机器学习介绍与定义
机器学习定义
- 机器学习(Machine Learning)本质上就是让计算机自己在数据中学习规律,并根据所得到的规律对未来数据进行预测。
- 机器学习包括如聚类、分类、决策树、贝叶斯、神经网络、深度学习(Deep Learning)等算法。
- 机器学习的基本思路是模仿人类学习行为的过程,如我们在现实中的新问题一般是通过经验归纳,总结规律,从而预测未来的过程。机器学习的基本过程如下:

机器学习的发展历史
从机器学习发展的过程上来说,其发展的时间轴如下所示:

机器学习分类
机器学习经过几十年的发展,衍生出了很多种分类方法,这里按学习模式的不同,可分为监督学习、半监督学习、无监督学习和强化学习。
监督学习
- 监督学习(Supervised Learning)是从有标签的训练数据中学习模型,然后对某个给定的新数据利用模型预测它的标签。如果分类标签精确度越高,则学习模型准确度越高,预测结果越精确。
- 监督学习主要用于回归和分类。

- 常见的监督学习的回归算法有线性回归、回归树、K邻近、Adaboost、神经网络等。
- 常见的监督学习的分类算法有朴素贝叶斯、决策树、SVM、逻辑回归、K邻近、Adaboost、神经网络等。
半监督学习
- 半监督学习(Semi-Supervised Learning)是利用少量标注数据和大量无标注数据进行学习的模式。
- 半监督学习侧重于在有监督的分类算法中加入无标记样本来实现半监督分类。
- 常见的半监督学习算法有Pseudo-Label、Π-Model、Temporal Ensembling、Mean Teacher、VAT、UDA、MixMatch、ReMixMatch、FixMatch等。
无监督学习
- 无监督学习(Unsupervised Learning)是从未标注数据中寻找隐含结构的过程。
- 无监督学习主要用于关联分析、聚类和降维。
- 常见的无监督学习算法有稀疏自编码(Sparse Auto-Encoder)、主成分分析(Principal Component Analysis, PCA)、K-Means算法(K均值算法)、DBSCAN算法(Density-Based Spatial Clustering of Applications with Noise)、最大期望算法(Expectation-Maximization algorithm, EM)等。
强化学习
- 强化学习(Reinforcement Learning)类似于监督学习,但未使用样本数据进行训练,是是通过不断试错进行学习的模式。
- 在强化学习中,有两个可以进行交互的对象:智能体(Agnet)和环境(Environment),还有四个核心要素:策略(Policy)、回报函数(收益信号,Reward Function)、价值函数(Value Function)和环境模型(Environment Model),其中环境模型是可选的。
- 强化学习常用于机器人避障、棋牌类游戏、广告和推荐等应用场景中。
机器学习的应用场合
机器学习的应用场景非常广泛,几乎涵盖了各个行业和领域。以下是一些常见的机器学习应用场景的示例:
- 自然语言处理(NLP)
- 医疗诊断与影像分析
- 金融风险管理
- 预测与推荐系统
- 制造业和物联网
- 能源管理与环境保护
- 决策支持与智能分析
- 图像识别与计算机视觉
机器学习项目开发步骤
有5个基本步骤用于执行机器学习任务:
- 收集数据:无论是来自excel,access,文本文件等的原始数据,这一步(收集过去的数据)构成了未来学习的基础。相关数据的种类,密度和数量越多,机器的学习前景就越好。
- 准备数据:任何分析过程都会依赖于使用的数据质量如何。人们需要花时间确定数据质量,然后采取措施解决诸如缺失的数据和异常值的处理等问题。探索性分析可能是一种详细研究数据细微差别的方法,从而使数据的质量迅速提高。
- 练模型:此步骤涉及以模型的形式选择适当的算法和数据表示。清理后的数据分为两部分 - 训练和测试(比例视前提确定); 第一部分(训练数据)用于开发模型。第二部分(测试数据)用作参考依据。
- 评估模型:为了测试准确性,使用数据的第二部分(保持/测试数据)。此步骤根据结果确定算法选择的精度。检查模型准确性的更好测试是查看其在模型构建期间根本未使用的数据的性能。
- 提高性能:此步骤可能涉及选择完全不同的模型或引入更多变量来提高效率。这就是为什么需要花费大量时间进行数据收集和准备的原因。
scikit-learn工具介绍

-
Python语言机器学习工具
-
Scikit-learn包括许多智能的机器学习算法的实现
-
Scikit-learn文档完善,容易上手,丰富的API接口函数
-
Scikit-learn官网:scikit-learn: machine learning in Python --- scikit-learn 1.5.2 documentation
-
Scikit-learn中文文档:sklearn
scikit-learn安装
参考以下安装教程:https://www.sklearncn.cn/62/
pip install -i https://pypi.tuna.tsinghua.edu.cn/simple scikit-learn
Scikit-learn包含的内容

数据集
sklearn玩具数据集介绍
数据量小,数据在sklearn库的本地,只要安装了sklearn,不用上网就可以获取(波士顿房价数据现在不能被本地获取)

