引言
VTS(Vector Transport Service),全称向量传输服务,是一个由Zilliz开发的专注于向量和非结构化数据迁移的开源工具。VTS的核心特点在于其基于Apache SeaTunnel开发,这一事实使其在数据处理和迁移方面具有显著的优势。Apache SeaTunnel作为一个分布式数据集成平台,以其丰富的连接器系统和多引擎支持而闻名,VTS正是在此基础上,进一步扩展了其在向量数据库迁移和非结构化数据处理的能力。
VTS:基于Apache SeaTunnel的开源向量数据迁移工具
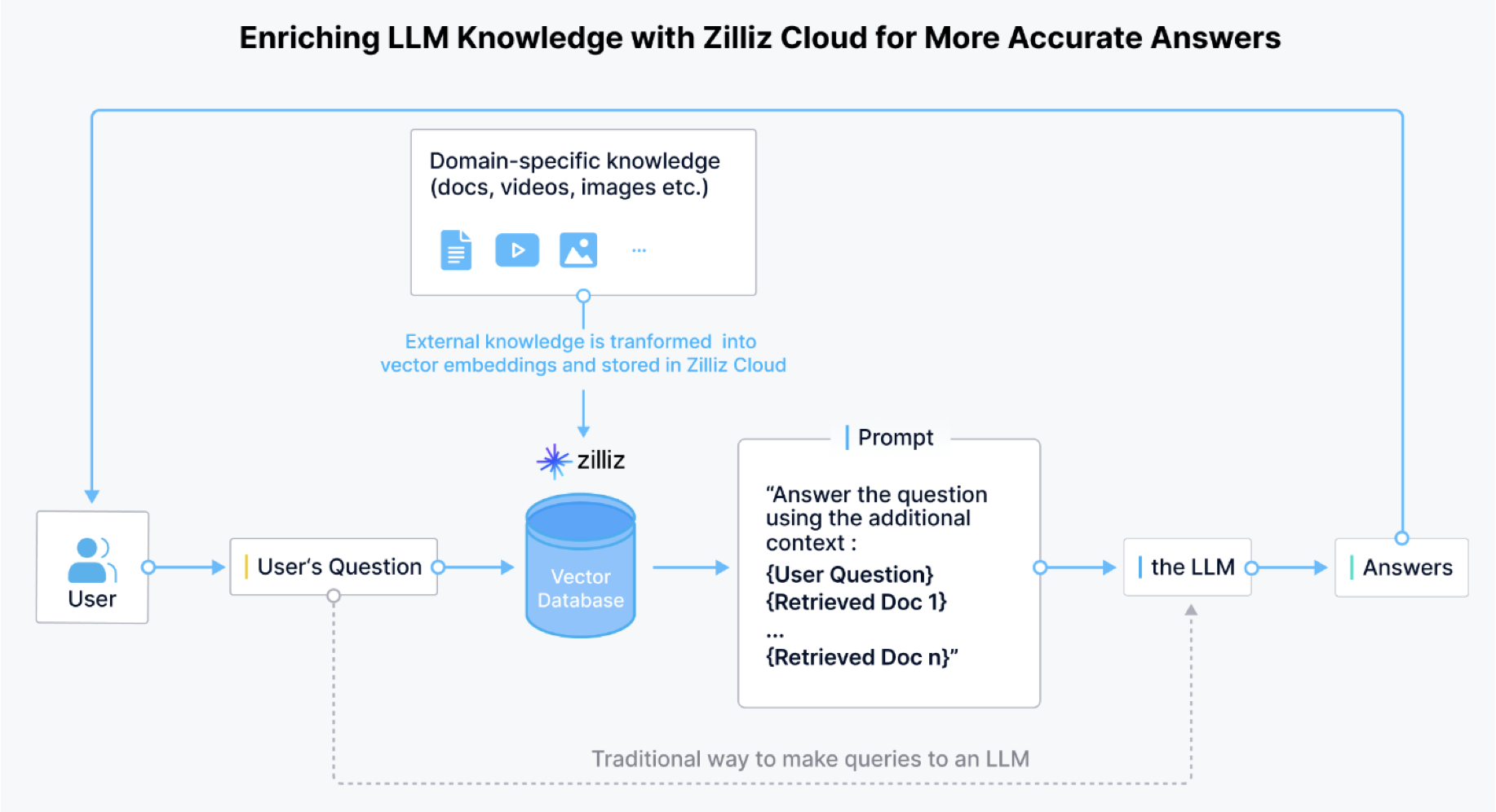
什么是向量数据库
向量数据库是一种专门用于存储和检索向量数据的 数据库系统: • 它能够高效处理高维向量数据,支持相似性搜索 • 支持KNN(K-近邻)搜索 • 计算向量间的距离(欧氏距离、余弦相似度等) • 快速检索最相似的向量 • 主要用于AI和机器学习应用场景 • 图像检索系统 • 推荐系统 • 自然语言处理 • 人脸识别 • 相似商品搜索
开发动力和背景
作为领先的向量数据库服务提供商,Zilliz 深知开发出色的 AI 应用离不开数据本身。然而,在有效处理 AI 应用中的非结构化数据时,我们常常会面临以下挑战:
-
