python进阶-05-利用Selenium来实现动态爬虫
一.说明
这是python进阶部分05,我们上一篇文章学习了Scrapy来爬取网站,但是很多网站需要登录才能爬取有用的信息,或者网站的静态部分是一个空壳,内容是js动态加载的,或者人机验证,请求拦截转发等,那么这种情况Scrapy来爬取就很费劲,有人说我们可以分析登录接口,js加载内容实现爬取我们需要的内容,哼哼你想多了,请求内容经过服务器转发给你加过包的!所以还是不行,那就没有办法来抓取我们想要的数据了么?
有,就是Selenium动态爬取网页信息,Selenium会启动和控制浏览器直接实现自动登录,Selenium直接运行在浏览器中从而可以直接爬取js加载完的信息。
那么Selenium这么强大有没有什么缺陷?也是有的,效率不高!
但省事啊,就跟Python一样!人生苦短,我用Python,好,继续开始我们的日拱一卒,让我们彻底掌握这一技术!。
二.安装
要使用Selenium,就得先安装,但是Selenium安装不仅仅需要安装Selenium python库,还要在python虚拟环境中安装对应的浏览器驱动!所以安装Selenium分别为 安装Selenium Python库 下载和安装浏览器及对应浏览器的驱动 。
-
下载Selenium库
bashpip install selenium -i http://pypi.doubanio.com/simple --trusted-host pypi.doubanio.com -
下载对应浏览器和驱动
-
Chrome的驱动chromedriver
bash#谷歌浏览器驱动官方 https://chromedriver.storage.googleapis.com/index.html # 谷歌浏览器官方开发者文档 # https://developer.chrome.com/docs/chromedriver/downloads?hl=zh-cn #谷歌浏览器历史版本下载 https://downzen.com/en/windows/google-chrome/versions/?page=1 #禁用谷歌浏览器更新,大家可看下面的文章,在此不进行重复说明 #chrome://version/ 查看浏览器版本和安装文件夹 https://blog.csdn.net/weixin_65228312/article/details/141724054
通过测试发现chromedriver下载的均为支持最新版本的谷歌浏览器,大家安装最新浏览器即可!
如果驱动不支持 会提示您应该安装的浏览器版本,安装指定浏览器版本,和禁用浏览器更新即可。
-
Firefox的驱动geckodriver下载地址
bashhttps://github.com/mozilla/geckodriver/releases/
-
IE/微软Edge的驱动IEdriver下载地址
bashhttps://www.nuget.org/packages/Selenium.WebDriver.IEDriver/
-
-
为了帮助大家快速理解,我已经准备了一套Firefox浏览器和对应驱动geckodriver,一套谷歌131版本的浏览器驱动,在我的资源里面,大家可以直接下,下载地址如下
bash#Firefox的驱动geckodriver https://download.csdn.net/download/Lookontime/90059540 #Chrome的驱动chromedriver https://download.csdn.net/download/Lookontime/90091812 -
如何安装,浏览器直接安装,
geckodriver.exe驱动文件放到 我们的虚拟python环境的Scripts中即可bash#直接复制到虚拟环境 Scripts中即可,如果没有装虚拟环境的小伙 直接将驱动放到python跟目录下 F:\python_demo_07\my_venv\Scripts
三.启动selenium驱动浏览器的方法
-
启动谷歌浏览器来爬取内容
pythonfrom selenium import webdriver from selenium.webdriver.common.keys import Keys #提供键盘按键的支持,如回车键 RETURN browser = webdriver.Chrome(executable_path="F:/python_demo_07/my_venv/Scripts/chromedriver.exe") browser.get('http://www.myurlhub.com') elem = browser.find_element_by_name("q") #获取节点 elem.clear() #清除搜索框中的默认文本 elem.send_keys("pycon") #输入 "pycon" elem.send_keys(Keys.RETURN) #模拟按下键盘的回车键 RETURN,触发搜索 assert "No results found." not in driver.page_source #断言页面标题中包含 "Python"。如果不包含,则抛出异常 browser.close() #关闭浏览器窗口 -
启动Firefox
pythonfrom selenium import webdriver browser = webdriver.Firefox(executable_path="F:/python_demo_07/my_venv/Scripts/geckodriver.exe") browser.get('http://www.myurlhub.com') -
启动IE(不推荐 古老项目可能需要吧)
pythonfrom selenium import webdriver browser = webdriver.Ie(executable_path="F:/python_demo_07/my_venv/Scripts/IEDriver .exe") browser.get('http://www.myurlhub.com')
四.selenium的详细用法
4.1 声明浏览器对象
python
from selenium import webdriver
browser = webdriver.Chrome()
browser = webdriver.Firefox()
browser = webdriver.Safari()
browser = webdriver.Edge()
browser = webdriver.PhantomJS()4.2 访问页面
python
from selenium import webdriver
browser = webdriver.Chrome(executable_path="F:/python_demo_07/my_venv/Scripts/chromedriver.exe")
browser.get('http://www.myurlhub.com')
print(browser.page_source) #打印页面源代码
browser.close() #关闭浏览器窗口4.3 查找单个元素
python
from selenium import webdriver
from selenium.webdriver.common.by import By #
browser = webdriver.Chrome(executable_path="F:/python_demo_07/my_venv/Scripts/chromedriver.exe")
