大家好啊!我是NiJiMingCheng
我的博客:NiJiMingCheng
上一节我们分享了安装selenium的内容,这一节我们继续来实战,这一节我们主要学习爬取上海软科中国大学排名并存入表格,本文仅以办学层次进行演示,其他数据同理可得,加油
Selenium 各浏览器驱动下载与配置使用(详细流程)
目录
[(五)if name == "main"(主运行函数)部分](#(五)if name == "main"(主运行函数)部分)
结果展示(文末附完整代码):
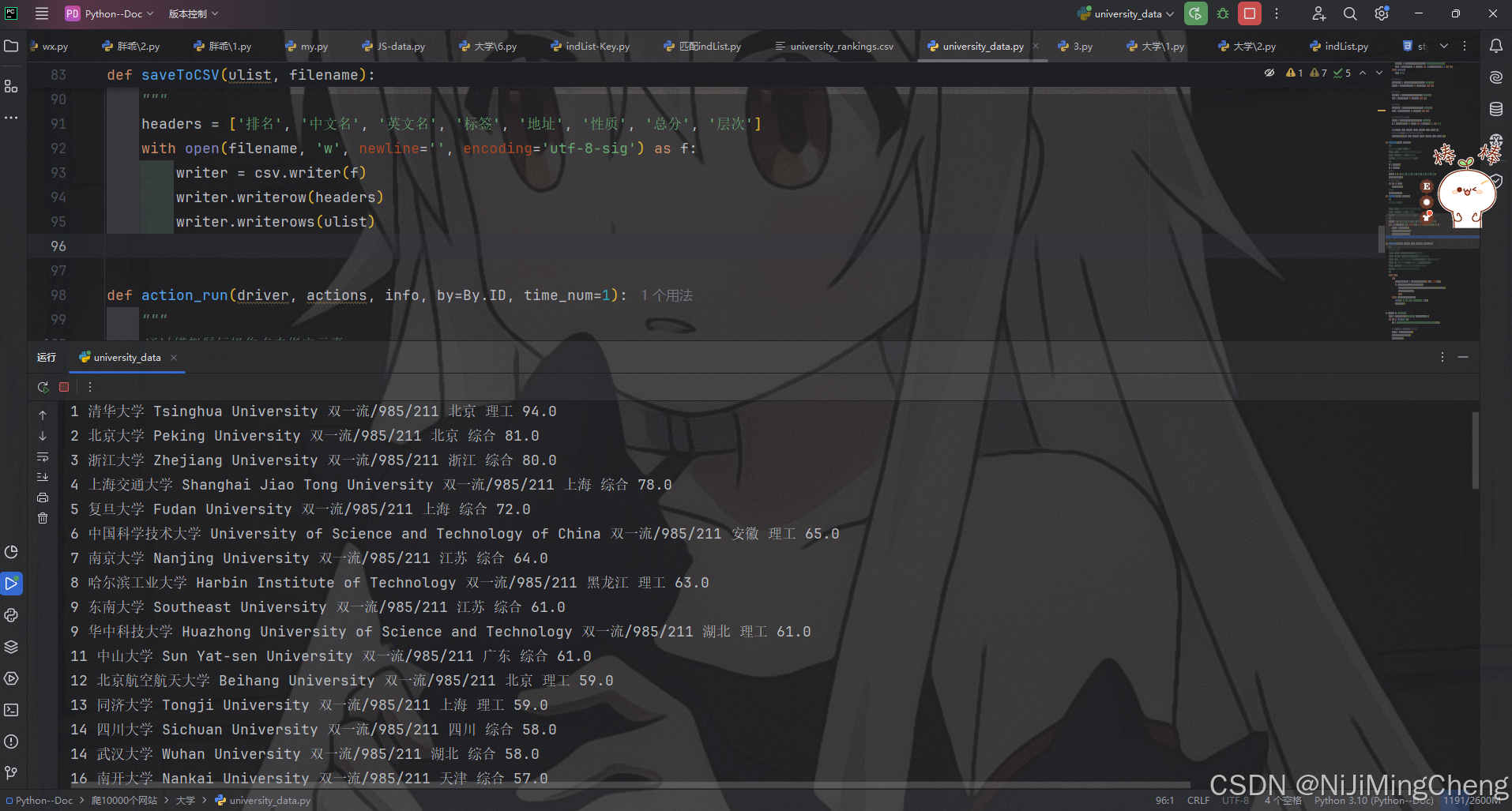
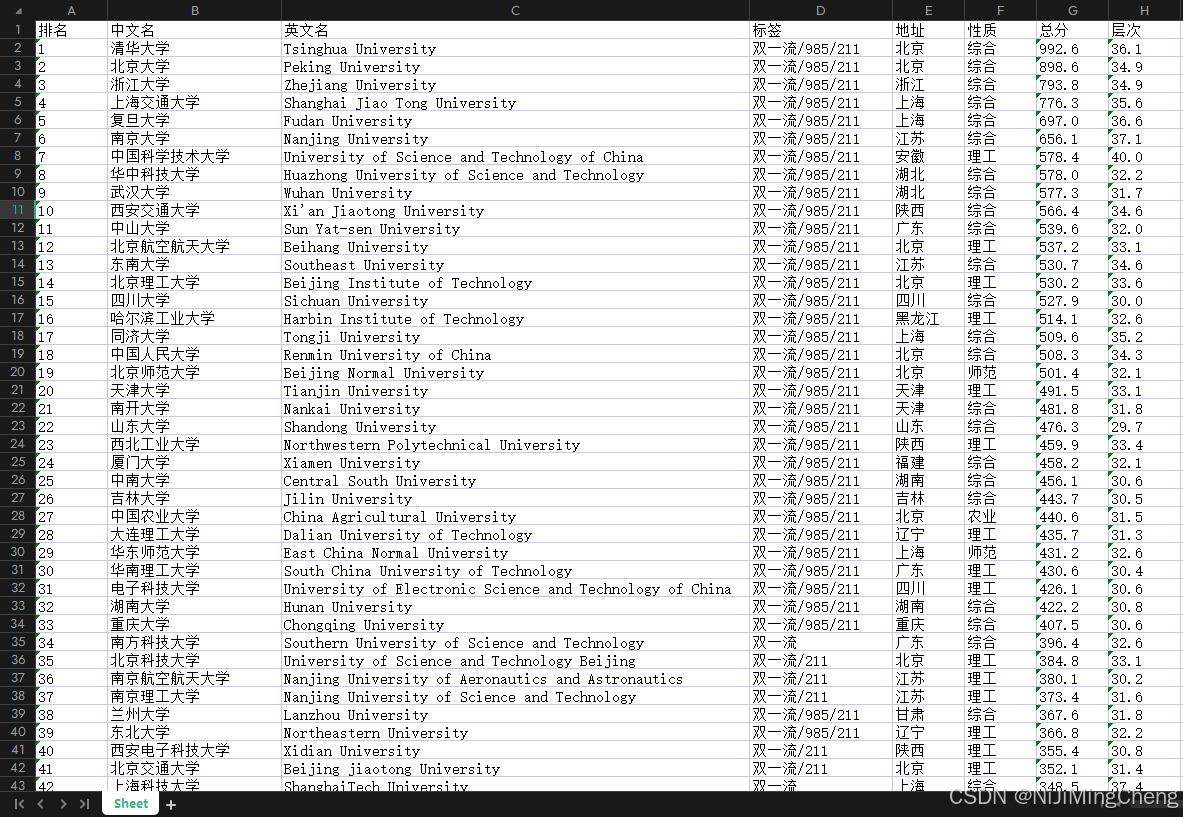
一、引言
在当今数字化时代,数据的获取和分析变得愈发重要。对于教育领域,大学排名数据是众多学生、家长和教育工作者关注的焦点。本文将详细介绍如何使用 Python 语言,结合 Selenium 和 openpyxl 库,编写一个爬虫程序来抓取特定网页上的大学排名信息,并将其保存为 Excel(XLSX 格式)和 CSV 文件。
二、准备工作
(一)安装必要的库
- Selenium :用于自动化浏览器操作,模拟用户在网页上的行为,如点击、滚动等。可以通过
pip install selenium命令进行安装。 - openpyxl :用于操作 Excel 文件,实现数据的写入和保存。使用
pip install openpyxl进行安装。 - ChromeDriver:Selenium 需要与浏览器驱动配合使用,这里以 Chrome 为例,需要下载对应版本的 ChromeDriver,并将其路径添加到系统环境变量中。
(二)导入所需的模块
在 Python 脚本中,我们需要导入以下模块:
python
from openpyxl.workbook import Workbook
from selenium import webdriver
from selenium.common import NoSuchElementException
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import csv三、代码解析
(一)university函数
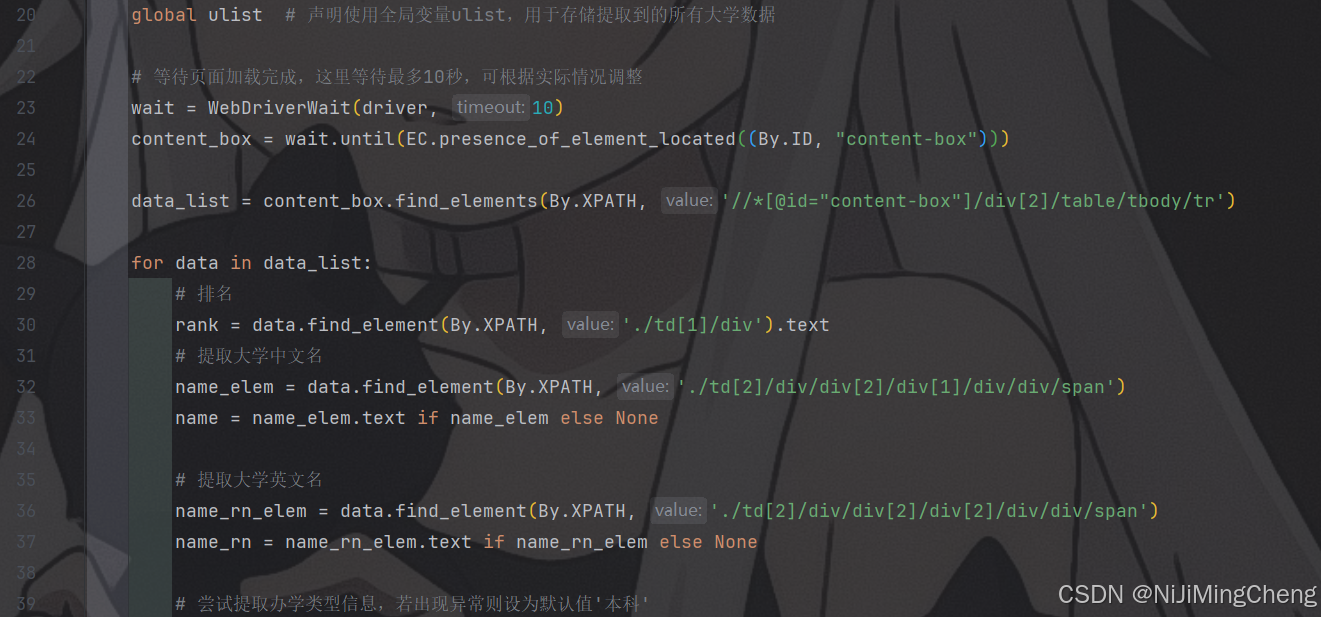
- 功能概述
- 该函数用于从网页表格中提取每一行数据的相关信息,包括排名、大学中文名、英文名、办学类型、所在省份、分类、总分和层次等。
- 代码实现细节
- 首先,使用
WebDriverWait等待页面加载完成,确保要提取数据的元素已经存在于页面中。 - 然后,通过 XPath 表达式定位到表格中的每一行数据(
content_box.find_elements(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr'))。 - 对于每一行数据,分别使用 XPath 表达式提取各个字段的信息。例如,排名通过