sklearn现实世界数据集介绍
数据量大,数据只能通过网络获取

sklearn加载玩具数据集
鸢尾花数据
1.鸢尾花数据集介绍
(1)特征有
- 花萼长 sepal length
- 花萼宽sepal width
- 花瓣长 petal length
- 花瓣宽 petal width
(2)三分类(target_names):
- 0-Setosa山鸢尾
- 1-Versicolour变色鸢尾
- 2-Virginica维吉尼亚鸢尾
(3)iris字典中有几个重要属性:
data 特征
feature_names 特征描述
target 目标
target_names 目标描述
DESCR 数据集的描述
filename 下后到本地保存后的文件名
python
from sklearn.datasets import load_iris
import numpy as np
import pandas as pd
# 鸢尾花数据集是一个字典
# 但它不是一个真正的字典,但你可以像访问字典那样访问它的属性和键
iris = load_iris()# 加载鸢尾花的数据集(去本地加载了一个csv文件)
# iris.feature_names存储在字典的Bunch对象中对于data特征(行数据)的特征描述(列名), 是一个非numpy的列表
pd.DataFrame(iris.data, columns = iris.feature_names).head()| | sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) |
| 0 | 5.1 | 3.5 | 1.4 | 0.2 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 |
|---|
python
"""
0-Setosa山鸢尾
1-Versicolor变色鸢尾
2-Virginica维吉尼亚鸢尾
"""
# 数据集中记录的不同的鸢尾花花型,不同的数字代表不同的花型
print(f"目标形状:\n",iris.target)#目标形状,返回值是一个numpy数组目标形状: 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
python
print(f"目标描述:\n",iris.target_names)#目标描述,对于目标形状对应的值
print(iris.DESCR)#数据集的描述目标描述: 'setosa' 'versicolor' 'virginica'
python
iris = load_iris()# 加载鸢尾花的数据集(去本地加载了一个csv文件)
print(iris.filename) # 数据集文件的路径(如果数据集是从文件中加载的,否则可能是None)iris.csv
下面使用pandas把特征和目标一起显示出来
python
import pandas as pd
import numpy as np
from sklearn.datasets import load_iris
# 加载玩具数据集
iris = load_iris()
# 获取data数据
feature = iris.data
# 获取鸢尾花的目标形状
target = iris.target
#将目标形状转为二维数组
target.shape = (len(target),1)
# 使用 np.hstack 将它们沿水平方向拼接成一个新的数组
data = np.hstack([feature, target])
print(type(data))
# 获取特征描述(列名)
cols = iris.feature_names
# 加入目标形状列
cols.append("target")
#转为dataframe数组,查看前五行数据
pd.DataFrame(data, columns=cols).head()<class 'numpy.ndarray'>
| | sepal length (cm) | sepal width (cm) | petal length (cm) | petal width (cm) | target |
| 0 | 5.1 | 3.5 | 1.4 | 0.2 | 0.0 |
| 1 | 4.9 | 3.0 | 1.4 | 0.2 | 0.0 |
| 2 | 4.7 | 3.2 | 1.3 | 0.2 | 0.0 |
| 3 | 4.6 | 3.1 | 1.5 | 0.2 | 0.0 |
| 4 | 5.0 | 3.6 | 1.4 | 0.2 | 0.0 |
|---|
分析糖尿病数据集(后面的具体数据含义可自行上网查找)
这是回归数据集,有442个样本,有可能就有442个目标值。
python
from sklearn.datasets import load_diabetes
import pandas as pd
# 不同的数据集中包含的数据略有不同
diabetes = load_diabetes()
print(diabetes.keys())
# print(f"数据集特征data:\n", diabetes.data)
df = pd.DataFrame(diabetes.data, columns=diabetes.feature_names).head()
display(df)dict_keys('data', 'target', 'frame', 'DESCR', 'feature_names', 'data_filename', 'target_filename', 'data_module')
葡萄酒数据集
python
from sklearn.datasets import load_wine
import pandas as pd
wine_data = load_wine()
print(dict(wine_data).keys())dict_keys('data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names')
数字数据集
python
digits = load_digits()
print(digits.keys())dict_keys('data', 'target', 'frame', 'feature_names', 'target_names', 'images', 'DESCR')
linnerud物理锻炼数据集
python
from sklearn.datasets import load_linnerud
linnerud = load_linnerud()
print(linnerud.keys())dict_keys('data', 'feature_names', 'target', 'target_names', 'frame', 'DESCR', 'data_filename', 'target_filename', 'data_module')
威斯康星州乳腺癌数据集
python
from sklearn.datasets import load_breast_cancer
breast = load_breast_cancer()
print(breast.keys())dict_keys('data', 'target', 'frame', 'target_names', 'DESCR', 'feature_names', 'filename', 'data_module')
sklearn获取现实世界数据集
(1)所有现实世界数据,通过网络才能下载后,默认保存的目录可以使用下面api获取。实际上就是保存到home目录
python
from sklearn import datasets
datasets.get_data_home() #查看数据集默认存放的位置(2)下载时,有可能因为网络问题而出题,要"小心"的解决网络问题,不可言.....
(3)第一次下载会保存的硬盘中,如果第二次下载,因为硬盘中已经保存有了,所以不会再次下载就直接加载成功了。
获取20分类新闻数据
1.使用函数: sklearn.datasets.fetch_20newsgroups(data_home,subset)
2.函数参数说明:
(1)data_home
- None:这是默认值,下载的文件路径为 "C:/Users/ADMIN/scikit_learn_data/20news-bydate_py3.pkz"
- 自定义路径
例如 "./src", 下载的文件路径为"./20news-bydate_py3.pkz"
(2)subset
- "train",只下载训练集
- "test",只下载测试集
- "all", 下载的数据包含了训练集和测试集
(3)return_X_y,决定着返回值的情况
- False,这是默认值
- True
3.代码
python
from sklearn.datasets import fetch_20newsgroups #这是一个20分类的数据
news = fetch_20newsgroups(data_home=None,subset='all')
print(len(news.data)) #18846
print(news.target.shape) #(18846,)
print(len(news.target_names)) #20
print(len(news.filenames)) #18846本地csv数据
创建csv文件
1.方式1:打开计事本,写出如下数据,数据之间使用英文下的逗号, 保存文件后把后缀名改为csv
csv文件可以使用excel打开
, milage,Liters,Consumtime,target
40920,8.326976,0.953952,3
14488,7.153469,1.673904,2
26052,1.441871,0.805124,1
75136,13.147394,0.428964,1
2.方式2:创建excel 文件, 填写数据,以csv为后缀保存文件
pandas加载csv(加载的文件是pandas的数组文件)
1.使用pandas的read_csv("文件路径")函数可以加载csv文件,得到的结果为数据的DataFrame形式
pd.read_csv("./src/ss.csv")
数据集的划分
1.相关知识
- 星号传参
python
def m(*a, **b):
print(a) #('hello', 123)
print(b) #{'name': '小王', 'age': 30, 'sex': '男'}
m("hello", 123, name="小王", age=30, sex="男")2.列表
python
list = [11,22,33]
a, b, c = list # a=11 b=22 c=33
a, b = ["小王", 30] #a="小王" b=30函数
sklearn.model_selection.train_test_split(*arrays,**options)
参数
- *array
- 这里用于接收1到多个"列表、numpy数组、稀疏矩阵或padas中的DataFrame"。
2.options, 重要的关键字参数有:
- test_size 、train_size值为0.0到1.0的小数,表示划分后测试集占的比例
- random_state 值为任意整数,表示随机种子,使用相同的随机种子对相同的数据集多次划分结果是相同的。否则多半不同
- stratify 值为目标数组,分层的划分对象
3.返回值说明
- 返回值为列表list, 列表长度与形参array接收到的参数数量相关联, 形参array接收到的是什么类型,list中对应被划分出来的两部分就是什么类
数据集划分
列表数据集划分
- 因为随机种子都使用了相同的整数(22),所以划分的情况是相同的。
- 随机方式的相同,便于每次测试的遍历
python
from sklearn.model_selection import train_test_split
arr1 = [33,43,22,21,32,23,24,25,63,73,82,92,10]
#分割为两部分,二维数据,一部分占80%,另一部分占20%
data = train_test_split(arr1, train_size=0.8)
"""
列表中存储分层后的两个列表
[[33, 23, 21, 32, 63, 22, 82, 73, 24, 92], [25, 10, 43]]
"""
print(data)
x_trian,y_test = train_test_split(arr1, train_size=0.8)
"""
将列表中分层的列表单独取出
[22, 43, 23, 21, 63, 32, 82, 25, 24, 10]
[73, 92, 33]
"""
print(x_trian)
print(y_test)
# 两个数组不按顺序(随机)进行百分比划分,但两个数组的分割后的下标要对齐,
# 比如,arr1的第一个下标的值要与arr2的第一个下标的值的所处位置对应,以此类推。
# 比如33与1的位置一定要对应
arr1 = [33,43,22,21,32,23,24,25,63,73,82,92,10]
arr2 = [1,2,2,2,1,1,1,2,2,3,3,4,5]
x_trian, x_test, y_train, y_test = train_test_split(arr1, arr2, test_size=0.2)
"""
[23, 63, 73, 22, 24, 25, 82, 92, 32, 33] [21, 10, 43]
[1, 2, 3, 2, 1, 2, 3, 4, 1, 1] [2, 5, 2]
"""
print(x_trian, x_test)
print(y_train, y_test)ndarray数据集划分
python
# ndarray的数据集划分
from sklearn.model_selection import train_test_split
import numpy as np
x = np.arange(100)
print(x)#这个x数据集中有几个数据集(50个), 每一个数据有两个特征(2)
x_trian, x_test = train_test_split(x, test_size=0.2, random_state=42)
"""
(80,)
(20,)
<class 'numpy.ndarray'>
<class 'numpy.ndarray'>
"""
print(x_trian.shape)
#测试集不是元组,是列表中储存的元组
print(x_test.shape)
print(type(x_test))
print(type(x_trian))二维数组数据集划分
train_test_split只划分第一维度,第二维度保持不变
python
x= [[1,2,3,111],
[1,23,3,112],
[1,24, 113],
[1,42,34,114],
[1,2,33,115],
[1,2,3,116],
[14,2,3,117],
[14,2,35,118],
[1,42,3,119],
[14,23,34,220],
]
y = [1,1,1,1,1,2,2,2,1,1]
# stratify=y根据进行分层
# shuffle洗牌,打乱,默认为True
# 因为y的2元素太少,取0.8,分割后的y_test中就没有2这类元素了
x_trian, x_test, y_train, y_test=train_test_split(x, y, train_size=0.8, stratify=y)
"""
x_train:
[[14, 2, 35, 118], [1, 42, 3, 119], [1, 2, 3, 111], [14, 2, 3, 117], [1, 24, 113], [14, 23, 34, 220], [1, 2, 3, 116], [1, 42, 34, 114]]
x_test:
[[1, 2, 33, 115], [1, 23, 3, 112]]
y_train:
[1, 1, 1, 2, 1, 1, 2, 1]
y_test:
[1, 1]
"""
print("x_train: \n", x_trian)
print("x_test: \n", x_test)
print("y_train: \n", y_train)
print("y_test: \n", y_test)- 随机种子:规定随机的算法一致
python
x= [[1,2,3,111],
[1,23,3,112],
[1,24, 113],
[1,42,34,114],
[1,2,33,115],
[1,2,3,116],
[14,2,3,117],
[14,2,35,118],
[1,42,3,119],
[14,23,34,220],
]
y = [1,1,1,1,1,2,2,2,2,2]
#random_state某种随机算法的随机种子,
# 相同的随机种子,多次运行同个数据,随机方式一样,利于比较
x_trian, x_test, y_train, y_test=train_test_split(x, y, train_size=0.8, stratify=y, random_state=4)
print("x_train: \n", x_trian)
print("x_test: \n", x_test)
print("y_train: \n", y_train)
print("y_test: \n", y_test)DataFrame数据集划分
可以划分DataFrame, 划分后的两部分还是DataFrame
python
# dataFrame的数据划分
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
#数据集的划分
data = np.arange(1,100).reshape(33,3)
data = pd.DataFrame(data, columns=['a','b','c'])
# print(data)
# 0.7不为整,进行取整
# train和test的取整不超过原值数量
train, test = train_test_split(data, train_size=0.7, shuffle=True, random_state=4)
"""
随机划分行数据
(23, 3)
(10, 3)
"""
print(train.shape)
print(test.shape)字典数据集划分
可以划分非稀疏矩阵,用于将字典列表转换为特征向量。这个转换器主要用于处理类别数据和数值数据的混合型数据集
- 对于类别特征
DictVectorizer会为每个不同的类别创建一个新的二进制特征,如果原始数据中的某个样本具有该类别,则对应的二进制特征值为1,否则为0。 - 对于数值特征保持不变,直接作为特征的一部分,这样,整个数据集就被转换成了一个适合机器学习算法使用的特征向量形式
python
# 字典的特征提取和数据划分
# 将科学键值转换为科学计数法,不是纯数字的将转化成矩阵,每列表示一个没数字的键值,对应的键值为一,非对应的为0
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
arr = [{"name":"重庆", "count":2000, "tempreture":41},
{"name":"成都", "count":2300, "tempreture":28},
{"name":"广州", "count":4900, "tempreture":20},
{"name":"深圳", "count":1200, "tempreture":35}]
model = DictVectorizer(sparse=False)#sparse=False表示返回一个完整的矩阵,sparse=True表示返回稀疏矩阵
data = model.fit_transform(arr)
"""
# 字典的特征提取和数据划分
# 将科学键值转换为科学计数法,不是纯数字的将转化成矩阵,每列表示一个没数字的键值,对应的键值为一,非对应的为0
from sklearn.feature_extraction import DictVectorizer
from sklearn.model_selection import train_test_split
arr = [{"name":"重庆", "count":2000, "tempreture":41},
{"name":"成都", "count":2300, "tempreture":28},
{"name":"广州", "count":4900, "tempreture":20},
{"name":"深圳", "count":1200, "tempreture":35}]
model = DictVectorizer(sparse=False)#sparse=False表示返回一个完整的矩阵,sparse=True表示返回稀疏矩阵
data = model.fit_transform(arr)
print(data)
x_train, y_train = train_test_split(data, train_size=0.8, random_state=666)
print(x_train)
print(y_train)
"""
print(data)
x_train, y_train = train_test_split(data, train_size=0.8, random_state=666)
"""
[[2.3e+03 0.0e+00 1.0e+00 0.0e+00 0.0e+00 2.8e+01]
[4.9e+03 1.0e+00 0.0e+00 0.0e+00 0.0e+00 2.0e+01]
[2.0e+03 0.0e+00 0.0e+00 0.0e+00 1.0e+00 4.1e+01]]
[[1.2e+03 0.0e+00 0.0e+00 1.0e+00 0.0e+00 3.5e+01]]
"""
print(x_train)
print(y_train)鸢尾花数据集划分
python
# 鸢尾花的数据集划分
from sklearn import datasets
from sklearn.model_selection import train_test_split
iris = datasets.load_iris()
x = iris.data
y = iris.target
# stratify=y分层默认了对y进行分层
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2, random_state=4, stratify=y)
"""
(120, 4)
(30, 4)
(120,)
(30,)
"""
print(x_train.shape)
print(x_test.shape)
print(y_train.shape)
print(y_test.shape)现实世界数据集划分
python
from sklearn.datasets import fetch_20newsgroups
from sklearn.model_selection import train_test_split
import numpy as np
news = fetch_20newsgroups(data_home=None, subset='all')
list = train_test_split(news.data, news.target,test_size=0.2, random_state=22)
# """
# 返回值是一个list:其中有4个值,分别为训练集特征、测试集特征、训练集目标、测试集目标
# 与iris相同点在于x_train和x_test是列表,而iris是
# """
x_train, x_test, y_train, y_test = list
#打印结果为: 15076 3770 (15076,) (3770,)
print(len(x_train), len(x_test), y_train.shape, y_test.shape)特征工程
特征工程概念
1.特征工程:就是对特征进行相关的处理,一般使用pandas来进行数据清洗和数据处理、使用sklearn来进行特征工程
2.特征工程是将任意数据(如文本或图像)转换为可用于机器学习的数字特征,比如:字典特征提取(特征离散化)、文本特征提取、图像特征提取。
3.特征工程步骤为
(1)特征提取, 如果不是像dataframe那样的数据,要进行特征提取,比如字典特征提取,文本特征提取
(2)无量纲化(预处理)
-
归一化
-
标准化
-
降维
-
底方差过滤特征选择
-
主成分分析-PCA降维
-
特征工程API
1.实例化转换器对象,转换器类有很多,都是Transformer的子类, 常用的子类有:
DictVectorizer 字典特征提取
CountVectorizer 文本特征提取
TfidfVectorizer TF-IDF文本特征词的重要程度特征提取
MinMaxScaler 归一化
StandardScaler 标准化
VarianceThreshold 底方差过滤降维
PCA 主成分分析降维
2.转换器对象调用fit_transform()进行转换, 其中fit用于计算数据,transform进行最终转换
fit_transform()可以使用fit()和transform()代替
data_new = transfer.fit_transform(data)
可写成
transfer.fit(data)
data_new = transfer.transform(data)
DictVectorizer 字典列表特征提取
稀疏矩阵
1.稀疏矩阵是指一个矩阵中大部分元素为零,只有少数元素是非零的矩阵。在数学和计算机科学中,当一个矩阵的非零元素数量远小于总的元素数量,且非零元素分布没有明显的规律时,这样的矩阵就被认为是稀疏矩阵。例如,在一个1000 x 1000的矩阵中,如果只有1000个非零元素,那么这个矩阵就是稀疏的。
2.由于稀疏矩阵中零元素非常多,存储和处理稀疏矩阵时,通常会采用特殊的存储格式,以节省内存空间并提高计算效率。
3.三元组表 (Coordinate List, COO):三元组表就是一种稀疏矩阵类型数据,存储非零元素的行索引、列索引和值:
(行,列) 数据
(0,0) 10
(0,1) 20
(2,0) 90
(2,20) 8
(8,0) 70
表示除了列出的有值, 其余全是0
非稀疏矩阵(稠密矩阵)
1.非稀疏矩阵,或称稠密矩阵,是指矩阵中非零元素的数量与总元素数量相比接近或相等,也就是说矩阵中的大部分元素都是非零的。在这种情况下,矩阵的存储通常采用标准的二维数组形式,因为非零元素密集分布,不需要特殊的压缩或优化存储策略。
- 存储:稀疏矩阵使用特定的存储格式来节省空间,而稠密矩阵使用常规的数组存储所有元素,无论其是否为零。
- 计算:稀疏矩阵在进行计算时可以利用零元素的特性跳过不必要的计算,从而提高效率。而稠密矩阵在计算时需要处理所有元素,包括零元素。
- 应用领域:稀疏矩阵常见于大规模数据分析、图形学、自然语言处理、机器学习等领域,而稠密矩阵在数学计算、线性代数等通用计算领域更为常见。
在实际应用中,选择使用稀疏矩阵还是稠密矩阵取决于具体的问题场景和数据特性。
API
1.创建转换器对象
sklearn.feature_extraction.DictVectorizer(sparse=True)
2.参数
- sparse=True返回类型为csr_matrix的稀疏矩阵
- sparse=False表示返回的是数组,数组可以调用.toarray()方法将稀疏矩阵转换为数组
3.转换器对象:
- 转换器对象调用fit_transform(data)函数,参数data为一维字典数组或一维字典列表,返回转化后的矩阵或数组
- 转换器对象get_feature_names_out()方法获取特征名
提取为稀疏矩阵对应的数组
python
# 字典列表特征提取
from sklearn.feature_extraction import DictVectorizer
import pandas as pd
# 当字典数字数据不是很大时,转换时就不会用科学计数法来显示,反之
data = [{"name":"重庆", "money":38, "age":41},
{"name":"成都", "money":60, "age":28},
{"name":"广州", "money":30, "age":20},
{"name":"深圳", "money":40, "age":35}]
# 初始化工具(字典变成向量的工具器)
model = DictVectorizer(sparse=False)# sparse是否转换为三元组形式
data = model.fit_transform(data)
"""
[[41. 38. 0. 0. 0. 1.]
[28. 60. 0. 1. 0. 0.]
[20. 30. 1. 0. 0. 0.]
[35. 40. 0. 0. 1. 0.]]
<class 'numpy.ndarray'>
['age' 'money' 'name=广州' 'name=成都' 'name=深圳' 'name=重庆']
"""
print(data)
print(type(data))
# numpy数组的列标签
# 数组的特征描述
print(model.get_feature_names_out())
# 只要不用print打印,就会渲染Dataframe数组列表
# pd.DataFrame(data, columns=model.get_feature_names_out())
ddata = pd.DataFrame(data, columns=model.get_feature_names_out())
ddata| age | money | name=广州 | name=成都 | name=深圳 | name=重庆 |
| 0 | 41.0 | 38.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 1 | 28.0 | 60.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 2 | 20.0 | 30.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 3 | 35.0 | 40.0 | 0.0 | 0.0 | 1.0 | 0.0 |
|---|
提取为稀疏矩阵
python
# 字典列表特征提取
from sklearn.feature_extraction import DictVectorizer
import pandas as pd
# 当字典数字数据不是很大时,转换时就不会用科学计数法来显示,反之
data = [{"name":"重庆", "money":38, "age":41},
{"name":"成都", "money":60, "age":28},
{"name":"广州", "money":30, "age":20},
{"name":"深圳", "money":40, "age":35}]
# 初始化工具(字典变成向量的工具器)
model = DictVectorizer(sparse=True)# sparse是否转换为三元组形式
data = model.fit_transform(data)
"""
(np.int32(0), np.int32(0)) 41.0
(np.int32(0), np.int32(1)) 38.0
(np.int32(0), np.int32(5)) 1.0
(np.int32(1), np.int32(0)) 28.0
(np.int32(1), np.int32(1)) 60.0
(np.int32(1), np.int32(3)) 1.0
(np.int32(2), np.int32(0)) 20.0
(np.int32(2), np.int32(1)) 30.0
(np.int32(2), np.int32(2)) 1.0
(np.int32(3), np.int32(0)) 35.0
(np.int32(3), np.int32(1)) 40.0
(np.int32(3), np.int32(4)) 1.0
<class 'scipy.sparse._csr.csr_matrix'>
['age' 'money' 'name=广州' 'name=成都' 'name=深圳' 'name=重庆']
[[41. 38. 0. 0. 0. 1.]
[28. 60. 0. 1. 0. 0.]
[20. 30. 1. 0. 0. 0.]
[35. 40. 0. 0. 1. 0.]]
"""
print(data)
print(type(data))
# numpy数组的列标签
# 数组的特征描述
print(model.get_feature_names_out())
# 将三元组转化成数组(系数矩阵)
"""
稀疏矩阵转为数组
稀疏矩阵对象调用toarray()函数, 得到类型为ndarray的二维稀疏矩阵
"""
arr_data = data.toarray()
print("系数矩阵:")
print(arr_data)字典提取加归一化
python
# 字典列表特征提取+归一化
from sklearn.preprocessing import MinMaxScaler
from sklearn.feature_extraction import DictVectorizer
import pandas as pd
# 当字典数字数据不是很大时,转换时就不会用科学计数法来显示,反之
data = [{"name":"重庆", "money":38, "age":41},
{"name":"成都", "money":60, "age":28},
{"name":"广州", "money":30, "age":20},
{"name":"深圳", "money":40, "age":35}]
# 初始化工具(字典变成向量的工具器)
model = DictVectorizer(sparse=False)# sparse是否转换为三元组形式
data = model.fit_transform(data)
print(data)
print(type(data))
# numpy数组的列标签
# 数组的特征描述
print(model.get_feature_names_out())
# 如果需要再不同的位置显示Dateframe数组列表,需要使用display()函数来进行显示
ddata = pd.DataFrame(data, columns=model.get_feature_names_out())
display(ddata)
print("\n")
print("============对数字化后的字典进行归一化处理====================")
print("\n")
scaler = MinMaxScaler(feature_range=(0, 1))
data_scalrt = scaler.fit_transform(data)
print(data_scalrt)
print(type(data_scalrt))
# numpy数组的列标签
# 数组的特征描述
print(scaler.get_feature_names_out())
# 只要不用print打印,就会渲染Dataframe数组列表
# pd.DataFrame(data, columns=model.get_feature_names_out())
ddata_scaler = pd.DataFrame(data_scalrt, columns=scaler.get_feature_names_out())
ddata_scaler
#只有在代码最后才会被显示,Jupyter Notebook 会在代码单元的最后一个表达式处自动显示结果。
# ddata = pd.DataFrame(data, columns=model.get_feature_names_out())
# ddata| | age | money | name=广州 | name=成都 | name=深圳 | name=重庆 |
| 0 | 41.0 | 38.0 | 0.0 | 0.0 | 0.0 | 1.0 |
| 1 | 28.0 | 60.0 | 0.0 | 1.0 | 0.0 | 0.0 |
| 2 | 20.0 | 30.0 | 1.0 | 0.0 | 0.0 | 0.0 |
| 3 | 35.0 | 40.0 | 0.0 | 0.0 | 1.0 | 0.0 |
|---|
| | x0 | x0 | x1 | x2 | x3 | x4 |
| 0 | 1.000000 | 0.266667 | 0.0 | 0.0 | 0.0 | 1.0 |
| 1 | 0.380952 | 1.000000 | 0.0 | 1.0 | 0.0 | 0.0 |
| 2 | 0.000000 | 0.000000 | 1.0 | 0.0 | 0.0 | 0.0 |
| 3 | 0.714286 | 0.333333 | 0.0 | 0.0 | 1.0 | 0.0 |
|---|
CountVectorizer 文本特征提取
API
sklearn.feature_extraction.text.CountVectorizer
- 构造函数关键字参数stop_words,值为list,表示词的黑名单(不提取的词)
- fit_transform函数的返回值为稀疏矩阵
英文文本提取
python
# CountVectorizer文本特征提取
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
corpus = ['I love machine learning. It is very popular!', 'Its a great day for machine learning!', 'I am so happy to be here!', 'I love my job. I am working at amazon.', 'I love my family. They are very happy!']
# 创建一个词频提取对象, 剔除amazon
# sparse=True 表示返回稀疏矩阵,但词频提取器没有这个可以转为三元组的参数
vectorizer = CountVectorizer(stop_words=['amazon'])
# 提取词频, 将文字转化为numpy数组,可迭代的容器中有几个一层元素二维数组中就有多少的个列表元素
# 但词频提取的结果是三元组形状
x = vectorizer.fit_transform(corpus)
#print(x)数据过大,会遮挡后面的输出内容
# 比如转化为numpy的列表数组的完整输出
# print(x)
# y = x.toarray()
# print(y)
print(x.toarray())
# 二维numpy数组中的列表元素中的每一个元素的特征值
# 通俗语言,列元素的列标签
print(vectorizer.get_feature_names_out())
# columns 参数处于第三个参数位置,当只用两个参数时,columns 使用位置索引传参
pd.DataFrame(x.toarray(), columns = vectorizer.get_feature_names_out())
"""
[[0 0 0 0 0 0 0 0 0 0 1 1 0 0 1 1 1 0 1 0 0 0 1 0]
[0 0 0 0 1 0 1 1 0 0 0 0 1 0 1 0 1 0 0 0 0 0 0 0]
[1 0 0 1 0 0 0 0 1 1 0 0 0 0 0 0 0 0 0 1 0 1 0 0]
[1 0 1 0 0 0 0 0 0 0 0 0 0 1 0 1 0 1 0 0 0 0 0 1]
[0 1 0 0 0 1 0 0 1 0 0 0 0 0 0 1 0 1 0 0 1 0 1 0]]
['am' 'are' 'at' 'be' 'day' 'family' 'for' 'great' 'happy' 'here' 'is'
'it' 'its' 'job' 'learning' 'love' 'machine' 'my' 'popular' 'so' 'they'
'to' 'very' 'working']
"""中文文本提取
中文不会进行提取词
python
# CountVectorizer文本特征提取
from sklearn.feature_extraction.text import CountVectorizer
# 要手动分割, 只会识别空格对文本进行分割,因为是英文文本的格式模式
corpus = ['我爱北京天安门', '天安门上', '我爱成都天宫']
#出错,不能一个一个的分词,分词要有意义
# corpus = ['我 爱 北 京 天 安 门', '天 安 门 上', '我 爱 成 都 天 宫']
# 创建一个词频提取对象
# stop_words=None报错
vectorizer = CountVectorizer(stop_words=[])
#提取词频
x = vectorizer.fit_transform(corpus)
"""
(np.int32(0), np.int32(1)) 1
(np.int32(1), np.int32(0)) 1
(np.int32(2), np.int32(2)) 1
[[0 1 0]
[1 0 0]
[0 0 1]]
['天安门上' '我爱北京天安门' '我爱成都天宫']
"""
print(x)
print(x.toarray())
print(vectorizer.get_feature_names_out())使用jieba分词
1.中文文本不像英文文本,中文文本文字之间没有空格,所以要先分词,一般使用jieba分词.
2.下载jieba组件, (不要使用conda)
! pip install -i https://pypi.tuna.tsinghua.edu.cn/simple jieba
3.jieba的基础
python
import jieba
data = "在如今的互联网世界,正能量正成为澎湃时代的大流量"
data = jieba.cut(data)
data = list(data)
print(data) #['在', '如今', '的', '互联网', '世界', ',', '正', '能量', '正', '成为', '澎湃', '时代', '的', '大', '流量']
data = " ".join(data)
print(data) #"在 如今 的 互联网 世界 , 正 能量 正 成为 澎湃 时代 的 大 流量"- 使用jieba封装一个函数,功能是把汉语字符串中进行分词(会忽略长度小于等于1的词语,因为它们往往缺乏语义信息,不能很好地表达文本的特征)
python
import jieba
def cut(text):
return " ".join(list(jieba.cut(text)))
data = "在如今的互联网世界,正能量正成为澎湃时代的大流量"
data = cut(data)
print(data) #"在 如今 的 互联网 世界 , 正 能量 正 成为 澎湃 时代 的 大 流量"- 示例
python
import jieba
from sklearn.feature_extraction.text import CountVectorizer
import pandas as pd
def my_cut(text):
#传入的文本用结巴分词工具转化为数据容器(可迭代的容器),然后用数据容器中的元素用空格连接成字符串
return " ".join(jieba.cut(text))
corpus = ['我爱北京天安门', '我爱成都天府广场']
#创建一个词频提取对象
vectorizer = CountVectorizer(stop_words=[])
# 提取词频
x = vectorizer.fit_transform([my_cut(el) for el in corpus])
"""
(np.int32(0), np.int32(0)) 1
(np.int32(0), np.int32(1)) 1
(np.int32(1), np.int32(3)) 1
(np.int32(1), np.int32(2)) 1
[[1 1 0 0]
[0 0 1 1]]
<bound method CountVectorizer.get_feature_names_out of CountVectorizer(stop_words=[])>
"""
print(x)
print(x.toarray())
print(vectorizer.get_feature_names_out)
pd.DataFrame(x.toarray(),columns=vectorizer.get_feature_names_out())| | 北京 | 天安门 | 天府广场 | 成都 |
| 0 | 1 | 1 | 0 | 0 |
| 1 | 0 | 0 | 1 | 1 |
|---|
python
import pandas
mylist = []
for i in range(len(data)):
print("第"+str(i)+"名")
mylist.append("第"+str(i)+"句")
pandas.DataFrame(data_final.toarray(), index=mylist, columns=transfer.get_feature_names_out())
TfidfVectorizer TF-IDF文本特征词的重要程度特征提取
算法
词频(Term Frequency, TF), 表示一个词在当前篇文章中的重要性
逆文档频率(Inverse Document Frequency, IDF), 反映了词在整个文档集合中的稀有程度

