2024-11-11,由斯坦福大学创建的FineTuneBench数据集,揭示了商业大型语言模型(LLMs)微调API在新知识学习和现有知识更新方面的显著不足,这对于理解和改进LLMs的适应性和可靠性具有重要意义。
数据集地址:FineTuneBench|大型语言模型数据集|微调评估数据集
一、研究背景:
随着大型语言模型(LLMs)在软件开发、医疗等领域的广泛应用,确保这些模型包含最新和相关知识变得至关重要。然而,当前的前沿模型大多是闭源的,用户无法直接应用模型微调技术。一些公司通过商业API提供了对他们专有模型的监督微调,但这些微调服务是否能够实现知识注入尚不清楚。
目前遇到困难和挑战:
1、商业LLM微调API的效果和方法缺乏透明度,用户难以了解其背后的微调方法。
2、缺乏统一的基准来评估和比较不同商业微调API的效果。
3、用户在微调时可调整的超参数选项有限,不清楚这些选项是否足以适应新知识和更新知识。
数据集地址:FineTuneBench|大型语言模型数据集|微调评估数据集
二、让我们来一起看一下FineTuneBench数据集
FineTuneBench是一个评估框架和数据集,用于理解商业微调API在LLMs中成功学习新知识和更新知识的能力。
FineTuneBench包含625个训练问题和1075个测试问题,覆盖最新新闻、虚构人物、医疗指南和代码更新四个领域,旨在评估商业微调API在不同泛化任务中的知识注入能力。
数据集构建:
数据集通过收集最新新闻文章、生成虚构人物描述、更新医疗指南和代码库变更等信息构建而成。例如,从2024年9月的新闻中提取问题和答案对,以及基于Scikit-Learn代码库生成代码相关问题。
数据集特点:
FineTuneBench的特点在于其多样性和实用性,它不仅测试模型对新信息的学习能力,还测试模型对现有知识的更新能力。数据集包含对问题的不同变体,如改写、日期变更等,以测试模型的泛化能力。
FineTuneBench数据集可用于微调LLMs,并评估其在特定领域的知识注入效果。
用户可以通过FineTuneBench测试不同模型在新信息摄入和知识更新方面的表现,并比较不同微调API的效果。
基准测试:
FineTuneBench提供了一个基准测试平台,允许研究人员和开发者比较不同LLMs在知识注入任务上的性能,包括记忆原始问题和回答修改后问题的能力。
A:FineTuneBench概述。
我们在四个新数据集上微调了五个LLMs(GPT-4o、GPT-4o-mini、GPT-3.5-turbo、Gemini-1.5 Pro、Gemini-1.5 Flash),以测试商业微调 API 学习和更新知识的能力。
B:我们提供了 Latest News 数据集中的示例以及微调前后的模型响应。
