文章目录
- [一. 基于FastAPI之Web站点开发](#一. 基于FastAPI之Web站点开发)
-
- [1. 基于FastAPI搭建Web服务器](#1. 基于FastAPI搭建Web服务器)
- [2. Web服务器和浏览器的通讯流程](#2. Web服务器和浏览器的通讯流程)
- [3. 浏览器访问Web服务器的通讯流程](#3. 浏览器访问Web服务器的通讯流程)
- [4. 加载图片资源代码](#4. 加载图片资源代码)
- [二. 基于Web请求的FastAPI通用配置](#二. 基于Web请求的FastAPI通用配置)
-
- [1. 目前Web服务器存在问题](#1. 目前Web服务器存在问题)
- [2. 基于Web请求的FastAPI通用配置](#2. 基于Web请求的FastAPI通用配置)
- [三. Python爬虫介绍](#三. Python爬虫介绍)
-
- [1. 什么是爬虫](#1. 什么是爬虫)
- [2. 爬虫的基本步骤](#2. 爬虫的基本步骤)
- [3. 安装requests模块](#3. 安装requests模块)
- [4. 爬取照片](#4. 爬取照片)
一. 基于FastAPI之Web站点开发
1. 基于FastAPI搭建Web服务器
python
# 导入FastAPI模块
from fastapi import FastAPI
# 导入响应报文Response模块
from fastapi import Response
# 导入服务器uvicorn模块
import uvicorn
# 创建FastAPI框架对象
app = FastAPI()
# 通过@app路由装饰器收发数据
# @app.get(参数) : 按照get方式接受请求数据
# 请求资源的 url 路径
@app.get("/index.html")
def main():
with open("source/html/index.html", "rb") as f:
data = f.read()
# return 返回响应数据
# Response(content=data, media_type="text/html"
# 参数1: 响应数据
# 参数2: 数据格式
return Response(content=data, media_type="text/html")
# 运行服务器
# 参数1: 框架对象
# 参数2: IP地址
# 参数3: 端口号
uvicorn.run(app, host="127.0.0.1", port=8000)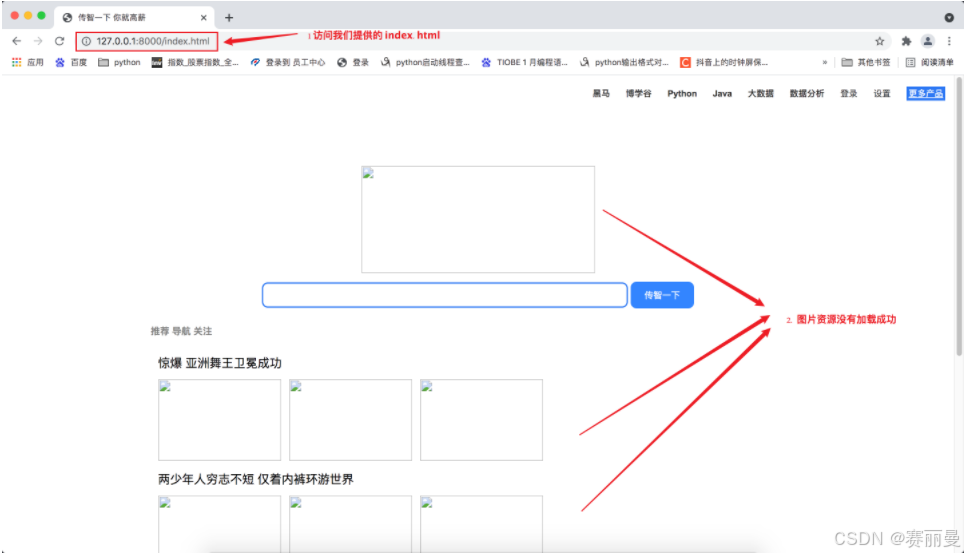
2. Web服务器和浏览器的通讯流程
实际上Web服务器和浏览器的通讯流程过程并不是一次性完成的, 这里html代码中也会有访问服务器的代码, 比如请求图片资源。