API
sklearn.feature_extraction.text.TfidfVectorizer()
- 构造函数关键字参数stop_words,表示词特征黑名单
- fit_transform函数的返回值为稀疏矩阵
示例
代码与CountVectorizer的示例基本相同,仅仅把CountVectorizer改为TfidfVectorizer即可
示例中data是一个字符串list, list中的第一个元素就代表一篇文章.
python
from sklearn.feature_extraction.text import TfidfVectorizer, CountVectorizer
import jieba
import pandas as pd
def my_cut(text):
return " ".join(jieba.cut(text))
data = ["教育学会会长期间,坚定支持民办教育事业!", "扶持民办,学校发展事业","事业做出重大贡献!"]
data = [my_cut(i) for i in data]
"""
['教育 学会 会长 期间 , 坚定 支持 民办教育 事业 !', '扶持 民办 , 学校 发展 事业', '事业 做出 重大贡献 !']
['事业' '会长' '做出' '发展' '坚定' '学会' '学校' '扶持' '支持' '教育' '期间' '民办' '民办教育' '重大贡献']
[[0.21786941 0.36888498 0. 0. 0.36888498 0.36888498
0. 0. 0.36888498 0.36888498 0.36888498 0.
0.36888498 0. ]
[0.28321692 0. 0. 0.47952794 0. 0.
0.47952794 0.47952794 0. 0. 0. 0.47952794
0. 0. ]
[0.38537163 0. 0.65249088 0. 0. 0.
0. 0. 0. 0. 0. 0.
0. 0.65249088]]
"""
print(data)
transfer = TfidfVectorizer(stop_words=[])
res = transfer.fit_transform(data)
print(transfer.get_feature_names_out())
print(res.toarray())
pd.DataFrame(res.toarray(), columns = transfer.get_feature_names_out())无量纲化-预处理
1..无量纲,即没有单位的数据
2.无量纲化包括"归一化"和"标准化", 为什么要进行无量纲化呢?
- 这是一个男士的数据表:
| 编号id | 身高 h | 收入 s | 体重 w |
|---|---|---|---|
| 1 | 1.75(米) | 15000(元) | 120(斤) |
| 2 | 1.5(米) | 16000(元) | 140(斤) |
| 3 | 1.6(米) | 20000(元) | 100(斤) |
假设算法中需要求它们之间的欧式距离, 这里以编号1和编号2为示例:
从计算上来看, 发现身高对计算结果没有什么影响, 基本主要由收入来决定了,但是现实生活中,身高是比较重要的判断标准. 所以需要无量纲化.
MinMaxScaler 归一化
1.通过对原始数据进行变换把数据映射到指定区间(默认为0-1)
归一化公式:

这里的 𝑥min 和 𝑥max 分别是每种特征中的最小值和最大值,而 𝑥是当前特征值,𝑥scaled 是归一化后的特征值。
若要缩放到其他区间,可以使用公式:x=x*(max-min)+min;
比如 -1, 1的公式为:

手算过程:

归一化API
sklearn.preprocessing.MinMaxScaler(feature_range)
1.参数
- feature_range=(0,1) 归一化后的值域,可以自己设定
- fit_transform函数归一化的原始数据类型可以是list、DataFrame和ndarray**, 不可以是稀疏矩阵**
- fit_transform函数的返回值为ndarray
归一化示例
python
import pandas as pd
scaler = MinMaxScaler(feature_range=(0,1))
data = pd.read_excel("../../src/身高体重.xlsx")
"""
[[1.75e+00 1.50e+04 1.20e+02]
[1.50e+00 1.60e+04 1.40e+02]
[1.60e+00 2.00e+04 1.00e+02]]
"""
print(data.values)
# arr = scaler.fit_transform(data.values)
arr = scaler.fit_transform(data)
"""
[[1. 0. 0.5]
[0. 0.2 1. ]
[0.4 1. 0. ]]
"""
print(arr)原始数据类型为DataFrame
python
from sklearn.preprocessing import MinMaxScaler
import pandas as pd;
data=[[12,22,4],[22,23,1],[11,23,9]]
data = pd.DataFrame(data=data, index=["一","二","三"], columns=["一列","二列","三列"])
transfer = MinMaxScaler(feature_range=(0, 1))
data_new = transfer.fit_transform(data)
print(data_new)原始数据类型为 ndarray
python
from sklearn.feature_extraction import DictVectorizer
from sklearn.preprocessing import MinMaxScaler
data = [{'city':'成都', 'age':30, 'temperature':200}, {'city':'重庆','age':33, 'temperature':60}, {'city':'北京', 'age':42, 'temperature':80}]
transfer = DictVectorizer(sparse=False)
data = transfer.fit_transform(data) #data类型为ndarray
print(data)
transfer = MinMaxScaler(feature_range=(0, 1))
data = transfer.fit_transform(data)
print(data)缺点
- 最大值和最小值容易受到异常点影响,所以鲁棒性较差。所以常使用标准化的无量钢化
StandardScaler 标准化
- 在机器学习中,标准化是一种数据预处理技术,也称为数据归一化或特征缩放。它的目的是将不同特征的数值范围缩放到统一的标准范围,以便更好地适应一些机器学习算法,特别是那些对输入数据的尺度敏感的算法。
标准化公式
- 最常见的标准化方法是Z-score标准化,也称为零均值标准化。它通过对每个特征的值减去其均值,再除以其标准差,将数据转换为均值为0,标准差为1的分布。这可以通过以下公式计算:

其中,z是转换后的数值,x是原始数据的值,μ是该特征的均值,σ是该特征的标准差
标准化 API
sklearn.preprocessing.StandardScale
与MinMaxScaler一样,原始数据类型可以是list、DataFrame和ndarray
fit_transform函数的返回值为ndarray, 归一化后得到的数据类型都是ndarray
python
from sklearn.preprocessing import StandardScale
#不能加参数feature_range=(0, 1)
transfer = StandardScaler()
data_new = transfer.fit_transform(data) #data_new的类型为ndarray标准化示例
python
from sklearn.preprocessing import StandardScaler
import numpy as np
#初始化标准化工具
scaler = StandardScaler()
np.random.seed(7)
data = np.array([[1,2,3,4],
[2,2,3,4],
[3,2,3,4],
[4,2,3,4]]
)
# data = np.random.randint(0,100,(30,4))
x = scaler.fit_transform(data)
"""
[[-1.34164079 0. 0. 0. ]
[-0.4472136 0. 0. 0. ]
[ 0.4472136 0. 0. 0. ]
[ 1.34164079 0. 0. 0. ]]
"""
print(x)注意点
在数据预处理中,特别是使用如StandardScaler这样的数据转换器时,fit、fit_transform和transform这三个方法的使用是至关重要的,它们各自有不同的作用:
(1)fit:
- 这个方法用来计算数据的统计信息,比如均值和标准差(在
StandardScaler的情况下)。这些统计信息随后会被用于数据的标准化。 - 你应当仅在训练集上使用
fit方法。
(2)fit_transform:
- 这个方法相当于先调用
fit再调用transform,但是它在内部执行得更高效。 - 它同样应当仅在训练集上使用,它会计算训练集的统计信息并立即应用到该训练集上。
(3)transform:
- 这个方法使用已经通过
fit方法计算出的统计信息来转换数据。 - 它可以应用于任何数据集,包括训练集、验证集或测试集,但是应用时使用的统计信息必须来自于训练集。
当你在预处理数据时,首先需要在训练集X_train上使用fit_transform,这样做可以一次性完成统计信息的计算和数据的标准化。这是因为我们需要确保模型是基于训练数据的统计信息进行学习的,而不是整个数据集的统计信息。
一旦scaler对象在X_train上被fit,它就已经知道了如何将数据标准化。
特征降维
1.实际数据中,有时候特征很多,会增加计算量,降维就是去掉一些特征,或者转化多个特征为少量个特征
2.特征降维其目的:是减少数据集的维度,同时尽可能保留数据的重要信息。
3.特征降维的好处
- 减少计算成本:在高维空间中处理数据可能非常耗时且计算密集。降维可以简化模型,降低训练时间和资源需求。
- 去除噪声:高维数据可能包含许多无关或冗余特征,这些特征可能引入噪声并导致过拟合。降维可以帮助去除这些不必要的特征。
4.特征降维的方式
-
特征选择:从原始特征集中挑选出最相关的特征
-
主成份分析(PCA):主成分分析就是把之前的特征通过一系列数学计算,形成新的特征,新的特征数量会小于之前特征数量
特征选择
VarianceThreshold 低方差过滤特征选择
1.Filter(过滤式): 主要探究特征本身特点, 特征与特征、特征与目标 值之间关联
(1)方差选择法: 低方差特征过滤
如果一个特征的方差很小,说明这个特征的值在样本中几乎相同或变化不大,包含的信息量很少,模型很难通过该特征区分不同的对象,比如区分甜瓜子和咸瓜子还是蒜香瓜子,如果有一个特征是长度,这个特征相差不大可以去掉。
- 计算方差:对于每个特征,计算其在训练集中的方差(每个样本值与均值之差的平方,在求平均)。
- 设定阈值:选择一个方差阈值,任何低于这个阈值的特征都将被视为低方差特征。
- 过滤特征:移除所有方差低于设定阈值的特征
函数
sklearn.feature_selection.VarianceThreshold(threshold=2.0)
1.解释
- 创建对象,准备把方差为等于小于2的去掉,threshold的缺省值为2.0 把x中低方差特征去掉, x的类型可以是DataFrame、ndarray和list VananceThreshold.fit_transform(x) fit_transform函数的返回值为ndarray
python
# 低方差过滤
from sklearn.feature_selection import VarianceThreshold
# threshold阈值(方差阈值):threshold=2.0过滤低于2的方差特征
transfer = VarianceThreshold(threshold=0.1)
x = [[0, 2, 0,3],
[0, 4, 2, 5],
[0, 6, 0, 8],]
x = transfer.fit_transform(x)
"""
# 低方差过滤
from sklearn.feature_selection import VarianceThreshold
# threshold阈值(方差阈值):threshold=2.0过滤低于2的方差特征
transfer = VarianceThreshold(threshold=0.1)
x = [[0, 2, 0,3],
[0, 4, 2, 5],
[0, 6, 0, 8],]
x = transfer.fit_transform(x)
print(x)
"""
print(x)根据相关系数的特征选择
理论
1.正相关:正相关性(Positive Correlation)是指两个变量之间的一种统计关系。
- 如果第一个变量增加,第二个变量也有很大的概率会增加。
- 同样,如果第一个变量减少,第二个变量也很可能会减少。
2.负相关
- 负相关性(Negative Correlation)与正相关性刚好相反,但是也说明相关,比如运动频率和BMI体重指数程负相关
- 不相关指两者的相关性很小,一个变量变化不会引起另外的变量变化,只是没有线性关系. 比如饭量和智商
3.皮尔逊相关系数
(1)皮尔逊相关系数(Pearson correlation coefficient)是一种度量两个变量之间线性相关性的统计量。它提供了两个变量间关系的方向(正相关或负相关)和强度的信息。皮尔逊相关系数的取值范围是 −1,1,其中:
表示完全正相关,即随着一个变量的增加,另一个变量也线性增加。
相关系数的绝对值为0-1之间,绝对值越大,表示越相关,当两特征完全相关时,两特征的值表示的向量是在同一条直线上,当两特征的相关系数绝对值很小时,两特征值表示的向量接近在同一条直线上。当相关系值为负数时,表示负相关
API
1.scipy.stats.personr(x, y) 计算两特征之间的相关性
2.返回对象有两个属性:
- statistic皮尔逊相关系数-1,1
- pvalue零假设(了解),统计上评估两个变量之间的相关性,越小越相关
3.示例
python
from scipy.stats import pearsonr
import pandas as pd
data = pd.read_csv("../../src/factor_returns.csv")
# print(data)
#取的所有行,1到-2列的数据
data = data.iloc[:, 1:-2]
# print(data)
# pd.DataFrame(data, columns=data.columns)
r = pearsonr(data["pe_ratio"], data["pb_ratio"])
print(r.statistic, r.pvalue)开发中一般不使用求相关系数的方法,一般使用主成分分析,因为主成分分样过程中就包括了求相关系数了。
主成份分析(PCA)
PCA的核心目标是从原始特征空间中找到一个新的坐标系统,使得数据在新坐标轴上的投影能够最大程度地保留数据的方差,同时减少数据的维度。
原理

