1. 引言
本教程旨在介绍在Mac 电脑上安装Hadoop
2. 前提条件
2.1 安装JDK
Mac电脑上安装Hadoop,必须首先安装JDK,并配置环境变量(此处不做详细描述)
2.2 配置ssh环境
关闭防火墙

在Mac下配置ssh环境,防止后面启动hadoop时出现Connection refused 连接被拒绝的错误。
bash
ssh localhost执行上面命令后,终端如果出现如下问题:
ssh: connect to host localhost port 22: Connection refused
表示当前用户没权限,更改设置如下:

再次输入ssh localhost会提示输入密码,这个时候要重新配置一下ssh免密登录。
(1) 进入ssh的目录:
bash
cd ~/.ssh(2) 将id_rsa.pub中的内容拷贝到 authorized_keys中:
bash
cat id_rsa.pub >> authorized_keys3.安装与配置Hadoop
3.1 使用brew 安装 Hadoop
bash
brew install hadoop3.2 查看是否安装成功
hadoop version3.3 修改Hadoop 配置文件
3.3.1 进入Hadoop的目录
bash
cd /opt/homebrew/Cellar/hadoop/3.4.0/libexec/etc/hadoop3.3.2 修改core-site.xml
bash
# 以文件方式打开配置文件
open -e core-site.xml在core-site.xml文件的标签内添加如下内容:
xml
<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://localhost:8020</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/opt/homebrew/Cellar/hadoop/tmp</value>
</property>
</configuration>创建tmp文件夹,用来指定hadoop运行时产生文件的存放目录
bash
mkdir /opt/homebrew/Cellar/hadoop/tmp3.3.3 修改hdfs-site.xml
bash
open -e hdfs-site.xml在hdfs-site.xml文件的标签内添加如下内容:
xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.permissions</name>
<value>false</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/opt/homebrew/Cellar/hadoop/tmp/dfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/opt/homebrew/Cellar/hadoop/tmp/dfs/data</value>
</property>
</configuration>创建dfs、name、data文件夹(存放数据)
bash
mkdir /opt/homebrew/Cellar/hadoop/tmp/dfs
mkdir /opt/homebrew/Cellar/hadoop/tmp/dfs/name
mkdir /opt/homebrew/Cellar/hadoop/tmp/dfs/data 3.3.4 修改mapred-site.xml
bash
open -e mapred-site.xml在配置文件中添加一下内容,注意配置中的路径
xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9010</value>
</property>
<property>
<name>yarn.app.mapreduce.am.env</name>
<value>HADOOP_MAPRED_HOME=/opt/homebrew/Cellar/hadoop/3.4.1/libexec</value>
</property>
<property>
<name>mapreduce.map.env</name>
<value>HADOOP_MAPRED_HOME=/opt/homebrew/Cellar/hadoop/3.4.1/libexec</value>
</property>
<property>
<name>mapreduce.reduce.env</name>
<value>HADOOP_MAPRED_HOME=/opt/homebrew/Cellar/hadoop/3.4.1/libexec</value>
</property>
</configuration>3.3.5 修改yarn-site.xml
bash
open -e yarn-site.xml在配置文件中添加一下配置:
xml
<configuration>
<!-- Site specific YARN configuration properties -->
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.resourcemanager.address</name>
<value>localhost:9000</value>
</property>
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>100</value>
</property>
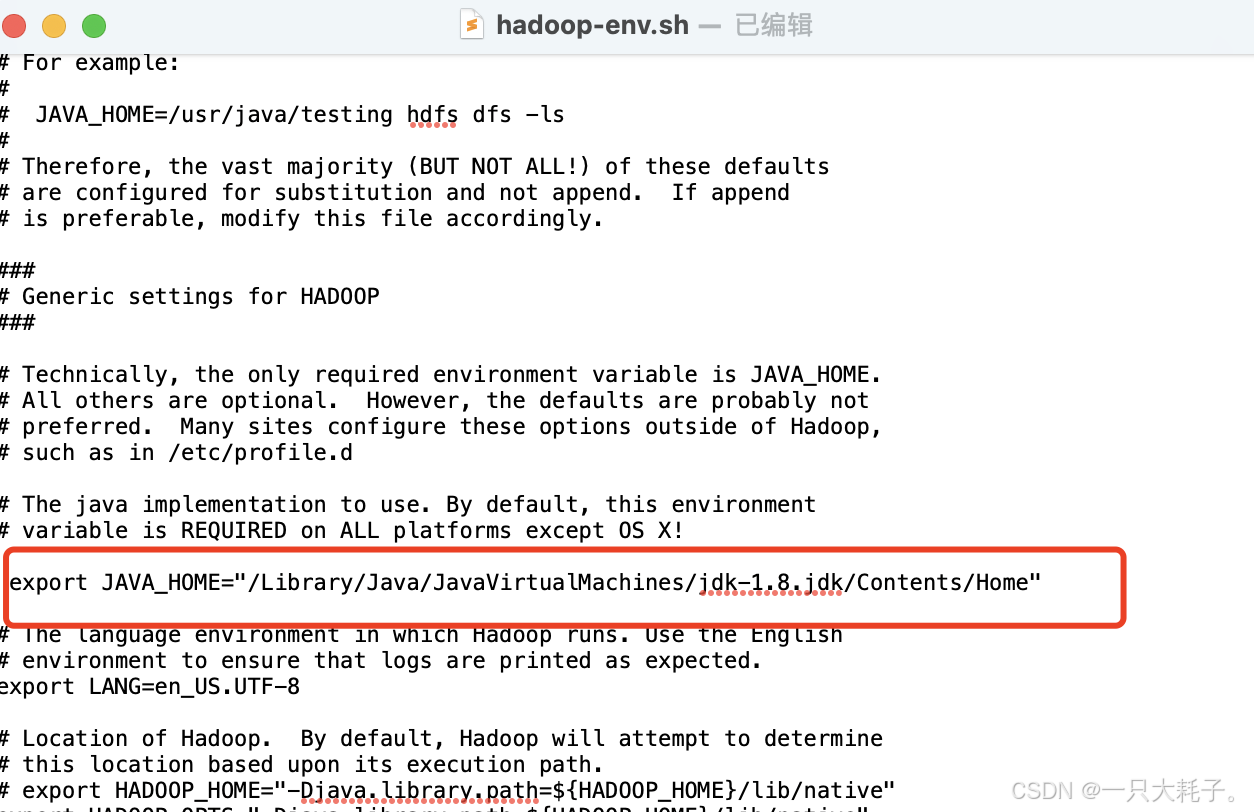
</configuration>3.4 修改hadoop-env.sh 文件
cd /opt/homebrew/Cellar/hadoop/3.4.0/libexec/etc/hadoop
open -e hadoop-env.sh找到文件中 export JAVA_HOME该行,打开注释,并添加Java安装路径,如下:
4.启动Hadoop
4.1 对文件系统进行格式化
bash
cd /opt/homebrew/Cellar/hadoop/3.4.1/libexec/sbin
hdfs namenode -format出现以下信息代表成功

4.2 执行HDFS启动命令
bash
./start-dfs.sh访问http://localhost:9870出现一下页面代表成功

4.3 执行YARN调度系统启动
bash
./start-yarn.sh