摘要:
①将前一帧的对象特征应用为当前帧的查询,并引入一组学习的对象查询来检测新出现的对象
②通过一次完成对象检测和对象关联建立了一种新颖的联合检测和跟踪范例
引言:
背景:
多目标跟踪(MOT)在视觉监控、公共安全等领域至关重要。
现有MOT方法因多阶段处理流程导致模型复杂和计算成本高。
TransTrack提出了一种新的联合检测和跟踪框架,以共享检测和目标关联之间的知识。
对比:
基于检测的多目标跟踪:
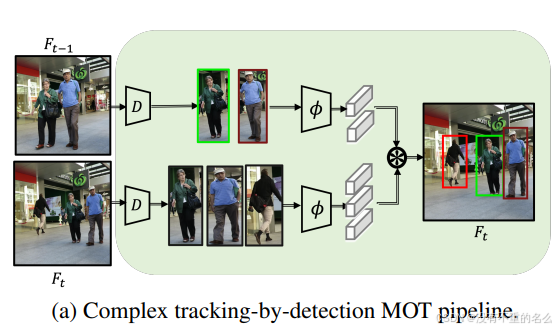
过程:
①视频序列中的连续帧通过检测器识别出目标对象
②使用特征提取器从每个检测到的对象中提取特征
③比较与
对象的特征,确定是否为同一对象。通过特征匹配和数据关联,更新每个对象的轨迹,包括位置、速度和方向等信息。新检测到的对象会初始化新的轨迹,而长时间未检测到的对象轨迹则被终止。
简单的QK单目标跟踪:
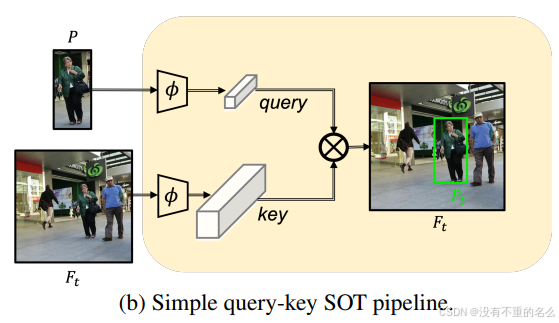
过程:
①从目标对象的初始帧中经过特征提取器提取特征生成查询(query)
②在视频序列的每一帧中经过特征提取器提取特征生成键(key)
③通过比较查询和键的相似度,系统能够在当前帧中定位目标对象
简单的QK多目标跟踪:
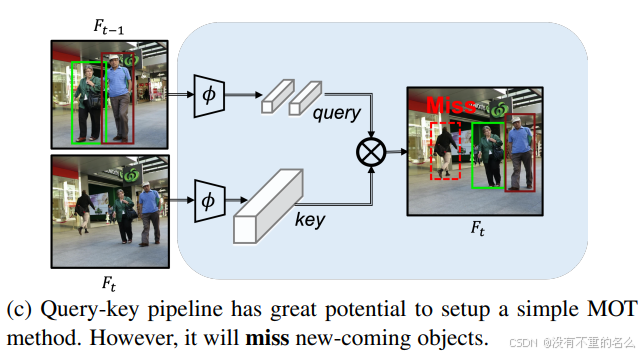
过程:
①在前一帧中检测到的目标通过特征提取器
生成查询(query)
②在当前帧中提取所有目标的特征生成键(key)
③比较查询和键的相似度,在当前帧中定位前一帧的目标
缺点:
会错过新出现的目标,因为它依赖于前一帧的信息来识别和跟踪目标。
TransTrack:
流程:
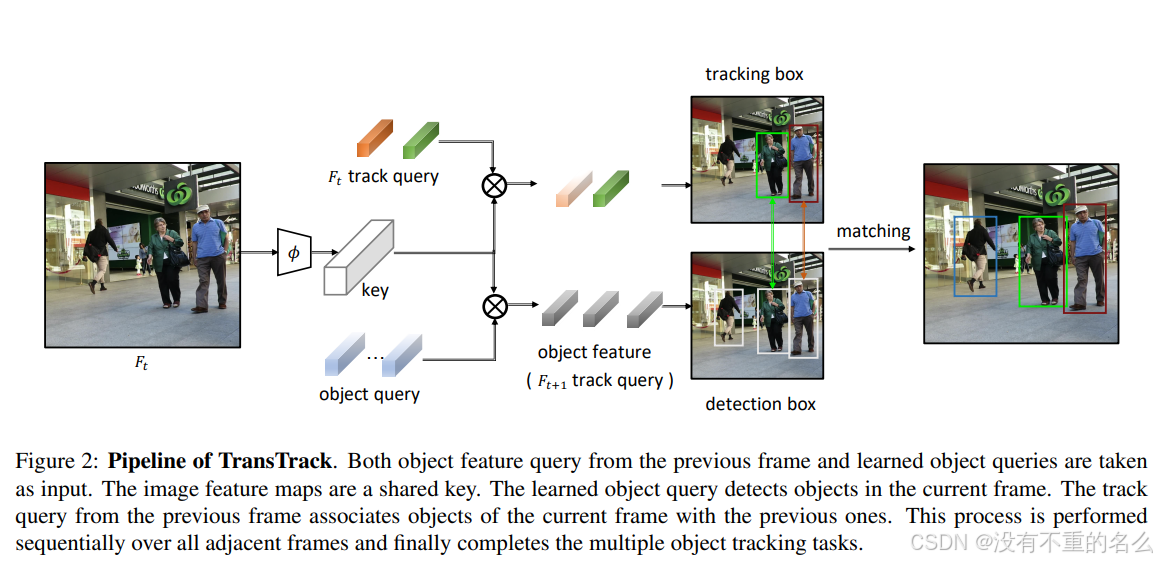
① 输入帧(Input Frame):表示当前处理的视频帧
python
cap = cv2.VideoCapture(args.video_input)
...