数据碎片化:用户数据分散在多个平台中,如 S3、HDFS、Kafka、数仓和数据湖。
-
多样的数据格式:非结构化数据以各种格式存在,包括 JSON、CSV、Parquet、JPEG 等。
-
缺乏完整的解决方案:目前没有一款产品能够完全满足跨系统高效传输非结构化数据和向量数据的复杂需求。
在上述这些挑战中,最突出的就是,如何将转化来自各种数据源和以各种格式存在的非结构化数据,并导入向量数据库中。这一过程比处理传统的 SQL 关系型数据要复杂得多,大部分公司或组织都低估了这一点。
因此,许多公司或组织在搭建自定义的非结构化数据流水线(Pipeline)时,通常会面临性能、可扩展性和维护成本的问题。这些问题可能会影响数据质量和准确性,从而可能削弱应用的数据分析能力。
更糟糕的是,许多公司在选择向量数据库时都忽视或者低估了供应商锁定和数据容灾等因素。
供应商锁定带来的影响
供应商锁定是指一个组织过度依赖单一供应商的专有技术。在这种情况下,该组织会难以切换到另一种解决方案,或者切换方案的成本十分高昂。这个问题在向量数据库领域尤为重要,由于向量数据的特性和缺乏标准化数据格式可能使得跨系统数据迁移变得极具挑战性。
供应商锁定的影响远不止于此。它还限制了组织在面对业务需求变化时的灵活性,甚至可能随着时间的推移会进一步增加组织运营成本。此外,锁定单一供应商的生态系统还会限制技术创新。如果所选解决方案无法很好地随着组织需求的增长而扩展,还会影响应用系统的性能。
