目录
[二、为什么是 Transformer?](#二、为什么是 Transformer?)
[三、什么是 Transformer?](#三、什么是 Transformer?)
[3.1 译者的类比](#3.1 译者的类比)
[4.1 、从文本输入到输入嵌入](#4.1 、从文本输入到输入嵌入)
[4.2 词嵌入](#4.2 词嵌入)
[4.2 N倍编码器段](#4.2 N倍编码器段)
[4.4 多头注意力机制](#4.4 多头注意力机制)
[4.5 添加残差和层归一化](#4.5 添加残差和层归一化)
[4.6 添加残差和层归一化](#4.6 添加残差和层归一化)
一、说明
西如今,当你阅读有关自然语言处理中的机器学习的文章时,你听到的只有一件事------Transformers。自 2017 年以来,基于这种深度学习架构的模型席卷了 NLP 世界。事实上,它们是当今的首选方法,许多方法都以某种方式建立在原始 Transformer 之上。
然而,Transformer 并不简单。原始的 Transformer 架构非常复杂,许多衍生架构也是如此。因此,我们将研究 Vaswani 等人在 2017 年提出的 vanilla Transformer 架构。它是探索许多其他 Transformer 架构的基础。今天的文章不会涉及大量数学知识,而是直观易懂,以便许多人能够理解 vanilla Transformer 内部发生了什么。
本文的结构如下。首先,我们将通过研究 Transformer 的前身(主要是LSTM和 GRU)的问题来了解 Transformer 出现的原因。然后,我们将从整体(即从高层次)来了解 Transformer 架构。接下来,我们将对架构进行更细致的分析,因为我们将首先研究编码器部分,然后研究解码器部分。最后,我们将介绍如何训练 Transformer。
准备好了吗?我们开始吧!
二、为什么是 Transformer?
自然语言处理中的机器学习传统上是用循环神经网络进行的。这里的循环意味着,当处理一个序列时,用于生成标记预测的隐藏状态(或"记忆")也会被传递,以便在生成后续预测时使用它。
循环神经网络( RNN) 是一类人工神经网络,其中节点之间的连接沿时间序列形成有向图。这使得它能够表现出时间动态行为。RNN 源自前馈神经网络,可以使用其内部状态(内存)来处理可变长度的输入序列。
维基百科(2005年)
循环网络已经存在了一段时间。最早出现的循环网络之一是简单或原始的循环网络,或原始 RNN。它是下面图库中的顶部图像。如您所见,在生成预测时,更新后的隐藏状态会传递给自身,以便可以用于任何后续预测。展开后,我们可以清楚地看到它如何与各种输入标记和输出预测一起工作。
虽然循环网络能够提升当时自然语言处理的最高水平,但它们也遇到了一系列的缺点/瓶颈:
- 由于隐藏状态传递的方式,RNN 对消失梯度问题非常敏感。尤其是对于较长的序列,用于优化的梯度链可能非常长,以至于前几层的实际梯度非常小。换句话说,与任何受到消失梯度影响的网络一样,最上游的层几乎什么都学不到。
- 记忆也是如此:隐藏状态会传递到下一个预测步骤,这意味着大多数可用的上下文信息与模型在短期内看到的内容有关。因此,对于经典 RNN,模型面临长期记忆问题,因为它们擅长短期记忆,但对长期记忆却非常不擅长。
- 处理是按顺序进行的。也就是说,短语中的每个单词都必须经过循环网络,然后返回预测。由于循环网络在计算要求方面可能非常密集,因此可能需要一段时间才能生成输出预测。这是循环网络的固有问题。
幸运的是,在 2010 年代,人们研究并应用了长短期记忆网络(LSTM,中间图片) 和门控循环单元 (GRU,底部) 来解决上述三个问题中的一些。特别是 LSTM,通过保留记忆的细胞状结构,对消失梯度问题具有鲁棒性。更重要的是,由于记忆现在与之前的细胞输出(例如,下面 LSTM 图中]c_{t} 流)分开维护,因此两者都能够存储长期记忆。
尤其是当在此基础上发明了注意力机制时,其中提供了一个加权上下文向量来代替隐藏状态,该向量对所有先前预测步骤的输出进行加权,长期记忆问题正在迅速减少。唯一悬而未决的问题是必须按顺序执行处理,这对训练自然语言处理模型造成了重大的资源瓶颈。