browser.get('http://www.myurlhub.com')
# 1. 根据 ID 查找元素
element_by_id = browser.find_element(By.ID, "element_id")
element_by_id = browser.find_element_by_id("element_id")
# 2. 根据 name 属性查找元素
element_by_name = browser.find_element(By.NAME, "element_name")
# 3. 根据 class 名称查找元素
element_by_class_name = browser.find_element(By.CLASS_NAME, "class_name")
element_by_class_name = browser.find_element_by_css_selector("#class_name")
# 4. 根据标签名查找元素
element_by_tag_name = browser.find_element(By.TAG_NAME, "tag_name")
# 5. 使用 CSS 选择器查找元素
element_by_css = browser.find_element(By.CSS_SELECTOR, ".class_name #element_id")
# 6. 使用 XPath 查找元素
element_by_xpath = browser.find_element(By.XPATH, "//div[@class='class_name']")
browser.close() #关闭浏览器窗口4.4 查找多个元素
python
from selenium import webdriver
from selenium.webdriver.common.by import By
# 启动 Chrome 浏览器
browser = webdriver.Chrome(executable_path="F:/python_demo_07/my_venv/Scripts/chromedriver.exe")
# 打开指定网址
browser.get('http://www.myurlhub.com')
# 1. 根据 class 名查找多个元素
elements_by_class_name = browser.find_elements(By.CLASS_NAME, "class_name")
element_by_class_name = browser.find_element_by_css_selector("#class_name")
# 2. 根据标签名查找多个元素
elements_by_tag_name = browser.find_elements(By.TAG_NAME, "tag_name")
# 3. 使用 CSS 选择器查找多个元素
elements_by_css = browser.find_elements(By.CSS_SELECTOR, ".class_name #element_id")
# 4. 使用 XPath 查找多个元素
elements_by_xpath = browser.find_elements(By.XPATH, "//div[@class='class_name']")
# 输出查找到的元素个数
print(f"找到 {len(elements_by_class_name)} 个元素")4.5元素的交互操作
python
from selenium import webdriver
from selenium.webdriver.common.by import By
# 启动 Chrome 浏览器
browser = webdriver.Chrome(executable_path="F:/python_demo_07/my_venv/Scripts/chromedriver.exe")
# 打开指定网址
browser.get('http://www.myurlhub.com')
#点击按钮
button = browser.find_element(By.ID, "submit_button")
button.click() # 点击按钮
#输入文本
input_box = browser.find_element(By.NAME, "username")
input_box.send_keys("my_username") # 输入文本
#清除文本框内容
input_box.clear() # 清空输入框
#获取元素文本
paragraph = browser.find_element(By.TAG_NAME, "p")
print(paragraph.text) # 输出段落的文本内容
#获取元素属性
link = browser.find_element(By.LINK_TEXT, "Python")
href = link.get_attribute("href") # 获取链接的 href 属性
print(href)
#提交表单
form = browser.find_element(By.ID, "search_form")
form.submit() # 提交表单
#悬停操作
from selenium.webdriver.common.action_chains import ActionChains #引入动作链
element = browser.find_element(By.ID, "hover_element")
actions = ActionChains(browser)
actions.move_to_element(element).perform() # 悬停在元素上
#拖放操作
source = browser.find_element(By.ID, "drag_source")
target = browser.find_element(By.ID, "drop_target")
actions = ActionChains(browser)
actions.drag_and_drop(source, target).perform() # 拖放操作
#键盘操作
from selenium.webdriver.common.keys import Keys
input_box = browser.find_element(By.NAME, "query")
input_box.send_keys("selenium" + Keys.ENTER) # 输入文本并回车
#切换到 iframe
iframe = browser.find_element(By.TAG_NAME, "iframe")
browser.switch_to.frame(iframe) # 切换到 iframe4.6 执行JavaScript 脚本
python
#执行简单 JavaScript 脚本
browser.execute_script("alert('Hello from Selenium!');")
#操作 DOM 元素
element = browser.find_element(By.ID, "my_element")
browser.execute_script("arguments[0].style.backgroundColor = 'yellow';", element)