在选择向量数据库时,组织应优先考虑开放标准(open standards)和互通性,从而降低上述风险。在制定清晰的数据治理策略过程中,规划数据的可移植性至关重要。定期评估对供应商特定功能的依赖程度,可以帮助组织保持系统灵活性。
非结构化数据迁移的挑战
然而,即使有了上述预防措施,组织也必须准备好面对向量数据库带来的独特挑战。我们发现,向量数据库之间的数据迁移比传统的关系型数据库之间的数据迁移要复杂得多。这种复杂性凸显了选择合适的向量数据库的重要性,并解释了为什么需要注意避免供应商锁定。向量数据库迁移的主要挑战包括:
-
缺乏面向向量数据库的 ETL 工具:像 Airbyte 和 Seatunnel 之类的主流工具仅面向传统的关系型数据库,无法有效满足向量数据库之间的数据迁移需求。
-
向量数据库之间能力差异:
-
许多向量数据库不支持数据导出。
-
部分向量数据库的增量数据实时处理能力有限。
-
向量数据库之间的数据 Schema 不匹配。
-
为应对这些挑战,组织需要构建更具弹性、灵活性和与时俱进的 AI 应用,充分利用非结构化数据的力量,并保持适应未来技术的灵活性。
为向量数据而生的数据迁移工具
