集群与架构组件
相关组件
组件交互关系
一台服务器是一个节点,一个节点下面可能有多个pod,一个pod下面可能有多个容器
-
控制面板(Master)
控制面板式K8S的核心,它负责管理整个集群,并协调工作节点上的容器化应用的部署和运行。
1.1kubectl
- 作用:这是K8S的命令行工具,允许管理员与API Server进行交互,比如创建资源、部署应用或查询集群状态。
- 交互:通过kubectl,管理员可以发送命令给API Server,API Server再把指令传递给集群中的其他组件。
1.2API Server
- 作用:API Server是K8S的入口,它处理所有外部请求,并将这些请求转化为集群内部的操作。
- 功能:
- 提供REST API接口,共
kubectl或其他工具访问。 - 验证和处理请求。
- 将集群的状态信息存储到
etcd中。
- 提供REST API接口,共
- 与其他组件的交互:
- 接收kubectl的请求并处理。
- 将数据写入etcd
- 与Scheduler和Controller-manager交互。
1.3 etcd
- 作用:分布式键值存储系统,用于保存K8S集群的所有状态数据。
- 功能:
- 存储集群的配置信息,例如部署、服务发现等。
- 以强一致性方式存储数据,确保就请你的高可靠性。
- 与其他组件的交互:
- 接收API Server提供的调度任务。
- 更新调度决策到etcd中。
1.4 Controller-manager
- 作用:负责处理集群中的控制循环(controller loop).
- 功能:
- 确保实际状态和期望状态一致。
- 管理副本控制器(ReplicaSets)、节点控制器、服务控制器等。
- 与其他组件的交互:
- 从API Server或etcd获取资源状态。
- 根据状态更新任务,触发相关操作。
-
工作节点(Node)
工作节点是K8S集群运行应用程序的实际计算资源。每个节点运行以下核心组件:
2.1kubelet
- 作用:Kubelet是Node上的核心代理,它负责管理节点上的容器。
- 功能:
- 根据API Server的指令在节点上创建、启动和销毁Pod。
- 监控Pod的状态,并报告给API Server.
- 与其他组件的交互:
- 接收来自API Server的调度指令。
- 启动Docker容器或其他容器运行是的实例。
- 定期向API Server汇报节点和Pod的状态。
2.2kube-proxy
- 作用:kube-proxy是K8s的网络组件,负责服务发现和负载均衡。
- 功能:
- 在节点上实现K8S的服务(Service)抽象。
- 维护网络规则,确保Pod能够通过ClusterIP或NodePort被访问。
- 与其他组件的交互
- 获取服务和端点(Endpoints)的信息,配置iptables或其他网络代理工具。
2.3Docker(或其他容器运行时)
- 作用:容器运行时是K8S管理容器的基础组件,负责容器的实际启动和运行。
- 功能:
- 根据Kubelet的指令启动容器。
- 提供资源隔离(CPU、内存)和文件系统支持。
2.4Pod
- 作用:Pod是K8s中最小的部署单元,一个Pod可以包含一个或多个容器。
- 功能:
- 容器共享网络命名空间和存储卷。
- 为应用提供运行环境。
- 控制平面与工作节点的交互
- API Server与Node:
- API Server是集群的中央通信中心,负责向Kubelet下发调度任务(如部署Pod)。
- API Server定期从Kubelet获取节点和Pod的状态数据。
- Scheduler和Node:
- Scheduler 根据集群状态和调度算法,为新的 Pod 选择工作节点。
- 调度决定通过 API Server 下发给 Kubelet。
- Controller-manager与Node:
- Controller-manager 监控 Pod 和节点的状态,确保实际状态与期望状态一致。
- 当节点不可用时,Controller-manager 会启动恢复操作(如重启 Pod)。
- 工作流程总结
- 用户通过
kubectl提交资源描述(如 Deployment)。 - API Server 接收并验证请求,将期望状态存储到
etcd。 - Scheduler 根据调度策略,将 Pod 分配到最优节点。
- Kubelet 在指定的节点上启动 Pod,调用 Docker 或其他容器运行时来运行容器。
- kube-proxy 设置网络规则,确保 Pod 和服务可以互相通信。
- 各组件持续监控,确保状态一致,并根据需要执行恢复或调整。
- 用户通过


- 用户请求流程
- 用户使用kubectl 或其他客户端,通过RESTful API与kube-apiserver交互,提交操作请求。
- 请求流程
- kube-apiserve r接收到创建Pod的请求,将信息存储在etcd中。
- kube-scheduler 监听到有新的未调度的Pod,决定将其调度到某个Worker Node。
- 调度决策通过kube-apiserver 更新到etcd。
- 节点执行
- 目标Worker Node 上的kubelet监听到新的Pod分配,获取PodSpec。
- kublet 通过容器运行时拉取所需的镜像并创建容器。
- kubelet 持续监控容器的运行状态,定期向kube-apiserver汇报。
- 服务发现与网络通信
- kube-proxy监听kube-apiserver,获取服务(Service)和端点(Endpoint)信息。
- 配置本节点的网络规则,实现服务的负载均衡和网络转发。
- 云资源管理
- cloud-controller-manager 监听kube-apiserver,获取需要云资源支持的服务(如LoadBalancer类型的Service)
- 与云厂商API交互,创建或配置相应的云资源。
控制面板组件
控制面板组件和节点组件是搭建k8s集群后一定在的,附加组件可以安装也可以不安装
kube-apiserver
kube-apiserver 是 Kubernetes 控制面的核心组件,提供了集群的 RESTful API 接口。
- 功能:
- 处理所有对集群的 REST 请求,验证并更新数据到 etcd。
- 提供认证、授权、准入控制等安全机制。
- 特点:
- 可扩展性:支持自定义资源和第三方 API 组。
- 高性能:通过水平扩展多个实例,提升处理能力。
- 作用:
- 作为其他所有控制面组件的通信枢纽。
- 提供 kubectl 等客户端与集群交互的接口。
cloud-controller-manager
cloud-controller-manager 是用于与云供应商交互的控制器,负责管理云特定的控制逻辑。
- 功能:
- 处理与云平台相关的控制任务,如节点生命周期、负载均衡器和存储卷的管理。
- 特点:
- 插件化:通过云供应商插件,支持多种云平台。
- 解耦性:将云特定逻辑从核心 Kubernetes 中分离,方便维护和扩展。
- 组件:
- Node Controller:监控云端节点的变化。
- Route Controller:设置云端路由。
- Service Controller:创建、更新云负载均衡器。
kube-scheduler
