Stable Diffusion是一种基于扩散技术的深度学习文本转图像模型,于 2022 年发布。
生成式人工智能技术是Stability AI的首要产品,被认为是正在进行的人工智能热潮的一部分。
它主要用于根据文本描述生成详细图像,但也可应用于其他任务,如修复、去除
图像以及根据文本提示生成图像到图像的转换。
它的开发由慕尼黑大学CompVis 小组和Runway的研究人员参与,Stability 提供计算支持,
并使用了非营利组织提供的训练数据。
稳定扩散是一种潜在扩散模型,是一种深度生成人工神经网络。
其代码和模型权重已公开发布,并且可以在大多数配备至少 4 GB VRAM的
普通GPU的消费级硬件上运行。
这与之前只能通过云服务访问的专有文本转图像模型(如DALL-E和Midjourney)不同。
Stable Diffusion 起源于一个名为Latent Diffusion的项目,由德国
慕尼黑路德维希马克西米利安大学和海德堡大学的研究人员开发。最初的 5 位作者中
有 4 位(Robin Rombach、Andreas Blattmann、Patrick Esser 和 Dominik Lorenz)
后来加入了 Stability AI,并发布了 Stable Diffusion 的后续版本。
该模型的技术许可证由慕尼黑路德维希马克西米利安大学的 CompVis 团队发布。
开发由Runway的 Patrick Esser 和 CompVis 的 Robin Rombach 领导,
他们是先前发明了 Stable Diffusion 使用的潜在扩散模型架构的研究人员之一。
Stability AI 还将EleutherAI和LAION(一家德国非营利组织,收集了
Stable Diffusion 训练所用的数据集)列为该项目的支持者。
架构
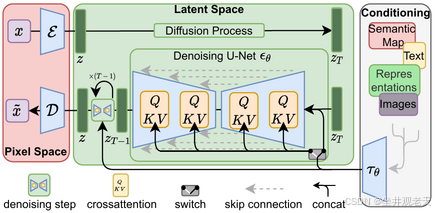
SD3之前的稳定扩散系列模型都使用了一种扩散模型(DM),称为潜在扩散模型 (LDM),
由慕尼黑大学CompVis(计算机视觉与学习)小组开发。扩散模型于 2015 年推出,
其训练目标是消除训练图像上连续应用的高斯噪声,可将其视为一系列去噪自动编码器。
稳定扩散由 3部分组成:
变分自动编码器(VAE)、U-Net和可选的文本编码器。
VAE 编码器将图像从像素空间压缩到更小维度的潜在空间,从而捕捉图像更基本的语义含义。
在前向扩散过程中,高斯噪声会迭代地应用于压缩的潜在表示。
U-Net 模块由ResNet主干组成,它对前向扩散的输出进行去噪,以获得潜在表征。
最后,VAE 解码器通过将表征转换回像素空间来生成最终图像。

去噪步骤可以灵活地根据文本字符串、图像或其他模态进行调节。
编码后的调节数据通过交叉注意机制暴露给去噪 U-Nets 。
对于文本调节,使用固定的、预训练的CLIP ViT-L/14 文本编码器将文本提示转换为嵌入空间。
研究人员指出,LDM 的优势在于训练和生成的计算效率更高。
扩散这个名字的灵感来自于热力学 扩散,2015 年,这个纯物理场与深度学习之间建立了重要的联系。
U-Net 中有 8.6亿个参数, 文本编码器中有 1.23 亿个参数,按 2022 年的标准,
Stable Diffusion 被认为是相对轻量级的。与其他扩散模型不同,它可以在消费级GPU上运行,
如果使用OpenVINO版本的 Stable Diffusion ,甚至可以仅在CPU 上运行。
3.0版本彻底改变了骨干网络。不再是 UNet,而是Rectified Flow Transformer,它使用
Transformer实现了整流方法。
SD 3.0使用的 Transformer 架构有三个"轨道",分别用于原始文本编码、转换后的文本编码和图像编码(在潜在空间中)。
转换后的文本编码和图像编码在每个 Transformer 块中混合。
该架构被命名为"多模态扩散变换器(MMDiT)",其中"多模态"表示它在其操作中混合了文本和图像编码。
这与以前版本的 DiT 不同,其中文本编码会影响图像编码,但反之则不然。
训练数据
稳定扩散模型在从 LAION-5B 中获取的图像和标题对上进行训练,LAION-5B 是一个公开可用的数据集,
源自从网络上抓取的Common Crawl数据,其中 50 亿个图像-文本对基于语言进行分类,并根据分辨率、
预测包含水印的可能性和预测的"美学"分数(例如主观视觉质量)过滤到单独的数据集中。
该数据集由德国非营利组织LAION创建,该组织获得 Stability AI 的资助。
稳定扩散模型在 LAION-5B 的三个子集上进行了训练:laion2B-en、laion-high-resolution 和 laion-aesthetics v2 5+。
第三方对模型训练数据的分析发现,在从原始使用的更广泛数据集中获取的 1200 万张图像的较小子集中,
约有 47% 的图像样本来自 100 个不同的域,其中Pinterest占该子集的 8.5%,
其次是WordPress、Blogspot、Flickr、DeviantArt和Wikimedia Commons等网站。
巴伐利亚广播公司的一项调查显示,LAION 托管在 Hugging Face 上的数据集包含大量私人和敏感数据。
训练过程
该模型最初在 laion2B-en 和 laion-high-resolution 子集上进行训练,最后几轮训练在
LAION-Aesthetics v2 5+ 上进行,LAION-Aesthetics v2 5+ 是一个包含 6 亿张带字幕图像的子集,
LAION-Aesthetics Predictor V2 预测,当被要求评价人们对这些图像的喜欢程度时,人类平均会给出至少5分(满分10分)。
LAION-Aesthetics v2 5+ 子集还排除了低分辨率图像和 LAION-5B-WatermarkDetection
识别为带有水印的概率超过 80% 的图像。
最后几轮训练还放弃了 10%的文本条件,以改进无分类器扩散指导。
该模型使用Amazon Web Services上的 256 个Nvidia A100 GPU进行训练,总共耗时 150,000 GPU 小时,
成本为 600,000 美元。 30 31 32
SD3的训练成本约为 1000 万美元。