Flink 作业执行流程 (Application 模式)
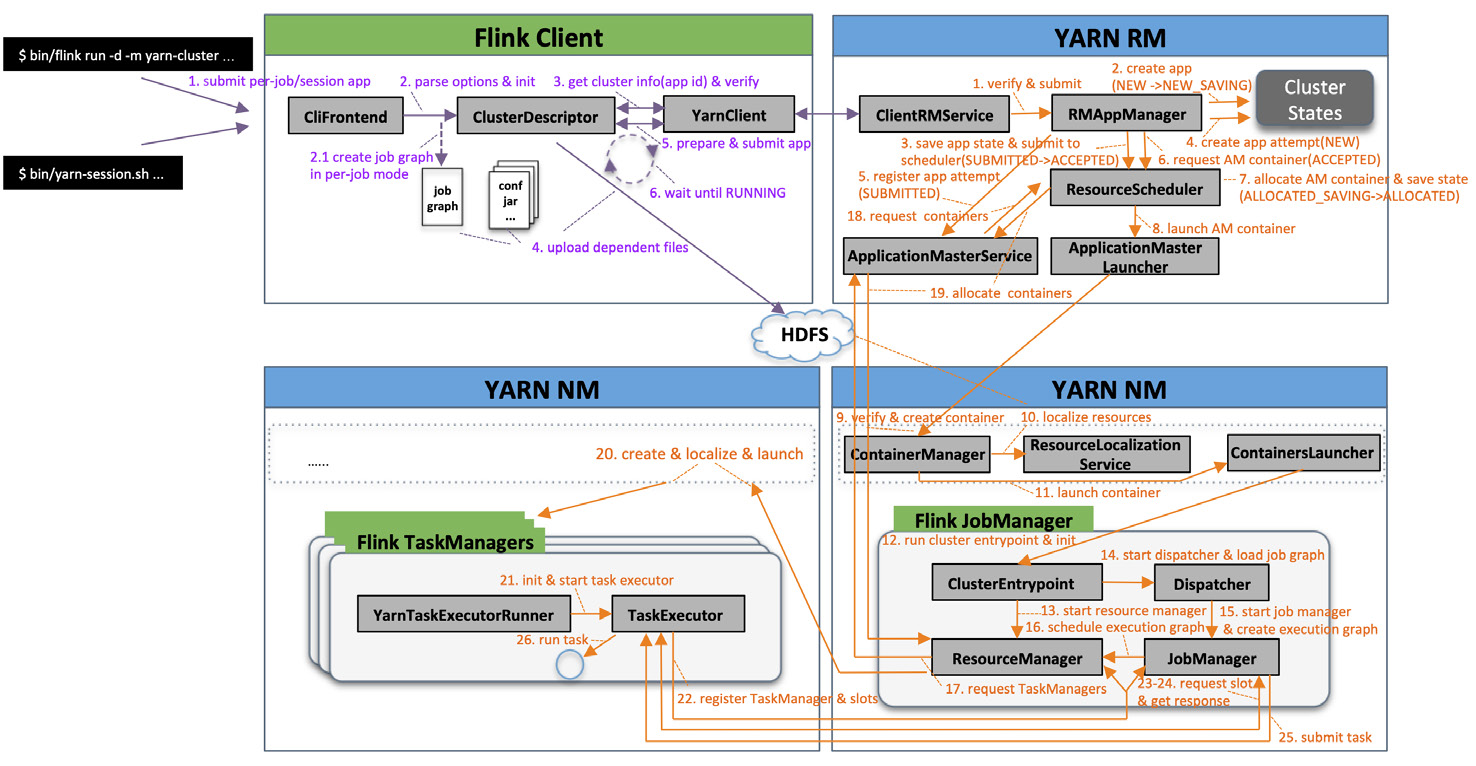
客户端通过 ClusterDescriptor 提交 Application 模式 Sql 任务到服务端,服务端调用作业时 StreamTableEnvironment 使用 FlinkSqlParser 将 SQL 转换为 Operation , StreamTableEnvironment 转换 SQL 过程中使用 CatalogSourceTable 调用 FactoryUtil 的 createDynamicTableSource 方法创建 DynamicTableSource,StreamTableEnvironment 解析完 Sql 后就开始执行 Operation。
StreamTableEnvironment 执行 Operation 过程中, Opeartion 会先被转化为 Transformation,转换过程中也会创建 DynamicTableSink,然后 StreamExecutionEnvironment 会创建并使用 StreamGraphGenerator 通过 Transformation 创建 StreamGraph,然后通过 StreamingJobGraphGenerator 再将 StreamGraph 转换为 JobGraph, 再调用 StreamExecutionEnvironment 执行 JobGraph,也就是将作业提交到 JobManager 上。
StreamTableEnvironment 执行 Operation 过程中,会调用 ExecNodeBase (CommonExecTableSourceScan 和 CommonExecSink) 将 Operation 转换为 Transformation,ExecNodeBase 会从 DynamicTableSource/Sink 中获取 ScanTableSource.ScanRuntimeProvider / Sink / Function / OutputFormat / InputFormat 等数据处理实现类用于创建 Transformation,Transformation 可以理解为对数据流进行处理和转换的操作。
Operation 转换成 Transformation 转换后, StreamTableEnvironment 将通过 Transformation 创建 StreamGraph。