投影到L的大小为
投影到L的大小为
使用表示一个点, 表明该点有两个特征, 而映射到L上有一个特征就可以表示这个点了。这就达到了降维的功能 。
投影到L上的值就是降维后保留的信息,投影到与L垂直的轴上的值就是丢失的信息。保留信息/丢失信息=信息保留的比例
下图中红线上点与点的距离是最大的,所以在红色线上点的方差最大,粉红线上的刚好相反.
所以红色线上点来表示之前点的信息损失是最小的。

步骤
1.得到矩阵
2.用矩阵P对原始数据进行线性变换,得到新的数据矩阵Z,每一列就是一个主成分, 如下图就是把10维降成了2维,得到了两个主成分

3.根据主成分的方差等,确定最终保留的主成分个数, 方差大的要留下。一个特征的多个样本的值如果都相同,则方差为0, 则说明该特征值不能区别样本,所以该特征没有用。
- 比如下图的二维数据要降为一维数据,图形法是把所在数据在二维坐标中以点的形式标出,然后给出一条直线,让所有点垂直映射到直线上,该直线有很多,只有点到线的距离之和最小的线才能让之前信息损失最小。
- 这样之前所有的二维表示的点就全部变成一条直线上的点,从二维降成了一维。

上图是一个从二维降到一维的示例:的原始数据为
| 特征1-X1 | 特征2-X2 |
|---|---|
| -1 | -2 |
| -1 | 0 |
| 0 | 0 |
| 2 | 1 |
| 0 | 1 |
降维后新的数据为
| 特征3-X0 |
|---|
| -3/√2 |
| -1/√2 |
| 0 |
| 3/√2 |
| -1/√2 |
API
from sklearn.decomposition import PCA
1.参数
(1)n_components:
- 实参为小数时:表示降维后保留百分之多少的信息
- 实参为整数时:表示减少到多少特征(降为多少维)
n_components为小数
python
from sklearn.decomposition import PCA
import pandas as pd
import numpy as np
# rand(5,100)5行100列的随机数
data = np.random.rand(5,100)
# print(data)
# n_components= 0.3百分之多少的信息量,最终找到保留比的维度数据
pca = PCA(n_components = 0.3 )
data = pca.fit_transform(data)
"""
(5, 2)
[[ 0.5485538 0.86241583]
[ 1.16059689 -0.7678228 ]
[-2.67860555 0.28730381]
[ 0.13219012 -2.13789231]
[ 0.83726474 1.75599547]]
"""
print(data.shape)
print(data)n_components为整数
python
from sklearn.decomposition import PCA
import pandas as pd
data = [[2,8,4,5],
[6,3,0,8],
[5,4,9,1]]
# 只能降维,但不可升维
# n_components=2留几个维度
pca = PCA(n_components=2)
data = pca.fit_transform(data)
"""
[[-1.28620952e-15 3.82970843e+00]
[-5.74456265e+00 -1.91485422e+00]
[ 5.74456265e+00 -1.91485422e+00]]
"""
print(data)sklearn机器学习概述
1.获取数据、数据处理、特征工程后,就可以交给预估器进行机器学习,流程和常用API如下。
(1)实例化预估器(估计器)对象(estimator), 预估器对象很多,都是estimator的子类
用于分类的预估器
- sklearn.neighbors.KNeighborsClassifier k-近邻
- sklearn.naive_bayes.MultinomialNB 贝叶斯
- sklearn.linear_model.LogisticRegressioon 逻辑回归
- sklearn.tree.DecisionTreeClassifier 决策树
- sklearn.ensemble.RandomForestClassifier 随机森林
用于回归的预估器
- sklearn.linear_model.LinearRegression线性回归
- sklearn.linear_model.Ridge岭回归
用于无监督学习的预估器
- sklearn.cluster.KMeans 聚类
(2)进行训练,训练结束后生成模型
- estimator.fit(x_train, y_train)
(3)模型评估
方式1,直接对比
- y_predict = estimator.predict(x_test)
- y_test == y_predict
方式2, 计算准确率
- accuracy = estimator.score(x_test, y_test)
(4)使用模型(预测)
- y_predict = estimator.predict(x_true)
KNN算法-分类
样本距离判断
明可夫斯基距离
欧式距离,明可夫斯基距离的特殊情况
曼哈顿距离,明可夫斯基距离的特殊情况
两个样本的距离公式可以通过如下公式进行计算,又称为欧式距离。

欧式距离


曼哈顿距离


KNN 算法原理
K-近邻算法(K-Nearest Neighbors,简称KNN),根据K个邻居样本的类别来判断当前样本的类别;
如果一个样本在特征空间中的k个最相似(最邻近)样本中的大多数属于某个类别,则该类本也属于这个类别
比如: 有10000个样本,选出7个到样本A的距离最近的,然后这7个样本中假设:类别1有2个,类别2有3个,类别3有2个.那么就认为A样本属于类别2,因为它的7个邻居中 类别2最多(近朱者赤近墨者黑)
4. 举例
使用KNN算法预测《唐人街探案》电影属于哪种类型?分别计算每个电影和预测电影的距离然后求解:

KNN缺点
- 对于大规模数据集,计算量大,因为需要计算测试样本与所有训练样本的距离。
- 对于高维数据,距离度量可能变得不那么有意义,这就是所谓的"维度灾难"
- 需要选择合适的k值和距离度量,这可能需要一些实验和调整
API
1.函数
class sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, algorithm='auto')
2.参数
- n_neighbors: int, default=5, 默认情况下用于kneighbors查询的近邻数,就是K
- algorithm:{'auto', 'ball_tree', 'kd_tree', 'brute'}, default='auto'。找到近邻的方式,注意不是计算距离的方式,与机器学习算法没有什么关系,开发中请使用默认值'auto'
3.调用方法:
- fit(x, y) :使用X作为训练数据和y作为目标数据
- predict(X) 预测提供的数据,得到预测数据
案例
python
# KNN算法
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import numpy as np
# load_iris(return_X_y=True)
iris = load_iris()
x, y = iris.data, iris.target
#先对x进行标准化预处理
#此时的标准化,算入了后面分层过后的x_text和y_test的测试集
#相当于训练集和测试集都进行了标准化,此时fit的标准差等数据是整个鸢尾花的数据
#那么在预测分层后的test数据预测率就非常高,不符合实际
#所有如果要测试预测分层后的数据,应该先进行分层,再对x进行标准化,再进行预测
# x_stander = stander.fit_transform(x)
# print(x_stander)
#划分
#对数据集进行分割
#应该对原数据进行分割
# x_train, x_test, y_train, y_test = train_test_split(x_stander, y, train_size=0.3, random_state=666)
# 应该先进行划分数据集
# 对相关train的数据标准化,作为训练集的底层数据支持,以这个底层数据来标准化其他数据
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.3, random_state=666)
#创建knn工具
stander = StandardScaler()
x_stander = stander.fit_transform(x_train)
model = KNeighborsClassifier(n_neighbors=5)
#训练,训练量越大,预测精准度越高
model.fit(x_train, y_train)
#预测
# 比较预测值和真实值(y_predict和y_test) 是否一致
# 基于这个model.fit(x_train, y_train)结果去预测给出的特征是什么样的目标
y_predict = model.predict(x_test)
# print("x_test:",x_test)
# 直接打印比较原本的y_test(target)的对应值与预测的y_predict(target)值是否一致
"""
y_predict:
[1 2 1 1 0 1 1 2 1 1 1 0 0 0 2 1 0 2 2 2 1 0 2 0 1 1 0 1 2 2 0 0 1 2 1 1 2
2 0 1 2 2 1 1 0 0 0 0 1 0 0 2 1 1 1 0 0 2 1 1 1 0 1 1 0 1 0 0 1 2 1 1 1 2
2 0 1 2 0 0 1 0 1 2 0 1 0 0 0 1 1 1 0 0 1 1 1 2 2 2 0 1 1 1 1]
y_test:
[1 2 1 2 0 1 1 2 1 1 1 0 0 0 2 1 0 2 2 2 1 0 2 0 1 1 0 1 2 2 0 0 1 2 1 1 2
2 0 1 2 2 1 1 0 0 0 0 1 0 0 2 1 1 1 0 0 2 2 1 2 0 1 1 0 1 0 0 2 2 2 1 1 2
2 0 1 2 0 0 2 0 2 2 0 1 0 0 0 1 1 1 0 0 2 1 2 2 2 2 0 2 2 1 1]
"""
print(f"y_predict:\n",y_predict)
print(f"y_test:\n",y_test)
# #评估1
# 比较预测值和真实值(y_predict和y_test),对应位置生成布尔值存入在res列表中
# res = y_predict==y_test
# print(res)
# # np.sum(res):(True值为1,False值为0,本质是对res列表的数据元素求和)True的总个数处于总个数,精准度0.9238095238095239
# score=np.sum(res)/len(res)
# print(score)
# 评估2,精准度0.9238095238095239
# 使用训练集的标准化底层基础来对预测的数据进行标准化
x_test_stand = stander.transform(x_test)
# 进行预测方法model.predict(x_test), 返回到x_test的预测值,然后和y_test进行比较,看预测值和真实值是否一致,一致的
# 可以不用单独model.predict(x_test)预测
# 直接对x_test进行预测,然后和y_test原始数据进行了比较,得出了预测值
"""
0.8952380952380953
"""
print(model.score(x_test, y_test))
#推理
x_new = [[5, 2.9, 1, 0.2],
[5.7, 2.6, 3.5, 1.0],
[6.2, 2.2, 4.5, 1.5],
[6.2, 5.5, 4.6, 1.0]]
# x_stander = stander.fit_transform(x)前面已经用数据进行了标准化了,存储在了stander中
x_new_stand = stander.transform(x_new)
# 预测出的是结果值,鸢尾花的结果值是target
y_detect = model.predict(x_new_stand)
"""
推理的结果 [0 0 0 0]
推理的结果 ['setosa' 'setosa' 'setosa' 'setosa']
"""
print("推理的结果",y_detect)
# target的0,1,2对应的是target_names的索引值,不同的索引值对应不同的鸢尾花
print("推理的结果",iris.target_names[y_detect])模型保存与加载
保存
python
# KNN算法
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import numpy as np
import joblib
# load_iris(return_X_y=True)
iris = load_iris()
x, y = iris.data, iris.target
#对数据集进行分割
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.3, random_state=666)
stander = StandardScaler()
#对x进行标准化预处理
x_stander = stander.fit_transform(x_train)
#划分
#创建knn工具
model = KNeighborsClassifier(n_neighbors=5)
#训练,训练量越大,预测精准度越高
model.fit(x_train, y_train)
#预测
# 比较预测值和真实值(y_predict和y_test) 是否一致
y_predict = model.predict(x_test)
# print("x_test:",x_test)
print(f"y_predict:\n",y_predict)
print(f"y_test:\n",y_test)
# #评估1
# res = y_predict==y_test
# print(res)
# # True的总个数处于总个数,精准度0.9238095238095239
# score=np.sum(res)/len(res)
# print(score)
# 评估2,精准度0.9238095238095239
# 进行预测方法model.predict(x_test), 返回到x_test的预测值,然后和y_test进行比较,看预测值和真实值是否一致,一致的
# 可以不用单独model.predict(x_test)预测
print(model.score(x_test, y_test))
# 模型保存
# model.fit(x_train, y_train)保存的模型是已经进行训练过的模型
joblib.dump(model, "../model/knn.pkl")加载
python
import joblib
#加载模型
model = joblib.load("../model/knn.pkl")
# 推理
x = stander.transform([[1,2,3,4]])
y = model.predict(x)
print(y)模型选择与调优
交叉验证
保留交叉验证HoldOut(HoldOut Cross-validation(Train-Test Split))
1.在这种交叉验证技术中,整个数据集被随机地划分为训练集和验证集。根据经验法则,整个数据集的近70%被用作训练集,其余30%被用作验证集。也就是我们最常使用的,直接划分数据集的方法。
2.优点:很简单很容易执行。
3.缺点
- 不适用于不平衡的数据集。假设我们有一个不平衡的数据集,有0类和1类。假设80%的数据属于 "0 "类,其余20%的数据属于 "1 "类。这种情况下,训练集的大小为80%,测试数据的大小为数据集的20%。可能发生的情况是,所有80%的 "0 "类数据都在训练集中,而所有 "1 "类数据都在测试集中。因此,我们的模型将不能很好地概括我们的测试数据,因为它之前没有见过 "1 "类的数据。
- 一大块数据被剥夺了训练模型的机会。
在小数据集的情况下,有一部分数据将被保留下来用于测试模型,这些数据可能具有重要的特征,而我们的模型可能会因为没有在这些数据上进行训练而错过。
K-折交叉验证(K-fold)(K-fold Cross Validation,记为K-CV或K-fold)
1.K-Fold交叉验证技术中,整个数据集被划分为K个大小相同的部分。每个分区被称为 一个"Fold"。所以我们有K个部分,我们称之为K-Fold。一个Fold被用作验证集,其余的K-1个Fold被用作训练集。
该技术重复K次,直到每个Fold都被用作验证集,其余的作为训练集。
模型的最终准确度是通过取k个模型验证数据的平均准确度来计算的。

分层k-折交叉验证Stratified k-fold(Stratified k-fold cross validation)
1.K-折交叉验证的变种, 分层的意思是说在每一折中都保持着原始数据中各个类别的比例关系,比如说:原始数据有3类,比例为1:2:1,采用3折分层交叉验证,那么划分的3折中,每一折中的数据类别保持着1:2:1的比例,这样的验证结果更加可信。

