目录
整合结构
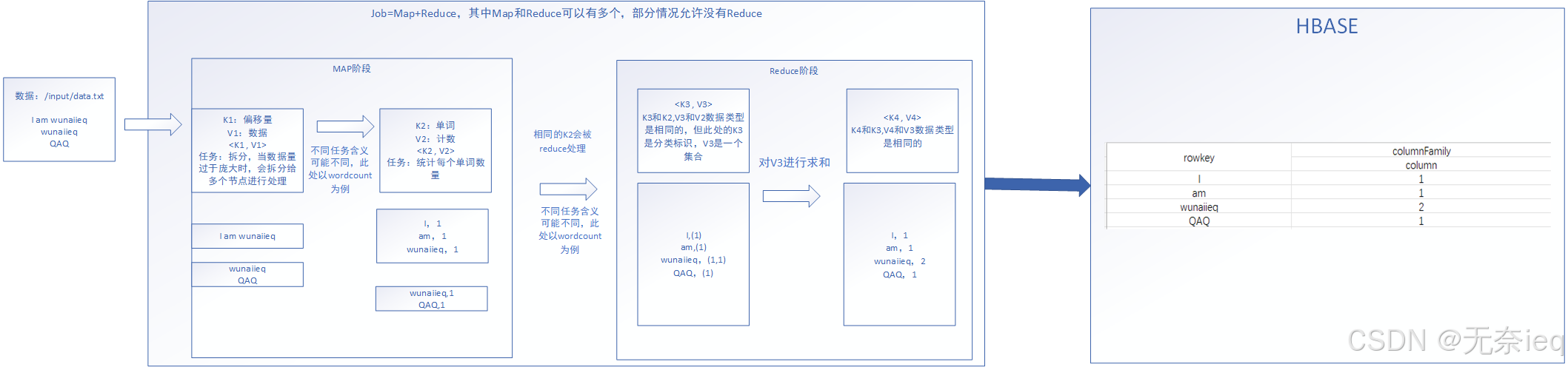
准备
- 上传hdfs data.txt数据
data.txt
bash
I am wunaiieq
QAQ
123456
Who I am
In todays interconnected world the role of technology cannot be overstated It has revolutionized the way we live work and communicate From smartphones to social media platforms technology has made the world more accessible and connected Than ever before It has enabled us to stay informed and connected with people across the globe allowing for instant communication and collaboration The impact of technology on education healthcare and business has been profound It has transformed the way we learn access medical information and conduct business operations As we continue to advance technologically it is essential that we understand and adapt to these changes to fully harness their potentialhdfs
bash
hdfs dfs -put data.txt /input- 制作hbase表格
Hbase shell
bash
create "wunaiieq:wordcount","colf"java API 编写
pom.xml
包含hbase和hdfs的依赖文件
bash
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.hbase</groupId>
<artifactId>hdfs2hbase</artifactId>
<version>1.0-SNAPSHOT</version>
<properties>
<maven.compiler.source>8</maven.compiler.source>
<maven.compiler.target>8</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<hadoop.version>3.1.3</hadoop.version>
<hbase.version>2.2.3</hbase.version>
</properties>
<dependencies>
<!-- Hadoop Dependencies -->
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-yarn-api</artifactId>
<version>${hadoop.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-streaming</artifactId>
<version>${hadoop.version}</version>
</dependency>
<!-- HBase Dependencies -->
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-client</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-server</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-common</artifactId>
<version>${hbase.version}</version>
</dependency>
<dependency>
<groupId>org.apache.hbase</groupId>
<artifactId>hbase-mapreduce</artifactId>
<version>${hbase.version}</version>
</dependency>
<!-- Other Dependencies -->
<dependency>
<groupId>com.google.protobuf</groupId>
<artifactId>protobuf-java</artifactId>
<version>3.19.1</version>
</dependency>
<dependency>
<groupId>org.slf4j</groupId>
<artifactId>slf4j-log4j12</artifactId>
<version>1.7.25</version>
</dependency>
<dependency>
<groupId>log4j</groupId>
<artifactId>log4j</artifactId>
<version>1.2.17</version>
</dependency>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>RELEASE</version>
<scope>compile</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<!--声明-->
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-assembly-plugin</artifactId>
<version>3.3.0</version>
<!--具体配置-->
<configuration>
<archive>
<manifest>
<!--jar包的执行入口-->
<mainClass>org.wunaiieq.hdfs2hbase.Main</mainClass>
</manifest>
</archive>
<descriptorRefs>
<!--描述符,此处为预定义的,表示创建一个包含项目所有依赖的可执行 JAR 文件;
允许自定义生成jar文件内容-->
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
</configuration>
<!--执行配置-->
<executions>
<execution>
<!--执行配置ID,可修改-->
<id>make-assembly</id>
<!--执行的生命周期-->
<phase>package</phase>