StreamGraph 是一副以 StreamNode 为顶点,StreamEdge 为边连接起来的流图。StreamTableEnvironment 创建 StreamGraph 时会通过 StreamGraphGenerator 使用 Transformation 对应的 TransformationTranslator 将 Transformation 转换成相应的 Operator,然后再使用 Operator 创建 StreamNode 和 StreamEdge。例如在创建过程中 StreamGraphGenerator 会根据 SourceTransformation 创建 SourceOperatorFactory,SourceOperatorFactory 用于创建 SourceOperator 和 SourceCoordinator。StreamNode 代表作业的单个操作,每个操作中包含相关的算子、输入输出类型、资源等配置。可以简单理解为创建 StreamGraph 就是创建算子,以及将所有算子连接起来的操作。
StreamGraph 创建完后,StreamTableEnvironment 还需要将 StreamGraph 转换为 JobGraph。JobGraph 是一副以 JobVertex 为顶点,JobEdge 为边连接起来的作业图, 表示了一个 Flink 作业的逻辑结构,其中包括了任务之间的依赖关系、数据流图、操作符和配置信息等,它定义了整个作业的结构和逻辑,但还没有包括与具体执行相关的信息。JobVertex 表示 Flink 作业中的一个逻辑操作单元,用于描述逻辑任务及其依赖关系,每个 JobVertex 包含一个或多个算子操作。
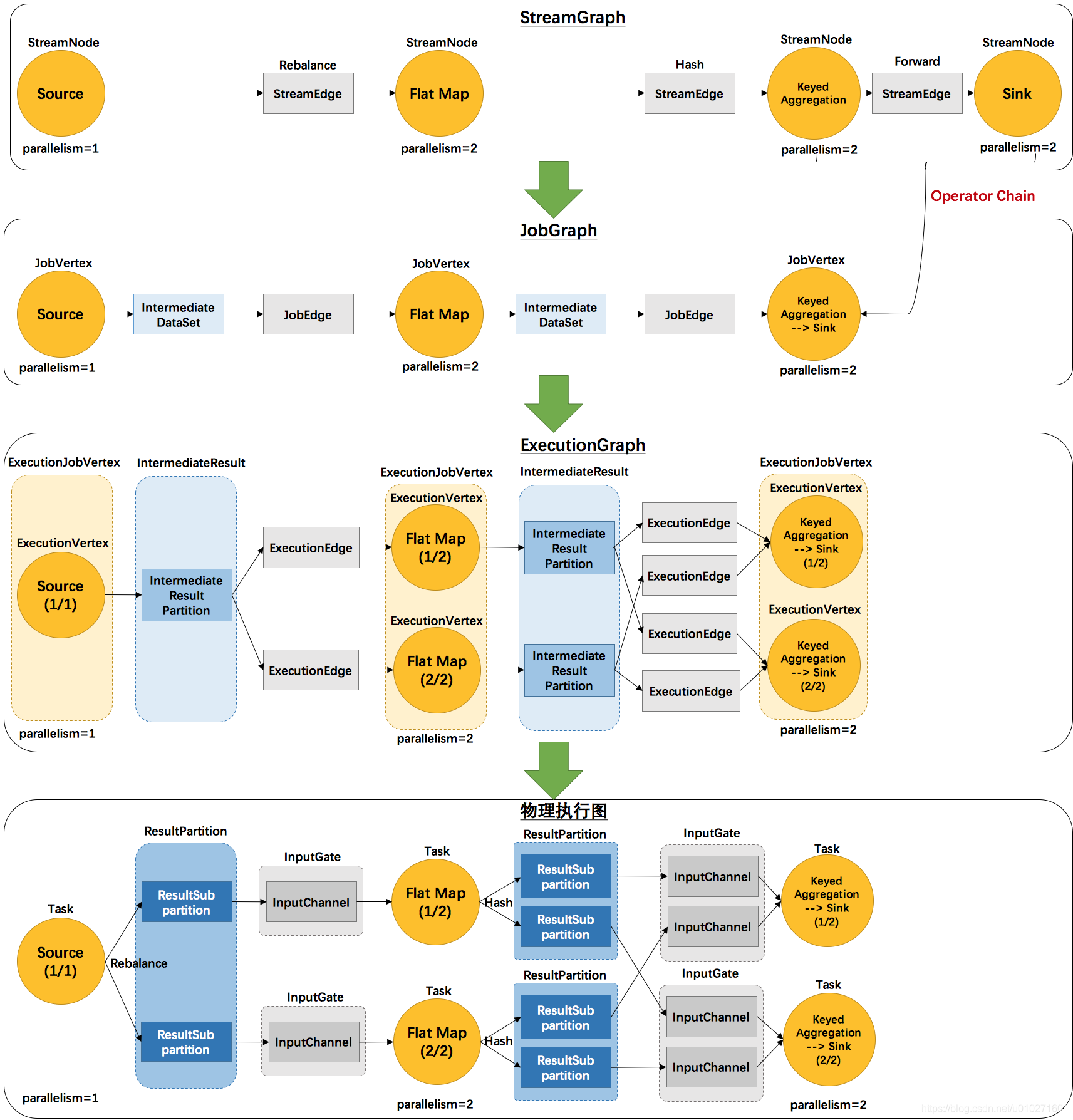
从 StreamGraph 转换到 JobGraph 需要进行 OperatorChain 操作,Chain 的过程就是将相连且只有单个输入源的 StreamNode 合并在一起,组成一个 JobVertex,JobVertex 根据连接的 StreamNode 源端创建。多个输入源的 StreamNode 会作为一个单独的 Vertex 创建成 JobVertex,同理,后面与其相连的单输入源的 StreamNode 会合并到该 JobVertex 里面。JobVertex 创建完后,每个 JobVertex 会通过 JobEdge 连接到一起。简单理解就是如果两个算子的数据是直接Forward,在同一个slot组并且并行度一致,那就可以合并。反过来,如果两个Operator之间有shuffle (比如keyBy)、rebalance (比如并行度不一样) 之类的操作,或者一个Operator有多个上游 (就是有多个operator), 那就不能合并。Chain 的过程中还会调用 OperatorFactory 创建相应的 OperatorCoordinator.Provider 并传递到 JobVertex 中。
