
序言:许多人最初接触人工智能都是在ChatGPT火热之际,并且大多停留在应用层面。对于希望了解其技术根源的人来说,往往难以找到方向。因此,我们编写了《人工智能大语言模型起源篇》,旨在帮助读者找到正确的学习路径,了解大型语言模型的大致起源。本文将分为三个部分,介绍当前主流的大型语言模型架构Transformer(变换器)模型的起源及其发展历程。Transformer并非横空出世,而是人工智能领域研究者们在长期探索和实验中逐步发展起来的。
大型语言模型(LLM)早已经征服了当今的人工智能领域------这不是开玩笑。在短短五年多的时间里,大型语言模型------即变换器(Transformers)------几乎彻底改变了自然语言处理领域。而且,它们正在彻底改变计算机视觉和计算生物学等领域。
由于变换器对每个人的研究议程产生了如此大的影响,今天的这篇文章我想为那些刚刚入门的人工智能学习研究者和从业者整理一份简短的渐进式阅读清单。
建议按下面清单的先后顺序来阅读,这些则主要是专注于学术研究论文。当然,市场上还有很多其他有用的资源:
Jay Alammar 的《Illustrated Transformer》http://jalammar.github.io/illustrated-transformer/;
Lilian Weng 的《一篇更技术性的博客文章》https://lilianweng.github.io/posts/2020-04-07-the-transformer-family/;
Xavier Amatriain 汇总并绘制的《所有主要变换器的目录和家谱》https://amatriain.net/blog/transformer-models-an-introduction-and-catalog-2d1e9039f376/;
Andrej Karpathy 为了教育目的提供的《生成语言模型的最简代码实现》https://github.com/karpathy/nanoGPT;
Sebastian Raschka的《讲座》https://sebastianraschka.com/blog/2021/dl-course.html#l19-self-attention-and-transformer-networks和《书籍》https://github.com/rasbt/machine-learning-book/tree/main/ch16。