#获取js执行结果
title = browser.execute_script("return document.title;")
print(title) # 输出页面标题
#滚动页面
# 滚动到页面底部
browser.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# 滚动到特定元素
element = browser.find_element(By.ID, "target_element")
browser.execute_script("arguments[0].scrollIntoView(true);", element)
#添加动态内容
browser.execute_script("document.body.innerHTML += '<p>Added by Selenium</p>';")
#处理窗口大小和位置
# 调整窗口大小
browser.execute_script("window.resizeTo(1024, 768);")
# 获取窗口位置
position = browser.execute_script("return window.screenX, window.screenY;")
print(position)4.7 获取元素信息
python
element = browser.find_element(By.ID, "my_element")
print(element.text) # 输出元素的文本内容
element = browser.find_element(By.NAME, "username")
value = element.get_attribute("value") # 获取输入框的值
print(value)
href = element.get_attribute("href") # 获取链接的 href 属性
print(href)
element = browser.find_element(By.CLASS_NAME, "button")
color = element.value_of_css_property("color") # 获取按钮的文字颜色
print(color)
element = browser.find_element(By.ID, "my_element")
print(element.tag_name) # 输出标签名,如 'div'、'input'
element = browser.find_element(By.ID, "my_element")
print(element.size) # 输出元素的宽度和高度 {'width': 100, 'height': 50}
print(element.location) # 输出元素的位置 {'x': 50, 'y': 100}
element = browser.find_element(By.ID, "my_element")
print(element.is_displayed()) # 检查元素是否可见
print(element.is_enabled()) # 检查元素是否启用
print(element.is_selected()) # 检查复选框或单选按钮是否选中
element = browser.find_element(By.ID, "my_element")
print(element.is_displayed()) # 检查元素是否可见
print(element.is_enabled()) # 检查元素是否启用
print(element.is_selected()) # 检查复选框或单选按钮是否选中
element = browser.find_element(By.ID, "my_element")
print(element.get_attribute("outerHTML")) # 输出元素的完整 HTML
print(element.get_attribute("innerHTML")) # 输出元素内部的 HTML4.8 等待
等待的目的是确保操作的元素已经出现在页面上,避免因加载延迟导致的异常,Selenium 中等待分为隐式等待和显式等待
4.8.1 隐式等待
对整个 WebDriver 会话生效,隐式等待会在查找元素时,等待一定的时间。如果在超时时间内找到了元素,就继续执行;如果超时,抛出 NoSuchElementException
python
from selenium import webdriver
browser = webdriver.Chrome()
browser.implicitly_wait(10) # 设置隐式等待时间为10秒
browser.get("http://example.com")
element = browser.find_element(By.ID, "my_element") # 如果元素在10秒内加载完成,立即返回4.8.2 显式等待
显式等待会针对特定条件或特定元素等待指定时间。可以结合条件使用,比如等待元素可见、可点击等。
Selenium 提供了一些常见的等待条件,配合显式等待使用:
presence_of_element_located: 等待元素出现在 DOM 中,但不一定可见。visibility_of_element_located: 等待元素出现在 DOM 中并可见。element_to_be_clickable: 等待元素可以被点击。text_to_be_present_in_element: 等待某元素的文本出现。alert_is_present: 等待弹窗出现。
python
#等待元素点击
from selenium.webdriver.common.by import By
from selenium.webdriver.common.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.Chrome()
browser.get("http://example.com")
# 等待最多10秒,直到元素可被点击
element = WebDriverWait(browser, 10).until(
EC.element_to_be_clickable((By.ID, "my_element"))
)
element.click() # 点击元素
#等待元素可见
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
# 等待元素可见,最多 10 秒
element = WebDriverWait(browser, 10).until(
EC.visibility_of_element_located((By.CLASS_NAME, "visible-element"))
)
element2 = WebDriverWait(self.driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'p img'))
)
print(element.text) # 输出元素文本
#等待文本出现在元素中,等待元素中出现特定文本 "Success"。
element = WebDriverWait(browser, 10).until(
EC.text_to_be_present_in_element((By.ID, "status"), "Success")
)
print("Text found!")