kube-scheduler 是 Kubernetes 的默认调度器,负责将新创建的 Pod 分配到合适的节点上。
- 功能:
- 根据资源需求、调度策略和约束条件,为 Pod 选择最佳节点。
- 特点:
- 多策略支持:资源利用率、亲和性/反亲和性、数据局部性等。
- 可扩展性:支持自定义调度器和调度策略插件。
- 流程:
- 过滤不符合条件的节点(Predicates)。
- 对符合条件的节点进行打分(Priorities)。
- 选择得分最高的节点。
etcd
etcd 是一个强一致性的分布式键值存储系统,用于存储 Kubernetes 集群的所有重要数据,包括配置信息、状态数据和元数据。
- 功能:
- 存储集群的配置信息和状态数据。
- 支持分布式锁和领导者选举机制,确保数据一致性。
- 特点:
- 高可用性:通过集群方式部署,避免单点故障。
- 强一致性:基于 Raft 共识算法,实现数据的线性一致性。
- 应用:
- 保存 Kubernetes 的所有 API 对象状态,如 Pod、Service、ConfigMap 等。
- 为其他需要分布式一致性存储的应用提供支持。
节点组件
Node(节点)是集群中运行工作负载的基本计算单元。每个Node都代表一个单独的物理机或虚拟机,并运行多个核心组件,以支持Pods(Kubernetes中的最小部署单元)的调度和管理。


- 角色:
- Node是Kubernetes集群的工作节点,承载并运行容器化的应用程序。
- 每个Node节点上都运行关键的Kubernetes组件和支持容器化应用的系统服务。
- 组成:
- 宿主机操作系统。
- Kubernetes的必要组件(如kubelet、kube-proxy等)。
- 容器运行时(例如Docker或containerd)
kubelet
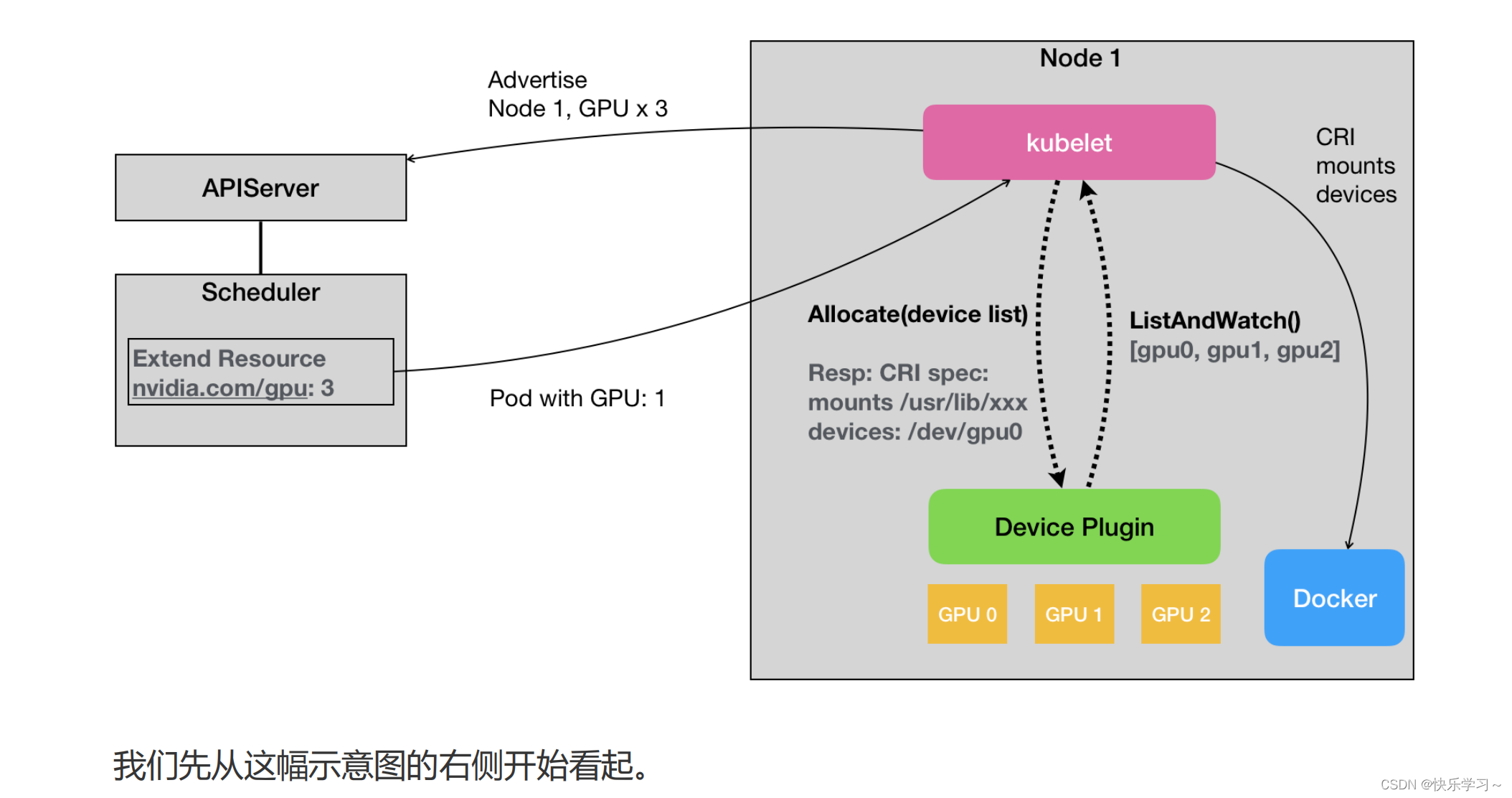
kubelet 是运行在每个节点上的主要代理服务,负责管理该节点上的 Pod 和容器。
- 功能:
- 负责与Kubernetes控制平面交互。
- 监听API Server的指令,并根据调度的Pods创建和管理容器。
- 定期汇报Node的状态(资源使用情况、运行的Pods等)到控制平面。
- 管理Pods的生命周期,监控容器的运行状况,并重新启动失败的容器。
- 工作方式:
- kubelet根据PodSpec(由API Server下发的描述Pod的文件)来创建和管理容器。
kube-proxy

kube-proxy 是 Kubernetes 中的网络代理,运行在每个节点上,维护网络规则以实现服务的通信和负载均衡。
- 功能:
- 管理网络规则和负载均衡,支持Kubernetes Service的网络功能。
- 负责将服务的流量路由到正确的Pod。
- 通过设置IP表规则或运行用户空间代理来转发服务的请求。
- 工作方式:
- 使用Kubernetes API提供的服务信息,动态配置路由规则。
- 确保服务于工作负载之间的网络浏览稳定可靠。
container runtime
容器运行时 负责管理容器的生命周期,包括创建、运行和销毁容器。
- 常见实现:
- Docker:最早的容器运行时,实现了 OCI 标准。
- containerd:轻量级的容器运行时,由 Docker 抽象出来。
- CRI-O:专为 Kubernetes 设计的容器运行时,直接支持 OCI 容器。
- 特点:
- CRI 接口:Kubernetes 通过 CRI 与容器运行时通信,支持多种实现。
- 功能:
- 拉取容器镜像。
- 管理容器的启动、停止和删除。
附加组件