<goals>
<!--执行的目标,single表示创建一个分发包-->
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>Main.java
程序主类,和原有的Mapreduce相比逻辑上没有多大的区别
不过原有的mr程序调用的reduce接口的实现类
现在调用的则是TableReducer接口的实现类
bash
package org.wunaiieq.hdfs2hbase;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.streaming.io.InputWriter;
import org.apache.hadoop.hbase.mapreduce.*;
public class Main {
public static void main(String[] args) throws Exception {
//配置文件,写在resources目录下
Job job =Job.getInstance(new Configuration());
//入口类
job.setJarByClass(Main.class);
//文件输入路径(命令行手动输入)
FileInputFormat.setInputPaths(job,new Path(args[0]));
//直接规定,不过我是打jar包,不推荐这么做
//FileInputFormat.setInputPaths(job,new Path("/input/data.txt"));
//Mapper类
job.setMapperClass(Map.class);
job.setMapOutputKeyClass(Text.class);//k2
job.setMapOutputValueClass(IntWritable.class);//v2
//Redecer类,由于写入Hbase,因此此处做出一些修改
TableMapReduceUtil.initTableReducerJob(
"wunaiieq:wordcount",//输入表的名称
Reduce.class,//Reducer类,需要实现TableReducer接口
job,//job实例,当前的作业
null,//输入格式类的类型
null,//输入键的类类型
null,//输入值的类类型
null,//输出键的类类型
false//是否将 HBase 和 Hadoop 的相关依赖 JAR 文件添加到作业的 classpath 中。
);
job.waitForCompletion(true);
}
}Map.java
没什么需要特别注明的,Map层并没有什么修改
bash
package org.wunaiieq.hdfs2hbase;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
public class Map extends Mapper<LongWritable, Text,Text, IntWritable> {
private Text k2 =new Text();
private IntWritable v2 =new IntWritable(1);
@Override
protected void map(LongWritable k1, Text v1,Context context)
throws IOException, InterruptedException {
//将输入文本转成String类型的变量
String data =v1.toString();
//切分单词
String words[]=data.split(" ");
for(String word :words){
//对k2v2进行赋值,k2应为单词,作为后续的rowkey
k2.set(word);
//v2应为1,每次统计时算1个
v2.set(1);
context.write(k2,v2);
//做法相同
//context.write(new Text(word),new IntWritable(1));
}
}
}Reduce
和一般MR程序不同,此处实现TableReducer的接口
bash
package org.wunaiieq.hdfs2hbase;
import org.apache.hadoop.hbase.client.Mutation;
import org.apache.hadoop.hbase.client.Put;
import org.apache.hadoop.hbase.mapreduce.TableMapReduceUtil;
import org.apache.hadoop.hbase.mapreduce.TableReducer;
import org.apache.hadoop.hbase.util.Bytes;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.NullWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* 查看代码原文<br>
* public abstract class TableReducer < k3, v3, k4> <br>
* extends Reducer< k3, v3, k4, Mutation> <br>
*这里的Mutation也就是v4,这个类则是输出到hbase中
* **/
// K3 V3 K4
public class Reduce extends TableReducer<Text, IntWritable,Text> {
@Override
protected void reduce(Text k3, Iterable<IntWritable> v3, Reducer<Text, IntWritable, Text, Mutation>.Context context) throws IOException, InterruptedException {
int sum =0;
for (IntWritable value :v3){
sum+=value.get();
}
//创建Put对象,设置rowkey为k3(单词)
Put put =new Put(Bytes.toBytes(k3.toString()));
//指定列
put.addColumn("colf".getBytes(),"count".getBytes(),Bytes.toBytes(sum));
//输出k4,正常来讲,k4应该等于k3,但此处没有多大作用,因为是输出到hbase中,这一步仅是作为规范
Text k4 =k3;
context.write(k4,put);
}
}运行
注意下哈,这里是hadoop jar
bash
hadoop jar hdfs2hbase-1.0-SNAPSHOT-jar-with-dependencies.jar /input/data.txthadoop jar和java -jar的区别