JobGraph 创建完后,将提交 JobGraph 到 JobManager 上, 在 Application 模式中,这时需要高可用启动作业管理器 JobManager。JobManager 包含三大组件,资源管理器 (ResourceManager) 、调度器 (Dispatcher) 和相应作业对应的单个作业控制器(JobMaster)。
ResourceManager 将不断与 JobManager 保持通信,并处理 JobManager 的资源请求和分配处理 TaskManager。Dispatcher 负责分发向 JobManager 发送的各种请求、处理作业的提交、管理集群资源,以及协调其他组件的运行。JobMaster 在运行作业时拉起,与其他组件协作通信,负责相应的单个作业的调度、管理和容错。
JobManager 启动完成并接收到 JobGraph 后, 开始通过 JobGraph 创建 JobMaster 然后调度作业,JobMaster 创建过程中会创建重要的作业调度器 SchedulerNG,作业调度器包含作业调度需要的所有信息和策略,它在创建时会通过 JobGraph 创建和恢复作业执行图 ExecutionGraph。
作业执行图 ExecutionGraph 表示了作业的具体执行信息,它包括了具体的任务、任务之间的数据交换通道、部署信息以及与作业的执行相关的所有信息。ExecutionGraph 内部包含 ExecutionJobVertex,如果 ExecutionGraph 表示 JobGraph 执行时的信息,那么 ExecutionJobVertex 就表示 JobGraph 中 JobVertex 的执行节点,不过 ExecutionJobVertex 是并行数量个 JobVertex,它也代表着相关子任务的执行信息,相关的Coordinator 也会在 ExecutionJobVertex 创建时被创建 。
ExecutionGraph 的创建也代表作业需要执行,这时也会创建单次子任务的执行 Execution 以及对应的 ExecutionVertex ,Execution 表示子任务的执行操作,ExecutionVertex 表示子任务的执行信息,每一次任务的执行和重试都需要使用它们。如果开启了Checkpoint,ExecutionGraph 还需要创建状态相关组件以及初始化状态数据信息。