#等待多个元素加载完成
elements = WebDriverWait(browser, 10).until(
EC.presence_of_all_elements_located((By.TAG_NAME, "li"))
)
for element in elements:
print(element.text)
#等待按钮变为可点击状态
button = WebDriverWait(browser, 10).until(
EC.element_to_be_clickable((By.CSS_SELECTOR, ".submit-button"))
)
button.click() # 点击按钮
#等待 iframe 可切换
iframe = WebDriverWait(browser, 10).until(
EC.frame_to_be_available_and_switch_to_it((By.TAG_NAME, "iframe"))
)
print("Switched to iframe")
iframe = WebDriverWait(browser, 10).until(
EC.frame_to_be_available_and_switch_to_it((By.TAG_NAME, "iframe"))
)
print("Switched to iframe")
# 等待 alert 弹窗出现
alert = WebDriverWait(browser, 10).until(EC.alert_is_present())
alert.accept() # 接受 alert 弹窗
#等待元素属性变化 等待元素的 class 属性变为 "completed"。
element = browser.find_element(By.ID, "progress")
WebDriverWait(browser, 10).until(
lambda driver: element.get_attribute("class") == "completed"
)
print("Progress completed!")
#等待页面标题变更
WebDriverWait(browser, 10).until(EC.title_contains("Dashboard"))
print("Page loaded with expected title!")
#等待特定元素不可见
WebDriverWait(browser, 10).until(
EC.invisibility_of_element_located((By.ID, "loading-spinner"))
)
print("Spinner disappeared!")
#等待文件下载完成(JavaScript 控制按钮触发下载)点击下载按钮后,通过检查页面的 cookie 确认文件下载完成。
download_button = WebDriverWait(browser, 10).until(
EC.element_to_be_clickable((By.ID, "download-btn"))
)
download_button.click()
WebDriverWait(browser, 20).until(
lambda driver: "file_downloaded=true" in driver.execute_script("return document.cookie")
)
print("File download completed!")4.9 浏览器的前进和后退,刷新等操作
python
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 打开两个页面
browser.get("https://www.example.com")
time.sleep(2) # 等待页面加载
browser.get("https://www.google.com")
time.sleep(2)
# 后退到第一个页面
browser.back()
print("后退到:", browser.current_url)
# 前进到第二个页面
browser.forward()
print("前进到:", browser.current_url)
# 刷新页面
browser.refresh()
print("页面已刷新")4.10 cookies处理(了解即可 selenium 不需要操作cookies)
python
from selenium import webdriver
browser = webdriver.Chrome()
# 打开网站
browser.get("https://www.example.com")
# 添加 Cookie
browser.add_cookie({"name": "my_cookie", "value": "cookie_value"})
# 获取所有 Cookies
print("所有 Cookies:", browser.get_cookies())
# 获取指定 Cookie
print("单个 Cookie:", browser.get_cookie("my_cookie"))
# 删除指定 Cookie
browser.delete_cookie("my_cookie")
# 删除所有 Cookies
browser.delete_all_cookies()
# 刷新页面以使添加和删除cookie 生效
browser.refresh()
browser.quit()4.11 JWT令牌处理(了解即可 selenium 不需要操作JWT 和发送请求)
python
#方式一
from selenium import webdriver
from selenium.webdriver.common.by import By
# 初始化浏览器
browser = webdriver.Chrome()
# 打开目标页面(需与 JWT 的域匹配)
browser.get("https://www.example.com")
# 添加 JWT 令牌到 Cookie
jwt_token = "your_jwt_token_here"
browser.add_cookie({
"name": "Authorization", # 一般服务端会使用这个名称,但请根据具体情况修改
"value": f"Bearer {jwt_token}",
"domain": "www.example.com", # 确保域名与当前页面匹配
"path": "/"
})
# 刷新页面或访问需要 JWT 身份验证的页面
browser.refresh()
# 验证是否登录成功
print("Current URL:", browser.current_url)
#方式二
browser.execute_script("""
fetch('https://www.example.com/protected', {
method: 'GET',
headers: {
'Authorization': 'Bearer your_jwt_token_here'
}
}).then(response => response.json()).then(data => console.log(data));
""")4.12 切换页面操作
python
#页面切换
from selenium import webdriver
import time
browser = webdriver.Chrome()
# 打开第一个页面
browser.get("https://www.example.com")
print("当前窗口句柄:", browser.current_window_handle)
# 打开新标签页
browser.execute_script("window.open('https://www.google.com');")
time.sleep(2) # 等待页面加载
# 获取所有窗口句柄
handles = browser.window_handles
print("所有窗口句柄:", handles)
# 切换到新标签页(第二个窗口)
browser.switch_to.window(handles[1])
print("当前窗口句柄:", browser.current_window_handle)
print("当前页面 URL:", browser.current_url)
# 切换回第一个窗口
browser.switch_to.window(handles[0])
print("当前窗口句柄:", browser.current_window_handle)
print("当前页面 URL:", browser.current_url)
browser.quit()
python
#iframe 切换
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://www.example.com")
# 切换到 iframe
iframe = browser.find_element_by_tag_name("iframe")
browser.switch_to.frame(iframe)
# 在 iframe 内部执行操作
element = browser.find_element_by_id("inner_element")
element.click()
# 切换回主页面
browser.switch_to.default_content()
# 继续在主页面操作
browser.quit()五.案例一 爬取翻译内容(技术文章仅用于学习与研究目的,不得用于违法行为,如需要翻译接口请购买正版翻译接口)
别看百度翻译很简单,其实我们直接Requests百度翻译或者Scrapy 会发现当字符超过一定长度,就无法获取结果,因为页面结果是js动态生成的!