kube-dns
kube-dns 是 Kubernetes 的默认 DNS 插件,为集群中的服务和 Pod 提供 DNS 名称解析。
- 功能:
- 根据服务和 Pod 的元数据自动创建 DNS 记录。
- 实现服务发现机制,使得应用程序可以使用域名互相通信。
- 特点:
- 自动化:无需手动配置,动态更新 DNS 记录。
- 可替代性:CoreDNS 已逐渐取代 kube-dns,提供更高的性能和灵活性。
- 作用:
- 简化应用程序的网络通信配置。
- 提供对外部服务的名称解析。
Ingress Controller
Ingress Controller 是用于管理 Ingress 资源的控制器,为集群提供 HTTP 和 HTTPS 路由。
- 功能:
- 根据 Ingress 规则,将外部请求路由到集群内部的服务。
- 常见实现:
- Nginx Ingress Controller:最常用的实现,功能丰富。
- Traefik:支持自动发现,配置简单。
- HAProxy:性能高,配置灵活。
- 特点:
- 七层负载均衡:支持基于域名、路径等进行路由。
- SSL/TLS 支持:可以终止或传递 SSL。
- 作用:
- 统一管理集群的外部入口。
- 提供安全、灵活的路由策略。
Heapster
现在常用的是普罗米修斯
Heapster 是 Kubernetes 早期的资源监控工具,用于聚合和分析集群的性能数据。
- 功能:
- 收集各节点和 Pod 的 CPU、内存、网络等指标。
- 提供数据给自动扩缩容组件(HPA)。
- 特点:
- 集成性:与 Kubernetes 无缝集成,使用 Kubernetes API 进行数据收集。
- 可扩展性:支持将数据导出到多种后端存储,如 InfluxDB。
- 注意:
- 已被弃用:Heapster 已被 Metrics Server 取代,后者性能更高,集成更好。
Dashboard
Dashboard 是 Kubernetes 官方提供的 Web UI,可视化地管理和监控集群资源。
- 功能:
- 查看集群的整体状态和各资源的详细信息。
- 创建、更新、删除各种 Kubernetes 资源。
- 特点:
- 用户友好:提供直观的界面,降低操作门槛。
- 安全性:支持基于角色的访问控制(RBAC)。
- 作用:
- 方便运维人员和开发者快速了解集群状况。
- 提供图形化的操作方式,减少命令行的复杂度。
Federation
Federation(联邦)是 Kubernetes 的多集群管理方案,允许将多个集群联合起来进行统一管理。
- 功能:
- 跨集群同步资源,实现资源的全局配置。
- 提供跨集群的服务发现和负载均衡。
- 特点:
- 高可用性:提高应用的容错和灾难恢复能力。
- 统一管理:简化多集群环境下的运维工作。
- 应用场景:
- 地理分布式部署,需要将流量引导到最近的集群。
- 跨云部署,避免对单一云供应商的依赖。
Fluentd-elasticsearch
Fluentd-elasticsearch 是 Kubernetes 中的日志收集和存储解决方案,结合 Fluentd、Elasticsearch 和 Kibana(简称 EFK)实现。
- 功能:
- Fluentd:收集和转发日志数据。
- Elasticsearch:存储和索引日志。
- Kibana:可视化和分析日志。
- 特点:
- 高性能:Fluentd 轻量级且高效,适合大规模日志收集。
- 灵活性:支持多种输入和输出插件,可定制性强。
- 作用:
- 集中管理和分析集群日志。
- 提高故障排查和性能调优的效率。
分层架构
生态系统
接口层
管理层
核心层
服务的分类
