技术背景
Apache SeaTunnel 作为一款开源的数据集成框架,支持多种数源的集成。根据我司的业务场景,需要将每日的流水数据从MySQL按日期归档到ClickHouse中。
用户可以通过ClickHouse实现在线分析处理查询(OLAP)和分析数据报告生成。通过Apache SeaTunnel实现每日增量流水数据从MySQL归档到ClickHouse。
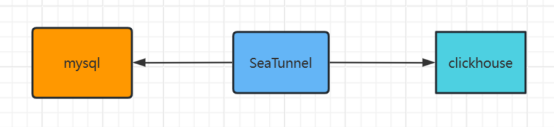
由于使用华为增强的ClickHouse版本,目前开源中的ClickHouse连接器无法直接使用,且需要经过Kerberos认证。
同时华为增强的ClickHouse版本是基于ELB(Elastic Load Balance)的HA部署架构,需要通过Https协议访问高可用的ELB节点。
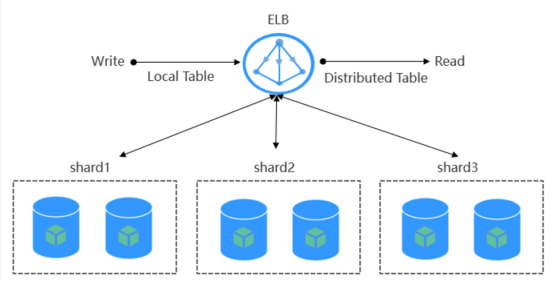
支持华为增强的ClickHouse版本
基于通用性的考虑,采用增强Connector-JDBC的方式,使该连接器兼容华为增强的ClickHouse版本的JDBC连接方式。
目前Connector-JDBC模块支持了多种SQL方言,如MySQL,GBASE,DB2等。
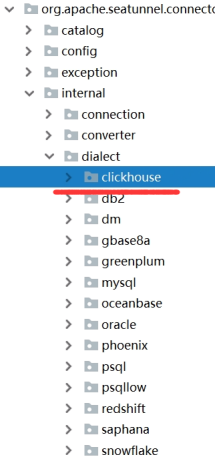
Connector-JDBC模块使用自动服务加载器(ServiceLoader)实现方言组件的自动加载(目前大部分开源组件都会使用类似机制以提高程序的可扩展性)。
在Connector-JDBC模块增加对华为增强的ClickHouse版本支持分为如下步骤:
增加ClickHouse方言配置
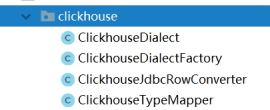
1)ClickhouseDialect:定义方言名称等信息
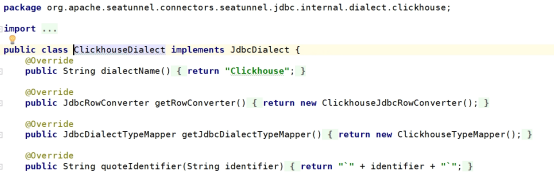
2)ClickhouseFactory: ClickHouse方言定义工厂。
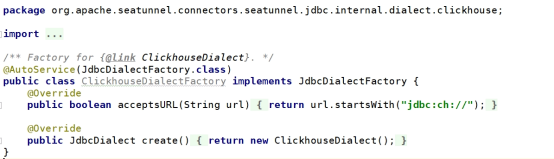
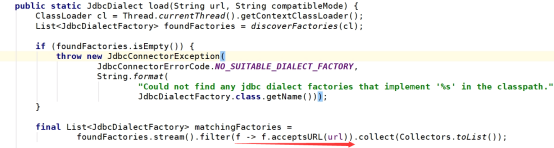
Source或者Sink组件启动时会根据URL开头匹配到实际的方言工厂类,并进行加载。
3)ClickHouseJdbcRowConverter:行转换器

4)ClickHouseTypeMapper:类型转换器
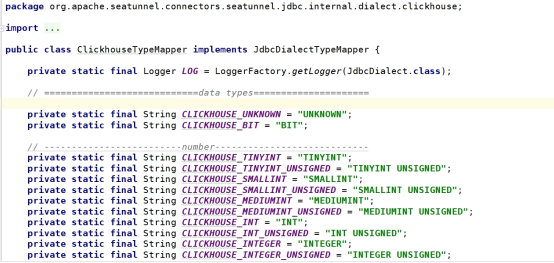
由于Apache SeaTunnel自定义了通用数据类型SeaTunnelRow,所有其他的数据类型都需要转化成SeaTunnel自身的数据类型。
例如: 将ClickHouse中的UINT16对应到LONG类型:

跟踪源码,Source在初始化时会进行转化操作。
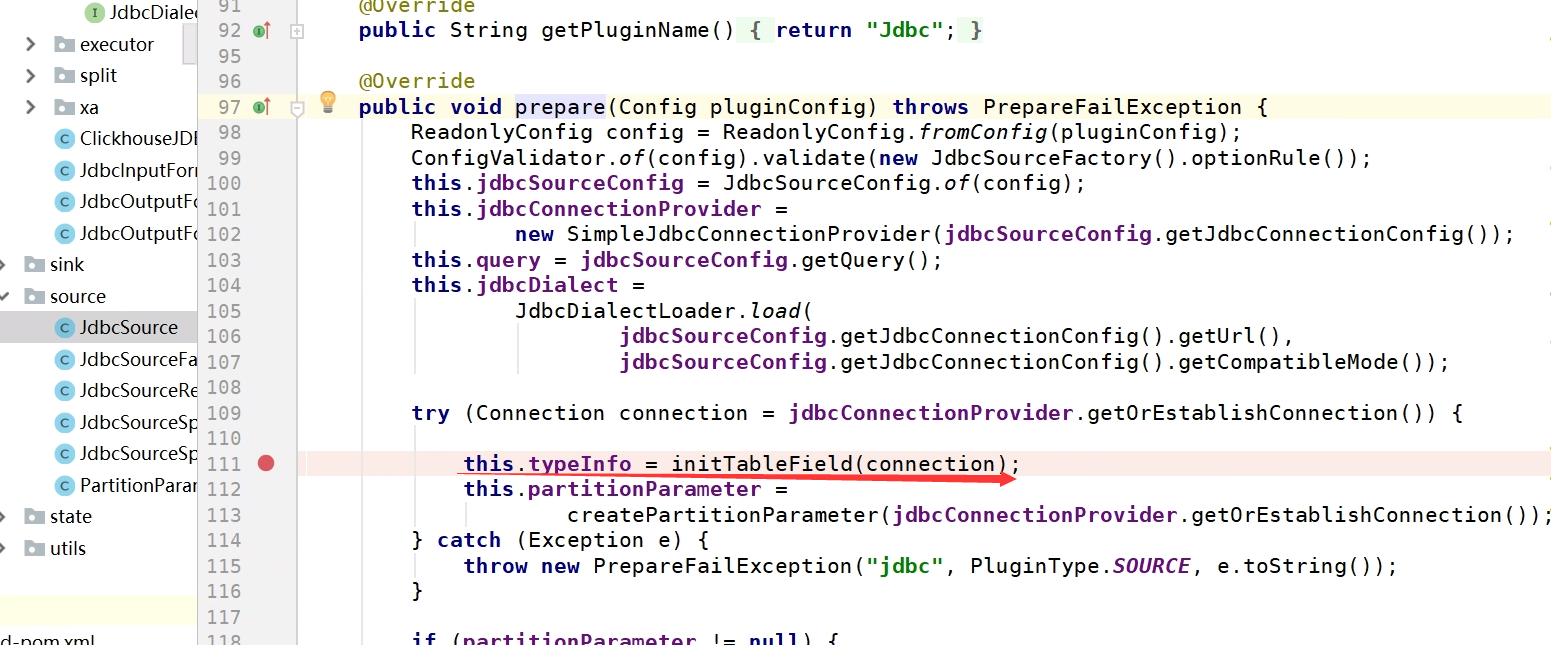
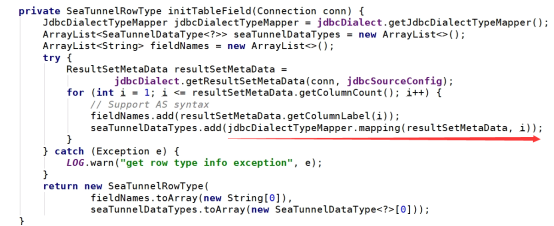
新增华为ClickHouse的JDBC连接工具类。
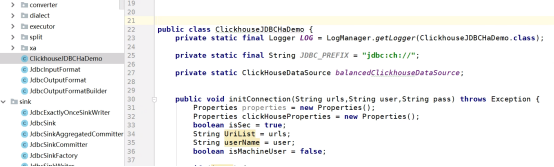

该类参考华为官方给的ClickHouse示例代码。
扩展
SimpleJdbcConnectionProvider,以支持ClickHouse的JDBC连接。
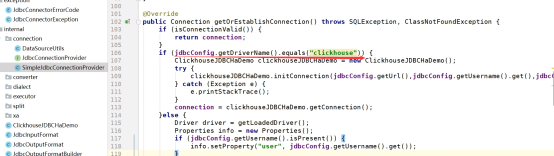
测试连接器
配置SeaTunnel脚本:使用Example模块进行单元测试
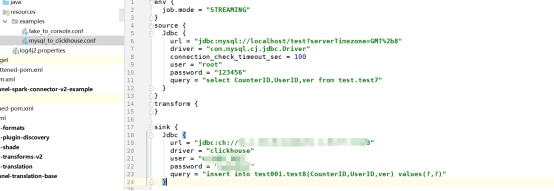
其中Source配置的是MYSQL的数据源
Sink配置ClickHouse的数据源
-
driver:clickhouse
-
url:jdbc:ch//IP:PORT,IP是ELB的IP,PORT是HTTPS的端口
-
user: kerberos认证用户
-
password: kerberos认证用户密码
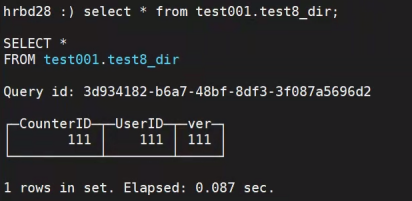
运行成功,查看结果:
本文由 白鲸开源科技 提供发布支持!