其它验证
- 去除p交叉验证)
- 留一交叉验证)
- 蒙特卡罗交叉验证
- 时间序列交叉验证
API
from sklearn.model_selection import StratifiedKFold
说明:普通K折交叉验证和分层K折交叉验证的使用是一样的 只是引入的类不同
from sklearn.model_selection import KFold
使用时只是KFold这个类名不一样其他代码完全一样
分层K折交叉验证
strat_k_fold=sklearn.model_selection.StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
1.参数
- n_splits:划分为几个折叠
- shuffle:是否在拆分之前被打乱(随机化)
- False:则按照顺序拆分
- random_state:随机因子
- indexs=strat_k_fold.split(X,y)
2.返回值
- 返回一个可迭代对象,一共有5个折叠,每个折叠对应的是训练集和测试集的下标
- 然后可以用for循环取出每一个折叠对应的X和y下标来访问到对应的测试数据集和训练数据集 以及测试目标集和训练目标集
for train_index, test_index in indexs:
Xtrain_index ytrain_index Xtest_index ytest_index
示例
python
from sklearn.datasets import load_iris
from sklearn.model_selection import StratifiedKFold
from sklearn.neighbors import KNeighborsClassifier
# 返回data和target数据
x,y = load_iris(return_X_y=True)
# 创建交叉验证工具,使用交叉验证就可以不用再进行分层了
# 交叉验证已经对数据进行了分层,训练集和测试集包含原数据的不同数据
folder = StratifiedKFold(n_splits=5, shuffle=True, random_state=666)
iter = folder.split(x,y)
# 创建knn算法工具
knn = KNeighborsClassifier(n_neighbors=7)
# 创建一个空列表来储存预测值
score_arr=[]
# 遍历交叉验证分层索引(x的行索引)
for train_index, test_index in iter:
X_train, X_test = x[train_index], x[test_index]
y_train, y_test = y[train_index], y[test_index]
model=knn.fit(X_train, y_train)
s = model.score(X_test, y_test)
score_arr.append(s)
"""
[1.0]
平均准确率率: 1.0
[1.0, 0.9666666666666667]
平均准确率率: 0.9833333333333334
[1.0, 0.9666666666666667, 0.9666666666666667]
平均准确率率: 0.9777777777777779
[1.0, 0.9666666666666667, 0.9666666666666667, 1.0]
平均准确率率: 0.9833333333333334
[1.0, 0.9666666666666667, 0.9666666666666667, 1.0, 1.0]
平均准确率率: 0.9866666666666667
"""
print(score_arr)
# score_arr的值在0-1之间,而len长度就代表完全预测准确的预测率相加
# sum(score_arr)计算的是列表中数值的总和
# sum(score_arr)/len(score_arr)就是平均准确率
print("平均准确率率:", sum(score_arr)/len(score_arr))超参数搜索(超参数搜索也叫网格搜索(Grid Search))
- 比如在KNN算法中,k是一个可以人为设置的参数,所以就是一个超参数。网格搜索能自动的帮助我们找到最好的超参数值。

sklearn API
class sklearn.model_selection.GridSearchCV(estimator, param_grid)
1.说明:同时进行交叉验证(CV)、和网格搜索(GridSearch),GridSearchCV实际上也是一个估计器(estimator),同时它有几个重要属性:
- best_params_ 最佳参数
- best_score_ 在训练集中的准确率
- best_estimator_ 最佳估计器
- cv_results_ 交叉验证过程描述
- best_index_最佳k在列表中的下标
3.参数
- estimator: scikit-learn估计器实例
- param_grid:以参数名称(str)作为键,将参数设置列表尝试作为值的字典
4.示例: {"n_neighbors": 1, 3, 5, 7, 9, 11}
5.cv: 确定交叉验证切分策略,值为:
- None 默认5折
- integer 设置多少折
如果估计器是分类器,使用"分层k-折交叉验证(StratifiedKFold)"。在所有其他情况下,使用KFold。
示例
python
# 超参数的选择(网格搜素)
from sklearn.model_selection import GridSearchCV
from sklearn.neighbors import KNeighborsClassifier
from sklearn.datasets import load_iris
X_train, y_train = load_iris(return_X_y=True)
model = KNeighborsClassifier()
# 返回预估器estimator
# 自动保留了分层,交叉验证的功能,但没有标准化的处理
model = GridSearchCV(estimator=model, param_grid={'n_neighbors': [5,7,9,10]})
model.fit(X_train, y_train)
"""
best_params_ 最佳参数 {'n_neighbors': 7}
best_score_ 在训练within的准确率 0.9800000000000001
best_estimator_ 最佳估计器 KNeighborsClassifier(n_neighbors=7)
cv_results_ 交叉验证过程描述 {'mean_fit_time': array([0.00099769, 0.00080194, 0.00080323, 0.00099602]), 'std_fit_time': array([2.37271410e-06, 4.01007366e-04, 7.52600774e-04, 1.40100892e-05]), 'mean_score_time': array([0.00360088, 0.00339947, 0.00339456, 0.00300517]), 'std_score_time': array([4.88463229e-04, 4.85243503e-04, 4.84330884e-04, 7.56294399e-06]), 'param_n_neighbors': masked_array(data=[5, 7, 9, 10],
mask=[False, False, False, False],
fill_value=999999), 'params': [{'n_neighbors': 5}, {'n_neighbors': 7}, {'n_neighbors': 9}, {'n_neighbors': 10}], 'split0_test_score': array([0.96666667, 0.96666667, 0.96666667, 0.96666667]), 'split1_test_score': array([1., 1., 1., 1.]), 'split2_test_score': array([0.93333333, 0.96666667, 0.96666667, 1. ]), 'split3_test_score': array([0.96666667, 0.96666667, 0.93333333, 0.93333333]), 'split4_test_score': array([1., 1., 1., 1.]), 'mean_test_score': array([0.97333333, 0.98 , 0.97333333, 0.98 ]), 'std_test_score': array([0.02494438, 0.01632993, 0.02494438, 0.02666667]), 'rank_test_score': array([3, 1, 3, 1], dtype=int32)}
best_index_最佳k在列表中的下标 1
"""
# best_params_ 最佳参数
print("best_params_ 最佳参数",model.best_params_)
# best_score_ 在训练集中的准确率
print("best_score_ 在训练within的准确率",model.best_score_)
# best_estimator_ 最佳估计器
print("best_estimator_ 最佳估计器",model.best_estimator_)
# cv_results_ 交叉验证过程描述
print("cv_results_ 交叉验证过程描述",model.cv_results_)
# best_index_最佳k在列表中的下标,最佳参数的下标
print("best_index_最佳k在列表中的下标",model.best_index_)朴素贝叶斯分类
贝叶斯分类理论
假设现在我们有一个数据集,它由两类数据组成,数据分布如下图所示:

我们现在用p1(x,y)表示数据点(x,y)属于类别1(图中红色圆点表示的类别)的概率,用p2(x,y)表示数据点(x,y)属于类别2(图中蓝色三角形表示的类别)的概率,那么对于一个新数据点(x,y),可以用下面的规则来判断它的类别:
-
如果p1(x,y)>p2(x,y),那么类别为1
-
如果p1(x,y)<p2(x,y),那么类别为2
也就是说,我们会选择高概率对应的类别。这就是贝叶斯决策理论的核心思想,即选择具有最高概率的决策。
条件概率
- 在学习计算p1 和p2概率之前,我们需要了解什么是条件概率(Conditional probability),就是指在事件B发生的情况下,事件A发生的概率,用P(A|B)来表示。

- 根据文氏图,可以很清楚地看到在事件B发生的情况下,事件A发生的概率就是P(A∩B)除以P(B)。
𝑃(𝐴|𝐵)=𝑃(𝐴∩𝐵)/𝑃(𝐵)
- 因此,
𝑃(𝐴∩𝐵)=𝑃(𝐴|𝐵)𝑃(𝐵)
- 同理可得,
𝑃(𝐴∩𝐵)=𝑃(𝐵|𝐴)𝑃(𝐴)
- 即
𝑃(𝐴|𝐵)=𝑃(B|A)𝑃(𝐴)/𝑃(𝐵)
- 这就是条件概率的计算公式。
全概率公式
- 除了条件概率以外,在计算p1和p2的时候,还要用到全概率公式,因此,这里继续推导全概率公式。
- 假定样本空间S,是两个事件A与A'的和。

- 上图中,红色部分是事件A,绿色部分是事件A',它们共同构成了样本空间S。
- 在这种情况下,事件B可以划分成两个部分。

- 即:
𝑃(𝐵)=𝑃(𝐵∩𝐴)+𝑃(𝐵∩𝐴′)
- 在上面的推导当中,我们已知
𝑃(𝐵∩𝐴)=𝑃(𝐵|𝐴)𝑃(𝐴)
- 所以:
𝑃(𝐵)=𝑃(𝐵|𝐴)𝑃(𝐴)+𝑃(𝐵|𝐴′)𝑃(𝐴′)
- 这就是全概率公式。它的含义是,如果A和A'构成样本空间的一个划分,那么事件B的概率,就等于A和A'的概率分别乘以B对这两个事件的条件概率之和。
- 将这个公式代入上一节的条件概率公式,就得到了条件概率的另一种写法:
贝叶斯推断
- 对条件概率公式进行变形,可以得到如下形式:

- 我们把P(A)称为"先验概率"(Prior probability),即在B事件发生之前,我们对A事件概率的一个判断。
- P(A|B)称为"后验概率"(Posterior probability),即在B事件发生之后,我们对A事件概率的重新评估。
- P(B|A)/P(B)称为"可能性函数"(Likelyhood),这是一个调整因子,使得预估概率更接近真实概率。
所以,条件概率可以理解成下面的式子:
- 后验概率 = 先验概率x调整因子
这就是贝叶斯推断的含义。我们先预估一个"先验概率",然后加入实验结果,看这个实验到底是增强还是削弱了"先验概率",由此得到更接近事实的"后验概率"。
朴素贝叶斯推断
理解了贝叶斯推断,那么让我们继续看看朴素贝叶斯。贝叶斯和朴素贝叶斯的概念是不同的,区别就在于"朴素"二字,朴素贝叶斯对条件概率分布做了条件独立性的假设。 比如下面的公式,假设有n个特征:
根据贝叶斯定理,后验概率 P(a|X) 可以表示为:
其中:
- P(X|a) 是给定类别 ( a ) 下观测到特征向量 X=(x_1, x_2, ..., x_n) 的概率;
- P(a) 是类别 a 的先验概率;
- P(X) 是观测到特征向量 X 的边缘概率,通常作为归一化常数处理。
朴素贝叶斯分类器的关键假设是特征之间的条件独立性,即给定类别 a ,特征 和
(其中
相互独立。)
因此,我们可以将联合概率 P(X|a) 分解为各个特征的概率乘积:
将这个条件独立性假设应用于贝叶斯公式,我们得到:
这样,朴素贝叶斯分类器就可以通过计算每种可能类别的条件概率和先验概率,然后选择具有最高概率的类别作为预测结果。
这样我们就可以进行计算了。如果有些迷糊,让我们从一个例子开始讲起,你会看到贝叶斯分类器很好懂,一点都不难。
| 纹理 | 色泽 | 鼔声 | 类别 | |
|---|---|---|---|---|
| 1 | 清晰 | 清绿 | 清脆 | 好瓜 |
| 2 | 模糊 | 乌黑 | 浊响 | 坏瓜 |
| 3 | 模糊 | 清绿 | 浊响 | 坏瓜 |
| 4 | 清晰 | 乌黑 | 沉闷 | 好瓜 |
| 5 | 清晰 | 清绿 | 浊响 | 好瓜 |
| 6 | 模糊 | 乌黑 | 沉闷 | 坏瓜 |
| 7 | 清晰 | 乌黑 | 清脆 | 好瓜 |
| 8 | 模糊 | 清绿 | 沉闷 | 好瓜 |
| 9 | 清晰 | 乌黑 | 浊响 | 坏瓜 |
| 10 | 模糊 | 清绿 | 清脆 | 好瓜 |
| 11 | 清晰 | 清绿 | 沉闷 | ? |
| 12 | 模糊 | 乌黑 | 浊响 | ? |
示例: p(a|X) = p(X|a)* p(a)/p(X) p(X|a) = p(x1,x2,x3...xn|a) = p(x1|a)*p(x2|a)*p(x3|a)...p(xn|a) p(X) = p(x1,x2,x3...xn) = p(x1)*p(x2)*p(x3)...p(xn) p(a|X) = p(x1|a)*p(x2|a)*p(x3|a)...p(xn|a) * p(a) / p(x1)*p(x2)*p(x3)...p(xn) P(好瓜)=(好瓜数量)/所有瓜 P(坏瓜)=(坏瓜数量)/所有瓜 p(纹理清晰)=(纹理清晰数量)/所有瓜 p(纹理清晰|好瓜)= 好瓜中纹理清晰数量/好瓜数量 p(纹理清晰|坏瓜)= 坏瓜中纹理清晰数量/坏瓜数量 p(好瓜|纹理清晰,色泽清绿,鼓声沉闷) =【p(好瓜)】*【p(纹理清晰,色泽清绿,鼓声沉闷|好瓜)】/【p(纹理清晰,色泽清绿,鼓声沉闷)】 =【p(好瓜)】*【p(纹理清晰|好瓜)*p(色泽清绿|好瓜)*p(鼓声沉闷|好瓜)】/【p(纹理清晰)*p(色泽清绿)*p(鼓声沉闷)】 p(坏瓜|纹理清晰,色泽清绿,鼓声沉闷) =【p(坏瓜)*p(纹理清晰|坏瓜)*p(色泽清绿|坏瓜)*p(鼓声沉闷|坏瓜)】/【p(纹理清晰)*p(色泽清绿)*p(鼓声沉闷)】 从公式中判断"p(好瓜|纹理清晰,色泽清绿,鼓声沉闷)"和"p(坏瓜|纹理清晰,色泽清绿,鼓声沉闷)"时,因为它们的分母 值是相同的,[值都是p(纹理清晰)*p(色泽清绿)*p(鼓声沉闷)],所以只要计算它们的分子就可以判断是"好瓜"还是"坏瓜"之间谁大谁小了,所以没有必要计算分母 p(好瓜) = 6/10 p(坏瓜)=4/10 p(纹理清晰|好瓜) = 4/6 p(色泽清绿|好瓜) = 4/6 p(鼓声沉闷|好瓜) = 2/6 p(纹理清晰|坏瓜) = 1/4 p(色泽清绿|坏瓜) = 1/4 p(鼓声沉闷|坏瓜) = 1/4 把以上计算代入公式的分子 p(好瓜)*p(纹理清晰|好瓜)*p(色泽清绿|好瓜)*p(鼓声沉闷|好瓜) = 4/45 p(坏瓜)*p(纹理清晰|坏瓜)*p(色泽清绿|坏瓜)*p(鼓声沉闷|坏瓜) = 1/160 所以 p(好瓜|纹理清晰,色泽清绿,鼓声沉闷) > p(坏瓜|纹理清晰,色泽清绿,鼓声沉闷), 所以把(纹理清晰,色泽清绿,鼓声沉闷)的样本归类为好瓜
拉普拉斯平滑系数
某些事件或特征可能从未出现过,这会导致它们的概率被估计为零。然而,在实际应用中,即使某个事件或特征没有出现在训练集中,也不能完全排除它在未来样本中出现的可能性。拉普拉斯平滑技术可以避免这种"零概率陷阱"
公式为:

通过这种方法,即使某个特征在训练集中从未出现过,它的概率也不会被估计为零,而是会被赋予一个很小但非零的值,从而避免了模型在面对新数据时可能出现的过拟合或预测错误
比如计算判断新瓜(纹理清晰,色泽淡白,鼓声沉闷)是好和坏时,因为在样本中色泽淡白没有出现,导致出现0值,会影响计算结果,要采用拉普拉斯平滑系数
p(好瓜|纹理清晰,色泽淡白,鼓声沉闷) =【p(好瓜)】*【p(纹理清晰|好瓜)*p(色泽淡白|好瓜)*p(鼓声沉闷|好瓜)】/【p(纹理清晰)*p(色泽淡白)*p(鼓声沉闷)】 p(坏瓜|纹理清晰,色泽淡白,鼓声沉闷) =【p(坏瓜)】*【p(纹理清晰|坏瓜)*p(色泽淡白|坏瓜)*p(鼓声沉闷|坏瓜)】/【p(纹理清晰)*p(色泽淡白)*p(鼓声沉闷)】 p(纹理清晰|好瓜)= (4+1)/(6+3) # +1是因为防止零概率 +3是因为有3个特征(纹理,色泽,鼓声) p(色泽淡白|好瓜)= (0+1)/(6+3) p(鼓声沉闷|好瓜) = (2+1)/(6+3) p(纹理清晰|坏瓜)= (1+1)/(4+3) p(色泽淡白|坏瓜)= (0+1)/(4+3) p(鼓声沉闷|坏瓜) = (1+1)/(4+3)
sklearn API
sklearn.naive_bayes.MultinomialNB() estimator.fit(x_train, y_train) y_predict = estimator.predict(x_test)
sklearn 示例
用朴素贝叶斯算法对鸢尾花的分类
python
from sklearn.datasets import load_iris
from sklearn.naive_bayes import MultinomialNB
from sklearn.model_selection import train_test_split
import joblib
# 实例化一个贝叶斯分类器
model = MultinomialNB()
#加载鸢尾花数据集
x,y = load_iris(return_X_y=True)
#划分数据集
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size = 0.7, random_state = 666, stratify = y)
#训练
model.fit(x_train, y_train)
#评估
score = model.score(x_test, y_test)
#保存模型
joblib.dump(model, '..\model\iris_bayes.bin')
python
import joblib
model = joblib.load('..\model\iris_bayes.bin')
y_pred = model.predict([[5.1,3.5,1.4,0.2]])
print(y_pred)泰坦尼克号
python
# 泰坦尼克的数据集 贝叶斯分类
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.naive_bayes import MultinomialNB
from sklearn.feature_extraction import DictVectorizer
# 加载的问价以Da'ataFrame格式存储在jupyter notebook中
data = pd.read_csv('..\\src\\titanic\\titanic.csv')
x = data[["age", "sex", "pclass"]]
# print(type(x))
# x
# 数据处理
# age中的缺失值用众数填充
# 不管怎么填充都会发出警告,修改原数据,没有返回值
# x["age"].fillna(x["age"].value_counts().index[0], inplace=True)
# model_age = x["age"].mode()[0]
# x["age"].fillna(model_age, inplace=True)
# 用索引去填充空值不会发生警告,获取特征数据
x.loc[x["age"].isnull(), "age"] = x["age"].mode()[0]
x
# # display(x)
# 获取目标数据
y = data[["survived"]]
# 不是字典,不可以用DictVectorizer来转换
# dictvector = DictVectorizer(sparse=False)
"""
res = 1 if x>0 else x
arr = [i*2 for i in arr]
# [i*2,i*2,i*2]
"""
# x["sex"] = [1 if i == "male" else 0 for i in x["sex"]]
# 报错
# x["age"] = (1 if i > 30 else 0 for i in x["age"])
x["sex"] = x["sex"].map({"female": 0, "male": 1})
# # display(x)
x["pclass"] = [int(i[:-2]) for i in x["pclass"]]
# # 创建模型
model = MultinomialNB()
# #数据划分
x_train, x_test, y_train, y_test = train_test_split(x, y, train_size=0.8, random_state=666)
# #训练模型
model.fit(x_train, y_train)
# # 评估
print(model.score(x_test, y_test))
# # 预测
print(model.predict([[33, 1, 1]]))决策树-分类
概念
1、决策节点 通过条件判断而进行分支选择的节点。如:将某个样本中的属性值(特征值)与决策节点上的值进行比较,从而判断它的流向。
2、叶子节点 没有子节点的节点,表示最终的决策结果。
3、决策树的深度 所有节点的最大层次数。
决策树具有一定的层次结构,根节点的层次数定为0,从下面开始每一层子节点层次数增加
4、决策树优点:
可视化 - 可解释能力-对算力要求低
5、 决策树缺点:
容易产生过拟合,所以不要把深度调整太大了。


| 是动物 | 会飞 | 有羽毛 | |
|---|---|---|---|
| 1麻雀 | 1 | 1 | 1 |
| 2蝙蝠 | 1 | 1 | 0 |
| 3飞机 | 0 | 1 | 0 |
| 4熊猫 | 1 | 0 | 0 |
是否为动物
| 是动物 | 会飞 | 有羽毛 | |
|---|---|---|---|
| 1麻雀 | 1 | 1 | 1 |
| 2蝙蝠 | 1 | 1 | 0 |
| 4熊猫 | 1 | 0 | 0 |
是否会飞
| 是动物 | 会飞 | 有羽毛 | |
|---|---|---|---|
| 1麻雀 | 1 | 1 | 1 |
| 2蝙蝠 | 1 | 1 | 0 |
是否有羽毛
| 是动物 | 会飞 | 有羽毛 | |
|---|---|---|---|
| 1麻雀 | 1 | 1 | 1 |
信息增益决策树
信息熵
- 信息熵描述的是不确定性。信息熵越大,不确定性越大。信息熵的值越小,则D的纯度越高。
信息增益
- 信息增益是一个统计量,用来描述一个属性区分数据样本的能力。信息增益越大,那么决策树就会越简洁。
基于基尼指数决策树的建立(了解)
基尼指数(Gini Index)是决策树算法中用于评估数据集纯度的一种度量,基尼指数衡量的是数据集的不纯度,或者说分类的不确定性。在构建决策树时,基尼指数被用来决定如何对数据集进行最优划分,以减少不纯度。
基尼指数的计算
- 对于一个二分类问题,如果一个节点包含的样本属于正类的概率是 (p),则属于负类的概率是 (1-p)。那么,这个节点的基尼指数 (Gini(p)) 定义为:
- 对于多分类问题,如果一个节点包含的样本属于第 k 类的概率是 p_k,则节点的基尼指数定义为:
基尼指数的意义
- 当一个节点的所有样本都属于同一类别时,基尼指数为 0,表示纯度最高。
- 当一个节点的样本均匀分布在所有类别时,基尼指数最大,表示纯度最低。
决策树中的应用
- 在构建决策树时,我们希望每个内部节点的子节点能更纯,即基尼指数更小。因此,选择分割特征和分割点的目标是使子节点的平均基尼指数最小化。具体来说,对于一个特征,我们计算其所有可能的分割点对应的子节点的加权平均基尼指数,然后选择最小化这个值的分割点。这个过程会在所有特征中重复,直到找到最佳的分割特征和分割点。
APL
1.函数
class sklearn.tree.DecisionTreeClassifier(....)
2.参数
(1)criterion (默认为="gini")
- 当criterion="gini":采用 基尼不纯度(Gini impurity)算法构造决策树,
- 当criterion="entropy":采用信息增益( information gain)算法构造决策树.
(2)max_depth int, 默认为=None 树的最大深度
3.可视化工具
python
function sklearn.tree.export_graphviz(estimator, out_file="iris_tree.dot", feature_names=iris.feature_names)(1)参数
- estimator决策树预估器
- out_file生成的文档
- feature_names节点特征属性名
(2)网站
把生成的文档打开,复制出内容粘贴到"http://webgraphviz.com/"中,点击"generate Graph"会生成一个树型的决策树图
4.实例
python
from sklearn.tree import DecisionTreeClassifier, export_graphviz
from sklearn.datasets import load_iris
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
x, y =load_iris(return_X_y=True)
# entropy信息熵的方式构建决策树
# criterion="gini" 默认
model =DecisionTreeClassifier(criterion="entropy", max_depth=2)
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25, random_state=666)
scaler =StandardScaler()
scaler.fit(x_train)
x_train_scaler =scaler.transform(x_train)
model.fit(x_train_scaler, y_train)
x_test_scaler =scaler.transform(x_test)
# x_test_scaler进行预测,生成的预测与y_test进行比较
print(model.score(x_test_scaler, y_test))
y_pred=model.predict([[1,1,1,1], [2,2,2,2]])
print(y_pred)
iris = load_iris()
# 决策过程可视化
export_graphviz(model, out_file="..\\model\\tree.dot", feature_names = iris.feature_names)
"""
0.9736842105263158
[2 2]
"""集成学习方法之随机森林
机器学习中有一种大类叫集成学习(Ensemble Learning),集成学习的基本思想就是将多个分类器组合,从而实现一个预测效果更好的集成分类器。集成算法可以说从一方面验证了中国的一句老话:三个臭皮匠,赛过诸葛亮。集成算法大致可以分为:Bagging,Boosting 和 Stacking 三大类型。
- 每次有放回地从训练集中取出 n 个训练样本,组成新的训练集;
- 利用新的训练集,训练得到M个子模型;
- 对于分类问题,采用投票的方法,得票最多子模型的分类类别为最终的类别;
随机森林就属于集成学习,是通过构建一个包含多个决策树(通常称为基学习器或弱学习器)的森林,每棵树都在不同的数据子集和特征子集上进行训练,最终通过投票或平均预测结果来产生更准确和稳健的预测。这种方法不仅提高了预测精度,也降低了过拟合风险,并且能够处理高维度和大规模数据集
算法原理

1.随机: 特征随机,训练集随机
- 样本:对于一个总体训练集T,T中共有N个样本,每次有放回地随机选择n个样本。用这n个样本来训练一个决策树。
- 特征:假设训练集的特征个数为d,每次仅选择k(k<d)个来构建决策树。
2.森林: 多个决策树分类器构成的分类器, 因为随机,所以可以生成多个决策树
3.处理具有高维特征的输入样本,而且不需要降维
4.使用平均或者投票来提高预测精度和控制过拟合
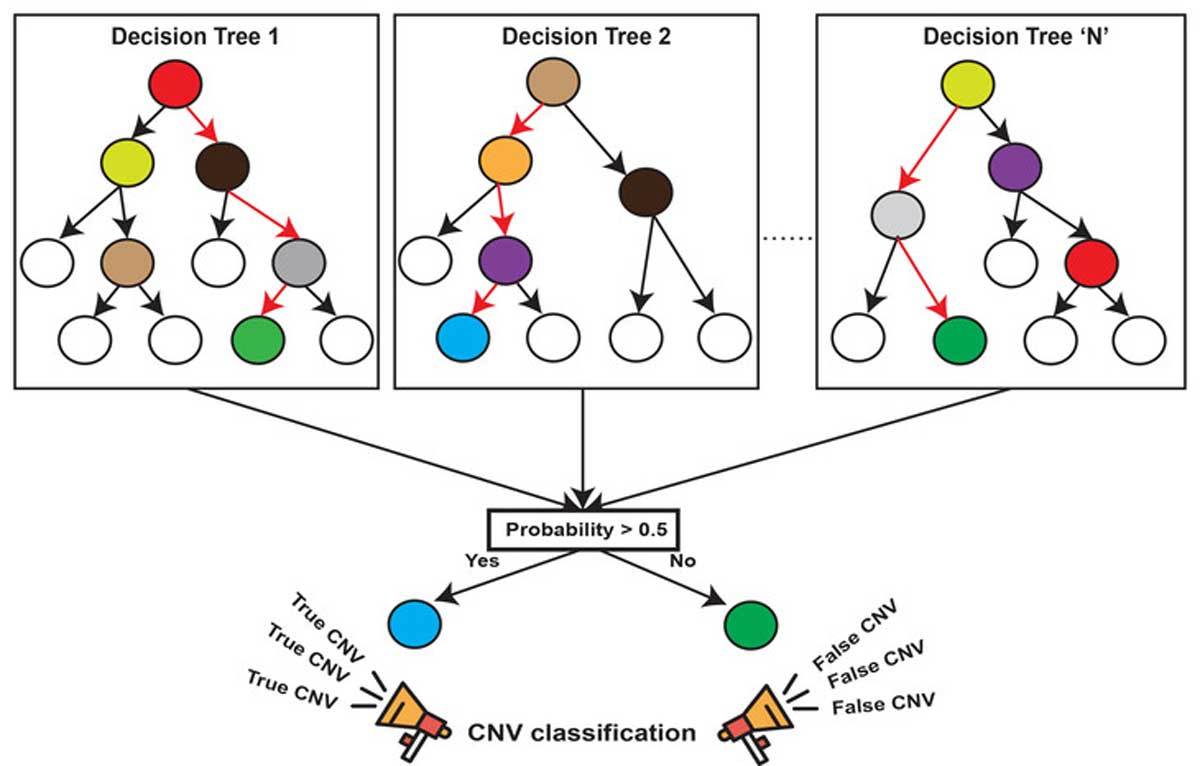
Sklearn API
1.函数
class sklearn.ensemble.RandomForestClassifier
2.参数:
(1)n_estimators( int, default=100):森林中树木的数量。(决策树个数)
- gini:基尼不纯度(Gini impurity)算法构造决策树,
- entropy:信息增益( information gain)算法构造决策树.
(2)max_depth int, default=None 树的最大深度。
3.示例
python
# 随机森林
from sklearn.ensemble import RandomForestClassifier
import pandas as pd
from sklearn.feature_extraction import DictVectorizer
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
data = pd.read_csv("..\src\\titanic\\titanic.csv")
data["age"].fillna(data["age"].mode()[0], inplace=True)
# data.tail()
# x = data[["pclass", "age", "sex"]]
# y = data[["survived"]] 取出的是某列不是numpyy array数组
y = data[["survived"]].to_numpy()
# print(y)
data.drop(["survived"], axis=1, inplace=True)
x =data
display(x)
dict1 = data.to_dict(orient='records')
# dict1
vec = DictVectorizer(sparse=False)
x= vec.fit_transform(dict1)
display(x)
print(vec.feature_names_)
# 分割数据
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.25, random_state=666)
# 标准化
scaler = StandardScaler()
x_train = scaler.fit_transform(x_train)
x_test = scaler.transform(x_test)
# 随机森林
rf = RandomForestClassifier(n_estimators=100, max_depth=4, criterion="gini")
# 训练
rf.fit(x_train, y_train)
# 模型评估
print("测试集的准确率是:", rf.score(x_test, y_test))线性回归(重点)
- 分类的目标变量是标称型数据 ,回归是对连续型的数据做出预测。
标称型数据
1.标称型数据(Nominal Data)是统计学和数据分析中的一种数据类型,它用于分类或标记不同的类别或组别,数据点之间并没有数值意义上的距离或顺序。例如,颜色(红、蓝、绿)、性别(男、女)或产品类别(A、B、C)。
2.标称数据的特点:
- 无序性:标称数据的各个类别之间没有固有的顺序关系。例如,"性别"可以分为"男"和"女",但"男"和"女"之间不存在大小、高低等顺序关系。
- 非数值性:标称数据不能进行数学运算,因为它们没有数值含义。你不能对"颜色"或"品牌"这样的标称数据进行加减乘除。
- 多样性:标称数据可以有很多不同的类别,具体取决于研究的主题或数据收集的目的。比如西瓜的颜色,纹理,敲击声响这些数据就属于标称型数据,适用于西瓜分类
连续型数据
1.连续型数据(Continuous Data)表示在某个范围内可以取任意数值的测量,这些数据点之间有明确的数值关系和距离。例如,温度、高度、重量等
2.连续型数据的特点包括:
- 可测量性:连续型数据通常来源于物理测量,如长度、重量、温度、时间等,这些量是可以精确测量的。
- 无限可分性:连续型数据的取值范围理论上是无限可分的,可以无限精确地细分。例如,你可以测量一个物体的长度为2.5米,也可以更精确地测量为2.53米,甚至2.5376米,等等。
- 数值运算:连续型数据可以进行数学运算,如加、减、乘、除以及求平均值、中位数、标准差等统计量。
3.在数据分析中,连续型数据的处理和分析方式非常丰富,常见的有:
- 描述性统计:计算均值、中位数、众数、标准差、四分位数等,以了解数据的中心趋势和分布情况。
- 概率分布:通过拟合概率分布模型,如正态分布、指数分布、伽玛分布等,来理解数据的随机特性。
- 图形表示:使用直方图、密度图、箱线图、散点图等来可视化数据的分布和潜在的模式。
- 回归分析:建立连续型变量之间的数学关系,预测一个或多个自变量如何影响因变量。比如西瓜的甜度,大小,价格这些数据就属于连续型数据,可以用于做回归
回归
回归的目的是预测数值型的目标值y。最直接的办法是依据输入x写出一个目标值y的计算公式。
求这些回归系数(用现有的xy数据去求出满足类似条件的方程)的过程就是回归。一旦有了这些回归系数,再给定输入,做预测就非常容易了。具体的做法是用回归系数乘以输入值,再将结果全部加在一起,就得到了预测值。
线性回归(思路)
对于回归一般都是指线性回归(linear regression)。
线性回归意味着可以将输入项分别乘以一些常量,再将结果加起来得到输出。线性回归是机器学习中一种有监督学习 的算法,回归问题 主要关注的是因变量 (需要预测的值)和一个或多个数值型的自变量(预测变量)之间的关系.
- 需要预测的值:即目标变量,target,y
- 影响目标变量的因素:
- 因变量和自变量之间的关系:即模型,model,就是我们要求解的
人工智能中的线性回归:数据集中,往往找不到一个完美的方程式来100%满足所有的y目标
我们就需要找出一个最接近真理的方程式
损失函数
- 对于数据: \[4.2, 3.8,4.2, 2.7,2.7, 2.4,0.8, 1.0,3.7, 2.8,1.7, 0.9,3.2, 2.9]
- 我们假设 这个最优的方程是:
- 我们有很多方式认为某条直线是最优的,其中一种方式:均方差
- 就是每个点到线的竖直方向的距离平方 求和 在平均 最小时 这条直接就是最优直线