该模型在每个问答对上训练最多 30 个 epoch,然后在同一对上重新评估模型(记忆)。然后,我们还在问题的修改版本上评估模型,该问题测试模型将其获得的知识推广到单纯记忆(Generalization)之外的能力。在 Latest News 数据集中,我们包括两个修改:rephrasing,这涉及更改问题的措辞但保留相同的答案;和 date change,它保留原始问题,但将年份换成将来的日期,以便正确的回答应该是 refal。我们观察到,尽管微调模型能够记住原始问题,但当日期更改时,它无法回答重新措辞的问题和相同的问题。

针对新知识获取数据集的原始训练问题(记忆)和修改后的问题(泛化)的微调 <代码 id=g1001>LLM) 的性能
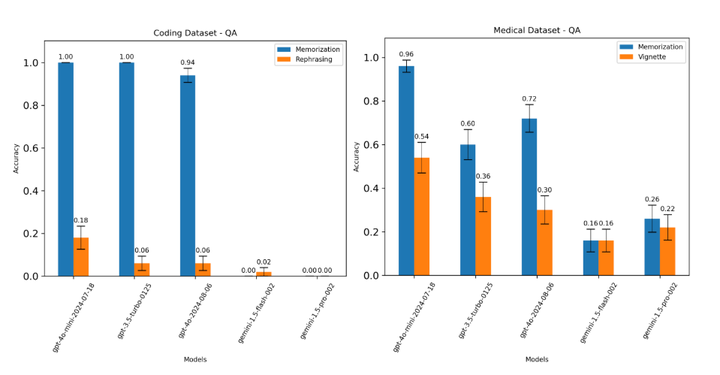
微调模型在更新知识数据集上的性能
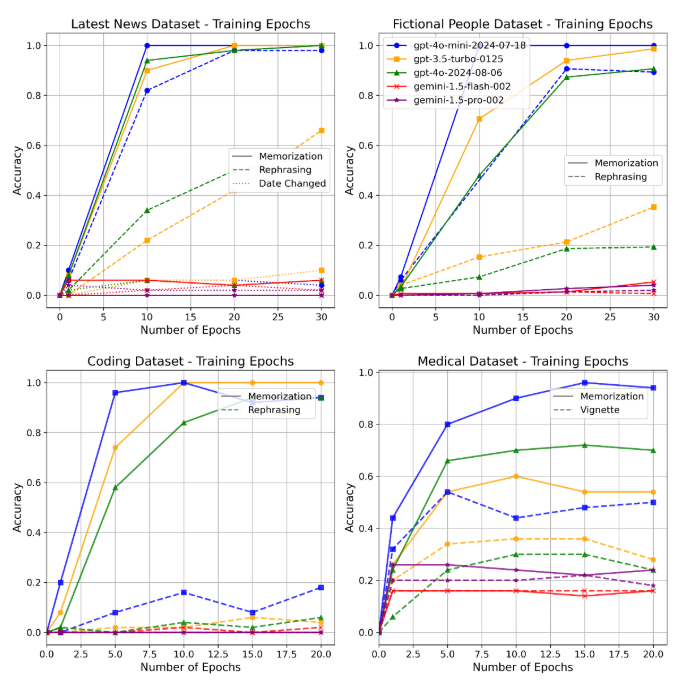
每个模型和数据集的训练动态(准确率与训练时期数)
三、让我们展望FineTuneBench的应用
比如我是某医院的IT主管,我们医院最近决定引入一个大型语言模型(LLM)来辅助医生们做出更精准的临床决策。这个模型得是个万事通,不光要知道最新的医疗研究,还得紧跟我们医院自己的治疗指南。但是,我们也知道,这些模型就像是个书呆子,它们需要不断学习新知识,才能保持聪明。
所以,我们决定用FineTuneBench数据集来测试一下。这个数据集就像是个专门为我们这种情况设计的工具箱,它能帮助我们看看这个LLM是不是真的能学到新东西,并且能记住这些新知识。
比如说,我们最近更新了一条关于糖尿病治疗的指南,我们想知道这个LLM能不能学会这个新知识。在FineTuneBench的帮助下,我们创建了一个测试场景,我们把这条新的糖尿病治疗指南作为一个问题-答案对输入到模型中,然后我们问模型:"对于2型糖尿病患者,我们现在推荐的首选药物是什么?"
我们希望模型能回答:"我们现在推荐的首选药物是新上市的XX药物。" 但是,如果模型回答的是旧的药物,或者干脆说不知道,那我们就知道这个模型在学习新知识上还有问题。
通过FineTuneBench,我们不仅测试了模型对新知识的学习能力,还测试了它对知识更新的能力。我们甚至可以改变问题的表述方式,比如问:"在最新的临床指南中,对于2型糖尿病患者,首选的药物治疗方案是什么?" 这样,我们就能看看模型是不是真的理解了这个知识点,而不仅仅是记住了某个特定的问题。
这个测试结果对我们来说非常重要,因为它直接关系到我们医院的服务质量。如果LLM能够准确地学习和应用最新的医疗知识,那么我们就可以更有信心地将它集成到我们的临床决策支持系统中。这样,我们的医生就能更快地获取准确的信息,我们的患者也能得到更好的治疗。