使用StarRocks用于数据湖,实时或离线数仓表查询是一个常见的需求。而大部分湖仓(如Paimon、Iceberg、Hive 等)是Java生态,StarRocks 通过 JNI(Java Native Interface)Connector 支持与这些组件的交互。本文从一条简单的sql查询导致的 OutOfMemoryError,剖析 StarRocks 是在什么情况下会使用 JNI 读取器,分析为啥 BE 也会有堆内存溢出的问题。
问题背景
执行一条查询paimon表的sql
csharp
select * from xxx where dt='xxx' limit 10;执行过程中 StarRocks 的 BE 进程抛出 java.lang.OutOfMemoryError: Java heap space 异常,导致查询失败。
kotlin
Exception in thread "Thread-523" java.io.IOException: Failed to open the paimon reader. at com.starrocks.paimon.reader.PaimonSplitScanner.open(PaimonSplitScanner.java:121)Caused by: java.lang.UnsupportedOperationException: 14600369 cannot be satisfied. at org.apache.paimon.data.columnar.heap.HeapBytesVector.reserve(HeapBytesVector.java:105) at org.apache.paimon.data.columnar.heap.HeapBytesVector.appendBytes(HeapBytesVector.java:77) at org.apache.paimon.format.parquet.reader.BytesColumnReader.readBinary(BytesColumnReader.java:89) ... at org.apache.paimon.reader.RecordReaderIterator.<init>(RecordReaderIterator.java:36) at com.starrocks.paimon.reader.PaimonSplitScanner.initReader(PaimonSplitScanner.java:107) at com.starrocks.paimon.reader.PaimonSplitScanner.open(PaimonSplitScanner.java:116)Caused by: java.lang.OutOfMemoryError: Java heap space at org.apache.paimon.data.columnar.heap.HeapBytesVector.reserve(HeapBytesVector.java:100) ... 20 more初步怀疑是表数据过大导致,但查询更大的 Paimon 或 Hive 表时问题并未复现。因此,转向分析是否为 paimon reader 模块的 bug,或读取主键表时堆内存未释放导致溢出。
问题分析
于是把 BE 进程的堆内存 dump 下来,通过MAT分析堆内存里的对象,如下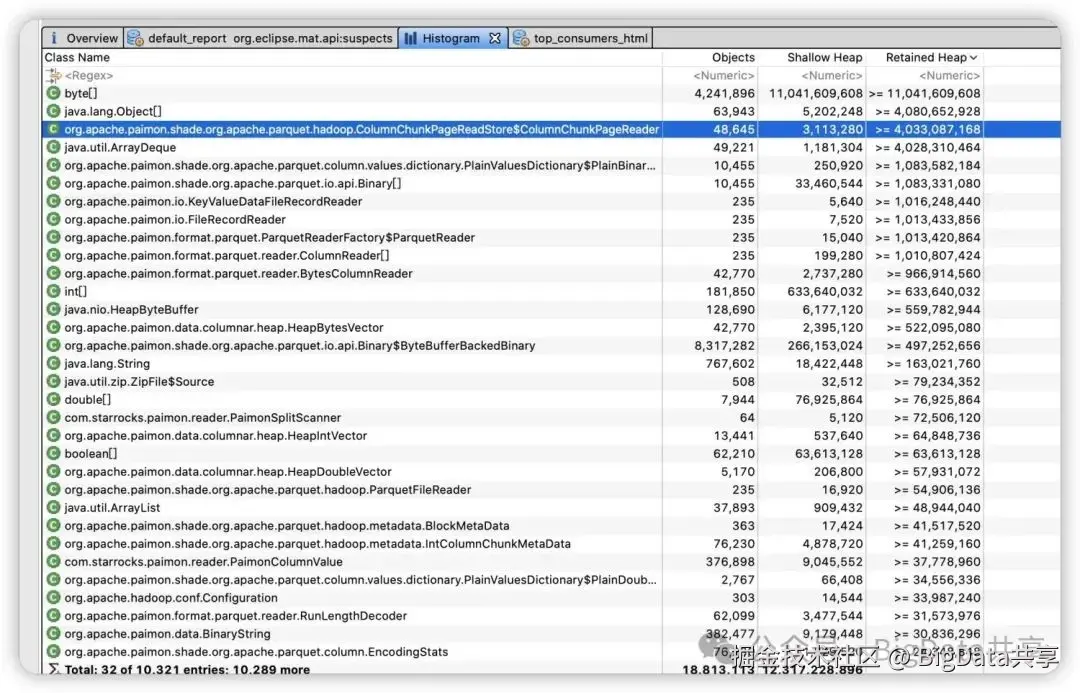
堆内存里的byte\[\]数组是 Paimon Scanner 在读取数据时生成的大量中间对象,如果人为触发GC,大部分也能被GC回收。于是梳理了下代码分析 BE 是怎么通过 JNI 创建相关的读取器。 通过 GDB 调试 BE 进程,查看初始化 JNI Scanner 的堆栈,确认了堆栈
less
#0 starrocks::JniScanner::_init_jni_table_scanner (this=this@entry=0x7f2335864600, env=env@entry=0x7f2348db6340, runtime_state=runtime_state@entry=0x7f2300ebd000) at be/src/exec/jni_scanner.cpp:101#1 0x0000000007b25fcd in starrocks::JniScanner::do_open (this=0x7f2335864600, state=0x7f2300ebd000) at be/src/exec/jni_scanner.cpp:52#2 0x0000000007b36ce7 in starrocks::HdfsScanner::open (this=this@entry=0x7f2335864600, runtime_state=runtime_state@entry=0x7f2300ebd000) at be/src/exec/hdfs_scanner.cpp:219#3 0x0000000007aaa202 in starrocks::connector::HiveDataSource::_init_scanner (this=this@entry=0x7f233593a800, state=state@entry=0x7f2300ebd000) at be/src/connector/hive_connector.cpp:736#4 0x0000000007aab431 in starrocks::connector::HiveDataSource::open (this=0x7f233593a800, state=0x7f2300ebd000) at