针对这种情况,就需要分析页面结构,隐藏接口等情况,才能爬取,且翻译的字符超过一定数量接口就会改变,导致我们在做百度翻译,失败!
但是现在不同的!这时候就适合用selenium技术!不用哪些花里胡哨的的操作!
但是利用selenium技术,爬取页面内容会很慢,如需翻译接口,请购买百度翻译接口,本文主要是用来解释selenium技术。
1.开发环境
python 3.6.8
火狐浏览器:65.0.2 (64 位)
#Firefox的驱动geckodriver
1.我们新建一个FastAPI接口,创建和启用FastAPI接口,看我的这篇文章:
https://blog.csdn.net/Lookontime/article/details/1436966292.在项目文件夹中创建main.py 代码如下
python
#main.py
from fastapi import FastAPI
from api.crawler import fanyi
app = FastAPI()
# 包含用户相关的所有路由
app.include_router(fanyi.router, prefix="/crawler", tags=["CrawlerAPI"])3.创建api文件夹 用作FastAPI路由
api文件夹下新建:__init__.py 文件 及crawler文件夹,其中__init__.py无任何内容
crawler文件夹下新建:fanyi.py和params.py 文件
代码如下:
params.py 文件
python
#params.py
from pydantic import BaseModel
from typing import List, Optional
class FanyiParams(BaseModel):
query: str
lang: str = 'en2zh'
ext_channel: str = 'DuSearch'fanyi.py文件
python
#fanyi.py
from fastapi import APIRouter, HTTPException
from selenium import webdriver
from .params import *
#确保页面加载完成,避免异步调用导致异常
from selenium import webdriver
from selenium.webdriver.firefox.options import Options
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
router = APIRouter()
@router.post("/baidu_fanyi")
def baidu_fanyi(params:FanyiParams):
try:
# 设置 Firefox 的无头模式
options = Options()
options.headless = True # 启用无头模式,避免打开实际浏览器
browser = webdriver.Firefox(executable_path="F:/python_demo_07/my_venv/Scripts/geckodriver.exe", options=options)
browser.get(f'https://fanyi.baidu.com/mtpe-individual/multimodal?query={params.query}&lang={params.lang}&ext_channel={params.ext_channel}')
# 等待页面中某个元素加载完成
WebDriverWait(browser, 10).until(
EC.presence_of_element_located((By.ID, 'trans-selection'))
)
fanyi = browser.find_element(By.ID, "trans-selection")
fanyi_text = fanyi.text
print("翻译结果",fanyi_text)
browser.close()
# html = browser.page_source # 获取完整 HTML 内容
return fanyi_text
except Exception as e:
print(f"发生错误: {e}")
return {"error": "无法获取翻译结果"}4.启动FastAPI
bash
(my_venv) PS F:\python_demo_07> uvicorn main:app --port 8082但是很抱歉截止文章发布前,这种原生的selenium应用已经无法爬取翻译内容了
5.升级selenium
开发环境,这次我们用谷歌浏览器
python 3.12.6
谷歌浏览器:131.0.6778.109
#Chrome的驱动chromedriver
https://download.csdn.net/download/Lookontime/90091812
插件:undetected_chromedriver
pip install undetected_chromedriver -i http://pypi.doubanio.com/simple --trusted-host pypi.doubanio.com
因为selenium很容易被检测到是selenium驱动的浏览器,所以我们需要让浏览器检测不到
代码替换如下:
python
from fastapi import APIRouter, HTTPException