data.find_element(By.XPATH, './td[1]/div').text获取,大学中文名通过data.find_element(By.XPATH, './td[2]/div/div[2]/div[1]/div/div/span').text获取(如果元素存在),以此类推。 - 在提取办学类型信息时,使用了异常处理,若出现异常则将办学类型设为默认值
'本科'。 - 最后,将提取到的每一行数据打印输出,并添加到全局的
ulist列表中(如果ulist已定义)。
- 首先,使用
(二)saveToXLSX函数
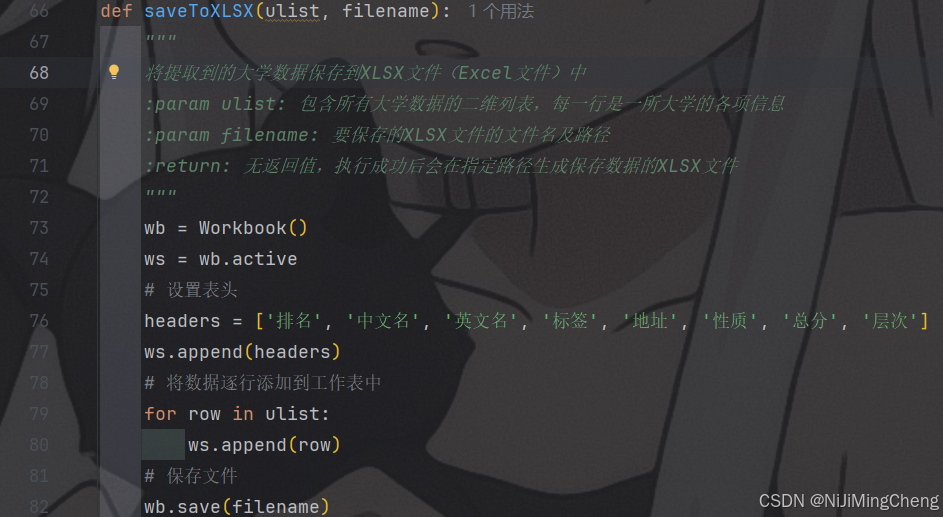
- 功能概述
- 将提取到的大学数据保存到 XLSX 文件(Excel 文件)中。
- 代码实现细节
- 创建一个
Workbook对象(wb = Workbook()),并获取活动的工作表(ws = wb.active)。 - 设置表头,定义了一个包含字段名的列表
headers = ['排名', '中文名', '英文名', '标签', '地址', '性质', '总分', '层次'],并将其添加到工作表中(ws.append(headers))。 - 遍历
ulist列表,将每一行数据添加到工作表中(ws.append(row))。 - 最后保存文件(
wb.save(filename)),其中filename是要保存的文件的名称及路径。
- 创建一个
(三)saveToCSV函数
- 功能概述
- 将提取到的大学数据保存到 CSV 文件中。
- 代码实现细节
- 定义表头列表
headers = ['排名', '中文名', '英文名', '标签', '地址', '性质', '总分', '层次']。 - 使用
with open语句以写入模式打开指定的 CSV 文件,设置newline=''和encoding='utf - 8 - sig',创建一个csv.writer对象。 - 先写入表头(
writer.writerow(headers)),然后写入数据行(writer.writerows(ulist))。
- 定义表头列表
(四)action_run函数
- 功能概述
- 通过模拟鼠标操作点击指定元素。
- 代码实现细节
- 使用
while True循环不断尝试查找要点击的元素。 - 使用
try - except块来处理元素未找到的情况,如果元素未找到,打印提示信息并等待 1 秒后继续尝试。 - 当找到元素且元素可见时,使用
ActionChains将鼠标移动到元素上并点击(actions.move_to_element(config_facesearch).click().perform()),然后等待指定的时间(time.sleep(time_num)),最后跳出循环。
- 使用
(五)if __name__ == "__main__"(主运行函数)部分
- 功能概述
- 这是程序的入口点,在这里执行主要的逻辑流程,包括循环遍历多个网页,抓取数据,保存数据等操作。
- 代码实现细节
- 首先记录程序开始时间(
start = time.strftime("%H:%M:%S", time.localtime()))。 - 然后使用