res, img = cap.read()② 特征提取(Feature Extraction):使用特征提取器 从当前帧
中提取图像特征,生成特征图(key)
python
self.body = IntermediateLayerGetter(backbone, return_layers=return_layers)
python
def forward(self, tensor_list: NestedTensor):
# 通过self.body提取特征
xs = self.body(tensor_list.tensors)
out: Dict[str, NestedTensor] = {}
for name, x in xs.items():
m = tensor_list.mask
assert m is not None
# 调整掩码
mask = F.interpolate(m[None].float(), size=x.shape[-2:]).to(torch.bool)[0]
# out字典包含了特征图和其相关掩码
out[name] = NestedTensor(x, mask)
return out③ 对象查询(Object Query):从上一帧学习得到的对象查询(object query)用于在当前帧中检测对象
Object Query 就是一个通过训练逐步学习的"标签"或"查询",它最终学会了代表目标的边界框位置和类别。它的角色不仅是标记一个位置,而是作为一个"查询向量"从图像中"获取"有关该目标的信息,并通过 Transformer 的解码过程不断优化自己,直到能够精准地定位和分类目标。这个过程就像是每个 Object Query 在图像中"寻找"一个目标,并根据图像特征逐步调整,直到它能够正确表示这个目标。
python
query_embed, tgt = torch.split(query_embed, c, dim=1)④ 跟踪查询(Track Query):从上一帧中提取的对象特征查询(track query)用于将当前帧中的对象与上一帧的对象进行关联。
python
pos_trans_out = self.pos_trans_norm(self.pos_trans(self.get_proposal_pos_embed(topk_coords_unact)))
query_embed, tgt = torch.split(pos_trans_out, c, dim=2)⑤ 特征匹配(Feature Matching):进行两次QK
QK1:
object query与key进行对比,检测目标对象,生成新对象的检测框
检测框(Detection Box):学习的对象查询在当前帧中生成检测框,用于标记新检测到的对象。
python
class DeformableTransformerDecoder(nn.Module):
def forward(self, track_query, key, value):
# query_pos 通常表示 object query,它是用来表示需要检测的目标的查询向量
# query_pos 会与 src(输入特征)进行对比,通过注意力机制来为每个目标生成一个候选框
output = layer(output, query_pos, reference_points_input, src, src_spatial_shapes, src_padding_mask)
return outputs_trackingQK2:
track query与key进行对比,跟踪关联,进行跟踪生成跟踪框
跟踪框(Tracking Box):通过匹配过程,为每个跟踪的对象生成跟踪框,这些框在视频序列中连续地标记同一对象。
python
class DeformableTransformerDecoder(nn.Module):
def forward(self, track_query, key, value):
# reference_points_input 是用来表示当前参考点(可能是跟踪中的目标)的位置,它也可以理解为 track query
# reference_points_input 会影响每个查询向量的加权和,从而帮助模型更准确地预测每个目标的位置信息
output = layer(output, query_pos, reference_points_input, src, src_spatial_shapes, src_padding_mask)