from .params import *
#确保页面加载完成,避免异步调用导致异常
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
router = APIRouter()
@router.post("/baidu_fanyi")
def baidu_fanyi(params:FanyiParams):
try:
# 设置 无头模式
options = uc.ChromeOptions()
# 添加无头模式选项
options.add_argument('--headless')
# 添加其他必要参数
options.add_argument('--disable-gpu') # 禁用 GPU
options.add_argument('--no-sandbox') # 避免沙盒模式问题(可选)
options.add_argument('--disable-dev-shm-usage') # 防止共享内存问题(可选)
options.add_argument('--window-size=1920,1080') # 设置窗口大小
options.add_argument('--disable-blink-features=AutomationControlled') # 禁用自动化控制检测
browser = uc.Chrome(
executable_path="F:/开发源码/python_demo_07/my_venv_3_12_6/Scripts/chromedriver.exe",
options=options
)
browser.get(f'https://fanyi.baidu.com/mtpe-individual/multimodal?query={params.query}&lang={params.lang}&ext_channel={params.ext_channel}')
# 等待页面中某个元素加载完成
WebDriverWait(browser, 10).until(
EC.presence_of_element_located((By.ID, 'trans-selection'))
)
fanyi = browser.find_element(By.ID, "trans-selection")
fanyi_text = fanyi.text
print("翻译结果",fanyi_text)
browser.close()
# html = browser.page_source # 获取完整 HTML 内容
return fanyi_text
except Exception as e:
print(f"发生错误: {e}")
return {"error": "无法获取翻译结果"}ok这次我们又可以了
六.案例二 利用selenium技术爬取壁纸(技术文章仅用于学习与研究目的,不得用于违法行为,如需要壁纸请购买)
这次我们测试selenium技术的壁纸网站是https://pic.netbian.com/new/ 我看很多大佬已经拿这个网站实验过了,但是现在想爬这个网站是有点难度了,因为网站加了一个人机验证,我们通过selenium会被认为是机器人,就拒绝我们访问!如果用Scrapy 那更不行了。。。好!看我们搞定!
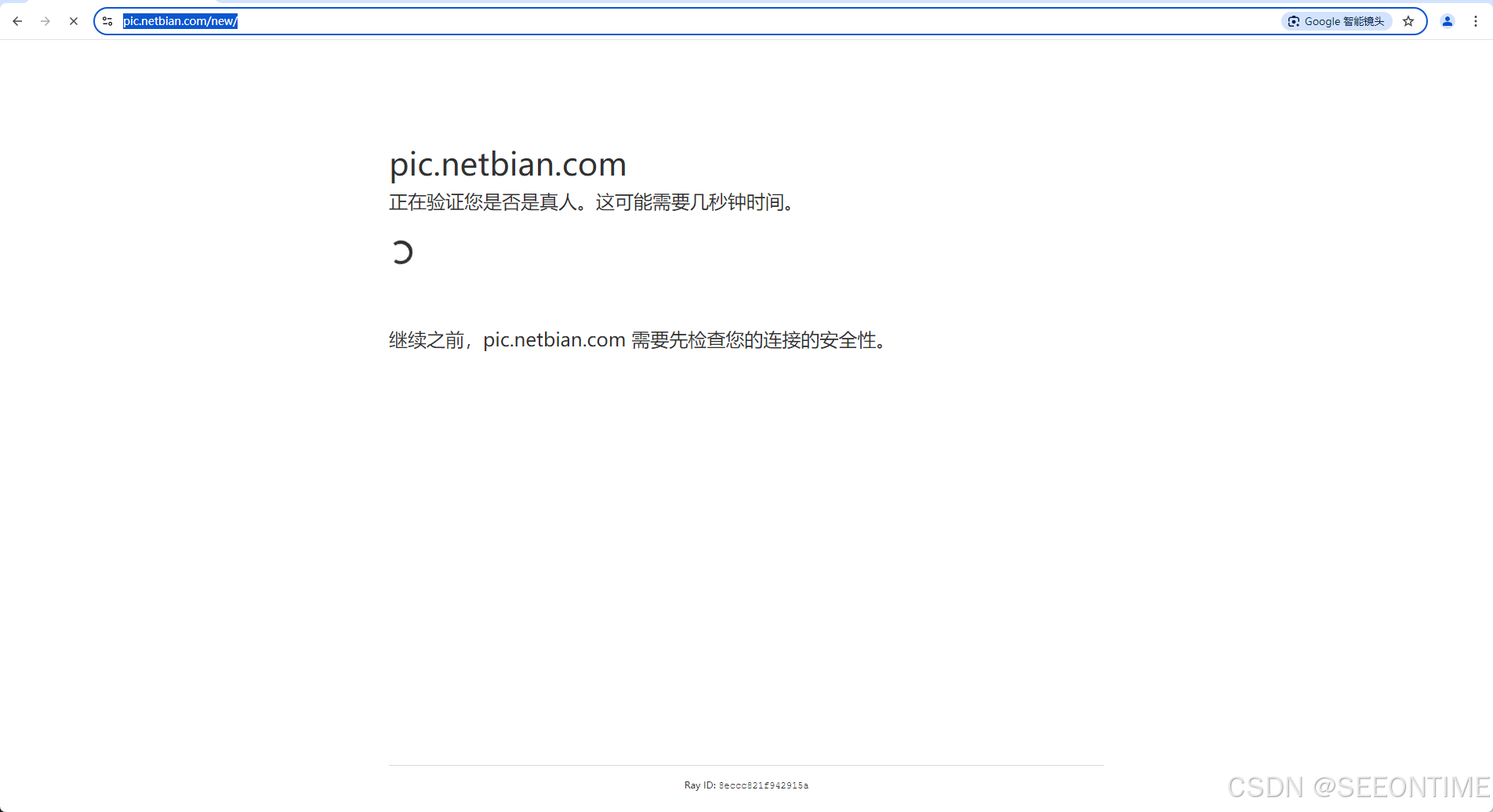
6.1开发环境
python 3.12.6
谷歌浏览器:131.0.6778.109
#Chrome的驱动chromedriver
https://download.csdn.net/download/Lookontime/90091812
插件:undetected_chromedriver
pip install undetected_chromedriver -i http://pypi.doubanio.com/simple --trusted-host pypi.doubanio.com
6.2修改params.py 文件
python
#params.py文件
from pydantic import BaseModel
from typing import List, Optional
class FanyiParams(BaseModel):
query: str
lang: str = 'en2zh'
ext_channel: str = 'DuSearch'
# lang: Optional[str] = 'zh2en'
# ext_channel: Optional[str] = 'DuSearch'
class BiziParams(BaseModel):
keyboard: str6.3新增servers类库
- 在主目录在新增servers文件夹
- servers文件夹下新增
__init__.py文件内容为空 - servers文件夹下新增seleniumHelper文件夹
- seleniumHelper文件夹 新增
index.py文件
python
#index.py
import base64
from io import BytesIO
import os
from pathlib import Path
import re
import time
from PIL import Image
#确保页面加载完成,避免异步调用导致异常
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