for循环遍历从 2015 到 2024(range(15, 25))的年份,构建对应的网页 URL(url = f"https://www.shanghairanking.cn/rankings/bcur/20{num}")。 - 对于每个 URL,创建一个 Chrome 浏览器的
WebDriver实例,最大化窗口,并打开网页(driver = webdriver.Chrome(); driver.maximize_window(); driver.get(url))。 - 创建
ActionChains对象用于模拟鼠标操作,初始化ulist列表用于存储数据。 - 获取网页上显示的总页数(
page = driver.find_element(By.XPATH,'//*[@id="content-box"]/ul/li[8]/a').text),然后循环遍历每一页。 - 在每一页中,先获取页面源代码,调用
university函数提取数据,滚动页面到底部(driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")),然后使用action_run函数点击 "下一页" 按钮,实现翻页操作。 - 当遍历完所有页后,关闭浏览器(
driver.quit()),并将数据保存为 XLSX 文件(saveToXLSX(ulist, f'./20{num}.xlsx')),打印保存成功的提示信息。 - 最后记录程序结束时间(
end = time.strftime("%H:%M:%S", time.localtime())),并计算程序运行的时长(print("用时%s - %s" % (start, end)))。
- 首先记录程序开始时间(
四、运行程序
完整代码:
python
# -*- coding:utf-8 -*-
from openpyxl.workbook import Workbook
from selenium import webdriver
from selenium.common import NoSuchElementException
from selenium.webdriver import ActionChains
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
import csv
def university():
"""
从网页表格中提取每一行数据的相关信息
:param j: 当前行的起始索引,用于在打印输出时显示正确的排名序号
:return: 无直接返回值,但会在函数内部打印提取到的每所大学的各项信息,并将数据添加到全局的ulist列表中(如果定义了的话)
"""
global ulist # 声明使用全局变量ulist,用于存储提取到的所有大学数据
# 等待页面加载完成,这里等待最多10秒,可根据实际情况调整
wait = WebDriverWait(driver, 10)
content_box = wait.until(EC.presence_of_element_located((By.ID, "content-box")))