return outputs_tracking⑥ 匹配(Matching):将检测框与跟踪框进行计算相似度匹配,以更新对象的轨迹。
python
# 使用匈牙利算法计算成本矩阵
C = self.cost_bbox * cost_bbox + self.cost_class * cost_class + self.cost_giou * cost_giou
indices = [linear_sum_assignment(c[i]) for i, c in enumerate(C.split(sizes, -1))]⑦ 序列处理(Sequential Processing):在所有相邻帧上顺序执行,最终完成多目标跟踪任务。
架构:
基于Transformer的编码器-解码器框架,利用多头注意力层和前馈网络。
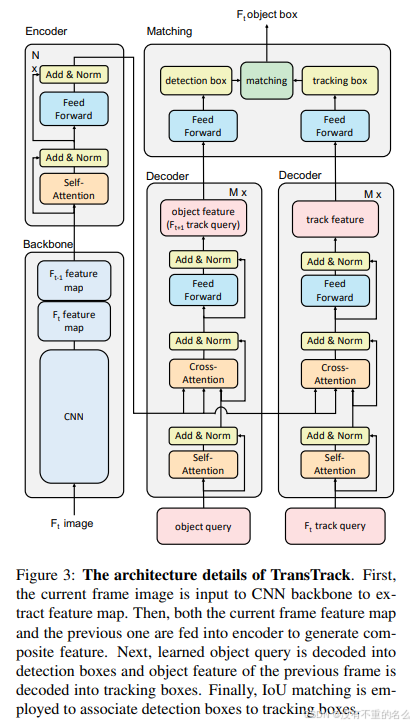
来自两个来源的查询:
以对象查询作为输入,提供常见的对象检测结果;利用先前检测到的对象的特征来形成另一个"跟踪查询",以发现后续帧上的关联对象。
两个并行解码器:
从编码器生成的特征图被两个解码器用作公共密钥
两个解码器被设计为分别执行对象检测和对象传播
python
self.decoder = DeformableTransformerDecoder(decoder_layer, num_decoder_layers, return_intermediate_dec)
self.decoder_track = DeformableTransformerDecoder(decoder_layer, num_decoder_layers, return_intermediate_dec)目标检测:
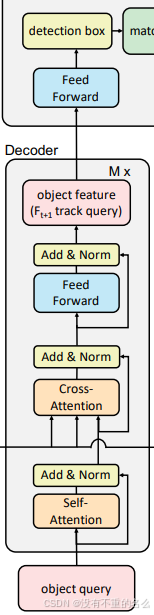
从输入图像生成的全局特征图,对象查询查找图像中感兴趣的对象并输出最终的检测预测
python
outputs_classes = []
outputs_coords = []
for lvl in range(hs.shape[0]):
if lvl == 0:
reference = init_reference
else:
reference = inter_references[lvl - 1]
reference = inverse_sigmoid(reference)
outputs_class = self.class_embed[lvl](hs[lvl])
tmp = self.bbox_embed[lvl](hs[lvl])
if reference.shape[-1] == 4:
tmp += reference
else:
assert reference.shape[-1] == 2
tmp[..., :2] += reference
outputs_coord = tmp.sigmoid()
outputs_classes.append(outputs_class)
outputs_coords.append(outputs_coord)
outputs_class = torch.stack(outputs_classes)
outputs_coord = torch.stack(outputs_coords)目标传播:
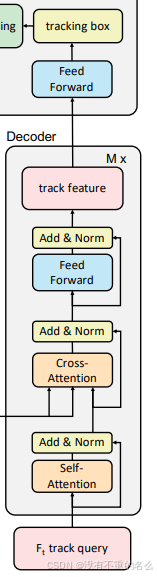
将前一帧检测到的目标特征作为跟踪查询,以在当前帧中定位相应目标。
框关联:
使用框IoU匹配方法得到最终的跟踪结果
将Kuhn-Munkres(KM)算法应用于检测框和跟踪框的IoU相似度,将检测框与跟踪框进行匹配。
实验:
损失函数:

在MOT17和MOT20数据集上评估TransTrack的性能。
进行了消融研究,包括Transformer架构、解码器查询、跟踪框匹配策略和边界框关联策略。
训练和推理:
使用AdamW优化器,从ImageNet预训练的ResNet-50作为网络骨干。
训练150个周期,学习率在第100个周期降低10倍
消融研究:
Transformer架构:比较了不同Transformer结构对性能的影响。
解码器查询:研究了使用对象查询和跟踪查询对性能的影响。
跟踪框匹配策略:比较了不同匹配策略的效果。
边界框关联:比较了匈牙利算法和NMS方法的效果。
结论:
TransTrack是第一个基于Transformer解决MOT问题的工作,提供了一个新的视角和高效的基线。