理解主要架构和任务
如果你是第一次接触变换器 / 大型语言模型,那么最好从头开始。
(1)Bahdanau、Cho 和 Bengio 于2014年发表的《通过联合学习对齐和翻译的神经机器翻译》(Neural Machine Translation by Jointly Learning to Align and Translate),https://arxiv.org/abs/1409.0473
如果你有几分钟的时间,我建议从上述论文开始。它介绍了一种用于递归神经网络(RNN)的注意力机制,以提高长序列建模能力。这使得RNN能够更准确地翻译更长的句子------这也是后来开发原始变换器架构的动机。
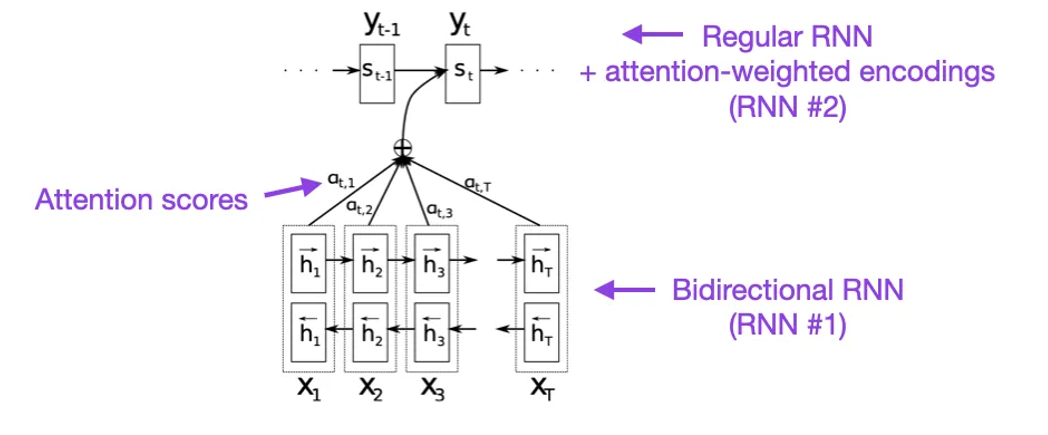
图片来源:https://arxiv.org/abs/1409.0473
(2)Vaswani、Shazeer、Parmar、Uszkoreit、Jones、Gomez、Kaiser 和 Polosukhin 于2017年发表的《Attention Is All You Need》,https://arxiv.org/abs/1706.03762
上面的论文介绍了原始的变换器架构,包括一个编码器和一个解码器部分,这两个部分后来会作为独立的模块变得非常重要。此外,这篇论文还介绍了一些概念,比如缩放点积注意力机制、多头注意力模块和位置输入编码,这些都成为了现代变换器的基础。
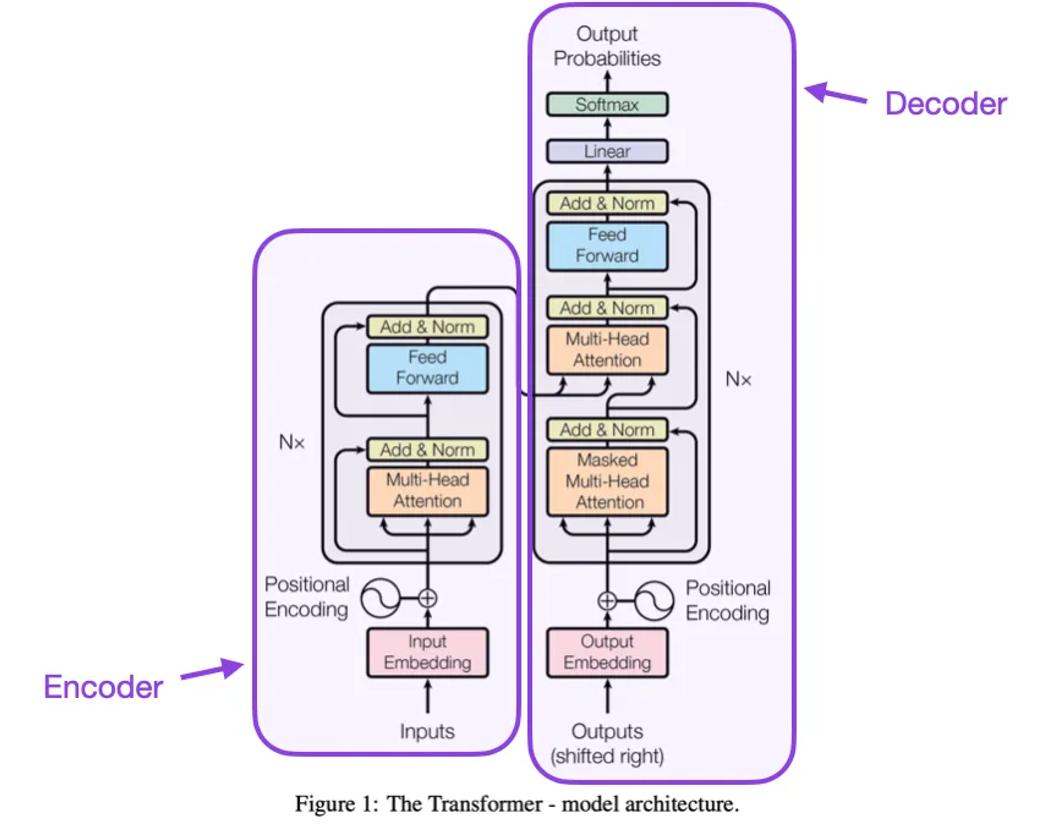
图片来源:https://arxiv.org/abs/1706.03762
(3)Xiong、Yang、He、K Zheng、S Zheng、Xing、Zhang、Lan、Wang 和 Liu 于2020年发表的《On Layer Normalization in the Transformer Architecture》,https://arxiv.org/abs/2002.04745
虽然上面这张来自《Attention Is All You Need》(https://arxiv.org/abs/1706.03762)的原始变换器图是对原始编码器-解码器架构的有用总结,但图中层归一化(LayerNorm)的位置一直是一个备受争议的话题。