Zilliz 推出全新迁移服务(Migration Services)并将其开源,以帮助用户应对上述种种挑战。Zilliz 迁移服务是一款基于 Apache SeaTunnel,专为向量数据迁移设计的工具。
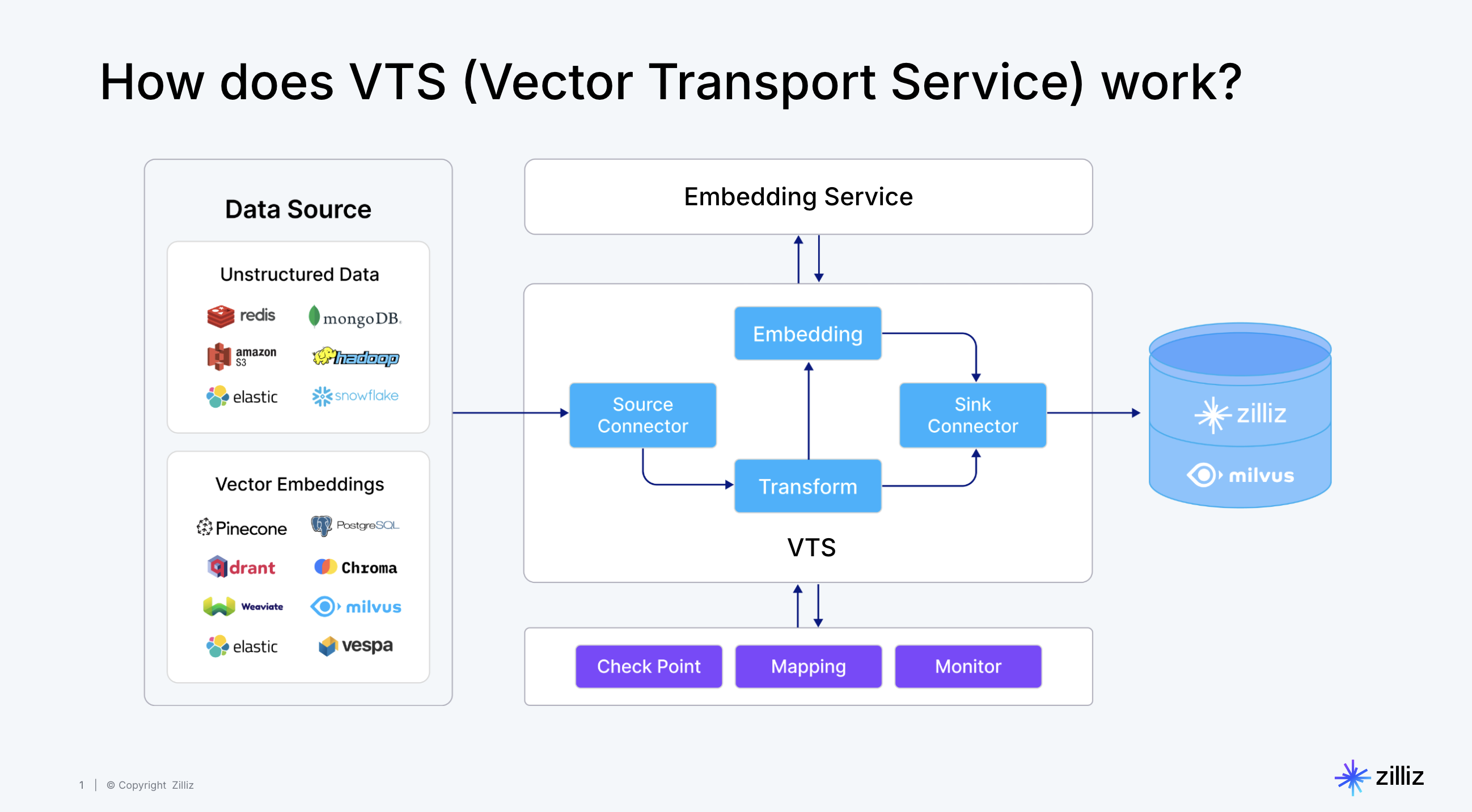 迁移服务工作原理
迁移服务工作原理
- GitHub地址:https://github.com/zilliztech/vts
得到验证测试后,这项服务将会merge到SeaTunnel官方分支中。
总的来说,推动Zilliz开发这款工具的背后原因包括:
-
满足日益增长的数据迁移需求:用户的需求不断扩展,演变为将数据从不同的向量数据库、传统的搜索引擎(如 Elasticsearch 和 Solr)、关系型数据库、数仓、文档数据库,甚至 S3 和数据湖进行迁移。
-
支持实时流数据流和离线导入:随着向量数据库能力的不断扩展,用户需要对实时流数据的支持和离线批量导入的能力。
-
简化非结构化数据转换流程:与传统 ETL 不同,转换非结构化数据需要借助 AI 模型的力量。迁移服务结合了 Zilliz Cloud Pipelines,能够将非结构化数据转换为 Embedding 向量并完成数据标记等任务,显著降低数据清洗成本和操作难度。
-
