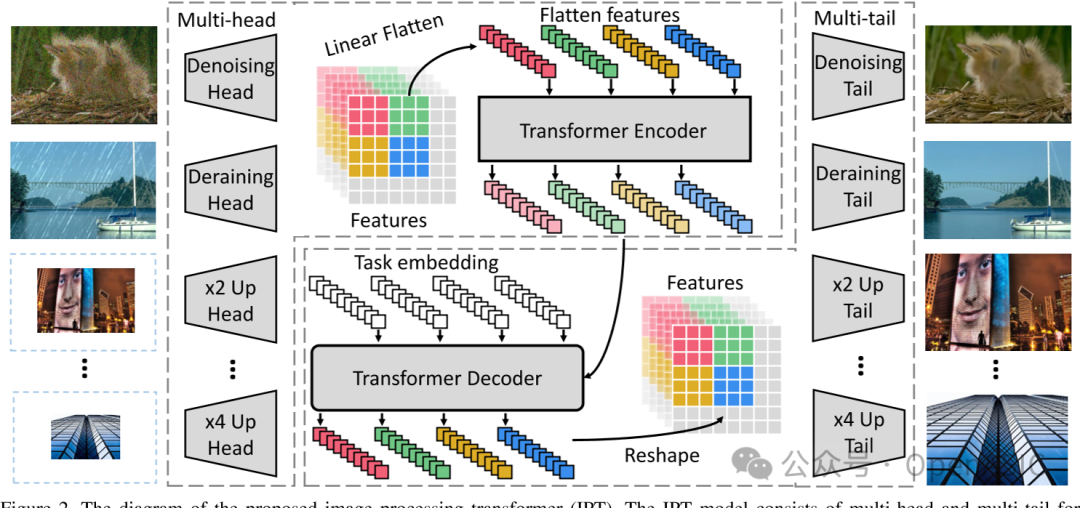
IPT的整体结构主要包括四个部分:Heads, Transformer encoder, Transformer decoder和Tail。
- Heads
为了处理不同的任务,我们使用多头架构来分别处理每个任务,其中每个头由三个卷积层组成。每个head主要用来提取输入有损图像的特征。 - Transformer encoder && decoder和Tail
本文所采用的transformer的与Attention is all you need结构相同,如下所示:

在把提取到的特征输入到Transformer body之前,会对特征进行分块处理,特征会被分成若干个大小的patch,每个patch会被看成是一个word。对这些patch进行展开即可得到对应的embedding,表示为, 为了保持patch之间的位置关系,本文采用了基于学习的位置编码,然后会把作为transformer encoder的输入进行处理。
本文所采用的Transformer encoder的处理过程可以表示为下述形式:
其中表示编码器的输出,LN表示Layer Norm,MSA表示Multi-Head Attention,FFN表示Feed Forward模块
decoder部分主要由两个多头注意力机制和一个Feed Forward Network模块组成,与原始的Transformer不同,在decoder中,这篇文章额外使用了特定于任务的embedding()作为解码器的附加输入, decoder处理结果如下:
其中表示解码器的输出。
- Tail
与heads类似,我们使用了多个tail来应对不同图像处理的任务,每个tail的输出是一个的图像,最后图像的尺寸有具体的任务决定,例如对于超分任务。
Pre-training on ImageNet
训练图像的生成
对于ImageNet中的原始图像,文章会通过对不同任务自定义的变换来获得有损图像,该过程可以表示为:
f表示退化变换,对于超分任务,f为双三次下采样;对于去噪任务,表示加信高斯噪声。在训练的过程中以退化后的图像作为输入,以原始的图像作为ground-truth来训练。
损失函数
在监督模式下,IPT的损失函数为:
该公式表示多个任务的损失函数的求和。表示传统的损失。
在训练时,对于每个批次,从个任务中随机选择一个任务进行训练, 每个任务将同时使用相应的头、尾和任务嵌入进行处理。 在对IPT模型进行预训练后,它将捕获大量图像处理任务的内在特征和转换。 训练完成后只需使用对应任务提供的数据集进行参数微调,就可以应用于特定的任务。 此外,为了节省计算成本,在微调时将删除其他头部和尾部,并根据反向传播更新剩余的头部、尾部和主干中的参数。
由于在训练的过程中所使用的退化的图片还是有限的,为了应对在实际任务中可能出现的不同特征的有损图像,同时同一图像中的不同patch又是相互关联的,所以文章使用对比学习来提高模型泛化能力。 其目的是最小化来自同一张图片的特征patch间的距离,而最大化来自不同图片的特征patch间的距离。 对比学习的损失函数定义如下:
最后在训练过程中使用的损失函数为:
Experiments
预训练的数据集采用的是ImageNet,训练时,patch size均为,测试时,patch size尺寸一致, 但是具有10像素的交叠。训练的硬件平台为32张NVIDIA Tesla V100, 使用的优化器为Adam优化器。一共训练了300个Epoch,学习率为,在200个epoch后衰减为。训练时所采用的batch size为256.
在具体任务上进行微调时,采用的学习率为,训练次数为30个Epoch。最后的结果如下所示。
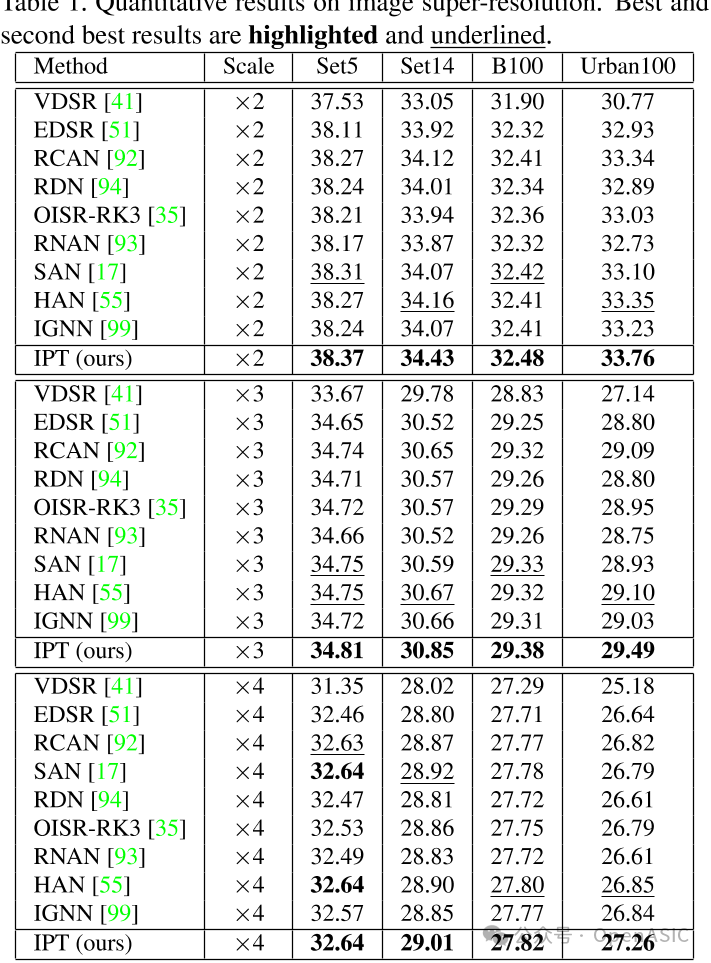
图像超分
IPT模型在x2图像超分任务中表现良好,在Urban100数据集上超过其他方法。实现了33.76dB的psnr,而先前SOTA的方法只能超越其他方法,结果如下:
在Urban100数据集实现x4的超分任务时,先前SOTA的方法生成的图像会包括一些模糊,但是使用IPT生成的图像可以很好地保留图像中的细节。如下图所示:

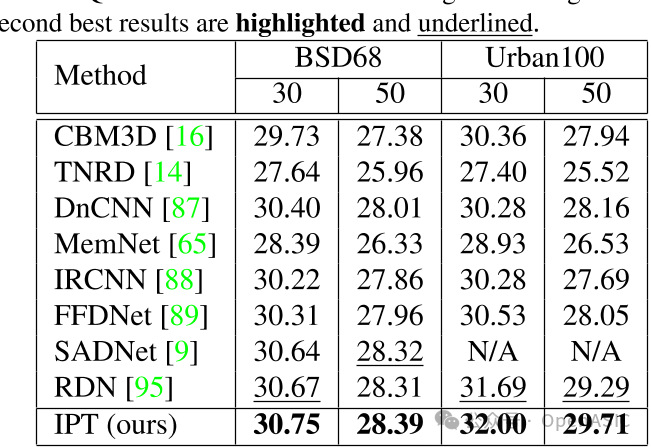
去噪
IPT模型在BSD68和Urban100数据集上与其他SOTA的方法进行去噪比较,发现IPT实现了最好的效果,并且在Urban100数据集上,IPT相较于SOTA的方法有的性能提升,所得到的结果如下:
去噪的可视化效果如下所示:

可以发现,IPT去噪后的图像中,对原始图像的细节保留到位。
去雨
对于去雨任务,使用Rain100L数据集对其进行评估,相比于先前的SOTA算法,IPT实现了1.62dB的提升,结果如下所示:

去雨的可视化结果如下:

以前的SOTA算法都没有办法重建一个很干净的原始图像,但IPT去雨后的图片实现几乎和原始图片质量一致。
结语
总之,本文训练了一个预训练的 Transformer 模型 (IPT) 解决图像处理问题。
IPT 模型采用多头、多尾共享的 Transformer 主体设计,用于处理不同的图像处理任务, 例如图像超分辨率和去噪。为了最大限度地挖掘 Transformer 架构在各种任务上的性能, 作者们探索了一个合成的 ImageNet 数据集。其中,每个原始图像将被降级为一系列对应图像作为成对 的训练数据。然后使用监督和自监督方法训练 IPT 模型,这显示出其强大的捕捉低级图像处理内在特征的能力。
实验结果表明,PT 仅使用一个预训练模型经过快速微调就能胜过最先进的方法。 在未来的工作中, IPT 模型有望扩展到更多的任务,如修复、去雾等。
如何学习AI大模型?
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
这份完整版的大模型 AI 学习资料已经上传CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】

一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

四、AI大模型商业化落地方案

作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。