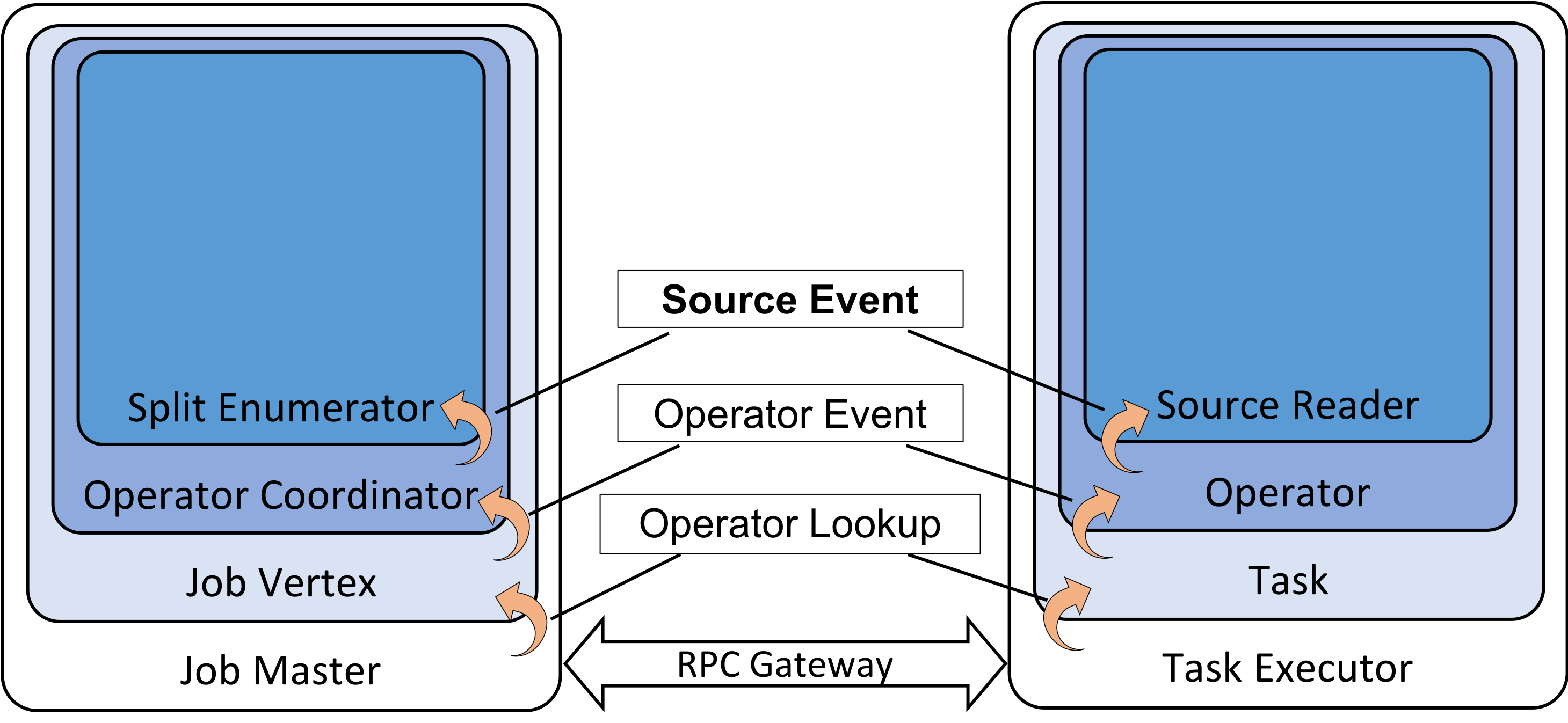
JobManager 调用 SchedulerNG 开始部署任务。作业的部署主要是需要部署所有的子任务,也就是 ExeuctionGraph 中所有的 Execution。不过在部署前,还会先会启动算子的 Coordinator,例如在 Source 端,SourceCoordinator 启动时会调用 Source 的 createEnumerator 方法创建并启动 SplitEnumerator,SplitEnumerator 启动一般用于监听 Split 的改变 ( Kafka Connector 中是使用 Topic Partition 表示 Split 的) 。
SchedulerNG 计算任务需要的资源也就是 Slot 数量,并向 ResourceManager 发送资源请求,ResourceManager 收到资源请求后,如果资源请求合理,则根据需要的 Slot 数量启动 TaskManager (TaskExecutor),TaskManager 启动完后,则将 TaskManager 资源信息发送给 SchedulerNG。
SchedulerNG 接收到资源信息后,调用所有子任务的执行 Execution 将任务部署到 TaskManager 相应的 Slot 上面,Execution 通过ExecutionVertex 获取任务部署描述符 TaskDeploymentDescriptor,然后将任务部署描述符发送给 TaskManager 部署任务。
TaskExecutor 接收到任务信息后创建 Task 启动任务,Task 使用 TaskDeploymentDescriptor 初始化配置并从 Blob 上下载相关的 Jar 包并创建相关的 ClassLoader,然后通过 ClassLoader 和 Configuration 反序列化创建运行时主任务 StreamTask,StreamTask 在创建时会创建 MailboxProcessor、SubtaskCheckpointCoordinator 等重要的组件,StreamTask 创建完后 Task 开始恢复 StreamTask。