举个例子,《Attention Is All You Need》中的变换器图将层归一化放在残差块之间,这与原始变换器论文中附带的官方https://github.com/tensorflow/tensor2tensor/commit/f5c9b17e617ea9179b7d84d36b1e8162cb369f25(更新版)代码实现不一致。图中所示的变体被称为Post-LN变换器,而更新的代码实现默认使用的是Pre-LN变体。
《On Layer Normalization in the Transformer Architecture》https://arxiv.org/abs/2002.04745这篇论文指出,Pre-LN效果更好,能解决梯度问题,如下所示。许多架构在实践中采用了这一方法,但它可能会导致表示崩塌。
所以,虽然目前关于使用Post-LN还是Pre-LN的讨论仍在继续,但也有一篇新论文提出了利用两者优势的方案:ResiDual:带有双残差连接的变换器(https://arxiv.org/abs/2304.14802);它是否在实践中有用,仍有待观察。
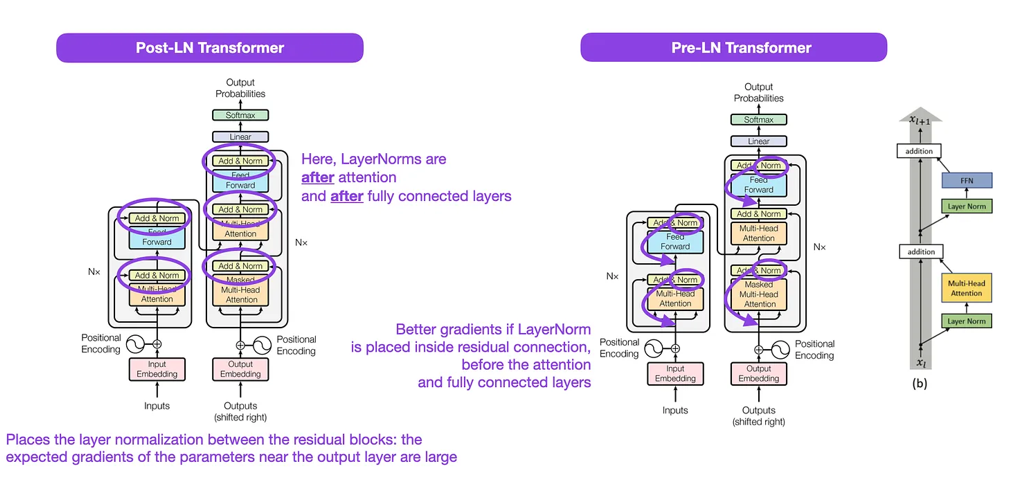
图片来源: https://arxiv.org/abs/1706.03762(左和中)以及 https://arxiv.org/abs/2002.04745(右)
(4)Schmidhuber 于1991年发表的《Learning to Control Fast-Weight Memories: An Alternative to Dynamic Recurrent Neural Networks》,https://www.semanticscholar.org/paper/Learning-to-Control-Fast-Weight-Memories%3A-An-to-Schmidhuber/bc22e87a26d020215afe91c751e5bdaddd8e4922
这篇论文推荐给那些对历史细节以及与现代变换器(Transformers)原理上有相似性的早期方法感兴趣的人。