确保端到端的数据质量:数据集成和同步过程中容易出现数据丢失和不一致的问题。迁移服务通过强大的监控和告警机制解决了这些可能影响数据质量的问题。
VTS的核心能力
基于Apache SeaTunnel
VTS继承了Apache SeaTunnel的高吞吐量和低延迟特性,同时增加了对向量数据和非结构化数据的支持。这使得VTS能够作为一个强大的工具,用于构建AI应用数据Pipeline,实现向量数据的实时同步,以及非结构化数据的转换与加载。
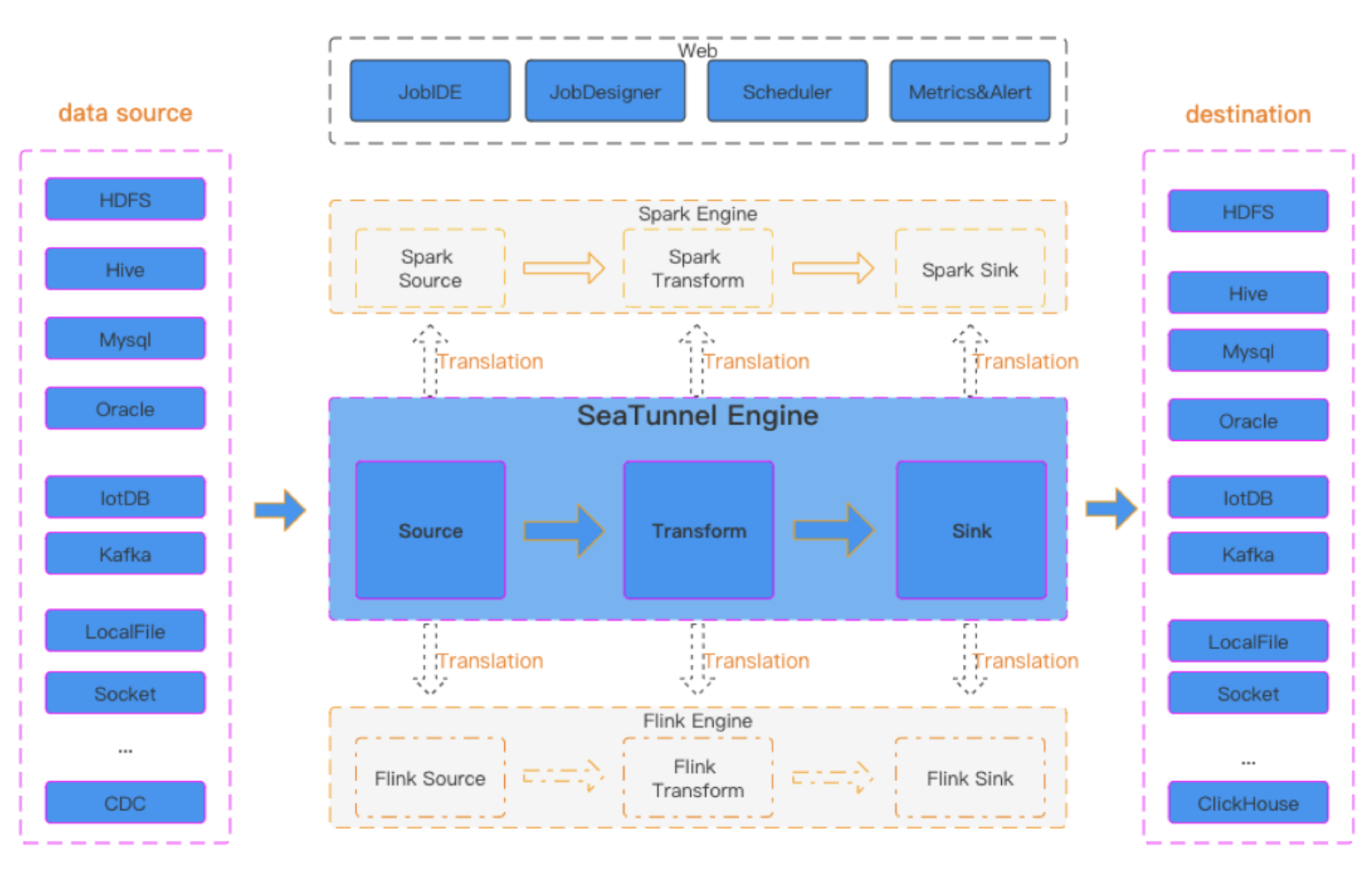
VTS的核心能力包括:
- 向量数据库迁移
- AI应用数据Pipeline构建
- 向量数据实时同步
- 非结构化数据转换与加载
- 跨平台数据集成
向量数据库迁移
VTS的核心能力之一是向量数据库迁移。它能够处理向量数据的迁移,这对于AI和机器学习应用来说至关重要,因为这些应用常常需要处理大量的高维向量数据。
跨平台数据集成
VTS支持跨平台数据集成,这意味着它可以将数据从一个系统无缝迁移到另一个系统,无论是传统的关系型数据库还是现代的向量数据库。
VTS支持的Connector和Transform
支持的Connector
VTS支持多种Connector,包括但不限于Milvus、Pinecone、Qdrant、Postgres SQL、ElasticSearch、Tencent Vector DB等,这使得VTS能够与多种数据源和存储系统兼容。