data_list = content_box.find_elements(By.XPATH, '//*[@id="content-box"]/div[2]/table/tbody/tr')
for data in data_list:
# 排名
rank = data.find_element(By.XPATH, './td[1]/div').text
# 提取大学中文名
name_elem = data.find_element(By.XPATH, './td[2]/div/div[2]/div[1]/div/div/span')
name = name_elem.text if name_elem else None
# 提取大学英文名
name_rn_elem = data.find_element(By.XPATH, './td[2]/div/div[2]/div[2]/div/div/span')
name_rn = name_rn_elem.text if name_rn_elem else None
# 尝试提取办学类型信息,若出现异常则设为默认值'本科'
try:
type_elem = data.find_element(By.XPATH, './td[2]/div/div[2]/p')
type_ = type_elem.text if type_elem and len(type_elem.text) > 0 else None
except Exception:
type_ = '本科'
# 提取大学所在省份信息
provice_elem = data.find_element(By.XPATH, './td[3]')
provice = provice_elem.text if provice_elem else None
# 提取大学分类信息
leix_elem = data.find_element(By.XPATH, './td[4]')
leix = leix_elem.text if leix_elem else None
# 提取大学总分信息
score_elem = data.find_element(By.XPATH, './td[5]')
score = score_elem.text if score_elem else None
# 提取大学层次信息,若未找到则设为'暂无'
bx_elem = data.find_elements(By.XPATH, './td[6]')
bx = bx_elem[0].text if bx_elem and len(bx_elem) > 0 else '暂无'
print(rank, name, name_rn, type_, provice, leix, score, bx)
# 将当前行数据添加到ulist列表中,形成二维列表,每一行代表一所大学的数据
ulist.append([rank, name, name_rn, type_, provice, leix, score, bx])
def saveToXLSX(ulist, filename):
"""
将提取到的大学数据保存到XLSX文件(Excel文件)中