- 假设:
- 把带入进去 然后得出:
...
- 然后计算
- 有的点在上面有点在下面,如果直接相加有负数和正数会抵消,体现不出来总误差,平方后就不会有这个问题了
- 总误差(也就是传说中的损失):
- 平均误差(总误差会受到样本点的个数的影响,样本点越多,该值就越大,所以我们可以对其平均化,求得平均值,这样就能解决样本点个数不同带来的影响)
- 这样就得到了传说中的损失函数:
- 根据求导求出最值
多参数回归(思路)
多元线性回归:
b是截距,我们也可以使用w_0来表示只要是个常量就行
那么损失函数就是
求解知识(具体百度了解)
- 最小二乘法MSE
- 前景知识: 矩阵相关公式
- 最小二乘法
API
sklearn.linear_model.LinearRegression()
1.功能: 普通最小二乘法线性回归, 权重和偏置是直接算出来的,对于数量大的不适用,因为计算量太大,计算量太大的适合使用递度下降法
2.参数:
- fit_intercept bool, default=True :是否计算此模型的截距(偏置)。如果设置为False,则在计算中将不使用截距(即,数据应中心化)。
3.属性:
- coef_ 回归后的权重系数
- intercept_ 偏置
示例
python
# 线性回归
from sklearn.linear_model import LinearRegression
import numpy as np
# fit_intercept 是否考虑截距
model = LinearRegression(fit_intercept=True)
data=np.array([[0,14,8,0,5,-2,9,-3,399],
[-4,10,6,4,-14,-2,-14,8,-144],
[-1,-6,5,-12,3,-3,2,-2,30],
[5,-2,3,10,5,11,4,-8,126],
[-15,-15,-8,-15,7,-4,-12,2,-395],
[11,-10,-2,4,3,-9,-6,7,-87],
[-14,0,4,-3,5,10,13,7,422],
[-3,-7,-2,-8,0,-6,-5,-9,-309]])
x = data[:,0:8] # 取第一列到第七列
y = data[:,-1]
model.fit(x,y)
print(" 权重参数:\n",model.coef_)
print("截距:\n", model.intercept_)
# 预测
print("模型预测结果:\n",model.predict([[0,14,8,0,5,-2,9,-3]]))
print("模型预测结果:\n",model.predict([[0,14,8,0,5,-2,9,-3],
[-4,10,6,4,-14,-2,-14,8],
[-1,-6,5,-12,3,-3,2,-2],
[5,-2,3,10,5,11,4,-8],
[-15,-15,-8,-15,7,-4,-12,2],
[11,-10,-2,4,3,-9,-6,7],
[-14,0,4,-3,5,10,13,7],
[-3,-7,-2,-8,0,-6,-5,-9]]))
"""
权重参数:
[ 3.41704677 9.64733333 9.96900258 0.49065266 10.67072206 4.50852922
17.60894156 12.27111727]
截距:
18.18163864119797
模型预测结果:
[399.]
模型预测结果:
[ 399. -144. 30. 126. -395. -87. 422. -309.]
"""梯度下降
梯度下降概念
正规方程求解的缺点
1.之前利用正规方程求解的W是最优解的原因是MSE这个损失函数是凸函数。但是,机器学习的损失函数并非都是凸函数,设置导数为0会得到很多个极值,不能确定唯一解,MSE还有一个问题,当数据量和特征较多时,矩阵计算量太大.
- 假设损失函数是这样的,利用正规方程求解导数为0会得到很多个极值,不能确定唯一解

2.使用正规方程求解要求X的特征维度
不能太多,逆矩阵运算时间复杂度为
, 效率大大降低,所以 正规方程求出最优解并不是机器学习和深度学习常用的手段,梯度下降算法更常用
梯度下降

- 逐渐向最低点逼近,直到到达谷底(局部或全局最优点)。
- 在机器学习中,梯度表示损失函数对于模型参数的偏导数 。具体来说,对于每个可训练参数,梯度告诉我们在当前参数值下,沿着每个参数方向变化时,损失函数的变化率。通过计算损失函数对参数的梯度,梯度下降算法能够根据梯度的信息来调整参数,朝着减少损失的方向更新模型,从而逐步优化模型,使得模型性能更好。
- 在
- 梯度下降法( Gradient Descent)是一个算法,但不是像多元线性回归那样是一个具体做回归任务的算法,而是一个非常通用的优化算法来帮助一些机器学习算法求解出最优解 ,所谓的通用就是很多机器学习算法都是用梯度下降,甚至深度学习 也是用它来求解最优解。 所有优化算法的目的都是期望以最快的速度把模型参数W求解出来,梯度下降法就是一种经典常用的优化算法。
梯度下降步骤

梯度下降流程就是"猜"正确答案的过程:
- Random随机数生成初始W,随机生成一组成正太分布的数值
- 求梯度g,梯度代表曲线某点上的切线的斜率,沿着切线往下就相当于沿着坡度最陡峭的方向下降.
- if g < 0,w变大,if g >0,w变小(目标左边是斜率为负右边为正 )
- 判断是否收敛,如果收敛跳出迭代,如果没有达到收敛,回第2步再次执行2~4步收敛的判断标准是:随着迭代进行查看损失函数Loss的值,变化非常微小甚至不再改变,即认为达到收敛
- 上面第4步也可以固定迭代次数
梯度下降公式


- 随机给一个w初始值,然后就不停的修改它,直到达到抛物线最下面附近,比如
- w=0.2
- w=w-0.01*w为0.2时的梯度(导数) 假设算出来是 0.24
- w=w-0.01*w为0.24时的梯度(导数) 假设算出来是 0.33
- w=w-0.01*w为0.33时的梯度(导数) 假设算出来是 0.51
- w=w-0.01*w为0.51时的梯度(导数) 假设算出来是 0.56
- w=w-0.01*w为0.56时的梯度(导数) 假设算出来是 0.58
- w=w-0.01*w为0.58时的梯度(导数) 假设算出来是 0.62
- 就这样一直更新下去,会在真实值附近,我们可以控制更新的次数
关于随机的w在左边和右边问题:
- 因为导数有正负
- 如果在左边 导数是负数 减去负数就是加 往右移动
- 如果在右边 导数是正数 减去正数就是减 往左移动
学习率
- 根据我们上面讲的梯度下降公式,我们知道α是学习率,设置大的学习率α;每次调整的幅度就大,设置小的学习率α;每次调整的幅度就小,然而如果步子迈的太大也会有问题! 学习率大,可能一下子迈过了,到另一边去了(从曲线左半边跳到右半边),继续梯度下降又迈回来,使得来来回回震荡。步子太小呢,就像蜗牛一步步往前挪,也会使得整体迭代次数增加。

- 学习率的设置是门一门学问,一般我们会把它设置成一个小数,0.1、0.01、0.001、0.0001,都是常见的设定数值(然后根据情况调整)。一般情况下学习率在整体迭代过程中是不变,但是也可以设置成随着迭代次数增多学习率逐渐变小,因为越靠近山谷我们就可以步子迈小点,可以更精准的走入最低点,同时防止走过。还有一些深度学习的优化算法会自己控制调整学习率这个值
代码实现梯度下降
- 假设一个损失函数
python
import numpy as np
import matplotlib.pyplot as plt
w =np.linspace(-10, 20, 100)
def loss(w):
return (w - 3.5)**2-4.5*w + 10
def dloss(w):
return 2*(w-3.5)-4.5
# print(loss)
# 所有wd值对应的loss值
plt.plot(w, loss(w))
# plt.show()
# 梯度下降
# 学习率
learning = 0.1
# 初始化一个随机的w值
np.random.seed(1)
w = np.random.randint(-10, 20)# 随机给个w值
print(w)
e=loss(w) # 初始化的w为-5时的loss值
x = [w]
y = [e]
# 第一次梯度下降,来更新w的值,最后找对最接近损失值为0的w值
# 就是这个式子中变得的结果w与变量w最相等的值时
# w = w - learning*dloss(w)接近0的结果:当dloss(w)导数达到0时就是损失函数的最小值时对应的w值
w = w-learning*dloss(w)
# 在loss途中找出w对应的loss值,观察其中的变化
e = loss(w)
x.append(w)
y.append(e)
# 第二次梯度下降
w = w-learning*dloss(w)
e = loss(w)
x.append(w)
y.append(e)
# 第三次梯度下降
w = w-learning*dloss(w)
e = loss(w)
x.append(w)
y.append(e)
# plt.plot([w,0], [e, 40])
# 为更改画布,所以就在同一个画布上
# 此时的x和y是两个数组,在途中就可以画出存在于x和y中一一对应的的所有点
# plt.plot([w,0], [e, 40])效果和这个差不多
plt.scatter(x, y)
# plt.plot(x, y)
plt.show()
python
# 优化,循环
import numpy as np
import numpy as np
import matplotlib.pyplot as plt
w =np.linspace(-10, 20, 100)
learning = 0.1
def loss(w):
return (w - 3.5)**2-4.5*w + 10
def dloss(w):
return 2*(w-3.5)-4.5
def tidu(w):
return w-learning*dloss(w)
# print(loss)
# 所有wd值对应的loss值
plt.plot(w, loss(w))
# plt.show()
# 没有规定随机种子,所有每次起始点不同,下图的黄线部分不同
w =np.random.randint(0, 10)
print(w)
e = loss(w)
x = [w]
y = [e]
while True:
if w != tidu(w):
w = tidu(w)
x.append(w)
y.append(loss(w))
else:
break
# 这时的x和y是循环结束后损失函数的最值对应的所有的坐标点
# x和y中是列表, 存储的是不同的点的点
plt.plot(x, y)
# 损失函数最小值对应的w
print(w)
- 多维梯度下降
python
import numpy as np
# 假设有一个函数是y=wix通过损失函数的思路已经得出:损失函数
def loss(w1, w2):
return (w1-3.5)**2 + (w2-2)**2 + 3*w1*w2 - 4.5*w1 + 2*w2 +20
# 得出导函数
def dloss_w1(w1, w2):
return 2*(w1 - 3.5) + 3*w2 - 4.5
def dloss_w2(w1, w2):
return 0 + 2*(w2 - 2) + 3*w1 + 2
# 梯度下降算法
def train():
# 初始化随机一个w1和w2的值
w1 = 10
w2 = 10
# 初始化学习率
lr = 0.1
epochs = 1000
for i in range(epochs):
# 更新w1和w2的值
w1_=w1
w2_=w2
w1 = w1_ - lr*dloss_w1(w1_, w2_)
w2 = w2_ - lr*dloss_w2(w1_, w2_)
print("epoch:", i,"w1:", w1, "w2:",w2, "loss:", loss(w1, w2))
train()sklearn梯度下降
1.官方的梯度下降API常用有三种:
- 批量梯度下降BGD(Batch Gradient Descent)
- 小批量梯度下降MBGD(Mini-BatchGradient Descent)
- 随机梯度下降SGD(Stochastic Gradient Descent)。