完全循环网络。由Wikipedia的fdeloche创建,许可为CC BY-SA 4.0。未做任何更改。

LSTM 单元。由维基百科的Guillaume Chevalier(svg 由 Ketograff 制作)创建,获得CC BY 4 许可。

) 一个 GRU 单元。由Jeblad在Wikipedia创建,许可为CC BY-SA 4.0(未进行任何更改)。
三、什么是 Transformer?
在 2017 年的一项里程碑式研究中,Vaswani 等人声称注意力就是你所需要的一切------换句话说,深度学习模型中不需要循环构建块就能在 NLP 任务中表现出色。他们提出了一种新的架构 Transformer,它能够在并行处理序列的同时保持注意力机制:将所有单词放在一起,而不是逐个单词地处理。
这种架构消除了上述三个问题中的最后一个问题,即必须按顺序处理序列,这会产生大量的计算成本。使用 Transformers,并行性已成为现实。
正如我们将在不同的文章中看到的那样,基于 Transformer 的架构有不同的风格。基于传统的 Transformer 架构,研究人员和工程师进行了大量实验并带来了变化。然而,原始的 Transformer 架构如下所示:

来源:Vaswani 等人(2017 年)
我们可以看到,它有两个相互交织的部分:
- 编码器段从源语言获取输入,为其生成嵌入,编码位置,计算每个单词在多上下文设置中需要注意的位置,然后输出一些中间表示。
- 解码器部分,它从目标语言获取输入,为它们生成带有编码位置的嵌入,计算每个单词需要关注的位置,然后将编码器输出与迄今为止生成的内容相结合。结果是对下一个标记的预测,通过 Softmax 和 argmax 类预测(其中每个标记或单词都是一个类)。
因此,原始的 Transformer 是一个经典的序列到序列模型。
请注意,Transformers 可用于各种语言任务,从自然语言理解 (NLU) 到自然语言生成 (NLG)。因此,源语言和目标语言可能相同,但情况并非一定如此。
如果你说你现在有点不知所措,我可以理解。当我第一次读到关于 Transformers 的文章时,我就有这种反应。这就是为什么我们现在将分别研究编码器和解码器部分,仔细研究每个步骤。我们将使用翻译器的类比,尽可能直观地介绍它们。
3.1 译者的类比
假设我们的目标是建立一个能够将德语文本翻译成英语的语言模型。在经典场景中,使用更经典的方法,我们将学习一个能够直接进行翻译的模型。换句话说,我们正在教一名翻译将德语翻译成英语。换句话说,翻译人员需要能够流利地说两种语言,理解两种语言中单词之间的关系,等等。虽然这可行,但它不具有可扩展性。
Transformer 的工作方式不同,因为它们使用编码器-解码器架构。想象一下,如果你正在与两个翻译人员一起工作。第一个翻译人员能够将德语翻译成某种中间通用语言。另一个翻译人员能够将该语言翻译成英语。但是,在每次翻译任务中,你都会让翻译首先通过中间语言。这将与经典方法一样有效(就模型是否产生任何可用的结果而言)。但是,它也是可扩展的:例如,我们可以使用中间语言来训练用于总结文本的模型。我们不再需要为第一个翻译任务进行训练。
在不同的文章中,我们会看到这种预训练和微调原则如今非常流行,尤其是像 BERT 这样的架构,它们从原始 Transformer 中获取编码器部分,在海量数据集上对其进行预训练,并允许人们自己对各种任务进行微调。但是,现在我们将坚持使用原始 Transformer。在其中,{德语} -> {中间语言} 翻译任务将由编码器部分执行,在这个类比中,中间状态就是中间语言。然后,{中间语言} -> {英语} 翻译任务由解码器部分执行。
现在让我们更详细地看一下这两个部分。