那像0.jpg、1.jpg、2.jpg、3.jpg、4.jpg、5.jpg、6.jpg这些访问来自哪里呢 ?
答:它们来自index.html

3. 浏览器访问Web服务器的通讯流程

浏览器访问Web服务器的通讯流程:
浏览器(127.0.0.1/index.html) ==> 向Web服务器请求index.htmlWeb服务器(返回index.html) ==>浏览器浏览器解析index.html发现需要0.jpg ==>发送请求给Web服务器请求0.jpgWeb服务器收到请求返回0.jpg ==>浏览器接受0.jpg
通讯过程能够成功的前提:
浏览器发送的0.jpg请求, Web服务器可以做出响应, 也就是代码如下
python
# 当浏览器发出对图片 0.jpg 的请求时, 函数返回相应资源
@app.get("/images/0.jpg")
def func_01():
with open("source/images/0.jpg", "rb") as f:
data = f.read()
print(data)
return Response(content=data, media_type="jpg")4. 加载图片资源代码
python
# 导入FastAPI模块
from fastapi import FastAPI
# 导入响应报文Response模块
from fastapi import Response
# 导入服务器uvicorn模块
import uvicorn
# 创建FastAPI框架对象
app = FastAPI()
@app.get("/images/0.jpg")
def func_01():
with open("source/images/0.jpg", "rb") as f:
data = f.read()
print(data)
return Response(content=data, media_type="jpg")
@app.get("/images/1.jpg")
def func_02():
with open("source/images/1.jpg", "rb") as f:
data = f.read()
return Response(content=data, media_type="jpg")
@app.get("/images/2.jpg")
def func_03():
with open("source/images/2.jpg", "rb") as f:
data = f.read()
return Response(content=data, media_type="jpg")
@app.get("/images/3.jpg")
def func_04():
with open("source/images/3.jpg", "rb") as f:
data = f.read()
return Response(content=data, media_type="jpg")
@app.get("/images/4.jpg")
def func_05():
with open("source/images/4.jpg", "rb") as f:
data = f.read()
return Response(content=data, media_type="jpg")
@app.get("/images/5.jpg")
def func_06():
with open("source/images/5.jpg", "rb") as f:
data = f.read()
return Response(content=data, media_type="jpg")
@app.get("/images/6.jpg")
def func_07():
with open("source/images/6.jpg", "rb") as f:
data = f.read()
return Response(content=data, media_type="jpg")
@app.get("/index.html")
def main():
with open("source/html/index.html", "rb") as f:
data = f.read()
# return 返回响应数据
# Response(content=data, media_type="text/source"
# 参数1: 响应数据
# 参数2: 数据格式
return Response(content=data, media_type="text/html")
# 运行服务器
# 参数1: 框架对象
# 参数2: IP地址
# 参数3: 端口号
uvicorn.run(app, host="127.0.0.1", port=8000)二. 基于Web请求的FastAPI通用配置
1. 目前Web服务器存在问题
python
# 返回0.jpg
@app.get("/images/0.jpg")
def func_01():
with open("source/images/0.jpg", "rb") as f:
data = f.read()
print(data)
return Response(content=data, media_type="jpg")
# 返回1.jpg
@app.get("/images/1.jpg")
def func_02():
with open("source/images/1.jpg", "rb") as f:
data = f.read()
return Response(content=data, media_type="jpg")
# 返回2.jpg
@app.get("/images/2.jpg")
def func_03():
with open("source/images/2.jpg", "rb") as f:
data = f.read()
return Response(content=data, media_type="jpg")对以上代码观察,会发现每一张图片0.jpg、1.jpg、2.jpg就需要一个函数对应, 如果我们需要1000张图片那就需要1000个函数对应, 显然这样做代码的重复太多了.
2. 基于Web请求的FastAPI通用配置
python
# 当请求为 /images/0.jpg 时, path ==> 0.jpg
@app.get("/images/{path}")
# 注意这里的参数需要设置为 path
# path : str ==> 指定path为字符串类型的数据
def get_pic(path: str):
# 这里open()的路径就是 ==> f"source/images/0.jpg"
with open(f"source/images/{path}", "rb") as f:
data = f.read()
# return 返回响应数据
# Response(content=data, media_type="jpg")
# 参数1: 响应数据
# 参数2: 数据格式
return Response(content=data, media_type="jpg")完整代码
python
# 导入FastAPI模块
from fastapi import FastAPI
# 导入响应报文Response模块
from fastapi import Response
# 导入服务器uvicorn模块
import uvicorn
# 创建FastAPI框架对象
app = FastAPI()
# 当请求为 /images/0.jpg 时, path ==> 0.jpg
@app.get("/images/{path}")
# 注意这里的参数需要设置为 path
# path : str ==> 指定path为字符串类型的数据
def get_pic(path: str):
# 这里open()的路径就是 ==> f"source/images/0.jpg"
with open(f"source/images/{path}", "rb") as f:
data = f.read()
# return 返回响应数据
# Response(content=data, media_type="jpg")
# 参数1: 响应数据
# 参数2: 数据格式
return Response(content=data, media_type="jpg")
@app.get("/{path}")
def get_html(path: str):
with open(f"source/html/{path}", 'rb') as f:
data = f.read()
# return 返回响应数据
# Response(content=data, media_type="text/source"
# 参数1: 响应数据
# 参数2: 数据格式
return Response(content=data, media_type="text/html")
# 运行服务器
# 参数1: 框架对象
# 参数2: IP地址
# 参数3: 端口号
uvicorn.run(app, host="127.0.0.1", port=8000)运行结果

三. Python爬虫介绍
1. 什么是爬虫
网络爬虫:
又被称为网页蜘蛛,网络机器人,是一种按照一定的规则,自动地抓取网络信息的程序或者脚本,另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
通俗理解:
简单来讲,爬虫就是一个探测机器,它的基本操作就是模拟人的行为去各个网站溜达,点点按钮,查查数据,或者把看到的信息背回来. 就像一只虫子在一幢楼里不知疲倦地爬来爬去.
你可以简单地想象: 每个爬虫都是你的「分身」。就像孙悟空拔了一撮汗毛,吹出一堆猴子一样
**百度:**其实就是利用了这种爬虫技术, 每天放出无数爬虫到各个网站,把他们的信息抓回来,然后化好淡妆排着小队等你来检索。
有了这样的特性, 对于一些自己公司数据量不足的小公司, 这个时候还想做数据分析就可以通过爬虫获取同行业的数据然后进行分析, 进而指导公司的策略指定。
2. 爬虫的基本步骤
基本步骤:
-
起始URL地址
-
发出请求获取响应数据
-
对响应数据解析
-
数据入库
3. 安装requests模块
- requests : 可以模拟浏览器的请求
- 官方文档 :http://cn.python-requests.org/zh_CN/latest/
- 安装 :pip install requests
快速入门(requests三步走):
python
# 导入模块
import requests
# 通过requests.get()发送请求
# data保存返回的响应数据(这里的响应数据不是单纯的html,需要通过content获取html代码)
data = requests.get("http://www.baidu.com")
# 通过data.content获取html代码
data = data.content.decode("utf-8")