be/src/connector/hive_connector.cpp:185#5 0x00000000048459ec in starrocks::pipeline::ConnectorChunkSource::_open_data_source (this=this@entry=0x7f24e2576150, state=<optimized out>, state@entry=0x7f2300ebd000, mem_alloc_failed=mem_alloc_failed@entry=0x7f247dc5ec4f) at be/src/exec/pipeline/scan/connector_scan_operator.cpp:757#6 0x0000000004845c2d in starrocks::pipeline::ConnectorChunkSource::_read_chunk (this=0x7f24e2576150, state=0x7f2300ebd000, chunk=0x7f247dc5eda0) at be/src/exec/pipeline/scan/connector_scan_operator.cpp:784 ...在 hive_connector.cpp 代码里判断是创建对应的 JNI_Scanner 还是使用StarRocks原生的 Scanner。
其中,Avro、RCFile 和 SequenceFile 等文件格式是通过 Java Native Interface(JNI)读取的,而非 StarRocks 原生 Reader。因此,对比 Parquet 和 ORC 等格式,这些文件格式的读取性能可能较低,因为多了一层 c++ 调用 java的开销。
scss
if (_datacache_options.enable_cache_select) { scanner = new CacheSelectScanner(); } else if (_use_partition_column_value_only) { DCHECK(_can_use_any_column); scanner = new HdfsPartitionScanner(); } else if (use_paimon_jni_reader) { scanner = create_paimon_jni_scanner(jni_scanner_create_options).release(); } else if (use_hudi_jni_reader) { scanner = create_hudi_jni_scanner(jni_scanner_create_options).release(); } else if (use_odps_jni_reader) { scanner = create_odps_jni_scanner(jni_scanner_create_options).release(); } else if (use_iceberg_jni_metadata_reader) { scanner = create_iceberg_metadata_jni_scanner(jni_scanner_create_options).release(); } else if (use_kudu_jni_reader) { scanner = create_kudu_jni_scanner(jni_scanner_create_options).release(); } else if (format == THdfsFileFormat::PARQUET) { scanner = new HdfsParquetScanner(); } else if (format == THdfsFileFormat::ORC) { scanner_params.orc_use_column_names = state->query_options().orc_use_column_names; scanner = new HdfsOrcScanner(); } else if (format == THdfsFileFormat::TEXT) { scanner = new HdfsTextScanner(); } else if ((format == THdfsFileFormat::AVRO || format == THdfsFileFormat::RC_BINARY || format == THdfsFileFormat::RC_TEXT || format == THdfsFileFormat::SEQUENCE_FILE) && (dynamic_cast<const HdfsTableDescriptor*>(_hive_table) != nullptr || dynamic_cast<const FileTableDescriptor*>(_hive_table) != nullptr)) { scanner = create_hive_jni_scanner(jni_scanner_create_options).release(); }Hive表的是否走JNI读取器是在be侧,根据文件的格式来决定。AVRO, RC_BINARY, RC_TEXT, SEQUENCE_FILE 文件格式是通过 JNI 读取的,而PARQUET, ORC, TEXT这些使用StarRocks原生Reader。
而对于paimon表,是在FE里根据逻辑决定是否使用JNI读取器,具体见 PaimonScanNode.java
- 当会话变量 forceJNIReader 为 true, 无论文件格式如何,都会使用 JNI 读取器