:param ulist: 包含所有大学数据的二维列表,每一行是一所大学的各项信息
:param filename: 要保存的XLSX文件的文件名及路径
:return: 无返回值,执行成功后会在指定路径生成保存数据的XLSX文件
"""
wb = Workbook()
ws = wb.active
# 设置表头
headers = ['排名', '中文名', '英文名', '标签', '地址', '性质', '总分', '层次']
ws.append(headers)
# 将数据逐行添加到工作表中
for row in ulist:
ws.append(row)
# 保存文件
wb.save(filename)
def saveToCSV(ulist, filename):
"""
将提取到的大学数据保存到CSV文件中
:param ulist: 包含所有大学数据的二维列表,每一行是一所大学的各项信息
:param filename: 要保存的CSV文件的文件名及路径
:return: 无返回值,执行成功后会在指定路径生成保存数据的CSV文件
"""
headers = ['排名', '中文名', '英文名', '标签', '地址', '性质', '总分', '层次']
with open(filename, 'w', newline='', encoding='utf-8-sig') as f:
writer = csv.writer(f)
writer.writerow(headers)
writer.writerows(ulist)
def action_run(driver, actions, info, by=By.ID, time_num=1):
"""
通过模拟鼠标操作点击指定元素
:param driver: Selenium的WebDriver实例,用于控制浏览器
:param actions: Selenium的ActionChains实例,用于构建鼠标操作动作链
:param info: 要查找并点击的元素的定位信息,可以是ID、CSS_SELECTOR等,根据by参数指定的定位方式来确定
:param by: 定位元素的方式,默认为By.ID,可传入其他定位方式如By.CSS_SELECTOR等
:param time_num: 点击操作完成后等待的时间(秒),默认为1秒,可根据实际情况调整
:return: 无返回值,执行成功后会完成对指定元素的点击操作并等待指定时间
"""
while True:
try:
config_facesearch = driver.find_element(by=by, value=info)
if config_facesearch.is_displayed():
actions.move_to_element(config_facesearch).click().perform()
time.sleep(time_num)
break
except NoSuchElementException:
print("%s is not find, waiting..." % info)
time.sleep(1)