StreamTask 的恢复会先创建算子链,算子链创建过程中会先主算子,以及其配置,然后从主算子配置中获取所有相关算子的配置 StreamConfig,再通过 StreamConfig 反序列创建之前 Vertex 中的所有算子工厂,并通过算子工厂创建算子,最后将算子连接起来成为算子链。算子创建过程中还会创建算子数据的输出端 StreamTaskInput 、 输入端 DataOutput 以及输入端处理器 StreamInputProcessor,StreamOneInputProcessor 将 StreamTaskInput 和 DataOutput 连接起来,用于将输入端的数据传输到输出端,是算子之间数据传输的桥梁。
算子链创建完后会先初始化主算子,如果主算子是 SourceOperator 算子,那么算子在初始化时会通过 Source 创建 SourceReader,并通知 SourceCoordinator 注册 SourceReader,然后启动 SourceReader。
**主算子初始化完后,开始恢复所有算子和网关的状态和打开所有算子。**这个过程 TaskManager 将通知 JobMaster 任务已经达到运行状态,JobMaster 开始定期执行 Checkpoint 任务,任务的 ResultPartitionWriter 和 InputGate 将读取任务状态管理器中 Channel 状态 ,InputGate 将会请求相关的子分区,算子将读取恢复 keyed 状态和算子状态, MailboxProcessor 这时也会启动直到状态恢复。
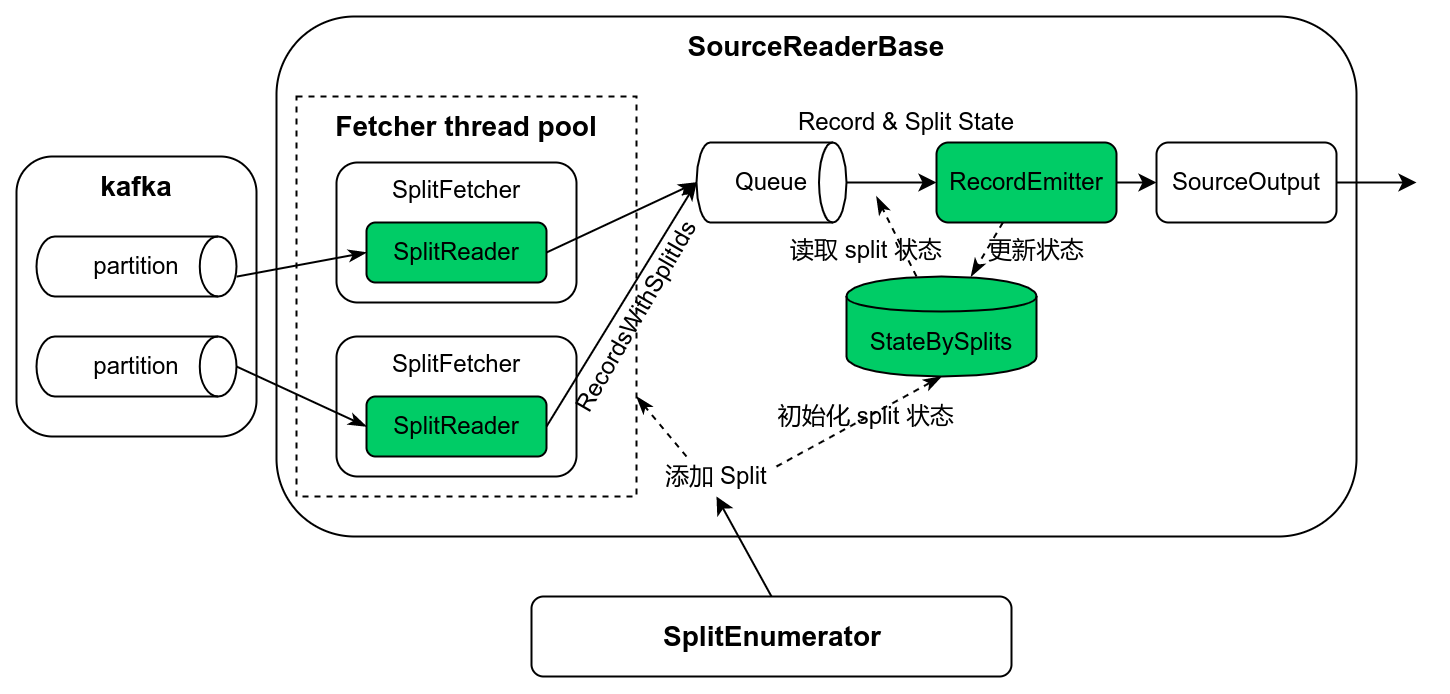
SourceOperator 打开时将会恢复相关的 Reader Split 并添加到 Reader 中,然后异步给 SourceCoordinator 发送 ReaderRegistrationEvent 事件,用于给子任务注册 SourceReader,随后开始启动 SourceReader (SourceReader#start)。
SourceCoordinator 接收到 ReaderRegistrationEvent 事件后, 调用 SplitEnumerator 给子任务添加 Reader,一般来说,SplitEnumerator 会在启动的时候获取 Split 并缓存,或者添加 Reader 时获取 Split, 然后通过 Split 创建 AddSplitEvent 事件,并给 SourceOperator 发送该事件。
SourceOperator 接受到 AddSplitEvent 后,SourceOperator 需要先使用 Source 通过 getSplitSerializer 创建的 SimpleVersionedSerializer,然后根据 splitId 创建 SourceOutput,随后将 Splits 添加到 Reader 中,最后如果是 SourceReaderBase,则 会调用 SplitFetcherManager 添加 Splits。