四、编码器部分
Transformer 的编码器部分负责将输入转换为某种中间、高维表示。从视觉上看,它看起来如下。编码器段由几个单独的组件组成:
- 输入嵌入,将标记化的输入转换为向量格式,以便使用。Vaswani 等人(2017 年)的原创作品利用了学习嵌入,这意味着标记到向量的转换过程是与主要机器学习任务(即学习序列到序列模型)一起学习的。
- 位置编码,它会稍微改变嵌入层的向量输出,并向这些向量添加位置信息。
- 实际的编码器段学习输出输入向量的关注表示,并由以下子段组成:
- 多头注意力部分,进行多头自注意力,添加残差连接,然后进行层归一化。
- 前馈段,为每个标记生成编码器输出。
- 编码器段可以重复N 次;Vaswani 等人(2017)选择N = 6。
现在让我们更详细地了解编码器的每个单独组件。

4.1 、从文本输入到输入嵌入
您将使用文本数据集训练 Transformer。您可以想象,这样的数据集由短语组成(通常由相互对应的短语对组成)。例如,对于英语,该短语在法语中I go to the store等于Je vais au magasin。
标记化
然而,我们无法将文本输入机器学习模型------例如,TensorFlow 是一个数字处理库,优化技术也适用于数字。
因此,我们必须找到一种用数字表达文本的方法。我们可以通过标记化来实现这一点,这使我们能够将文本表示为整数列表。例如,tf.keras Tokenizer允许我们执行两件事(Nuric,2018):
- 根据文本生成词汇表。 我们从一个空的 Python 字典开始,
{}然后慢慢地但肯定地用每个不同的单词填充它,例如,,dictionary["I"] = 1等等dictionary["go"] = 2。 - 使用词汇表将单词转换为整数。 基于词汇表(显然其中包含大量单词),我们可以将短语转换为基于整数的序列。例如,
I go to the store到["I", "go", "to", "the", "store"]可能变成[1, 2, 39, 49, 128]。显然,这里的整数取决于词汇表的生成方式。
独热编码词语不实用
假设我们已经使用 Tokenizer 为 45,000 个不同的单词生成了一个单词索引。然后,我们有一个包含 45,000 个键的 Python 字典,因此len(keys) = 45000。下一步是对数据集中的每个短语进行标记,例如["I", "go", "to", "the", "store"]变为[1, 2, 39, 49, 128],["I", "will", "go", "now"]变为[1, 589, 2, 37588]。这里的数字当然是任意的,由 Tokenizer 决定。
由于这些变量是分类变量,我们必须以不同的方式表达它们------例如通过独热编码(KDNuggets,nd)。然而,对于非常大的词汇量,这种方法效率极低。例如,在我们上面的词典中,每个标记都是一个 45,000 维的向量!因此,对于小词汇量,独热编码可能是表达文本的好方法。对于较大的词汇量,我们需要一种不同的方法。
4.2 词嵌入
然而,我们有一个解决方案。
我们可以使用词嵌入:
词嵌入是自然语言处理 (NLP) 中的一组语言建模和特征学习技术之一,其中词汇表中的单词或短语被映射到实数向量。从概念上讲,它涉及从每个单词具有多个维度的空间到具有低得多维度的连续向量空间的数学嵌入。
维基百科(2014年)
换句话说,如果我们可以学会将标记映射到向量,我们就有可能在低维空间中为每个单词找到一个唯一的向量。我们可以在下面的可视化图中看到这一点。对于 10,000 个单词,可以在三维空间中可视化它们(由于应用了PCA,信息损失很小),而如果我们应用独热编码,我们将使用 10.000 维向量。

使用Embedding 投影仪绘制的 Word2Vec 10K 数据集中的图,其中三个主成分在三维空间中绘制。突出显示了"routine"一词。
Vanilla Transformers 使用学习到的输入嵌入
Vanilla Transformers 使用学习的输入嵌入层(Vaswani 等人,2017 年)。这意味着嵌入是动态学习的,而不是使用预训练的嵌入(例如预训练的 Word2Vec 嵌入,这也是一种选择)。动态学习嵌入可确保每个单词都可以正确映射到向量,从而提高效率(不会遗漏任何单词)。
学习到的嵌入产生维度为 d_{model} 的向量,其中 Vaswani 等人(2017)设置 d_{model} = 512。d_{model} 也是模型中所有子层的输出。