if __name__ == "__main__":
start = time.strftime("%H:%M:%S", time.localtime())
for num in range(15, 25):
url = f"https://www.shanghairanking.cn/rankings/bcur/20{num}"
# 创建Chrome浏览器的WebDriver实例,并最大化窗口
driver = webdriver.Chrome()
driver.maximize_window()
driver.get(url)
"模拟鼠标操作"
actions = ActionChains(driver)
ulist = []
page = driver.find_element(By.XPATH,'//*[@id="content-box"]/ul/li[8]/a').text
# 获取总页数遍历
for i in range(int(page)):
html = driver.page_source
university()
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);") # 滚动至底部
action_run(driver, actions, info="li[title='下一页']", by=By.CSS_SELECTOR)
# 关闭浏览器
driver.quit()
saveToXLSX(ulist, f'./20{num}.xlsx')
print(f'./20{num}.xlsx已保存成功!')
end = time.strftime("%H:%M:%S", time.localtime())
print("用时%s - %s" % (start, end)) # 时长统计
# # 将提取到的所有大学数据保存为CSV文件
# saveToCSV(ulist, './university_rankings.csv')- 确保已经正确安装了所需的库和 ChromeDriver,并配置好环境变量。
- 将上述代码保存为一个
.py文件,例如university_rankings.py。 - 在命令行中进入代码所在的目录,运行
python university_rankings.py命令。 - 程序将自动打开 Chrome 浏览器,访问指定的网页,抓取大学排名数据,并将数据保存为多个 XLSX 文件(每个年份一个文件),同时在控制台输出程序运行的相关信息,包括开始时间、结束时间和每个文件保存成功的提示。
五、总结
通过本文介绍的 Python 爬虫程序,我们可以方便地从网页上抓取大学排名数据,并将其保存为常用的 Excel 和 CSV 格式,便于后续的数据处理和分析。在实际应用中,还可以根据需要对代码进行进一步的优化和扩展,例如增加数据清洗、处理更多的网页元素等功能,以满足更复杂的需求。希望本文能够帮助读者掌握 Python 爬虫在数据获取方面的基本应用技巧。
注意:
请注意,在实际使用中,如果涉及到对网站数据的获取,需要确保遵守相关网站的使用条款和法律法规,避免未经授权的访问和数据滥用等问题,本文仅供交流学习,请勿滥用。