SplitFetcherManager 添加 Splits 时,将会创建 SplitReader,然后调用 SplitReader 创建 SplitFetcher,SplitFetch 调用 SplitFetcher 添加 Splits,然后启动 SplitFetcher,用于获取分片数据。
SplitFetcher 创建时也会创建一个"主任务" (FetchTask,用于获取数据) ,而且 SplitFetcher 内部会维护一个任务队列。SplitFetcherManager 给 SplitFetcher 添加 Splits 时,将会创建一个 AddSplitsTask 任务添加到 SplitFetcher 内部的任务队列中。
SplitFetcher 是一个单独的线程,启动后它循环执行内部任务队列中的任务,它将会首先执行队列中已经存在的任务,像前面 SplitFetcherManager 添加的 AddSplitsTask,如果队列中没有任务了,则会执行主任务 FetchTask 去获取数据。
SplitFetcher 的 FetchTask 任务被执行时,会调用 SplitReader 的 fetch 方法真正从 Source 中获取数据,获取后的数据将会与相应的数据 Splits 一起封装成 RecordsWithSplitIds,RecordsWithSplitIds 将会放入 SplitFetcherManager 维护的元素队列中。
SourceTask 恢复完后,开始启动 (SourceTask#invoke),也就是开始运行 MailboxProcessor,MailboxProcessor 会不断同步处理发送过来的 Mail,如果没有需要处理的 Mail, 那么会执行默认动作 (处理输入端数据) (StreamTask#processInput)。
处理输入端动作将会调用 StreamOneInputProcessor 让 StreamTaskInput 将数据发送给 DataOutput (PushingAsyncDataInput#emitNext)。
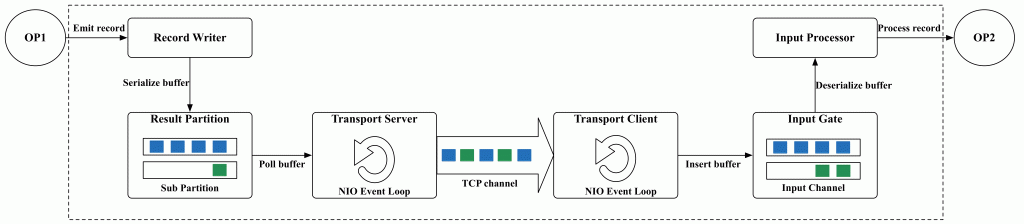
