序言
当数据在进行交互的时候,如果连接发生了改变,就必然会涉及到是否是无损关闭连接,主要就是看结束连接的时候是否是四次挥手关闭,短连接其实还好,最关键的是长连接如何关闭。
在k8s中,如果运行的是nginx ingress,就涉及到一个是reload会改变连接,一个是后面的svc发生变化的时候的连接;如果是普通的deployment,就涉及到rollingupdate滚动更新的时候,连接如何进行关闭的问题。
优雅的关闭连接
1 长连接与短连接
所谓的长连接,就是和客户端的tcp连接一直在一个会话上面,当你使用netstat查看的时候,连接的端口一直是同样的一个保持不变;而短连接则是使用netstat查看的时候,连接的端口总是同一个。
css
netstat -antp(在命令中的62257一直保持不变,一直在estabished状态)Active Internet connections (servers and established)Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program nametcp 0 0 10.10.1.132:6379 10.0.20.3:62257 ESTABLISHED 9717/redis站在nginx的角度来看,长连接要分为客户端和nginx之间的连接(还有nginx与upsteam的连接),这个是nginx参数keepalive_timeout来设置的,当客户端空闲多久的时候,就会将这个连接断开,也就是说,如果客户端一直在发送数据,那么这个连接可以到天长地久,只要世界不崩溃,这个连接就一直在。
css
Syntax: keepalive_timeout timeout [header_timeout];Default: keepalive_timeout 75s;Context: http, server, location当然也可以配置为不是无限发送,所以偶尔会有一个长连接上发送的请求数量来进行限制,就类似于数据库的连接池,从而在到了一定的时候,这个连接肯定会进行关闭。
css
Syntax: keepalive_requests number;Default: keepalive_requests 1000;Context: http, server, location要想流量进行无缝的衔接,从而应该有机会让长连接得到释放,不然的话,如果长连接无法释放,那么理论上还是偶尔有损失的。特别是对于websocket连接,grpc的连接,这种都是一个连接到死的那种,不过现在基本上客户端都兼容了,也就是连接断开了,也会自动进行重连。
2 pod的关闭流程
在k8s中,要支持优雅无损的进行关闭连接,首要的条件就是pod是支持对应的信号,看一下pod的关闭流程会发送哪些信号。

pod的状态变化,可以是使用命令kubectl进行手动删除pod,也可以是deployment在进行更新pod镜像的时候,pod的状态会先变成terminating,然后开始执行pod的prestop逻辑,执行一些必要的清理工作,然后当prestop执行完成之后,kubelet就会发送sigterm信号进行关闭pod,然后等待terminationgracetime,默认是30秒,到了时间之后,就会发送sigkill信号强制杀死pod,也就完成了一个pod的生命周期。
在这里,要注意的pod里面,是能够捕获到sigterm信号的,否则永远也无法进行优雅的关闭,除非你运气足够好,验证的方法是进入到你的pod,然后直接执行:
bash
默认发送的是sigterm信号kill 1如果你执行完成之后,退出了这个pod,也就说明你的pod能捕获到sigterm信号,能正确的处理,如果pod未退出,还是老样子,说明pod的主进程无法捕获sigterm信号,你需要检查容器的主进程了,如果是shell脚本,那么你需要自己捕获并传递sigterm信号,而在很多的dockerfile里面写的时候,entrypoint.sh里面使用exec直接取代shell,从而能捕获到sigterm信号,如果不想写,那么可以将tini作为你的主进程,这个能捕获并传递信号,而且能清理掉僵尸进程。