支持的Transform
VTS还支持多种数据转换操作,如TablePathMapper(更改表名)、FieldMapper(增删列)、Embedding(文本向量化)等,这些转换操作使得VTS在数据处理上更加灵活。
支持的数据类型
VTS支持包括Float Vector、Sparse Float Vector、多向量列、动态列、数据插入,包括Upsert和Bulk Insert(离线,大批量)等多种数据类型,这进一步增强了其在处理复杂数据迁移任务时的能力。
性能演示
VTS在性能上也表现出色,例如在Pinecone到Milvus的迁移Demo中,同步1亿向量的速率为2961/s,大约需要9个半小时(4核/8GB内存)。
Demo见顶部视频。
非结构化数据支持
此外,VTS还支持非结构化数据的处理,目前支持Shopify数据类型,之后将逐步支持包括PDF、Google Doc、Slack、Image/Text在内的非结构化数据类型,不断加强其在极其重要的非结构化数据方面的支持力度。
应用场景
VTS的使用场景广泛,比如在商品推荐场景中,可以从Shopify同步产品和库存数据,调用嵌入服务,将数据存入Milvus,并进行相似度搜索,最终返回最相似的商品,极大地优化商品推荐的效果。
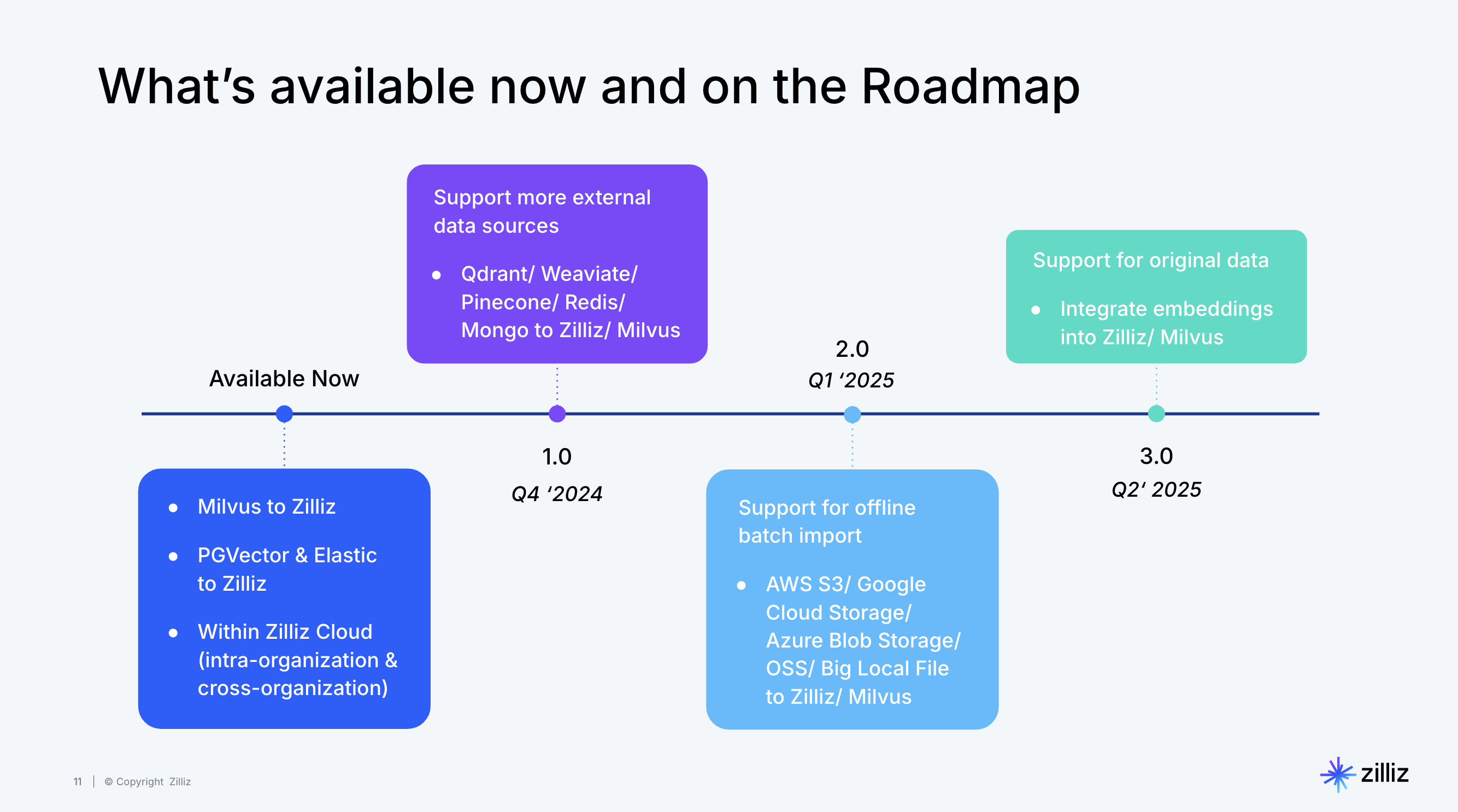
未来规划
展望未来,迁移服务将不断发展。通过VTS开源迁移服务工具,不仅仅能够解决当前向量数据管理中的问题和挑战,还在为创新型 AI 应用开发铺平道路。
VTS的未来规划包括支持更多的数据源,如Chroma DB、DataStax(Astra DB)、DataLake、Mongo DB、Kafka(实时AI)、对象存储导入等。
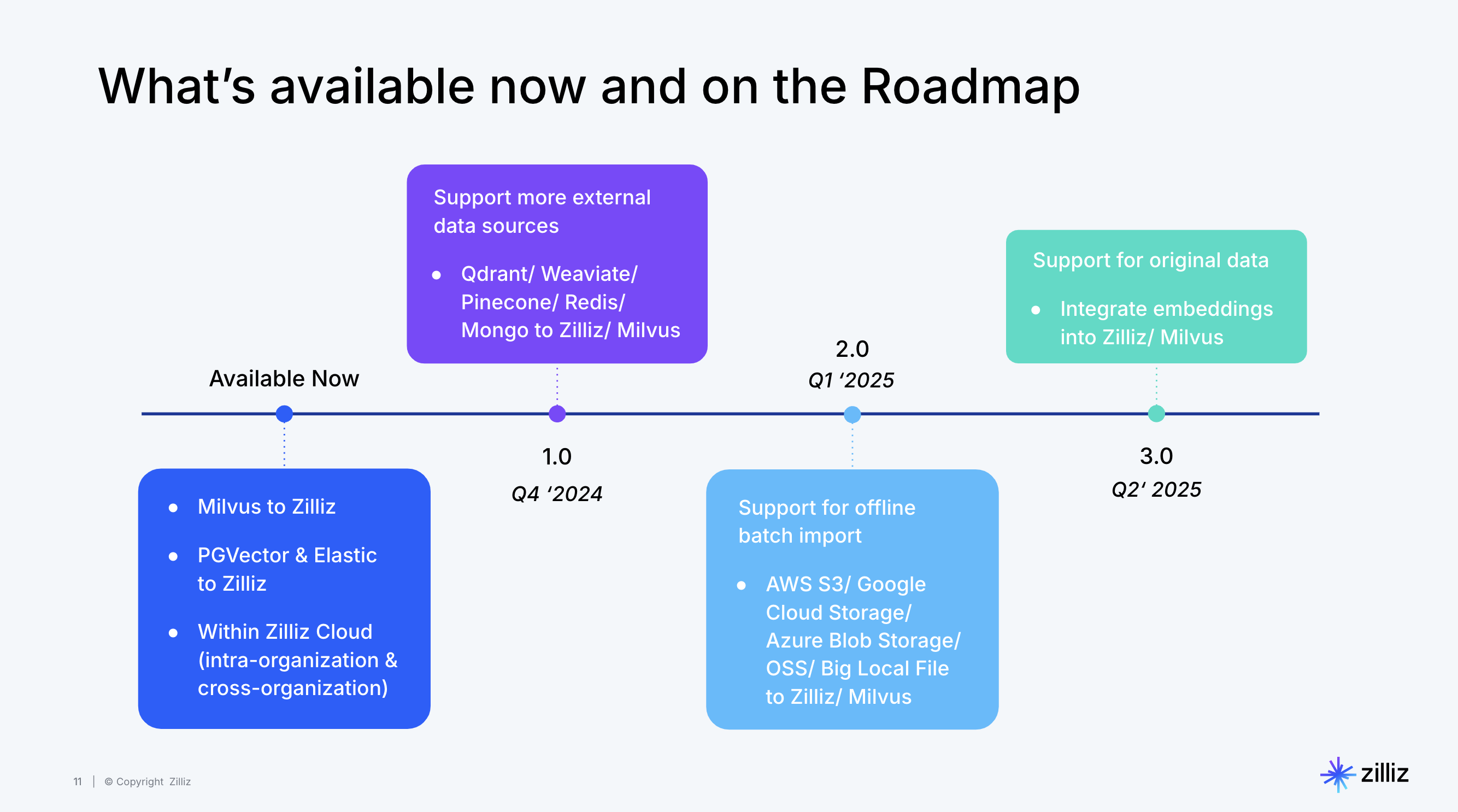
据悉,VTS直接插入原始数据和使用原始数据进行搜索的功能,预计在Milvus 2.5版本中实现。
另外,在针对GenAI的ETL pipeline方面,VTS也将尝试支持任务流编排、Embedding service,外部API,以及对开源大数据工作流调度平台Apache DolphinScheduler的支持。
结语
VTS作为一个基于Apache SeaTunnel开发的向量数据迁移工具,不仅继承了SeaTunnel的强大数据处理能力,还扩展了对向量数据和非结构化数据的支持,使其成为AI和机器学习领域中不可或缺的数据迁移工具。更多关于VTS的信息和资源可以在其GitHub页面找到。
本文由 白鲸开源科技 提供发布支持!