一. Source 简介
DataStream是Flink的低级API,用于进行数据的实时处理,Flink编程模型分为Source、Transformation、Sink三个部分,如下图所示。

默认Flink提供了大量的内置Source,常见的Source如下:
- 基于文件的Source
- 基于Socket的Source
- 基于集合的Source
- 基于Kafka消息队列的Source
当以上内置Source不能满足业务需要时,可以实现自定义Source。
Flink中有关Source的接口类的继承关系如下:
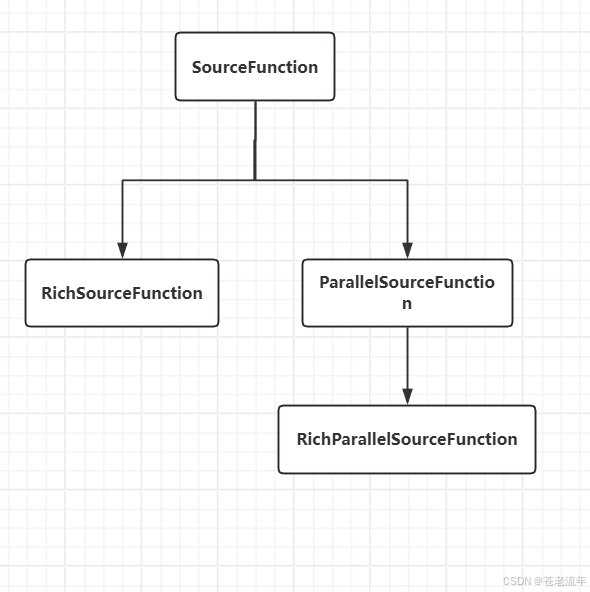
- SourceFunction:单并行度Source的基类
- RichSourceFunction:单并行度增强型Source的基类
- ParallelSourceFunction:多并行度Source的基类
- RichParallelSourceFunction:多并行度增强型Source的基类
二. 自定义单并行度Source
自定义单并行度的source需要实现SourceFunction接口。
代码实现:
MySource.java
java
package flink.basic.source;
import org.apache.flink.streaming.api.functions.source.SourceFunction;
import java.util.Random;
public class MySource implements SourceFunction<String> {
boolean running = true;
@Override
public void run(SourceContext<String> ctx) throws Exception {
Random random = new Random();
while (running) {
// "Num"加上0~100的随机数生成一个字符串
ctx.collect("Num: " + random.nextInt(100));
Thread.sleep(1000);
}
}
@Override
public void cancel() {
running = false;
}
}SourceDemo.java
java
package flink.basic.source;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SourceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env= StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = env.addSource(new MySource());
source.print();
env.execute("source_demo");
}
}运行结果:
bash
5> Num: 62
6> Num: 91
7> Num: 13
8> Num: 53三. 自定义多并行度Source
自定义多并行度的source需要实现ParallelSourceFunction接口。
代码实现:
MyParallelSource.java
java
package flink.basic.source;
import org.apache.flink.streaming.api.functions.source.ParallelSourceFunction;
import java.util.Random;
public class MyParallelSource implements ParallelSourceFunction<String> {
boolean running = true;
@Override
public void run(SourceContext<String> ctx) throws Exception {
Random random = new Random();
while (running) {
ctx.collect("Num: " + random.nextInt(100));
Thread.sleep(1000);
}
}
@Override
public void cancel() {
running = false;
}
}SourceDemo.java
java
package flink.basic.source;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SourceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env= StreamExecutionEnvironment.getExecutionEnvironment();
DataStreamSource<String> source = env.addSource(new MyParallelSource());
source.print();
env.execute("source_demo");
}
}运行结果:
bash
7> Num: 43
8> Num: 30
1> Num: 92
2> Num: 50
5> Num: 39
6> Num: 6
4> Num: 20
3> Num: 2四. 自定义单并行度增强型Source
增强型Source额外提供了open和close方法,可以用于自定义Source的初始化和清理工作。单并行度增强型Source需要实现RichSourceFunction接口。下面演示实现读取mysql表的单并行度Source。
在mysql中创建student表,并插入三条数据。
sql
create table student (
id int primary key,
name varchar(50),
age int
);
insert into student values(1, "name1", 20),(2, "name2", 30), (3, "name3", 15);实现代码
Student.java
java
package flink.basic.source;
public class Student {
private int id;
private String name;
private int age;
public Student(int id, String name, int age) {
this.id = id;
this.name = name;
this.age = age;
}
public Student() {}
public int getId() {
return id;
}
public void setId(int id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return "Student{" +
"id=" + id +
", name='" + name + '\'' +
", age=" + age +
'}';
}
}MysqlSource.java
java
package flink.basic.source;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.streaming.api.functions.source.RichSourceFunction;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.ResultSet;
import java.sql.Statement;
public class MysqlSource extends RichSourceFunction<Student> {
Connection conn;
Statement stmt;
@Override
public void open(Configuration parameters) throws Exception {
Class.forName("com.mysql.cj.jdbc.Driver");
String url = "jdbc:mysql://192.168.47.130:3306/test";
String user = "root";
String password = "root";
conn = DriverManager.getConnection(url,user,password);
stmt = conn.createStatement();
}
@Override
public void run(SourceContext<Student> ctx) throws Exception {
ResultSet rs = stmt.executeQuery("select * from student");
while (rs.next()) {
int id = rs.getInt("id");
String name = rs.getString("name");
int age = rs.getInt("age");
ctx.collect(new Student(id, name, age));
}
rs.close();
}
@Override
public void cancel() {
}
@Override
public void close() throws Exception {
stmt.close();
conn.close();
}
}SourceDemo.java
java
package flink.basic.source;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
public class SourceDemo {
public static void main(String[] args) throws Exception {
StreamExecutionEnvironment env= StreamExecutionEnvironment.getExecutionEnvironment();
// 添加mysql Source
DataStreamSource<Student> source = env.addSource(new MysqlSource());
source.print();
env.execute("source_demo");
}
}运行结果:
bash
1> Student{id=3, name='name3', age=15}
8> Student{id=2, name='name2', age=30}
7> Student{id=1, name='name1', age=20}