在 Kubernetes(K8s)中,根据应用的状态管理和数据存储需求,服务通常分为**无状态(Stateless)和有状态(Stateful)**两类。理解这两类服务的区别及其在 Kubernetes 中的实现方式,对于设计和部署高效、可扩展的应用至关重要。
无状态
无状态服务是指其运行过程中不依赖于任何持久化存储,每个请求都是独立的,服务器不会保留任何会话信息。这类服务通常更易于扩展和管理,因为它们不需要担心数据一致性和持久性的问题。
代表应用
- Nginx
- 简介:Nginx 是一个高性能的 HTTP 服务器和反向代理服务器,也可用作负载均衡器和邮件代理服务器。
- 用途:常用于静态内容托管、反向代理、负载均衡和 API 网关。
- Apache
- 简介:Apache HTTP Server 是一个开源的跨平台 HTTP 服务器,具有高度的模块化和可扩展性。
- 用途:广泛用于托管网站、提供静态和动态内容服务。
优点
- 对客户端透明:客户端无需关心后端实例的具体实现,每个实例对客户端来说都是相同的。
- 无依赖关系:各实例之间独立运行,不需要共享状态或数据,减少了复杂性。
- 高效扩展和迁移:可以轻松地根据负载增加或减少实例数量,支持自动化的弹性伸缩。
- 故障恢复:单个实例的故障不会影响整体服务的可用性,Kubernetes 可以快速替换故障实例。
缺点
- 数据存储限制:无状态应用无法本地存储持久数据,所有需要持久化的数据必须依赖外部服务,如数据库或分布式存储系统。
- 会话管理:需要额外的机制(如会话保持或分布式缓存)来管理用户会话,确保请求的一致性。
在 Kubernetes 中的实现
- Deployment:无状态应用通常使用 Deployment 资源进行管理,Deployment 可以确保指定数量的 Pod 实例始终运行,并支持滚动更新和回滚。
- Service:通过 Kubernetes Service(如 ClusterIP、NodePort、LoadBalancer)为无状态应用提供稳定的访问入口和负载均衡。
示例配置
以下是一个部署 Nginx 无状态应用的 Kubernetes 配置示例,包含详细注释:
yaml
# 定义一个 Deployment 资源,用于管理无状态的 Nginx 应用
apiVersion: apps/v1
kind: Deployment
metadata:
name: nginx-deployment # Deployment 的名称
spec:
replicas: 3 # 指定运行的 Pod 副本数量
selector:
matchLabels:
app: nginx # 选择器,用于匹配具有相同标签的 Pod
template:
metadata:
labels:
app: nginx # 为 Pod 分配标签,便于 Service 进行选择
spec:
containers:
- name: nginx # 容器名称
image: nginx:latest # 使用的 Nginx 镜像及其版本
ports:
- containerPort: 80 # 暴露的容器端口,用于接收流量
---
# 定义一个 Service 资源,为 Nginx Deployment 提供网络访问
apiVersion: v1
kind: Service
metadata:
name: nginx-service # Service 的名称
spec:
selector:
app: nginx # 选择器,匹配具有标签 app: nginx 的 Pod
ports:
- protocol: TCP # 使用的协议