根据 Vaswani 等人 (2017) 的说法,输入嵌入层和输出嵌入层之间的权重矩阵是共享的,以及预 softmax 线性变换。为了保证稳定性,权重还乘以 SQRT{d_{model}。共享权重是一种设计决策,并非绝对必要,并且可能与性能背道而驰,正如 Ncasas 的解释所示:
源和目标嵌入可以共享也可以不共享。这是一个设计决定。如果共享标记词汇表,则它们通常会共享,这通常发生在您拥有具有相同脚本(即拉丁字母)的语言时。如果您的源语言和目标语言是英语和中文,它们具有不同的书写系统,那么您的标记词汇表可能不会共享,然后嵌入也不会共享。
纳卡萨斯 (2020)
位置编码
构建语言理解或语言生成模型的经典方法受益于处理的顺序。由于必须按顺序处理单词,模型能够识别常见的顺序(例如I am),因为隐藏状态(包括)I总是在处理之前传递am。
有了 Transformer,情况就不再如此了,因为我们知道这类模型没有循环方面,而只使用注意力机制。当将整个短语输入到 Transformer 模型时,它不一定按顺序进行处理,因此模型不知道序列中短语内的任何位置顺序。

使用位置编码 ,我们将表示单词相对位置的向量添加到嵌入层生成的单词向量中。这是一个简单的向量乘法:v _{encoded} = v _{embedding} x v _{encoding}。您可以将其想象为一种重组操作,其中公共向量的位置更紧密地结合在一起。
Vaswani 等人 (2017) 使用基于数学(更具体地说是基于正弦和余弦)的方法进行位置编码。通过让位置和维度根据其奇数或偶数流经正弦或余弦函数,我们可以生成位置编码,并可用于对嵌入输出进行位置编码。此步骤的结果是一个向量,它保留了嵌入的大部分信息,但也包含一些有关相对位置(即单词如何相关)的信息。
4.2 N倍编码器段
生成输入嵌入和应用位置编码是准备步骤,使我们能够在 Transformer 模型中使用文本数据。现在是时候看看实际的编码器段了。
首先我们必须注意,我们在这里讨论的内容可以重复 N 次;如果你愿意的话,可以将其堆叠起来。堆叠编码器时,每个编码器的输出将用作下一个编码器的输入,从而生成更加抽象的编码。虽然堆叠编码器确实可以通过泛化提高模型性能,但它也需要大量计算。Vaswani 等人 (2017) 选择设置 N = 6,因此使用 6 个堆叠在一起的编码器。
每个编码器段由以下组件构成:
- 多头注意力模块。该模块允许我们对每个序列执行自我注意力(即,对于我们提供给模型的每个短语,基于每个标记(每个单词)确定短语中的哪些其他标记(单词)与该标记相关;从而确定在读取该标记/单词时要注意哪里)。
- 前馈块。在为每个 token(单词)生成注意力之后,我们必须生成一个 d_{model}{-Dimension} 向量,也就是对 token 进行编码的 512 维向量。前馈块负责执行此操作。
- 残差连接。残差连接是一种不流经复杂块的连接。我们可以在这里看到两个残差连接:一个从输入流向第一个 Add & Norm 块;另一个从那里流向第二个块。残差连接允许模型更有效地优化,因为从技术上讲,梯度可以从模型的末尾自由流向开头。
- 添加和规范块。在这些块中,多头注意力块或前馈块的输出与残差合并(通过加法),其结果随后进行层规范化。
由于编码器段的输入要么是嵌入的和位置规范化的标记,要么是来自前一个编码器段的输出,因此编码器会学习为输入标记(编码)生成上下文感知的中间表示。通过这种通过执行自注意力实现的上下文感知,Transformers 可以发挥其作用。