StreamTaskInput 调用内部的 SourceOperator 给 DataOutput 发送已收集的数据, SourceOperator 调用 SourceReader 轮询下一条可用记录到 DataOutput ,SourceReader 不断从 RecordsWithSplitIds 的所有 Split 中获取数据,并调用 RecordEmitter 将数据发送给DataOutput, 然后 DataOutput 将数据发送给下游算子 (SinkOperator#processElement 等),如果我们在 DAG 构建中使用 Partition (将数据分区)相关的操作,比如 DataStream 的 keyBy 或 rescale、SQL 中的 Group By,Flink 会引入一轮 Shuffle。
最后下游算子开始处理数据,这里使用 SinkWriterOperator 来说明,最后 SinkWriterOperator 在 processElement 方法中将调用我们自定义的 SinkWriter 来处理数据。
如果 RecordsWithSplitIds 中分片 Split 的所有数据都处理完成了,那么任务也会自己结束运行。
MailboxProcessor 中途可能会接受到 Checkpoint Mail,那么相关的算子也需要完成 Checkpoint 相关操作。
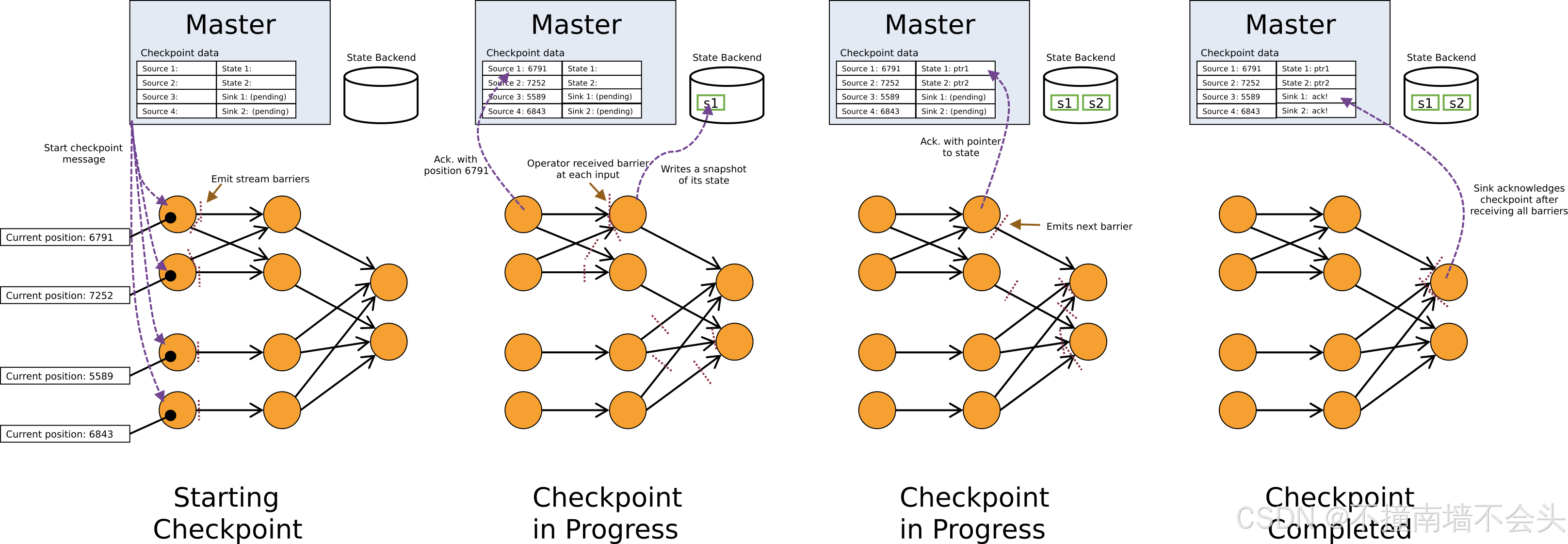
任务运行后 JobMaster 定时执行 Checkpoint,JobMaster 会通过调用 CheckpointCoordinator 对作业进行 Checkpoint。
CheckpointCoordinator 开始进行 Checkpoint,它首先会先创建 PendingCheckpoint,然后开始给 Checkpoint 计时,再关闭网关开始触发 OperatorCoordinator 的 Checkpoint。
如果是 SourceOperatorCoordinator,则这时会调用 Source 的 getSplitSerializer,获取分片序列化器,然后将 SplitAssignmentTracker 中任务运行时分配的分片序列化创建 Snapshot,再将 Snapshot 放入 PendingCheckpoint 中。
OperatorCoordinator 状态触发完后,开始触发 MasterHooks 状态快照,MasterTriggerRestoreHook 由 UDFStreamOperator 内部的实现 WithMasterCheckpointHook 接口的 Function 创建,用于在 Master 触发 Checkpoint 时,Function 需要进行的操作。