当你发现不能正确关闭的时候咋办,可以来追踪一下是否发送了信号。
powershell
登录宿主机,找到pod的主进程strace -f -e trace=signal -p pid这个时候你就可以看到发送了什么信号,在普通的容器中,一般是收到sigterm信号,但是在有的pod中,收到的sigquit信号,例如nginx,例如openresty,当他们进行reload的时候,其实也是发送的sigquit信号,而且在他们的dockerfile中,有如下的写法。当然,你也可以到node上去,查看kubelet的日志,里面会看到对应的发送信号的日志。
go
STOPSIGNAL SIGQUIT这两个信号有啥区别呢,sigterm信号对于长连接来说,它会一直等,直到客户端关闭连接,也就是说,如果长连接持续发送请求,那么这个连接基本不会关闭;而对于sigquit信号来说,是快速关闭,针对连接上的当前请求处理完成之后,立刻关闭连接。
3 pod关闭时间的设置
在有的时候,不能让pod关闭的太快,或者是快速的收到sigterm或者sigquit信号,那么可以在prestop里面直接sleep一个120秒,然后将terminationGracePeriodSeconds设置为300秒,这样就给了pod充足的时间来消化当前的请求,让请求更加无损的切换到新的pod或者连接上去。
在k8s的各个版本中,在v1.24版本以下都有个bug,配置了上面的两个时间之后,会导致pod删除的时间是120+300秒,但是在v1.26以上好像修复了,也就是基本上到了300秒就会直接删除pod,不会有过多的时间。这种配置带来的坏处就是每次你进行deployment升级或者是kubectl删除pod的时候,你会发现差不多要300秒才会删除这个pod,rolling的整体时间会变长。
在进行长连接销毁的时候,涉及到的是一个是老的连接,一个是新的连接,对于新的连接来说,需要的是pod的状态是ready的,也就是能正常的为客户端提供服务,也就意外着pod的liveness和readyness两个健康检查要进行配置,否则没准新请求就挂了,还没有ready就把流量调度上去了;而对于老的连接来说,主要是多久处理完成,从而对老的pod给予多少宽限的时间,也就是gracetime的设置,一个请求的最长超时时间是多久,太长的请求,其实。。。抛弃也无所谓了。
在nginx ingress里面,reload可能会造成问题,所以很多都开始直接内存进行更新对应的配置了,那么为什么reload会有问题,而直接更新内存不会有问题呢?
因为如果reload了,你会发现老的woker process被关闭了,新的进程起来了,新的连接要和新的进程建连,而如果在内存中更新,这个worker process是不会发生变化的,从而无论是什么连接,都可以保持不变进行继续处理。
4 压测抓包
当上面的都做完之后,就可以进行压测了,例如当你使用的ingress的时候,就可以不停的reload,就可以不停的修改ingress规则,然后查看压测的结果是否有5xx产生,如果有,就要检查下是不是哪个步骤出了问题。
当追踪信号的时候,如果出现了sigkill,那么估计会有连接被杀死,那么可以使用抓包看看,到底是长连接没释放,还是说服务端发送了reset包。由于压测的时候,包其实是很多的,所以一般可以用分段抓包,一个包100m进行抓包,从而减少分析的难度。
go
tcpdump -C 100 -w tcp.pcap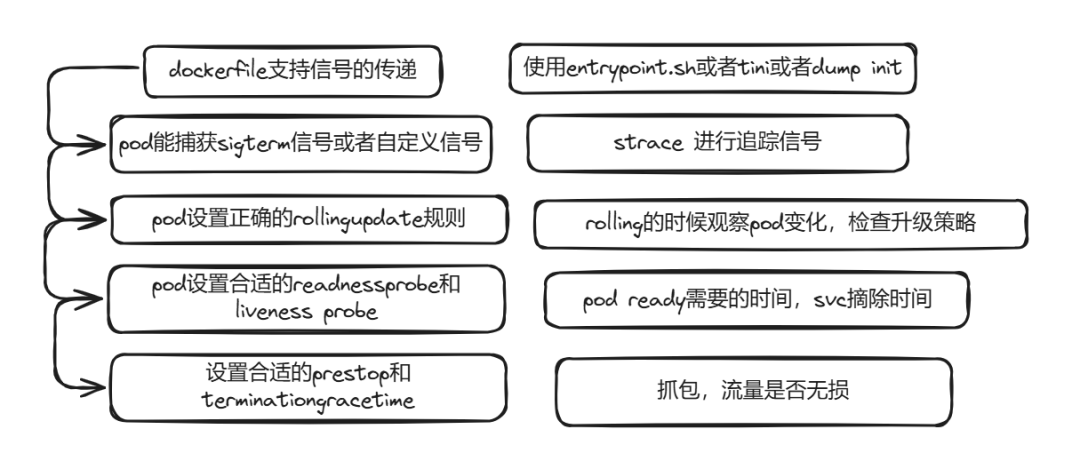
风言风语
连接的关闭是否优雅,就看请求是否有失败的可能,如果可能有失败的,那么说明不是优雅的,尽量优雅,但是有些垃圾流量其实也是可以适当抛弃的,用客户端来进行兜底处理。
只要你足够细心,那么你就会发现各种各样的问题,然后就会有无穷的问题来解。抓住发现问题的点,然后一点一点分析下去,总是会找到解决问题的办法,如果实在没招了,那就放弃下一个。