class seleniumInit:
def __init__(self):
options = uc.ChromeOptions()
options.add_argument('--disable-gpu')
self.driver = uc.Chrome(
executable_path="F:/开发源码/python_demo_07/my_venv_3_12_6/Scripts/chromedriver.exe",
options=options
)
self.keyboard = None
def start_requests(self,keyboard='手机'):
self.keyboard = keyboard
# 初始页面只需要加载一次并输入关键词
url = "https://pic.netbian.com/new/"
self.driver.get(url)
WebDriverWait(self.driver, 10).until(
EC.presence_of_element_located((By.NAME, 'keyboard'))
)
input_box = self.driver.find_element(By.NAME, "keyboard")
input_box.clear()
input_box.send_keys(keyboard + Keys.RETURN)
# 等待页面跳转到搜索结果页
WebDriverWait(self.driver, 10).until(
EC.presence_of_element_located((By.CLASS_NAME, 'nextpage'))
)
# 从搜索结果开始解析
self.parse_with_selenium(self.driver.current_url)
def parse_with_selenium(self, url):
self.driver.get(url)
WebDriverWait(self.driver, 10).until(
EC.presence_of_element_located((By.XPATH, "//a[@target='_blank']"))
)
next_page_element = self.driver.find_element(By.XPATH, "//li[@class='nextpage']/a")
next_page_href = next_page_element.get_attribute('href')
a_list = self.driver.find_elements(By.XPATH, "//a[@target='_blank']")
hrefs = [a.get_attribute('href') for a in a_list if a.get_attribute('href')]
for href in hrefs:
if href.startswith('https://pic.netbian.com/tupian'):
print(f"发现链接: {href}")
self.get_img(href)
# 处理下一页
try:
if next_page_href:
self.parse_with_selenium(next_page_href)
except Exception:
print("没有下一页")
def get_img(self, url):
self.driver.get(url)
WebDriverWait(self.driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, 'a#img img'))
)
img_element = self.driver.find_element(By.CSS_SELECTOR, 'a#img img')
img_src = img_element.get_attribute('src')
if img_src:
# 确保 URL 是完整的
img_url = img_src if img_src.startswith('http') else f"https://pic.netbian.com{img_src}"
print('准备下载图片:', img_url)
# 下载并保存图片
# 设置保存图片的文件夹路径
save_folder = f"F:/ImageFiles/{self.keyboard}/" # 你可以根据需要修改这个路径
if not os.path.exists(save_folder):
os.makedirs(save_folder) # 如果文件夹不存在,则创建
# 合成完整的文件路径
file_name = img_url.split('/')[-1]
file_path = os.path.join(save_folder, file_name)
js = "let c = document.createElement('canvas');let ctx = c.getContext('2d');" \
"let img = document.querySelector('a#img img'); /*找到图片*/ " \
"c.height=img.naturalHeight;c.width=img.naturalWidth;" \
"ctx.drawImage(img, 0, 0,img.naturalWidth, img.naturalHeight);" \
"let base64String = c.toDataURL();return base64String;"