2.三种梯度下降的区别
- Batch Gradient Descent (BGD) : 在这种情况下,每一次迭代都会使用全部的训练样本计算梯度来更新权重。这意味着每一步梯度更新都是基于整个数据集的平均梯度。这种方法的优点是每次更新的方向是最准确的,但缺点是计算量大且速度慢,尤其是在大数据集上。
- Mini-Batch Gradient Descent (MBGD): 这种方法介于批量梯度下降和随机梯度下降之间。它不是用全部样本也不是只用一个样本,而是每次迭代从数据集中随机抽取一小部分样本(例如,从500个样本中选取32个),然后基于这一小批样本的平均梯度来更新权重。这种方法在准确性和计算效率之间取得了一个平衡。
- Stochastic Gradient Descent (SGD): 在随机梯度下降中,每次迭代仅使用随机单个样本(或有时称为"例子")来计算梯度并更新权重。这种方法能够更快地收敛,但由于每次更新都基于单个样本,所以会导致权重更新路径不稳定。
批量梯度下降BGD
- 批量梯度下降是一种用于机器学习和深度学习中的优化算法,它用于最小化损失函数(目标函数)。批量梯度下降使用整个训练数据集来计算梯度并更新模型参数。
原理
- 批量梯度下降的基本思想是在每个迭代步骤中使用所有训练样本来计算损失函数的梯度,并据此更新模型参数。这使得更新方向更加准确,因为它是基于整个数据集的梯度,而不是像随机梯度下降那样仅基于单个样本。
更新规则
- 假设我们有一个包含 ( m ) 个训练样本的数据集
- 损失函数可以定义为:
- 其中
- 批量梯度下降的更新规则为:
特点
- 准确性:由于使用了所有训练样本,所以得到的梯度是最准确的,这有助于找到全局最小值。
- 计算成本:每次更新都需要遍历整个数据集,因此计算量较大,特别是在数据集很大的情况下。
- 收敛速度:虽然每一步的更新都是准确的,但由于计算成本较高,实际收敛到最小值的速度可能不如其他方法快。
- 内存需求:需要在内存中存储整个数据集,对于大型数据集来说可能成为一个问题。
使用场景
- 小数据集:当数据集较小时,批量梯度下降是一个不错的选择,因为它能保证较好的收敛性和准确性。
- 不需要实时更新:如果模型不需要实时更新,例如在离线训练场景下,批量梯度下降是一个合理的选择。
实现注意事项
- 选择合适的学习率:选择合适的学习率对于快速且稳定的收敛至关重要。如果学习率太小,收敛速度会很慢;如果太大,则可能会导致不收敛。
- 数据预处理:对数据进行标准化或归一化,可以提高批量梯度下降的效率。
- 监控损失函数:定期检查损失函数的变化趋势,确保算法正常工作并朝着正确的方向前进。
API
- 批量梯度下降通常不是首选方法,因为它在大数据集上的计算成本较高。代码需要自己实现
随机梯度下降SGD
- 随机梯度下降(Stochastic Gradient Descent, SGD)是一种常用的优化算法,在机器学习和深度学习领域中广泛应用。与批量梯度下降(BGD)和小批量梯度下降(MBGD)相比,SGD 每一步更新参数时仅使用单个训练样本,这使得它更加灵活且计算效率更高,特别是在处理大规模数据集时。
基本步骤
初始化参数 :选择一个初始点作为参数向量的初始值。
选择样本 :随机选取一个训练样本。
计算梯度 :使用所选样本 来近似计算损失函数
的梯度
。
更新参数:
- 根据梯度的方向来更新参数
- 其中
重复步骤 2 到 4:对所有的训练样本重复此过程,直到完成一个完整的 epoch(即所有样本都被访问过一次)。
重复多个 epoch:重复上述过程,直到满足某个停止条件,比如达到最大迭代次数或者梯度足够小。
输出结果:输出最小化损失函数后的最优参数 \\theta\^\*。
注意事项
- 学习率
- 随机性 : 每次迭代都从训练集中随机选择一个样本,这有助于避免陷入局部最小值。
- 停止条件: 可以是达到预定的最大迭代次数,或者梯度的范数小于某个阈值。
- 随机梯度下降的一个关键优势在于它能够快速地进行迭代并适应较大的数据集。然而,由于每次只使用一个样本进行更新,梯度估计可能较为嘈杂,这可能导致更新过程中出现较大的波动。在实际应用中,可以通过减少学习率(例如采用学习率衰减策略)来解决这个问题。
API
sklearn.linear_model.SGDRegressor()
1.功能:梯度下降法线性回归
2.参数:
- loss: 损失函数,默认为 'squared_error'
- fit_intercept: 是否计算偏置, default=True
- eta0: float, default=0.01学习率初始值
- learning_rate: str, default='invscaling'
- The learning rate schedule:
'constant': eta = eta0 学习率为eta0设置的值,保持不变
'optimal': eta = 1.0 / (alpha * (t + t0))
'invscaling': eta = eta0 / pow(t, power_t)
'adaptive': eta = eta0, 学习率由eta0开始,逐步变小
- max_iter: int, default=1000 经过训练数据的最大次数(又名epoch)
- shuffle=True 每批次是否洗牌
- penalty: {'l2', 'l1', 'elasticnet', None}, default='l2'
- 要使用的惩罚(又称正则化项)。默认为' l2 ',这是线性SVM模型的标准正则化器。' l1 '和' elasticnet '可能会给模型(特征选择)带来' l2 '无法实现的稀疏性。当设置为None时,不添加惩罚。
3.属性
- coef_ 回归后的权重系数
- intercept_ 偏置
案例:
python
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import SGDRegressor
from sklearn.metrics import mean_squared_error
data = fetch_california_housing(data_home='../src')
print(data.data.shape)
print(data.target.shape)
print(data.feature_names)
print(data.target_names)
# 因为target不是分类的,所有有线性回归
# print(data.target[0:10])
x = data.data
y = data.target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
# 数据标准化
stander = StandardScaler()
x_train = stander.fit_transform(x_train)
# 生成SGD随机梯度下降模型
sgd_model = SGDRegressor(loss = "squared_error", alpha=0.01, fit_intercept=True,max_iter=1000, shuffle=True, random_state=666)
# 训练
sgd_model.fit(x_train, y_train)
# 评估
x_test = stander.transform(x_test)
print("预估:",sgd_model.predict(x_test[0:10]))
print("评估:",sgd_model.score(x_test, y_test))
# 训练的结果
print("权重:",sgd_model.coef_)
# 预测
y = sgd_model.predict([[1,2,3,4,5,6,7,8]])
print("预测:",y)
# 算均方差
y_predict = sgd_model.predict(x_test)
e = mean_squared_error(y_predict, y_test)
print("均方差:",e)
"""
(20640, 8)
(20640,)
['MedInc', 'HouseAge', 'AveRooms', 'AveBedrms', 'Population', 'AveOccup', 'Latitude', 'Longitude']
['MedHouseVal']
预估: [3.11705001 3.84823374 0.8795867 3.14842425 0.39963106 2.00928407
2.59070772 1.50706438 1.99236836 1.50359815]
评估: 0.6217953826382787
权重: [ 0.78148926 0.12924797 -0.17687603 0.26624485 0.00213343 -0.03054688
-0.82436232 -0.77745659]
预测: [-8.5152925]
均方差: 0.5278344581040766
"""小批量梯度下降MBGD
- 小批量梯度下降是一种介于批量梯度下降(BGD)与随机梯度下降(SGD)之间的优化算法,它结合了两者的优点,在机器学习和深度学习中被广泛使用。
原理
- 小批量梯度下降的基本思想是在每个迭代步骤中使用一小部分(即"小批量")训练样本来计算损失函数的梯度,并据此更新模型参数。这样做的好处在于能够减少计算资源的需求,同时保持一定程度的梯度准确性。
特点
- 计算效率:相比于批量梯度下降,小批量梯度下降每次更新只需要处理一部分数据,减少了计算成本。
- 梯度估计:相比于随机梯度下降,小批量梯度下降提供了更准确的梯度估计,这有助于更稳定地接近最小值。
- 内存需求:相比批量梯度下降,小批量梯度下降降低了内存需求,但仍然比随机梯度下降要高。
- 收敛速度与稳定性:小批量梯度下降能够在保持较快的收敛速度的同时,维持相对较高的稳定性。
使用场景
- 中等规模数据集:当数据集大小适中时,小批量梯度下降是一个很好的折衷方案,既能够高效处理数据,又能够保持良好的收敛性。
- 在线学习:在数据流式到达的场景下,小批量梯度下降可以有效地处理新到来的数据批次。
- 分布式环境:在分布式计算环境中,小批量梯度下降可以更容易地在多台机器上并行执行。
实现注意事项
- 选择合适的批量大小:批量大小的选择对性能有很大影响。较大的批量可以减少迭代次数,但计算成本增加;较小的批量则相反。
- 选择合适的学习率:选择合适的学习率对于快速且稳定的收敛至关重要。如果学习率太小,收敛速度会很慢;如果太大,则可能会导致不收敛。
- 数据预处理:对数据进行标准化或归一化,可以提高小批量梯度下降的效率。
- 监控损失函数:定期检查损失函数的变化趋势,确保算法正常工作并朝着正确的方向前进。
API
sklearn.linear_model.SGDRegressor()
- 只是训练时我们分批次地训练模型,调用partial_fit函数训练会直接更新权重,而不需要调fit从头开始训练。通常情况下,我们会将数据分成多个小批量,然后对每个小批量进行训练。
案例
python
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import SGDRegressor
from sklearn.metrics import mean_squared_error
import math
data = fetch_california_housing(data_home='../src')
x = data.data
y = data.target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
# 数据标准化
stander = StandardScaler()
x_train = stander.fit_transform(x_train)
def train():
# 配置一些训练参数
eta0 = 0.001
epoch = 1000
batch_size = 16
n_sample = len(x_train) # 样本数量,假设是20000个
model = SGDRegressor()
for epoch_i in range(epoch):
n_batch = math.ceil(n_sample/batch_size)
for i in range(n_batch):
start = i * batch_size
end =min((i+1) * batch_size, n_sample)
# x_train[start:end], y_train[start:end]
model.partial_fit(x_train[start:end], y_train[start:end])
# 一轮训练结束,打印一次损失值
y_pred = model.predict(stander.transform(x_test))
mse = mean_squared_error(y_pred, y_test)
print(mse)
print(f"第{epoch_i}轮训练结束, mess:{mse}")
train() 梯度下降优化
1.标准化:前期数据的预处理,之前讲的
2.正则化:防止过拟合
欠拟合过拟合


欠拟合
欠拟合是指模型在训练数据上表现不佳,同时在新的未见过的数据上也表现不佳。这通常发生在模型过于简单,无法捕捉数据中的复杂模式时。欠拟合模型的表现特征如下:
- 训练误差较高。
- 测试误差同样较高。
- 模型可能过于简化,不能充分学习训练数据中的模式。
过拟合
过拟合是指模型在训练数据上表现得非常好,但在新的未见过的数据上表现较差。这通常发生在模型过于复杂,以至于它不仅学习了数据中的真实模式,还学习了噪声和异常值。过拟合模型的表现特征如下:
- 训练误差非常低。
- 测试误差较高。
- 模型可能过于复杂,以至于它对训练数据进行了过度拟合。
正则化
- 正则化就是防止过拟合,增加模型的鲁棒性,鲁棒是Robust 的音译,也就是强壮的意思。
- 比如,下面两个方程描述同一条直线,哪个更好?
- 第一个更好,因为下面的公式是上面的十倍,当w越小公式的容错的能力就越好。将原来的损失函数加上一个惩罚项使得计算出来的模型W相对小一些,就是正则化。这里面损失函数就是原来固有的损失函数,比如回归的话通常是MSE,然后在加上一部分惩罚项来使得计算出来的模型W相对小一些来带来泛化能力。
- 常用的惩罚项有L1正则项或者L2正则项:
对应曼哈顿距离
对应欧氏距离
- 其实L1 和L2 正则的公式在数学里面的意义就是范数,代表空间中向量到原点的距离
- 当我们把多元线性回归损失函数加上
岭回归Ridge
损失函数公式
岭回归是失损函数通过添加所有权重的平方和的乘积(L2)来惩罚模型的复杂度。

均方差除以2是因为方便求导,指所有的权重系数, λ指惩罚型系数,又叫正则项力度
特点:
- 岭回归不会将权重压缩到零,这意味着所有特征都会保留在模型中,但它们的权重会被缩小。
- 适用于特征间存在多重共线性的情况。
- 岭回归产生的模型通常更为平滑,因为它对所有特征都有影响。
API
1.具有L2正则化的线性回归-岭回归。
sklearn.linear_model.Ridge()
2.参数:
- alpha, default=1.0,正则项力度
- fit_intercept, 是否计算偏置, default=True
- solver, {'auto', 'svd', 'cholesky', 'lsqr', 'sparse_cg', 'sag', 'saga', 'lbfgs'}, default='auto'当值为auto,并且数据量、特征都比较大时,内部会随机梯度下降法。
- normalize:,default=True, 数据进行标准化,如果特征工程中已经做过标准化,这里就该设置为False
- max_iterint, default=None,梯度解算器的最大迭代次数,默认为15000
3.属性
- coef_ 回归后的权重系数
- intercept_ 偏置
说明:SGDRegressor也可以做岭回归的事情,比如SGDRegressor(penalty='l2',loss="squared_loss"),但是其中梯度下降法有些不同。所以推荐使用Ridge实现岭回归
示例
岭回归 加载加利福尼亚住房数据集,进行回归预测
python
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Ridge
from sklearn.metrics import mean_squared_error
import math
data = fetch_california_housing(data_home='../src')
x = data.data
y = data.target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
# 数据标准化
# stander = StandardScaler()
# x_train = stander.fit_transform(x_train)
def train():
# 配置一些训练参数
eta0 = 0.001
epoch = 1000
batch_size = 16
n_sample = len(x_train) # 样本数量,假设是20000个
# 它会有标准化的操作
model = Ridge()
model.fit(x_train,y_train)
s = model.score(x_test, y_test)
print(s)
train() 拉索回归Lasso
损失函数公式
Lasso回归是一种线性回归模型,它通过添加所有权重的绝对值之和(L1)来惩罚模型的复杂度。
Lasso回归的目标是最小化以下损失函数:
其中:
特点:
- 拉索回归可以将一些权重压缩到零,从而实现特征选择。这意味着模型最终可能只包含一部分特征。
- 适用于特征数量远大于样本数量的情况,或者当特征间存在相关性时,可以从中选择最相关的特征。
- 拉索回归产生的模型可能更简单,因为它会去除一些不重要的特征。
API
sklearn.linear_model.Lasso()
1.参数:
- alpha (float, default=1.0):控制正则化强度;必须是非负浮点数。较大的 alpha 增加了正则化强度。
- fit_intercept (bool, default=True):是否计算此模型的截距。如果设置为 False,则不会使用截距(即数据应该已经被居中)。
- precompute (bool or array-like, default=False):如果为 True,则使用预计算的 Gram 矩阵来加速计算。如果为数组,则使用提供的 Gram 矩阵。
- copy_X (bool, default=True):如果为 True,则复制数据 X,否则可能对其进行修改。
- max_iter (int, default=1000):最大迭代次数。
- tol (float, default=1e-4):精度阈值。如果更新后的系数向量减去之前的系数向量的无穷范数除以 1 加上更新后的系数向量的无穷范数小于 tol,则认为收敛。
- warm_start (bool, default=False):当设置为 True 时,再次调用 fit 方法会重新使用之前调用 fit 方法的结果作为初始估计值,而不是清零它们。
- positive (bool, default=False):当设置为 True 时,强制系数为非负。
- random_state (int, RandomState instance, default=None):随机数生成器的状态。用于随机初始化坐标下降算法中的随机选择。
- selection ({'cyclic', 'random'}, default='cyclic'):如果设置为 'random',则随机选择坐标进行更新。如果设置为 'cyclic',则按照循环顺序选择坐标。
2.属性:
- **coef_:**系数向量或者矩阵,代表了每个特征的权重。
- **intercept_:**截距项(如果 fit_intercept=True)。
- **n_iter_:**实际使用的迭代次数。
- n_features_in_ (int)::训练样本中特征的数量。
示例
python
from sklearn.datasets import fetch_california_housing
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import Lasso
from sklearn.metrics import mean_squared_error
import math
def data_load():
data = fetch_california_housing(data_home='../src')
x = data.data
y = data.target
x_train, x_test, y_train, y_test = train_test_split(x, y, test_size=0.2)
# 数据标准化
# stander = StandardScaler()
# x_train = stander.fit_transform(x_train)
return x_train, x_test, y_train, y_test
def train(x_train, y_train):
model = Lasso(alpha=0.1)
model.fit(x_train, y_train)
return model
def test(model, x_test, y_test):
y_predict = model.predict(x_test)
mse = mean_squared_error(y_test, y_predict)
rmse = math.sqrt(mse)
return rmse
x_train, x_test, y_train, y_test = data_load()
model = train(x_train, y_train)
s = test(model, x_test, y_test)
print(s)
print(model.coef_)
y=model.predict(x_test[0:4])
print(y)
s = model.score(x_test, y_test)
print(s)
"""
0.7673056368342309
[ 3.90407715e-01 1.49166600e-02 -0.00000000e+00 0.00000000e+00
1.71248405e-05 -3.14801601e-03 -1.15449987e-01 -1.01094045e-01]
[3.19335138 1.22986215 2.38290172 1.94014059]
0.5491967521497159
"""十二 逻辑回归
概念
- 逻辑回归(Logistic Regression)是机器学习中的一种分类模型,逻辑回归是一种分类算法,虽然名字中带有回归,但是它与回归之间有一定的联系。由于算法的简单和高效,在实际中应用非常广泛。
原理
- 逻辑回归的输入是线性回归的输出
- 线性回归:
- sigmoid激活函数 :
- sigmoid函数的值是在0,1区间中的一个概率值,默认为0.5为阈值可以自己设定,大于0.5认为是正例,小于则认为是负例
- 把上面的

- 损失函数(官方提供):

- 损失函数图:
- 当y=1时(y=0时与之相反):

- 通过损失函数图像,我们知道:
- 当y=1时,我们希望
- 当y=0时,我们希望
- 综合0和1的损失函数:

- 计算:

- 然后使用梯度下降算法,去减少损失函数的值,这样去更新逻辑回归前面对应算法的权重参数,提升原本属于1类别的概率,降低原本是0类别的概率.
API
sklearn.linear_model.LogisticRegression()
1.参数:
(1)fit_intercept bool, default=True 指定是否计算截距
(2)max_iter int, default=100 最大迭代次数。迭代达到此数目后,即使未收敛也会停止。
(3)模型对象:
- .coef_ 权重
- .intercept_ 偏置
- predict()预测分类
- predict_proba()预测分类(对应的概率)
- score()准确率
示例
python
from sklearn.datasets import load_iris
from sklearn.linear_model import LogisticRegression
from sklearn.model_selection import train_test_split
x,y = load_iris(return_X_y=True)
index = y!=2
y = y[index]
x = x[index]
x_train,x_test,y_train,y_test = train_test_split(x,y,test_size=0.2)
# print(x)
# print(y)
model = LogisticRegression()
model.fit(x_train,y_train)
# new_x = [[4.3,2.5,7.2,2.5]]
# y_pred = model.predict(new_x)
# print(y_pred)
y_pred = model.predict(x_test)
# true:有几个预测正确
s = sum(y_pred == y_test)
print(s)
print(s/len(y_test))