MasterHooks 调用完后,CheckpointCoordinator 将给子任务 TaskManager 发送请求,通知它们开始 Checkpoint。
TaskExecutor 获取相应的任务 Task,Task 调用 StreamTask 开始进行 Checkpoint,StreamTask 调用 Mailbox 执行 Checkpoint 事件,Mailbox 执行 Checkpoint 事件时, Source 将不会从数据源读取数据。
Checkpoint 事件开始执行,如果 Checkpoint 需要强制对齐,那么需要异步创建 Channel 和结果分区的数据快照, 随后在执行传播 Barrier 前,SubtaskCheckpointCoordinatorImpl 会调用 OperatorChain 让 Operator 进行 Barrier 前的准备操作,然后开始往下游传播 Barrier。
SubtaskCheckpointCoordinatorImpl 创建 CheckpointBarrier 并将 CheckpointBarrier 发送给 RecordWriterOutput 将 Barrier 传输给下游任务,然后注册 Barrier 对齐超时计时器。
Barrier 传播完后,如果 Checkpoint 需要 Channel 状态 ,那么还需要异步创建 Channel 和 结果分区的数据快照。
最后 SubtaskCheckpointCoordinatorImpl 开始对当前子任务的所有算子进行 Checkpoint,算子将会把状态存储到 OperatorStateBackend 和 KeyedStateBackend,然后 OperatorStateBackend 和 KeyedStateBackend 的状态快照,不过 Operator 的状态一般会存储在 StateSnapshotContext 中。
总的来说,Checkpoint 将创建托管键值状态、托管算子状态、未处理的键值状态、未处理的算子状态、输入通道状态和结果分区状态的快照。
下游任务这时是正常处理上游发送过来的数据的,但是上游正在进行 Checkpoint,数据也是被发送过来的 CheckpointBarrier 分割开了,处理到后面会接收到上游的 CheckpointBarrier,也就表示着当前 Checkpoint 上游快照数据已经处理完,下游也开始进行 Checkpoint 了,下游进行 Checkpoint 的过程也是和上面的一样,继续调用 SubtaskCheckpointCoordinatorImpl 开始进行 Checkpoint。