base64_str = self.driver.execute_script(js)
img = self.base64_to_image(base64_str)
print("最终img",img)
# 转换为RGB模式(如果是RGBA)
if img.mode == 'RGBA':
img = img.convert('RGB')
img.save(file_path, format='JPEG')
time.sleep(6)
print(f'图片已保存: {file_name}')
def base64_to_image(self,base64_str):
base64_data = re.sub('^data:image/.+;base64,', '', base64_str)
byte_data = base64.b64decode(base64_data)
image_data = BytesIO(byte_data)
img = Image.open(image_data)
return img6.4 修改fanyi.py文件添加一个接口
python
#fanyi.py
from fastapi import APIRouter, HTTPException
from .params import *
#确保页面加载完成,避免异步调用导致异常
import undetected_chromedriver as uc
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from servers.seleniumHelper.index import seleniumInit
router = APIRouter()
@router.post("/baidu_fanyi")
def baidu_fanyi(params:FanyiParams):
try:
# 设置 无头模式
options = uc.ChromeOptions()
# 添加无头模式选项
options.add_argument('--headless')
# 添加其他必要参数
options.add_argument('--disable-gpu') # 禁用 GPU
options.add_argument('--no-sandbox') # 避免沙盒模式问题(可选)
options.add_argument('--disable-dev-shm-usage') # 防止共享内存问题(可选)
options.add_argument('--window-size=1920,1080') # 设置窗口大小
options.add_argument('--disable-blink-features=AutomationControlled') # 禁用自动化控制检测
browser = uc.Chrome(
executable_path="F:/开发源码/python_demo_07/my_venv_3_12_6/Scripts/chromedriver.exe",
options=options
)
browser.get(f'https://fanyi.baidu.com/mtpe-individual/multimodal?query={params.query}&lang={params.lang}&ext_channel={params.ext_channel}')
# 等待页面中某个元素加载完成
WebDriverWait(browser, 10).until(
EC.presence_of_element_located((By.ID, 'trans-selection'))
)
fanyi = browser.find_element(By.ID, "trans-selection")
fanyi_text = fanyi.text
print("翻译结果",fanyi_text)
browser.close()
# html = browser.page_source # 获取完整 HTML 内容
return fanyi_text
except Exception as e:
print(f"发生错误: {e}")
return {"error": "无法获取翻译结果"}
# 2.爬取壁纸
@router.post("/iciba_fanyi")
def iciba_fanyi(params:BiziParams):
sInit = seleniumInit()
sInit.start_requests(params.keyboard)
return "爬取完成"总结下这个网站我是看csdn上有个大佬爬过,所以我也就试试用来测试技术,技术文章仅用于学习与研究目的,不得用于违法行为,如需要壁纸请购买,支持正版,而且正版的壁纸清晰度很高,这部分不能是爬取到的。
但是发现这个网站加了机器人 加了图片请求转换,等待,所以开发的思路就是不能用原生selenium,否则机器人检测我们过不去,等我们千辛万苦绕过机器人时,发现请求图片被后端进行转换了并不能给你图片信息,这个时候就需要用js来实现复制图片。
代码地址:
bash
https://download.csdn.net/download/Lookontime/90097745七.总结
Python 进阶中的selenium就介绍到这里,再次声明文章只是为了研究selenium技术。
创作整理不易,请大家多多关注 多多点赞,有写的不对的地方欢迎大家补充,我来整理,再次感谢!