例如,在1991年,也就是大约在上述原始变换器论文(《Attention Is All You Need》)发布的二十五年半之前,Juergen Schmidhuber 提出了一个递归神经网络的替代方案,称为快速权重编程(Fast Weight Programmers,FWP)。FWP方法涉及一个前馈神经网络,通过梯度下降慢慢学习来编程另一个神经网络的快速权重变化。
这个与现代变换器的类比在这篇博客文章https://people.idsia.ch//\~juergen/fast-weight-programmer-1991-transformer.html#sec2中是这样解释的:
在今天的变换器术语中,FROM 和 TO 分别被称为键(key)和值(value)。应用于快速网络的输入被称为查询(query)。本质上,查询通过快速权重矩阵处理,后者是键和值外积的和(忽略归一化和投影)。由于两个网络的所有操作都是可微的,我们通过加法外积或二阶张量积获得了快速权重变化的端到端可微的主动控制。FWP0-3a 因此,慢网络可以通过梯度下降学习在序列处理过程中快速修改快网络。这在数学上等价(除了归一化)于后来被称为具有线性自注意力的变换器(或线性变换器)。
正如上面博客摘录所提到的,这种方法现在被称为"线性变换器"或"具有线性化自注意力的变换器",通过2020年在arXiv上发布的几篇论文《Transformers are RNNs: Fast Autoregressive Transformers with Linear Attention》https://arxiv.org/abs/2006.16236和《Rethinking Attention with Performers》https://arxiv.org/abs/2009.14794进一步阐明了这一点。
2021年,论文《Linear Transformers Are Secretly Fast Weight Programmers》则明确展示了线性化自注意力和1990年代的快速权重编程之间的等价性。"
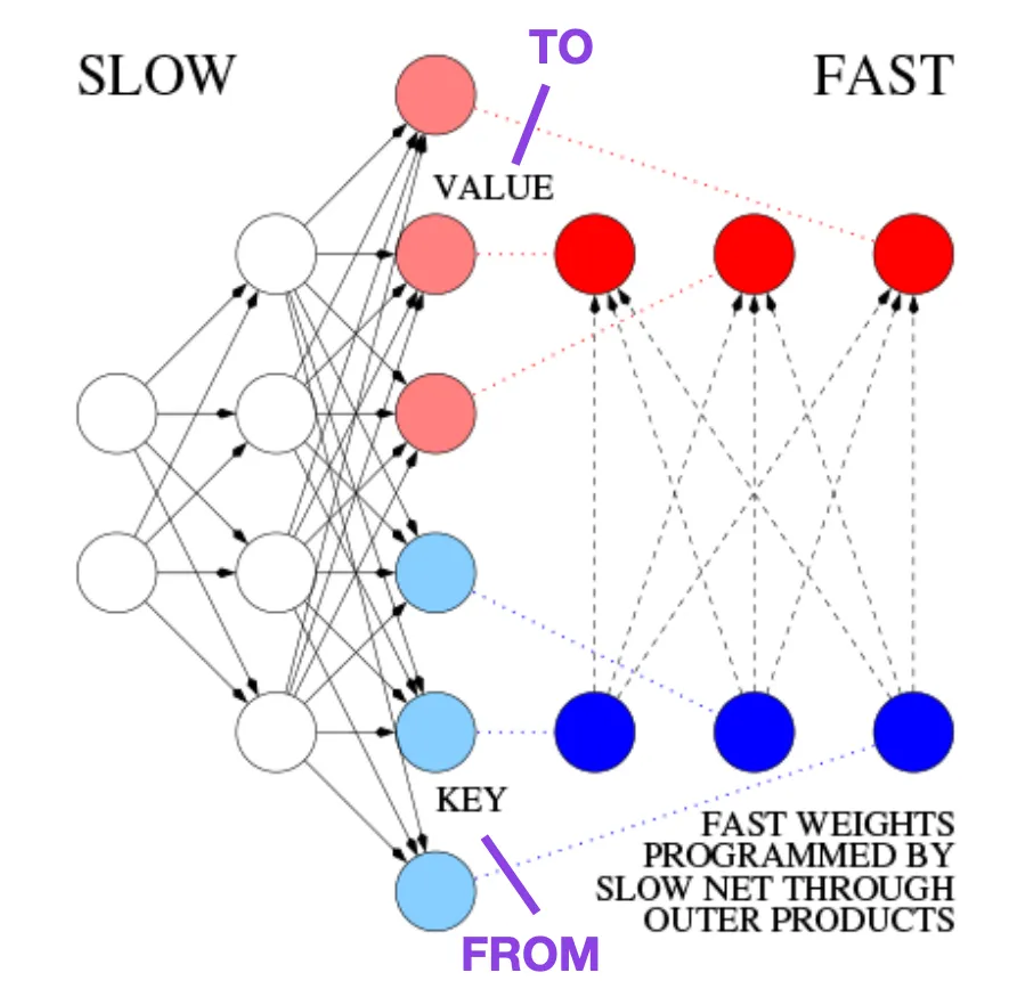
来源:基于https://people.idsia.ch//\~juergen/fast-weight-programmer-1991-transformer.html#sec2的注释图