多头注意力机制
(来自评论:可以在这里找到有关自我注意力过程的有用说明)。
现在让我们更详细地了解一下编码器段的各个组件。输入将流经的第一个块是多头注意力块。它由多个所谓的缩放点积注意力块组成,我们现在将仔细研究一下。
从视觉上看,这种缩放块如下所示(Vaswani 等,2017):

缩放点积注意力机制
您可以看到它有三个输入- 查询(Q)、键(K)和值(V)。这意味着位置编码的输入向量首先被分成三个独立的流,从而分成矩阵;我们将看到这是通过 3 个不同的线性层实现的。
在 Vaswani 等人(2017 年)中,这些 Q、K 和 V 值描述如下:
注意力函数可以描述为将查询和一组键值对映射到输出,其中查询、键、值和输出都是向量。输出计算为值的加权和,其中分配给每个值的权重由查询与相应键的兼容性函数计算得出。
Vaswani 等人(2017 年)
然而,Dontloo(2019)给出了更直观的描述:
键/值/查询概念来自检索系统。例如,当您键入查询以搜索 Youtube 上的某个视频时,搜索引擎会将您的查询与数据库中与候选视频相关的一组键(视频标题、描述等)进行映射,然后向您显示最匹配的视频(值)。
别闹 (2019)
我希望这能让你更好地理解 Transformers 中查询、键和值的作用。
重要提示:上面我写了 _vector_s 和matrices,因为所有 token 都是并行处理的!这意味着所有位置编码的输入向量都经过 3 个线性层,从而形成一个矩阵。这里重要的是要理解它们是联合处理的,以便接下来理解通过分数矩阵的自注意力是如何工作的。
然而,如果我们真的想呈现最匹配的视频,我们需要确定关注点(给定一些输入,哪些视频最相关?)这就是为什么在上图中,你会看到MatMul查询和键之间的运算。这是一个矩阵乘法,其中查询输出乘以键矩阵以生成分数矩阵。

分数矩阵如下所示:

它说明了在给定短语中的一个单词的情况下,短语中某些单词的重要性。但是,它们还不能进行比较。传统上,可以使用Softmax 函数(未来博客)来生成(伪)概率,从而使值具有可比性。
但是,如果您查看上面的流图,您会发现在应用 Softmax 之前,我们首先应用了一个缩放函数。我们应用此缩放是因为 Softmax 可能对消失梯度敏感,而这是我们不想要的。我们通过将所有值除以 sqrt{d_k} 来进行缩放,其中 d_k 是查询和键的维数。
然后,我们计算 Softmax 输出,它会立即显示对于一个单词来说,该短语中的哪些其他单词在该单词的上下文中很重要。


剩下的步骤是将包含注意力权重的分数矩阵与值进行矩阵乘法,有效地保留模型学习到的最重要的值。
这就是自我注意力的 工作方式,但随后进行了扩展------这就是为什么 Vaswani 等人(2017)称之为缩放点积自我注意力。
多头
但是,编码器块被称为多头注意力。多头注意力到底是什么?下面是视觉效果:

4.4 多头注意力机制
通过复制生成查询、键和值矩阵的线性层,让它们具有不同的权重,我们可以学习这些查询、键和值的多种表示。
用人类语言来说,你可以将其形象化,就好像你从不同的角度看待同一个问题,而不是只从单一角度(即我们刚刚介绍的自注意力)。通过学习多种表示,Transformer 变得越来越具有情境感知能力。如你所见,线性层的输出被发送到单独的缩放点积注意力块,这些块输出值的重要性;它们被连接起来并再次通过线性层。
每个单独的构建块组合称为注意力头。由于一个编码器段中存在多个注意力头,因此该块称为多头注意力块。它对每个块执行缩放的点积注意力,然后连接所有输出并让其流经线性层,再次产生 512 维输出值。
请注意,每个注意力头的维数为 d_{model}/h,其中 h 是注意力头的数量。Vaswani 等人(2017 年)使用的模型维数为 512,并使用了 8 个并行头,因此在他们的案例中,头部维数为 512/8 = 64。
4.5 添加残差和层归一化
多头注意力模块的输出首先与残差连接相加,即所有向量的位置编码输入嵌入。这是一个简单的加法运算。相加之后,对结果执行层归一化运算,然后将其传递到前馈段。应用层归一化可以稳定训练过程,添加残差连接也可以达到同样的效果。