- 如果 DataSplit 无法转换为 RawFile 则使用 JNI 读取器。或者,即使转为RawFile,但文件格式未知(fromType(p.format()) == THdfsFileFormat.UNKNOWN),也会使用 JNI 读取器
- 对于非 DataSplit 类型,如Paimon 系统表,直接使用 JNI 读取器处理
scss
boolean forceJNIReader = ConnectContext.get().getSessionVariable().getPaimonForceJNIReader(); Map<BinaryRow, Long> selectedPartitions = Maps.newHashMap(); for (Split split : splits) { if (split instanceof DataSplit) { DataSplit dataSplit = (DataSplit) split; Optional<List<RawFile>> optionalRawFiles = dataSplit.convertToRawFiles(); if (!forceJNIReader && optionalRawFiles.isPresent()) { List<RawFile> rawFiles = optionalRawFiles.get(); boolean validFormat = rawFiles.stream().allMatch(p -> fromType(p.format()) != THdfsFileFormat.UNKNOWN); if (validFormat) { Optional<List<DeletionFile>> deletionFiles = dataSplit.deletionFiles(); for (int i = 0; i < rawFiles.size(); i++) { if (deletionFiles.isPresent()) { splitRawFileScanRangeLocations(rawFiles.get(i), deletionFiles.get().get(i)); } else { splitRawFileScanRangeLocations(rawFiles.get(i), null); } } } else { long totalFileLength = getTotalFileLength(dataSplit); addSplitScanRangeLocations(dataSplit, predicateInfo, totalFileLength); } } else { long totalFileLength = getTotalFileLength(dataSplit); addSplitScanRangeLocations(dataSplit, predicateInfo, totalFileLength); } BinaryRow partitionValue = dataSplit.partition(); if (!selectedPartitions.containsKey(partitionValue)) { selectedPartitions.put(partitionValue, nextPartitionId()); } } else { // paimon system table long length = getEstimatedLength(split.rowCount(), tupleDescriptor); addSplitScanRangeLocations(split, predicateInfo, length); } }以 Paimon Scanner 为例,jni_scanner.cpp 中定义了 JNI 调用流程:
- 获取 Java 类和方法:通过 JNI 接口找到目标 Java 类及其方法。
- 调用 Java 方法:使用 JNI 函数调用 Java 的静态或实例方法。
- 处理返回值:从 Java 方法获取返回值并在 C++ 中处理。
ini
Status JniScanner::_init_jni_method(JNIEnv* env) { // init jmethod _jni_scanner_open = env->GetMethodID(_jni_scanner_cls, "open", "()V"); RETURN_IF_ERROR(_check_jni_exception(env, "Failed to get `open` jni method"));
_jni_scanner_get_next_chunk = env->GetMethodID(_jni_scanner_cls, "getNextOffHeapChunk", "()J"); RETURN_IF_ERROR(_check_jni_exception(env, "Failed to get `getNextOffHeapChunk` jni method"));
_jni_scanner_close = env->GetMethodID(_jni_scanner_cls, "close", "()V"); RETURN_IF_ERROR(_check_jni_exception(env, "Failed to get `close` jni method"));
_jni_scanner_release_column = env->GetMethodID(_jni_scanner_cls, "releaseOffHeapColumnVector", "(I)V"); RETURN_IF_ERROR(_check_jni_exception(env, "Failed to get `releaseOffHeapColumnVector` jni method"));