port: 80 # Service 对外暴露的端口
targetPort: 80 # 转发到 Pod 的端口
type: LoadBalancer # Service 类型,使用云提供商的负载均衡器有状态
有状态服务指的是其运行过程中依赖于持久化存储,每个实例可能维护特定的状态信息。这类服务通常用于数据库、缓存和其他需要保存数据的应用。
代表应用
- MySQL
- 简介:MySQL 是一个开源的关系型数据库管理系统,广泛用于存储和管理结构化数据。
- 用途:适用于需要事务支持、复杂查询和数据一致性的应用场景。
- Redis
- 简介:Redis 是一个开源的内存数据结构存储系统,支持多种数据类型,如字符串、哈希、列表、集合等。
- 用途:常用于缓存、会话存储、实时分析和消息队列等场景。
优点
- 数据持久化:能够独立存储和管理数据,确保数据在实例重启或迁移后依然可用。
- 数据管理:支持复杂的数据操作和事务处理,适用于需要强一致性和高可靠性的应用。
- 状态维护:能够维护应用的状态信息,适用于需要跟踪用户会话或业务流程的场景。
缺点
- 复杂性增加:在集群环境下,需要实现主从复制、数据同步、备份和恢复等机制,增加了运维的复杂性。
- 水平扩展挑战:有状态应用的扩展通常比无状态应用更为复杂,因为需要确保数据的一致性和完整性。
- 资源消耗:持久化存储和数据同步机制可能增加资源消耗,影响集群的整体性能。
在 Kubernetes 中的实现
- StatefulSet:有状态应用通常使用 StatefulSet 资源进行管理,StatefulSet 可以为每个 Pod 分配唯一的标识符,并确保 Pod 的稳定网络标识和持久存储。
- PersistentVolume (PV) 和 PersistentVolumeClaim (PVC):使用 PV 和 PVC 来提供持久化存储,确保有状态应用的数据在 Pod 重启或迁移后依然可用。
- Headless Service:配合 StatefulSet 使用 Headless Service,确保每个 Pod 都有稳定的网络标识,便于集群内部的服务发现和通信。
示例配置
以下是一个部署 MySQL 有状态应用的 Kubernetes 配置示例,包含详细注释:
yaml
# 定义一个 Headless Service,用于 StatefulSet 中的 MySQL Pod 之间的通信
apiVersion: v1
kind: Service
metadata:
name: mysql # Service 的名称
labels:
app: mysql # 标签,用于选择匹配的 Pod
spec:
ports:
- port: 3306 # Service 暴露的端口
name: mysql # 端口名称
clusterIP: None # 设置为 Headless Service,不分配 Cluster IP
selector:
app: mysql # 选择器,匹配具有标签 app: mysql 的 Pod
---
# 定义一个 StatefulSet 资源,用于管理有状态的 MySQL 应用
apiVersion: apps/v1
kind: StatefulSet
metadata:
name: mysql # StatefulSet 的名称
spec:
serviceName: "mysql" # 与 Headless Service 关联的名称
replicas: 3 # 指定运行的 Pod 副本数量
selector:
matchLabels:
app: mysql # 选择器,用于匹配具有相同标签的 Pod
template:
metadata:
labels:
app: mysql # 为 Pod 分配标签,便于 Service 进行选择
spec:
containers:
- name: mysql # 容器名称
image: mysql:5.7 # 使用的 MySQL 镜像及其版本
ports:
- containerPort: 3306 # 容器端口,用于接收 MySQL 连接
name: mysql # 端口名称
env:
- name: MYSQL_ROOT_PASSWORD # 环境变量名称
value: "password" # MySQL root 用户的密码
volumeMounts:
- name: mysql-persistent-storage # 卷名称,必须与下方的 volumeClaimTemplates 中的名称匹配
mountPath: /var/lib/mysql # 容器内的挂载路径,用于存储 MySQL 数据
volumeClaimTemplates:
- metadata:
name: mysql-persistent-storage # 卷声明的名称
spec:
accessModes: ["ReadWriteOnce"] # 存储访问模式,允许单一节点读写
resources:
requests:
storage: 10Gi # 请求的存储容量关键组件解释
- StatefulSet :管理有状态应用的部署和缩放,确保每个 Pod 都有唯一且稳定的标识符(如
mysql-0、mysql-1等)。 - Headless Service:不分配 Cluster IP,通过 DNS 记录为每个 Pod 提供稳定的网络标识,便于 StatefulSet 中的 Pod 进行相互通信。
- PersistentVolumeClaim (PVC):每个 Pod 通过 PVC 请求特定大小和类型的存储,确保数据的持久化。
无状态与有状态的比较
| 特性 | 无状态服务 | 有状态服务 |
|---|---|---|
| 数据存储 | 不依赖本地存储,所有数据外部化 | 依赖本地或持久化存储,数据与实例绑定 |
| 扩展性 | 容易横向扩展,添加或移除实例简单 | 扩展较复杂,需要管理数据一致性和同步 |
| 故障恢复 | 快速恢复,替换故障实例无需担心数据 | 需要确保数据的完整性和一致性 |
| 部署管理 | 使用 Deployment 等资源管理 | 使用 StatefulSet 等资源管理 |
| 典型应用场景 | Web 服务器、API 服务、前端应用 | 数据库、缓存系统、消息队列 |
选择适合的服务类型
在设计 Kubernetes 集群中的应用时,选择无状态还是有状态服务取决于应用的需求:
- 选择无状态服务 :
- 应用不需要持久化数据,或将数据存储在外部系统。
- 需要高弹性和易于扩展。
- 希望简化运维和部署流程。
- 选择有状态服务 :
- 应用需要持久化存储和管理数据。
- 需要维护应用的状态信息,如数据库和缓存。
- 可以接受更复杂的运维和管理流程,以确保数据的一致性和可用性。
总结
理解无状态和有状态服务的区别,对于在 Kubernetes 中正确部署和管理应用至关重要:
- 无状态服务适合于高弹性、易于扩展的应用场景,能够通过 Kubernetes 的原生资源(如 Deployment 和 Service)轻松管理。
- 有状态服务适合需要持久化存储和状态管理的应用,虽然部署和管理更为复杂,但 Kubernetes 提供了 StatefulSet 和持久化存储资源,帮助简化这些任务。
通过合理地分类和管理服务类型,可以充分发挥 Kubernetes 的优势,实现高效、可靠和可扩展的应用部署。