前馈层
完成层规范化后,输入将传递到一组前馈层。根据 Vaswani 等人 (2017) 的说法,每个位置(即 token)都单独通过此网络:它"分别且相同地应用于每个位置"。每个前馈网络包含两个线性层,中间有一个ReLU 激活函数(我们将在另一篇文章中详细讨论激活函数)。
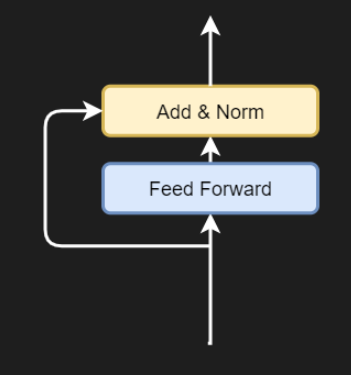
4.6 添加残差和层归一化
对于前馈网络,为了流动梯度,残差首先从输入中分支出来。它被添加到前馈网络的输出中,随后进行层归一化。
这是编码输入离开编码器段之前的最后一个操作。现在可以进一步使用它(例如在 BERT 中,我们将在另一篇文章中介绍)或作为原始 Transformer 解码器段的(部分)输入,我们将在本系列 Transformer 文章的第 2 部分中介绍。
(注意:讨论比我预期的要长一些。因此,我将其分成两部分。)如果您有兴趣,请继续阅读下一部分,了解解码器部分并训练 Transformer。
五、总结
Transformer 正在席卷自然语言处理领域。但它们的架构相对复杂,需要花费相当长的时间才能充分理解它们。这就是为什么我们在本文中研究了 Vaswani 等人在 2017 年的一篇论文中提出的 vanilla Transformer 架构。
这种架构是当今所有 Transformer 相关活动的基础,它解决了序列到序列模型的最后一个问题:序列处理问题。不再需要循环段,这意味着网络可以从并行性中受益,从而显著加快训练过程。事实上,如今的 Transformer 是用数百万个甚至更多的序列进行训练的。
为了提供必要的背景信息,我们首先了解了 Transformer 是什么以及为什么需要它们。然后我们继续研究编码器部分。
我们看到,在编码器部分,输入首先通过(学习到的)输入嵌入,将基于整数的标记转换为具有较低维度的向量。然后通过正弦和余弦函数对它们进行位置编码,以将有关标记相对位置的信息添加到嵌入中 - 由于处理的顺序性,传统模型中自然存在这些信息,但现在由于并行性而丢失了这些信息。在这些准备步骤之后,输入被馈送到编码器部分,该部分学习应用自我注意。换句话说,当查看特定单词时,模型会自己学习短语的哪些部分很重要。这是通过多头注意力和前馈网络实现的。
在第二部分中,我们将看到解码器部分的工作方式类似,尽管略有不同。首先,输出被嵌入并进行位置编码,之后它们也通过多头注意力模块。然而,此模块在生成分数矩阵时应用了前瞻掩码,以确保模型在预测当前单词时不能查看后续单词。换句话说,它只能使用过去的单词。随后,添加另一个多头注意力模块,将编码的输入作为查询和键与关注的输出值作为值进行组合。此组合被传递到前馈部分,最终使我们能够通过额外的线性层和 Softmax 激活函数生成标记预测。
如果将 Vanilla Transformers 用于翻译任务,则需要使用双语数据集进行训练。此类数据集的一个例子是 WMT 2014 英德数据集,其中包含英语和德语短语;Vaswani 等人 (2014) 曾使用它来训练他们的 Transformer。
希望您从今天的文章中学到一些东西。欢迎提出任何评论、问题或建议。感谢您的阅读。如果您对更多此类材料感兴趣,请点击"喜欢"和"关注"。