_jni_scanner_release_table = env->GetMethodID(_jni_scanner_cls, "releaseOffHeapTable", "()V"); RETURN_IF_ERROR(_check_jni_exception(env, "Failed to get `releaseOffHeapTable` jni method")); return Status::OK();}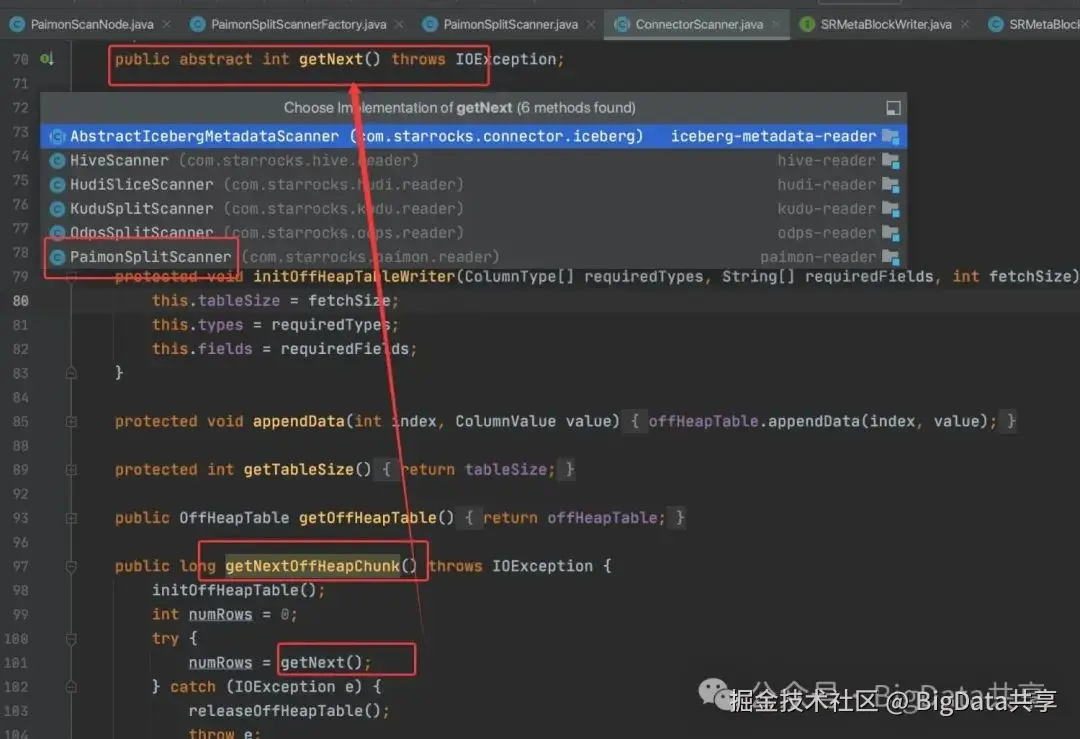
paimon scanner 就是通过 PaimonSplitScannerFactory 这个工厂类创建对应的 PaimonSplitScanner
c
// ---------------paimon jni scanner------------------
std::unique_ptr<JniScanner> create_paimon_jni_scanner(const JniScanner::CreateOptions& options) {
const auto& scan_range = *(options.scan_range);
const HiveTableDescriptor* hive_table = options.hive_table;
const auto* paimon_table = dynamic_cast<const PaimonTableDescriptor*>(hive_table);
std::map<std::string, std::string> jni_scanner_params;
jni_scanner_params["split_info"] = scan_range.paimon_split_info;
jni_scanner_params["predicate_info"] = scan_range.paimon_predicate_info;
jni_scanner_params["native_table"] = paimon_table->get_paimon_native_table();
jni_scanner_params["time_zone"] = paimon_table->get_time_zone();
std::string scanner_factory_class = "com/starrocks/paimon/reader/PaimonSplitScannerFactory";
return std::make_unique<JniScanner>(scanner_factory_class, jni_scanner_params);
}那么,JVM的堆内存大小又是在哪里设置的呢?分析下start_backend.sh脚本,脚本里设置了JAVA_HOME,并根据其值配置 LD_LIBRARY_PATH 环境变量,以确保 Java 相关的本地库(JNI)能够被正确加载使用。
bash
if [ "$JAVA_HOME" = "" ]; then
echo "[WARNING] JAVA_HOME env not set. Functions or features that requires jni will not work at all."
export LD_LIBRARY_PATH=$STARROCKS_HOME/lib:$LD_LIBRARY_PATH
else
java_version=$(jdk_version)
if [[ $java_version -gt 8 ]]; then
export LD_LIBRARY_PATH=$JAVA_HOME/lib/server:$JAVA_HOME/lib:$LD_LIBRARY_PATH
# JAVA_HOME is jdk
elif [[ -d "$JAVA_HOME/jre" ]]; then
export LD_LIBRARY_PATH=$JAVA_HOME/jre/lib/$jvm_arch/server:$JAVA_HOME/jre/lib/$jvm_arch:$LD_LIBRARY_PATH
# JAVA_HOME is jre
else
export LD_LIBRARY_PATH=$JAVA_HOME/lib/$jvm_arch/server:$JAVA_HOME/lib/$jvm_arch:$LD_LIBRARY_PATH
fi
fi启动脚本里并没有对堆内存设置大小,JVM这块堆内存是jdk初始化设置的最大堆内存:32178700288(大概30G)

而堆内存的大小是不被算在 BE 内存里,通过配置 mem_limit 指定 BE 内存,如果使用 JNI,top查看实际内存的使用基本上都会超过这个配置的内存大小。
问题解决
StarRocks 通过jni创建PaimonSplitScanner实例,每个scanner实例需要一定的堆内存做merge处理(具体见读主键表堆栈),假设每个实例对堆内存的使用是定量,那么对堆内存的需求跟实例数量成比例。也就是创建太多的scanner实例,而实例数是跟并发有关,因此可以通过减小并发(如果服务是混部可以通过num_cores, mem_limit限制 be 的资源使用也能减少并发)或者在start_backend.sh启动脚本里增加最大堆内存大小(-Xmx)参数,通过提高堆内存大小来解决堆内存溢出问题。 更多大数据干货,欢迎关注我的微信公众号---BigData共享